目录
[(二)Token ID:模型世界中的"身份证"](#(二)Token ID:模型世界中的“身份证”)
[(一)预测"下一个 Token"](#(一)预测“下一个 Token”)
[1. 模型规模与性能](#1. 模型规模与性能)
[2. 开源与生态规模](#2. 开源与生态规模)
[1. 政务与城市治理](#1. 政务与城市治理)
[2. 制造与工业数据智能](#2. 制造与工业数据智能)
[3. 科学研究与专业 AI 专家系统](#3. 科学研究与专业 AI 专家系统)
[4. 文化创意与视觉生成(通义万相)](#4. 文化创意与视觉生成(通义万相))
[1. 平台定位](#1. 平台定位)
[2. 核心功能](#2. 核心功能)
[3. 平台优势](#3. 平台优势)
[4. 核心应用场景示例](#4. 核心应用场景示例)
干货分享,感谢您的阅读!
近年来,大语言模型(Large Language Model,LLM)成为人工智能领域最具影响力的技术之一。从智能问答、代码生成,到多模态创作与行业应用,大模型正在以极高的效率重塑人类与计算机的交互方式。
本文将从大模型的基本工作原理出发,系统介绍其核心机制,并进一步结合阿里云通义大模型体系,探讨大模型在真实业务场景中的应用与价值。
一、大模型是如何"理解"和"回答"的?
在与大模型交互时,用户只需要输入自然语言文本,这段文本在技术上被称为**提示词(Prompt)。**提示词越清晰、结构越合理,模型生成的结果就越接近用户预期。
从内部机制来看,大模型对提示词的处理流程可以抽象为两个核心阶段:
-
分词化与词表映射(Tokenization & Vocabulary Mapping)
-
基于概率的自回归文本生成(Autoregressive Generation)
二、分词化(Tokenization)与词表映射
(一)什么是分词化?
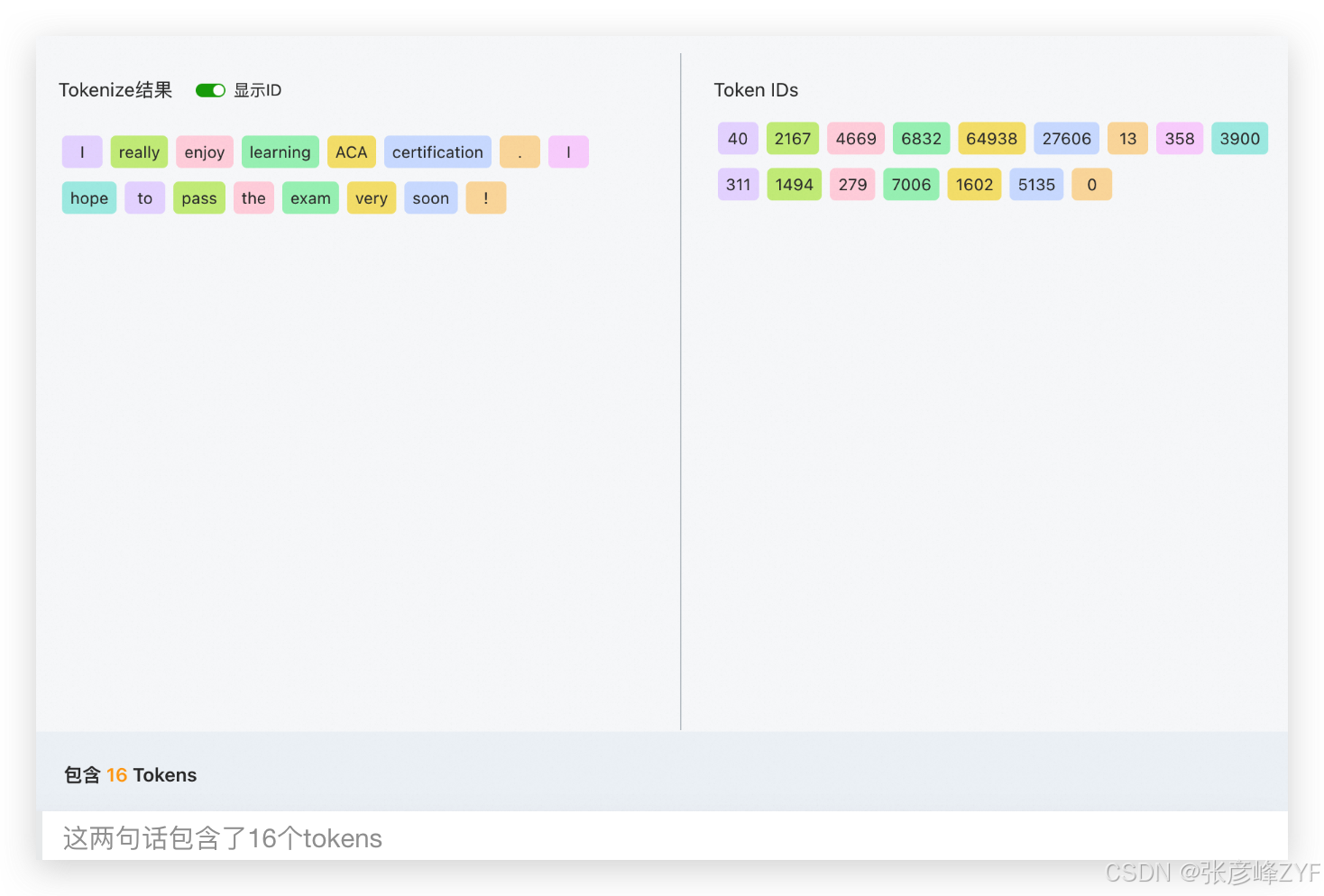
分词化(Tokenization)是自然语言处理(NLP)中的基础步骤,其目标是将一段连续的文本拆分为更小、可计算的基本单元------Token。
以一个简单的英文句子为例:
I want to study ACA.
