🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/
✅ 这个 Python 脚本(约 300 行代码量 )实现了一个大语言模型权重文件哈希校验工具 ,主要功能包括:
-
跨平台支持,同时支持从 HuggingFace 或 ModelScope 平台获取模型仓库中权重文件元数据的基准 SHA256 哈希值 ,把 "远端元数据 hash" 当作可信基线,避免 "再下载一遍算 hash",跨平台抽象:统一入口
get_llm_weight_file_hashes(),正则筛选权重分片,减少不必要的元数据/校验开销; -
计算本地文件的 SHA256 哈希值 (支持大文件内存优化,用大
chunk顺序读取,例如 8MB ~ 64MB,减少系统调用次数); -
打印 "远程应该有但本地缺失" 的文件 ,校验本地文件哈希是否与远程文件的哈希一致 ,进度条显示计算进度;
-
提供命令行 CLI 传参及调用、"权重文件名:哈希值" 对应数据保存 / 加载功能。
✨ 代码优点:
-
健壮的错误处理:对 API 调用、文件读取都有异常捕获
-
灵活过滤:支持正则表达式和 LFS 过滤
-
用户友好:提供命令行参数说明、文件的哈希预览,进度条显示计算进度
环境配置,需 pip install 安装第三方依赖库如下:
bash
modelscope==1.33.0
huggingface_hub==1.1.7
requests==2.32.5Python 源码如下:
python
import os
import re
import sys
import json
import hashlib
import argparse
from typing import Dict, Optional
import requests
from tqdm import tqdm
try:
from huggingface_hub import HfApi
except ImportError:
HfApi = None
try:
from modelscope.hub.api import HubApi
except ImportError:
HubApi = None
def get_llm_weight_file_hashes(
platform: str,
repo_name: str,
file_pattern: Optional[str] = None,
lfs_only: bool = True,
) -> Dict[str, str]:
if platform == "huggingface":
return _get_huggingface_hashes(repo_name, file_pattern, lfs_only)
elif platform == "modelscope":
return _get_modelscope_hashes(repo_name, file_pattern, lfs_only)
else:
raise ValueError(
f"目前不支持的平台: {platform}, 请使用 'huggingface' 或 'modelscope'"
)
def _get_huggingface_hashes(
repo_name: str,
file_pattern: Optional[str] = None,
lfs_only: bool = True,
) -> Dict[str, str]:
if HfApi is None:
raise ImportError("需安装好 huggingface_hub: pip install huggingface_hub")
api = HfApi()
print(f"正在从 HuggingFace 获取仓库 {repo_name} 的元数据...")
try:
model_info = api.model_info(repo_name, files_metadata=True)
except requests.exceptions.RequestException as e:
print(f"网络错误: {e}")
return {}
except Exception as e:
print(f"获取元数据失败: {type(e).__name__}: {e}")
return {}
sha256_dict = {}
pattern = re.compile(file_pattern) if file_pattern else None
for file_info in model_info.siblings:
filename = file_info.rfilename
if pattern and not pattern.match(filename):
continue
if lfs_only and not file_info.lfs:
continue
if file_info.lfs:
sha256_hash = file_info.lfs.get("sha256", None)
sha256_dict[filename] = sha256_hash
else:
# 非 LFS 文件不提供 SHA256, blob_id 是 Git SHA1
print(f"提醒: 文件 {filename} 不是 LFS 文件, 无法获取 SHA256 哈希")
continue
return sha256_dict
def _get_modelscope_hashes(
repo_name: str,
file_pattern: Optional[str] = None,
lfs_only: bool = True,
) -> Dict[str, str]:
if HubApi is None:
raise ImportError("请安装 modelscope: pip install modelscope")
api = HubApi()
print(f"正在从 ModelScope 获取仓库 {repo_name} 的元数据...")
