一、为什么需要 GMP?
在现代高并发场景下,传统的内核级线程(Thread)存在以下痛点:
- 内存消耗高:一个线程初始栈通常为 2MB,而 Goroutine 仅需 2KB。
- 切换成本高:线程切换涉及内核态/用户态转换,上下文切换耗时约 1-2 微秒。
- 调度开销大:内核调度器是通用的,无法针对语言特性(如 GC、Channel)优化。
Go 引入了 Goroutine ,在用户态实现轻量级线程,由 Go 运行时(Runtime)自行调度。
二、调度器的前世今生(GM → GMP)
- 旧调度器(Go 1.1 之前):只有 G 和 M。所有的 G 存储在一个全局队列中,M 每次获取 G 都要加全局锁。这导致了严重的锁竞争,且由于缺乏 P,无法保证局部性(Cache Locality)。
- 新调度器(GMP,Go 1.1 引入):引入了 P (Processor) 作为中间层,解决了锁竞争,并实现了更高效的本地队列。
三、核心组件:G、M、P 的深度拆解
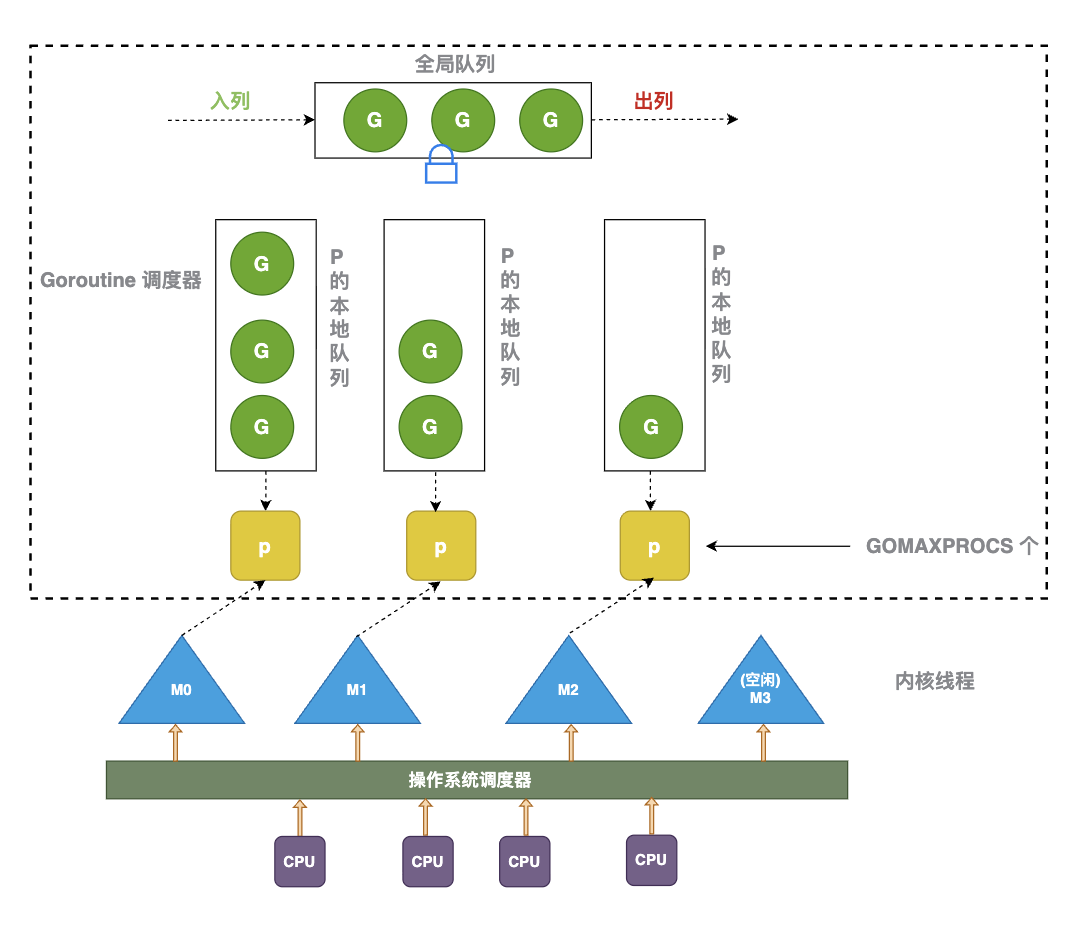
- G (Goroutine): 协程。保存了执行栈、状态、以及要执行的任务函数。
- M (Machine): 内核线程。它是真正的执行单元,由操作系统调度。它不保存 G 的状态,只是负责运行代码。
- P (Processor) : 逻辑处理器。调度上下文,解耦了 M 和 G 。
- 核心作用: 持有局部运行队列(Local Queue),解耦了 G 和 M。
- 数量: 由
$GOMAXPROCS$决定,通常等于 CPU 核心数。
一句话总结:G 负责干活,M 负责执行,P 负责调度。
3.1 G:Goroutine 的本质
在 GMP 模型中,G (Goroutine) 是执行单元的抽象。很多人说"Goroutine 是轻量级线程",但这只是表象。从源码层面看,G 实际上是一个由 Go Runtime 管理的用户态结构体。
为什么 Goroutine 初始栈只有 2KB?
这是 Go 能够支持百万级并发的关键。我们可以从对比和源码常数两个维度来看:
内存的精打细算
- 对比进程/线程:Linux 线程栈通常默认为 2MB - 8MB。如果你开 10 万个线程,仅栈内存就需要 200GB,物理内存直接爆表。
- Go 的策略:Go 团队发现,绝大多数协程在生命周期内并不需要巨大的栈空间。为了实现"高并发",必须极度压缩初始内存。在 Go 1.4 之后,初始栈被定为了 2048 Byte (2KB)。
- 计算公式:100 万个 Goroutine × 2KB ≈ 2GB。这是一个在现代服务器上完全可以接受的数字。
源码中的定义
在 src/runtime/stack.go 中,你可以找到这个神奇数字的定义:
go
// 指向 stack.go
_StackMin = 2048 // 初始栈大小栈的"伸缩艺术":从分段栈到连续栈
既然初始只有 2KB,万一函数调用深了(比如递归)溢出了怎么办?
- 早期的分段栈 (Segmented Stacks):如果空间不够,就再申请一块内存链过去。缺点是"热分裂问题":如果循环中频繁触发申请/释放,性能会急剧下降。
- 现在的连续栈 (Continuous Stacks) :这是 Go 目前使用的机制。
- 触发检查 :在每个函数入口(由编译器插入 prologue 代码),会对比当前的 SP 指针和
g.stackguard0。 - 扩容 :如果栈空间不足,Runtime 会分配一块 2 倍大的新内存。
- 搬家(关键) :Runtime 会把旧栈的数据全量拷贝到新栈,并修正所有指向栈内存的指针(这一步非常复杂,得益于 Go 的自省能力)。
- 收缩:GC 时如果发现栈利用率低于 1/4,会将其收缩回一半。
- 触发检查 :在每个函数入口(由编译器插入 prologue 代码),会对比当前的 SP 指针和
拆解 runtime.g 结构体:G 到底记住了什么?
