文章目录
- 什么是循环依赖
- 解决方法
- 源码
-
- [1. 实例化](#1. 实例化)
- [2. 加入第三级缓存](#2. 加入第三级缓存)
- [3. 依赖注入](#3. 依赖注入)
- [4. 递归并加入第二缓存](#4. 递归并加入第二缓存)
- [5. 回到上层依赖注入](#5. 回到上层依赖注入)
- 逻辑图
- 问题
什么是循环依赖
假设你有一个Spring项目,然后你创建了类AService,和BService,他们的关系是这样的
java
@Component
public class AService {
@Autowired
private BService bService;
}
@Component
public class BService {
@Autowired
private AService aService;
}他们相互依赖,根据我们之前说的Spring机制,在AService实例化和初始化时需要进行注入,也就是getBean创建BService,同时BService也同样做了相同的事,就会形成循环依赖。
我们退一步讲,不用Spring,正常的一个项目中,这样写,是不是就有问题。
解决方法
但是,你在项目中并没有遇到,或者你无意间粗心的写出了这样的代码,但是项目依然正常运行,甚至你都没发现,这是因为Spring针对这个场景做了设计。
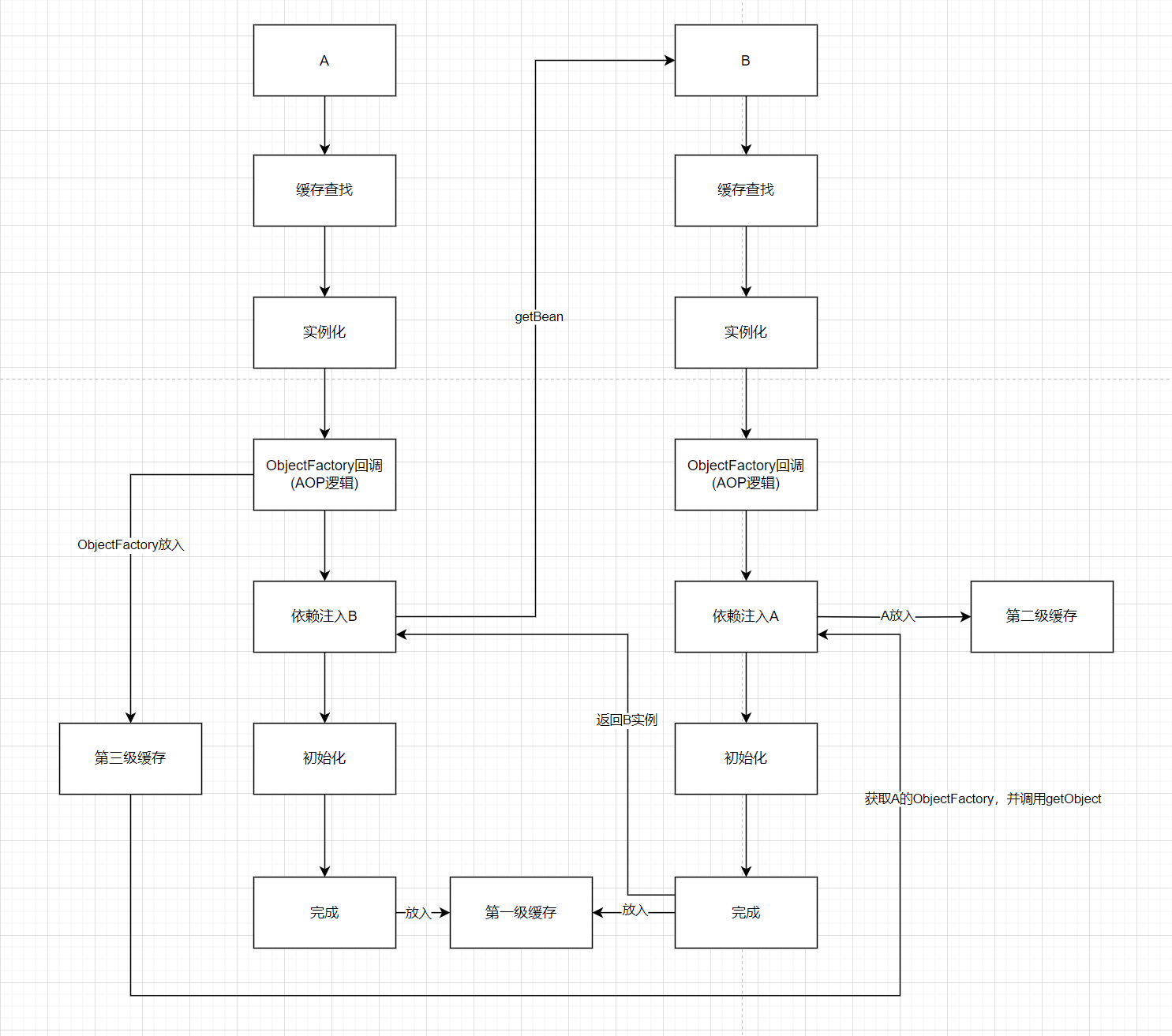
在Spring中他采用了三级缓存来解决这个问题。
一级缓存:单例池singletonObjects
二级缓存:半成品单例earlySingletonObjects