sha256_dict = {}
pattern = re.compile(file_pattern) if file_pattern else None
# 获取模型文件列表 (递归获取所有文件)
try:
files = api.get_model_files(repo_name, recursive=True)
except Exception as e:
print(f"获取文件列表失败: {e}")
return {}
for file_info in files:
if file_info.get("Type", "") == "tree":
continue
if lfs_only and not file_info.get("IsLFS"):
continue
filename = file_info.get("Path", "")
if pattern and not pattern.match(filename):
continue
sha256_hash = next(
(v for k, v in file_info.items() if k.lower() == "sha256"), None
)
sha256_dict[filename] = sha256_hash
return sha256_dict
def calculate_file_sha256(file_path: str, chunk_size: int = 33554432) -> str:
sha256_hash = hashlib.sha256()
with open(file_path, "rb") as f:
for byte_block in iter(lambda: f.read(chunk_size), b""):
sha256_hash.update(byte_block)
return sha256_hash.hexdigest()
def verify_file(
file_path: str,
expected_hashes: Dict[str, str],
filename: str,
) -> bool:
if not expected_hashes:
print("错误: 没有提供预期哈希字典")
return False
expected_hash = expected_hashes[filename]
print(f"正在计算 {filename} 的 SHA256, 文件较大请稍候...")
try:
actual_hash = calculate_file_sha256(file_path)
