三种题型:填空所有章节37,名词解释4答题(不能写的太少,简答题3
绪论不考
1 信息检索
一二填空
信息检索是什么,用的场景
二 信息检索本质
填空从ppt上寻找,有出处
解决问题:信息过载
处理:非结构化大量数据
搜索技术:从大规模非结构化数据(通常是文本)的集合(通常保存在计算机上)中找出满足用户信息需求的资料(通常是文档)的过程
访问速度有要求时,空间换时间


知道用到的场景
推荐差异不用管
知道**主要挑战:查询-文档 语义鸿沟(**用户输入的"查询(Query)"与数据库中的"文档(Document/Content)"在表达方式和语义空间上的不匹配。)
qd本质在计算相关度,了解相关度

信息检索集合的基本假设:一组文档。假设该集合为静态集合。目标:检索与用户信息需求相关且有助于用户完成任务的文档。
确定文档和查询之间的相关度是IR的核心问题
三四部分不考
2 词项词典
有可能有大题,如果没有大题那么就是填空
AB卷不同
七不考
建立词项词典的步骤,不同步骤有什么不同点,什么是停用词如何找-停用词表
3 中文分词
三不考
二可能有大题 隐马尔可夫模型
2.1不考
隐马尔可夫表述三元组五要素,解决的问题,输入什么,输出什么,有什么问题
2.4具体算法不考,不需要用公式描述,知道中文分词的过程表达清楚
一填空 中文分词,定义,评测标准不记,评测方法123,1不记
4 布尔模型与倒排索引
布尔模型大题
4.1了解即可,4.2不考,其他都需要掌握,重要
信息检索模型,四元组R是本质,是相关度表达,数据是实数,是排序的依据,用不同理论计算相关度,不同模型理论依据不同,集合论模型,代数模型,概率模型,深度学习模型(本质是代数模型
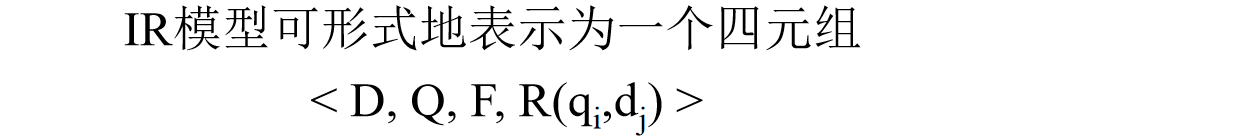
D是一个文档集合
Q是一个查询集合,用户任务的表达,由查询需求的逻辑视图来表示
R(qi,dj) 是一个排序函数,它给查询qi和文档 dj 之间的相关度赋予一个排序值
F是一个框架,用以构建文档,查询以及它们之间关系的模型 检索系统的理论框架,包括预处理、中间处理(分类、聚类、索引)
不用记时间线
理论:集合论(词包模型,布尔代数、

