1.朴素目标检测思路
1.训练阶段构建(分类+回归)
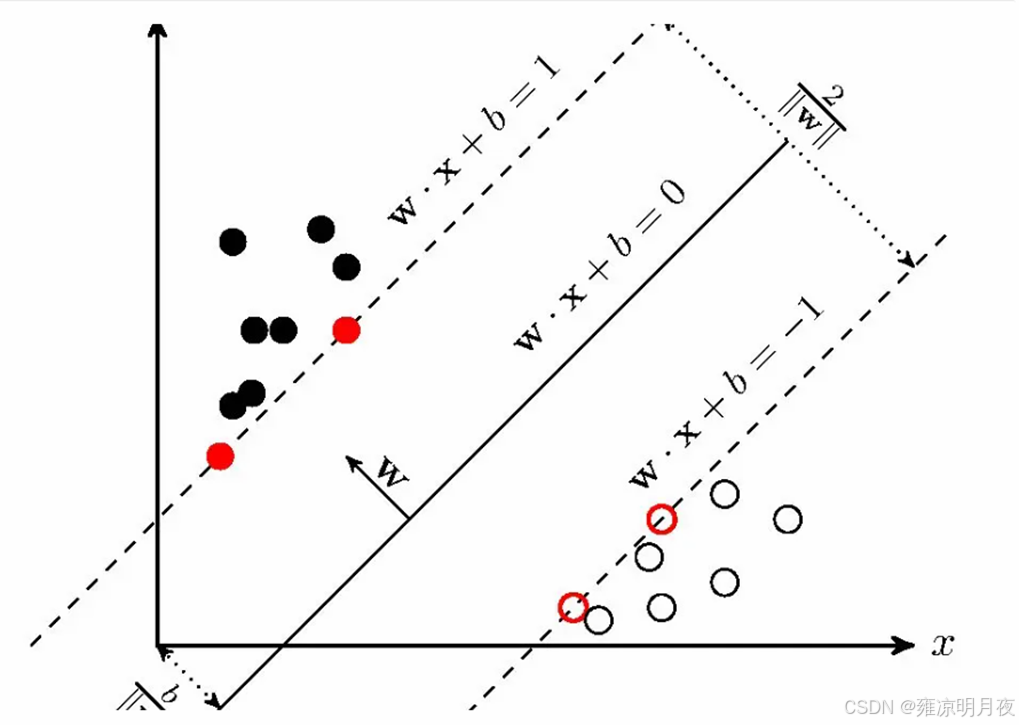
核心概念:IOU交并比
IOU(Intersection over Union)交并比 是目标检测、实例分割等任务中,衡量预测框(Prediction Box) 与真实框(Ground Truth Box) 重叠程度的核心指标。

RCNN:如何用分类来做检测
思路:
预处理→计算 IoU→样本划分→样本平衡→模型训练
- 预处理 :将输入图像划分为SxS个等大网格(网格单元 ),每个网格预先定义K个不同尺寸、长宽比的先验框。
- 计算 IOU :对每个先验框,计算它与图像中所有GT 框的 IOU 值。
- 样本划分
- 正样本:① 与某 GT 框 IoU > 高阈值(如 0.5);② 对每个 GT 框,匹配 IoU 最大的先验框(强制为正样本)。
- 负样本:与所有 GT 框 IoU < 低阈值(如 0.1)的先验框。
- 忽略样本:\(0.1 < IoU < 0.5\)的先验框,不参与训练。
- 样本平衡 :控制正负样本比例为1:3,多余的负样本随机丢弃,优先保留正样本附近的负样本(提升模型区分目标与背景的能力)。
- 模型训练:正样本同时计算「分类损失 + 回归损失」,负样本只计算「分类损失」,忽略样本无损失。
经验:不清晰/怀疑的样本/过小的样本不参与训练,我们保证正负样本的比例为1:3,多余的删除,挑选的负样本随机选/挑选正样本附近的区域。
框的划分
1.网格单元:将原图进行分割成9宫格或别的大小相等框。
2.目标框GT:我们任务目标所标记的框。
3.先验框:预先定义在每个网格单元上的 K 个不同尺寸、不同长宽比的参考框。
先验框的核心作用:
1.作为样本划分的 "判断依据", 每个先验框与 GT 框的 IoU 值,结合阈值(0.1/0.5),区分出正样本、负样本、忽略样本。
**2.作为边界框回归的 "基准锚点",**先验框的偏移量和缩放系数。
经过上述规划总结很容易发现重难点:
1.如何改良合适的先验框。
2.选正负样本,控制比例1:3。
分类module操作流程:
训练集:
1.自定义框(先验框)。
2.通过先验框+gt框 计算 IOU 划分正负样本1:3。
3.将正负样本喂给模型做分类 -> 构建分类模型。
验证集:
1.拿一张新图片,画格子
2.喂给模型做分类,发现其中的先验框2的概率最大 -> 先验框2有目标。
总结:分类模型的输入为图片上画的先验框,输出为正负样本的分类结果。
回归module操作流程:
**->**问题:我们仅判断先验框2有目标,其不会与人脸真实框完全重合有偏移。
-> 我们希望预测的Box与gt的Box差距最小-> pre_box ≈ gt_box
->偏差t的计算
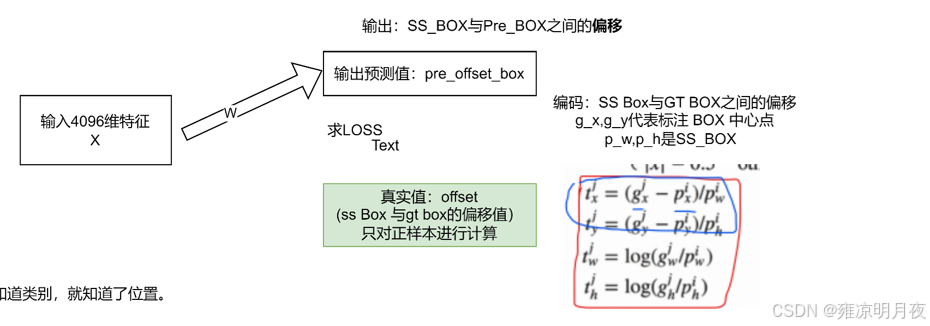