except Exception as e:
print(f"❌ 计算或读取错误: {e}")
return False
print(f"预期 SHA256: {expected_hash}")
print(f"实际 SHA256: {actual_hash}")
if actual_hash == expected_hash:
print("✅ 校验通过: 文件完整且一致!")
return True
else:
print("❌ 校验失败: 文件可能已损坏或被篡改!")
return False
def print_hashes_preview(hashes: Dict[str, str], preview_count: int = 3):
sorted_keys = sorted(hashes.keys())
if not sorted_keys:
print("没有找到任何文件")
return
print(f"\n共找到 {len(hashes)} 个文件的 SHA256:")
print(f"预览前 {preview_count} 个:")
for key in sorted_keys[:preview_count]:
print(f" '{key}': '{hashes[key]}'")
if len(sorted_keys) > preview_count * 2:
print(" ...")
print(f"预览后 {preview_count} 个:")
for key in sorted_keys[-preview_count:]:
print(f" '{key}': '{hashes[key]}'")
elif len(sorted_keys) > preview_count:
for key in sorted_keys[preview_count:]:
print(f" '{key}': '{hashes[key]}'")
def main():
parser = argparse.ArgumentParser(
description="获取大模型权重文件的 SHA256 哈希值并进行文件校验"
)
parser.add_argument(
"-p",
"--platform",
choices=["huggingface", "modelscope"],
type=str,
default="huggingface",
help="模型平台 (默认: huggingface) ",
)
parser.add_argument(
"-r",
"--repo_name",