三级缓存:单例工厂singletonFactories
这个原理,其实不难,可以理解为对象引用的操作。即当AService实例化后, 将当前实例对象放入缓存(这里我们不管几级缓存),这时还没有初始化,然后初始化时,依赖注入getBean("BService"),这时BService要注入AService,它就从缓存中取,缓存中有这个实例化好的AService,然后它注入到BService中,同样也放入缓存,返回实例对象,然后回到AService注入的过程,它已经可以拿到BService实例对象了,然后再设置到属性中。
就是这样的一个引用原理,在Spring中它用了三级缓存来解决。
它的一个简易流程如下:
- 实例化A
- 放入第三级缓存
- 依赖注入B,B没有
- 实例化B
- 放入第三级缓存
- 依赖注入A,A没有
- 从三级缓存取出A
- 将A放入第二级缓存,并从第三级移除
- 注入B
- 返回B,注入A
其实,这个我感觉两级缓存就可以解决循环依赖了,去掉第三级缓存:
- 实例化A
- 放入第二级缓存
- 依赖注入B,B没有
- 实例化B
- 放入第二级缓存
- 依赖注入A,A没有
- 从二级缓存取出A
- 注入B
- 返回B,注入A
源码
缓存管理类:DefaultSingletonBeanRegistry
单例的管理都由他管理,那么注入的逻辑都会涉及这个类,可以先了解一下。
接下来,我们开始循环依赖解决的源码流程。
1. 实例化
位置:org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean
这里实例化AService
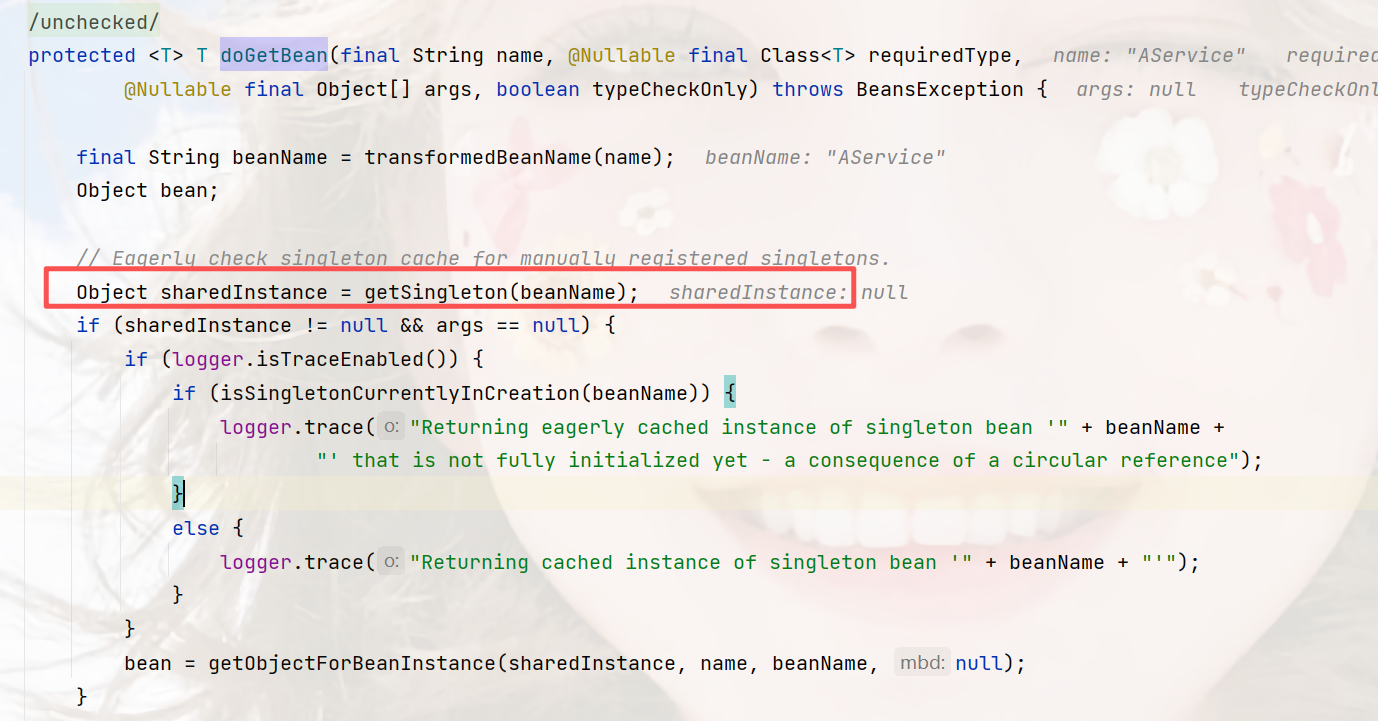
这一段,是从缓存中获取单例Bean的逻辑,可以看到:
- 单例池获取
- 单例池不存在,且正在创建该Bean时,从二级缓存获取
- 二级缓存不存在时,从三级缓存获取,然后存入到二级缓存,同时删除三级缓存
当第一次进入该方法时,第三级缓存singletonFactories也是空的,所以,第一次走这个方法是返回null,这不重要,你可以理解为在真正创建Bean时,先查询缓存,这是正常逻辑,就比如Redis缓存一样。
然后是下面这段:

这段过后才是真正的创建Bean的过程
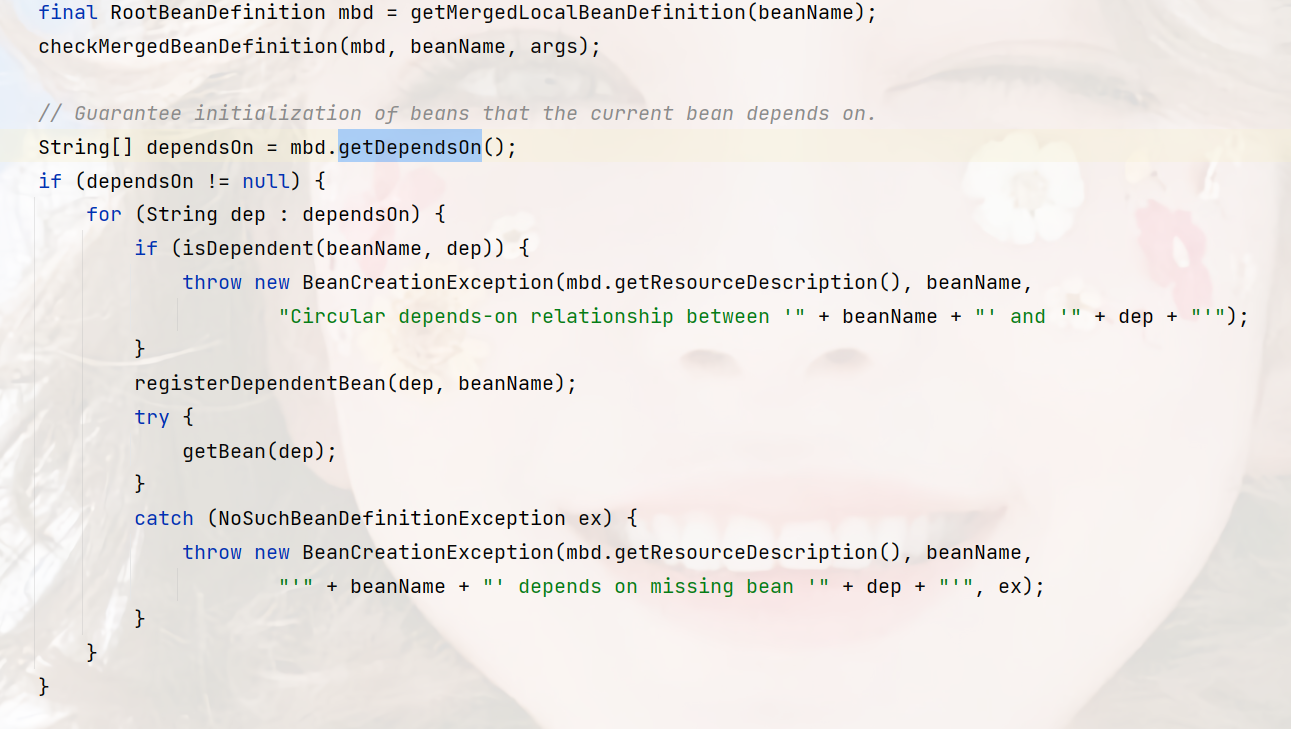
这段是通过BeanDefinition也就是Bean定义信息,拿到注解@DependsOn信息,也就是依赖的Bean然后做提前实例化,你可以看到里面这行代码:getBean(dep),也就是整个方法本身,就是递归。
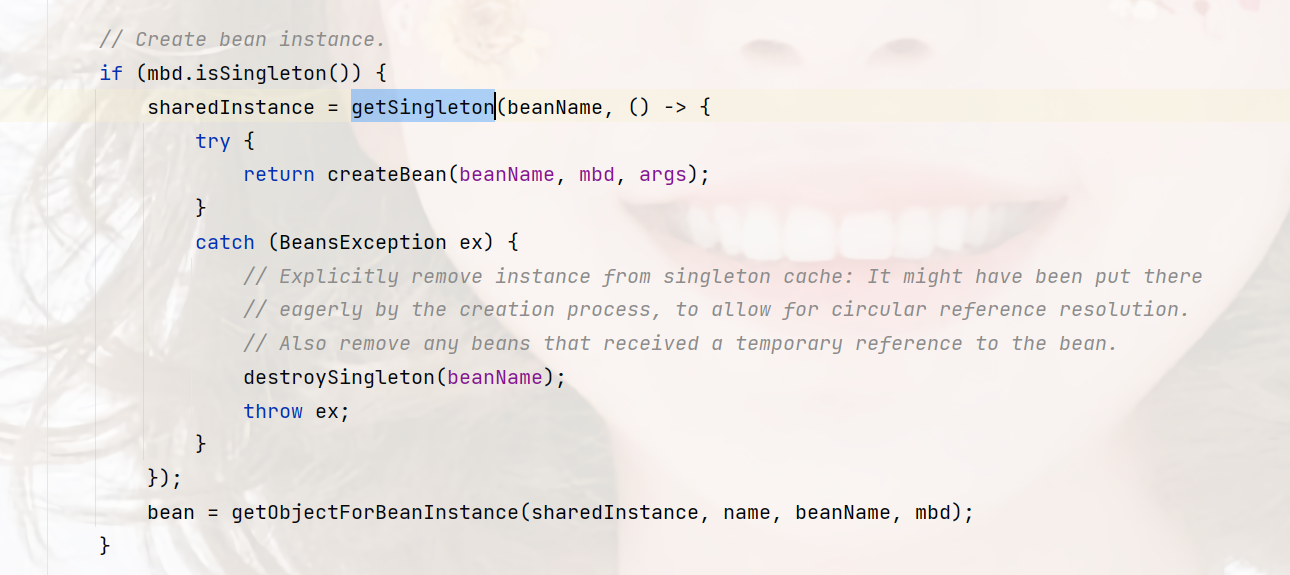
这段就是重点,createBean这个方法是创建Bean,但它是被作为一个回调方法参数,该方法主要做验证和添加到单例池,真正的创建是createBean,信息并不多,自行查看
位置:org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#getSingleton(java.lang.String, org.springframework.beans.factory.ObjectFactory<?>)
