
摘要
检索增强生成(Retrieval-Augmented Generation,RAG)通过引入外部知识来抑制幻觉,从而提升大语言模型(LLMs)的响应质量和领域特定性能。近期研究将图结构引入 RAG,以增强对实体之间语义关系的建模能力。然而,这类方法主要关注低阶的实体两两关系,限制了对多实体之间高阶关联的刻画。为弥补这一不足,超图增强方法通过超边对多实体交互进行建模,但通常仅局限于跨文本块的实体级表示,忽视了不同文本块之间全局主题结构的组织与对齐。
受人类推理自上而下认知过程的启发, 本文提出了一种主题对齐的双超图 RAG 框架(Cog-RAG):其中,主题超图用于捕获跨文本块的主题结构,实体超图用于建模高阶语义关系。此外,设计了一种认知启发的两阶段检索策略:首先在主题超图中激活与查询相关的主题内容,然后引导在实体超图中的细粒度召回与信息扩散,实现从全局主题到局部细节的语义对齐与一致生成。大量实验结果表明,Cog-RAG 显著优于现有的最先进基线方法。
引言
检索增强生成(Retrieval-Augmented Generation,RAG)近年来受到越来越多关注,用于提升大语言模型(LLMs)在知识密集型任务中的表现(Lewis 等,2020;Gao 等,2023;Li 等,2024)。它通过引入外部知识来抑制 LLM 的幻觉,从而增强响应的质量和可靠性(Ayala & Bechard,2024;Xia 等,2025)。此外,RAG 可与私有或领域特定知识库集成,从而提高模型在垂直领域的适应性。凭借这些优势,RAG 已成为问答、文档理解和智能助手等应用中的核心组成部分(Fan 等,2024;Dong 等,2025)。
尽管 RAG 在提升 LLM 响应质量方面具有显著潜力,但当前方法大多依赖扁平化的基于文本块的检索,即通过向量相似度将查询匹配到文档块(Asai 等,2023;Yang 等,2024)。然而,这种方法难以捕捉跨文本块的依赖关系和语义层次,导致检索内容零散、关联性弱,从而削弱模型对整体知识的结构化理解。
