Paper Card
- 论文标题 : π 0.5 \pi_{0.5} π0.5: a Vision-Language-Action Model with Open-World Generalization
- 论文作者:Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren, Lucy Xiaoyang Shi, Laura Smith, Jost Tobias Springenberg, Kyle Stachowicz, James Tanner, Quan Vuong, Homer Walke, Anna Walling, Haohuan Wang, Lili Yu, Ury Zhilinsky
- 论文链接 :arXiv:2504.16054
- 项目主页 :https://pi.website/blog/pi05
- 论文出处:CoRL 2025
- 论文被引:203 (03/01/26)
1. 摘要
π0.5 是基于 π0 开发的视觉-语言-动作(VLA)模型 ,旨在解决机器人学习中的核心难题:开放世界泛化(Open-World Generalization) 。通过在异构数据源(包括不同形态的机器人、高层语义预测、Web 数据和口头指令)上进行共训练(Co-training),π0.5 能够控制移动操作机器人在从未见过的家庭环境中执行长程、多阶段的家务任务(如收拾厨房、叠被子),任务时长可达 10-15 分钟 。
2. 提出背景和解决的问题
背景:VLA 模型虽然实现了端到端的机器人控制,但通常只能在与训练数据分布紧密匹配的环境中工作 。
核心问题:如何让机器人在完全陌生的环境(In-the-wild)中泛化?仅仅依靠扩大单一形态机器人的数据采集是不切实际的 。
解决思路 :人类的泛化能力来自于多源经验(书本知识、类比、通过观察他人)。同理,机器人模型应该通过迁移学习,利用其他形态机器人(如静态臂)、Web 数据(视觉/语言知识)和高层语义任务预测来弥补目标领域数据的不足 。
3. 主要方法
3.1 模型架构
π0.5 采用分层架构,但在同一个 Transformer 模型中实现。它结合了离散动作 Token 和连续动作预测。
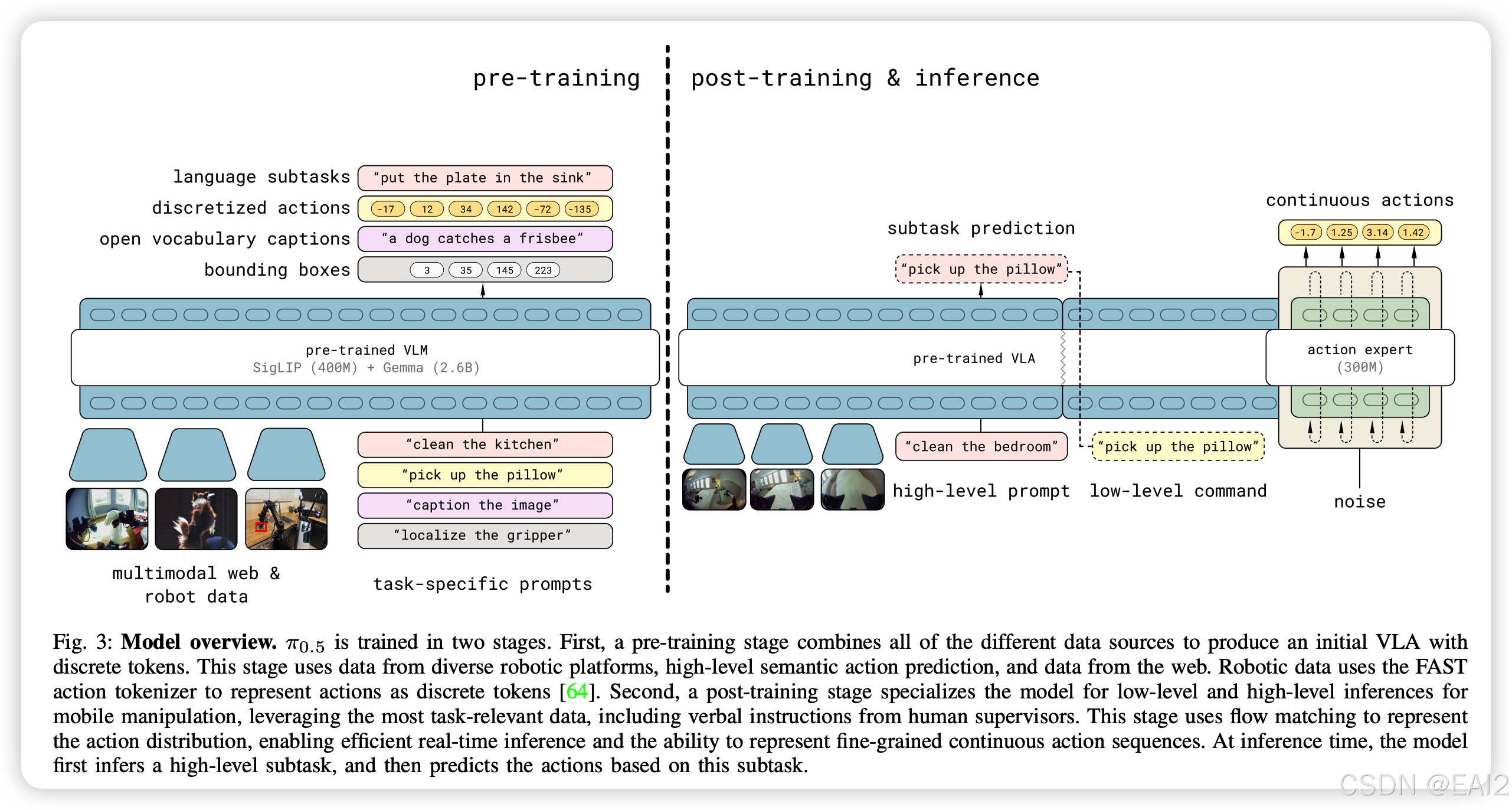
图注:π0.5 模型分为两个阶段训练:预训练阶段(Pre-training)使用离散 Token 处理所有数据源;后训练阶段(Post-training)引入 Action Expert,使用 Flow Matching 进行连续动作预测。
Backbone:PaliGemma(SigLIP 400M + Gemma 2B)
混合动作表示 (Hybrid Action Representation):
-
Pre-training:使用 FAST tokenizer 将动作离散化为 Token,进行自回归预测 。
-
Post-training :引入 Action Expert 模块,使用 Flow Matching 预测连续动作流 。Action Expert 是一个较小的 Transformer(300M参数),专门处理动作生成 。
