🎬 胖咕噜的稞达鸭 :个人主页
🔥 个人专栏 : 《数据结构》《C++初阶高阶》
《Linux系统学习》
《算法日记》
⛺️技术的杠杆,撬动整个世界!

本文的思维导图梳理:
手搓一个简化版的 FILE 结构体
这三种刷新策略决定了数据何时从内存缓冲区写入实际文件:
NONE_FLUSH(无缓冲) :- 数据直接写入文件,不经过缓冲区
- 适用于错误输出、即时日志等需要立即显示的场景
- 类似
stderr的行为
LINE_FLUSH(行缓冲) :- 遇到换行符
\n时刷新缓冲区 - 适用于交互式终端输出(如
stdout到终端时) - 提供即时的用户反馈
- 遇到换行符
FULL_FLUSH(全缓冲) :- 缓冲区满了才刷新
- 适用于文件I/O,提高效率
- 减少系统调用次数
cpp
#pragma once
#include <stdio.h>
#define MAX 1024//固定的缓冲区大小
#define NONE_FLUSH (1<<0)
#define LINE_FLUSH (1<<1)
#define FULL_FLUSH (1<<2)
typedef struct IO_FILE
{
int fileno;//文件描述符;
int flag;//打开文件的方式;
char outbuffer[MAX];
int bufferlen;//buffer内部的有效元素
int flush_method;
}MyFile;
MyFile *MyFopen(const char* path,const char* mode);
void MyFclose(MyFile *);
int MyFwrite(MyFile *,void *str,int len);
void MyFFlush(MyFile *);
cpp
#include "mystdio.h"
#include <sys/types.h> //提供系统数据类型定义
#include <sys/stat.h>
#include <fcntl.h>//提供文件控制选项(如O_CREAT, O_WRONLY等)
#include <string.h>
#include <stdlib.h>
#include <unistd.h> //提供系统调用(write, fsync等)
static MyFile *BuyFile(int fd,int flag)
{
MyFile *f =(MyFile*) malloc(sizeof(MyFile));
if(f == NULL) return NULL;
f->bufferlen = 0; // 初始化缓冲区长度为0(当前没有数据)
f->fileno = fd; // 设置文件描述符(open()返回的值)
f->flag = flag; // 设置打开文件的标志(O_WRONLY, O_CREAT等)
f->flush_method =LINE_FLUSH; // 设置刷新方式为行缓冲(遇到\n就刷新)
memset(f->outbuffer,0,sizeof(f->outbuffer)); // 将输出缓冲区全部清0
return f;
}
MyFile *MyFopen(const char* path,const char* mode)
{
int fd = -1; // 文件描述符,初始为-1表示无效
int flag = 0; // 打开文件的标志
// 如果模式是"w"(写模式)
if(strcmp(mode,"w") == 0)
{
// 设置标志:创建文件、只写、清空文件内容
int flag = O_CREAT | O_WRONLY | O_TRUNC;
// 打开文件,0666是文件权限(rw-rw-rw-)
fd = open(path,flag,0666);
}
// 如果模式是"a"(追加模式)
else if(strcmp(mode,"a")== 0)
{
// 设置标志:创建文件、只写、追加模式
int flag = O_CREAT | O_WRONLY | O_APPEND;
fd = open(path,flag,0666);
}
else if(strcmp(mode,"r")==0)
{
int flag = O_CREAT | O_WRONLY | O_APPEND;
fd = open(path,flag,0666);
}
// 正确的r模式(读模式)
else if(strcmp(mode,"r")==0)
{
int flag = O_RDWR; // 可读可写
fd = open(path,flag);
}
// 其他未实现的模式
else
{
//TODO // 待完成
}
// 如果打开文件失败(fd < 0),返回NULL
if(fd<0)return NULL;
// 调用BuyFile创建MyFile结构体
return BuyFile(fd,flag);
}
void MyFclose(MyFile *)
{}
int MyFwrite(MyFile *file,void *str,int len)
{
//1.拷贝
memcpy(file->outbuffer+file->bufferlen,str,len);
file->bufferlen += len;
//2.尝试判断是否满足刷新条件
if((file->flush_method & LINE_FLUSH) && file->outbuffer[file->bufferlen-1] == '\n')
{
MyFFlush(file);
}
return 0;
}
void MyFFlush(MyFile *file)
{
if(file->bufferlen <= 0)return;
//把数据从用户拷贝到内核文件缓冲区中
int n = write(file->fileno,file->outbuffer,file->bufferlen);
(void)n;
fsync(file->fileno);
file->bufferlen = 0;
}C语言中提供给用户的文件只有头文件,用户层面只有拿到头文件,
打得开文件:MyFile * filep = MyFopen(//以追加形式打开文件,最后要关闭*
缓冲区存在的意义:减少系统调用次数,如果我们自己在写代码的时候没有写"\n",只要代码写完之后用MyFFlush(),强制刷新,将数据从用户拷贝到文件的内核缓冲区中;
fsync:将文件中内核层面保存到存储设备(外设)上;
通过文件描述符将数据写到文件缓冲区中,最后通过sync将数据缓冲到文外设中。
Ext系列文件系统
我们每一次要打开文件,都是默认成功了的,但是没打开成功的呢?没有打开成功的文件在什么地方?有米有很好奇?
