系统性学习C++进阶-第十五讲-map和set的使用
- [1. 序列式容器和关联式容器](#1. 序列式容器和关联式容器)
- [2. set 系列的使用](#2. set 系列的使用)
-
- [2.1 set 和 multiset 参考文档](#2.1 set 和 multiset 参考文档)
- [2.2 set 类的使用](#2.2 set 类的使用)
- [2.3 set 的构造和迭代器](#2.3 set 的构造和迭代器)
- [2.4 set 的增删查](#2.4 set 的增删查)
- [2.5 insert 和迭代器遍历使用样例:](#2.5 insert 和迭代器遍历使用样例:)
- [2.6 find 和 erase 使用样例:](#2.6 find 和 erase 使用样例:)
- [2.7 multiset 和 set 的差异](#2.7 multiset 和 set 的差异)
- [2.8 练习题 LeetCode 349.两个数组的交集(https://leetcode.cn/problems/intersection-of-two-arrays/)](#2.8 练习题 LeetCode 349.两个数组的交集)
- [2.9 练习题 LeetCode 142.环形链表II(https://leetcode.cn/problems/linked-list-cycle-ii/description/)](#2.9 练习题 LeetCode 142.环形链表II)
- [3. map 系列的使用](#3. map 系列的使用)
-
- [3.1 map 和 multimap 参考文档](#3.1 map 和 multimap 参考文档)
- [3.2 map 类的介绍](#3.2 map 类的介绍)
- [3.3 pair 类型介绍](#3.3 pair 类型介绍)
- [3.4 map 的构造](#3.4 map 的构造)
- [3.5 map 的增删查](#3.5 map 的增删查)
- [3.6 map 的数据修改](#3.6 map 的数据修改)
-
- [3.6.1 insert 函数](#3.6.1 insert 函数)
- [3.6.2 operator 重载](#3.6.2 operator[ ] 重载)
- [3.7 构造遍历及增删查使用样例](#3.7 构造遍历及增删查使用样例)
- [3.8 map 的迭代器和 功能样例:](#3.8 map 的迭代器和 [ ] 功能样例:)
- [3.9 multimap 和 map 的差异](#3.9 multimap 和 map 的差异)
- [3.10 练习题 LeetCode 138. 随机链表的复制(https://leetcode.cn/problems/copy-list-with-random-pointer/description/)](#3.10 练习题 LeetCode 138. 随机链表的复制)
- [3.10 LeetCode 692. 前K个高频单词(https://leetcode.cn/problems/top-k-frequent-words/)](#3.10 LeetCode 692. 前K个高频单词)
1. 序列式容器和关联式容器
前面我们已经接触过 STL 中的部分容器如:string、vector、list、deque、array、forward_list 等,这些容器统称为序列式容器,
因为逻辑结构为线性序列的数据结构,两个位置存储的值之间⼀般没有紧密的关联关系,比如交换⼀下,他依旧是序列式容器。
顺序容器中的元素是按他们在容器中的存储位置来顺序保存和访问的。
关联式容器也是用来存储数据的,与序列式容器不同的是,关联式容器逻辑结构通常是非线性结构,两个位置有紧密的关联关系,
交换一下,他的存储结构就被破坏了。顺序容器中的元素是按关键字来保存和访问的。
关联式容器有 map / set 系列和 unordered_map / unordered_set 系列。本章节讲解的 map 和 set 底层是红黑树,
红黑树是⼀颗平衡二叉搜索树。set 是 key 搜索场景的结构,map 是key / value搜索场景的结构。
2. set 系列的使用
2.1 set 和 multiset 参考文档
链接:set
2.2 set 类的使用

-
set的声明如下,T就是set底层关键字的类型 -
set默认要求T支持小于比较,如果不支持或者想按自己的需求走可以自行实现仿函数传给第二个模版参数 -
set底层存储数据的内存是从空间配置器申请的,如果需要可以自己实现内存池,传给第三个参数。 -
⼀般情况下,我们都不需要传后两个模版参数。
-
set底层是用红黑树实现,增删查效率是 Ologn ,迭代器遍历是⾛的搜索树的中序,所以是有序的。 -
前面部分我们已经学习了
vector / list等容器的使用,STL 容器接口设计,高度相似,所以这里我们就不再⼀个接口⼀个接口的介绍,而是直接带着大家看文档,挑比较重要的接口进行介绍。
2.3 set 的构造和迭代器
set 的构造我们关注以下几个接口即可。
set 的迭代器支持正向和反向迭代遍历,遍历默认按升序顺序,因为底层是⼆叉搜索树,迭代器遍历走的中序;
支持迭代器意味着支持范围 for ,set 的 iterator 和 const_iterator 都不支持引用修改数据,修改关键字数据,破坏搜索树的结构。
cpp
// empty (1) ⽆参默认构造
explicit set (const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());
// range (2) 迭代器区间构造
template <class InputIterator>
set (InputIterator first, InputIterator last,
const key_compare& comp = key_compare(),
const allocator_type& = allocator_type());
// copy (3) 拷⻉构造
