Park, J., Lee, S., Kim, S., Xiong, Y., & Kim, H. J. (2023). Self-positioning Point-based Transformer for Point Cloud Understanding. CVPR.
博主导读 :
在点云 Transformer 的江湖里,各大门派(PointNet++, PTv1, PTv2)似乎都遵守着一个不成文的规定:"远亲不如近邻" 。为了节省算力,大家纷纷画地为牢,只在 k-NN 或 球查询 (Ball Query) 划定的局部圈子里折腾。
但这种"几何邻域"真的靠谱吗?一只细长的椅子腿,它的几何邻居可能是地板,但它真正的"语义亲戚"其实是远在另一头的椅子背。单纯的局部注意力,注定是"只见树木,不见森林"。
SPoTr (Self-Positioning Transformer) 站出来掀了桌子:谁说采样一定要用 FPS?谁说看全局一定要算 O ( N 2 ) O(N^2) O(N2)? 它提出了一种类似于 "可变形卷积 (Deformable Conv)" 的自定位机制 ------派出少量智能"探针",自动飞到物体最关键的部位(比如机翼尖、桌角),用极小的代价,把全局信息"吸"过来。
今天我们就来拆解这篇 CVPR 2023 的佳作,看它如何用"主动出击"取代"被动采样"。
论文:Self-Positioning Point-Based Transformer
1. 痛点:几何与语义的"错位"
在 SPoTr 出现之前,处理长距离依赖(全局信息)主要有两种笨办法:
- 硬抗派 (Global Attention) :直接对所有点算 Attention。
- 后果 :显存爆炸,计算量 O ( N 2 ) O(N^2) O(N2),根本跑不动大场景。
- 采样派 (Downsampling + Attention) :先用 FPS (最远点采样) 选几个点,再算 Attention。
- 后果:FPS 是**"盲目"**的。它只管几何上分得散,不管语义上重不重要。它很可能选了一堆地板上的点,却漏掉了关键的物体边缘。
SPoTr 的灵魂拷问 :
如果网络能像人眼一样,主动去关注那些"有意思"的地方(Self-Positioning),而不是被死板的几何规则(k-NN/FPS)束缚,是不是就能用很少的点,看清整个世界?