这里的公式不记
知道关联矩阵

倒排表 IVF重要 结构组成
4.3位置信息,二元索引,位置放到索引架构:这两种情况下的优缺点
布尔模型的特点
5 向量空间模型 重要
布尔模型的特点 需要记忆
if idf公式要求掌握-最终公式(不是中间
五价值不考,其中的模块名字Gensim要知道
向量空间模型定义,优缺点掌握
6 概率检索模型
概率模型的推导过程不用掌握
tfidf公式表不用记
记忆BM25公式
一不考
二三要知道这个模型是什么,有什么假设,如何使用,BM25公式,BM25模型中表现最好,这个模型比较重要,推导不要求掌握,要知道效果为什么好
7 搜索引擎工具 不考
8 检索排序
有大题
排序实现精确非精确topk都要知道
连接分析中的pagerank和其他排序算法都要掌握
知道k-gram :进行拼写矫正
在排序算法中pagerank和hits更重要些,山顶和专家评分不是很重要
以词项单位的处理算法和词项算法,这里算法可以去掉,考试不考算法
pagerank掌握一般公式,带着平滑项的公式(矩阵表达和一般表达都行,带平滑项的二选一
9 信息检索的评价 重要
有大题,四不考,大题在二三
以及检索中的评价公式,没有公式要知道评价怎么做!,p@k不考,MRR不考,这一章不出现的公式不考
10 主题模型
这一章没有大题
一不考
二三四不考参数估计(EM算法不考怎么做
LSA知道单词全称,用矩阵分解直接做,效果不好,实际工程中不做,知道优缺点
知道plsa概念,用概率的思想实现lsa的目标,并不是用矩阵分解做的,plsa主题模型
知道主题模型生成模型指责张图片,彩图,后一张概率图表示不用知道
模型训练em算法输入的p,输出的两个矩阵
后面em算法怎么做不用
plsa应用知道,怎么用,
LDA名字,全程,加了先验,用了贝叶斯,估计耿马分,用到变分EM算法gibbs采样
python用到gensim要记住
11 语言模型
有大题
与词包模型的比较,要知道词包模型和优缺点
语言模型的定义
统计语言模型的公式
分词后是否有顺序,无顺序词包,语言模型
(这里的不用记
语言模型定义:一个词的
句子出现的概率等于后面的概率,这里的公式最下面的公式要记忆
3概念 n-gram概念 零概率问题,参数太多问题,加入n-1阶段马尔可夫约束
(语言模型的定义自己整理,n-gram模型重要定义)
4神经网络语言模型优点:改善泛化能力不够,相似度,零概率,
剩下的训练过程与图解不要求
5知道 方案,稠密信息检索过程,方案QD是什么,具体训练过程不考,连续词包模型不考,后面训练不要
直到检索流程与优缺点,后面挑战之类不用
12 索引树
没说没有大题就是有大题,这个没有大题4
一最近邻不考
精确数 kd,球数,知道概念,区别(,不用知道具体算法
原理,应用场景,局限性,球优点,区别(维度?
近似树 annoy树,随机投影树,知道投影变换,思想:通过集成学习投票保持准确度,有随机性,集成学习这两个特点
对比图不用记忆具体数值
13 局部敏感哈希
大题
知道LLSH的概念,整理
simhash重要,知道过程
瓦片shingle 集合相似度表示文本相似度
minhash 构造多次哈希只取得最小值,减少计算量
取得前k个
第三部分的例子图示了解可以
第四部分重要
5不要
14 最近邻检索
有大题
pq,ivf倒排和聚类没有大题,hnsw
4不考
PQ前期知识不考,VLAD不考
从PQ乘积量化,基本的原理和步骤,对向量进行压缩:1.向量分割,子空间聚类。。步骤掌握
进行查询,简答题要加上查询过程!!
IVF与PQ,后面的合作,合作后的特点,谁精细
知道HNSw层次可导航小世界,跳表快速导航,图构造不考,具体的查询过程不考,需要知道优缺点和其他方法的组合
15 两阶段信息检索
1不要 learntorank,pls不考
两阶段注意事项
recallk公式不要,知道名字
提到的模型,不讲的lambdamt等没讲的不会填空colbert,ance
出现的稀疏向量检索,神经稀疏检索DeepCT,知道思想,输入什么输出什么,怎么做,效果好
MRR10不考,Deepct优缺点
前沿不考
稠密检索,概念DRT搜索模型,MIPS即近似annoy可以砍掉
16 神经网络信息检索
没有大题
两阶段召回+精排 神经一般在第二部分
知道神经网络重排架构的名字,四个中文名字,基于表征的,基于交互的,全交互的,迟交互
知道表征学习的操作,与交互的不同点,所有的表征哦都是双塔模型
2.1,2.2,2.3不考
知道2.4bert和2.5
百度的和simnet都不要
第三部分
知道基本概念,3.1不要,模型名字都不要,知道3.2即可