在 Go 的源码(src/go/runtime/runtime2.go)中定义了 g 的结构体
go
type g struct {
// Stack 参数
// stack 描述了实际的栈内存范围:[stack.lo, stack.hi)
stack stack
// stackguard0 是在 Go 栈增长序幕中对比的栈指针
// 通常为 stack.lo + StackGuard,也可以被设置为 StackPreempt 来触发异步抢占
stackguard0 uintptr
// stackguard1 是在 C 栈增长序幕中对比的栈指针
// 在 g0 和 gsignal 栈上为 stack.lo + StackGuard;在其他 G 上为 ~0,用以触发 morestackc
stackguard1 uintptr
_panic *_panic // 最内层的 panic 结构体链表
_defer *_defer // 最内层的 defer 结构体链表
m *m // 当前关联的 M(工作线程)
sched gobuf // 调度现场:保存 SP、PC、上下文等,用于协程切换
syscallsp uintptr // 如果 status == Gsyscall,则保存栈指针 SP 用于 GC 扫描
syscallpc uintptr // 如果 status == Gsyscall,则保存程序计数器 PC 用于 GC 扫描
stktopsp uintptr // 栈顶期望的 SP,用于回溯检查
// param 是一个通用指针参数字段,用于在特定上下文中传递值
// 1. 当通道操作唤醒阻塞的 G 时,指向已完成阻塞操作的 sudog
// 2. GC 辅助分配标记
// 3. debugCallWrap 传递参数
param unsafe.Pointer
atomicstatus atomic.Uint32 // G 的原子状态(如 _Grunnable / _Grunning 等)
stackLock uint32 // 栈锁,用于 sigprof/scang
goid uint64 // Goroutine 的唯一 ID
schedlink guintptr // 调度链表指针(指向下一个 G)
waitsince int64 // G 开始阻塞的大致时间
waitreason waitReason // 如果状态为 Gwaiting,记录阻塞的原因
preempt bool // 抢占信号:如果为 true,stackguard0 也会被设为 stackpreempt
preemptStop bool // 抢占时是否转换为 _Gpreempted 状态;否则仅重新调度
preemptShrink bool // 是否在同步安全点收缩栈
// asyncSafePoint 表示 G 是否停在异步安全点
// 这意味着栈帧上可能没有精确的指针信息
asyncSafePoint bool
paniconfault bool // 当出现意外的错误地址访问时,是否触发 panic 而不是直接 crash
gcscandone bool // 栈是否已完成 GC 扫描
throwsplit bool // 是否禁止栈分裂(不允许扩容)
// activeStackChans 表示是否存在未解锁的通道指向此 G 的栈
// 如果为 true,拷贝栈时需要获取通道锁来保护这些区域
activeStackChans bool
// parkingOnChan 表示 G 即将阻塞在通道发送或接收上
// 用于标记栈收缩的不安全点
parkingOnChan atomic.Bool
raceignore int8 // 忽略竞态检测事件
tracking bool // 是否正在为调度延迟统计跟踪此 G
trackingSeq uint8 // 跟踪序列号
trackingStamp int64 // 上次开始跟踪的时间戳
runnableTime int64 // 在可运行(Runnable)状态下花费的时间
lockedm muintptr // 调用了 LockOSThread 后绑定的 M
sig uint32 // 信号
writebuf []byte // 写缓冲区
sigcode0 uintptr // 信号代码 0
sigcode1 uintptr // 信号代码 1
sigpc uintptr // 触发信号的 PC
parentGoid uint64 // 创建此 G 的父协程 ID
gopc uintptr // 创建此 G 的 go 语句所在的 PC
ancestors *[]ancestorInfo // 祖先信息(仅在开启 debug.tracebackancestors 时使用)
startpc uintptr // 协程函数的起始 PC
racectx uintptr // 竞态检测上下文
waiting *sudog // 当前 G 正在等待的 sudog 链表(按锁顺序排列)
cgoCtxt []uintptr // cgo 回溯上下文
labels unsafe.Pointer // pprof 分析器标签
timer *timer // 为 time.Sleep 缓存的计时器
selectDone atomic.Uint32 // 是否参与了 select 竞争且已被唤醒
// goroutineProfiled 记录当前正在进行的 Goroutine 分析的状态
goroutineProfiled goroutineProfileStateHolder
// Per-G 跟踪器(Tracer)状态
trace gTraceState
// Per-G GC 辅助状态
// gcAssistBytes 是此 G 辅助 GC 扫描的信用度(字节数)
// 如果为正,表示有余额;如果为负,表示欠债,需要在 malloc 路径中执行扫描工作
gcAssistBytes int64
}接下来重点拆解以下字段
栈管理:stack 与 stackguard
go
stack stack // 描述实际栈内存的范围 [lo, hi)
stackguard0 uintptr // 扩容检查点- stack 记录了当前栈的边界。
go
type stack struct {
lo uintptr
hi uintptr
}- lo (low): 栈空间的低地址。
- hi (high): 栈空间的高地址。
Go 的栈是从高地址向低地址增长的。一个初始 2KB 的 G,其 stack.hi 到 stack.lo 的距离就是 2048 字节。当函数调用不断深入,SP 指针会逼近 lo。
- stackguard0 是性能优化的关键,它不仅用于检查栈溢出,还被用来实现抢占式调度(将其设为一个特殊值 StackPreempt,强制 G 进入调度逻辑)。
2.1 预防栈溢出(基础功能)
在每个 Go 函数的开头,编译器都会插入一段汇编代码(称为 prologue)。它会比较当前的栈指针(SP)和 g.stackguard0:
- 如果
SP > g.stackguard0:内存充足,继续执行。 - 如果
SP <= g.stackguard0:说明栈快满了,触发 morestack。
2.2 为什么它是性能优化的关键?
如果 Go 像传统 C 语言那样通过操作系统信号(SIGSEGV)来捕获栈溢出,开销会非常巨大。
- 内联检查: stackguard0 将复杂的内存判断简化为一条简单的 CPU 比较指令(通常只需 1-3 个时钟周期)。
- 无锁化: 每个 G 拥有自己的 stackguard0,检查时不需要访问全局锁或触发内核态切换。
- 黑科技:利用 stackguard0 实现抢占调度
这是 Go 1.14 引入异步抢占后的点睛之笔。
通常情况下,stackguard0 的值等于 stack.lo + StackGuard(预留的一小段安全区)。但当调度器(sysmon)发现一个 G 运行时间太长(超过 10ms),它想"抢占标识"时,会这样做:
- 修改标记: sysmon 会将该 G 的 stackguard0 设为一个特殊的抢占标记值 stackPreempt。
- 诱导进入: 正在运行的 G 在下一次函数调用时,执行那条比较指令:if SP <= stackguard0。
- 触发拦截: 由于 stackguard0 被设为了极大值,这个条件必然成立。G 会"误以为"栈溢出了,从而跳转到 morestack。
- 身份核实: morestack 内部会检查:到底是真要扩容,还是被要求抢占?如果是抢占,G 就会自愿交出 CPU 执行权,进入就绪队列。
总结: Go 巧妙地复用了"栈检查"这一必经之路,将其变成了"抢占信号"的检查点。这样不需要在代码中到处插桩,也不需要频繁中断 CPU,极大地降低了调度开销。
在 Go 1.14 之前,Go 只能在函数调用、安全点触发抢占,无法中断无函数调用的长时间运行代码,因此本质上仍是"协作式抢占"。。
但 Go 1.14 引入了基于信号的异步抢占。现在的抢占不一定非要等到函数调用触发"栈检查"。sysmon 可以向正在运行的 M 发送 SIGURG 信号,强制中断正在执行死循环(没有函数调用)的 G。
Go 1.14 之后,即便你的代码是一个不含函数调用的 for{} 死循环,调度器也能通过异步信号强行'断电',保证公平性。
- 2KB 初始栈的"扩容"与"缩容"
由于有了 stackguard0 的精准监控,Go 实现了真正的弹性栈:
- 扩容 (Growth) : 分配一个 2 倍大的新内存块,将旧栈数据拷贝过去,并更新所有指向栈内地址的指针(这是 Go 编译器最复杂的部分之一)。
- 缩容 (Shrink): 在垃圾回收(GC)期间,如果发现栈的使用率低于 1/4,会将其收缩为原先的一半,以归还内存。
现场保存:sched (gobuf)
go
sched gobuf
go
type gobuf struct {
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
//
// ctxt is unusual with respect to GC: it may be a
// heap-allocated funcval, so GC needs to track it, but it
// needs to be set and cleared from assembly, where it's
// difficult to have write barriers. However, ctxt is really a
// saved, live register, and we only ever exchange it between
// the real register and the gobuf. Hence, we treat it as a
// root during stack scanning, which means assembly that saves
// and restores it doesn't need write barriers. It's still
// typed as a pointer so that any other writes from Go get
// write barriers.
