文章目录
-
- 本篇摘要
- 一、核心原理
- 二、关键特性与实现机制
-
-
-
- [1. **数据结构设计(高效实现的核心)**](#1. 数据结构设计(高效实现的核心))
- [2. **频率动态更新**](#2. 频率动态更新)
- 3.实现思想及代码测试
- [4.为什么LFU用 双哈希表 + 双向链表?](#4.为什么LFU用 双哈希表 + 双向链表?)
-
-
- 三、典型优势与劣势
- 四、典型问题与优化策略
-
-
-
- [1. **新数据冷启动优化**](#1. 新数据冷启动优化)
- [2. **频率衰减(避免历史权重过高)**](#2. 频率衰减(避免历史权重过高))
-
-
- 五、适用场景与典型用例
- [六、LFU vs LRU 对比](#六、LFU vs LRU 对比)
- 八、一句话总结
- 九、模版源码
- 本篇小结

本篇摘要

一、核心原理
基础规则:
优先淘汰历史访问频率最低的数据(长期统计维度)。
- 每个缓存条目维护两个核心属性:键值对数据 + 访问频率计数器 。当
缓存容量达到上限时,系统会选择当前所有数据中访问频率最低的条目进行淘汰;若多个数据的频率相同,则进一步淘汰其中最久未被访问 的(类似LRU的兜底逻辑)。
操作流程:
- 访问数据时:命中缓存后,该数据的访问频率+1,并调整其在频率排序中的位置(确保高频数据优先保留,也就是在双向链表头部)。
- 写入新数据时 :若缓存未满,直接插入(初始频率通常为1或0+1);若缓存已满,
先淘汰频率最低的数据,再写入新条目(新数据频率初始化为1);如果对应key值存在,那就更新对应value,最后再调整对应频率。
二、关键特性与实现机制
1. 数据结构设计(高效实现的核心)
LFU通常通过双哈希表 + 频率双向链表 的组合实现O(1)时间复杂度的操作:
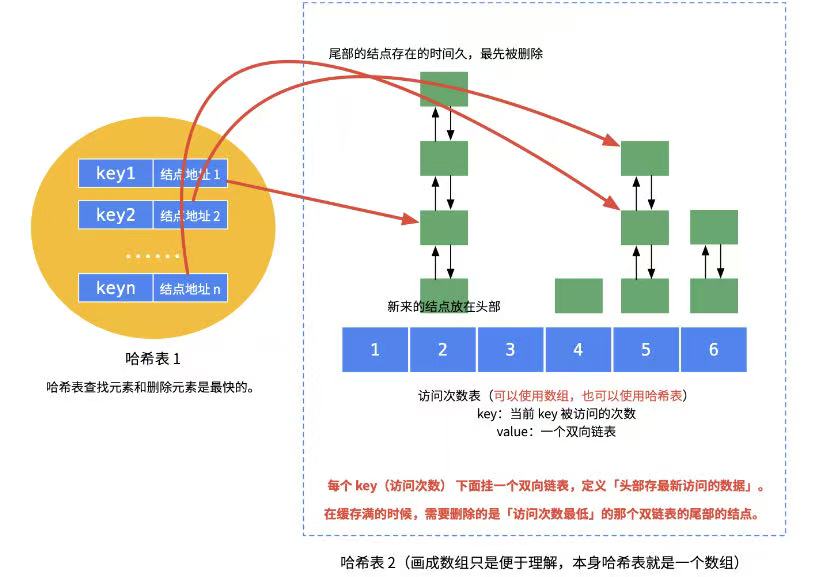
- 存储哈希表(Key-Node) :存储
键到缓存条目数据集的映射(快速定位数据,方便及时更新频率操作)。 - 频率哈希表 :以
频率值为键,而key类型的双向链表为值,维护该频率下的所有数据节点(通常用双向链表存储,支持快速插入/删除)。 - 最小频率计数器:记录当前缓存中最低的频率值,淘汰时直接定位到该频率链表。
比如 : 当数据A被访问时,其频率从1→2,需从原频率1的链表移除,并插入到频率2的链表头部;若新数据B写入,初始频率为1,插入频率1链表。
2. 频率动态更新
每次访问(读/写)缓存数据时,触发频率+1的更新操作:
- 从原频率对应的链表中移除该数据节点;
- 将频率值+1,并插入到新频率对应的链表头部(保证最近访问的数据在链表前端);
- 更新全局最小频率(若原最小频率链表为空,则最小频率+1)。
3.实现思想及代码测试
我们下面要设计的这个LFU算法逻辑和上面的演示图是差不多,只不过我们存储的不是自定义节点的地址,而是这个Node对象,当然地址也行,其他都差不多。
对应的节点结构如下:
cpp
// 定义对应的节点结构:
template <class K, class V>
struct Node
{
Node() {} //表明对应的默认对象必须存在,hash[key] = Node()!!