required=True,
type=str,
help="模型仓库名称, 格式通常为 组织/模型名, 如 'zai-org/GLM-4.7'",
)
parser.add_argument(
"-f",
"--file_pattern",
type=str,
default=r"model-\d{5}-of-\d{5}\.safetensors",
help="文件名匹配正则表达式, 如 r'model-\d{5}-of-\d{5}\.safetensors'",
)
parser.add_argument(
"-a",
"--all_files",
action="store_true",
help="默认只获取 LFS 文件的哈希 (不触发 all_files)",
)
parser.add_argument(
"-w",
"--weight_filepath",
type=str,
default="",
help="传入本地文件夹 (存放模型权重文件的目录)",
)
parser.add_argument(
"-o",
"--output_hashes_dict",
type=str,
default="weight_sha256.json",
help="保存哈希字典数据到 JSON 文件",
)
parser.add_argument(
"-e",
"--existed_hashes_dict",
type=str,
help="本地已保存的哈希字典数据 JSON 文件",
)
parser.add_argument(
"-n",
"--nums_preview",
type=int,
default=3,
help="预览显示的文件数量 (默认: 3) ",
)
args = parser.parse_args()
hashes = dict()
if args.existed_hashes_dict:
with open(args.existed_hashes_dict, "r") as f:
hashes = json.load(f)
else:
# 本地若无哈希字典数据, 还需获取权重文件: 哈希值字典数据
hashes = get_llm_weight_file_hashes(
args.platform,
args.repo_name,
args.file_pattern,
lfs_only=not args.all_files,
)
print_hashes_preview(hashes, args.nums_preview)
if args.output_hashes_dict:
with open(args.output_hashes_dict, "w") as f:
json.dump(hashes, f, indent=2, ensure_ascii=False)
print(f"\n哈希字典已保存到 {args.output_hashes_dict}")
if not hashes:
print("错误: 无法获取哈希字典, 无法进行校验! ")
sys.exit(1)
if os.path.isfile(args.weight_filepath):
raise ValueError("错误: -w 参数应为权重文件夹路径, 而不是单个文件路径! ")
# 检查本地缺失文件
local_files_set = set(os.listdir(args.weight_filepath))
missing_files = []
for file_ in hashes.keys():
if file_ not in local_files_set:
missing_files.append(file_)
print(f"⚠️ 提醒: 本地缺少文件: {missing_files}")
check_files = [
file_ for file_ in os.listdir(args.weight_filepath) if file_ in hashes.keys()
]
if args.weight_filepath and os.path.isdir(args.weight_filepath):
failed_files = []
for file_ in tqdm(check_files):
print(f"\n正在校验 {file_} ...")
success = verify_file(
os.path.join(args.weight_filepath, file_), hashes, file_
)
if not success:
failed_files.append(file_)
failed_files.sort()
print(
f"\n权重文件校验完成, {len(failed_files)} 个文件校验失败: \n{failed_files}"
)
else:
raise ValueError(f"错误: {args.weight_filepath} 不是有效的目录路径! ")
if __name__ == "__main__":
main()测试命令如下:
bash