sp uintptr
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}这是 G 的"档案柜"。当 G 被切走时,它的 SP (栈指针) 和 PC (程序计数器) 会保存在这里。下次恢复执行时,M 只要从 sched 中取出地址,就能丝滑地从断点继续运行。
g.param 的妙用
go
// param 是一个通用指针参数字段,用于在特定上下文中传递值
//1. 当通道操作唤醒阻塞的 G 时,指向已完成阻塞操作的 sudog
// 2. GC 辅助分配标记
// 3. debugCallWrap 传递参数
param unsafe.Pointer当 G 被唤醒时,param 存放的是 sudog 指针。
为什么不直接唤醒?
因为 G 醒来后需要知道是谁唤醒了它,以及数据是否发送成功(例如 channel 是否已关闭)。param 就像是 G 醒来后在床头看到的"留言条"。
状态监控:atomicstatus
go
atomicstatus atomic.Uint32G 的生命周期就在这个原子变量中切换。常见的状态流转如下:
| 状态 (Status) | 名称 | 核心含义与触发时机 |
|---|---|---|
_Gidle |
空闲态 | G 刚刚由 malg 分配,内存已就绪但尚未初始化任务函数。 |
_Gdead |
闲置态 | G 处于空闲池中(如 P 的 gFree)。可能是刚创建,也可能是任务执行完毕,等待被复用。 |
_Grunnable |
就绪态 | G 已分配任务并就绪,正在 P 的本地队列或全局队列中排队,等待 M 调度执行。 |
_Grunning |
运行态 | G 已夺取 CPU 执行权,正在某个 M 上实际执行代码。此时它必然绑定了一个 P。 |
_Gsyscall |
系统调用态 | G 正在执行阻塞式系统调用(如文件 IO)。此时 G 与 M 绑定,但 M 与 P 已解绑。 |
_Gwaiting |
主动挂起态 | G 因同步原语(Channel、Mutex、Sleep)阻塞。G 与 M 解绑,M 去执行其他 G。 |
_Gpreempted |
被抢占态 | G 因运行超时(10ms)被 sysmon 强行暂停,准备切回 _Grunnable 重新排队。 |
Goroutine 状态流转图 (State Machine)
newproc
初始化任务
M调度领走
任务结束
Channel/IO/Mutex
条件满足/唤醒
执行Syscall
调用结束且有空闲P
调用结束无空闲P
10ms超时抢占
交出执行权
_Gidle
_Gdead
_Grunnable
_Grunning
_Gwaiting
_Gsyscall
_Gpreempted
gcAssistBytes 的机制
go
gcAssistBytes int64在硬核拆解 Go GC 演进史------从 STW 到亚毫秒延迟提到过Mark Assist(标记辅助),说是如果后台标记协程(GC Worker)忙不过来,而业务协程分配内存太快,Go 会强迫业务协程停下手中的活,帮着 GC 去做标记。
到这篇文章就来揭秘了,就是因为 g.gcAssistBytes 字段。
这是 Go 垃圾回收不卡顿的秘诀之一。如果一个 G 疯狂申请内存(产生垃圾),GC 会通过这个字段强制它停下来帮忙扫描内存,即"谁污染谁治理"。
sudog ------ 协程的"代理人"
go
waiting *sudog // 当前 G 正在等待的 sudog 链表(按锁顺序排列)
go
type sudog struct {
// 以下字段受该 sudog 阻塞的 channel 的 hchan.lock 保护。
// 对于参与通道操作的 sudog,收缩栈(shrinkstack)的操作依赖于这些字段。
g *g // 指向拥有该 sudog 的 Goroutine
next *sudog // 双向链表后继指针(用于 hchan 的 waitq)
prev *sudog // 双向链表前驱指针
elem unsafe.Pointer // 数据元素指针。如果是发送,指向要发出的值;如果是接收,指向接收值的变量地址。
// 这个指针可能直接指向某个 Goroutine 的栈空间。
// 以下字段永远不会被并发访问。
// 对于 channel,waitlink 仅由 g 自己访问。
// 对于信号量(semaphores),只有在持有 semaRoot 锁时才会访问所有字段。
acquiretime int64 // 入队(开始阻塞)的时间
releasetime int64 // 出队(被唤醒)的时间
ticket uint32 // 信号量票据,用于实现公平调度
// isSelect 表示 g 正在参与 select 语句。
// 如果是,在唤醒时必须通过 CAS 操作竞争 g.selectDone 的所有权。
isSelect bool
// success 表示通道通信是否成功。
// 如果是因为接收到值或发送成功而被唤醒,则为 true;
// 如果是因为通道关闭(close)而被唤醒,则为 false。
success bool
parent *sudog // 用于 semaRoot(信号量树)的平衡二叉树父节点
waitlink *sudog // 指向 g.waiting 列表中的下一个 sudog(一个 G 可能在 select 中等待多个对象)
waittail *sudog // 用于 semaRoot 的链表尾部
c *hchan // 关联的 channel 指针
}在 g 结构体中,waiting *sudog 字段就是连接 调度器 与 同步原语(如 Channel) 的核心桥梁。
在聊聊 golang 中 channel中,提到过 channel 在运行时使用 runtime.hchan 结构体表示。
go
// runtime/chan.go
type hchan struct {
qcount uint // 队列中的数据个数
dataqsiz uint // 环形缓冲区的大小
buf unsafe.Pointer // 环形缓冲区指针
elemsize uint16 // 单个元素的大小
closed uint32 // 标志 channel 是否关闭
elemtype *_type // 元素的类型
sendx uint // 发送操作的索引
recvx uint // 接收操作的索引
recvq waitq // 等待接收的 goroutine 队列
sendq waitq // 等待发送的 goroutine 队列
lock mutex // 保护 channel 的锁
}其中的 recvq 和 sendq。这两个队列存放的就是 sudog 链表。
- 为什么不直接把 g 挂在 Channel 队列里?