重点看createBean,位置:org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#createBean(java.lang.String, org.springframework.beans.factory.support.RootBeanDefinition, java.lang.Object\[\])
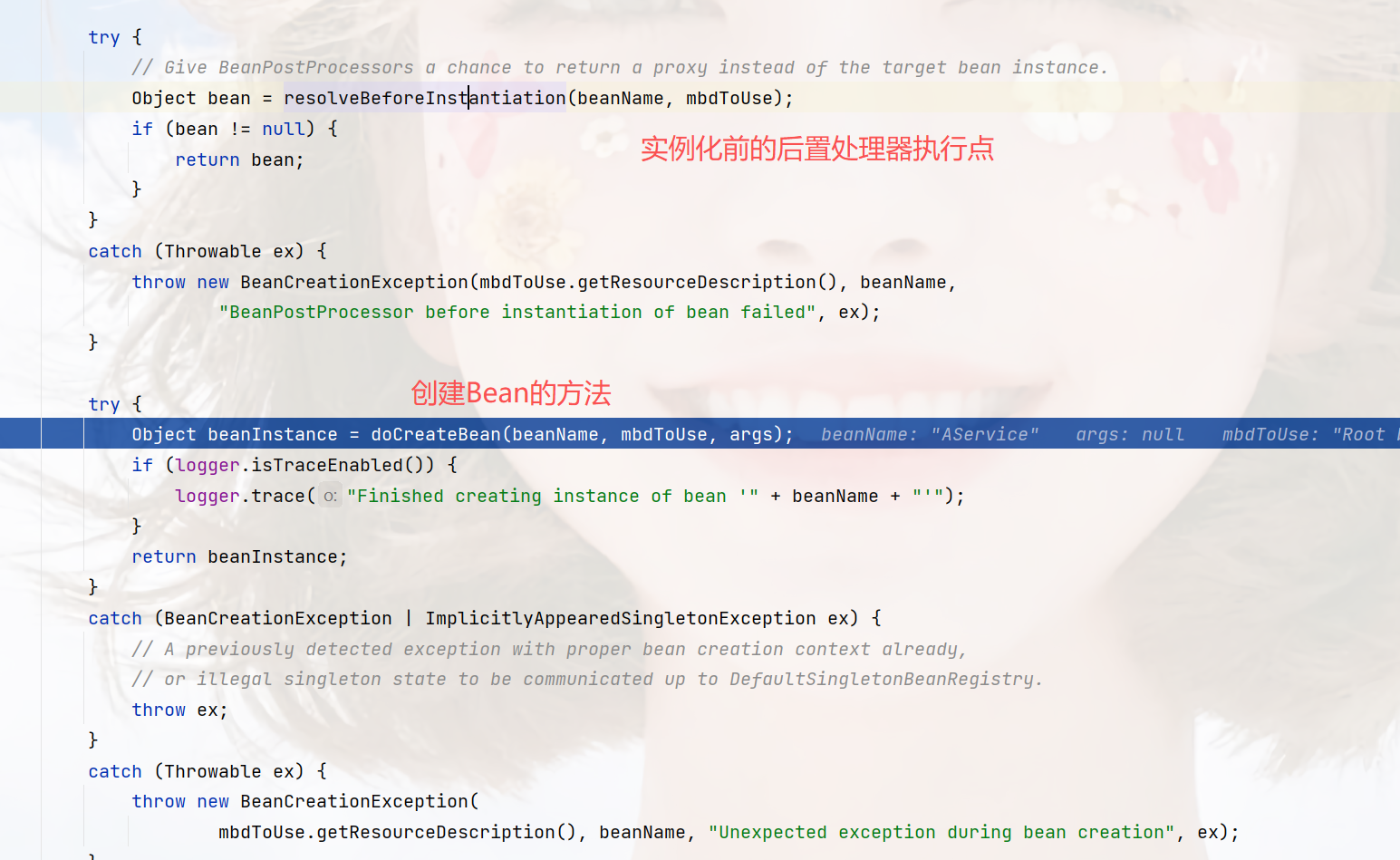
位置:org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean
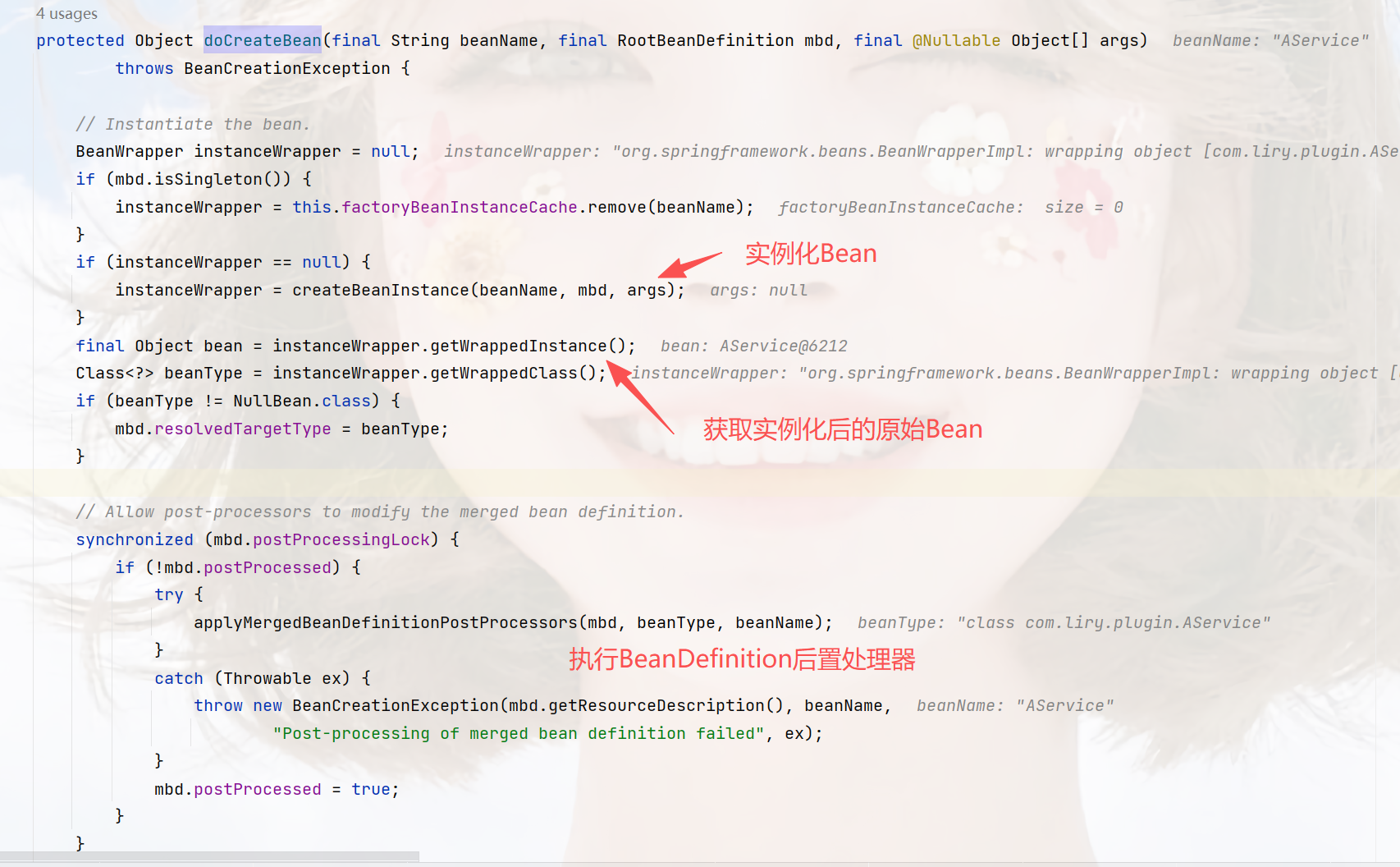
2. 加入第三级缓存
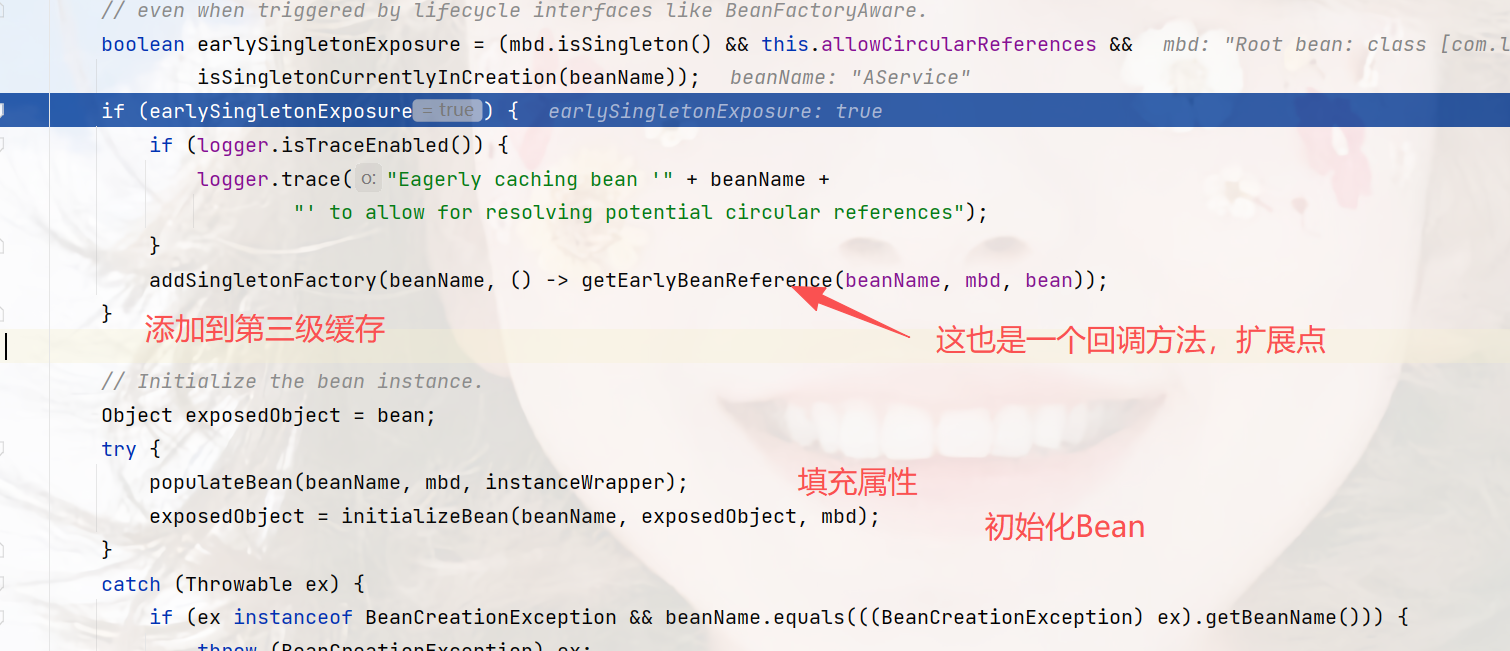
这个populateBean就是依赖注入的方法,里面是xml、注解方式的注入逻辑,而initializeBean是初始化bean的必要操作,如执行Aware、@PostConstruct等方法。
addSingletonFactory就是加入第三级缓存的地方,我们可以看一下这个方法:
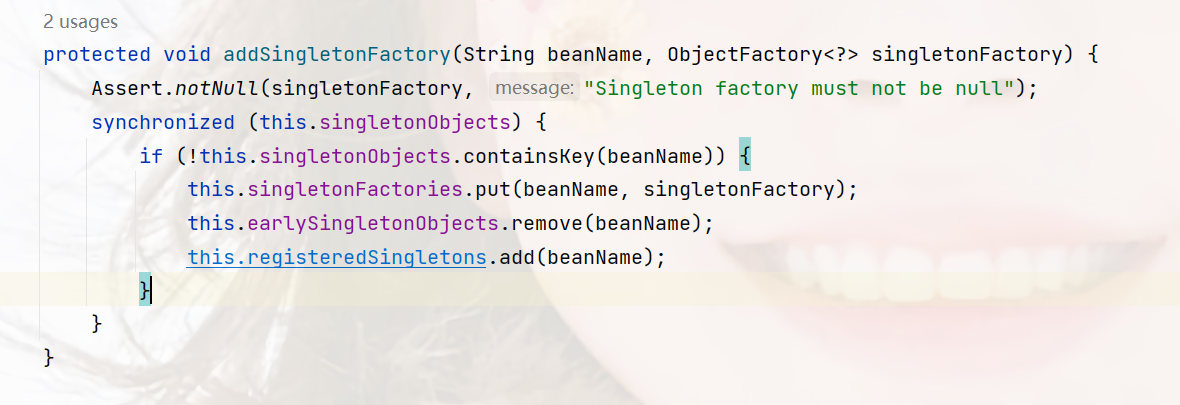
注意,这里只是添加第三级缓存,同时也移除了第二级缓存,AService已经在第三级缓存了。
3. 依赖注入
循环依赖是发生在依赖注入里的,所以我们进入这个方法
位置:org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#populateBean
