12月31日晚间,DeepSeek团队发布了一篇新论文,提出了一种名为mHC(流形约束超连接)的新架构。该架构解决了传统超连接(Hyper-Connections, HC)引发的信号爆炸与梯度不稳定问题。
DeepSeek创始人兼CEO梁文锋这次同样出现在合著名单中。

要了解论文提出的mHC,就不得不先说下残差连接。残差连接(Residual Connection)是深度学习领域的革命性创新: - 解决了超深层网络训练的梯度消失/爆炸问题。它最早由何恺明等人在2015年提出的 ResNet(Residual Network)中系统性地引入,并取得了显著效果。
为什么需要残差连接?
在训练非常深的神经网络时,人们发现:
- 网络深度增加后,训练误差反而上升(称为"退化问题");
- 并非过拟合,而是优化困难,导致性能不升反降;
- 传统的"逐层堆叠"方式限制了信息流动,尤其是梯度反向传播。
好比我们玩的传话游戏一样,第一个人说一句话传给第二个人,第二个人依次往下传播,当传播到第十个人的时候,原来的话已经变味了,丢失或者已经改变原有意思。深层的深度学习跟这个很像,训练的层数越多,**信息(尤其是最初的输入数据意义)在传播过程中丢失和扭曲得就越严重。**残差连接就是在传话的同时,把第一个人的话再直接传给第十个人,第十个人可以用第一个人的话纠正上一个人传的话。这样就防止了信息的丢失,可以让网络的层数堆叠的更深,训练出更好的模型。
HC:追求更灵活的特征融合机制
然而,随着模型规模扩大,研究者开始探索更复杂的连接拓扑。Hyper-Connections(HC)便是代表之一------它将残差路径扩展为多通道、多映射的高维结构,通过可学习的线性变换重组输入与输出特征,显著提升模型表达力。
但代价是:HC打破了恒等映射约束 。DeepSeek 实验发现,在 27B 参数模型中,HC 的残差映射在反向传播时可将信号放大近 3000 倍,导致严重梯度爆炸、训练损失震荡甚至发散。同时,HC 还带来更高的 GPU 显存占用与通信开销,限制其在超大规模场景的实用性。
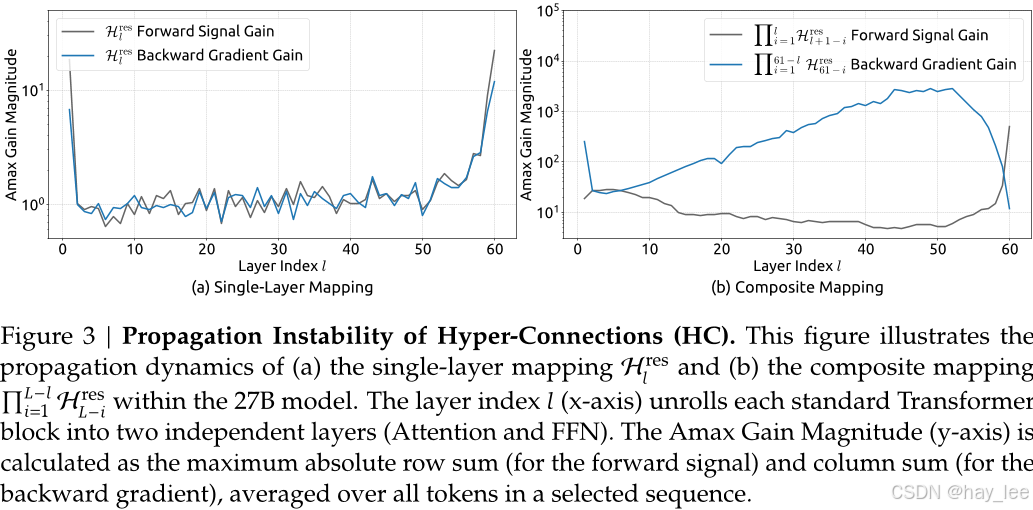