经过分词化处理后,模型看到的并不是字符串本身,而是类似如下的序列:
['I', 'want', 'to', 'study', 'ACA', '.']
通过将句子拆解为独立单元,模型可以更清晰地分析词语之间的语义关系、语法结构以及上下文依赖。这种处理方式对于长上下文建模尤为关键。
在实际工程中,分词并不只局限于"按单词切分",而是存在多种粒度策略,例如:
-
按词切分(Word-level)
-
按子词切分(Subword,如 BPE、WordPiece)
-
按字符切分(Character-level)
现代大模型通常采用子词级别的分词策略,在表达能力与词表规模之间取得更优平衡。
(二)Token ID:模型世界中的"身份证"
分词完成后,每一个 token 都会通过预先定义好的词表(Vocabulary),映射为一个唯一的整数编号,即 Token ID。
从模型视角来看:
-
文本 ≠ 字符串
-
文本 = Token ID 序列
最终,一句话会被表示为一个整数数组,作为神经网络可直接处理的输入形式。
三、大语言模型生成文本的核心机制
(一)预测"下一个 Token"
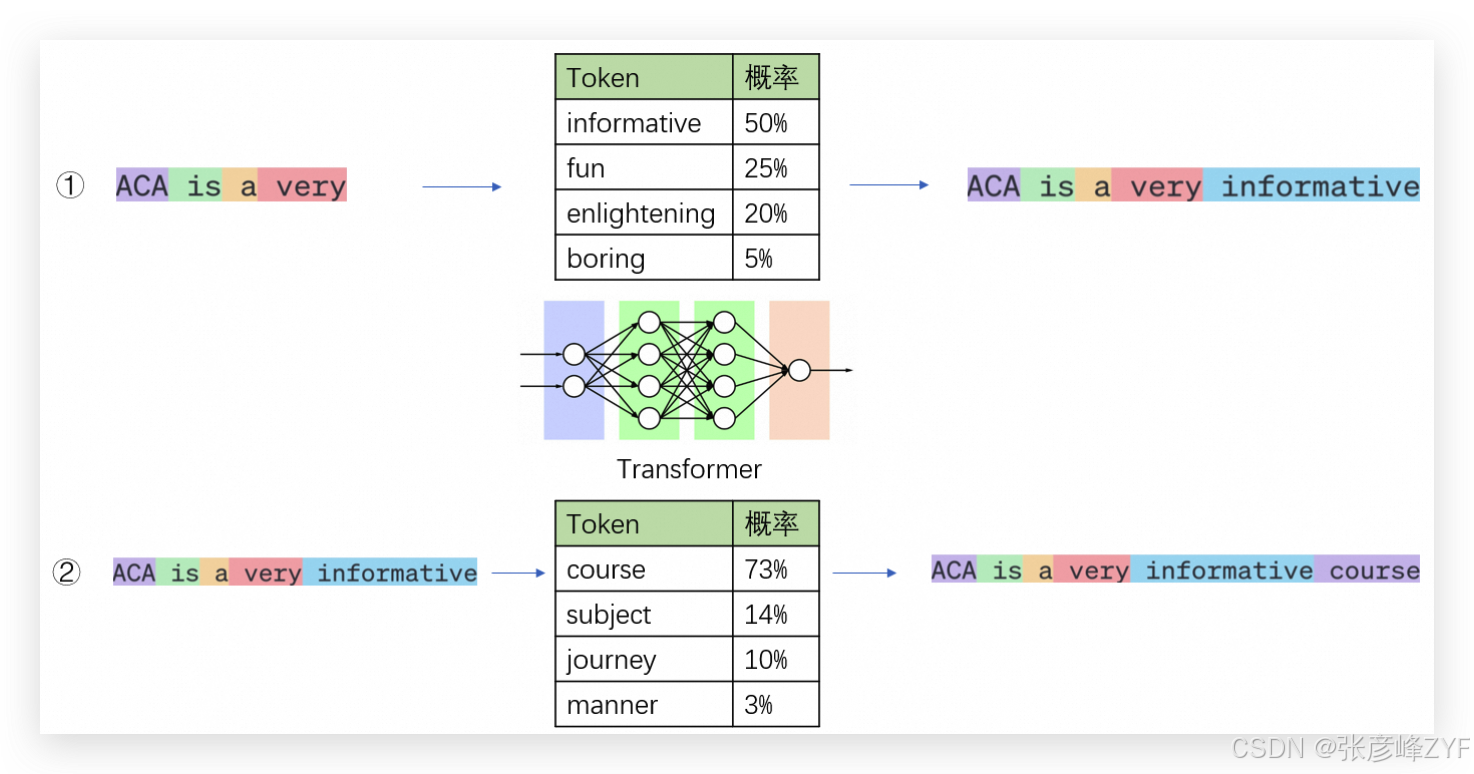
从本质上讲,大语言模型并不是"理解问题后直接给出答案",而是完成一个看似简单却极其强大的任务:
在给定已有 Token 序列的条件下,预测下一个最可能出现的 Token。
这意味着,当我们向模型提问时,模型实际上是在不断进行"续写"。
(二)自回归(Autoregressive)生成过程
大模型的推理并非一次性完成,而是一个逐步展开的自回归过程:
-
基于当前输入 Token 序列,计算下一个 Token 的概率分布;
-
按一定策略(如最大概率或采样)选出下一个 Token;
-
将新 Token 拼接到输入序列末尾;
-
重复上述过程,直到满足终止条件。
终止条件通常包括:
-
生成了特殊结束标记(如
<EOS>,End of Sentence) -
达到预设的最大输出长度
例如,当用户提问:
阿里云成立于什么时间?