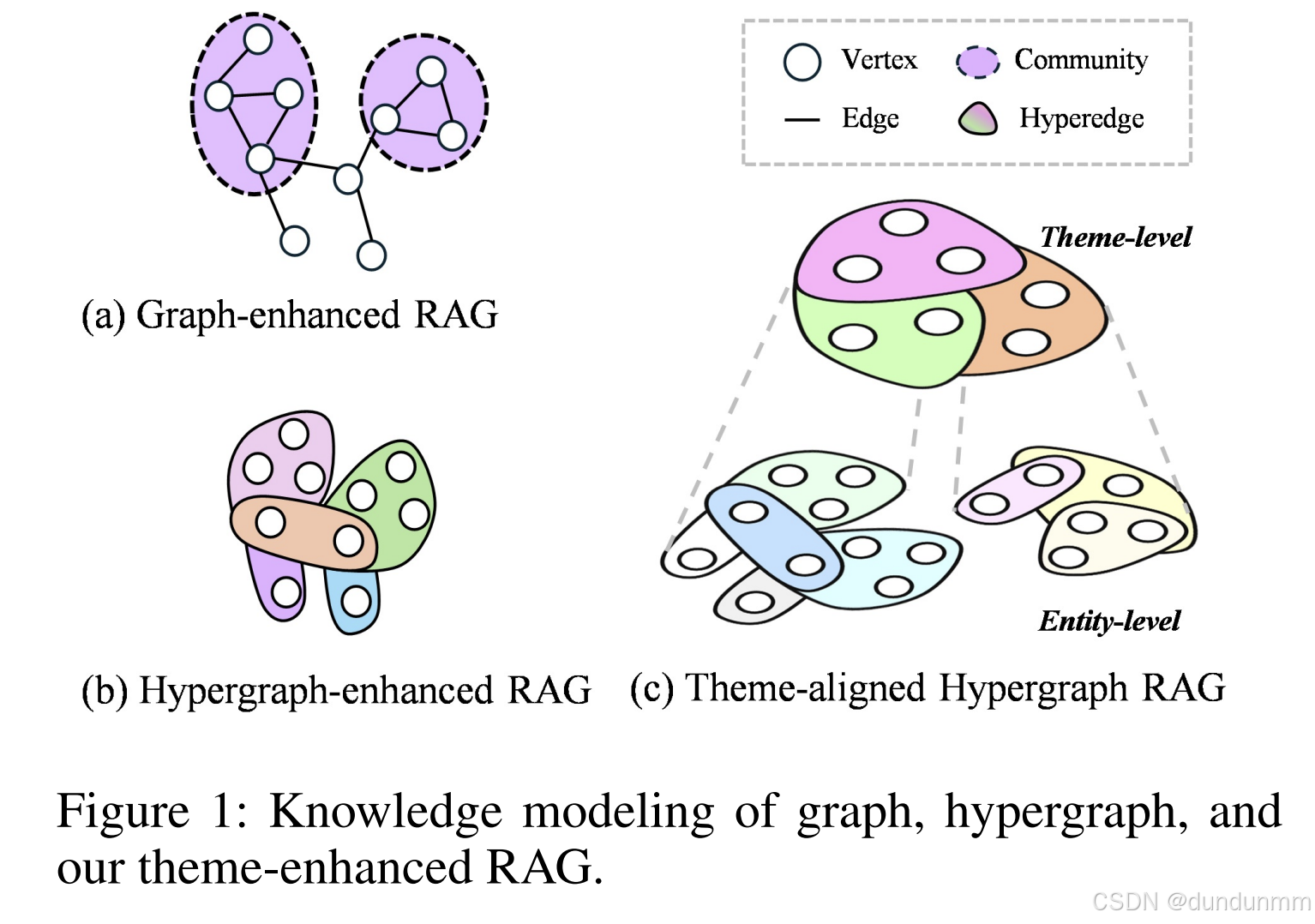
为了解决这一问题,近期研究尝试将图结构引入 RAG 框架,以构建覆盖语料库的知识图,捕捉实体间的结构化语义关系(Peng 等,2024;Zhang 等,2025;Wang 等,2025)。例如,GraphRAG(Edge 等,2024)和 LightRAG(Guo 等,2024)利用图结构增强实体级索引与检索,显式捕捉语义关系以改进信息组织;Hyper-RAG(Feng 等,2025a)则使用超图建模多实体间的复杂关系。++然而,这些方法主要集中于实体级结构建模,缺乏统一的主题组织和语义驱动的推理,因此难以支持从宏观理解到微观细节的信息层次整合。++
值得注意的是,人类在处理复杂任务时倾向于采用自上而下的信息处理路径(Cheng 等,2025;Gutierrez 等,2024)。他们通常首先识别问题的核心主题,构建全局语义框架,然后在此基础上回忆并整合相关细节,以形成连贯且结构化的响应。这种"主题驱动、细节回忆"的认知模式体现了人类信息处理中的固有层次组织与语义一致性。
受此认知启发,本文提出了一种主题对齐的双超图 RAG 框架(Cog-RAG)。图 1 展示了其在知识建模方面与其他方法的差异。方法利用双超图结构对全局主题结构和细粒度高阶语义关系进行建模。同时,引入认知启发的两阶段检索策略,模拟人类自上而下的信息理解过程,从而增强生成响应的语义一致性和结构表现力。
主要贡献总结如下:
-
提出 Cog-RAG:模拟人类自上而下的信息处理路径,实现从宏观语义理解到微观信息整合的分层生成建模。
-
设计双超图语义索引方案:分别建模跨文本块的全局主题结构与文本块内的细粒度高阶语义关系,克服以往图增强 RAG 模型仅关注两两关系、缺乏统一主题组织的局限。