我们直接看这一段
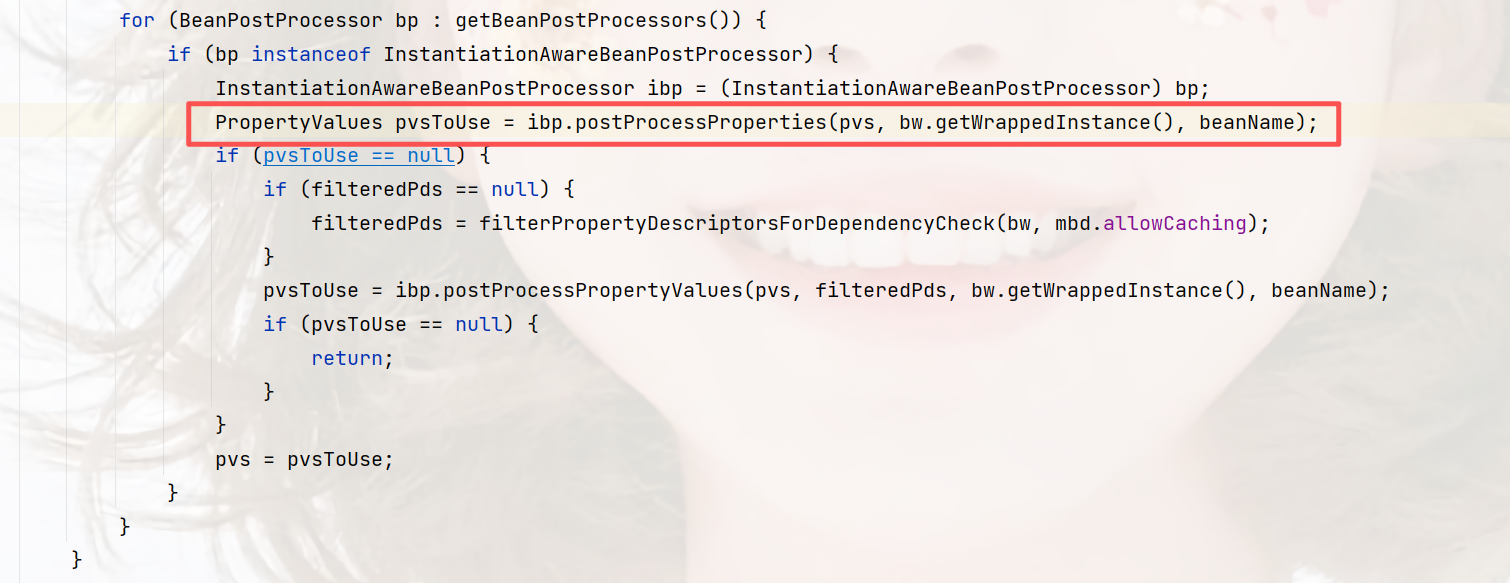
注解@Autowired、@Resource就是在这里执行的,分别通过AutowiredAnnotationBeanPostProcessor``CommonAnnotationBeanPostProcessor两个处理器执行。
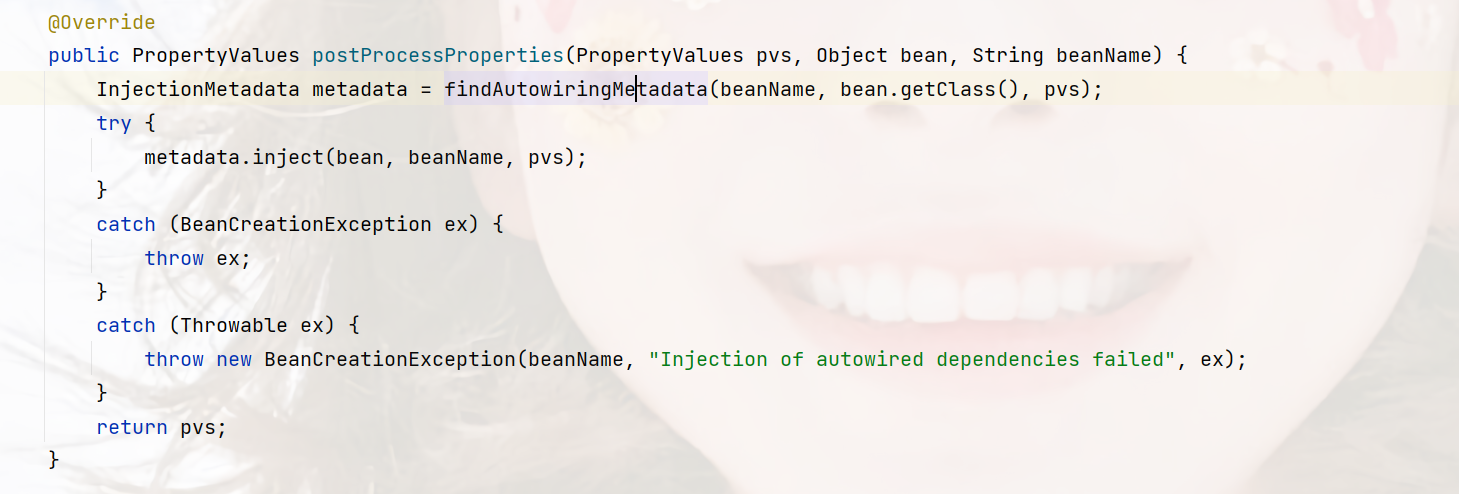
这个方法一共两行,第一行,拿到要要注入的属性元数据对象,第二行,就是执行注入。
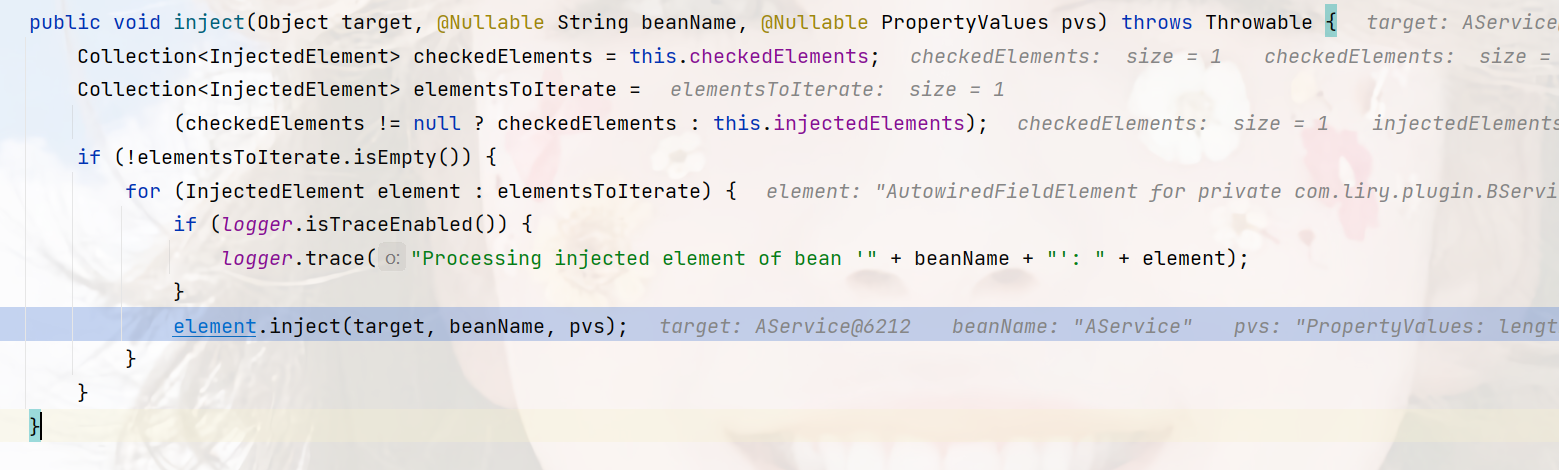
这里他是遍历当前Bean下的注入点,这些注入点就是要注入的属性对象,这里就是BService。
位置:org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement#inject
最后走到这步:
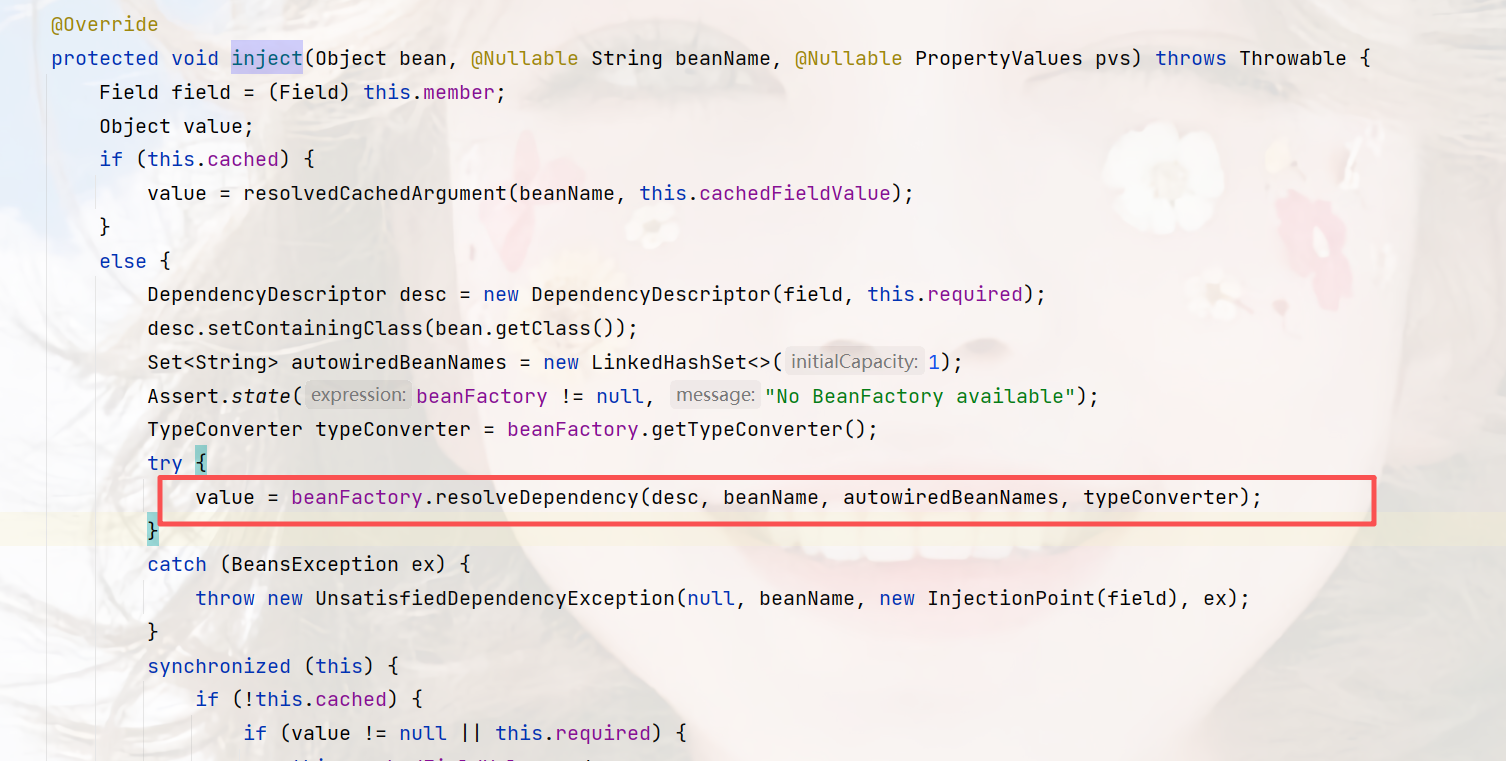
然后是:org.springframework.beans.factory.support.DefaultListableBeanFactory#doResolveDependency
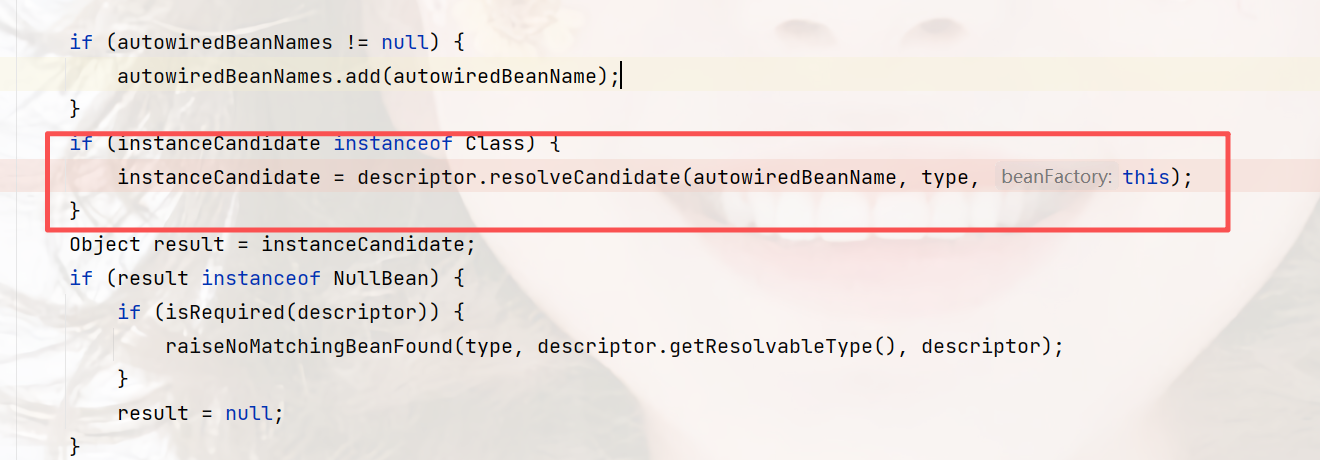
最后就是走到这,前面是验证和获取属性的类型,然后是:

这里它传入了要注入的属性beanName和类型,但是实际上,它只是通过BeanName去查找,那么重点是beanFactory.getBean(beanName);