set (const set& x);
// initializer list (5) initializer 列表构造
set (initializer_list<value_type> il,
const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());
// 迭代器是⼀个双向迭代器
iterator -> a bidirectional iterator to const value_type
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();2.4 set 的增删查
set 的增删查关注以下几个接口即可:
cpp
Member types
key_type -> The first template parameter (T)
value_type -> The first template parameter (T)
// 单个数据插⼊,如果已经存在则插⼊失败
pair<iterator,bool> insert (const value_type& val);
// 列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);
// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert (InputIterator first, InputIterator last);
// 查找val,返回val所在的迭代器,没有找到返回end()
iterator find (const value_type& val);
// 查找val,返回Val的个数
size_type count (const value_type& val) const;
// 删除⼀个迭代器位置的值
iterator erase (const_iterator position);
// 删除val,val不存在返回0,存在返回1
size_type erase (const value_type& val);
// 删除⼀段迭代器区间的值
iterator erase (const_iterator first, const_iterator last);
// 返回⼤于等val位置的迭代器
iterator lower_bound (const value_type& val) const;
// 返回⼤于val位置的迭代器
iterator upper_bound (const value_type& val) const;2.5 insert 和迭代器遍历使用样例:
cpp
#include<iostream>
#include<set>
using namespace std;
int main()
{
// 去重+升序排序
set<int> s;
// 去重+降序排序(给⼀个⼤于的仿函数)
//set<int, greater<int>> s;
s.insert(5);
s.insert(2);
s.insert(7);
s.insert(5);
//set<int>::iterator it = s.begin();
auto it = s.begin();
while (it != s.end())
{
// error C3892: "it": 不能给常量赋值
// *it = 1;
cout << *it << " ";
++it;
}
cout << endl;
// 插⼊⼀段initializer_list列表值,已经存在的值插⼊失败
s.insert({ 2,8,3,9 });
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
set<string> strset = { "sort", "insert", "add" };
// 遍历string⽐较ascll码⼤⼩顺序遍历的
for (auto& e : strset)
{
cout << e << " ";
}
cout << endl;
}2.6 find 和 erase 使用样例:
cpp
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> s = { 4,2,7,2,8,5,9 };
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
// 删除最⼩值
s.erase(s.begin());
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
// 直接删除x
int x;
cin >> x;
int num = s.erase(x);
if (num == 0)
{
cout << x << "不存在!" << endl;
}
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
// 直接查找在利⽤迭代器删除x
cin >> x;
auto pos = s.find(x);
if (pos != s.end())
{
s.erase(pos);
}
else
{
cout << x << "不存在!" << endl;
}
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
// 算法库的查找 O(N)
auto pos1 = find(s.begin(), s.end(), x);
// set⾃⾝实现的查找 O(logN)
auto pos2 = s.find(x);
// 利⽤count间接实现快速查找
cin >> x;
if (s.count(x))
{
cout << x << "在!" << endl;
}
else
{
cout << x << "不存在!" << endl;
}
return 0;
}在展示下面的示例代码之前我们先学习两个 set 中的查找函数 lower_bound 和 upper_bound
