此文仅供对深度学习感兴趣且0基础的同学了解。
2025 年,当 GPT - 6 能自动生成电影剧本,自动驾驶汽车在城市中穿梭时,你是否好奇这些黑科技背后的核心技术?答案就藏在深度学习这四个字里。这个让机器"学会学习"的技术,正在悄然改变我们生活的方方面面。今天,我们就用最通俗的语言,带你揭开深度学习的神秘面纱,从人工规则的局限到神经网络的智慧,一步步走进这个令人着迷的AI世界。
什么是深度学习
一句话理解深度学习
深度学习,简单来说,就是让计算机通过多层神经网络,像人类大脑一样从数据中自动学习规律和模式的技术。它不需要我们手动编写复杂的规则,而是通过大量的数据训练,让机器自己"悟"出解决问题的方法。
比如,给它看成千上万张猫的图片,它就能学会识别"这是不是猫";让它听海量的语音数据,它就能把声音转换成文字;用历史的股票数据训练它,它还能尝试预测未来的趋势。
从"人工规则"到"自动学习"的革命
在深度学习出现之前,传统的人工智能主要依靠人工设计规则。就像我们教电脑识别猫,可能会列出一系列特征:如果有胡须 + 两个尖耳朵 + 毛茸茸的尾巴 → 可能是猫。但这种方法有很大的局限性,规则复杂且容易出错。现实中的猫千奇百怪,有些猫没有尾巴,有些猫耳朵不尖,这时候规则就失效了。
而深度学习则完全不同,它不依赖人工规则。我们只需要给它提供大量的猫和非猫的图片作为训练数据,然后告诉它哪些是猫,哪些不是。机器会通过神经网络自动分析这些图片的特征,比如毛色、眼睛形状、轮廓等,最终形成自己的判断标准。
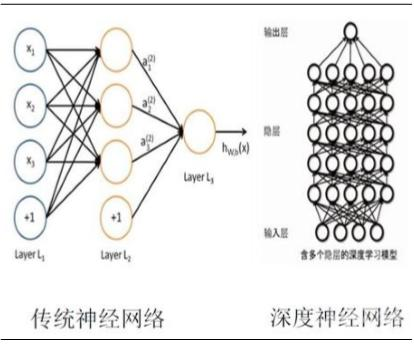
这张图清晰地展示了传统神经网络和深度神经网络的区别。左侧的传统神经网络层数较少,而右侧的深度神经网络则有多个隐藏层,能够学习更复杂的特征。
神经网络是什么
模仿人脑的简化模型
神经网络的灵感来源于我们人类的大脑。人脑中有数十亿个神经元相互连接,形成复杂的网络。人工神经网络就是对这种结构的简化模拟。
在人脑中,神经元接收来自其他神经元的信号,经过处理后再传递给下一个神经元。人工神经元也做类似的事情:接收输入信号,进行加权求和,然后通过激活函数处理,最后输出结果。
单个神经元的数学表达
单个神经元的工作原理可以用一个简单的数学公式来表示:
y = f(w1x1 + w2x2 + ... + wnxn + b)
其中:
-
x1, x2, ..., xn:输入信号(比如图片的像素值、声音的波形等)
-
w1, w2, ..., wn:权重(表示每个输入信号的重要程度)
-
b:偏置(调整神经元的输出,使其更灵活)
-
f():激活函数(对求和结果进行非线性变换,增加网络的表达能力)
-
y:神经元的输出
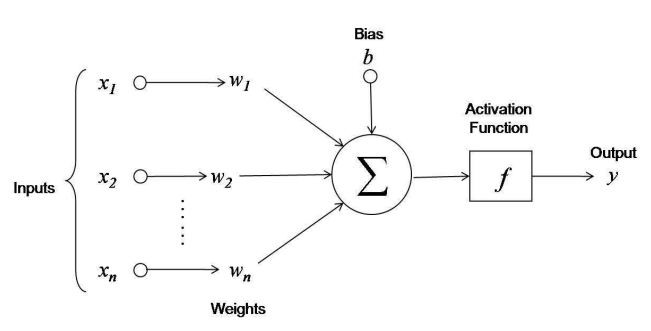
这张图展示了单个神经元的工作流程:输入信号经过权重加权,与偏置相加,然后通过激活函数处理,最后输出结果。