这就好比残差连接是一天单行道,hc直接修了一条多行道的高速公路,但是它没有划分车道,没有约束,时不时会出现很多车祸导致交通堵塞。
"性能提升了,但模型训练却不稳定了。"------这是当前大模型架构探索中的普遍困境。
DeepSeek提出mHC:用"双随机流形"重建稳定性
DeepSeek 的解决方案极具几何直觉:不对残差映射"放任自流",而是将HC中的残差映射矩阵投影到双随机矩阵构成的"流形空间",在保留拓扑表达力的同时,恢复原始残差连接的恒等映射性质。
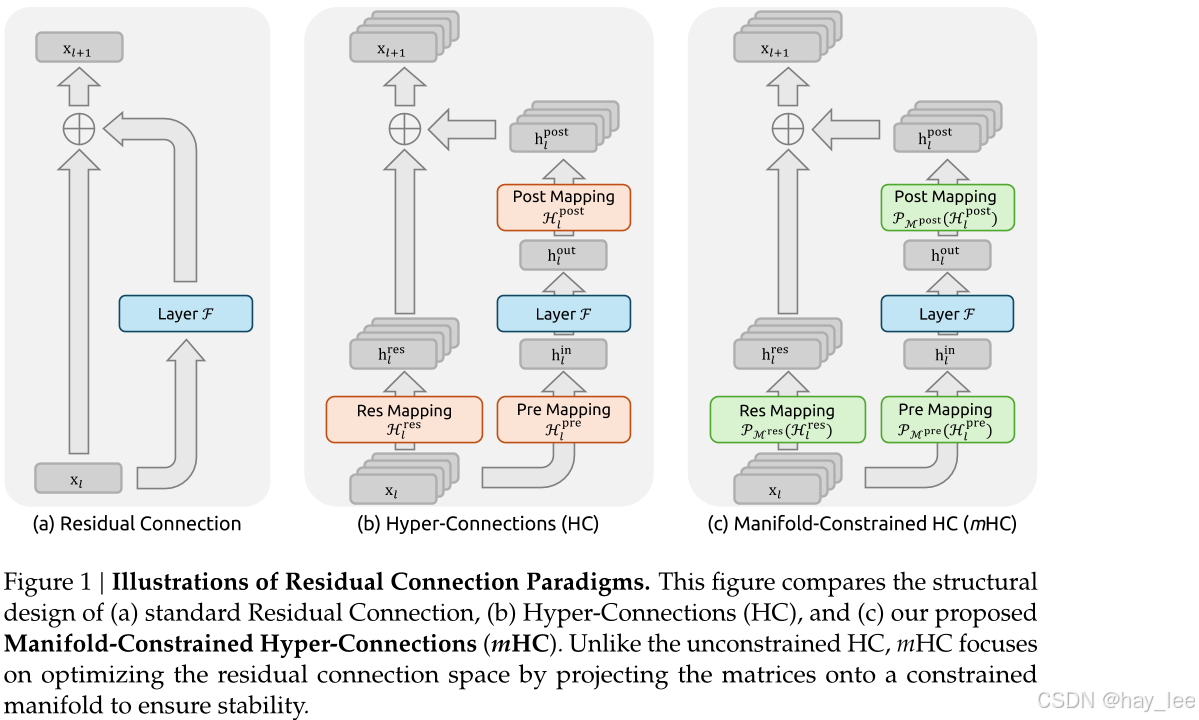
具体而言,mHC利用Sinkhorn-Knopp算法对Hes进行熵投影,使其落入Birkhoff多面体中。这一操作有效地将残差连接矩阵约束在由双随机矩阵构成的流形内。由于这些矩阵的行和列之和均等于1,因此Hesxi可视为输入特征的凸组合。这种特性有助于实现条件良好的信号传播:一方面,特征均值得以保持;另一方面,信号范数得到严格正则化,从而有效缓解了信号消失或爆炸的风险。此外,由于双随机矩阵的矩阵乘法具有封闭性,复合映射IH同样保留了这一保真特性。因此,mHC能够有效维持任意深度间恒等映射的稳定性。为了确保计算效率,我们采用了核融合技术,并基于TileLang开发了混合精度核。此外,他们还通过选择性重新计算以及在DualPipe调度中精心安排通信重叠,进一步降低了内存占用。
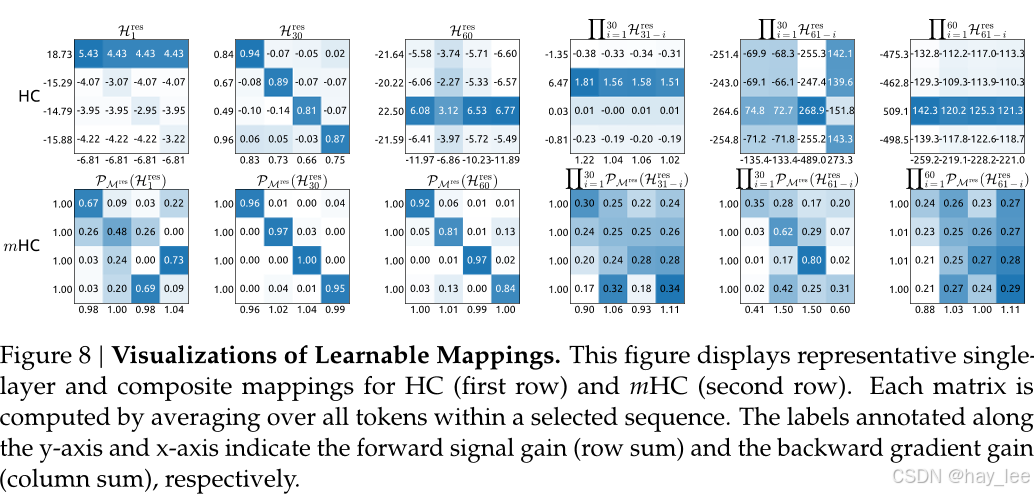
mHC对应的残差映射矩阵更集中于1附近,反观HC则存在多个爆炸点。
mHC就像对HC多行道的高速公路加了车道约束。
结果:mHC 的复合信号增益被控制在 1.6 倍 ,远低于 HC 的 3000 倍,逼近理想恒等映射的稳定性。
实测验证
DeepSeek 在 27B 参数规模下对比了 Baseline(标准残差)、HC 与 mHC 三种架构:
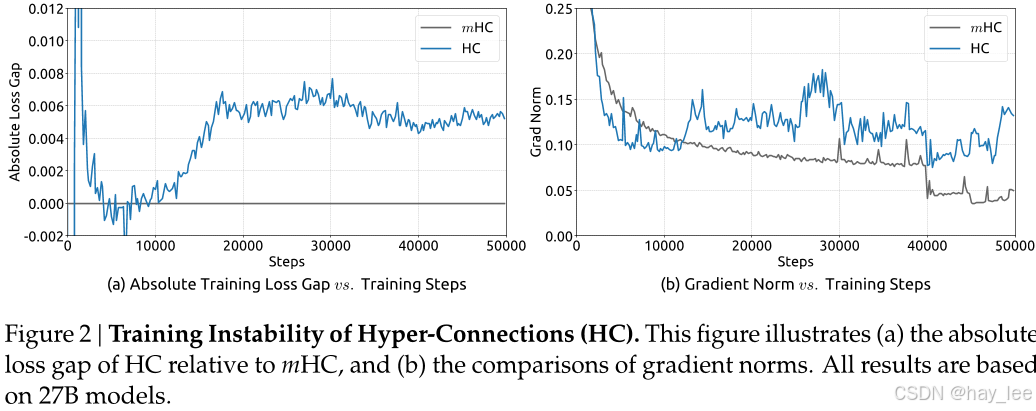
训练稳定性:
HC 训练中损失剧烈震荡;mHC 则平稳收敛,梯度范数稳定,无爆炸现象。
下游任务表现:
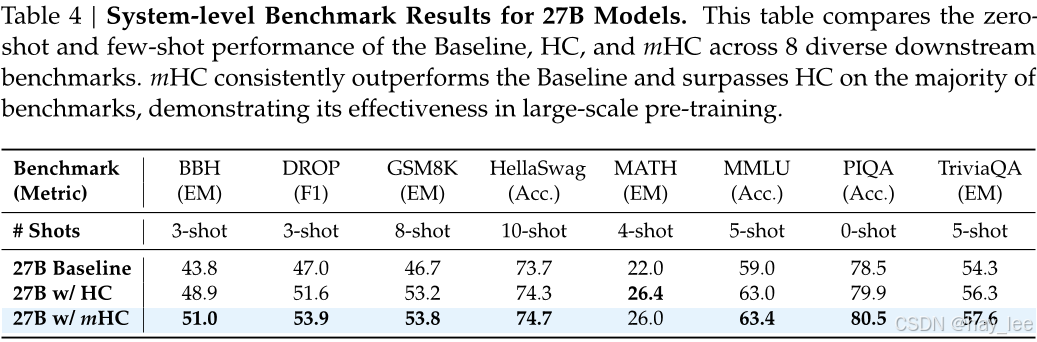
mHC 在 8 项关键基准上全面超越 HC 和 Baseline:
-
BBH(复杂推理):51.0 vs 48.9(+2.1%)
-
DROP(阅读理解):53.9 vs 51.6(+2.3%)
-
GSM8K、MATH、MMLU 等任务也取得显著提升。
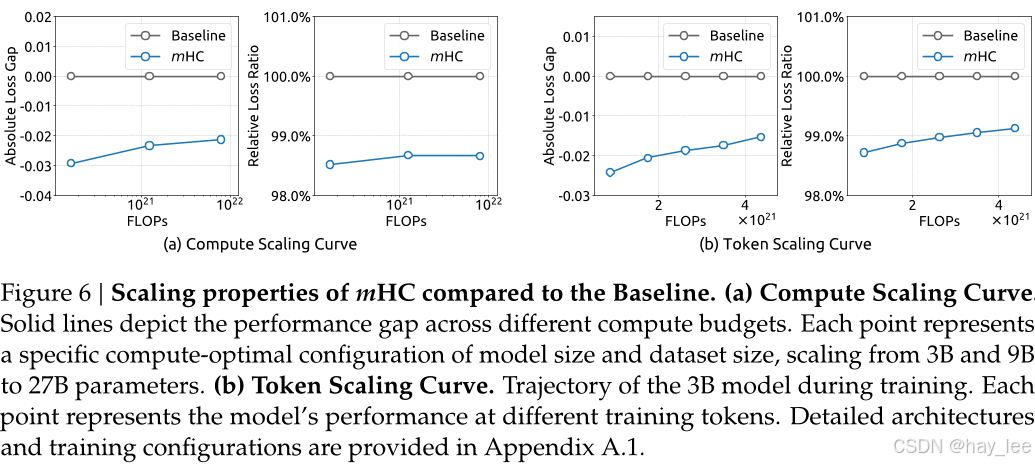
可扩展性 :
从 3B 到 27B,mHC 的性能增益随模型规模扩大而增强,证明其在深层大模型中更具适配性。在 1T token 训练下未出现过拟合,泛化能力优异。
系统效率:
尽管引入流形投影,mHC 通过内核融合、重计算、通信重叠 等工程优化,在扩展因子 n=4n=4 时仅增加 6.7% 训练时间开销,GPU 利用率超 90%,具备高工程可行性。
未来展望
DeepSeek 团队指出,mHC 并非终点,而是一个通用框架:
"双随机约束只是起点,未来可针对不同任务设计特定流形,在表达能力与稳定性之间实现更优权衡。"
更重要的是,mHC 重新将学界注意力拉回宏观架构设计 ------在"堆数据、堆参数"之外,对连接拓扑的几何与动力学理解,或将成为突破当前大模型瓶颈的关键。
论文地址:https://arxiv.org/pdf/2512.24880
大模型相关课程:
|----|---|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | 一 | 1.大模型的发展与局限性 |
| 2 | 二 | 1.1 ollama本地快速部署deepseek |
| 3 | 二 | 1.2 linux本地部署deepseek千问蒸馏版+web对话聊天 |
| 4 | 二 | 1.3 linux本地部署通义万相2.1+deepseek视频生成 |
| 5 | 二 | 1.4 Qwen2.5-Omni全模态大模型部署 |
| 6 | 二 | 1.5 Stable Diffusion中文文生图模型部署 |
| 7 | 二 | 1.6 DeepSeek-OCR部署尝鲜 |