模型并不是"一次性输出答案",而是逐字(逐 token)生成完整回复,这种机制正是大模型能够进行长文本推理和上下文关联的基础。
四、大模型的应用:以阿里云通义体系为例
阿里巴巴推出的通义大模型体系,是一套覆盖多领域、多场景的人工智能模型家族,服务范围已扩展至 200+ 应用场景,涵盖:
-
金融
-
法律
-
医疗
-
科研
-
教育
-
企业办公与个人效率工具
"通情,达义"不仅是产品理念,也体现了通义大模型在语义理解与实际应用之间的深度融合。
在技术策略上,阿里云坚持开放与共享,将核心模型能力向开发者开放,并通过平台化方式降低大模型应用门槛。
(一)阿里云通义大语言模型核心能力
1. 模型规模与性能
通义千问不断迭代,目前已发布包括 Qwen2.5 等多个版本,最大规模超过 1100亿参数 的基础模型已开源,性能在多项任务较上一代显著提升。Qwen2.5 在理解、逻辑推理、指令遵循和代码生成等能力分别提升约 9%--19%。证券时报
2. 开源与生态规模
-
通义系列模型已开源 200+ 个模型,包括多尺寸大模型与多模态版本,全球下载量累计超 3--4亿次。搜狐+1
-
Qwen衍生模型数量超过 10万 ,表达社区开发活跃且生态规模巨大。ue.aliyun.com
这些数据说明通义千问不仅参数规模大,而且实测能力具备全球竞争力,支撑多场景高质量推理与生成需求。
(二)通义系列的典型应用示例(行业落地效果)
1. 政务与城市治理
数字政府智能体服务
-