文件由内容 与属性两部分构成。已打开的文件通常暂存于内存中供系统直接处理,而未打开的文件则长期存储在磁盘等外部存储设备内。
磁盘的存储原理依赖于其表面的磁性材料------它由许多微小的磁颗粒(可视为"小磁铁")组成,每个颗粒具有南极和北极两种磁化方向。在写入数据时,通过改变电压来控制这些磁颗粒的磁极方向,以此表示二进制信息(例如用北极代表"0",南极代表"1"),从而实现不同文件的存储。
若需彻底销毁磁盘中的数据,可通过高温加热等方式破坏其磁性结构,使磁颗粒退磁,原有信息便无法恢复。
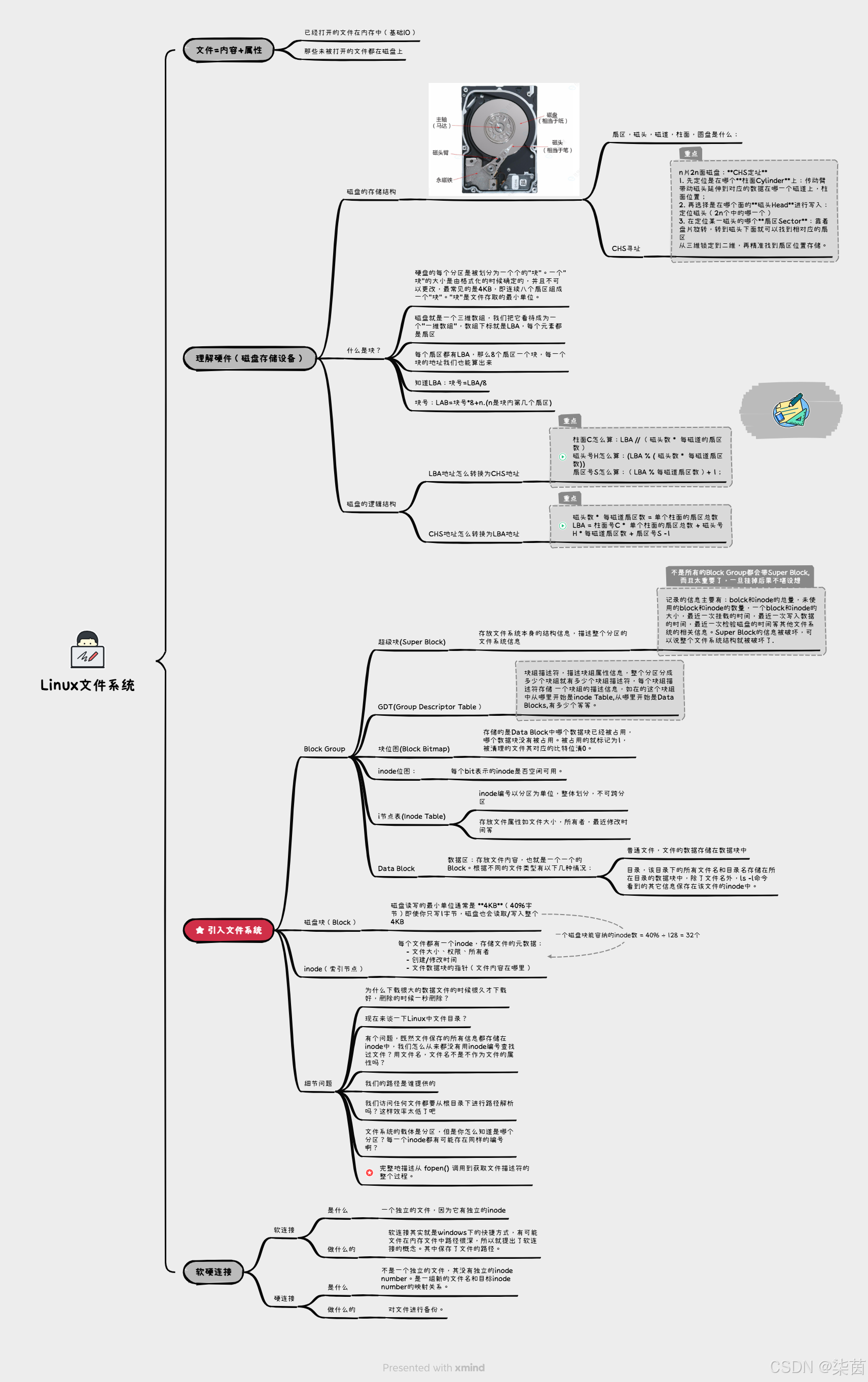