这个方法,他是统一的,同一个,所以这里是递归。
4. 递归并加入第二缓存
那么从现在开始,又回到第一步,然后再次执行:
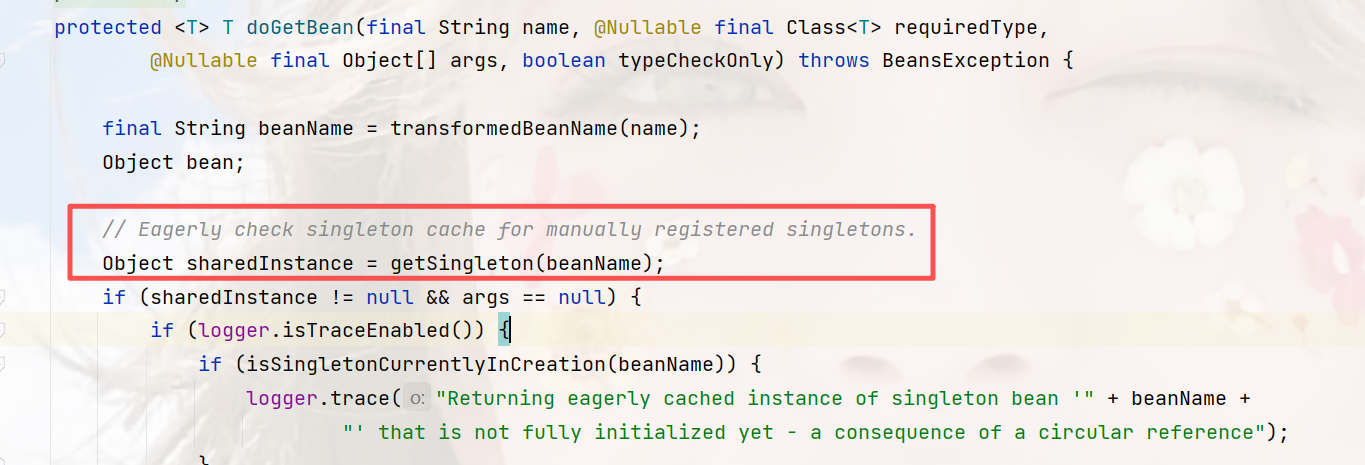
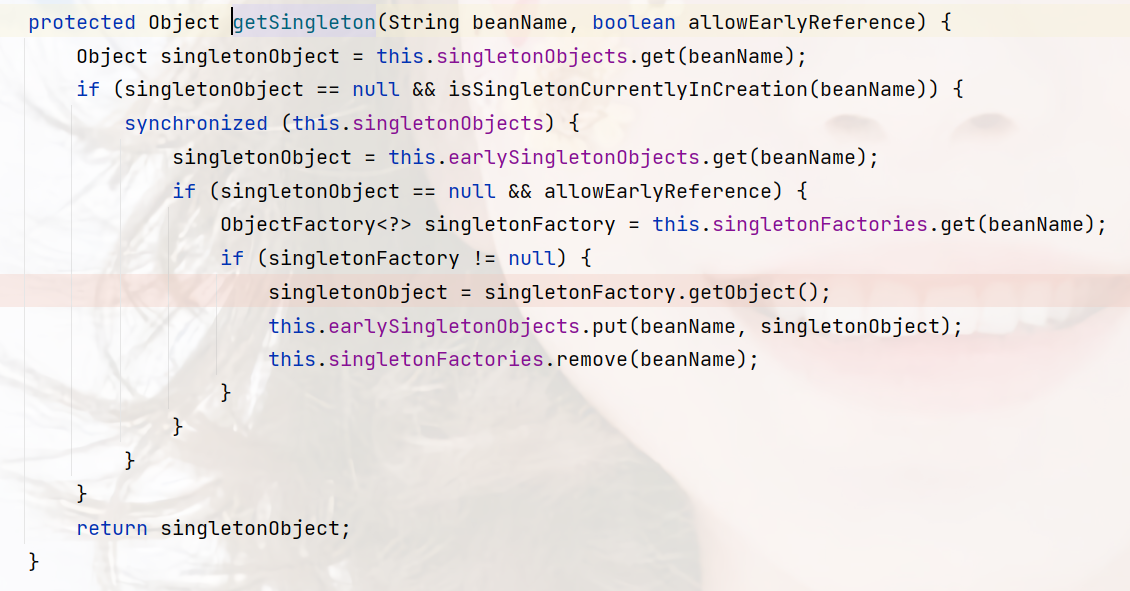
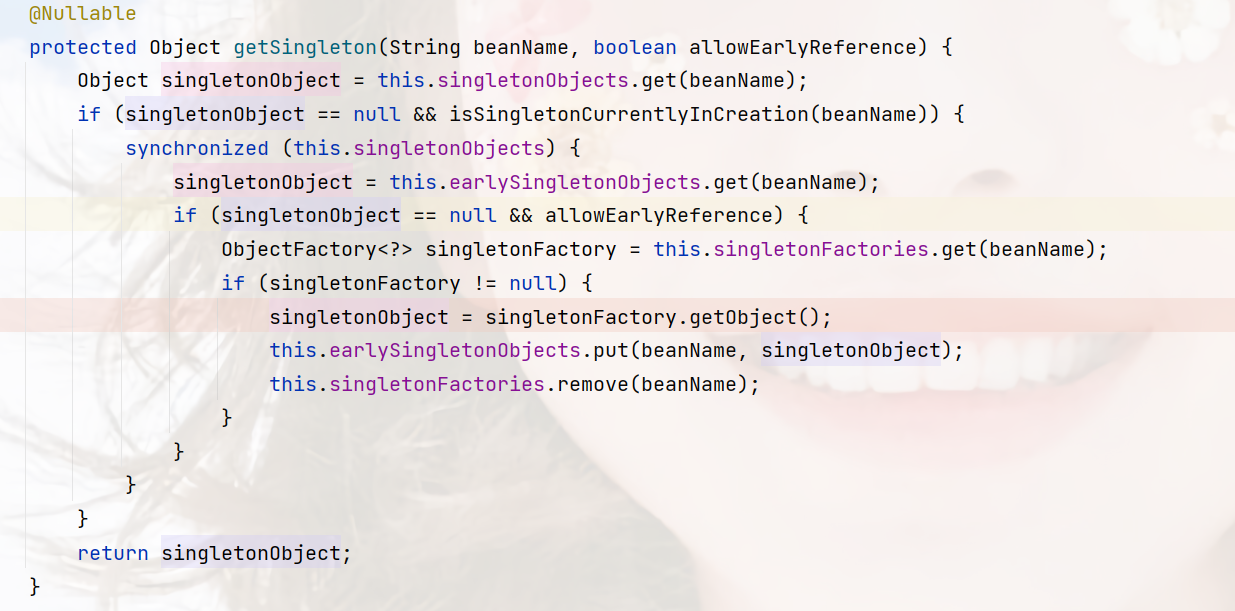
但是,这里同样和第一次一样,并没有缓存,然后直到走到依赖注入populateBean,然后inject,要注入AService,最后走到下面这个代码,此时按顺序从一二三级缓存查找,最后找到了AService在实例化之后加入的实例对象,最后加入到第二缓存。
java
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 单例池查找bean
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 找不到,且是正在创建的bean,那么就从二级缓存查找
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 二级缓存找不到,并且是允许提前参考的对象,那么从第三级缓存查找
// 第一次A类肯定没有,
// A类依赖注入B,B也没有
// B类依赖注入A,A有了,因为A实例化之后就加入了第三级缓存
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
// 找到之后,将第三级缓存的bean实例放入第二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 移除第三级缓存