在重庆数字治理体系中,基于通义千问构建的智能分析系统,实现跨部门协同方案生成、关键事件智能分类与多维度预案输出;对突发事件预案派送精准度提升约 40%。ue.aliyun.com
-
政务智能助手"渝小智"实现约 86.6% 的问题自动解决率,在数千类业务中提供**一站式"边聊边办"**体验。ue.aliyun.com
这些体现了通义大模型在政务"一体化智能体"中的实用性,能提升政务服务效率与公众满意度。
2. 制造与工业数据智能
产业智能体与研产供销协同
-
一汽集团发布基于通义大模型的企业级智能体 OpenMind,在产业数据分析和业务决策链路中,实现运营效率提升 100% 、决策效率提升 10倍 。ue.aliyun.com
-
国家电网多模态智能体分析设备图像、调度日志和气象数据,有效提升清洁能源消纳效率 18% ,客服场景准确率超过 95% 。ue.aliyun.com
这些指标表明,在工业和能源场景中通义大模型可以加速从数据感知到决策闭环的转化。
3. 科学研究与专业 AI 专家系统
科研领域大模型应用
-
国家天文台等科研机构基于通义大模型构建专业"科学智能体",用于太阳耀斑预测准确率达到 95% 以上。ue.aliyun.com
-
中科院相关大模型实现径流预测准确率约 98% ,接近领域内领先水平。ue.aliyun.com
这类案例显示,通义大模型能在特定科研任务中提供近专业水平的数据理解和结果输出。
4. 文化创意与视觉生成(通义万相)
文生图 & 图像/视频创作
- 通义万相及其升级版本可进行 文生图 / 图生图 / 图生视频 创作,并已在多个文化项目中落地,例如个性化邮票等文化产品生成。电商派