2. 核心大招:自定位点注意力 (SPA) 🔥
SPoTr 的核心模块 SPA (Self-Positioning Point-based Attention) 不再是被动地接收输入,而是变成了一个**"三步走"的主动侦察过程**:
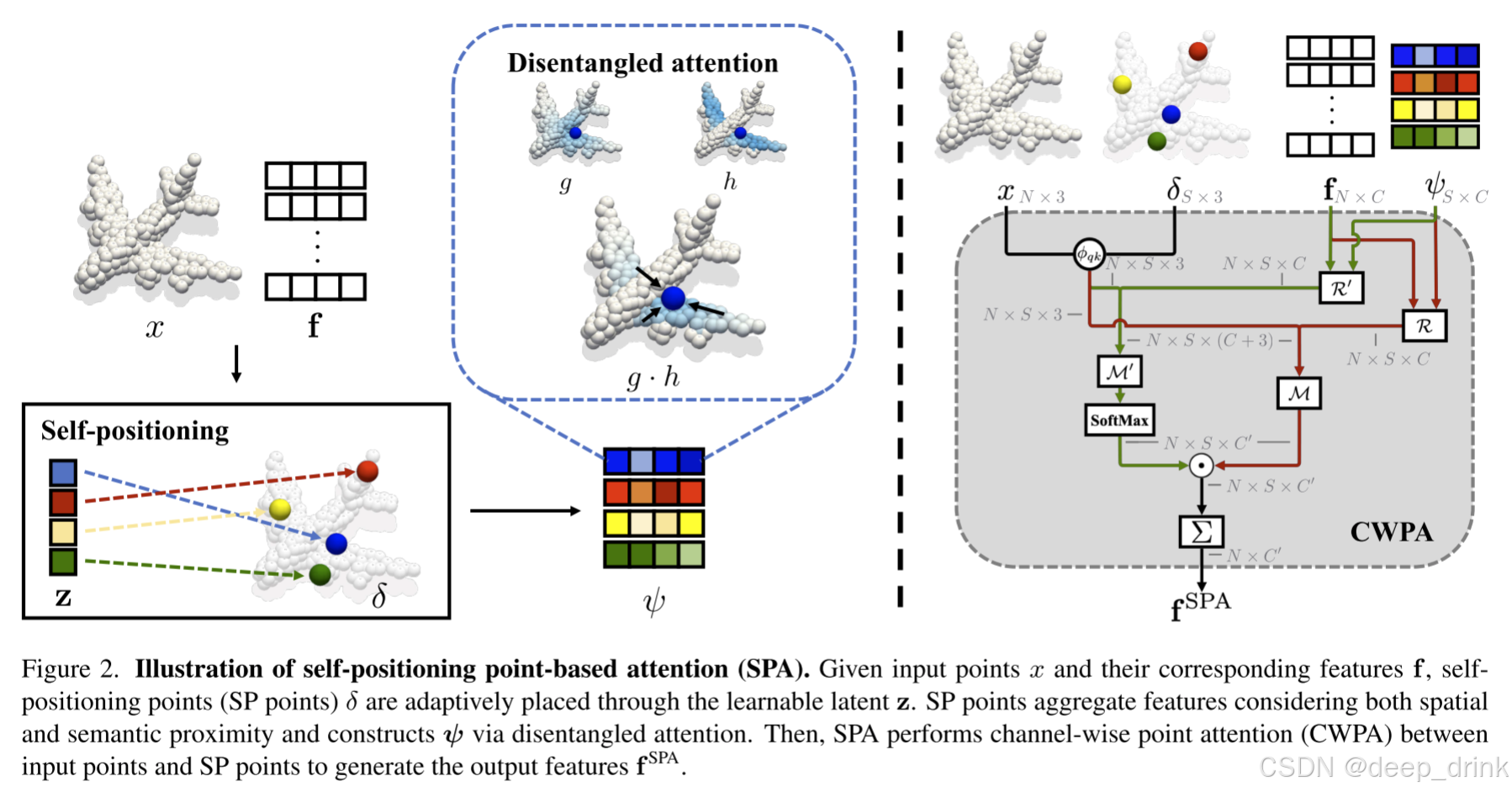
图解逻辑 :
左边是生成探针,中间是探针吸取信息(解耦注意力),右边是探针把信息发回给所有点。
2.1 第一步:探针去哪儿?(Positioning) 🎯
传统网络不知道哪里重要,但 SPoTr 引入了一组可学习的隐向量 (Latent Vector z s z_s zs) 。每一个 z s z_s zs 就像一个带着特定任务的"特工",比如"特工 A 负责找尖锐的角","特工 B 负责找平坦的面"。
δ s = ∑ i SoftMax ( f i ⊤ z s ) x i \delta_s = \sum_{i} \text{SoftMax}(f_i^\top z_s) x_i δs=i∑SoftMax(fi⊤zs)xi
- 原理 :网络计算输入特征 f i f_i fi 和特工意图 z s z_s zs 的相似度,以此为权重,算出新的重心 δ s \delta_s δs。
- 效果:这些探针会自动**"瞬移"**到点云中语义最丰富的地方。
2.2 第二步:怎么收集情报?(Disentangled Aggregation) 🧠
探针到位后,需要收集周围的特征。但这里有个坑:离得近 ≠ \neq = 是一伙的 。
比如探针落在了"桌腿"和"地板"的交界处,如果只按距离聚合,就会把地板特征混进来。
作者提出了 解耦注意力 (Disentangled Attention),这也是论文的一大亮点:
ψ s = ∑ i g ( δ s , x i ) ⏟ 空间核 ⋅ h ( z s , f i ) ⏟ 语义核 ⋅ f i \psi_s = \sum_{i} \underbrace{g(\delta_s, x_i)}{\text{空间核}} \cdot \underbrace{h(z_s, f_i)}{\text{语义核}} \cdot f_i ψs=i∑空间核 g(δs,xi)⋅语义核 h(zs,fi)⋅fi
- 空间核 g g g (Spatial Kernel) :类似于 RBF,只看距离。(离得近?)