cpp
iterator upper_bound (const value_type& val) const; //C++ 98- 核心功能:返回指向第一个不小于
val的元素的迭代器(即 ≥val的第一个元素) - 若所有元素都小于
val:返回end()迭代器(表示不存在满足条件的元素)
cpp
iterator lower_bound (const value_type& val) const; //C++ 98- 核心功能:返回指向第一个大于
val的元素的迭代器 - 若所有元素都小于等于
val:返回end()迭代器
cpp
#include<iostream>
#include<set>
using namespace std;
int main()
{
std::set<int> myset;
for (int i = 1; i < 10; i++)
myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90
for (auto e : myset)
{
cout << e << " ";
}
cout << endl;
// 实现查找到的[itlow,itup)包含[30, 60]区间
// 返回 >= 30
auto itlow = myset.lower_bound(30); //函数返回值为迭代器
// 返回 > 60
auto itup = myset.upper_bound(60);
// 删除这段区间的值
myset.erase(itlow, itup);
for (auto e : myset)
{
cout << e << " ";
}
cout << endl;
return 0;
}2.7 multiset 和 set 的差异
multiset 和 set 的使用基本完全类似,主要区别点在于 multiset 支持值冗余,
那么insert / find / count / erase 都围绕着支持值冗余有所差异,具体参看下面的样例代码理解。
cpp
#include<iostream>
#include<set>
using namespace std;
int main()
{
// 相⽐set不同的是,multiset是排序,但是不去重
multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };
auto it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
// 相⽐set不同的是,x可能会存在多个,find查找中序的第⼀个
int x;
cin >> x;
auto pos = s.find(x);
while (pos != s.end() && *pos == x)
{
cout << *pos << " ";
++pos;
}
cout << endl;
// 相⽐set不同的是,count会返回x的实际个数
cout << s.count(x) << endl;
// 相⽐set不同的是,erase给值时会删除所有的x
s.erase(x);
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
return 0;
}2.8 练习题 LeetCode 349.两个数组的交集
cpp
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> s1(nums1.begin(), nums1.end());
set<int> s2(nums2.begin(), nums2.end());
// 因为set遍历是有序的,有序值,依次⽐较
// ⼩的++,相等的就是交集
vector<int> ret;
auto it1 = s1.begin();
auto it2 = s2.begin();
while(it1 != s1.end() && it2 != s2.end())
{
if(*it1 < *it2)
{
it1++;
}
else if(*it1 > *it2)
{
it2++;
}
else
{
ret.push_back(*it1);
it1++;
it2++;
}
}
return ret;
}
};解析:
在还没有对 set 进行学习之前,这道题的处理思路大致是用元素个数较少的数组,拿出其中的单一元素,去与元素个数较多的数组,
逐一进行比较,元素相等就说明是交集,这样处理会有两个缺点:
- 数组中会出现重复的元素,浪费程序的运行时间
- 时间复杂度为 O(n2) ,过于复杂
在学习 set 后,就可以用 set 解决缺点,对于第一个痛点 ,set 并不允许存储重复的元素,所以就不会出现重复的元素,
对于第二个痛点 ,set 的元素不重复且为升序,所以我们不必再一次次地拿一个元素完全遍历另一个数组,直接从头开始进行比较,
谁小谁往后走,相等时说明为交集,均向后走,这样时间复杂度就被简化为O(n)
2.9 练习题 LeetCode 142.环形链表II
cpp
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
set<ListNode*> s;
ListNode* cur = head;
while(cur)
{
auto ret = s.insert(cur);
if(ret.second == false) //这里的 second 其实是 pair 结构体中的 second 在上文查 insert 函数找具体内容
return cur;
cur = cur->next;
}
return nullptr;
}
};其实这道题我们在之前地文章讲解过一遍:系统性学习数据结构-第二讲-顺序表与链表 其中的第 3.4.9 便是这道题的详细讲解,
但当时还并没有进入 C++ 的阶段,所以是用 C语言 来进行题目的解答的,可以看到为了做出这道题,我们当时进行了大量的论证,
十分的繁琐,但在进入 C++ 阶段后,结合 set 的一些特性,再解答这些题目,可谓是 降维打击 !