该类应用证明了大模型在视觉创作领域的商业化与消费级落地潜力。
(三)百炼大模型服务平台
百炼平台就是一个"企业版大模型工具箱",提供模型调用、训练、定制和应用构建的全套解决方案,让企业能快速把大模型能力变成可用业务功能。

1. 平台定位
阿里云打造的企业级大模型开发与应用平台,面向:
-
企业开发者
-
个人开发者
-
ISV合作伙伴
-
目标:让用户无需从零训练模型,也能快速调用、训练、定制和部署大模型应用。
2. 核心功能
| 功能模块 | 主要内容 | 价值与优势 |
|---|---|---|
| 模型调用 | 调用通义系列大模型及第三方模型 API | 标准化接口快速集成,企业无需从零训练即可使用大模型能力 |
| 模型训练与微调 | 在自有数据上微调模型,实现个性化能力 | 支持企业定制,提升模型对业务场景的理解和预测准确性 |
| 应用构建 | 提供插件、模板与开发套件,支持文案生成、客服对话、代码辅助等场景 | 快速构建定制化应用,缩短开发周期,提高落地效率 |
| 数据与安全 | 支持私有数据安全接入,保障模型训练与推理过程的数据隐私与合规性 | 企业数据安全有保障,满足行业合规要求 |
| 多模态支持 | 支持文本、图像、视频等多种数据类型 | 扩展业务应用场景,实现智能内容生成与分析 |
| 开放生态 | 对接丰富第三方模型与插件 | 提供更多功能扩展选项,助力企业构建多样化智能应用 |
3. 平台优势
-
开发效率高:无需从零构建大模型,快速实现应用落地
-