- 语义核 h h h (Semantic Kernel) :类似于 Attention,只看特征相似度。(长得像?)
- 双重过滤 :只有当一个点 既离得近,又长得像 时,它的特征才会被吸收。这就自带了强大的**"降噪"**功能。
2.3 第三步:情报分发 (Distribution) 📡
现在,这 S S S 个探针已经浓缩了整个点云的精华(Global Context)。最后一步就是通过 Cross-Attention,把这些全局信息"广播"回每一个原始点。
3. 数学之美:通道级点注意力 (CWPA) 🛠️
在上述的交互过程中,SPoTr 使用了 Channel-Wise Point Attention (CWPA)。这是对标准 Transformer 公式的魔改,专门针对点云特性进行了优化。
我们拆解论文中的 公式 (8) 和 公式 (9):
3.1 公式 (9):权重的生成 (The Weight)
A q , k , c = exp ( M ′ ( R ′ ( f q , f k ) ; ϕ q k / τ ) c ) ∑ k ′ ∈ Ω k e y exp ( M ′ ( R ′ ( f q , f k ′ ) ; ϕ q k ′ / τ ) c ) \mathbb{A}{q,k,c} = \frac{\exp(\mathcal{M}'(\\mathcal{R}'(f_q, f_k); \\phi_{qk}/\tau)c)}{\sum{k' \in \Omega{key}} \exp(\mathcal{M}'(\\mathcal{R}'(f_q, f_k'); \\phi_{qk'}/\tau)_c)} Aq,k,c=∑k′∈Ωkeyexp(M′(R′(fq,fk′);ϕqk′/τ)c)exp(M′(R′(fq,fk);ϕqk/τ)c)
- 向量化权重 :注意下标 c c c。这表示网络为每一个特征通道都单独计算了一组 Attention 权重。
- 物理含义 :
- 在处理 颜色通道 时,网络可能认为邻居 A 很重要(权重 0.9)。
- 在处理 法向通道 时,网络可能认为邻居 A 是噪声(权重 0.1)。
- 这种细粒度的控制力,是标准 Scalar Attention 无法做到的。
3.2 公式 (8):特征的聚合 (The Aggregation)
CWPA = ∑ k ∈ Ω k e y A q , k , : ⊙ M ( R ( f q , f k ) ⏟ 相对特征 ; ϕ q k ⏟ 相对位置 ) \text{CWPA} = \sum_{k \in \Omega_{key}} \mathbb{A}_{q,k,:} \odot \mathcal{M}(\\underbrace{\\mathcal{R}(f_q, f_k)}_{\\text{相对特征}}; \\underbrace{\\phi_{qk}}_{\\text{相对位置}}) CWPA=k∈Ωkey∑Aq,k,:⊙M(相对特征 R(fq,fk);相对位置 ϕqk)
这里藏着两个"魔鬼细节":
- 相对特征 (Subtraction) : R ( f q , f k ) = f q − f k \mathcal{R}(f_q, f_k) = f_q - f_k R(fq,fk)=fq−fk。论文实验证明,减法比点积或拼接都有效。网络更关心"邻居比我强多少",而不是"邻居是多少"。
- 逐元素乘法 ( ⊙ \odot ⊙) :权重向量 A \mathbb{A} A 与变换后的 Value 向量逐元素相乘。这实现了通道层面的精准特征提取。
博主笔记 :当公式 (9) 中的温度系数 τ → 0 \tau \to 0 τ→0 时,Softmax 会退化为 One-hot (Argmax)。此时 CWPA 就变成了 Max Pooling。这说明 SPoTr 在理论上完美兼容了 PointNet++ 的 Set Abstraction 操作,是一个更通用的超集。
4. 架构全景:SPoTr Block 与整体网络 🏗️
有了强大的 SPA 和 CWPA 算子,作者是如何搭建整个大厦的呢?