我们仅仅是使用了 set 中不允许重复元素插入这一特性,就轻易将这题解出,可以与之前文章中进行讲解长度的篇幅进行对比,
可以看到 STL 的巧妙之处。
3. map 系列的使用
3.1 map 和 multimap 参考文档
链接:map

3.2 map 类的介绍
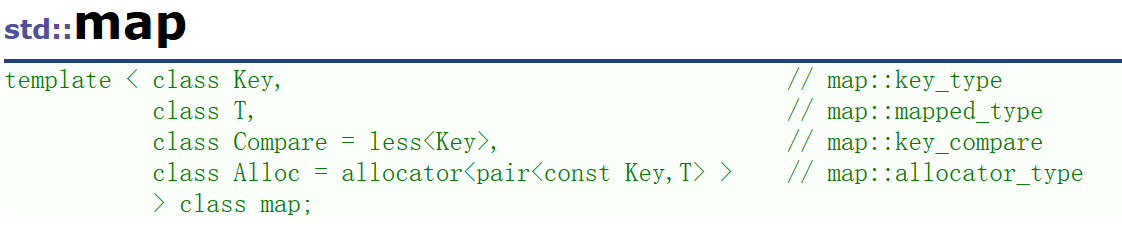
map的声明如上图,Key 就是 map 底层关键字的类型,T 是 map 底层 value 的类型,map 默认要求 Key 支持小于比较,
如果不支持或者需要的话可以自行实现仿函数传给第二个模版参数,map 底层存储数据的内存是从空间配置器申请的。
⼀般情况下,我们都不需要传后两个模版参数。map 底层是用红黑树实现,增删查改效率是 O(logN) ,迭代器遍历是走的中序,
所以是按 Key 有序顺序遍历的。
3.3 pair 类型介绍
map 底层的红⿊树节点中的数据,使⽤ pair<Key, T> 存储键值对数据。
cpp
typedef pair<const Key, T> value_type;
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair(): first(T1()), second(T2())
{}
pair(const T1& a, const T2& b): first(a), second(b)
{}
template<class U, class V>
pair (const pair<U,V>& pr): first(pr.first), second(pr.second)
{}
};
template <class T1,class T2>
inline pair<T1,T2> make_pair (T1 x, T2 y)
{
return ( pair<T1,T2>(x,y) );
}3.4 map 的构造
map 的构造我们关注以下几个接口即可。
map 的迭代器支持正向和反向迭代遍历,遍历默认按 Key 的升序顺序,因为底层是二叉搜索树,迭代器遍历走的中序;
支持迭代器就意味着支持范围 for,map 支持修改 value 数据,不⽀持修改 key 数据,修改关键字数据,破坏了底层搜索树的结构
cpp
// empty (1) ⽆参默认构造
explicit map (const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());
// range (2) 迭代器区间构造
template <class InputIterator>
map (InputIterator first, InputIterator last,
const key_compare& comp = key_compare(),
const allocator_type& = allocator_type());
// copy (3) 拷⻉构造
map (const map& x);
// initializer list (5) initializer 列表构造
map (initializer_list<value_type> il,
const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());
// 迭代器是⼀个双向迭代器
iterator -> a bidirectional iterator to const value_type
// 正向迭代器
iterator begin();
iterator end();
// 反向迭代器
reverse_iterator rbegin();
reverse_iterator rend();3.5 map 的增删查
map 的增删查关注以下几个接口即可:
map 增接口,插入的 pair 键值对数据,跟 set 所有不同,但是查和删的接口只用关键字 key 跟 set 是完全类似的,
不过 find 返回 iterator ,不仅仅可以确认 key 在不在,还找到 key 映射的 value ,同时通过迭代还可以修改 value 。
cpp
Member types
key_type -> The first template parameter (Key)
mapped_type -> The second template parameter (T)
value_type -> pair<const key_type,mapped_type>
// 单个数据插⼊,如果已经key存在则插⼊失败,key存在相等value不相等也会插⼊失败
pair<iterator,bool> insert (const value_type& val);
// 列表插⼊,已经在容器中存在的值不会插⼊
void insert (initializer_list<value_type> il);
// 迭代器区间插⼊,已经在容器中存在的值不会插⼊
template <class InputIterator>
void insert (InputIterator first, InputIterator last);
// 查找k,返回k所在的迭代器,没有找到返回end()
iterator find (const key_type& k);
// 查找k,返回k的个数
size_type count (const key_type& k) const;
// 删除⼀个迭代器位置的值
iterator erase (const_iterator position);