磁盘的物理结构:
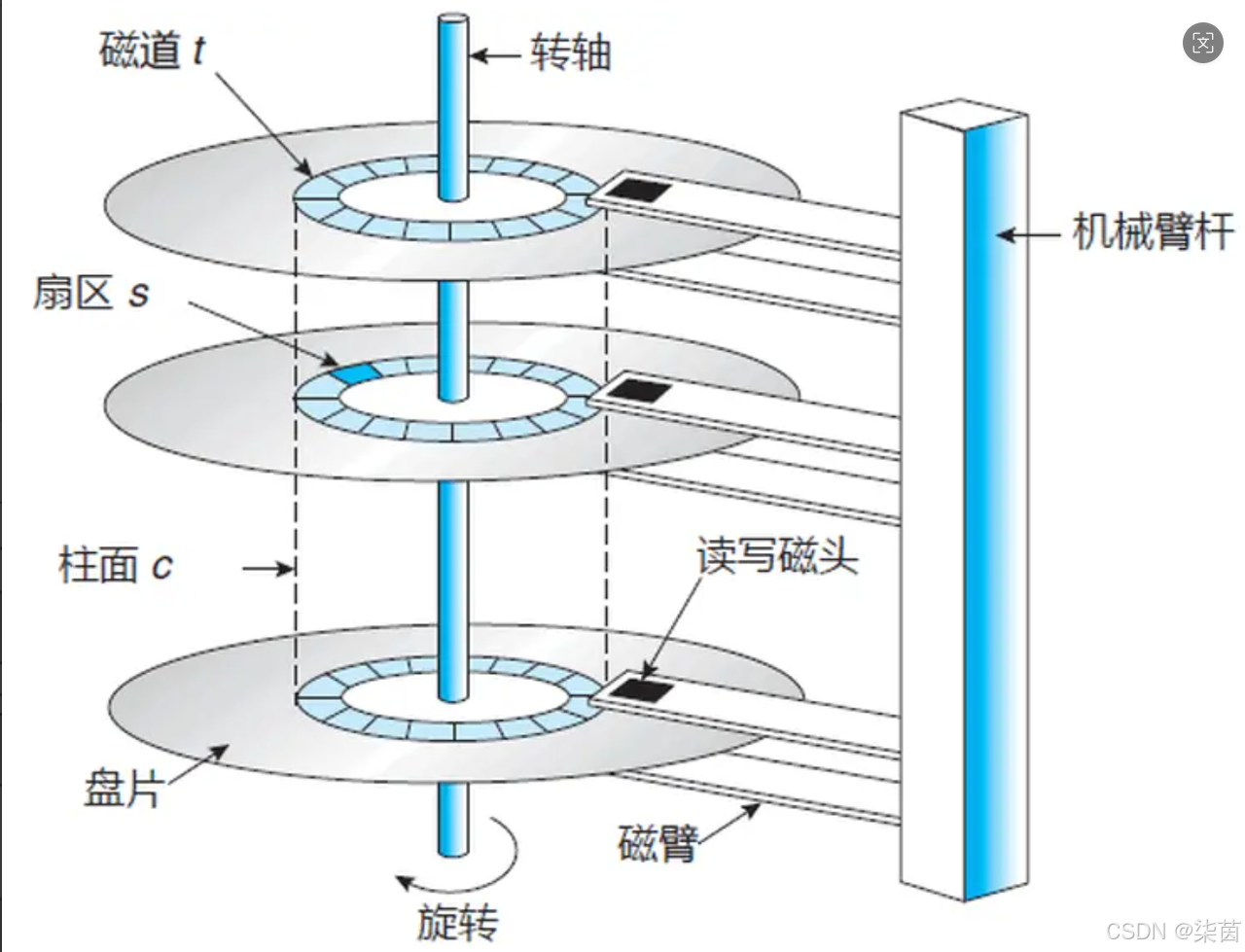
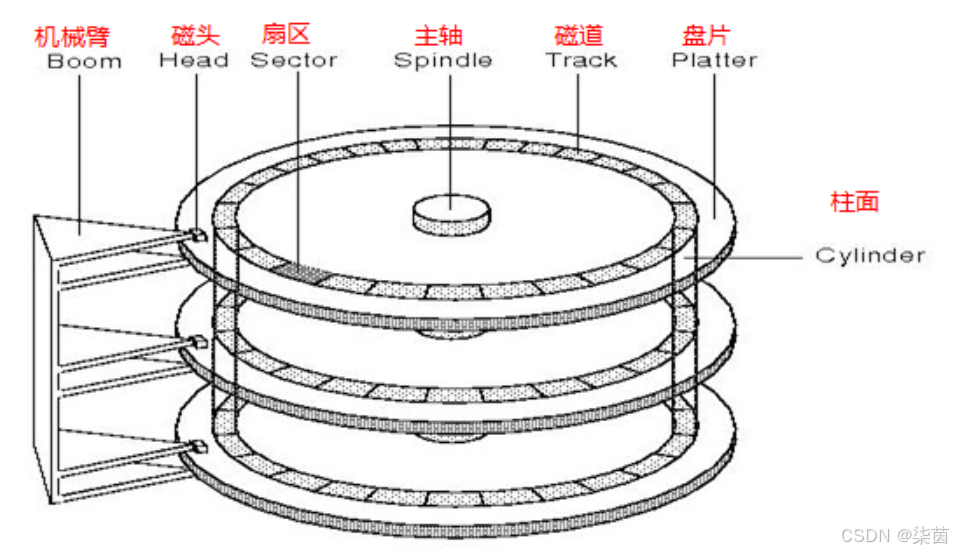
磁盘存储的基本单位 :扇区,512字节,块设备。(数据就在扇区中存储)
有几片就有几个磁头,(3片6面共有6个磁头)盘片在快速旋转的时候,磁头也在快速来回摆动。磁头在摆动的时候就是在确认是在哪个磁道上的,磁头在转动的情况下跟传动壁共进退)
磁盘写入的时候是向柱面进行批量写入的。
问题:512个字节,写到某一个扇区中,磁盘应该如何运动?