4.1 SPoTr Block:左右互搏,刚柔并济
一个标准的 SPoTr Block 采用了双流并行 的设计,就像人的左右手:
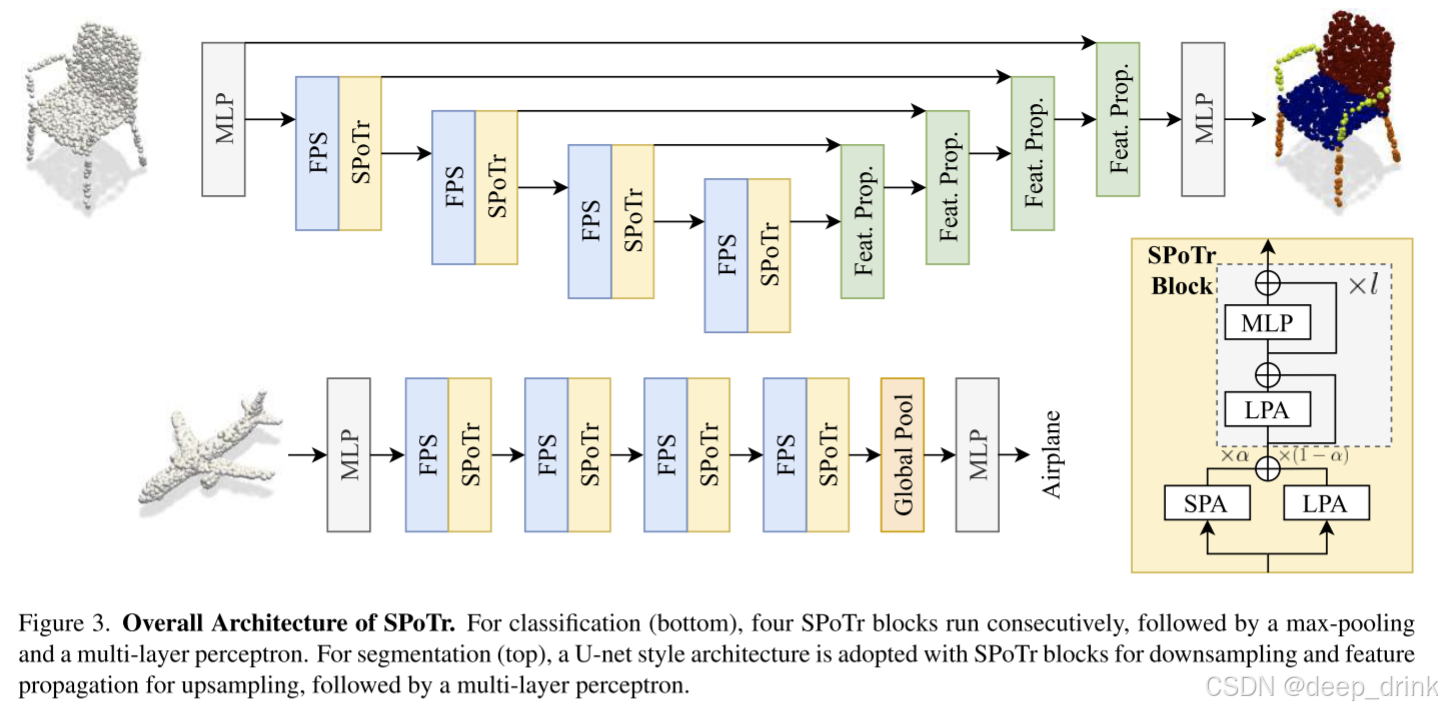
- 左手画圆 (LPA - Local Points Attention) :
- 传统的 k-NN / Ball Query。
- 使用 CWPA 提取局部精细几何特征。
- 右手画方 (SPA - Self-Positioning Attention) :
- 生成探针,主动出击。
- 使用 CWPA 提取全局长距离依赖。
融合机制 (Gating) :
f ^ i = α ⋅ f i S P A + ( 1 − α ) ⋅ f i L P A \hat{f}_i = \alpha \cdot f_i^{SPA} + (1 - \alpha) \cdot f_i^{LPA} f^i=α⋅fiSPA+(1−α)⋅fiLPA
- α \alpha α 是一个可学习参数。网络会自动决定"这一层我要多看细节(LPA)"还是"多看全局(SPA)"。这种软性的门控比简单的 Add 或 Concat 更灵活。
4.2 整体架构 (Macro Architecture)
基于 SPoTr Block,作者设计了针对分类和分割的两种架构:
-
分类任务 (Classification):
- 流程 :
MLP→ \to →SPoTr Block→ \to →FPS 下采样→ \to →SPoTr Block... → \to →Global Max Pooling→ \to →MLP。 - 典型的层级结构,随着层数加深,点数减少,特征维度增加。
- 流程 :
-
分割任务 (Segmentation):
- U-Net 结构:经典的"U"型设计。
- Encoder:利用 SPoTr Block 提取特征并下采样。
- Decoder :利用 Feature Propagation (FP) 层进行上采样,并通过 Skip Connection 恢复细节。
- 值得注意的是,在 Decoder 阶段同样使用了 SPoTr Block 来增强特征的语义一致性。
5. 可视化实锤:探针真的智能吗?
