安装
- 下载spark安装包;(spark-3.2.1-bin-hadoop2.7.tgz)
- 下载地址:https://archive.apache.org/dist/spark/
- 上传到bigdata目录下,解压到bigdata目录下;tar -zxvf spark-3.2.1-bin-hadoop2.7.tgz
(重命名为spark,mv命令)mv spark-3.2.1-bin-hadoop2.7 spark
- 配置环境变量:
vi /etc/profile
export SPARK_HOME=/bigdata/spark
export PATH=PATH:{SPARK_HOME}/bin:${SPARK_HOME}/sbin
刷新配置文件:
source /etc/profile
- 进入conf目录复制spark-env.sh.template,重命名为spark-env.sh文件,
cp spark-env.sh.template spark-env.sh
- 配置如下:vi spark-env.sh
export JAVA_HOME=/root/meituan/jdk1.8.0_121/
export SPARK_MASTER_IP=192.168.10.130
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/bigdata/hadoop/etc/hadoop
- 添加三个从节点信息, vim /bigdata/spark/conf/slaves
输入:先创建slaves文件,再添加如下内容:
son1
son2
son3
- cd /bigdata
scp -r spark root@son1:/bigdata
scp -r spark root@son2:/bigdata
scp -r spark root@son3:/bigdata
- 启动服务:cd /bigdata/spark
启动服务(hadoop):start-all.sh
启动服务(spark):sbin/start-all.sh
输入spark-shell即可看到如下信息:
Spark Shell 中运行的 Scala 语言代码
spark管理界面:http://192.168.10.130:8080/
Spark算子
Spark算子主要分为两大类: 转换算子(Transformation) 和 行动算子(Action) 。
转换算子 Transformation
用于从一个数据集转换生成另一个数据集,具有惰性求值特性,即调用后不会立即执行,而是记录操作依赖关系,直到遇到 行动算子 时才触发实际计算;常见的转换算子包括:
map(func)
对原RDD中每个元素运用func函数,并生成新的RDD
val list = List(1,2,3)
sc.parallelize(list).map(_ * 10).foreach(println)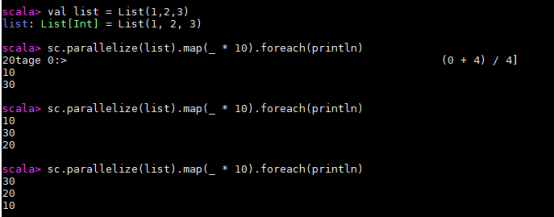
sc=spark context
上面的这句话中:行动算子是 foreach(println) 整体,而 println 只是传给 foreach 的一个普通函数参数。
filter(func)
对原RDD中每个元素使用func函数进行过滤,并生成新的RDD
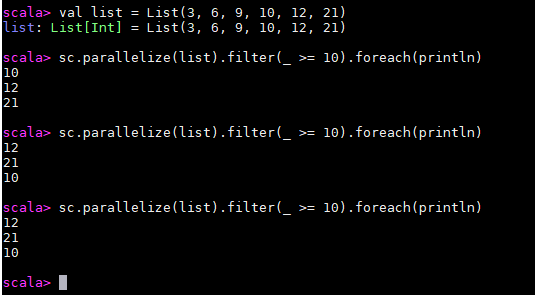
val list = List(3, 6, 9, 10, 12, 21)
sc.parallelize(list).filter(_ >= 10).foreach(println)
flatMap(func)
先映射(map)再扁平化(flat),处理完后会把所有结果合并成一个新的 RDD
把一个多维列表拍平成一维
val list = List(List(1, 2), List(3), List(), List(4, 5))
sc.parallelize(list).flatMap(_.toList).foreach(println)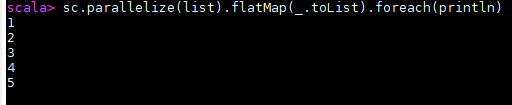
val lines = List("spark flume spark", "hadoop flume hive")
sc.parallelize(lines).flatMap(line => line.split(" ")).map(word=>(word,1)).reduceByKey(_+_).foreach(println)flatMap 这个算子在日志分析中使用概率非常高,这里进行一下演示:拆分输入的每行数据为单个单词,并赋值为 1,代表出现一次,之后按照单词分组并统计其出现总次数
sc.parallelize(lines).flatMap(line => line.split(" ")).map(word=>(word,1)).reduceByKey(+).foreach(println)

sc.parallelize(lines) 先把lines这个数据集传进去
=>:Scala 匿名函数的语法,相当于 "把 line 映射成..."