支持多模态:文本、图像、视频等多种数据类型
-
开放生态:对接丰富第三方模型和插件
-
企业专属定制:结合企业自身业务数据,实现智能化升级
4. 核心应用场景示例
-
智能客服(文档问答、多轮对话)
-
内容生成(文案、报告、营销素材)
-
代码辅助(生成、优化、测试)
-
数据分析与图表解读
五、通义大模型核心产品介绍
(一)通义千问(Qwen)
通义千问是阿里云自研的超大规模语言模型,在以下能力上表现突出:
-
复杂指令理解
-
文学与内容创作
-
数学与逻辑推理
-
代码理解与生成
-
多语言、多模态能力(文本 + 图像)
在实际使用中,通义千问可结合搜索能力,动态获取外部知识,提升回答的准确性和时效性。
典型应用包括:
-
实时天气查询
-
复杂图表解读(结合 VL 多模态模型)
-
长文档分析与总结
你可以直接访问通义官网或百炼平台来体验通义千问大模型。通义千问是阿里巴巴超大规模语言模型,能帮你写文案、代码,解答问题,提升工作效率,满足个性化创作需求,甚至还能与你进行趣味互动。
查询感兴趣的内容
庆余年具体讲的是什么?有哪些主要人物?具体结局是什么??(访问模型体验,在模型配置中开启搜索能力)
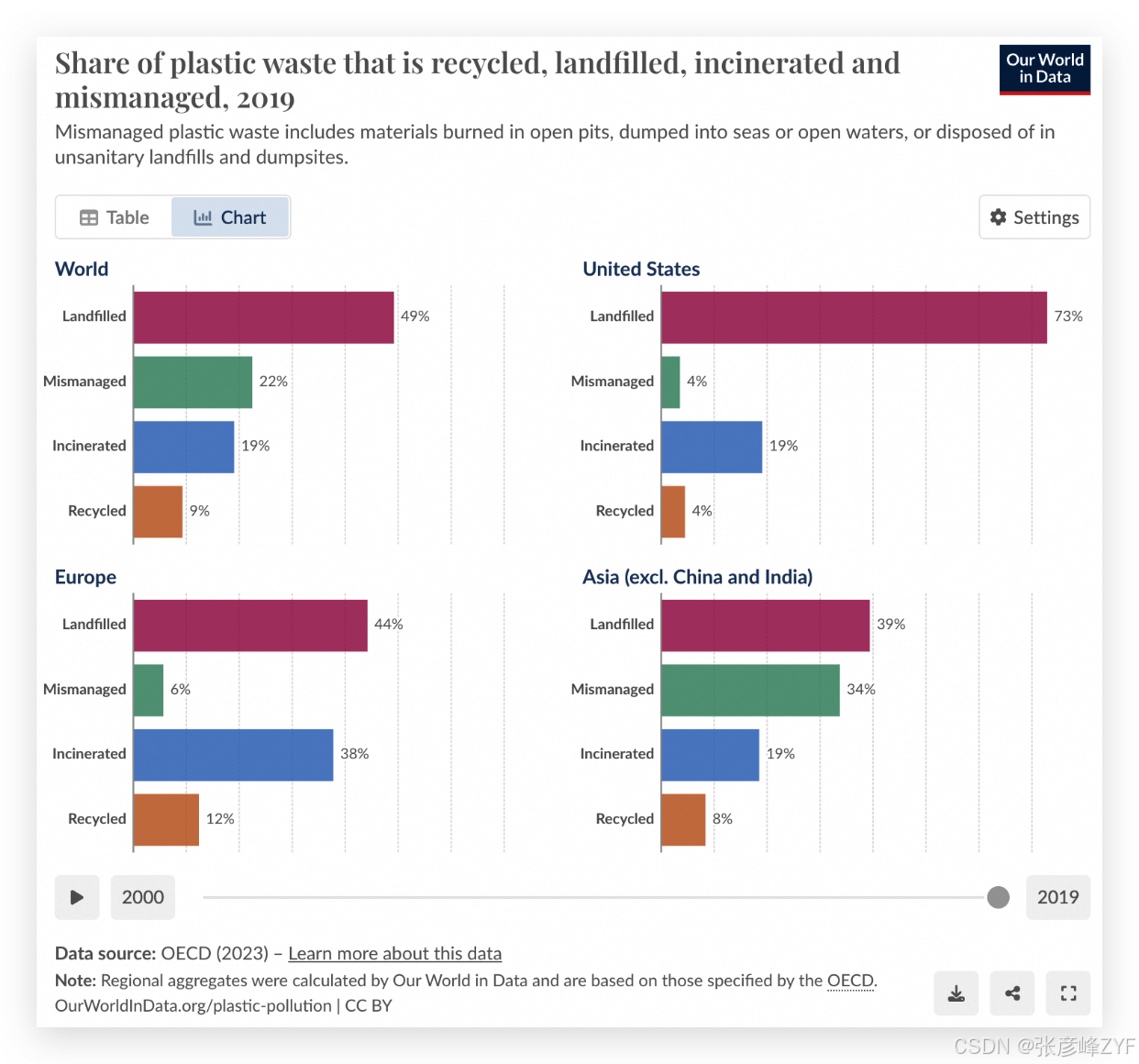
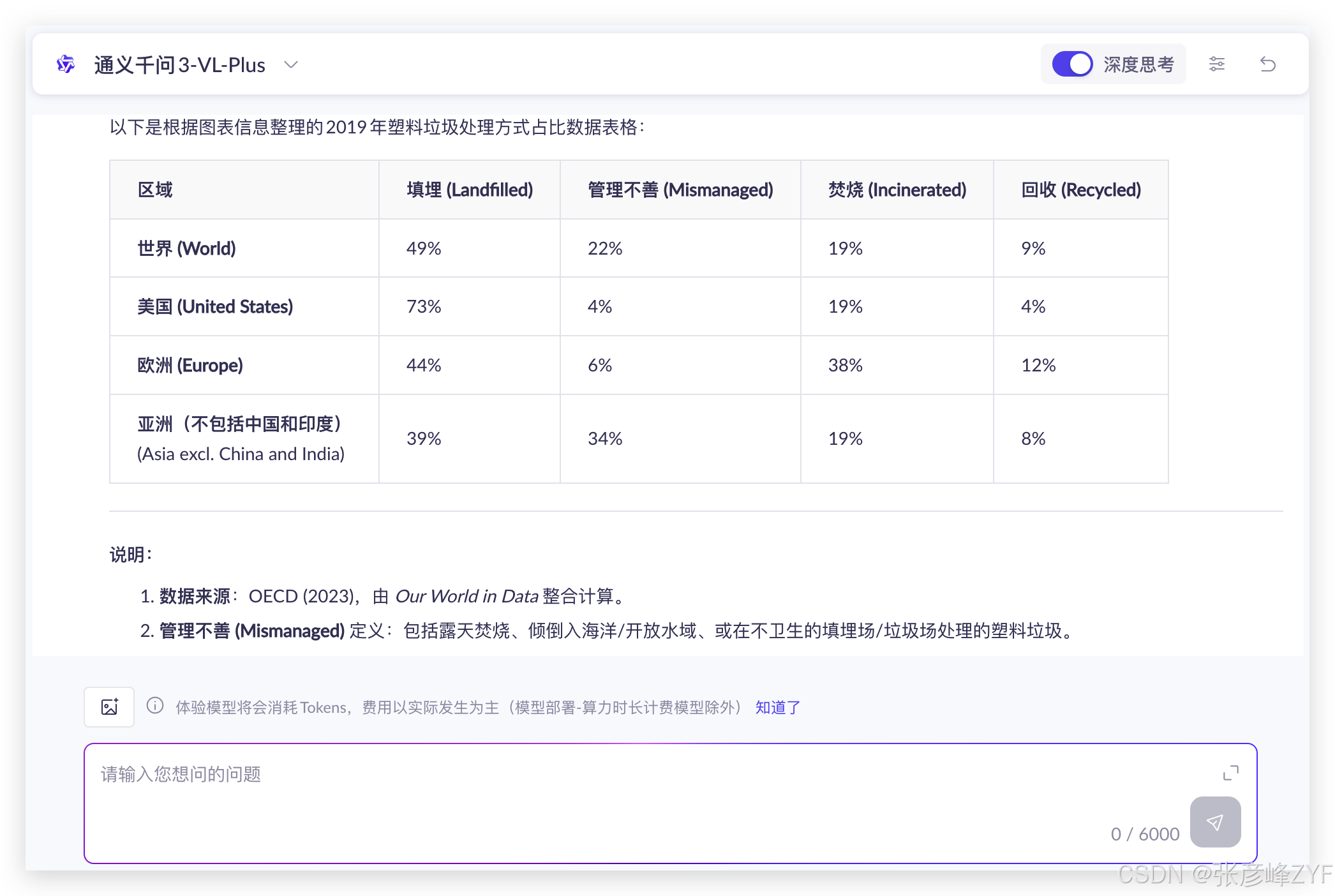
解读复杂图表
分析图中信息,并制作表格(图表解读需要使用通义千问VL模型,先上传图片后提问)
图表来源:https://ourworldindata.org/grapher/share-plastic-fate