-
开发认知启发的两阶段检索策略:首先在主题超图中激活相关上下文,然后在实体超图中触发细节回忆与信息扩散。这种"主题驱动、细节回忆"的流程实现跨粒度语义对齐,显著提升响应的连贯性和质量。
方法
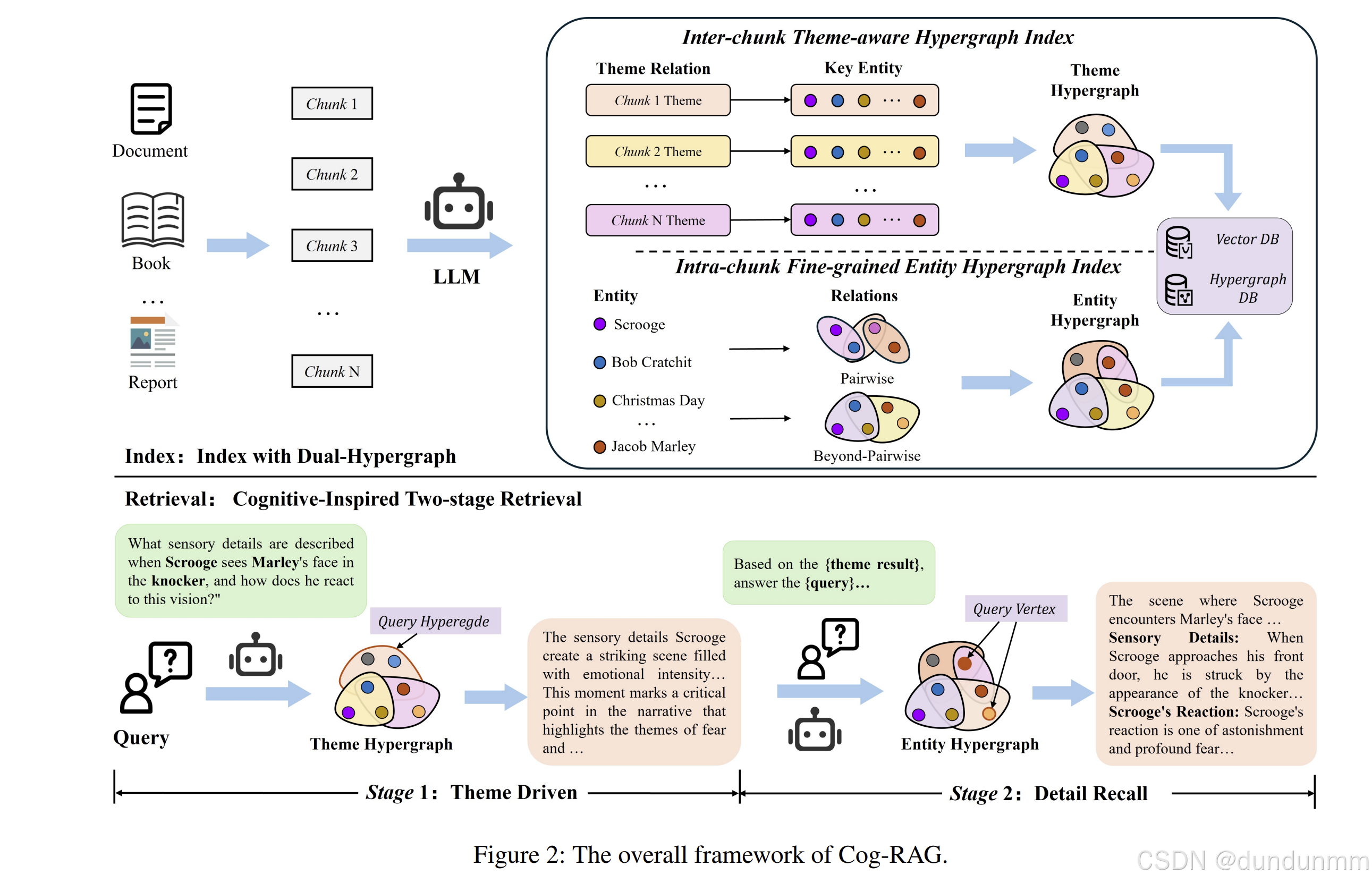
如图 2 所示,Cog-RAG 由两个主要组件构成:双超图索引 与认知启发的两阶段检索 。构建了具有互补语义粒度的双超图结构:其中,主题超图 用于捕获文本块之间的语义主题关联(如故事线、叙事大纲与摘要),提供全局语义主题组织;实体超图用于建模实体(如人物、概念与事件)之间细粒度的高阶关系,支撑局部语义关联。在检索阶段,Cog-RAG 模拟人类"自上而下"的推理模式,首先在主题超图中激活相关主题,作为全局语义锚点;在这些锚点的引导下,再从实体超图中检索相关实体及其关系信息。最终,语言模型基于"主题驱动、细节回忆"的知识证据生成响应。
双超图索引(Dual-Hypergraph Indexing)
为更有效地建模语料中多实体之间复杂的高阶关联,并避免传统图结构带来的信息损失,本文引入超图进行建模。其一般形式化定义如下:
M=(LLM,R(q,D={V,Elow,Ehigh})),(3)
其中,超边用于表示关系;Elow表示低阶的实体两两关系,Ehigh表示超越两两关系的多实体高阶关联。
主题感知超图索引(Theme-Aware Hypergraph Index)
主题超图旨在建模文档的语义故事线结构,构建叙事大纲,为后续的细节检索提供认知引导。
给定语料库 D(如书籍、报告或操作手册),先采用具有部分重叠的固定长度滑动窗口将其划分为一组文本块,以保持语义完整性,表示为:
D={D1,D2,...,DN},(4)
其中 Di表示第 i 个文档块,作为后续分析的基本单元。