因为一个 Goroutine 可能同时在多个等待队列中。
go
select {
case <-ch1:
case ch2 <- x:
} 当前的 g 会同时参与 ch1 的接收等待和 ch2 的发送等待。
| case | 操作 | 语义 |
|---|---|---|
<-ch1 |
receive | 从 ch1 接收 |
ch2 <- x |
send | 向 ch2 发送 |
进入 select 后(简化):
- 对 <-ch1
- 把当前 G 封装成 sudog
- 挂到 ch1.recvq
- 对 ch2 <- x
- 把当前 G 封装成 sudog
- 挂到 ch2.sendq
- 所以 同一个 G:
- 会有两个 sudog
- 分别挂在不同 channel、不同方向的等待队列上
因此,Go 引入了 sudog(可以理解为 Surrogate G,即 G 的代理/替身)。
- g.waiting 指针的作用
- 当 Goroutine 因为 Channel 操作阻塞时,Runtime 会为它创建一个或多个 sudog。
- g.waiting 会指向这些 sudog。
- 解耦:通过 sudog,Channel 只需要知道"谁在等我 "(通过 sudog.g 指向对应的 G),而调度器通过 g.waiting 知道"我在等谁"。
- 实例分析:当 go func() 遇到 ch <- v
- 阻塞发生 :
G1执行ch <- v,但此时hchan的缓冲区(buf)已满。- 调度器不会让
M跟着一起等,而是把G1的状态改为_Gwaiting。
- 创建代理 (
sudog) :- 运行时分配一个
sudog结构体。 sudog.g = G1(指向自己)。sudog.elem = &v(指向要发送的数据地址)。
- 运行时分配一个
- 入队与挂起 :
- 将这个
sudog放入hchan的sendq队列。 - 关键点 :此时
G1.waiting会指向这个sudog。 M调用schedule()触发调度,去执行P本地队列里的下一个G2。
- 将这个
- 唤醒过程 :
- 另一个
G3从ch接收了数据。 - G3(接收者) 发现
sendq中有等待的 G1。 - 直接拷贝 :
- 如果是无缓冲,G3 直接从 G1 的栈内存把数据"拷贝"到自己的栈内存。
- 如果有缓冲,G3 从缓冲区取走旧数据,再把 G1 的新数据"拷贝"到缓冲区。
- 解耦唤醒 :数据搬完后,G3 调用
ready(G1)。 - 重新调度 :G1 被标记为
_Grunnable,等待 M 下一次调度执行。G1 醒来后直接从阻塞点继续往后走,逻辑上它认为自己"完成了一次发送"。
- 另一个
也可以简化为如下流程:
- 打包现场 :G 将自己的数据和身份信息打包进一个
sudog结构体。 - 交接代理 :G 把
sudog交给 Channel 的sendq/recvq队列保管 - 挥手告别 :G 告诉调度器:"我等的人还没来,你先带 M 去跑别人吧。" 随后进入
_Gwaiting状态。 - 异步唤醒 :一旦 Channel 条件满足,另一个协程会通过
sudog找到这个 G,把它重新塞回调度器的待办清单(_Grunnable)。
g 结构体中的 M 引用
在 runtime2.go 的 type g struct 中,这两个字段决定了 G 的归属:
go
m *m // 当前运行该 G 的 M (当前正绑定在哪条内核线程上)g.m 指针:
- 作用:当 G 进入 _Grunning 状态时,必须指向一个具体的 m。
- 意义:通过这个指针,G 才能访问到线程本地存储(TLS)以及 M 关联的内核调用栈。如果 g.m 为空,说明该 G 此时处于就绪态或阻塞态,没有线程在为它服务。
为什么 g 结构体里没有 *p 直接引用?
- 这是一个非常精妙的设计。在 Go 运行时中,P 是资源的持有者,而 M 是执行者。
- G 绑定到 M 上运行,而 M 绑定到一个 P 上获取任务。
- 引用链条:G -> M -> P。
- 如果你去翻 m 的结构体源码,你会看到 m.p 指向当前的 P。所以 G 如果想知道自己在哪个 P 上运行,逻辑是:this.m.p。
G 的"复用"机制
G 并不是用完就丢弃的。
当一个 Goroutine 执行完毕进入 _Gdead 状态后,它会被放入 P 的 gFree 列表或全局的空闲列表。下次 go func() 时,Go 会优先从空闲列表找一个现成的 g 结构体,只重置它的栈和寄存器信息,从而避免了频繁申请内存的开销。
既然 G 这么轻量,我能不能无限开启 Goroutine?
答案:不能。虽然 G 初始只有 2KB,但过多的 G 会导致:
- 内存占用累积:1000 万个也是 20GB 内存。
- 调度开销 (CPU Boundary):虽然切换快,但如果每个 G 只跑 1ms 却要频繁切换,CPU 依然会浪费在 runtime 调度逻辑上。
- GC 压力:GC 需要扫描所有 G 的栈,G 越多,STW (Stop The World) 压力越大。
3.2 M:真正跑在 CPU 上的执行者
M 是操作系统线程(OS Thread)的抽象,它是真正的执行单元,负责执行 G 里的代码指令,并且必须绑定一个 P 才能执行 Go 代码。
为什么 M 不直接调度 G?