我们pre_box是具有的信息(px,py,pw,ph) == (中心点x,中心点y,pre_box的宽,pre_box的高)
我们gt_box是具有的信息(gtx,gty,gtw,gth) == (中心点x,中心点y,gt_box的宽,gt_box的高)
得到偏差t(x,y,h,w)包含下四项统称y_Box
tx = (gtx - px)/pw
ty = (gty - py)/ph
tw = log(ghw/pw)
th = log(gth/ph)
创建模型:将分类模型的正样本放进module之后得到的是偏移量的值pre_offset。
模型目标:
我们使用MSE损失函数计算pre_offset的Loss最小值也就是pre_box与gt_box想离最近的。
回归模型的原理:
1.回归首先获取分类结果的正样本的图。
2.代码实现正样本和gt之间的偏移量计算,模型训练获取最小的Loss。
3.我们希望通过预测框能更接近到我们的真实框。
**总结:回归模型的module的输入为分类模型的正样本,输出为4个offset偏移量。**称为编码
2.推理阶段的实现
1.首先我们从训练阶段中获取到分类module 和 回归module。
2.接着进入到推理阶段(测试集):我们使用分类module获取到正样本放入到训练得到的回归module中 -获取-> 4个预测的offset(偏移量) -求出-> 预测框pre_box(px,py,pw,ph)
3.我们现在已知 先验框(自定义)=(tx,ty,tw,th)和 预测框pre_box(px,py,pw,ph) 求gt框
其中的关系为:/pw/ph 是归一化的作用
tx = (gtx - px)/pw
ty = (gty - py)/ph
tw = log(ghw/pw)
th = log(gth/ph)
我们求其逆运算,得到实际目标的gt框(gtx,gty,gtw,gth)
**推理阶段的本质:**将推理数据放入训练阶段训练好的分类和回归的module,获取到其预测框的实际位置,并根据先验框和预测框组合计算出目标框gt的过程。称为解码过程。
目标检测的总体实现:
- 划分网格单元:将输入图切分为 S x S等大网格,每个网格负责预测「目标中心落在该网格内」的物体。
- 挂载先验框:给每个网格配置 K 个不同尺寸、长宽比的先验框。
- 划分样本 :计算每个先验框与所有 GT 框的 IoU,按阈值区分正 / 负 / 忽略样本。
- 训练编码:用正样本的先验框和 GT 框,训练模型预测 4 个偏移量(让先验框逼近 GT 框);同时训练类别分类。
- 推理解码:模型输出每个先验框的偏移量 + 类别概率,用「先验框 + 偏移量」计算出预测框,再通过非极大值抑制(NMS)去掉重复框,得到最终检测结果。
2.RCNN目标检测的实现
1.目标检测的起源
目标检测的任务类型:
1.找到位置(回归问题MSE)
2.划分类别(分类问题CE)
2014年
朴素版本的目标检测实践逻辑链:
1.目标检测 = 回归+分类