// 删除k,k存在返回0,存在返回1
size_type erase (const key_type& k);
// 删除⼀段迭代器区间的值
iterator erase (const_iterator first, const_iterator last);
// 返回⼤于等k位置的迭代器
iterator lower_bound (const key_type& k);
// 返回⼤于k位置的迭代器
const_iterator lower_bound (const key_type& k) const;3.6 map 的数据修改
前面我提到 map 支持修改 mapped_type 数据,不支持修改 key 数据,修改关键字数据,破坏了底层搜索树的结构。
map 第一个支持修改的方式是通过迭代器,迭代器遍历时或者 find 返回 key 所在的 iterator 修改,
map 还有一个非常重要的修改接口 operator[],但是 operator[] 不仅仅支持修改,还支持插入数据和查找数据,
所以他是一个多功能复合接口需要注意从内部实现角度,map 这里把我们传统说的 value 值,给的是 T类型,typedef 为 mapped_type
⽽ value_type 是红黑树结点中存储的 pair 键值对值。日常使用我们还是习惯将这⾥的 T 映射值叫做 value 。
cpp
Member types
key_type -> The first template parameter (Key)
mapped_type -> The second template parameter (T)
value_type -> pair<const key_type,mapped_type>
// 查找k,返回k所在的迭代器,没有找到返回end(),如果找到了通过iterator可以修改key对应的mapped_type值
iterator find (const key_type& k);由于 map 中的一些函数机制比较复杂,所以需要详细讲解一下
3.6.1 insert 函数
cpp
pair<iterator,bool> insert (const value_type& val)这里对于有能力的同学,我们放一下关于返回值的英文描述,可以先自行理解一下

关于调用 insert 插入一个 pair<key, T> 对象,会出现两种情况:
- 如果
key已经在map中,插入失败,则返回⼀个pair<iterator,bool>对象,返回pair对象first是key所在结点的迭代器,second是false - 如果
key不在在map中,插入成功,则返回⼀个pair<iterator,bool>对象,返回pair对象first是新插入key所在结点的迭代器,second是true
也就是说无论插入成功还是失败,返回 pair<iterator,bool> 对象的 first 都会指向 key 所在的迭代器
那么也就意味着 insert 插入失败时充当了查找的功能,正是因为这一点,insert 可以用来实现 operator[]
❗:需要注意的是这⾥有两个
pair,不要混淆了,⼀个是map底层红⿊树节点中存的pair<key, T>,另 ⼀个是insert返回值pair<iterator,bool>
3.6.2 operator 重载
cpp
mapped_type& operator[] (const key_type& k);
// operator的内部实现
mapped_type& operator[] (const key_type& k)
{
pair<iterator, bool> ret = insert({ k, mapped_type() });
iterator it = ret.first;
return it->second;
}在讲解完 insert 函数后,我们解释道函数的一些特性十分适合用来实现 operator[] ,这便是结构的不同造就了 map 独特的优势,
调用完 insert 函数后,一共会出现两种情况:
-
如果
k不在map中,insert会插⼊k和mapped_type默认值,同时[]返回结点中存储mapped_type值的引用,那么我们可以通过引用修改返映射值。所以[]具备了 插入 + 修改 功能 -
如果
k在map中,insert会插⼊失败,但是insert返回pair对象的first是指向key结点的迭代器,返回值同时[]返回结点中存储mapped_type值的引用,所以[]具备了 查找 + 修改 的功能
3.7 构造遍历及增删查使用样例
cpp
#include<iostream>
#include<map>
using namespace std;
int main()
{
// initializer_list构造及迭代遍历
map<string, string> dict = { {"left", "左边"}, {"right", "右边"},
{"insert", "插⼊"},{ "string", "字符串" } };
//map<string, string>::iterator it = dict.begin();
auto it = dict.begin();
while (it != dict.end())
{
//cout << (*it).first <<":"<<(*it).second << endl;
// map的迭代基本都使⽤operator->,这⾥省略了⼀个->