如果 M 直接管理 G(Go 1.1 之前就是 GM 调度模型):
- 所有调度逻辑都在 M 上
- 大量竞争锁
- 可扩展性极差
于是 Go 1.1 引入了 P 作为调度中枢。
M 的核心组成(源码 runtime.m 简析)
go
type m struct {
g0 *g // 持有调度栈的 Goroutine(每个 M 都有一个私有的 g0,用于执行运行时调度逻辑)
morebuf gobuf // 传递给 morestack 的 gobuf 参数
divmod uint32 // 仅用于 ARM 架构的整数除法/取模的分母
// --- 调试器不可见字段 ---
procid uint64 // 线程 ID (TID),供调试器使用
gsignal *g // 专门处理信号的 G
goSigStack gsignalStack // Go 分配的信号处理栈
sigmask sigset // 存储保存的信号掩码
tls [tlsSlots]uintptr // 线程本地存储 (Thread Local Storage)
mstartfn func() // M 启动时执行的函数
curg *g // 当前正在此 M 上运行的用户 Goroutine
caughtsig guintptr // 发生致命信号时正在运行的 G
p puintptr // 当前绑定的 P,用于执行 Go 代码 (如果不执行 Go 代码则为空)
nextp puintptr // 暂存即将绑定的 P
oldp puintptr // 执行系统调用之前绑定的 P
id int64 // M 的唯一 ID
mallocing int32 // 状态位:标记是否正在分配内存
throwing throwType // 状态位:标记是否正在抛出异常(runtime throw)
preemptoff string // 如果不为空,保持 curg 在当前 M 上运行,禁止抢占
locks int32 // 该 M 持有的锁数量
dying int32 // 状态位:标记 M 是否正在销毁
profilehz int32 // CPU 分析器的频率
spinning bool // 自旋状态:表示 M 当前没有任务,正在尝试从其他 P 窃取 G
blocked bool // 标记 M 是否阻塞在一个 note(同步机制)上
newSigstack bool // 在 C 线程上调用了 sigaltstack
printlock int8 // 打印锁
incgo bool // 标记 M 是否正在执行 CGO 调用
isextra bool // 是否为额外的 M(用于处理特殊场景或 C 线程回调)
isExtraInC bool // 是否是正在执行 C 代码的额外 M
freeWait atomic.Uint32 // 决定是否可以安全地释放 g0 并删除 M
fastrand uint64 // 快速随机数生成器状态
needextram bool // 是否需要额外的 M
traceback uint8 // 回溯标记
ncgocall uint64 // 总共执行过的 CGO 调用次数
ncgo int32 // 当前正在进行的 CGO 调用次数
cgoCallersUse atomic.Uint32 // cgoCallers 临时使用标记
cgoCallers *cgoCallers // CGO 调用崩溃时的回溯信息
park note // M 休眠时使用的同步原语
alllink *m // 所有的 M 连成的一个单向链表 (allm)
schedlink muintptr // 调度器空闲 M 链表中的下一个 M
lockedg guintptr // 与该 M 锁定的 G(由 LockOSThread 触发)
createstack [32]uintptr // 创建该线程时的栈信息
lockedExt uint32 // 外部 LockOSThread 锁定计数
lockedInt uint32 // 内部 lockOSThread 锁定计数
nextwaitm muintptr // 下一个等待锁的 M
// --- 状态切换中继 ---
// wait* 字段用于将参数从 gopark 传递到 park_m,
// 因为此时 G 的栈已经不能使用了,必须暂存在 M 上。
waitunlockf func(*g, unsafe.Pointer) bool
waitlock unsafe.Pointer
waitTraceBlockReason traceBlockReason
waitTraceSkip int
syscalltick uint32 // 系统调用计数
freelink *m // 空闲 M 链表 (sched.freem)
trace mTraceState // 链路追踪状态
// --- 系统调用与底层调用暂存 ---
libcall libcall
libcallpc uintptr // 供 CPU 分析器使用
libcallsp uintptr
libcallg guintptr
syscall libcall // Windows 下存储系统调用参数
vdsoSP uintptr // 在 VDSO 调用期间的 SP (回溯用)
vdsoPC uintptr // 在 VDSO 调用期间的 PC (回溯用)
preemptGen atomic.Uint32 // 完成的抢占信号计数
signalPending atomic.Uint32 // 标记该 M 上是否有挂起的抢占信号
dlogPerM // 调试日志
mOS // 操作系统特定的 M 结构
// --- 锁跟踪 ---
locksHeldLen int // 该 M 当前持有的锁数量
locksHeld [10]heldLockInfo // 记录持有的前 10 个锁的信息(用于锁排名检查)
}g0 是灵魂
go
g0 *g // 持有调度栈的 Goroutine(每个 M 都有一个私有的 g0,用于执行运行时调度逻辑)M 并不直接运行调度算法,而是切换到 g0 栈去跑调度函数。每个 M 都有一个内置的 g0:
- 非用户代码:g0 不运行用户定义的函数,只负责调度、垃圾回收、栈扩容等管理工作。
- 固定栈:与普通 G 的 2KB 动态栈不同,g0 使用的是操作系统为线程分配的系统栈(通常为 MB 级),但 runtime 仅在其上运行调度与管理代码,不受 Go 动态栈机制影响。
- 切换枢纽:每当 G 发生切换(例如从 G1 切换到 G2),必须经过 g0。
- 逻辑如下:G1 -> g0 -> G2。g0 就像是中转站,负责保存旧 G 现场,寻找新 G 并加载。
tips 特殊的 M0
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
curg 与 p
go
curg *g // 当前正在此 M 上运行的用户 Goroutine
p puintptr // 当前绑定的 P,用于执行 Go 代码 (如果不执行 Go 代码则为空)这是 M 的当前任务。curg 是正在跑的协程,p 是支持它运行的本地资源。
自旋状态 (spinning)
go
spinning bool // 自旋状态:表示 M 当前没有任务,正在尝试从其他 P 窃取 G这是 GMP 高效的关键。当 P 发现没有 G 可以运行时,M 会进入 spinning 状态,到处去"偷"任务(Work Stealing),而不是直接陷入系统调用阻塞,这样可以快速响应新产生的 G。
注意:通常情况下,最多只允许有 GOMAXPROCS 个自旋的 M。实际上,当有空闲 P 且没有活干时,Runtime 往往只保持一个自旋的 M,它像一个"侦察兵",一旦发现新任务就会唤醒其他兄弟。
自旋 M 的"三打白骨精": 一个自旋状态的 M,其 findrunnable 函数会按顺序执行以下动作:
- 检查全局队列。
- 检查网络轮询器(NetPoller)是否有就绪的 IO。
- 尝试 Work Stealing:随机找一个 P,偷走它 runq 里的一半任务。
- 如果连偷 4 次都失败了,M 才会无奈交出 P,进入休眠(parking)。
tips 问答环节:
- 问:为什么 M 在自旋时必须持有一个 P?
- 答: 这是为了随时待命。自旋的 M 本质上是"随时准备运行的工人"。如果它不持有 P,即便它偷到了 G,也无法立刻执行,还得去竞争 P。持有 P 的自旋 M 可以在发现任务的纳秒级时间内直接投入战斗,这体现了 Go 对"低延迟"的极致追求。
3.3 P (Processor):调度器真正的核心
P 是 GMP 模型的核心大脑。它不是真实的物理 CPU,而是执行 Go 代码所需的资源上下文。
为什么需要 P?