上传图片后,让大模型分析图表内容并制作数据表格。
(二)通义万相
通义万相是阿里云的多模态生成模型,专注于图像与视频创作,支持:
-
文生图
-
图生图
-
图生视频
-
虚拟模特
-
个性化写真
它为创意设计、内容生产和商业营销提供了极高的生产效率。
通过文本描述生成图像
新版通义万相文生图模型提升了语义理解能力,文字生成能力更强,适合创意设计场景,同时生成的图像质量更高。
提示词="生成一张新年祝福贺卡,背景有白雪,放鞭炮的小孩,蛇形成文案2025,并写上HAPPY NEW YEAR。"

人像风格重绘
通义万相可以将输入的人物图像进行多种风格化的重绘生成,使新生成的图像在兼顾原始人物相貌的同时,带来不同风格的绘画效果。

通过图片生成视频
通义万相可以将输入图片作为视频首帧,再根据提示词生成视频。视频呈现丰富的艺术风格及影视级画质。
输入提示词:生成一段介绍通义万象的视频
输入照片:

六、通义模型的行业级应用
在基础模型之上,阿里云构建了一系列面向具体业务的应用型产品:
(一)通义灵码
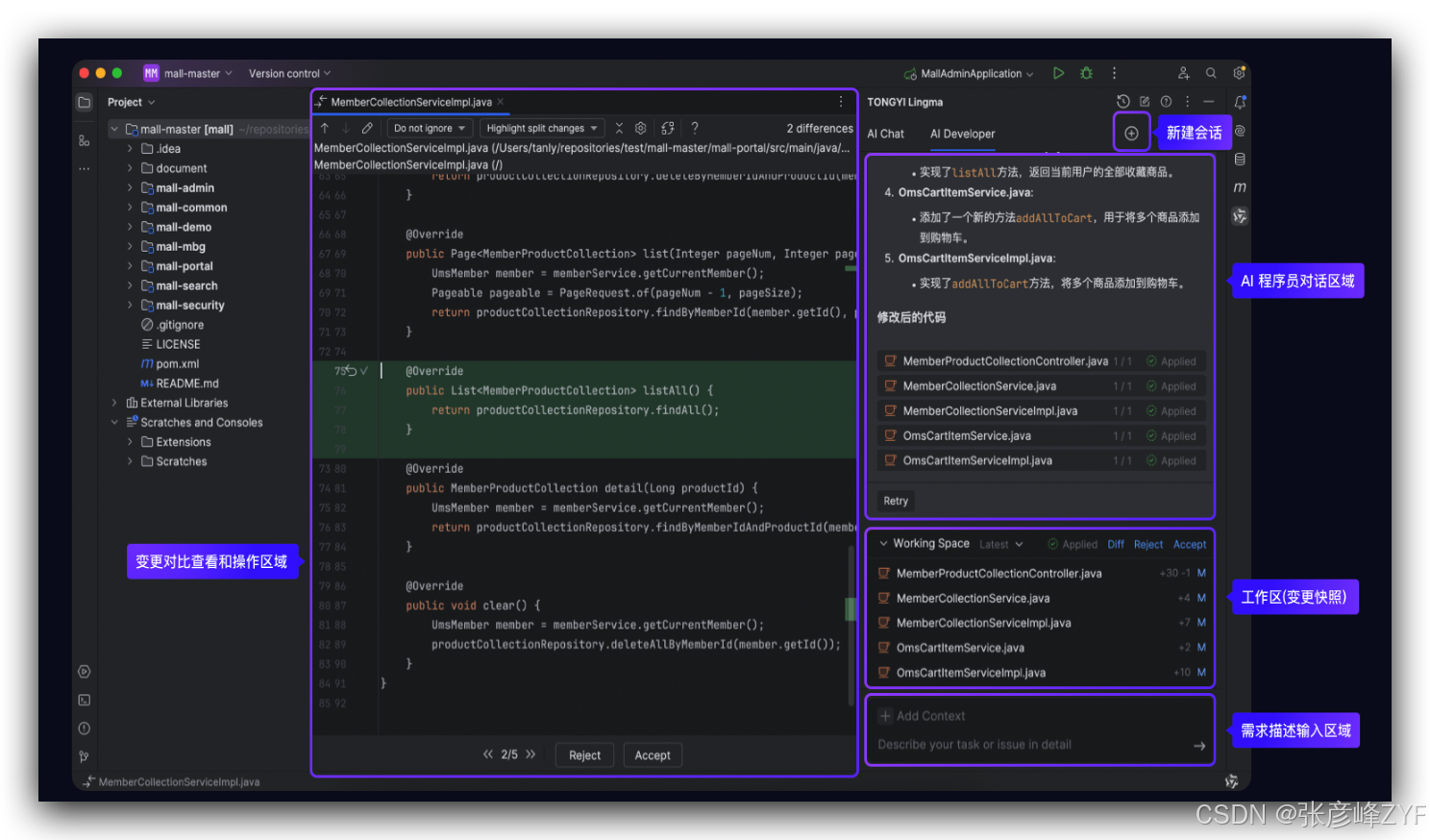
面向开发者的智能编程助手,可直接集成到代码编辑器中,支持:
-
代码生成与补全
-
代码解释
-
性能优化建议
-
单元测试生成
(二)通义听悟
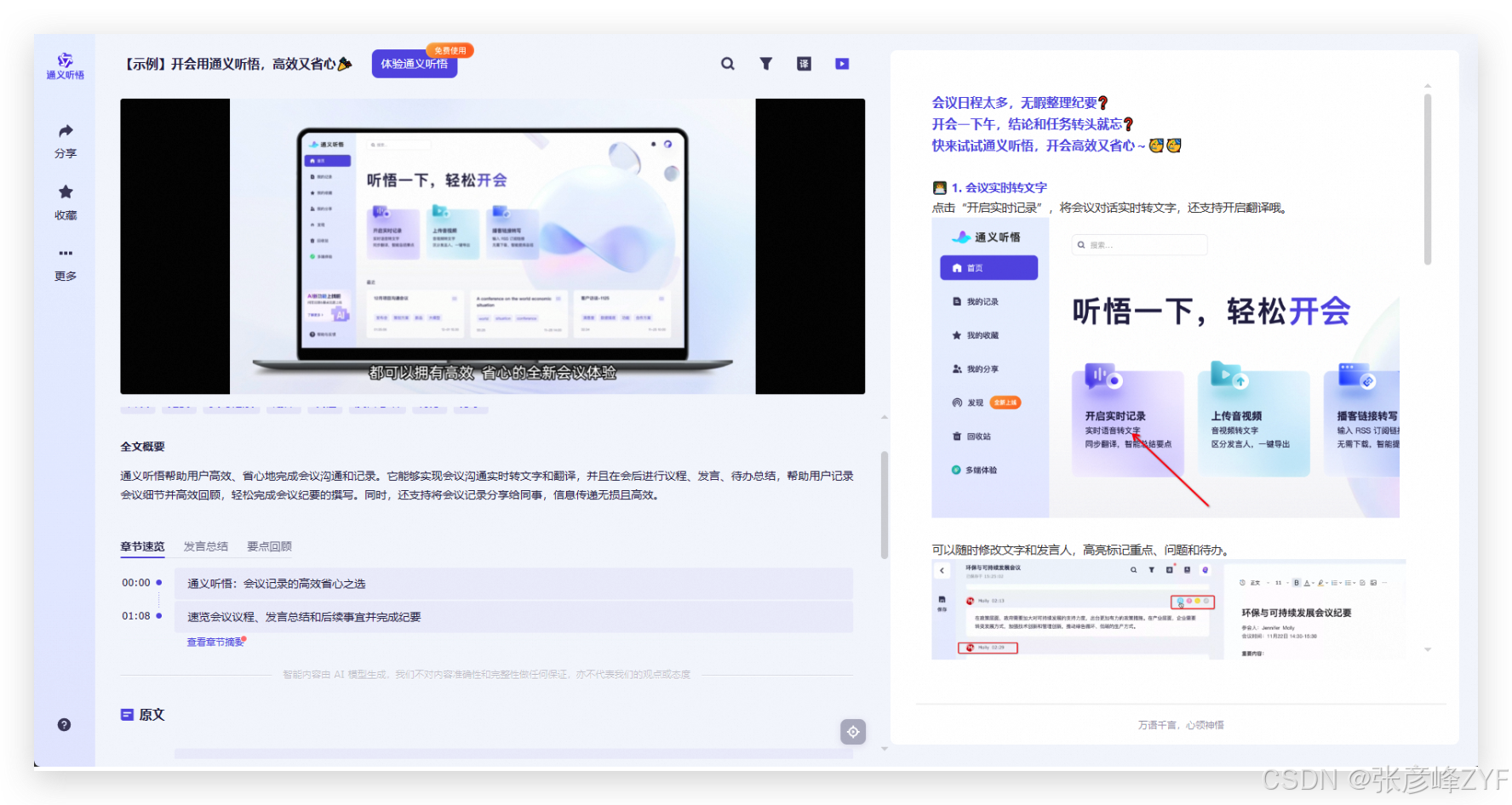
基于语音识别与大模型理解能力的智能听写工具,适用于:
-
会议记录
-
采访整理