n片2n面磁盘:CHS定址
- 先定位是在哪个柱面Cylinder上:传动臂带动磁头延伸到对应的数据在哪一个磁道上,柱面位置;
- 再选择是在哪个面的磁头Head进行写入:定位磁头(2n个中的哪一个)
- 在定位某一磁头的哪个扇区Sector :靠着盘片旋转,转到磁头下面就可以找到相对应的扇区
从三维锁定到二维,再精准找到扇区位置存储。
磁盘的逻辑结构
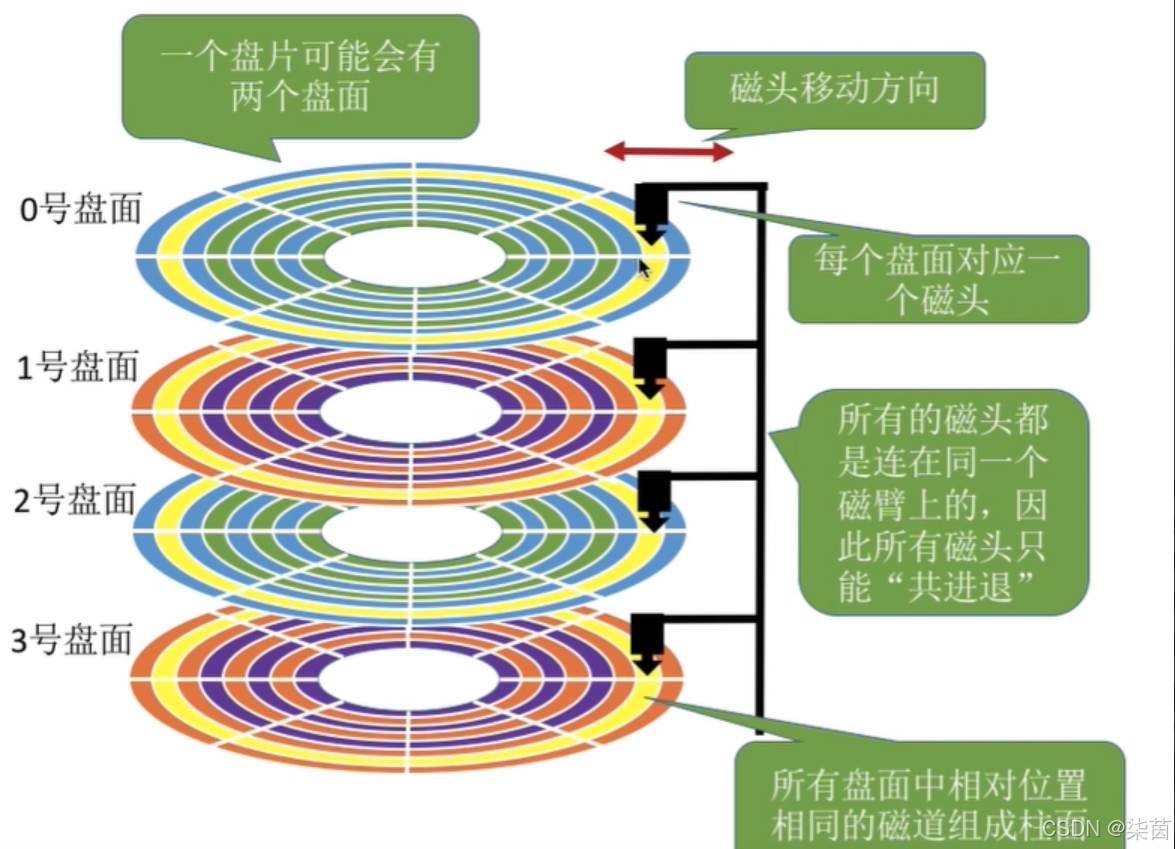
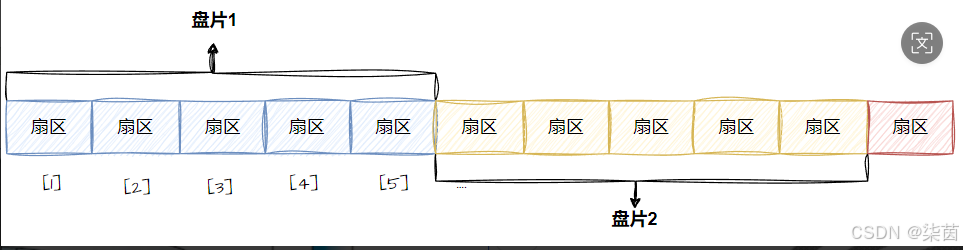
磁盘里面的磁带拉出来,本质上就是线性结构!
所以定位一个扇区,可以用数组下标。这样每一个扇区,就有了一个线性地址(数组下标),这种地址就是LBA
如果将每一个柱面都展开,(每个柱面有很多个扇区)就可以组成一个二维数组。
将所有柱面都展开就会有一个三维数组。
操作系统OS使用的是LBA,LBA可以转换为CHS地址,同样,CHS地址可以转换为LBA地址。
如何将LBA地址转换为CHS地址?
柱面C怎么算:LBA // (磁头数 * 每磁道的扇区数)
磁头号H怎么算:(LBA % ( 磁头数 * 每磁道扇区数))
扇区号S怎么算:(LBA % 每磁道扇区数)+ 1;
如何将CHS地址转换为LBA地址?
