📖标题:UniHetero: Could Generation Enhance Understanding for Vision-Language-Model at Large Data Scale?
🌐来源:arXiv, 2512.23512v1
🌟摘要
- 要点 1:生成可以提高理解,但只有当您生成语义时,Not Pixels 统一视觉语言模型中的一个常见假设是添加生成自然会加强理解。但是,这在规模上并不总是正确的。在 200M+ 预训练样本时,生成有助于仅在语义级别运行时才理解,即当模型学习在 LLM 内自动回归高级视觉表示时。一旦像素级目标(例如,扩散损失)直接干扰LLM,理解性能通常会下降。
- 要点 2:生成揭示了优越的数据缩放趋势和更高的数据利用率。与单独理解相比,统一生成理解表现出卓越的缩放趋势,揭示了一种更有效的方法,可以从视觉模态中学习仅视觉知识指令,而不是字幕到文本。
- 要点 3:输入嵌入的自回归可以有效地捕捉视觉细节。与常用的视觉编码器相比,对输入嵌入进行视觉自回归显示出更少的累积误差,并且与模态无关,可以扩展到所有模态。学习到的语义表示捕获视觉信息,例如对象、位置、形状和颜色;进一步启用像素级图像生成。
🛎️文章简介
🔸研究问题:生成任务如何促进视觉理解任务的增强?