| 8 | 二 | 2.1 从零训练自己的大模型概述 |
| 9 | 二 | 2.2 分词器 |
| 10 | 二 | 2.3 预训练自己的模型 |
| 11 | 二 | 2.4 微调自己的模型 |
| 12 | 二 | 2.5 人类对齐训练自己的模型 |
| 13 | 二 | 3.1 微调训练详解 |
| 14 | 二 | 3.2 Llama-Factory微调训练deepseek-r1实践 |
| 15 | 二 | 3.3 transform+LoRA代码微调deepseek实践 |
| 16 | 二 | 4.1 文生图(Text-to-Image)模型发展史 |
| 17 | 二 | 4.2 文生图GUI训练实践-真人写实生成 |
| 18 | 二 | 4.3 文生图代码训练实践-真人写实生成 |
| 19 | 二 | 5.1 文生视频(Text-to-Video)模型发展史 |
| 20 | 二 | 5.2 文生视频(Text-to-Video)模型训练实践 |
| 21 | 二 | 6.1 目标检测模型的发展史 |
| 22 | | 6.2 YOLO模型训练实践及目标跟踪 |
| 23 | 三 | 1.1 Dify介绍 |
| 24 | 三 | 1.2 Dify安装 |
| 25 | 三 | 1.3 Dify文本生成快速搭建旅游助手 |
| 26 | 三 | 1.4 Dify聊天助手快速搭建智能淘宝店小二 |
| 27 | 三 | 1.5 Dify agent快速搭建爬虫助手 |
| 28 | 三 | 1.6 Dify工作流快速搭建数据可视化助手 |
| 29 | 三 | 1.7 Dify chatflow快速搭建数据查询智能助手 |
| 30 | 三 | 2.1 RAG介绍 |
| 31 | 三 | 2.2 Spring AI-手动实现RAG |
| 32 | 三 | 2.3 Spring AI-开箱即用完整实践RAG |
| 33 | 三 | 2.4 LlamaIndex实现RAG |
| 34 | 三 | 2.5 LlamaIndex构建RAG优化与实践 |
| 35 | 三 | 2.6 LangChain实现RAG企业知识问答助手 |