Node(const K& key, const V& value, int access_count)
: key(key), value(value), access_count(access_count) {
}
K key;
V value;
// 存储对应key的访问次数:
int access_count;
// 对应节点的key值所在的list处的迭代器:
// 表明是类型不是list中的成员变量:
typename list<K>::iterator it; // 方便找到对应的list的具体位置,方便进行删除。
};然后我们只要的就是维护两个哈希,以及容量和对应最小频率计数器即可:
cpp
unordered_map<K, Node<K, V>> _hash_map; // 储存对应key值与对应的上述节点的hash
unordered_map<int, list<K>> _access_map; // 储存对应的访问次数的存放key的那个list
size_t _capacity; // 缓存最大容量,根据它进行决定进行对应的LFU策略更新
int _min_access_count; // 储存最少的访问次数,方便进行删除然而LFU,最大的特色就在于它的访问频率更新策略,通过它来保证整个算法的优越性,下面我们解释下这个策略:
- 首先比如我们put或者get一个数据的时候,此时对应的访问频次就要增加(这里我们设置的是默认增加1),此时就要调整对应的维护频率次数的那个hash了,及时进行对应list节点删除以及挂载即可。
需要注意的是:
- 操作过程要时刻维护着这个min_access_count,这是关键。
- 其次就是这两个hash是互相关联的,也就是移除了对应list的节点,此时对应第一个hash的映射就要及时删除。
- 其次就是如果对应list删除对应节点后为空了,此时就要移除第二个hash对应的槽位。
cpp
// 对于put或者get后进行对应的数据的访问次数等操作进行统一处理(比如进行LFU策略删除等)
void accessCountAdd(const K& key)
{
// 获取对应节点
Node<K, V>& node = _hash_map[key];
int old_access_cnt = node.access_count;
list<int>& cur_list = _access_map[old_access_cnt];
cur_list.erase(node.it);
// 删除后进行判断,如果访问的hash对应list空了,直接删除这个hash槽即可
if (cur_list.empty())
{
_access_map.erase(old_access_cnt);
// 如果恰好是最少的,更新下最小的即可
if (old_access_cnt == _min_access_count)
// 如果删除完对应的之前的key所在的list后,为空了而且此时对应的min_cnt也是当前key的cnt,此时说明min_cnt必须要+1完成更新了
_min_access_count++;
}
// 此时除了有可能它俩相同,就是cur_list不为空的情况,或者不等:
// 进行更新访问次数:
int new_access_cnt = old_access_cnt + 1;
node.access_count = new_access_cnt;
// 再次更新下,这里保险起见:
_min_access_count = min(_min_access_count, new_access_cnt);
// 把对应的key加入到新的list中:
auto& new_list = _access_map[new_access_cnt]; // 这里需要引用,因为后续会进行修改
new_list.push_front(node.key);
// 务必要更新对应迭代器:
node.it = new_list.begin();
}然后我们主要提供对应的get与put接口:
1·get:
这里其实就是通过快查hash,完成对应的获取,如果不存在返回默认构造(这里可能有点不合适,因为是模版暂时这样),如果存在就返回对应node的value,然后进行频率更新策略。
如下:
cpp
V get(const K& key)
{
// 先判断是否存在这个key:
if (_hash_map.find(key) == _hash_map.end())
return V(); //有点瑕疵,一般都是int int ,直接返回-1
// 存在这个key,进行访问次数+1:
accessCountAdd(key);
return _hash_map[key].value;
}2·put:
首先先去第一个hash找对应key的节点是否存在,分为两种情况:
- 存在,此时直接更新对应value,再执行对应的频率策略即可。
- 不存在,此时我们就要新插入了,但是插入之前,先判断是否容量已经满了,如果满了就要根据_min_access_count进行删除了,此时才能继续插入。
如下:
cpp
bool put(const K& key, const V& val)
{
// 1.判断容量是否为0:
if (_capacity <= 0)
return false;
//进行查找:
auto it = _hash_map.find(key);
if (it != _hash_map.end()) {
// 存在这个key,直接更新对应的值并根据对应LFU策略进行对应处理:
_hash_map[key].value = val;
// 2.更新访问次数:
accessCountAdd(key);
return true;
}
// 不存在,检查容量(根据LFU策略更新),插入新的:
// it==_hash_map.end()
if (_capacity <= _hash_map.size())
{
// 容量已满,执行LFU策略:
// 找到访问次数最少的list,也就是是最不经常使用的那一批数据:
auto& min_list = _access_map[_min_access_count];
// 根据LRU策略删除最近最少使用的key:
auto evict_key = min_list.back();
min_list.pop_back();
// 判断是否这个list为空了,进行删除:
if (min_list.empty())
_access_map.erase(_min_access_count);
_hash_map.erase(evict_key);
}
// 不存在直接构造插入:
// 3.插入新节点:
auto& new_list = _access_map[1]; // 这里是1,因为是新插入的节点,访问次数为1
_hash_map[key] = Node<K, V>(key, val, 1); // 这里也需要告诉编译器是个类型不是变量!!