3.2 训练策略 (两阶段训练)
预训练 (Pre-training) :
- 目标:适应多样化的机器人任务。
- 形式:纯离散 Token 预测(文本、物体框、离散动作)。
- 步数:280k
后训练 (Post-training) :
- 目标:专注于移动操作(Mobile Manipulation)并启用连续动作控制。
- 形式:联合训练 Next-token prediction(用于文本/高层任务)和 Flow Matching(用于低层动作)。
- 步数:额外 80k,Flow Matching 权重
3.3 训练数据构建 (异构数据源)

图注:展示了用于训练的多样化数据源,包括移动机器人数据、静态机械臂数据、Web 数据等。
π0.5 的核心在于数据混合(Mixture),具体包含:
- MM (Mobile Manipulator):约 400 小时,目标形态机器人在 100 个家庭中的数据 。
- ME (Multi-Environment non-mobile):静态机械臂在不同家庭的数据(易于采集,增加环境多样性) 。
- CE (Cross-Embodiment Lab):实验室内的多形态机器人数据(包括 Open X-Embodiment) 。
- HL (High-Level Subtask):标注的高层语义任务(如"pick up the plate"),用于类似 Chain-of-Thought 的推理 。
- WD (Web Data):图像描述、VQA、物体定位数据,用于保持视觉语义能力 。
