一、K-means
1.基本概念
聚成多少个簇:需要指定K的值
距离的度量:一般采用欧式距离
距离:
曼哈顿距离: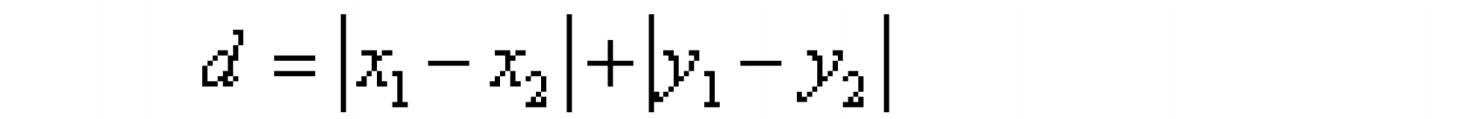
欧式距离:

2.聚类效果的评价方式:轮廓系数
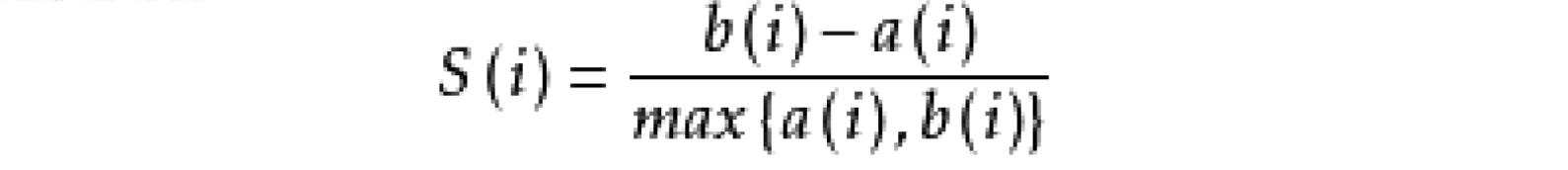
a(i):对于第i个元素xi,计算xi与其同一个簇内所有其他元素距离的平均值,表示了簇内的凝聚程度。
b(i):选取xi外的一个簇,计算xi与该簇内所有点距离的平均距离,遍历其他所有簇,取所有平均值中最小的一个,表示簇间的分离度。
计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数。
轮廓系数的评价:
1.轮廓系数范围在-1,1之间。该值越大,越合理。
2.si接近1,则说明样本i聚类合理;
3.si接近-1,则说明样本i更应该分类到另外的簇;
4.若si近似为0,则说明样本i在两个簇的边界上。
3.K-means的API参数
class sklearn.cluster.KMeans (n_clusters=8 , init='kmeans++' , n_init=10 , max_iter=300 , tol=0.0001 , precompute_distances='auto' , verbose=0 , random_state=None , copy_x=True , n_jobs=None , algorithm='auto' )source
n_clusters: 类中心的个数,就是要聚成几类。【默认是8个】
init : 参初始化的方法,默认为'k-means++'
(1)'k-means++': 用一种特殊的方法选定初始质心从而能加速迭代过程的收敛.
(2) 'random': 随机从训练数据中选取初始质心。
(3) 如果传递的是一个ndarray,则应该形如 (n_clusters, n_features) 并给出初始质心。
4.优缺点
优点:简单,快速,适合常规的数据集。
缺点:1.K值难以确定。2.很难发现任意形状的簇。
二、DBSCAN
1.概念
基于密度的带噪声的空间聚类应用算法,它是将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并在噪声的空间数据集中发现任意形状的聚类。
2.实现过程
1.输入数据集
2.指定半径
3.指定密度阈值
3.DBSCAN的API参数
class sklearn.cluster.DBSCAN (eps=0.5 , min_samples=5 , metric='euclidean' , metric_params=None , algorithm='auto' , leaf_size=30 , p=None , n_jobs=None )
eps: DBSCAN算法参数,即我们的ϵϵ-邻域的距离阈值,和样本距离超过ϵϵ的样本点不在ϵϵ-邻域内。默认值是0.5.一般需要通过在多组值里面选择一个合适的阈值。eps过大,则更多的点会落在核心对象的ϵϵ-邻域,此时我们的类别数可能会减少, 本来不应该是一类的样本也会被划为一类。反之则类别数可能会增大,本来是一类的样本却被划分开。
min_samples: DBSCAN算法参数,即样本点要成为核心对象所需要的ϵϵ-邻域的样本数阈值。默认值是5. 一般需要通过在多组值里面选择一个合适的阈值。通常和eps一起调参。在eps一定的情况下,min_samples过大,则核心对象会过少,此时簇内部分本来是一类的样本可能会被标为噪音点,类别数也会变多。反之min_samples过小的话,则会产生大量的核心对象,可能会导致类别数过少。