// 4.更新访问次数hash:
new_list.push_front(key);
// 更新对应的key的node的迭代器
_hash_map[key].it = new_list.begin();
_min_access_count = 1;
return true;
}注:
这里有个坑点:就是必须先从对应hash中查找对应的node,如果不存在的话,再去判断是否满了,进行删除以及后面的插入操作,不能上来就进行判满逻辑;否则比如满了,删了一个数据 1--2,但是插入的数据key存在,直接更新就好,因此这个 1--2 就相当于被误删了!
联合测试:
测试数据:
按照规则,这里我们先淘汰的是key为2的数据,接着就是key为4的数据:
cpp
LFUCache<int, int> cache(3);
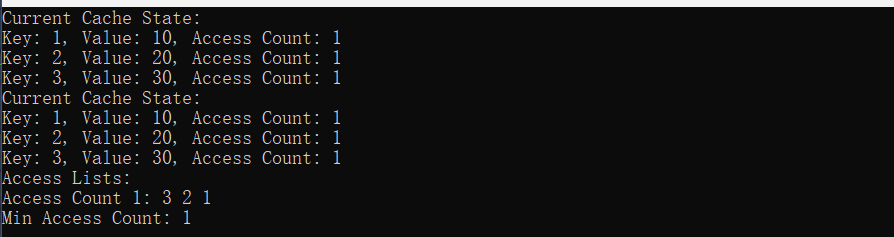
cache.put(1, 10);
cache.put(2, 20);
cache.put(3, 30);
cache.printCache();
cout << endl;
// 访问键1,增加其访问次数
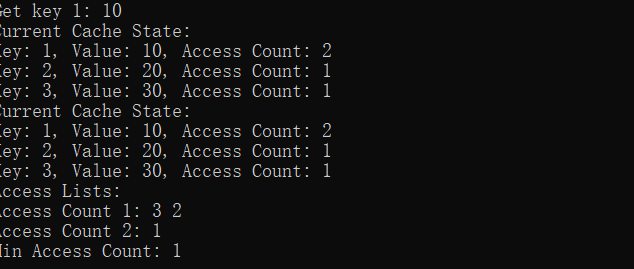
cout << "Get key 1: " << cache.get(1) << endl;
cache.printCache();
cout << endl;
// 添加新键4,应淘汰访问次数最低的键2
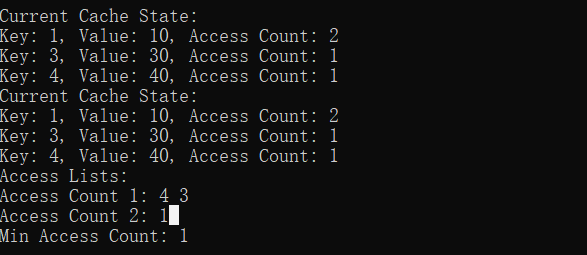
cache.put(4, 40);
cache.printCache();
cout << endl;
// 再次访问键3,增加其访问次数
cout << "Get key 3: " << cache.get(3) << endl;
cache.printCache();
cout << endl;
// 添加新键5,应淘汰访问次数最低的键4
cache.put(5, 50);
cache.printCache();效果:
插入key为1 2 3:
查询key为1的:
插入key为4的,必然淘汰之前key为2的:
访问下key为3的,然后插入key为5,必然淘汰key为4的:
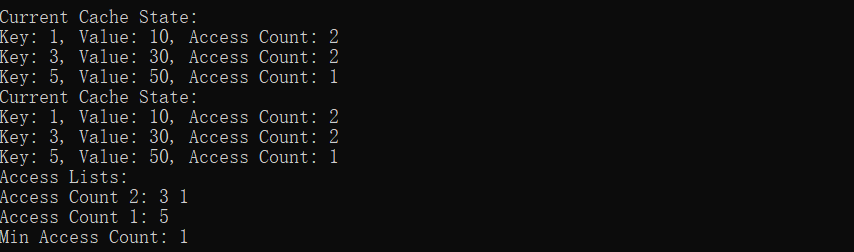
由此可以看出,全部符合预期,也就是这个简易版本的LFU缓存算法还算可以。
4.为什么LFU用 双哈希表 + 双向链表?