- 解耦 M 与 G:如果没有 P,当 M 因为系统调用(Syscall)阻塞时,它手里的 G 队列就全挂了。有了 P,M 阻塞时可以把 P 丢出来(Hand-off),让别的 M 领走这个 P 继续跑队列里的 G。
- 本地化(Locality):每个 P 有自己的 runq。M 优先从绑定的 P 的本地队列拿 G,不需要加全局锁,大大提升了并发效率。
P 的核心组成(源码 runtime.p 简析)
go
type p struct {
id int32
status uint32 // P 的状态:_Pidle, _Prunning, _Psyscall, _Pgcstop, _Pdead
link puintptr
schedtick uint32 // 每进行一次调度就加 1
syscalltick uint32 // 每进行一次系统调用就加 1
sysmontick sysmontick // 被 sysmon 观察到的最近一次时间戳
m muintptr // 反向链接到关联的 M(如果 P 处于空闲状态则为空)
mcache *mcache // P 自带的内存缓存,实现微小对象无锁分配的核心
pcache pageCache // 页缓存,从堆中获取内存
raceprocctx uintptr // 竞态检测上下文
deferpool []*_defer // 预分配的 defer 结构体池,优化 defer 性能
deferpoolbuf [32]*_defer
// Goroutine ID 缓存,减少对全局 runtime.sched.goidgen 的访问冲突
goidcache uint64
goidcacheend uint64
// --- 本地运行队列 (Local Run Queue) ---
// 可运行 Goroutine 的队列,访问时不需要加锁
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext:高优先级任务插队
// 如果不为空,当前的 G 准备就绪的 G 会放在这里。
// 它会继承当前 G 剩余的时间片优先执行,从而消除通信模式下的调度延迟。
runnext guintptr
// 处于 _Gdead 状态的 G 列表,用于复用 G 结构体以降低分配开销
gFree struct {
gList
n int32
}
sudogcache []*sudog // 缓存 sudog 结构体(用于 Channel 阻塞等场景)
sudogbuf [128]*sudog
// 从堆中缓存的 mspan 对象
mspancache struct {
len int
buf [128]*mspan
}
// 缓存单次 pinner 对象,减少重复创建的开销
pinnerCache *pinner
trace pTraceState // 执行跟踪状态
palloc persistentAlloc // P 级别的持久分配,避免全局锁
// 定时器堆中第一个条目的触发时间
timer0When atomic.Int64
// 状态为 timerModifiedEarlier 的定时器中最早的触发时间
timerModifiedEarliest atomic.Int64
// --- GC 相关状态 ---
gcAssistTime int64 // 在辅助分配(assistAlloc)中花费的纳秒数
gcFractionalMarkTime int64 // 在分数标记任务中花费的纳秒数
limiterEvent limiterEvent // GC CPU 限制器事件跟踪
gcMarkWorkerMode gcMarkWorkerMode // 下一个要运行的标记工作者模式
gcMarkWorkerStartTime int64 // 最近一个标记工作者启动的时间戳
gcw gcWork // GC 工作缓冲区缓存(写屏障产生的数据)
wbBuf wbBuf // GC 写屏障缓冲区
runSafePointFn uint32 // 若为 1,则在下一个安全点运行 sched.safePointFn
// statsSeq 是一个计数器,表示 P 是否正在写入统计信息(偶数:不在写入;奇数:正在写入)
statsSeq atomic.Uint32
// --- 定时器管理 ---
timersLock mutex // 定时器锁(通常由本 P 访问,但调度器也可以跨 P 访问)
timers []*timer // 当前 P 维护的所有定时器堆
numTimers atomic.Uint32 // P 堆中的定时器数量
deletedTimers atomic.Uint32 // P 堆中被标记为删除的定时器数量
timerRaceCtx uintptr // 执行定时器函数时的竞态上下文
maxStackScanDelta int64 // 待扫描栈空间的增量累计值
// GC 期间关于当前 Goroutine 的统计数据
scannedStackSize uint64 // 由此 P 扫描的协程栈总大小
scannedStacks uint64 // 由此 P 扫描的协程数量
// 抢占标记:设置为 true 时表示该 P 应该尽快进入调度器
preempt bool
pageTraceBuf pageTraceBuf // 用于页分配/释放/回收的跟踪缓冲区
}runnext 是响应速度的秘密
go
// runnext:高优先级任务插队
// 如果不为空,当前的 G 准备就绪的 G 会放在这里。
// 它会继承当前 G 剩余的时间片优先执行,从而消除通信模式下的调度延迟。
runnext guintptrrunnext 是 Go 给生产-消费模型开的'绿灯'。
在传统的调度算法中,公平性是第一准则,大家必须排队。但 Go 的设计者意识到,通信即协作。如果 G1 辛苦准备好了数据传给 G2,却让 G2 去排队,那 G1 的努力就白费了(上下文切换的开销会抵消并发的优势)。runnext 的本质是:让逻辑上连续的操作,在物理上也尽可能连续地在同一个 CPU 核心上完成(局部性原理,CPU 缓存亲和性(Cache Affinity))。
runq256 限制
go
// --- 本地运行队列 (Local Run Queue) ---
// 可运行 Goroutine 的队列,访问时不需要加锁
runqhead uint32
runqtail uint32
runq [256]guintptr在 runtime.p 结构体中,runq 是一个 256 长度的环形数组。如果 go func() 产生太多协程导致本地队列满了,就会触发"溢出"逻辑:将本地队列的一半任务移动到全局队列。
为什么 P 的 runq 为什么是 256?
冷知识:这个大小是硬编码的。为什么是 256?因为它足够小,可以放入 CPU 的缓存行,同时又足够大,能覆盖大多数场景的局部并发。当产生第 257 个 G 时,它会带着前 128 个 G 一起"投奔"全局队列。
runnext与 runq 的配合
调度顺序总结:
当 M 寻找下一个可运行的 G 时,顺序是:
- 第一优先级 :
runnext(最热的数据,最快的响应)。 - 第二优先级 :
runq本地队列(正常的待办任务)。 - 第三优先级:全局队列(保底公平)。
- 第四优先级:网络轮询器/任务窃取(保底不空转)。
mcache 本地化分配
go
mcache *mcache // P 自带的内存缓存,实现微小对象无锁分配的核心这是 Go 内存分配极快的原因之一。每个 P 都有自己的 mcache,G 申请小对象内存时直接在本地 P 分配,不需要加全局锁。
timers 定时器外包
go
timers []timer // 本地最小堆(四叉堆)在 Go 1.14 之前,定时器是全局管理的,锁竞争很严重。在 Go 1.14 之后,现在每个 P 维护自己的 timers 堆,极大提升了 time.Sleep 和 Timer 的并发处理能力。
这种本地化不仅是消除了那把沉重的全局锁,更重要的是实现了调度闭环。当你的代码执行 time.After 时,这个定时任务就静静地躺在当前 P 的 timers 数组里。由于它和你的 Goroutine 都在同一个 P 上,当时间一到,它能以最短的路径(甚至是直接通过 runnext)被当前 M 执行。这种空间局部性的优化,才是 Go 支撑每秒百万级 Timer 操作的真正底气。
tips: 问答环节
问:既然定时器在 P 里面,那是谁在不断检查它是否到期?