磁头数 * 每磁道扇区数 = 单个柱面的扇区总数
LBA = 柱面号C * 单个柱面的扇区总数 + 磁头号H * 每磁道扇区数 + 扇区号S -1
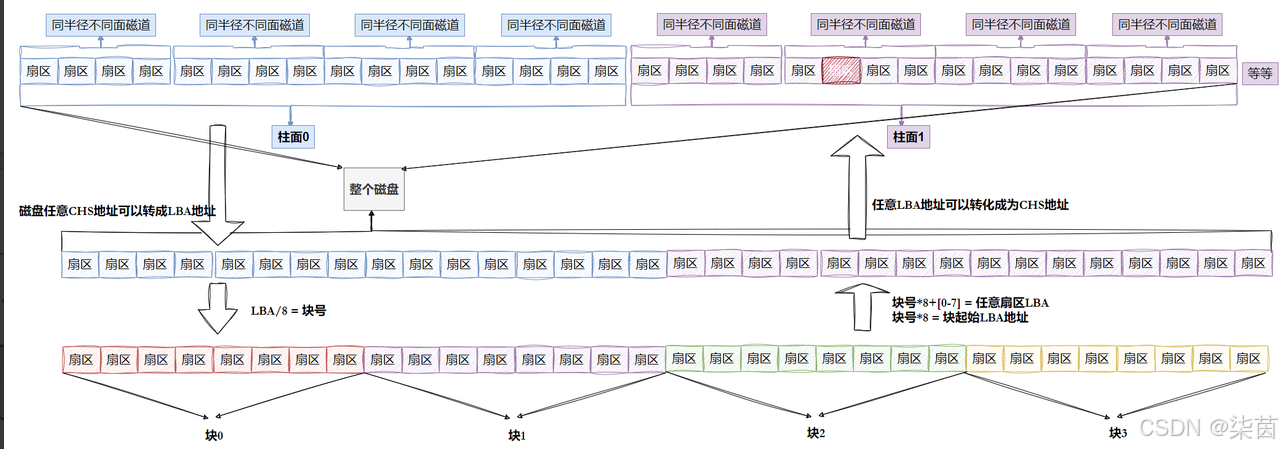
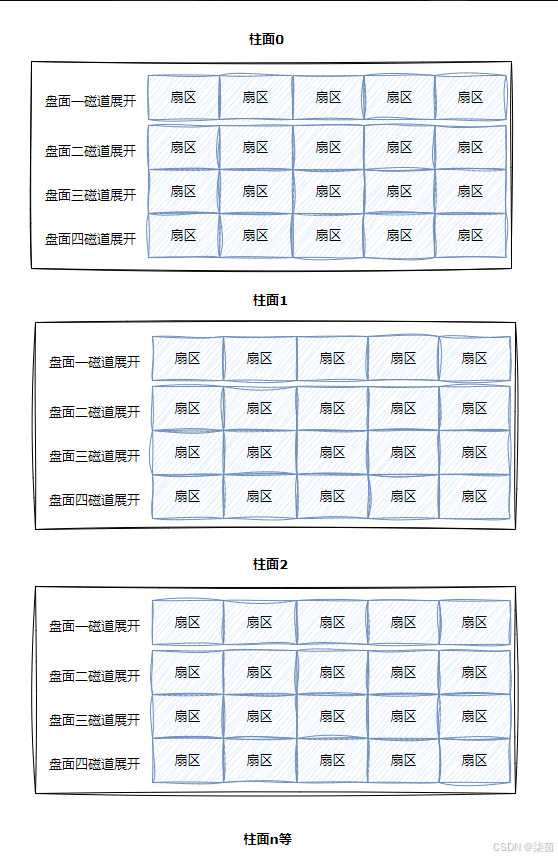
引入文件系统
OS文件的操作系统访问磁盘,不以扇区为单位,而是以块为单位,一般是4KB的(也就是连续8个扇区)512* 8
文件系统,使用磁盘块,是以4KB为单位的。
假如说有800GB的空间,该怎么管理:可以分区分为300,300,200
管理300GB该怎么管理:
Linux中的管理方式:分组
这种思想就是分治!!!
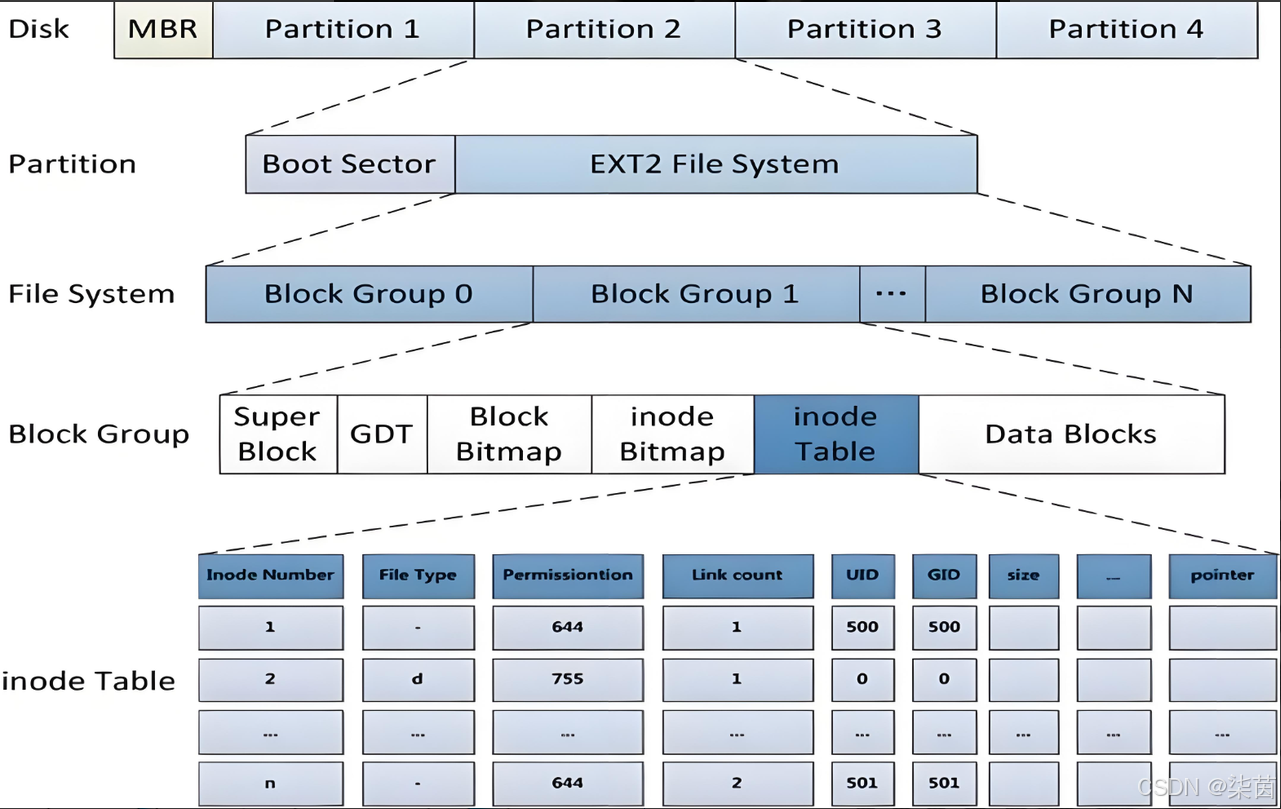
Linux中任何文件都拥有自己的属性集合。将描述文件属性信息的结构体是inode Table,属性大小是固定的,有128字节。
struct inode
{
type
size
int
}文件系统的载体是分区。
文件的属性大小是一致的。文件名字不会保存在文件的inode中。(文件名太长或者太短都不太好,文件名不会保存在文件属性当中)
filesystem和IO进行交互的时候,4KB磁盘块,inode table中有128字节,所以一个数据块有32个inode(4096/128)
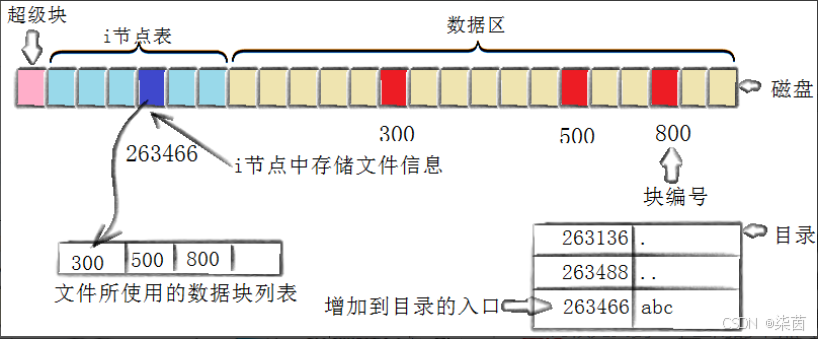
1. 磁盘块(Block)
- 磁盘读写的最小单位通常是 4KB(4096字节)
- 即使你只写1字节,磁盘也会读取/写入整个4KB块
- 这就像买水时最小单位是"一瓶",不能只买"一口"
2. inode(索引节点)
- 每个文件都有一个inode,存储文件的元数据 :
- 文件大小、权限、所有者
- 创建/修改时间
- 文件数据块的指针(文件内容在哪里)
- 这里假设inode大小为 128字节
一个磁盘块能容纳的inode数 = 4096 ÷ 128 = 32个
所以针对不同的文件就有自己的inode编号,磁盘在存储文件的时候不会存储文件名字,就会存储inode编号。