line => line.split(" ") 把lines里面的每一个元素(如:"spark flume spark")按照空格进行分割(得到如 "spark","flume","spark")。分割完以后,因为是flatMap还要拍平成一个列表(最终这一步得到的 RDD 是:"spark","flume","spark","hadoop","flume","hive")
① word:代表 flatMap 后 RDD 中的每一个单词(如 "spark")
② =>:匿名函数语法
③ (word,1):把每个单词转换成一个键值对(元组),键是单词,值是 1(如 ("spark",1))这一步后 RDD 变成:("spark",1),("flume",1),("spark",1),("hadoop",1),("flume",1),("hive",1)
reduceByKey(+) 的参数(简化版匿名函数)
reduceByKey()告诉 Spark 要 "按 Key 分组后做聚合"。(_+_) 只是这个算子的参数(一个匿名函数),是 "聚合规则",告诉 Spark 聚合时要 "把相同 Key 的 Value 相加"。
① _:代表匿名函数的参数(第一个_是第一个值,第二个_是第二个值)
② +:对值做累加这一步会把相同单词的 1 累加,结果 RDD 是:("spark",2),("flume",2),("hadoop",1),("hive",1)
foreach(println)
对 RDD 中的每个元素执行指定操作(无返回值),这是触发 Spark 任务执行的 "行动"
【问】:前面是lines,怎么后面变成line了?怎么又出来一个word变量?是不是写别的名字比如用example target这些词表示lines里面的元素也可以?
lines 是你定义的整个集合的名字(List 类型),代表 "所有行的集合",
而 flatMap(line => ...) 里的 line 是遍历集合时的 "单个元素" 的名字
mapPartitions(func)
先导入包:
import scala.collection.mutable.ArrayBuffer
val list = List(1, 2, 3, 4, 5, 6)
sc.parallelize(list, 3).mapPartitions(iterator => {
val buffer = new ArrayBufferInt
while (iterator.hasNext) {
buffer.append(iterator.next() * 100)
}
buffer.toIterator
}).foreach(println)
代码整体功能
先给你一个整体结论:这段代码把列表 [1,2,3,4,5,6] 并行化成 3 个分区的 RDD,然后按分区批量处理数据(每个元素乘以 100),最后打印所有处理后的结果。
// 2. 将Scala列表并行化为Spark的RDD,指定3个分区
sc.parallelize(list, 3)
sc:SparkContext 的实例,是 Spark 程序的入口,负责创建 RDD 、连接集群;
parallelize(数据集, 分区数):转换算子,把本地集合转成分布式 RDD
使得Spark可以连接上Hive
连接数据库的时候需要上传jar包到$SPARK_HOME/jars路径下
把驱动包放到 Spark 所有节点的 $SPARK_HOME/jars/ 目录下(确保集群所有节点都有,避免节点间驱动缺失);
scp -r jars root@son1:/bigdata/spark
scp -r jars root@son2:/bigdata/spark
scp -r jars root@son3:/bigdata/spark
-r是直接覆盖文件夹
把 Hive 的配置文件 hive-site.xml 复制到 Spark 的 conf 目录下(如 $SPARK_HOME/conf/)
cp /bigdata/apache-hive-2.3.3-bin/conf/hive-site.xml /bigdata/spark/conf/
scp -r hive-site.xml @son1:/bigdata/spark/conf
scp -r hive-site.xml @son2:/bigdata/spark/conf
scp -r hive-site.xml @son3:/bigdata/spark/conf
环境准备
先把 Hive 的配置文件就是把jar包拷给 Spark,不然连不上元数据:
cp /home/tony/hive/conf/hive-site.xml /bigdata/spark/conf/
启动 Spark Shell
注意要带上 MySQL 驱动包(大家路径可能不一样,先用 ls 找一下自己的包在哪):
bin/spark-shell --master spark://tonymin:7077 --jars /home/tony/hive/lib/mysql-connector-java-5.1.40.jar
bin/spark-shell --master spark://tonymin:7077 --jars /bigdata/spark/jars/mysql-connector-java-5.1.40.jar
Spark 代码
// 1. 切换到目标数据库
spark.sql("use liaoyang_bank;")
// 2. 取出前10条数据作为测试样本
spark.sql("select * from ods_cust_basic limit 10;")
-
res4:Spark给这个结果分配了一个变量名res8(result 8)
// 显示前10行,默认只显示20个字符的宽度
res4.show()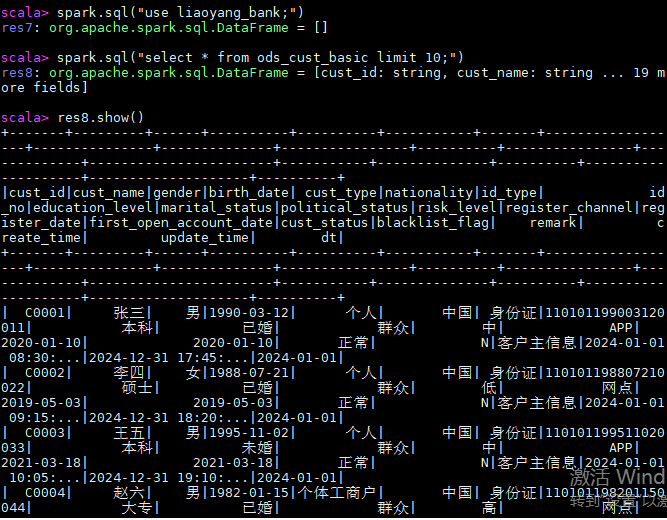
// 3. 将结果写入新表 (自动建表)
// 这里的 tony_vip_test 大家可以改成自己的名字
df.write.mode("overwrite").saveAsTable("tony_vip_test")
// 4. 验证查看结果
spark.sql("select * from tony_vip_test").show()