神经网络的结构
神经网络通常由三层组成:输入层 、隐藏层 和输出层。
-
输入层:接收原始数据,比如一张图片的像素值会作为输入层的神经元。
-
隐藏层 :位于输入层和输出层之间,负责提取和学习数据的特征。深度学习之所以"深",就是因为它有多个隐藏层,能够逐层提取更抽象、更高级的特征。
-
输出层:给出最终的结果,比如识别图片时,输出层的神经元会对应不同的类别。
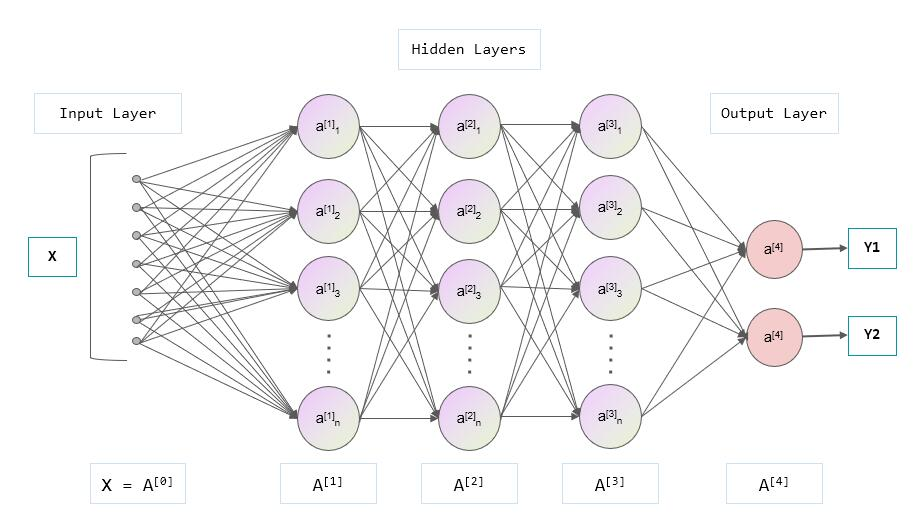
这张图展示了一个包含输入层、三个隐藏层和输出层的神经网络结构。数据从输入层进入,经过多层隐藏层的处理,最后从输出层输出结果。
模型是如何"学会"的
学习 = 调整参数(权重和偏置)
神经网络一开始并不知道如何解决问题,它的权重和偏置都是随机初始化的,输出结果可能很离谱。学习的过程就是不断调整这些参数,让输出结果越来越接近正确答案。
想象一下,你教一个小孩认识苹果。一开始他可能会把西红柿也当成苹果,但你告诉他"不对,这是西红柿"。通过不断的纠正和反馈,他逐渐掌握了苹果的特征,就能准确地区分苹果和其他水果了。神经网络的学习过程也是类似的。
用损失函数衡量"错得多不多"
那么,我们如何知道模型错了多少呢?这就需要损失函数(Loss Function)。损失函数就像一个"裁判",它计算模型的预测输出与真实答案之间的差距。差距越大,损失值就越大;差距越小,损失值就越小。
常见的损失函数有:
-
均方误差(MSE):常用于回归问题,计算预测值与真实值之差的平方的平均值。
-
交叉熵(Cross Entropy):常用于分类问题,衡量两个概率分布之间的差异。
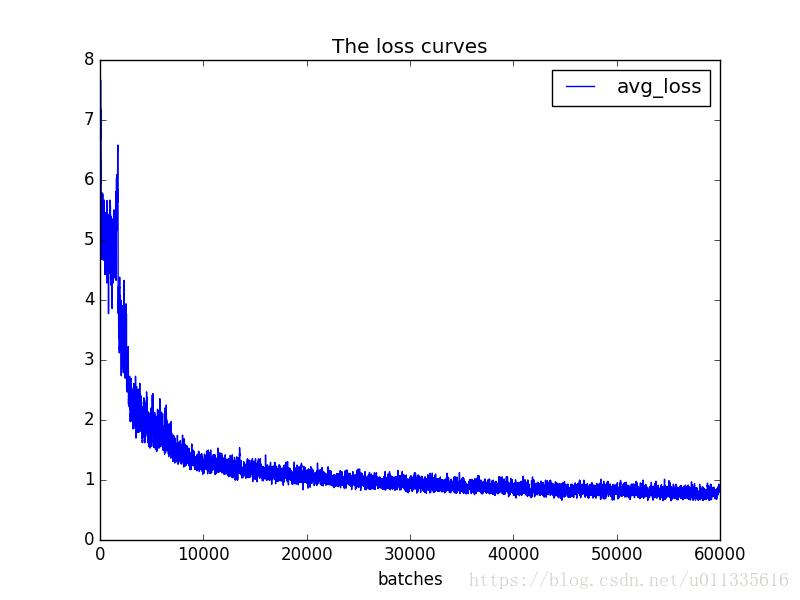
这张图展示了损失函数随着训练批次增加的变化趋势。可以看到,在训练初期,损失值下降得很快,说明模型在快速学习;随着训练的进行,损失值逐渐趋于稳定,表明模型已经接近收敛,学习到了数据中的规律。
模型训练的目标就是最小化损失函数。通过一种叫做"反向传播"的算法,我们可以计算出每个参数对损失值的影响,然后按照一定的规则调整参数,使损失值不断减小。这个过程就像我们在下山,每一步都朝着坡度最陡的方向前进,直到到达山脚(损失值最小)。
深度学习的应用与未来
深度学习已经在很多领域取得了惊人的成就:
-
计算机视觉:图像识别、人脸识别、目标检测、自动驾驶等。
-
自然语言处理:机器翻译、语音识别、文本生成、情感分析等。
-
医疗健康:疾病诊断、药物研发、医学影像分析等。
-
金融:股票预测、风险评估、欺诈检测等。
随着技术的不断发展,深度学习的应用范围还在不断扩大。未来,我们可能会看到更多令人惊叹的AI应用,比如个性化的教育、智能的城市管理、精准的环境保护等。
当然,深度学习也面临一些挑战,比如数据隐私、算法偏见、可解释性差等问题。但相信随着研究的深入和技术的进步,这些问题会逐步得到解决。