首先我们要知道:
LFU的核心需求是:缓存满时快速淘汰「访问频率最低」的数据,且每次访问数据时要快速更新其频率。如果用普通数组或单链表,找最低频率或移动节点都得遍历,效率太低(O(n))。
因此需要:
- 快速定位最低频率的数据(淘汰时用);
- 快速更新数据的访问频率(访问时用);
- 保证所有操作(查、增、删、频率更新)都是O(1)时间复杂度(高并发场景必备)。
设计策略:
- 哈希表1(键-值映射) :存
key → 节点,快速根据key找到数据(O(1))。 - 哈希表2(频率-链表映射) :存
频率 → 双向链表,把相同频率的数据串成链表,方便直接操作整组数据(O(1))。 - 双向链表:每个频率对应的链表里,数据按访问时间排序(头部最新,尾部最久未访问),方便快速找到同频率中最该淘汰的节点(O(1)),其实就是每个list相当于按照lru机制进行添加/淘汰。
- 最小频率计数器:直接记录当前最低频率,淘汰时不用遍历所有频率(O(1))。
效果:
- 淘汰时:通过最小频率指针找到最低频率的链表,直接取尾部节点(最久未访问的同频率数据)删除(O(1));
- 访问时:通过哈希表定位数据,更新频率后从原频率链表删掉,插入新频率链表头部(O(1))。
三、典型优势与劣势
优势场景
- 长期热点稳定:适合访问频率长期集中的数据(如经典文章、爆款商品、CDN热门视频)。高频数据因频率持续累积,会被优先保留,减少重复计算/加载的开销。
- 理论最优性:在"访问频率完全可预测且稳定"的场景下,LFU能最大化缓存命中率(长期高频数据几乎不被淘汰)。
劣势与挑战
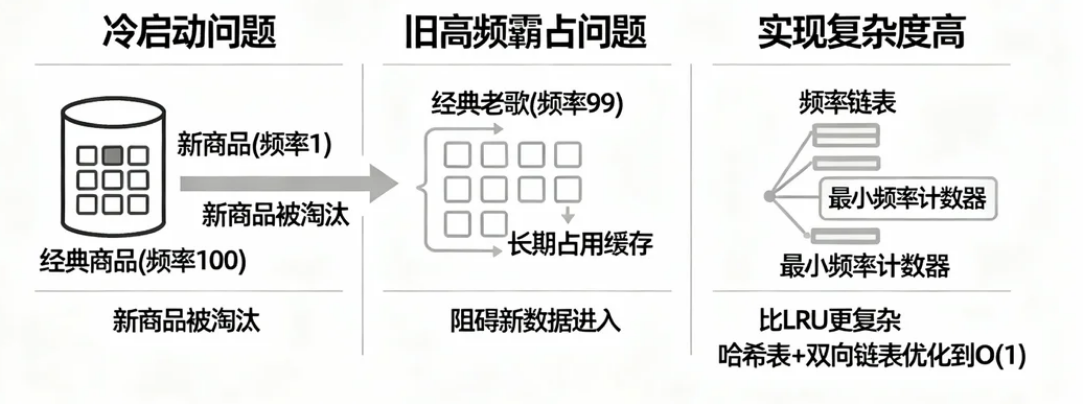
- 冷启动问题(新数据劣势):新加入的数据初始频率为0或1,即使近期被频繁访问,也可能因频率低于历史高频数据而被优先淘汰(例如:突然爆火的新商品挤不进缓存)。
- 旧高频霸占问题:历史高频但当前不再使用的数据(如过季商品、旧闻)可能因早期积累的高频率长期占位,阻碍新热点数据的缓存(例如:经典老歌长期占缓存,新歌难进入)。
- 实现复杂度高:需维护频率链表、最小频率计数器等结构,代码实现比LRU更复杂(但可通过哈希表+双向链表优化到O(1)操作)。
四、典型问题与优化策略
1. 新数据冷启动优化

- 初始频率加成:新数据的初始频率设为1(或更高,如2),避免因初始0被直接淘汰。
- 预热机制:对已知的高频新数据(如运营推荐的新品),手动初始化较高频率。