口说无凭,作者在 ScanObjectNN 和 SN-Part 上做了可视化,结果非常惊艳。
5.1 探针位置的一致性
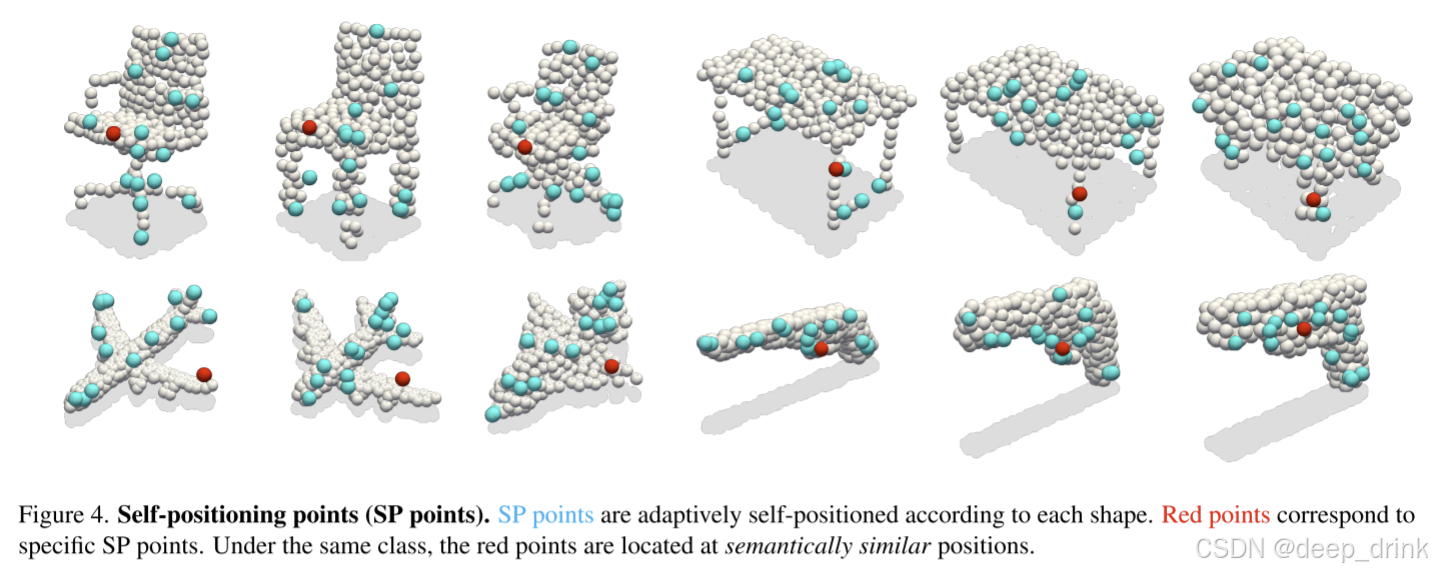
解读 :
看上面的飞机图(红点代表同一个 ID 的探针)。你会发现,无论飞机怎么摆放,形状如何变化,红色的探针总是死死地盯着"左机翼" 。这说明网络真的学到了"语义对齐",而不是随机乱飞。
也就是说相似语义的探针,位于相似的地方
5.2 解耦注意力的降噪效果
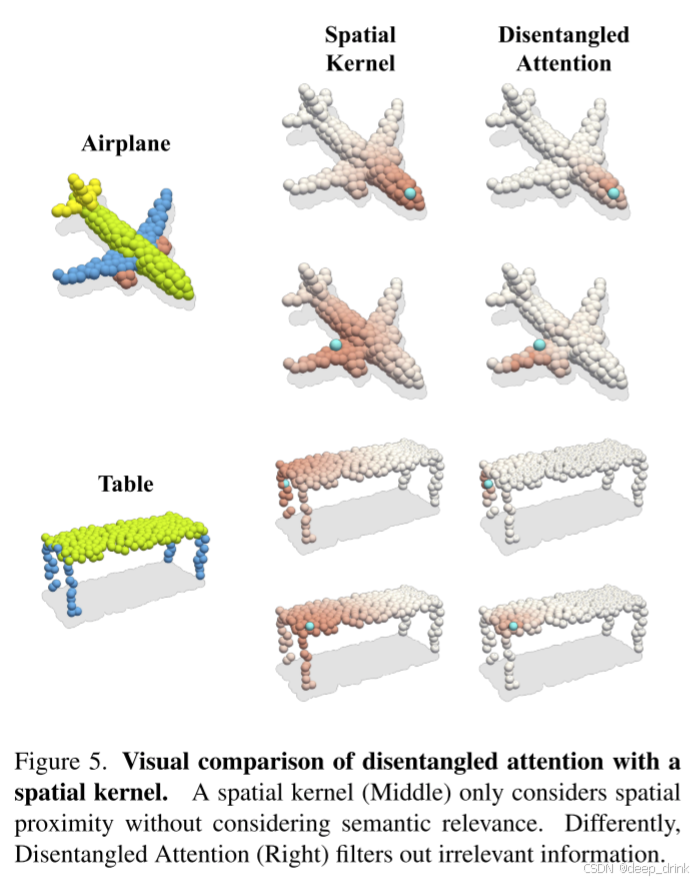
解读:
- 仅空间核):探针在机翼根部,结果把机身的一大块也"染红"了(误吸了机身特征)。
- 解耦注意力 :加上语义核后,红色区域完美地收缩在了机翼范围内,机身被过滤掉了。这就是"双边滤波"在特征空间的威力。
6. 总结 (Conclusion)
SPoTr 是 "Deformable (可变形)" 思想在点云 Transformer 中的一次教科书式落地。它的成功证明了:
- 主动优于被动:不要被 k-NN 锁死视野。让网络自己决定"看哪里",比人工设定的规则更有效。
- 以点带面 :全局信息不需要 O ( N 2 ) O(N^2) O(N2) 的全连接。只要找准几个关键点(SP points),就能以极低的代价 ( O ( N ⋅ S ) O(N \cdot S) O(N⋅S)) 撬动全局。