- VI (Verbal Instruction):Post-training 阶段加入,由专家通过语言逐步指导机器人操作的数据 。
3.4 评测方式
环境:3 个从未见过的真实家庭(Real Homes)和模拟环境(Mock Environments) 。
任务:包括厨房清理(Dishes in Sink, Items in Drawer)和卧室整理(Laundry in Basket, Make Bed) 。
4. 消融实验和关键结果
4.1 泛化能力随环境数量的扩展 (Scaling)
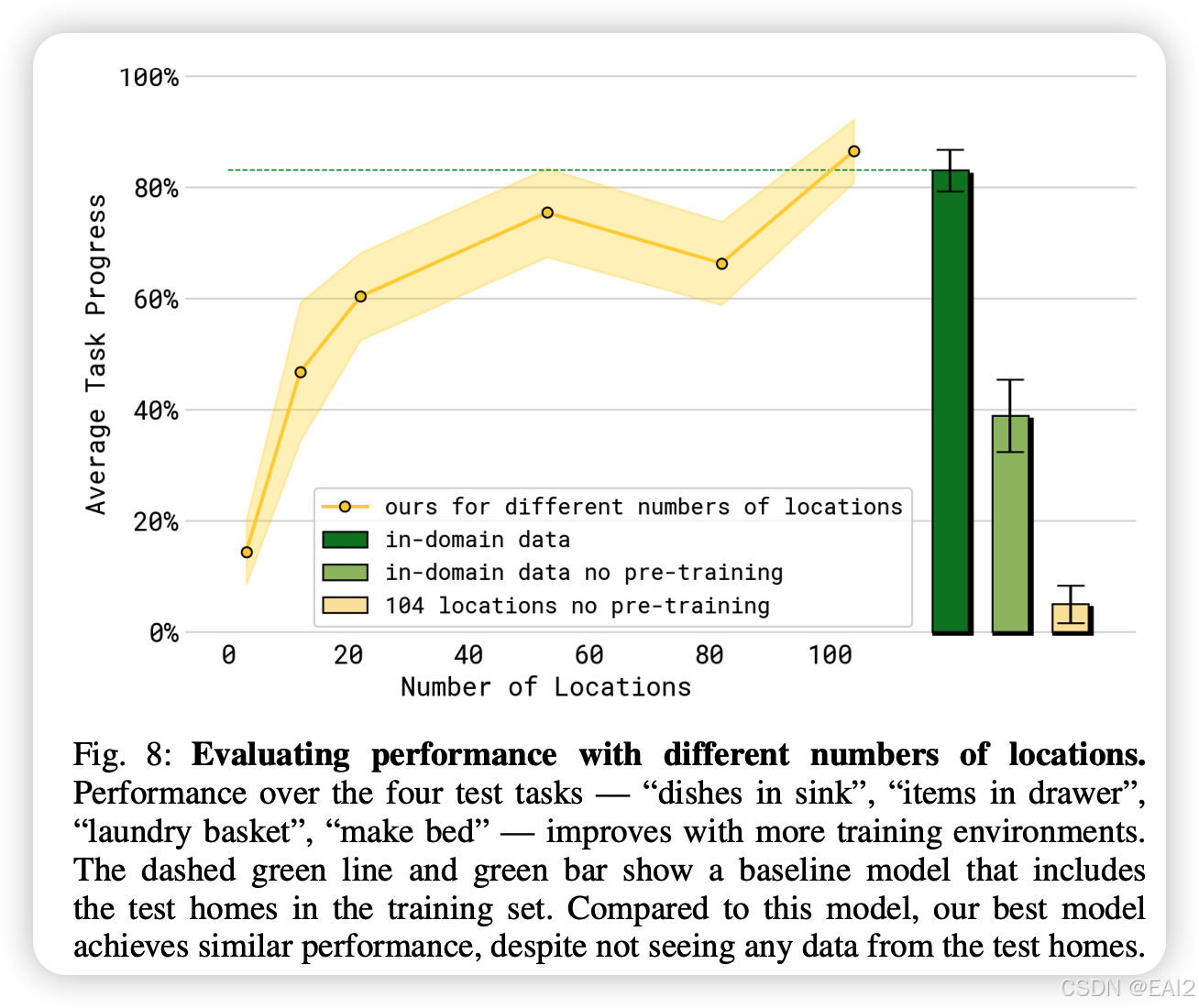
结果:泛化能力随训练环境数量增加而提升。包含 104 个地点的模型性能接近于直接在测试环境中训练的 Oracle 模型(绿色虚线) 。
4.2 数据配比消融 (Ablation Study)
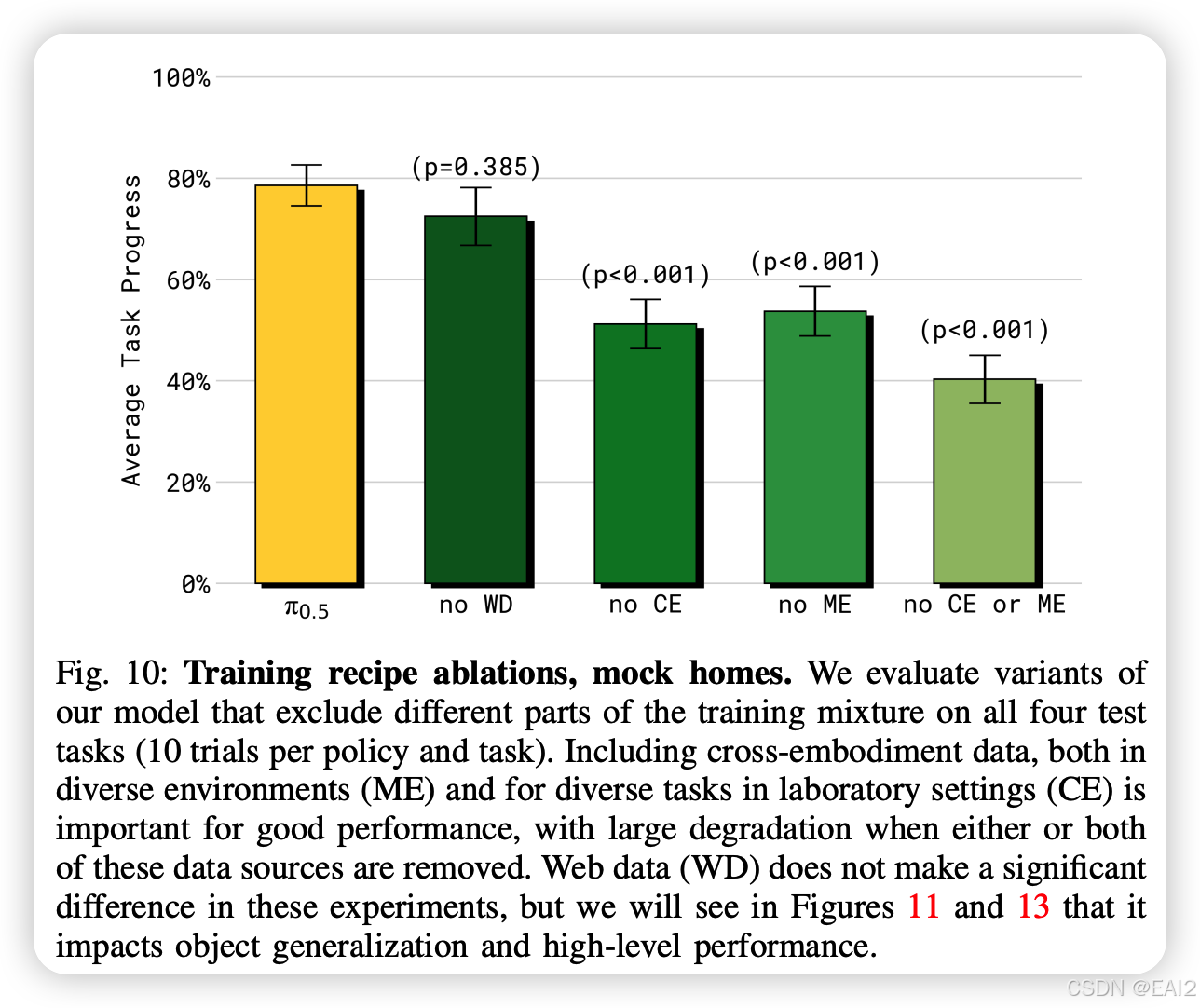
跨形态数据 (ME & CE) 至关重要:去掉其他机器人数据导致性能大幅下降(p<0.001),证明了从非目标形态机器人迁移知识的有效性 。
Web 数据 (WD) 的作用:虽然在总体任务进度上影响看似较小,但在涉及未见物体(Out-of-Distribution Objects)的语言指令跟随任务中,去掉 Web 数据会导致显著失败(论文 Figure 11) 。
4.3 高层推理的重要性
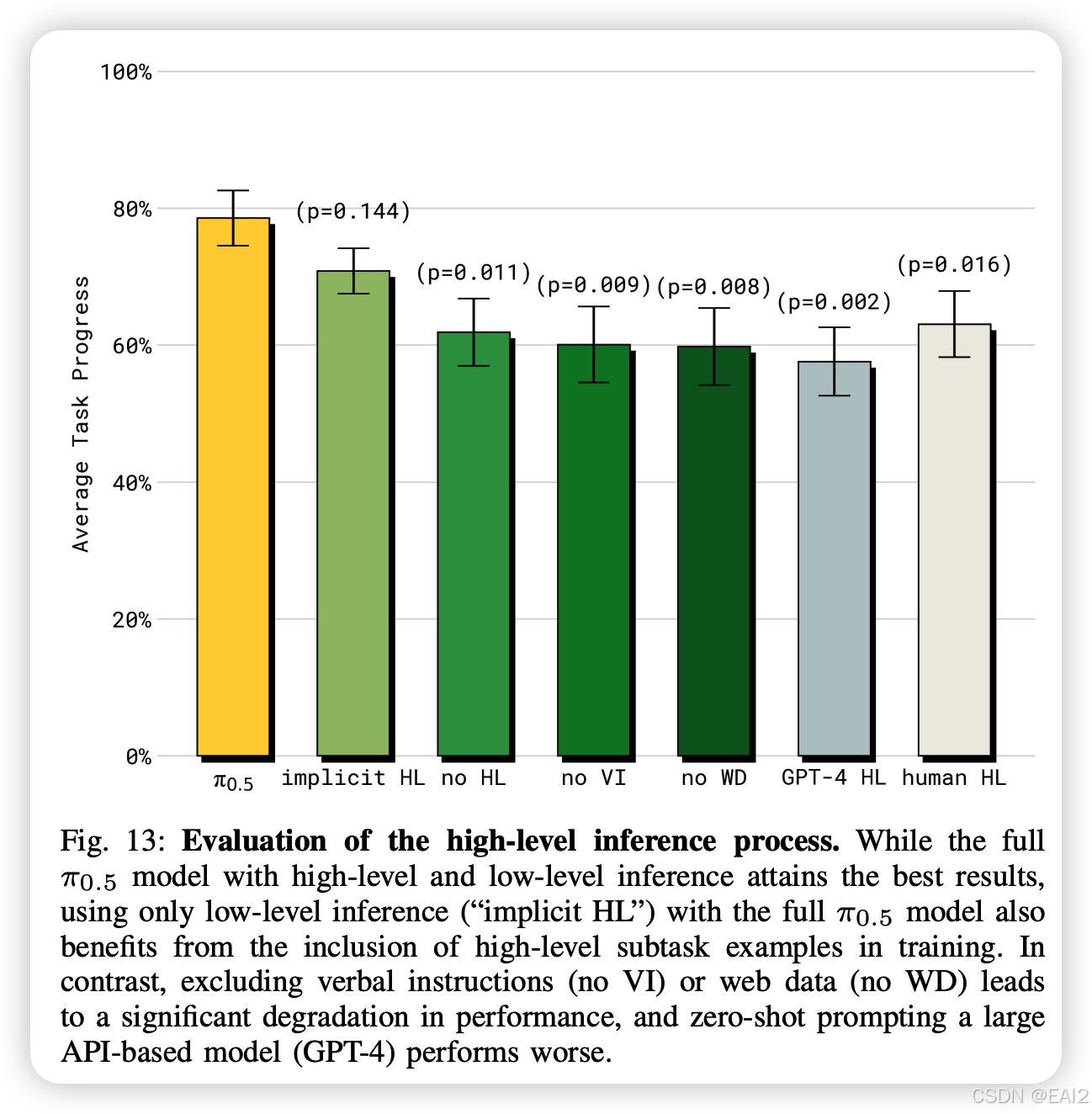
显式推理最优:显式预测子任务的 性能最佳。