- 混合策略:结合LRU思想,对新数据给予短期"保护期"(例如:新数据前N次访问不参与频率竞争)。
2. 频率衰减(避免历史权重过高)
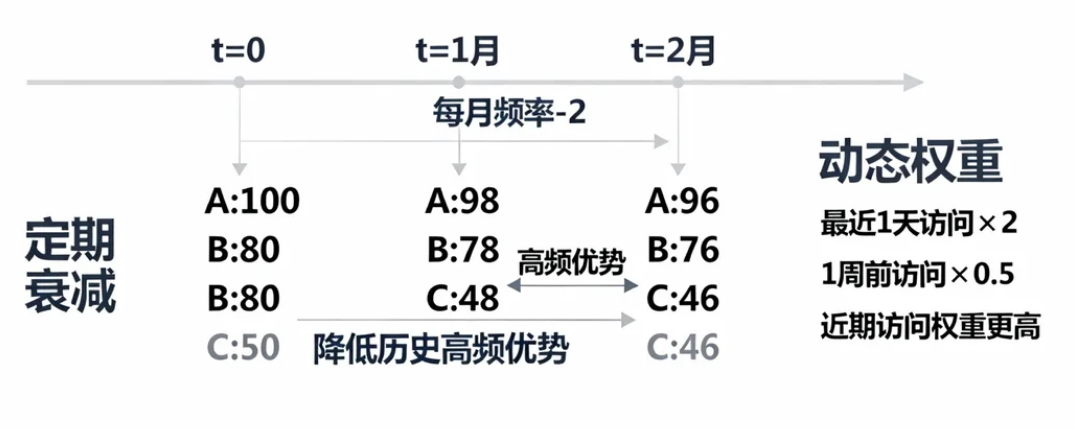
- 定期衰减:每隔固定时间,所有数据的频率值减半(或减去固定值),降低历史高频数据的绝对优势(例如:每月将所有数据频率÷2,让近期活跃数据更容易反超)。
- 动态权重:引入时间衰减因子,近期访问的频率权重更高(例如:最近1天的访问次数×2,1周前的访问次数×0.5)。
五、适用场景与典型用例
| 场景类型 | 具体例子 | 为什么适合LFU? |
|---|---|---|
| 长期稳定热点 | CDN热门视频缓存、经典文档/教程页 | 这些内容长期被高频访问,频率持续累积,LFU能确保其长期驻留缓存。 |
| 爆款商品/内容 | 电商平台的限时爆款、社交媒体的热帖 | 爆款期间访问频率极高,LFU会优先保留,支撑高并发请求。 |
| 低更新频率服务 | 在线词典的热门词条、百科经典词条 | 词条热度长期稳定,高频词条(如"人工智能")会被持续缓存。 |
六、LFU vs LRU 对比
| 维度 | LFU(最不经常使用) | LRU(最近最少使用) |
|---|---|---|
| 判断依据 | 历史访问频率(总次数) | 最近一次访问时间(时间戳) |
| 核心优势 | 保护长期高频热点数据,命中率高 | 快速响应新流量,适应突发热点 |
| 主要劣势 | 新数据易被淘汰,旧高频数据可能霸占 | 旧高频数据可能被误淘汰,不保护长期热点 |
| 实现复杂度 | 较高(需维护频率结构) | 较低(只需维护访问时间顺序) |
| 典型场景 | 经典内容、爆款商品、CDN稳定热点 | 浏览器缓存、数据库Buffer Pool、新热点 |
| 变种优化 | LFU-LRU混合、频率衰减、初始频率加成 | LRU-K(考虑最近K次访问)、ARC(自适应) |
八、一句话总结
LFU是缓存中的"时间的朋友"------谁被访问的次数越多,谁就越容易被保留;但它需要解决"新数据入场难"和"旧热点占位"的问题,实际常通过优化策略(如频率衰减、初始加成)或与LRU结合(如Redis的近似LFU)来平衡长期与短期热点需求。
九、模版源码
👉 https://gitee.com/wang-yimingq/crazy-learning-cpp/blob/master/LFU-algorithm/LFU.cpp 👈
本篇小结