- 特征要解耦:空间距离和语义相似度必须同时考虑,否则"跨界"的噪声会毁了特征的纯度。
如果你正在处理 稀疏、非结构化 的 3D 数据,或者苦恼于 Transformer 的计算量,SPoTr 的这种"探针"思路绝对值得一试。
📚 参考文献
1 Park, J., Lee, S., Kim, S., Xiong, Y., & Kim, H. J. (2023). Self-positioning Point-based Transformer for Point Cloud Understanding. CVPR.
💬 互动话题:
- 关于插值 :SPoTr 生成的探针坐标 δ s \delta_s δs 大概率不在真实的输入点上(是虚空的)。这种"虚拟点"的特征是通过插值得到的,你觉得这会引入混叠误差吗?有没有更好的特征获取方式?
- 对比 PTv3 :PTv3 (CVPR 2024) 通过 序列化 (Serialization) 解决了效率问题,而 SPoTr (CVPR 2023) 通过 主动采样 解决了效率问题。如果是你,你会更倾向于哪种技术路线?为什么?
📚 附录:点云网络系列导航
🔥 欢迎订阅专栏 :【点云特征分析_顶会论文代码硬核拆解】持续更新中...
本文为 CSDN 专栏【点云特征分析_顶会论文代码硬核拆解】原创内容,转载请注明出处。