// 第⼀个->是迭代器运算符重载,返回pair*,第⼆个箭头是结构指针解引⽤取pair数据
//cout << it.operator->()->first << ":" << it.operator->()->second << endl;
cout << it->first << ":" << it->second << endl;
++it;
}
cout << endl;
// insert插⼊pair对象的4种⽅式,对⽐之下,最后⼀种最⽅便
pair<string, string> kv1("first", "第⼀个");
dict.insert(kv1);
dict.insert(pair<string, string>("second", "第⼆个"));
dict.insert(make_pair("sort", "排序"));
dict.insert({ "auto", "⾃动的" });
// "left"已经存在,插⼊失败
dict.insert({ "left", "左边,剩余" });
// 范围for遍历
for (const auto& e : dict)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
string str;
while (cin >> str)
{
auto ret = dict.find(str);
if (ret != dict.end())
{
cout << "->" << ret->second << endl;
}
else
{
cout << "⽆此单词,请重新输⼊" << endl;
}
}
// erase等接⼝跟set完全类似,这⾥就不演⽰讲解了
return 0;
}3.8 map 的迭代器和 功能样例:
样例一:
cpp
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{
// 利⽤find和iterator修改功能,统计⽔果出现的次数
string arr[] = { "苹果", "西⽠", "苹果", "西⽠", "苹果", "苹果", "西⽠",
"苹果", "⾹蕉", "苹果", "⾹蕉" };
map<string, int> countMap;
for (const auto& str : arr)
{
// 先查找⽔果在不在map中
// 1、不在,说明⽔果第⼀次出现,则插⼊{⽔果, 1}
// 2、在,则查找到的节点中⽔果对应的次数++
auto ret = countMap.find(str);
if (ret == countMap.end())
{
countMap.insert({ str, 1 });
}
else
{
ret->second++;
}
}
for (const auto& e : countMap)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
return 0;
}样例二:
cpp
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{
// 利⽤[]插⼊+修改功能,巧妙实现统计⽔果出现的次数
string arr[] = { "苹果", "西⽠", "苹果", "西⽠", "苹果", "苹果", "西⽠",
"苹果", "⾹蕉", "苹果", "⾹蕉" };
map<string, int> countMap;
for (const auto& str : arr)
{
// []先查找⽔果在不在map中
// 1、不在,说明⽔果第⼀次出现,则插⼊{⽔果, 0},同时返回次数的引⽤,++⼀下就变成1次了
// 2、在,则返回⽔果对应的次数++
countMap[str]++;
}
for (const auto& e : countMap)
{
cout << e.first << ":" << e.second << endl;
}
cout << endl;
return 0;
}样例三:
cpp
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{
map<string, string> dict;
dict.insert(make_pair("sort", "排序"));
// key不存在->插⼊ {"insert", string()}
dict["insert"];
// 插⼊+修改
dict["left"] = "左边";
// 修改
dict["left"] = "左边、剩余";
// key存在->查找
cout << dict["left"] << endl;
return 0;
}3.9 multimap 和 map 的差异
multimap 和 map 的使用基本完全类似,主要区别点在于 multimap ⽀持关键值 key 冗余,
那么insert/find/count/erase 都围绕着支持关键值 key 冗余有所差异,这⾥跟 set 和 multiset 完全一样,
比如 find 时,有多个 key,返回中序第一个。其次就是 multimap 不⽀持 [] ,因为⽀持 key冗余, [] 就只能支持插入了,
不⽀持修改。
3.10 练习题 LeetCode 138. 随机链表的复制
数据结构初阶阶段,为了控制随机指针,我们将拷贝结点链接在原节点的后⾯解决,后⾯拷贝节点还得解下来链接,⾮常⿇烦。
这里我们直接让 {原结点,拷贝结点} 建⽴映射关系放到 map 中,控制随机指针会⾮常简单⽅便,