-
同声传译
-
视频字幕生成
(三)通义法睿
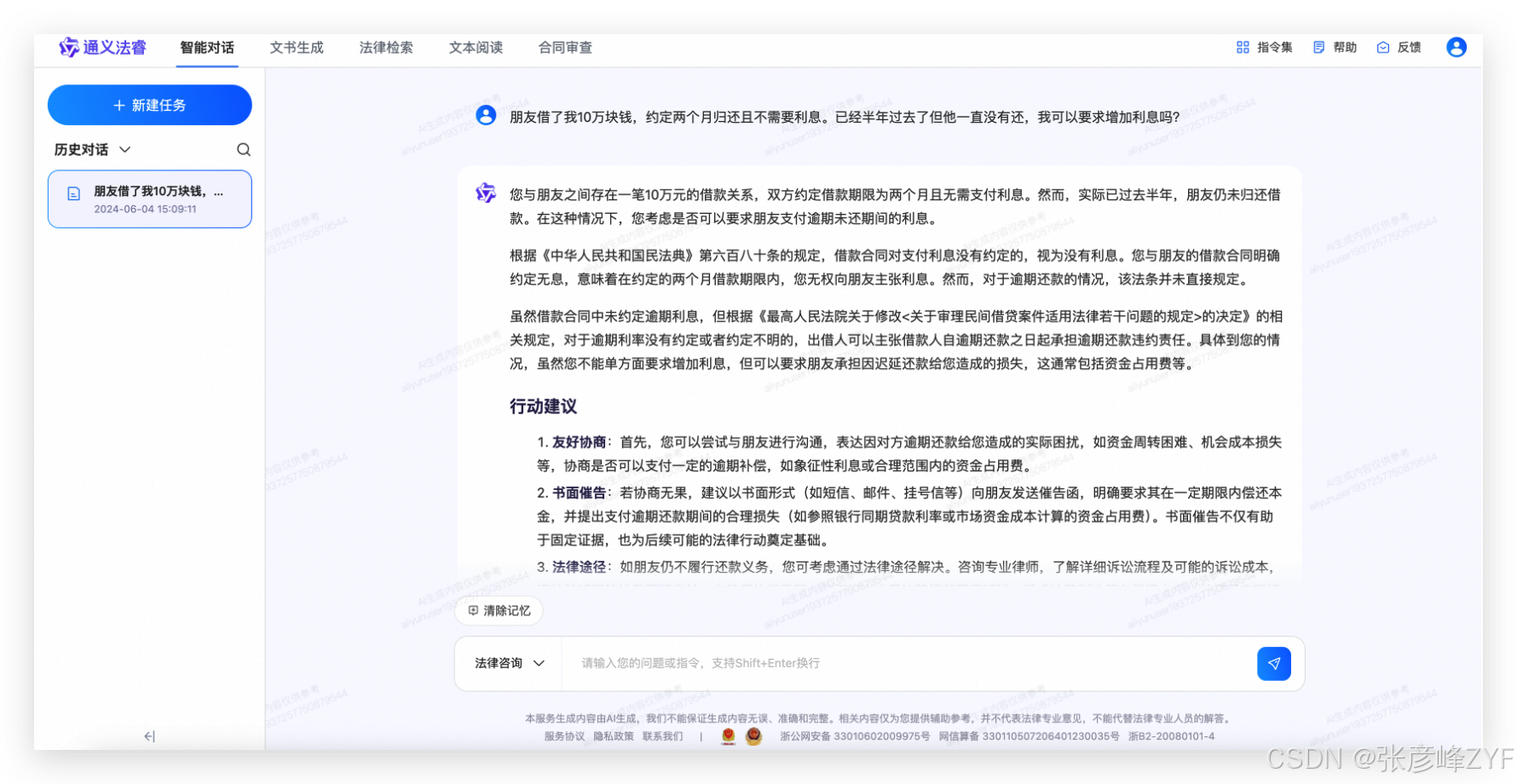
专注法律领域的智能助手,提供:
-
合同审查
-
法律咨询
-
法条定位
-
法律文书撰写
-
案情分析
(四)通义晓蜜
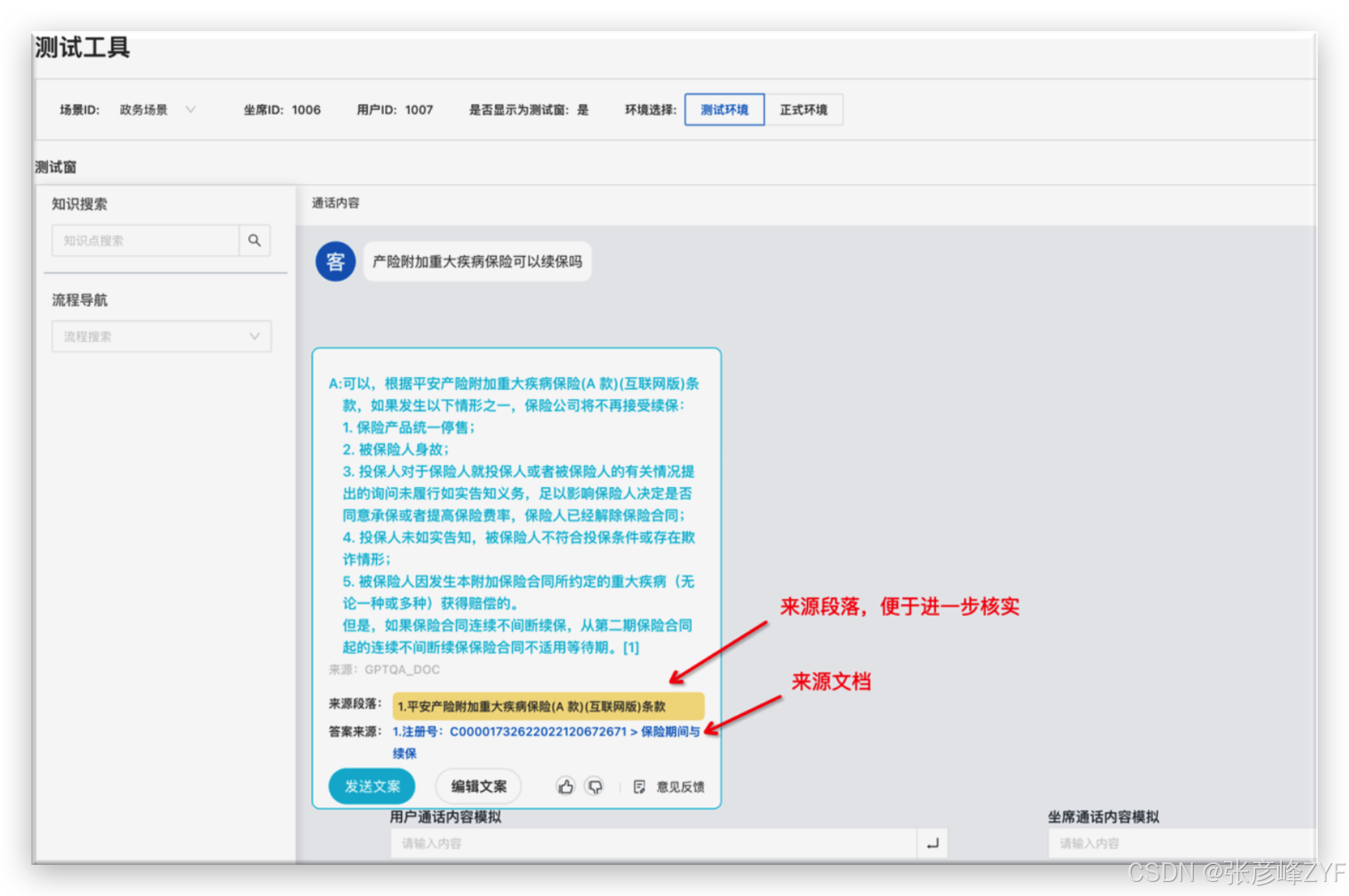
企业级智能客服解决方案,支持:
-
7×24 小时多轮对话
-
文档问答
-
坐席辅助与答案溯源
-
降低人工客服成本
此外,通义产品矩阵还包括通义效率、通义点金、通义星尘等,覆盖个人与企业的多样化需求。
七、结语
从分词化到自回归生成,从通用模型到行业应用,大模型正在逐步完成从"技术突破"到"规模化落地"的转变。
以通义大模型体系为代表的实践表明,大模型的真正价值,不在于参数规模本身,而在于与真实业务场景的深度融合。
随着平台化能力和开发工具的不断成熟,大模型将不再是少数技术专家的专属能力,而会成为每一位开发者、每一家企业的基础设施。
参考资料与延伸阅读
-
阿里云通义大模型官网:https://tongyi.aliyun.com
-
通义千问(Qwen)开源项目:https://github.com/QwenLM
-
阿里云百炼大模型服务平台:https://www.aliyun.com/product/bailian
-
Transformer 原始论文《Attention Is All You Need》
-
《Deep Learning》(Ian Goodfellow et al.)