答:Go 并没有创建一个专门的"定时器线程",而是将定时器检查揉进了调度循环:
- 调度循环检查 (
findrunnable) :当 M 在寻找可运行的 G 时,它会顺便调用checkTimers,看看自己 P 里的定时器到期没。 - 网络轮询器联动 (
NetPoller) :如果所有的 P 都没事干(Idle 状态),M 准备去休眠时,它会查一下所有 P 中最近的那个到期时间 ,并把这个时间传给epoll_wait。- 意义 :这实现了"按需唤醒"。M 休眠后,要么是有网络包来了被唤醒,要么是定时器到期了,由内核通过 epoll 机制准时叫醒。
- 系统监控补底 (
Sysmon) :如果一个 P 正在跑一个超长的 G(比如死循环),没人进调度循环怎么办?sysmon监控线程会发现这个 P 的定时器逾期了,它会强制发起一次抢占,或者在空闲 M 上触发定时器。
性能提升的真相
- 锁竞争几乎消失 :因为 M 操作的是自己绑定 P 的
timers,绝大多数情况下是无锁操作。 - STW 时间缩短:在旧版本中,GC 扫描全局定时器堆需要很长时间且需要 STW(Stop The World)。现在定时器分散在 P 中,GC 可以更灵活地并发扫描。
schedtick:全局队列的"低保机制"(1/61 规则)
go
schedtick uint32 // 每进行一次调度就加 1
go
// 源码逻辑简化
if _p_.schedtick % 61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp := dequeueGlobal() // 强制从全局拿一个任务
unlock(&sched.lock)
return gp
}为了防止全局队列里的 G 被"饿死",P 有一个硬性规定。
在 runtime.p 结构体中有一个 schedtick 字段。每执行 61 次调度,M 必须直接从全局队列中获取一个 G 来运行,无论本地队列是否为空。这个数字 61 是一个质数,为了避开各种周期性同步。
M 与 P 的"婚姻关系"
M 和 P 必须"成亲"才能让 G 跑起来。但这段婚姻关系并不总是稳定的:
场景一:Work Stealing (任务窃取)
当 M 绑定的 P 里的本地队列 runq 跑空了,M 不会闲着,它会:
- 去全局队列里尝试拿一部分 G。
- 如果全局队列也没了,它会去其他 P 的队列里"偷"一半的 G 过来。
深度点:这种机制保证了系统负载的绝对平衡,不会出现"一核有难,多核围观"的情况。
场景二:Hand Off (移交机制)
当 G1 在 M1 上执行系统调用(如读磁盘)导致 M1 阻塞时:
- 解绑:M1 会释放 P。
- 移交:P 会去找一个新的 M2(或从休眠池唤醒一个)继续工作。
- 回归:当 M1 完成系统调用回来时,它会尝试找一个空闲的 P。如果找不到,就把 G1 塞进全局队列,自己回线程池睡觉。
场景三:NetPoller (网络轮询器)
这是 Go 处理海量长连接(如高并发 Web Server)的杀手锏。
在传统的模型中,一个网络请求阻塞,整个线程就得等。但在 Go 中,网络 I/O 是"非对称作战":
不同于系统调用(Syscall)会带走 M,网络 I/O(如 http.Get)发生阻塞时:
- G 离场 :当 G 发起网络操作(如
conn.Read)发现数据未就绪时,它不会阻塞 M,而是将自己改为_Gwaiting状态,并被挂到 NetPoller(由底层系统的 epoll/kqueue 实现)中。 - M 换人 :M 发现 G 走了,立刻去 P 的队列里领下一个 G 继续干活。M 完全不阻塞。
- 异步唤醒 :一旦网络数据包到达,NetPoller 会收到内核通知,把对应的 G 重新标记为
_Grunnable,并塞回某个 P 的本地队列(或者全局队列)。
深度对比:
- Syscall(场景二) :是内核级的"重操作",M 必须跟着等,所以需要 Hand Off 丢下 P 让别人接管。
- NetPoller(场景三):是 Go 封装的"轻操作",M 不用等,直接找新活。这也就是为什么 Go 只需要几千个线程,就能轻松处理上百万个网络连接。
终章:一次 Goroutine 的完整生命周期
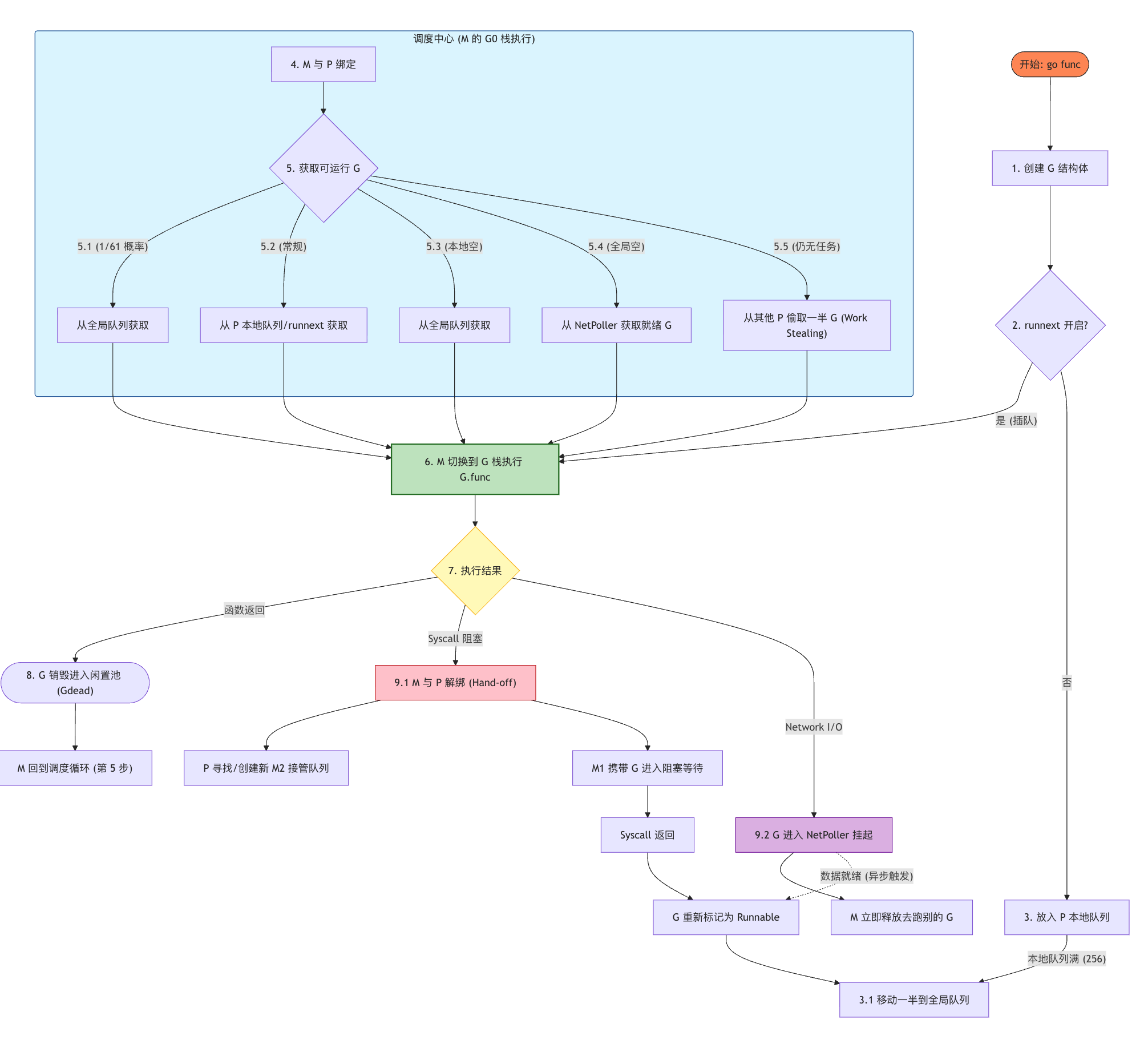
第一幕:世界被点亮
当我们写下这段简单的代码并运行时,背后发生了什么?
go
package main
import "fmt"
func main() {
fmt.Println("Hello World")
}这段代码的生命历程,实际上是一场关于 M0、G0 和 P 的宏大叙事。让我们跟随源码的足迹,看看 Go 是如何从虚无中建立起整个并发世界的。
1.1 黎明时刻:汇编入口与 M0/G0 的诞生
当你运行程序时,内核加载的可执行文件并不是直接跳到 main.main。真正的起点是汇编代码 runtime.rt0_go(以 amd64 linux 为例)。
在这一阶段,系统会完成两件最重要的事情:
-
全局初始化 :在内存的静态数据区,
m0和g0已经静静地躺在那里。 -
绑定互助 :汇编代码会将
m0和g0相互关联。go// 逻辑等同于以下源码: m0.g0 = &g0 g0.m = &m0
此时的状态:我们拥有了一个主线程 M0,它运行在 G0 栈上。它是这个世界的第一个"造物主"。
冷知识: M0 为什么不需要动态分配?