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}5. 回到上层依赖注入
然后返回这个方法:org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.AutowiredFieldElement#inject
通过反射注入
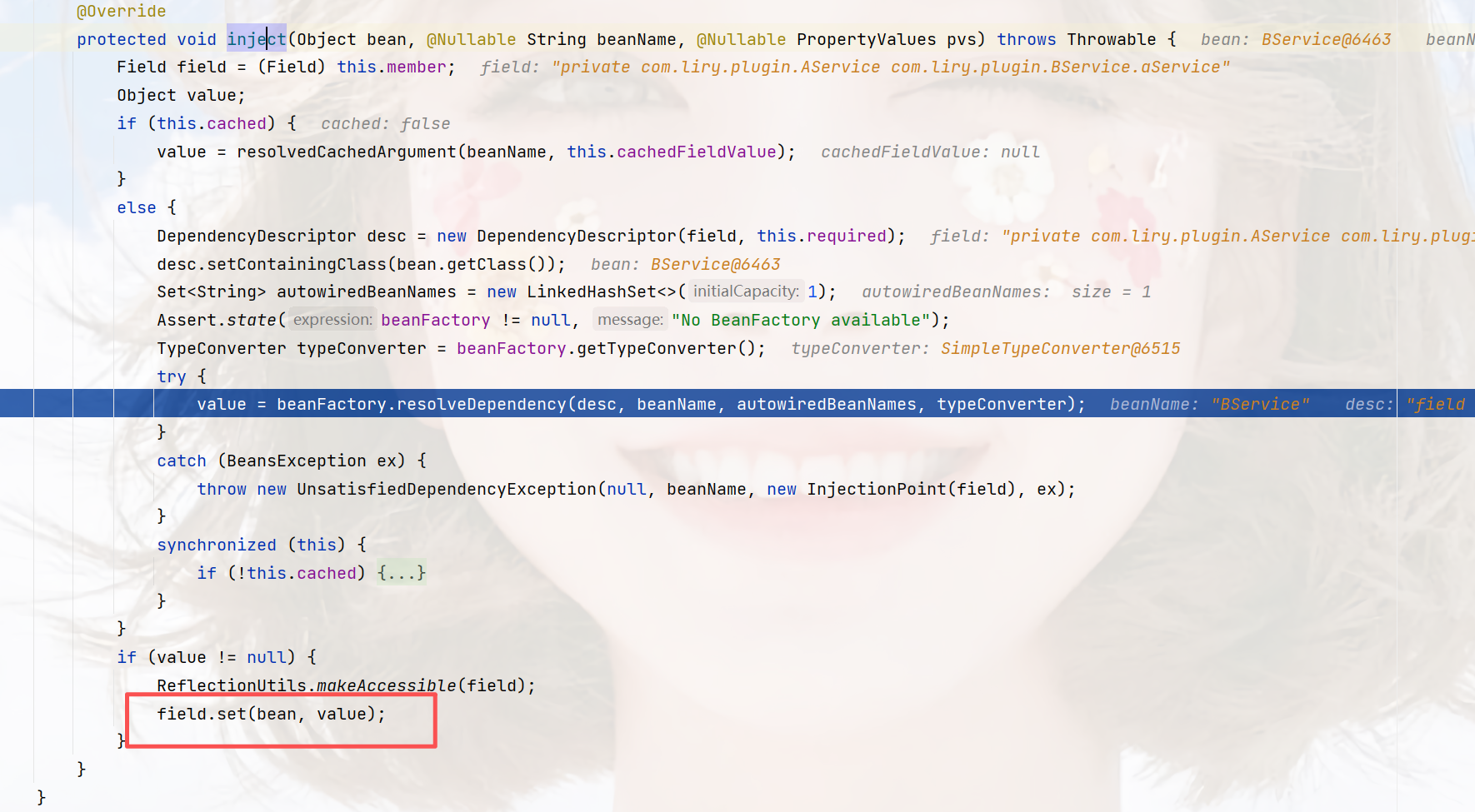
在获取到value之后,他还会做一步,就是校验这个value是否是对的,就是isTypeMatch,根据beanName和类型查找,但实际上的方法,和之前一样,类型作为入参,并没有传递下去,所以,还是通过beanName去查找(getBean)
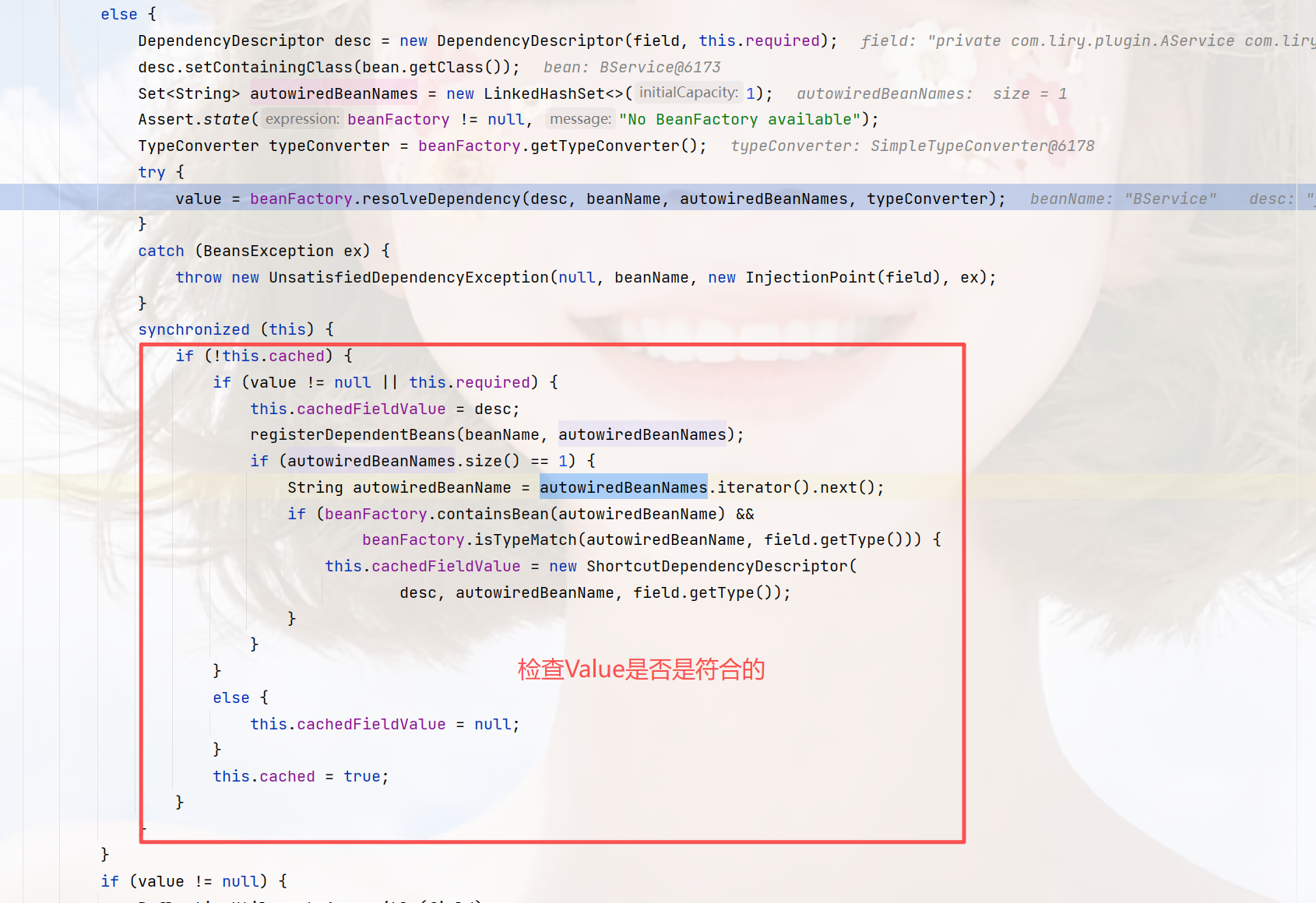
逻辑图
我简单的画了个图
问题
上面我们的流程基本没用到二级缓存,是为什么?
那么这里再引出其他问题:
- 代理对象作为属性,该如何做?
- 如果去掉第二级缓存,会如何?
我们先考虑第一个问题,假设我们的AService属性是BService,而我们的BService被代理类,我们创建一个代理类:
java
@Component
@Aspect
public class Asp {
@Pointcut("execution(* com.liry.plugin.BService.*(..))")
public void pointCut() {
}