随后,利用大语言模型对每个文本块进行语义解析,自动提取其潜在主题及相关关键实体,从而构建主题超图。具体而言,首先使用预定义的主题级抽取提示词 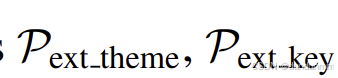 ,引导 LLM 对每个文本块 Di 进行语义解析并输出对应主题;然后进一步抽取与该主题相关的关键实体。其计算过程如下:
,引导 LLM 对每个文本块 Di 进行语义解析并输出对应主题;然后进一步抽取与该主题相关的关键实体。其计算过程如下:
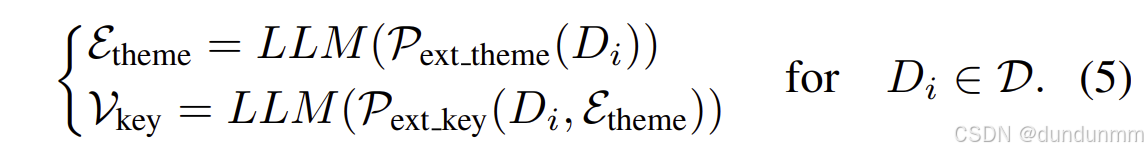 基于提取的主题与实体,构建主题超图 Gtheme,表示为:
基于提取的主题与实体,构建主题超图 Gtheme,表示为:
Gtheme={Vkey,Etheme},(6)
其中,每条超边 Etheme 表示一个文本块的叙事主题,而顶点 Vkey 为对应的关键实体。
细粒度实体超图索引(Fine-Grained Entity Hypergraph Index)
在构建主题超图并获得跨文本块的全局主题结构之后,为进一步捕获细粒度的多实体关系,在每个文本块内部构建实体超图,用于建模实体之间的高阶关系,支撑后续的细粒度检索。
对于每个文本块 DiD,首先利用 LLM 抽取实体(如人物、事件、组织等)及其描述,作为细粒度实体超图的顶点集合。随后,根据实体之间的语义关系构建两类超边:低阶超边 Elow 用于刻画基本的实体两两关系,高阶超边 Ehigh 用于建模多实体之间更复杂的语义关联,如事件中的共现关系或因果联系。其抽取过程表示如下:

其中, 为实体抽取提示词,P^{ext}{low} 与 P^{ext}{high}分别用于从已抽取实体中获取成对关系与群组关系。
为实体抽取提示词,P^{ext}{low} 与 P^{ext}{high}分别用于从已抽取实体中获取成对关系与群组关系。
最终,将所有抽取的实体及其低阶、高阶关系组织为一个细粒度实体超图 Gentity,并存储于超图数据库中:
Gentity={V,Elow,Ehigh}.(8)
认知启发的两阶段检索(Cognitive-Inspired Two-Stage Retrieval)
受人类记忆检索中自上而下信息处理模式的启发,本文设计了一种认知启发的两阶段检索策略。具体而言,该策略首先在主题超图中识别与查询相关的主题线索(theme threads),随后以这些线索作为提示,引导从实体超图中检索细粒度信息。
对于给定的用户查询 q,首先从中抽取主题关键词(即概括性的概念或主题),表示为:
Xtheme=LLM(Pkeyword(q)),(9)
其中 X∗={x1,x2,...},Pkeyword为从查询中抽取主题关键词的提示词。
主题感知超图检索(Theme-Aware Hypergraph Retrieval)
随后,在超图数据库上执行结构化检索。需要注意的是,主题关键词通常反映多个实体之间的抽象语义关系,因此主要用于检索相关的超边。
在第一阶段检索中,利用抽取的主题关键词在主题超图中进行语义匹配,选取相关度最高的 top-k 条主题超边:
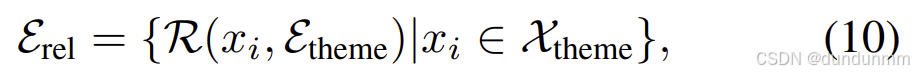 其中 Erel表示从向量数据库中检索得到的相关超边集合。随后,在超图数据库上执行扩散过程,检索这些超边的邻接顶点,以为主题提供更丰富的上下文信息:
其中 Erel表示从向量数据库中检索得到的相关超边集合。随后,在超图数据库上执行扩散过程,检索这些超边的邻接顶点,以为主题提供更丰富的上下文信息:
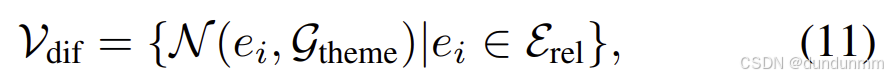
其中 N(⋅)表示从超图中获取相应邻居的函数,Vdif 为扩散得到的顶点集合。
接着,将 Erel与 Vdif 及其对应的文本上下文一并输入至 LLM,作为先验知识生成初始的主题感知回答:
Atheme=LLM(q,Erel,Vdif,Crele,Cdifv),(12)
其中 Atheme表示基于主题超图 Gtheme检索后对查询 q 的初步回答,C∗为对应的上下文信息。
主题对齐的实体超图检索(Theme-Aligned Entity Hypergraph Retrieval)
在完成基于主题的初始检索后,进一步在实体超图中执行细粒度信息检索。在已检索主题的引导下,该阶段补充实体级语义细节,实现局部信息与全局主题之间的有效对齐。
基于主题阶段生成的响应,进一步从查询 q 中抽取与主题对齐的实体关键词(即具体实体或细节信息),表示为:
Xentity=LLM(Palign(q,Atheme)),(13)
其中 Palign为用于抽取与主题对齐的实体关键词的提示词。Xentity 主要描述具体个体层面的信息,因此用于与实体超图中的顶点进行匹配。两类关键词(主题与实体)与超图结构的自然结合,提升了检索的针对性和结构一致性。
不同于主题检索阶段主要针对超边进行检索,该阶段侧重于依据实体关键词在实体超图中检索相关度最高的 top-k 个顶点,从而实现细粒度语义补充与结构化对齐:
Vrel={R(xi,Ventity)∣xi∈Xentity},(14)
其中 Vrel表示检索得到的相关实体集合。随后,在实体超图上执行结构扩散过程:
Edif={N(vi,Gentity)∣vi∈Vrel}.(15)
最后,将检索得到的实体集合 Vrel、扩散得到的超边 Edif及其对应上下文,与前一阶段的主题信息 Atheme进行整合,构成结构化输入,送入 LLM 生成查询 qqq 的最终回答 A,从而实现由主题引导到细节支撑的完整语义生成过程:
A=LLM(q,Atheme,Vrel,Edif,Crelv,Cdife).(16)
实验
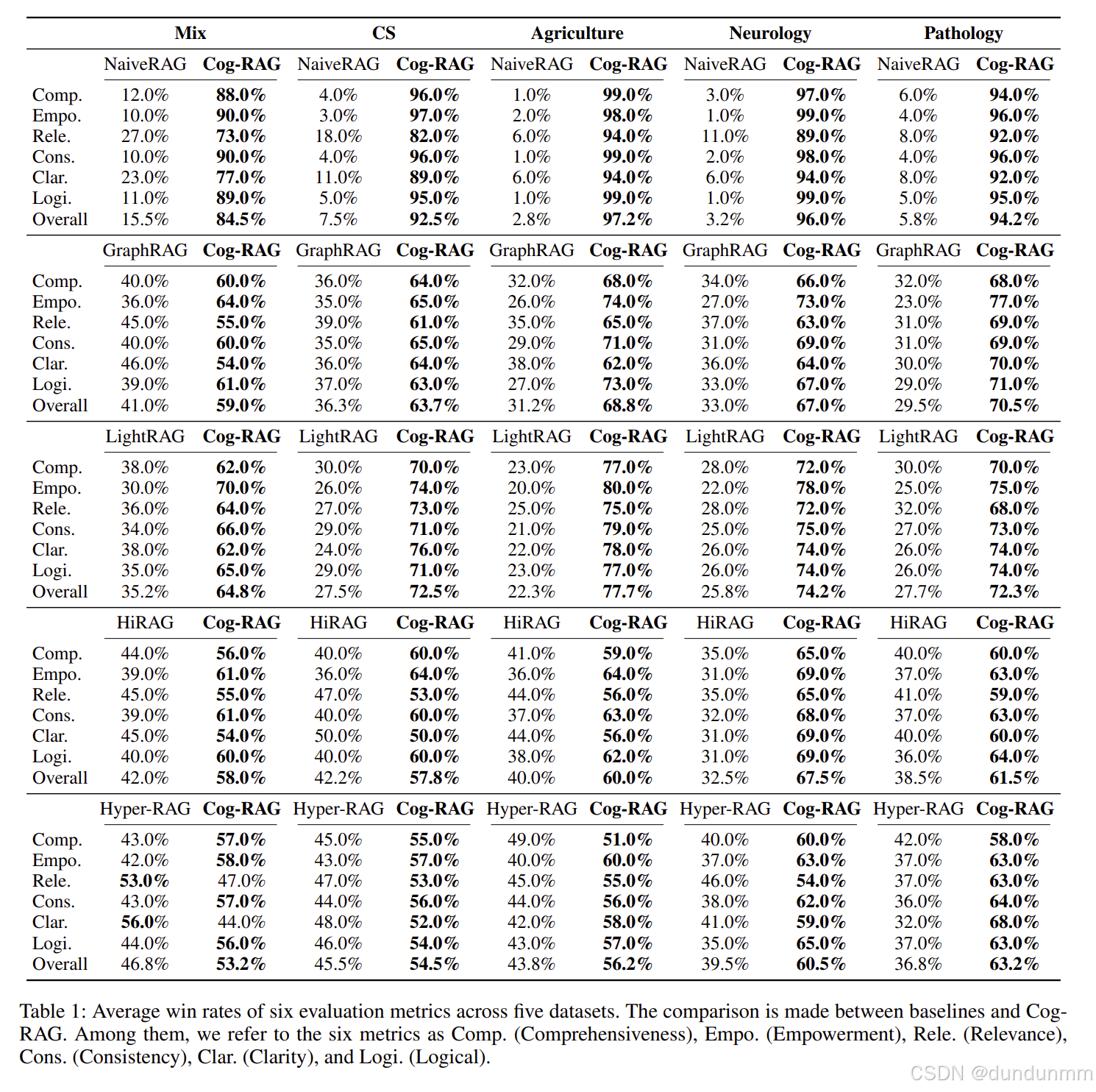
后面会详细的看一下实验的写法