因为它是在 Go 程序启动时,由汇编代码在全局数据段预留的内存。这意味着即使 Go 的内存分配器(mheap)还没初始化好,M0 也能正常工作。它是整个 GMP 世界的"第一推动力"。
1.2 混沌初开:runtime.schedinit (调度器初始化)
随后,M0 会在 G0 栈上调用 runtime.schedinit。这是调度器的"装修时刻":
- 内存分配器初始化(mheap/mcentral)。
- 栈分配器初始化。
- 垃圾回收器初始化。
- 参数与环境获取。
最关键的一步出现了:获取 GOMAXPROCS 并初始化 P 列表。
1.3 秩序建立:绑定 P (Processor)
在 schedinit 内部,会调用 runtime.procresize(nprocs)。
-
创建工位 :根据 CPU 核心数创建对应的
P结构体切片。 -
完成初婚 :M0 会紧紧绑定第一个 P(allp0) 。
go// 源码逻辑: _g_.m.p.set(allp[0]) allp[0].m.set(_g_.m)
此时的状态:M0 不再是一个孤立的线程,它拥有了执行权(P)。现在,万事俱备,只差"任务"了。
1.4 灵魂注入:创建 Main Goroutine
调度器准备好了,但 main.main 还没有变成一个可调度的协程。
此时,M0 会在 G0 栈上调用 runtime.newproc。
- 创建任务 :它创建了一个真正的用户协程
G。 - 包装函数 :这个 G 的任务内容并不是直接运行
main.main,而是一个包装函数runtime.main。 - 入队:这个新生的 G 被放入了 M0 所绑定的 P 的本地队列。
1.5 引擎点火:mstart 与 第一次切换
万事俱备,M0 发出了最后的指令:mstart。
- 进入循环 :M0 丢弃当前的初始化逻辑,正式进入
schedule()调度循环。 - 寻找任务:M0 的 G0 搜索 P 的本地队列,瞬间就找到了刚才放进去的 Main Goroutine。
- 身份切换(关键) :
- G0 保存自己的现场。
- M0 切换上下文,跳入 Main Goroutine 的栈。
- M0 开始执行
runtime.main。
第二幕:调度器开始呼吸
在完成初始化之后,Go 程序并不会"进入某个稳定态",而是进入一个永不停歇的调度循环。
从这一刻起,每一个正在运行的 M,都会反复执行同一件事情:
- 寻找一个可运行的 G,切换过去执行;
- 如果找不到,就想办法"等"或者"抢"。
这就是 Go 调度器真正的心跳。
2.1 调度器的主循环
在 runtime 中,这个循环以一个极其朴素的形式存在:
go
for {
schedule()
}schedule() 并不是"调度一次",而是调度器存在的方式本身。
只要 M 还活着,这个函数就会被反复调用。
从概念上看,schedule() 只做两件事:
- 找一个可运行的 goroutine
- 切换到它的执行栈上
如果这两件事无法完成,M 就不能继续占用 CPU。
2.2 findrunnable:寻找下一个 G
schedule() 的核心工作,集中在一个函数中完成:
go
findrunnable()这个函数体现了 Go 调度器的全部设计哲学。
它并不是"随机找一个 G",而是按照一套严格的优先级顺序逐层尝试。
2.2.1 第一优先级:本地运行队列(runq)
调度器首先检查 当前 P 的本地运行队列:
go
runqget(p)这是最理想的情况:
- 无需加锁
- 缓存局部性最好
- 几乎没有调度开销
这也是为什么 Go 要坚持 P 拥有本地队列 的根本原因。
在负载稳定的情况下,大多数 goroutine 都会在这一层被直接调度。
2.2.2 第二优先级:全局运行队列(globrunq)
如果本地队列为空,调度器会尝试从 全局运行队列 中获取任务:
go
globrunqget()全局队列的存在并不是为了性能,而是为了公平性:
- 防止某些 goroutine 长期得不到执行
- 作为新建 G 的初始落点
- 在系统负载不均时提供兜底
这一步需要加锁,因此只在必要时使用。
2.2.3 第三优先级:网络轮询器(netpoll)
如果仍然没有可运行的 G,调度器会把目光投向"外部世界":
go
netpoll()这里处理的是:
- epoll / kqueue 返回的 I/O 事件
- 被 I/O 唤醒的 goroutine
这些 G 往往之前处于阻塞状态,现在因为网络事件重新变为 runnable。
从调度器视角看,这一步意味着:
"也许不是 CPU 不够用,而是我在等 I/O。"
2.2.4 第四优先级:工作窃取(work stealing)
如果当前 P 仍然"无事可做",而系统中可能还有其他 P 正在忙碌,
调度器会进入 工作窃取 阶段:
go
stealWork()它会尝试从其他 P 的本地队列中"偷"一半的 G。
这一机制解决的是负载不均衡问题:
- 有的 P 任务堆积
- 有的 P 空闲
通过有限度的窃取,调度器在吞吐量和公平性之间取得平衡。
2.2.5 最后的选择:让 M 休眠(stopm)
如果以上所有路径都失败了,调度器必须做出一个决定:
go
stopm()这意味着:
- 当前 M 暂时没有任何可执行任务
- 继续空转只会浪费 CPU
- 主动让出执行权,进入休眠
当新的 G 变为 runnable 时,调度器会重新唤醒合适的 M。
2.3 execute:真正的上下文切换
一旦 findrunnable() 返回了一个 G,调度器就进入最后一步:
go
execute(g)这一步完成:
- 保存当前 g(通常是 g0)的上下文
- 切换到目标 G 的栈
- 开始执行用户代码
从这一刻起,用户代码重新掌控 CPU,而调度器则退回幕后,等待下一次被唤醒。
2.4 调度不是"一次事件",而是一种节律
需要特别强调的是:调度不是某个关键时刻发生的动作,而是 runtime 的常态。
每一次:
- goroutine 阻塞
- 系统调用返回
- channel 操作
- 抢占触发
都会把执行权重新交还给 schedule()。
Go 程序的运行,本质上就是无数次 schedule → execute 的往复。
第三幕:Hello World 的回响
在 runtime.main 内部,它会做最后两件事:
- 启动监控 :开启
sysmon线程(那个负责抢占式调度的"交警")。 - 调用业务 :真正执行我们在代码里写的
main.main。
于是,控制台打印出了:Hello World
结语:为什么我们要懂 GMP?
穿透 fmt.Println 的表象,你会发现这其实是一场由 M0 发起、G0 坐镇、P 资源统筹的宏大叙事。在 Go 的世界观里:
- G 是我们的业务逻辑,代表"谁要干活"。
- M 是物理世界的算力,代表"由谁来干"。
- P 是连接两者的纽带,代表"资源如何分配"。
理解 GMP,不仅是为了应付面试,更是为了理解 Go 如何在底层通过局部性原理避开锁竞争,如何通过异步抢占终结死循环。正是这种"让逻辑层与物理层解耦"的设计方案,才让 Go 在高并发的巨浪中,依然能保持极致的优雅与稳定。