这⾥体现了 map 在解决⼀些问题时的价值,完全是降维打击。
cpp
class Solution {
public:
Node* copyRandomList(Node* head) {
map<Node*, Node*> nodeMap;
Node* copyhead = nullptr,*copytail = nullptr;
Node* cur = head;
while(cur)
{
if(copytail == nullptr)
{
copyhead = copytail = new Node(cur->val);
}
else
{
copytail->next = new Node(cur->val);
copytail = copytail->next;
}
// 原节点和拷⻉节点map kv存储
nodeMap[cur] = copytail;
cur = cur->next;
}
// 处理random
cur = head;
Node* copy = copyhead;
while(cur)
{
if(cur->random == nullptr)
{
copy->random = nullptr;
}
else
{
copy->random = nodeMap[cur->random];
}
cur = cur->next;
copy = copy->next;
}
return copyhead;
}
};解析:
在这道题中我们使用 map 容器,<key ,value> 中 key 结构映射原结点,value 映射拷贝结点,这样对原链表进行遍历一次,
我们就能生成全部的拷贝结点,那么下面的难点就来到了如何处理拷贝结点的 random 指针上,对于指向空指针的情况,要进行特殊处理
将拷贝结点的 random 设置为空指针,对于其他的情况,我们利用 map 中 [] 返回 <key, value> 中 value 的特点,
我们将 cur->random 输入进去查找,返回的就是我们创建的对于 random 结点的拷贝结点,也就是 value 此时直接进行链接即可,
可以看到这道题巧妙运用了 map 容器的特性,简化了思路,这道题的难度相对于数据结构初期来说,下降很多。
3.10 LeetCode 692. 前K个高频单词
本题目我们利用 map 统计出次数以后,返回的答案应该按单词出现频率由高到低排序,
有⼀个特殊要求,如果不同的单词有相同出现频率,按字典顺序排序。
解决思路 1 :
用排序找前 k 个单词,因为 map 中已经对 key 单词排序过,也就意味着遍历 map 时,次数相同的单词,字典序小的在前面,
字典序大的在后面。那么我们将数据放到 vector 中用一个稳定的排序就可以实现上面特殊要求,但是 sort 底层是快排,是不稳定的,
所以我们要用 stable_sort ,他是稳定的。
cpp
class Solution {
public:
struct Compare
{
bool operator()(const pair<string, int>& x, const pair<string, int>& y) const
{
return x.second > y.second;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string, int> countMap;
for(auto& e : words)
{
countMap[e]++;
}
vector<pair<string, int>> v(countMap.begin(), countMap.end());
// 仿函数控制降序
stable_sort(v.begin(), v.end(), Compare());
//sort(v.begin(), v.end(), Compare());
// 取前k个
vector<string> strV;
for(int i = 0; i < k; ++i)
{
strV.push_back(v[i].first);
}
return strV;
}
};解决思路 2 :
将 map 统计出的次数的数据放到 vector 中排序,或者放到 priority_queue 中来选出前 k 个。利用仿函数强行控制次数相等的,
字典序小的在前面。
cpp
class Solution {
public:
struct Compare
{
bool operator()(const pair<string, int>& x, const pair<string, int>& y) const
{
return x.second > y.second || (x.second == y.second && x.first < y.first);;
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string, int> countMap;
for(auto& e : words)
{
countMap[e]++;
}
vector<pair<string, int>> v(countMap.begin(), countMap.end());
// 仿函数控制降序,仿函数控制次数相等,字典序⼩的在前⾯
sort(v.begin(), v.end(), Compare());
// 取前k个
vector<string> strV;
for(int i = 0; i < k; ++i)
{
strV.push_back(v[i].first);
}
return strV;
}
};