python check_sha256_of_llm_weight.py --platform "huggingface" --repo_name "zai-org/GLM-4.7" --file_pattern "model-\d{5}-of-\d{5}\.safetensors" --weight_filepath "D:\Coding\Vibe-Working" --output_hashes_dict "weight_sha256.json" --nums_preview 3
python check_sha256_of_llm_weight.py --platform "modelscope" --repo_name "ZhipuAI/GLM-4.7" --file_pattern "model-\d{5}-of-\d{5}\.safetensors" --weight_filepath "D:\Coding\Vibe-Working" --output_hashes_dict "weight_sha256.json" --nums_preview 3
python check_sha256_of_llm_weight.py --repo_name "zai-org/GLM-4.7" --existed_hashes_dict "weight_sha256.json" --weight_filepath "D:\Coding\Vibe-Working"以 HuggingFace 和 ModelScope 的 GLM-4.7 仓库为例,测试结果如下:
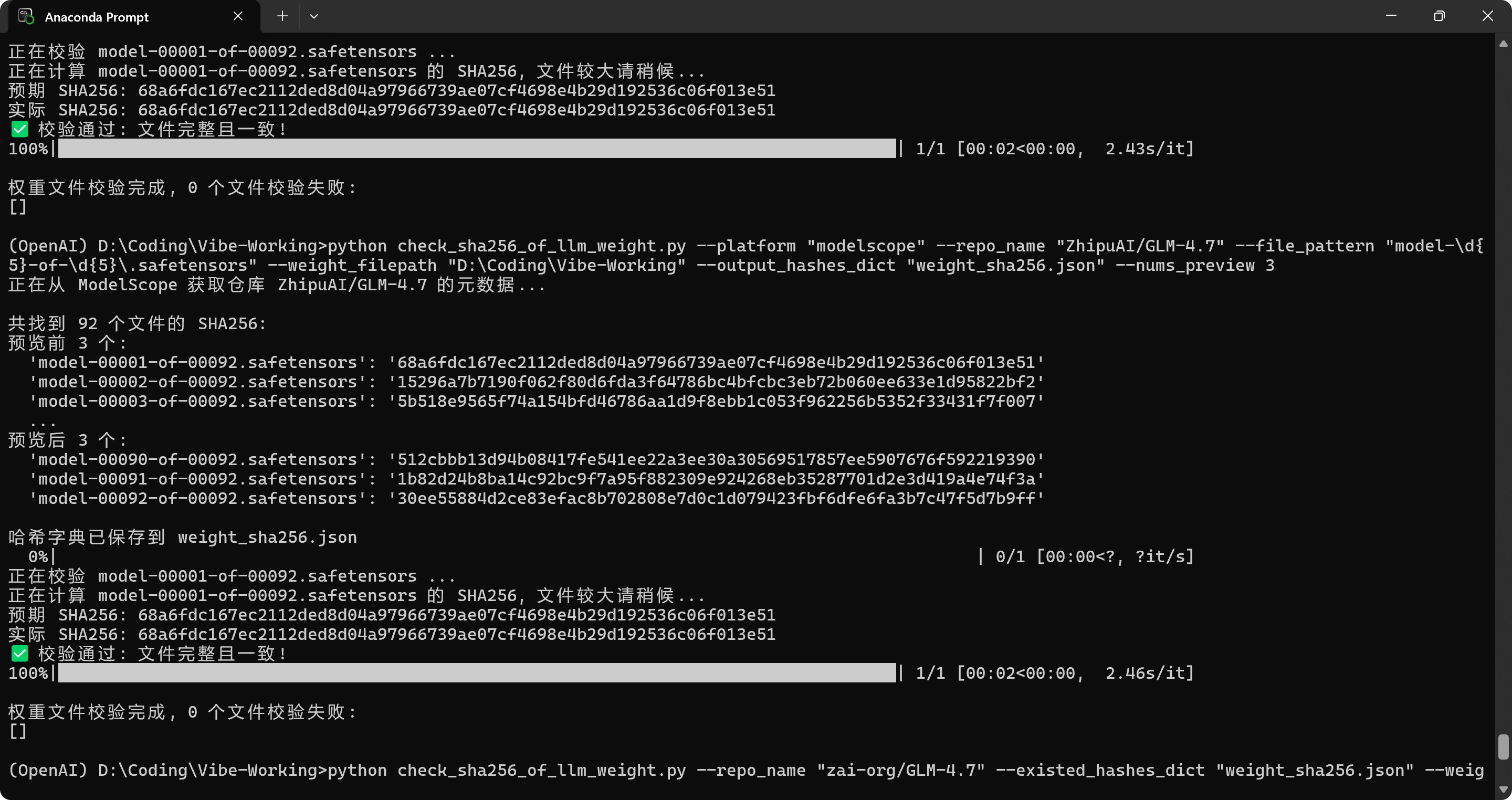
实现过程中遇到的问题及解决:
-
不同平台的 "元数据" 不一致 ,且 LFS / 非 LFS 的哈希来源不同,需仔细观察数据和实现正确的条件判断,确保程序逻辑正确。
-
ModelScope 的文件结构与字段名更 "松散",返回的 dict 键名、层级、是否包含 sha256 可能随 API 版本 / 模型类型变化。用了大小写不敏感匹配。
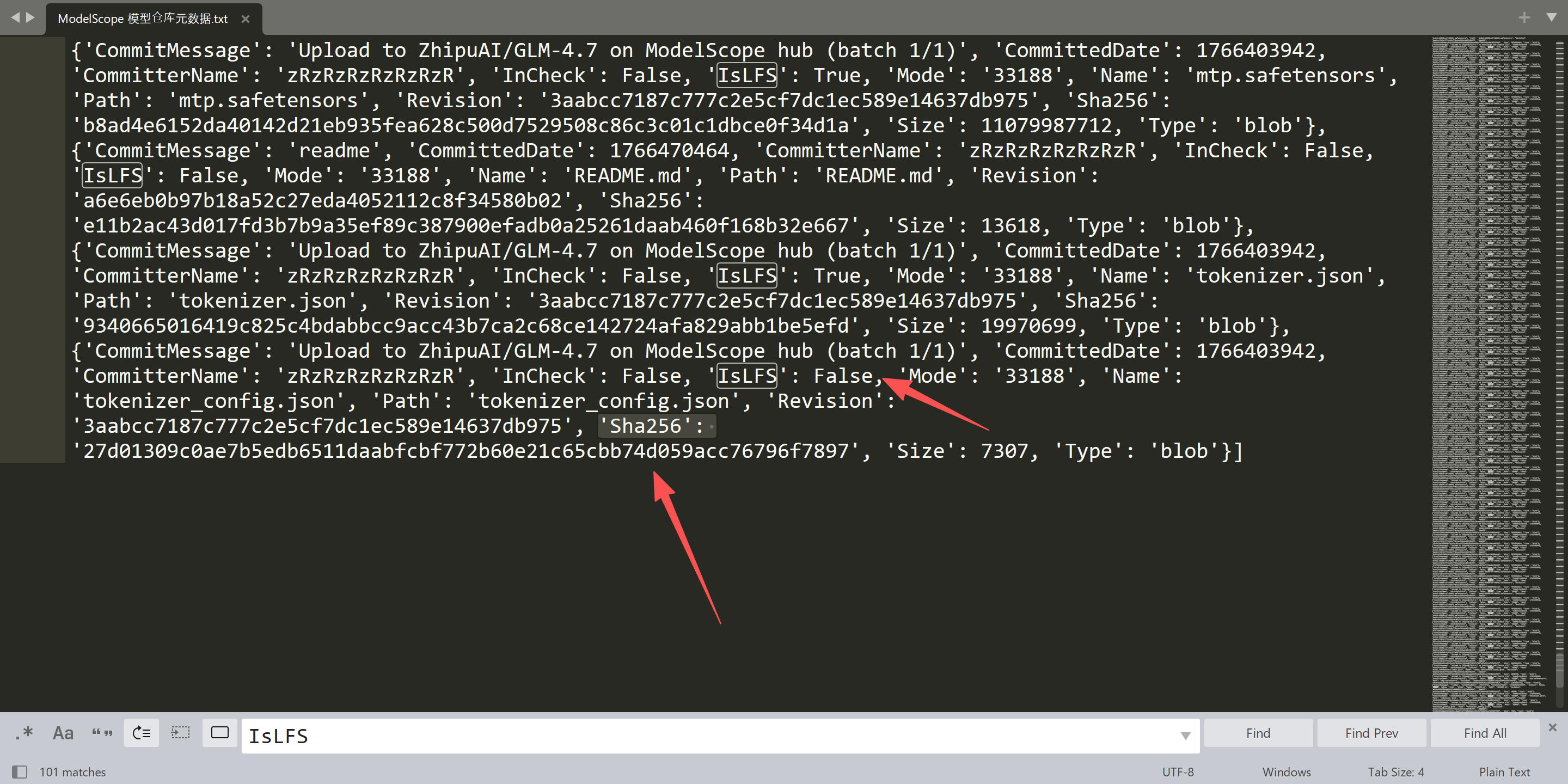
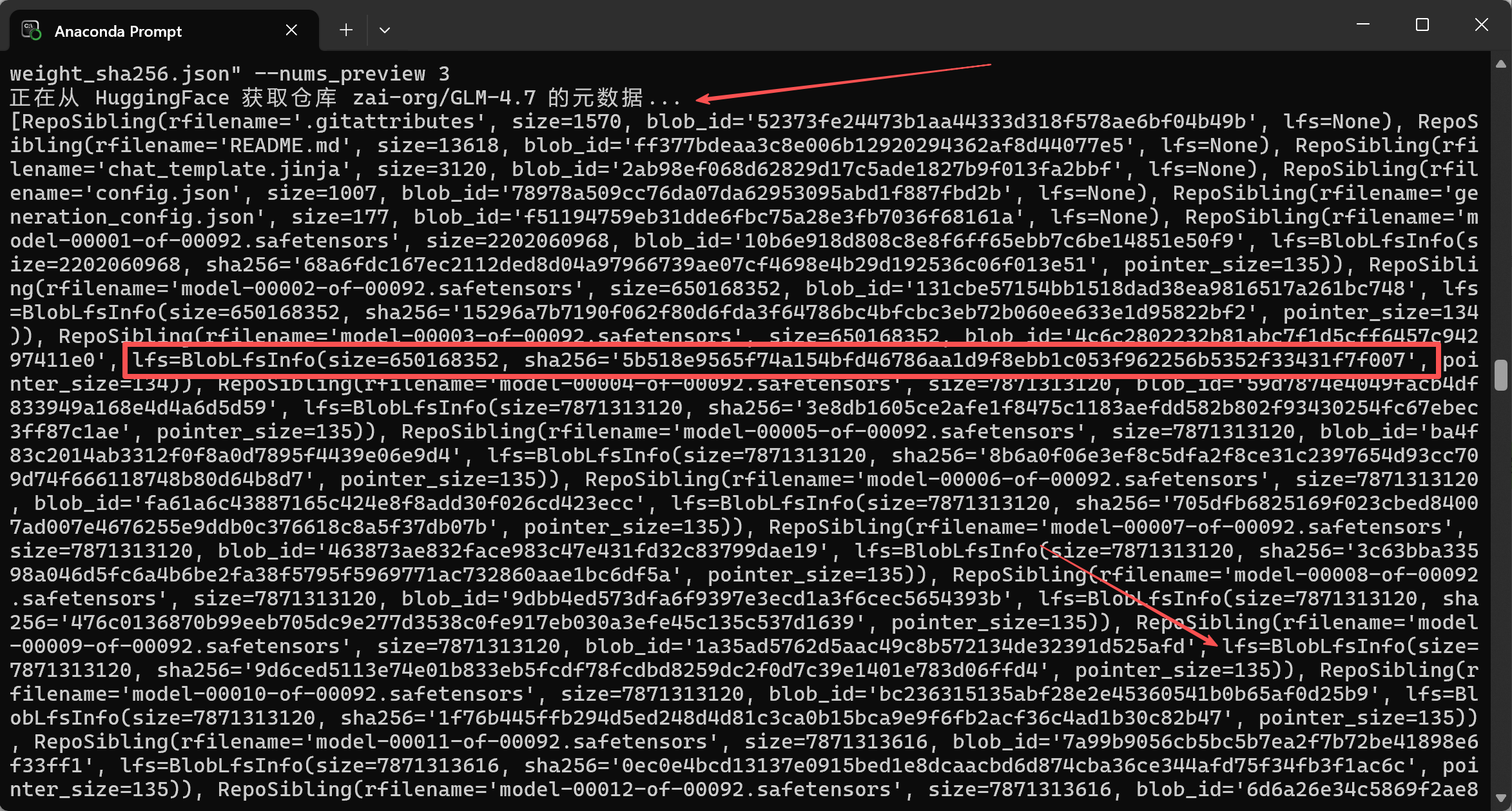
-
大模型权重文件尺寸大,考虑 GB 级文件的 hash 计算性能与稳定性。
-
注意:如果在服务器上运行这个 Python 脚本,可能遇到网络问题报错,也可以在办公电脑上(Proxy 配置好了,能正常访问 HuggingFace 和 ModelScope)运行脚本把 "权重文件名:哈希值" 对应数据保存为本地 JSON 文件,再传到服务器上用于校验即可。