🔸主要贡献:论文提出了一种统一的生成-理解模型(UniHetero),验证了在大规模数据下生成任务可以增强理解任务的效果。
📝重点思路
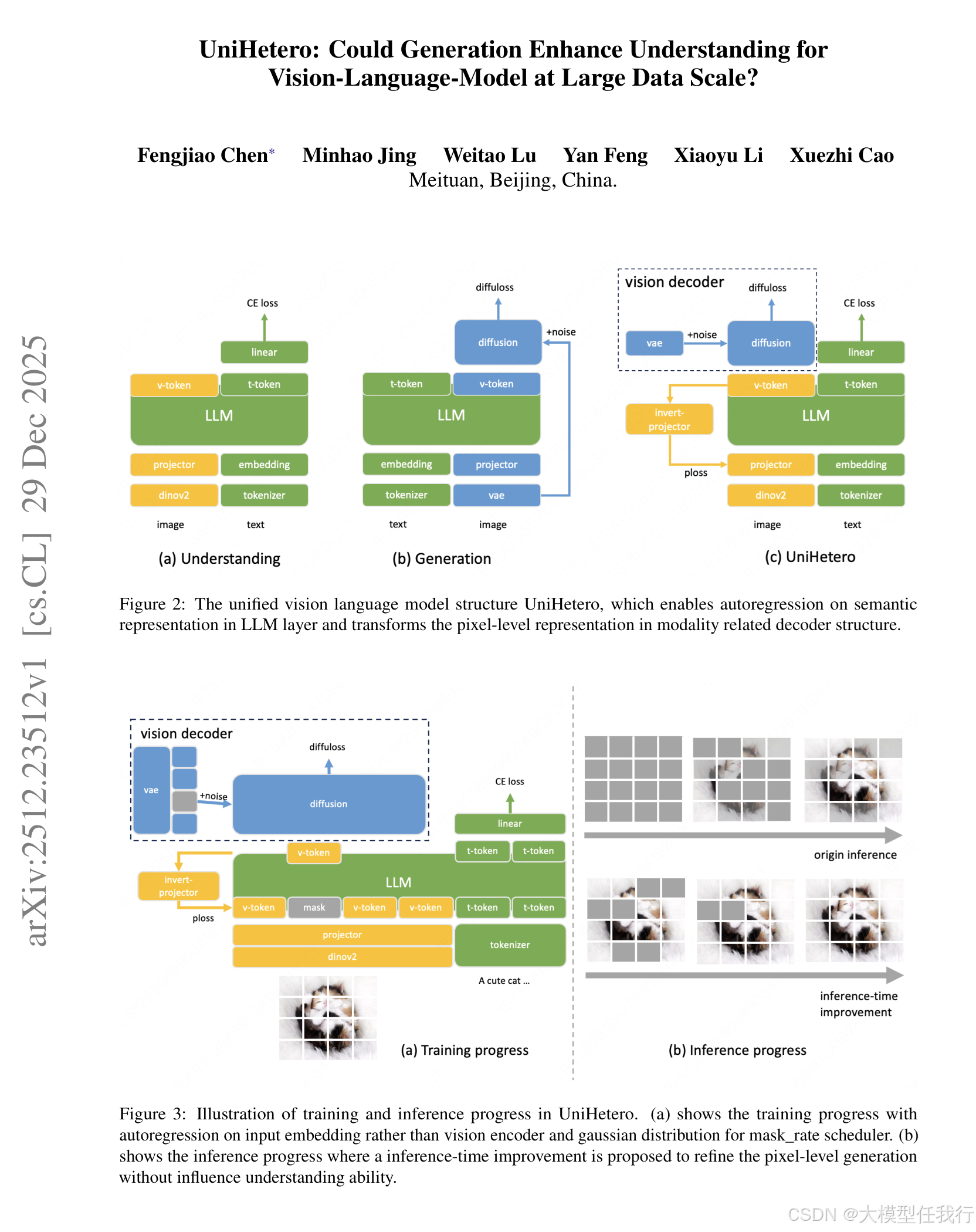
🔸采用连续编码的自回归模型架构,以提高数据利用效率。
🔸在预训练阶段,使用80百万对图像-文本对进行训练,经过三个周期后生成240百万训练实例。
🔸在模型训练中利用Llama2-7B作为LLM主干,采用多种训练技巧以优化模态融合。
🔸使用不同类型的损失函数以平衡语义特征与像素级特征之间的损失。
🔸通过实验设计验证生成建模是否增强理解,分析语义和像素表示的能力。
🔎分析总结
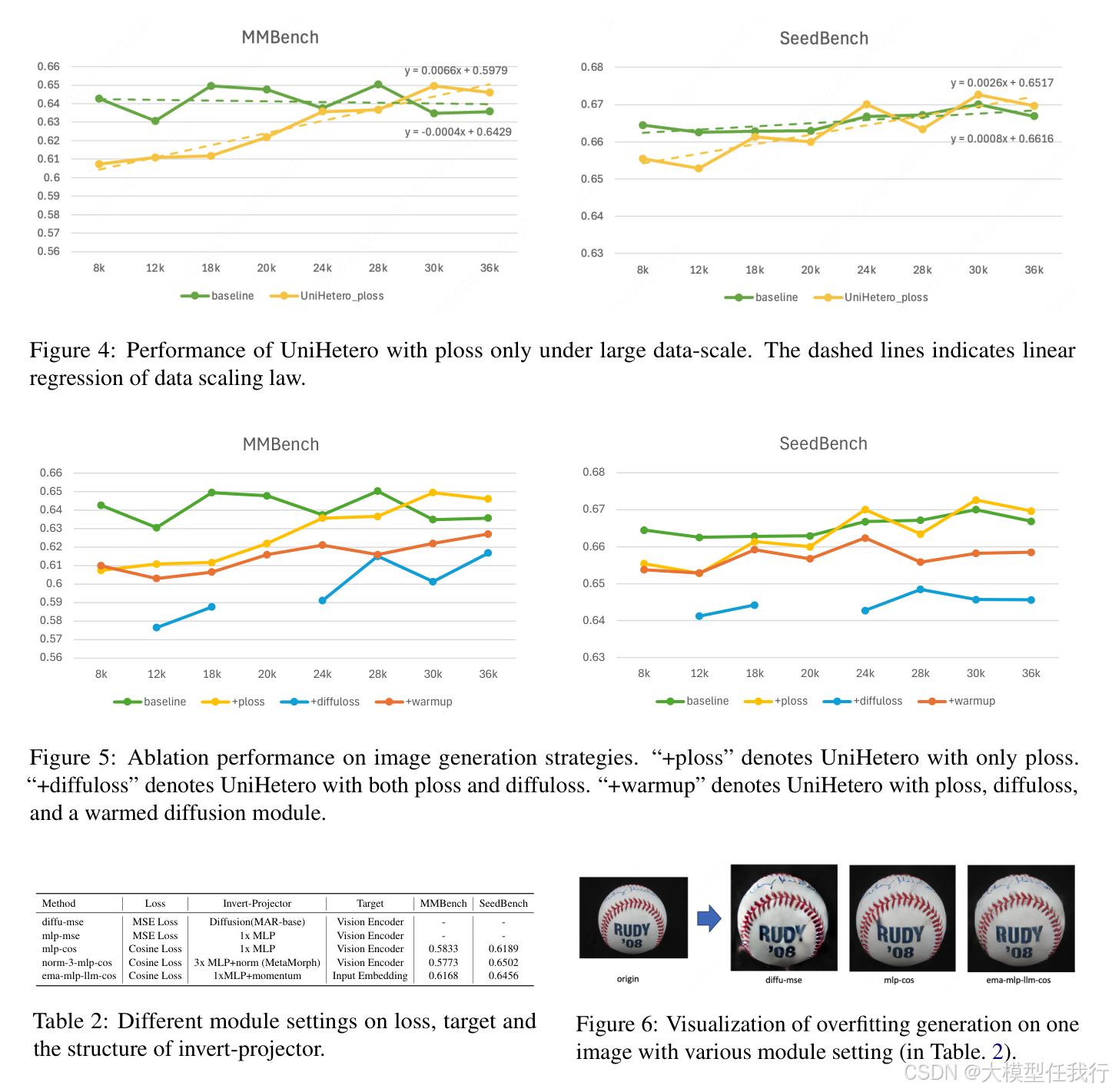
🔸实验结果表明,在UniHetero模型下,使用纯文本生成损失的基准组和加入图像生成损失的实验组相比,后者的理解性能有所提升,证明生成任务促进了理解。
🔸通过数量化分析,研究显示随着生成数据规模的增加,理解任务的表现指标呈现上升趋势。
🔸论文指出,图像表示中的语义特征与像素级表达冲突,影响整合任务的效果。
🔸经过优化的生成质量,需要进一步改进视觉解码器和训练策略来减少负面影响。
💡个人观点
论文强调生成任务在大量数据环境下对视觉理解的促进作用,统一的生成与理解任务设计,有助于推动多模态应用发展。
🧩附录