文件的内容被存储在Data Blocks。属性被存储在inode Table;
块位图(block Bitmap)存储的是Data Block中哪个数据块已经被占用,哪个数据块没有被占用。被占用的就标记为1,被清理的文件其对应的比特位清0。
inode位图:每个bit表示的inode是否空闲可用。
问题:为什么下载很大的数据文件的时候很久才下载好,删除的时候一秒删除?
下载文件要将内容存入Data Blocks中,将位图置为1,删除的时候只需要将位图置为0即可。恢复的文件就是将曾经占用的比特位恢复为1。
GDT:块组描述符,描述块组属性信息,整个分区分成多少个块组就有多少个块组描述符,每个块组描述符存储 一个块组的描述信息,如在的这个块组中从哪里开始是inode Table,从哪里开始是Data Blocks,有多少个等等。块组描述符在每个块组的开头都有一份拷贝。
超级块(Super Block):存放文件系统本身的结构信息,描述整个分区的文件系统信息。记录的信息主要有:bolck和inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
不是所有的Block Group都会带Super Block。
格式化的本质:写入文件系统的管理信息。
细节:在同一个分区内部,inode编号,和块号都是唯一的,跨组编号的,不可跨分区。
所以我们往后拿着一个inode编号就可以找到文件。
但是我们怎么知道是哪个分组里面的?
现在来谈一下Linux中文件目录?有个问题,既然文件保存的所有信息都存储在inode中?
目录也是按照这个方式存储的,目录也有inode和数据内容,文件名和目录是对应的映射关系,在磁盘中保存的信息不是inode就是数据。磁盘只认识inode。系统根目录是开机的时候操作系统自动写好的。我们在根目录找到文件路径,搜索到对应的文件。
我们访问任何目录都得有路径。
先打开当前所在的路径,读取对应目录里面的数据内容,得到文件名和inode的映射关系,文件名->inode->inode进行文件查找。
我们怎么从来都没有用inode编号查找过文件?用文件名,文件名不是不作为文件的属性吗?