@Before(value = "pointCut()", argNames = "joinPoint")
public void get(JoinPoint joinPoint) throws Throwable {
System.out.println("proxy befor");
}
}那么,当AService依赖注入的时候,应该注入的是原始的Bean还是代理类?
当项目运行中,直接调用属性,如果是原始bean,它是不会生效,在Spring当中,动态代理,只是通过配置的方式,自动代理,实际的还是需要想传统的代理对象那般,通过代理对象委托给原始Bean执行业务逻辑,所以,AService依赖注入中的BService一定是一个代理对象。
好,如果只有两级缓存,在循环依赖时,出现代理Bean,就直接存入第二级缓存,会如何?
假设AService依赖BService,BService依赖AService,AServiceAOP了,但是属性注入时,还是使用原始Bean,但第二级缓存已经放入了代理的AService,那么BService在注入时,可以直接从第二级拿到代理的AService,没问题,反过来,也同样成立。
所以,一开始我会说"我感觉两级缓存就可以解决循环依赖了"。
那如此,为什么要第三级缓存呢?
我有看到说,这是Spring的设计原则,代理对象应该时准保好的Bean,就是对完整Bean的代理,可是,
在刚刚的场景中,A依赖B,B依赖A,当B注入A时,创建了A的代理,放入缓存,实现B的注入,而此时是A的注入过程,还没有结束,初始化没有完成,所以,也不合理。
而且它所以表现出的现象,和二级缓存是一样,都是通过对象引用更新原始Bean。