隐式推理依然有效:即使推理时不输出子任务(Implicit HL),只要训练时包含 HL 数据,性能也优于完全不使用 HL 数据的模型 。
GPT-4 的局限:直接调用 GPT-4 进行高层规划(Zero-shot)的效果不如经过机器人数据微调的 VLA 模型 。
5. 关键结论、局限性和未来演进方向
5.1 关键结论
异构性是关键 (Heterogeneity is Key):实现真实世界泛化的关键不是仅仅堆砌单一机器人的数据,而是通过 Co-training 整合跨形态机器人数据、Web 数据和语义推理数据 。
分层 VLA (Hierarchical VLA):统一模型既做 Planner 又做 Controller(High-level -> Action)是可行的,且优于分离的架构 。
混合训练 (Hybrid Training):预训练用离散 Token(快、规模大),后训练用 Flow Matching(准、平滑)是训练高性能 VLA 的有效范式 。
5.2 局限性
提示词简单:目前只能处理相对简单的 Prompt,无法处理极其复杂的偏好或约束 。
物理交互限制:在处理未见过的复杂物理机构(如奇怪的把手)时仍会失败 。
上下文长度:模型 Context 有限,难以处理需要长时间记忆的任务(如跨房间导航) 。
5.3 未来演进方向
更丰富的上下文与记忆:引入更长的 Context Window 或记忆机制 。
口头指导:进一步探索通过自然语言与人类互动的监督方式 。
更广泛的数据源:探索更多样化的异构数据组合 。