保存在当前文件,所属的目录的数据内容中。
所以找到任何Linux文件中,都必须从根目录开始,进行路径解析找到对应的文件。
我们的路径是谁提供的?所有的操作都会被转换为进程,会涉及到环境变量,进程提供文件路径。
我们访问任何文件都要从根目录下进行路径解析吗?
效率太低?OS在进行路径解析的时候会把我们历史访问的所有目录形成一颗多叉树,进行保存!Linux系统的树状目录结构。
Linux中,在内核中维护树状路径结构的内核结构体叫做: struct dentry
文件系统的载体是分区,但是你怎么知道是哪个分区?每一个inode都有可能存在同样的编号啊?磁盘分区->格式化->我们依旧不能直接使用这个分区,我们的分区一定要按照一个特定的目录进行关联->通过这个目录,就相当于进入这个分区->挂载
什么叫做挂载?查找文件就看它前面挂载的分区。
整个过程?
cpp
FILE* fp = fopen("test.txt", "r"); // 没有指定绝对路径进行fopen的时候,没有指定路径,操作系统就会根据对应的文件cwd找到路径表,查找struct dentry树,查找到文件的路径,上面对应的节点全部打开,根据inode找到文件对应的属性和内容,在内核中创建struct file,创建struct inode,创建文件缓冲区,创建文件对应的表,随后把inode上面的属性填充进去,磁盘属性加载到内存,文件内容部分加载到文件缓冲区,把文件struct file对象对应的地址分配到,给用户返回文件描述符表。用户拿着文件描述符表就可以找到文件在内存中的位置,路径,以及文件缓冲区了。
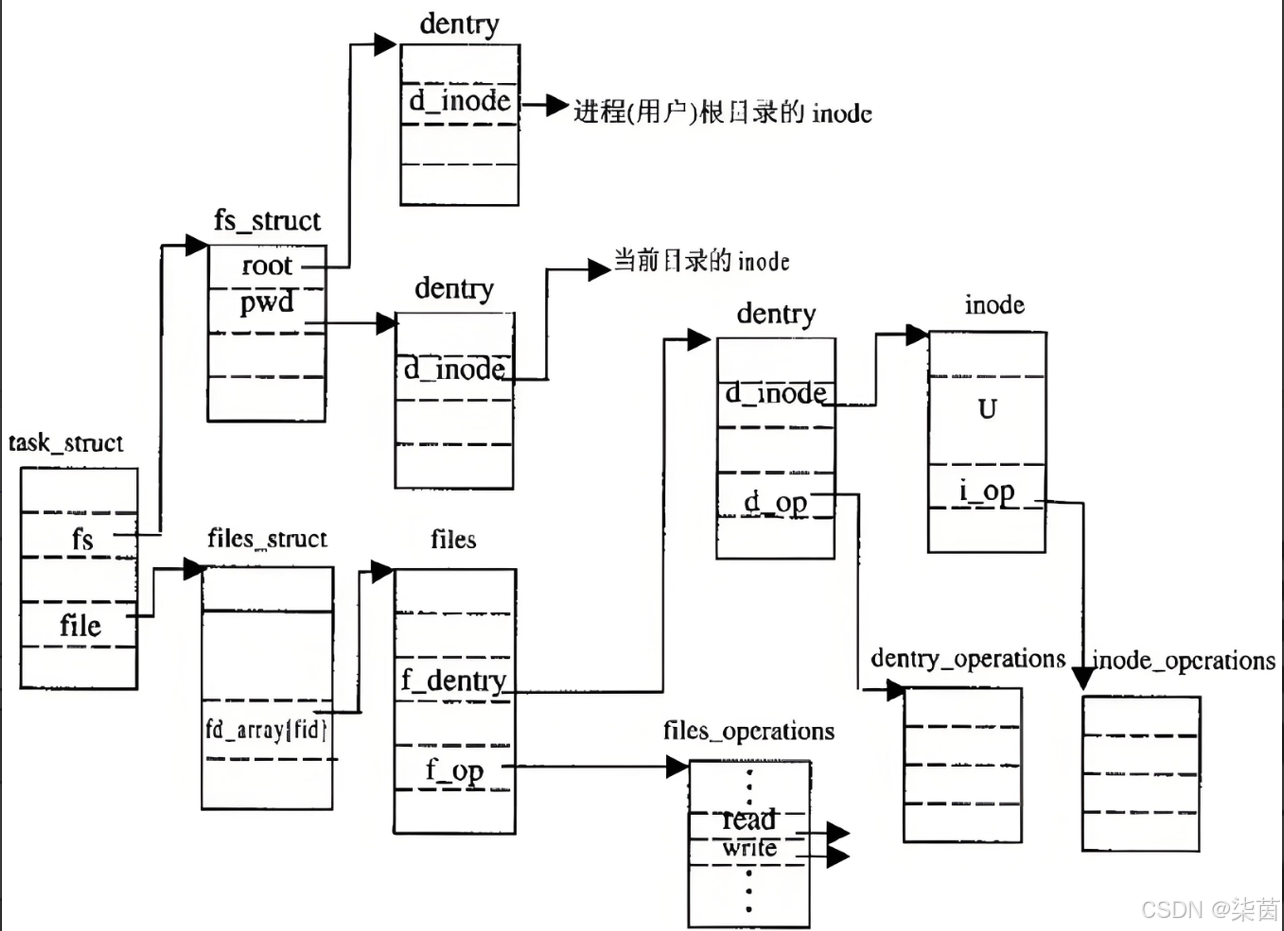
关键数据结构关系
用户进程
↓
FILE* (C标准库) ← 用户看到的
↓
fd (文件描述符) ← 系统调用接口(fopen,获取当前工作目录cwd,拼接完整的路径,在dentry树中查找,逐级查找)
↓
struct file (内核) ← 进程级别的文件对象
↓
struct dentry (内核) ← 目录项缓存
↓
struct inode (内核) ← 文件元数据
↓
页缓存/缓冲区 (内核) ← 文件内容缓存(填充文件信息,创建标准的IO的FILE结构)
↓
磁盘块 (物理存储) ← 实际数据用户怎么使用:
// 用户代码
FILE* fp = fopen("test.txt", "r");
// 内部转换
用户fopen() → 系统调用open() → 获取fd → 封装为FILE*
// 后续操作
fread(buf, 1, 100, fp);
// 实际发生:
// 1. 检查用户缓冲区是否足够
// 2. 如果不够,通过fd发起read系统调用
// 3. 内核检查页缓存是否有数据
// 4. 若无,从磁盘读取到页缓存
// 5. 复制到用户缓冲区那么如果文件太大保存不了怎么办?