2.回归问题损失使用MSE,分类问题使用CE
x (img) -module-> y'_Box + y'Label
module = 1.分类特征 2.空间信息BOX
module :有很强的位置和空间信息
2.目标检测的实操:
1.训练阶段:
训练阶段的分类模型:
1.一张图片随机画N个格子,取其中的2k张作为先验框SS_Box。
2.将SS_Box切割下来与gt_box做IOU。设置阈值划分正负略样本,保持正负比例1:3。
3.迁移学习VGG16进行特征提取4096维。
4.使用SVM向量机来做分类(2分类)。
此处的迁移学习+SVM向量机 == 分类阶段的module
SVM向量机:1.可解释性很强。2.数据不平衡的情况下效果好。
找一个最大间隔距离,使得类别能够进行区分。
对于类别不平衡的时候,效果不错,不太敏感。
训练阶段的回归模型:
1.从分类阶段拿到获取到的正样本(1x4096)的语义特征。
2.构建回归module -> 通过 SS_Box 和 Pre_Box的 预测4个偏移量 pre_offset_box
经过训练阶段的实现,我们得到了
1.分类模型 module_分类 == vgg迁移+svm。
2.回归模型 module_回归
2.推理阶段:
1.一张图片随机画N个格子,取其中的2k张作为先验框SS_Box。
2.运用module_分类(运用Vgg迁移学习得到2k x 4096再进行SVM(假设2分类)) -> 得到N个概率。
3.设置 置信度阈值,比如【分类概率>阈值】得到 10 x 4096正样本。
4.将筛选的正样本(10x4096)放到module2中进行回归模型的预测 得到 10x4个offset(一个box有四个参数)。
5.接着进行解码操作,根据下述公式产出10个预测框。
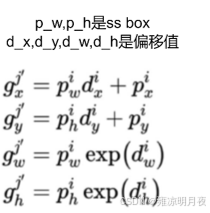
6.我们接着对产出的10个框进行筛选和去重找到最合适的框。
筛选使用的策略是:非极大值抑制策略(去重算法: 设置NMS_IOU超参数)
1.找到概率最大的框A1_box。
2.拿A1_box与剩余的box(A2_box...)做IOU。如果IOU>NMS_IOU 则意味着大面积重叠就去掉A2_box。如果IOU<NMS_IOU。则保留下来。
2.最大概率的框A1_box筛选完成后,按顺序找到筛选后剩下框中第二大概率的框也做这样的去重算法,循环以此类推。
3.重点总结
阈值的说明:
1.训练阶段
阈值:正负样本划分。
2.推理阶段
置信度阈值:分类概率>阈值获取 高概率的正样本
NMS_IOU(非极大值抑制):IOU>NMS_IOU删掉,IOU<NMS_IOU保留
3.总结
本文主要阐述了目标检测的朴素版本的实现思路,以及2014年最开始使用RCNN做目标检测的实现,笔者详细的阐述了其具体的实现过程和解决方法和训练阶段和推理阶段的实现方案,希望给大家学习目标检测带来帮助。