inode和dataBlock的编号是全局的,拿到块号就知道在哪个区中,文件的内容可以跨组保存。
软硬连接
cpp
[keda@VM-0-4-centos lesson21]$ vim code.c
[keda@VM-0-4-centos lesson21]$ ln -s code.c code-soft
[keda@VM-0-4-centos lesson21]$ ll
total 0
-rw-rw-r-- 1 keda keda 0 Jan 3 14:29 code.c
lrwxrwxrwx 1 keda keda 6 Jan 3 14:30 code-soft -> code.c
[keda@VM-0-4-centos lesson21]$ ls -ll
total 0
-rw-rw-r-- 1 keda keda 0 Jan 3 14:29 code.c
lrwxrwxrwx 1 keda keda 6 Jan 3 14:30 code-soft -> code.c
[keda@VM-0-4-centos lesson21]$ vim code-soft -> code.c软连接是一个独立的文件,因为它有独立的inode;为什么有这个概念?文件内容+文件属性,软连接其实就是windows下的快捷方式,有可能文件在内存文件中路径很深,所以就提出了软连接的概念。其中保存了文件的路径。
windows有快捷方式,删除了快捷方式不等于删除了文件。
硬连接:
是什么:本质是不是一个独立的文件,其没有独立的inode number。是一组新的文件名和目标inode number的映射关系。
cpp
[keda@VM-0-4-centos lesson21]$ ln code.c code-hard
[keda@VM-0-4-centos lesson21]$ ll
total 24
-rwxrwxr-x 1 keda keda 8360 Jan 3 14:34 a.out
drwxrwxr-x 3 keda keda 4096 Jan 3 14:35 bin
-rw-rw-r-- 2 keda keda 80 Jan 3 14:34 code.c
-rw-rw-r-- 2 keda keda 80 Jan 3 14:34 code-hard
[keda@VM-0-4-centos lesson21]$ ll -li
total 24
794369 -rwxrwxr-x 1 keda keda 8360 Jan 3 14:34 a.out
794370 drwxrwxr-x 3 keda keda 4096 Jan 3 14:35 bin
794368 -rw-rw-r-- 2 keda keda 80 Jan 3 14:34 code.c
794368 -rw-rw-r-- 2 keda keda 80 Jan 3 14:34 code-hard794368 -rw-rw-r-- 2 keda keda 80 Jan 3 14:34 code.c
794368 -rw-rw-r-- 2 keda keda 80 Jan 3 14:34 code-hard
2:硬连接指数,多一个新的文件名指向目标文件。
有什么用?
用途:对文件进行备份。
.和... 就是硬链接。
总结:
一、文件I/O缓冲
- 缓冲目的:减少系统调用,提高效率
- 三种策略:无缓冲(立即写)、行缓冲(遇\n写)、全缓冲(满才写)
- 数据流程:用户缓冲区 → 内核缓冲区 → 磁盘
二、磁盘结构
- 物理结构:柱面©、磁头(H)、扇区(S)三维定位
- 逻辑结构:LBA线性地址,可转换为CHS
- 读写单位:4KB块(8个扇区)
三、文件系统组织
- inode:128字节,存储文件属性(大小、权限等)
- Data Blocks:存储文件内容
- 位图管理 :
- Block Bitmap:标记数据块使用情况
- Inode Bitmap:标记inode使用情况
- 快速删除:只清位图,不擦数据
四、文件访问流程
- 路径解析:从当前目录逐级查找
- dentry缓存:内核路径树,避免重复查找
- inode获取:通过目录数据块找到文件名→inode映射
- 打开文件:创建内核结构体,分配文件描述符
- 数据读写:通过页缓存减少磁盘访问
五、软硬链接
- 软链接:独立文件,存目标路径(快捷方式)
- 硬链接:共享inode,多个文件名指向同一文件
- 硬链接数:.和...也是硬链接
六、挂载机制
- 分区必须挂载到目录才能访问
- 挂载点决定访问哪个分区
- 根目录/是自动挂载的起点
核心思想:磁盘按块组织,文件通过inode管理,路径经dentry缓存加速,缓冲机制优化I/O性能。