本文通过手机网购实战案例,深度拆解GUI Agent大模型利用PPO强化学习更新参数的核心逻辑。

1 强化学习架构
1.1 理解Agent的角色分工

GUI Agent大模型(图形用户界面智能体)的学习过程,本质上是一场没有标准答案的填空题考试。
✅ Actor(策略模型)
Actor 是这场考试的考生。在本文的案例中,它是一个具备视觉能力的大模型(如 Qwen3-VL)。它的职责是观察环境(手机屏幕),并根据当前的题目填写答案(做出点击、滑动等动作)。
✅ Critic(价值模型)
Critic 是 Actor 的辅导老师兼裁判。它不直接参与操作,而是根据以往的训练数据和经验,对当前界面的难度进行预估,并在事后对 Actor 的表现进行打分。
1.2 场景设定:Qwen3-VL的网购挑战

设定一个具体的 GUI 任务场景来贯穿全文:
-
用户指令:帮我买一箱苹果。
-
当前状态 (State):手机屏幕显示着购物 APP 的首页,顶部有一个显眼的红色搜索框。
在这个瞬间,Actor 需要决定下一步做什么。这就是强化学习循环的起点。
2 交互循环与优势计算
2.1 第一步:Actor 的概率选择
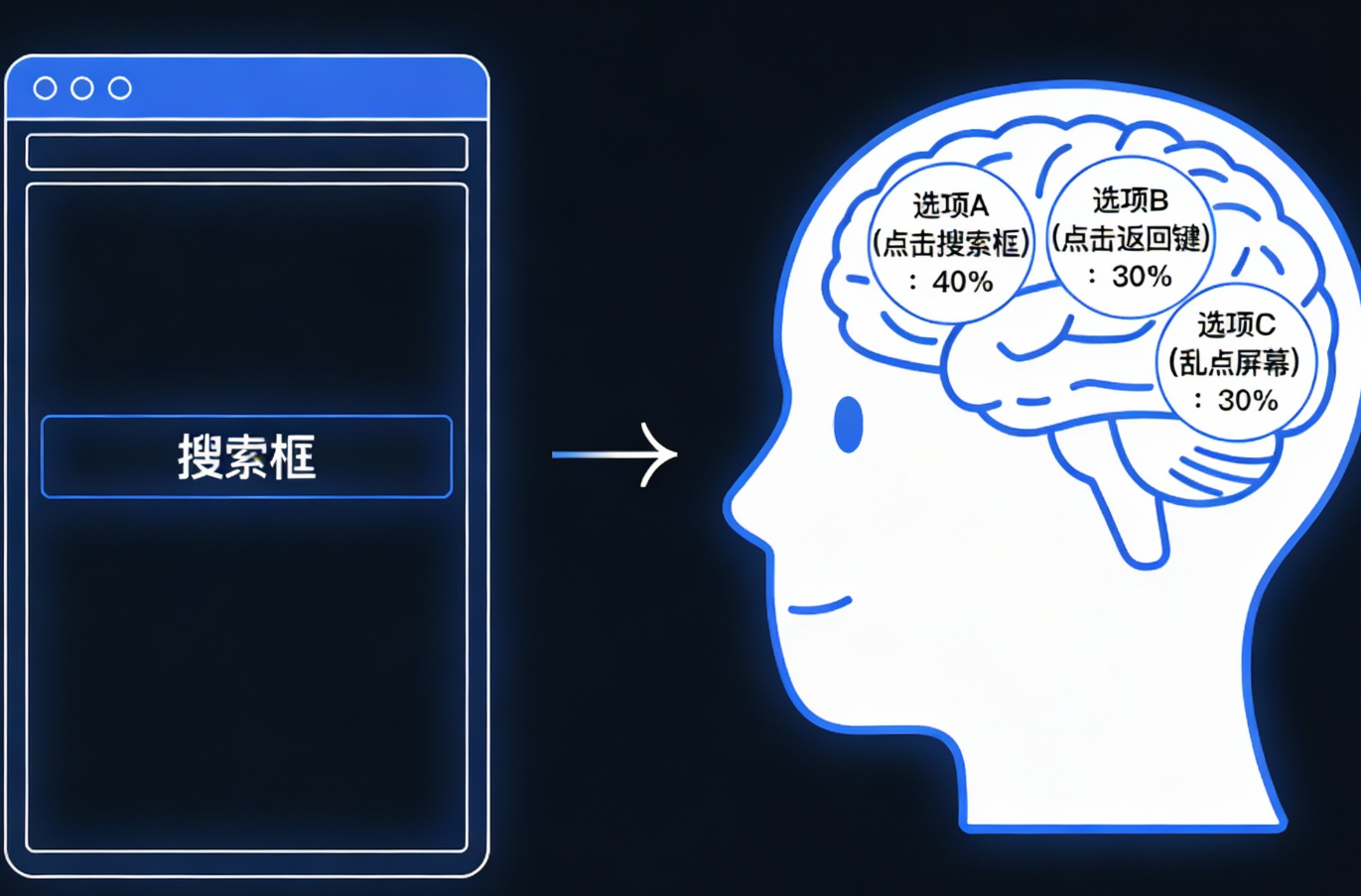
面对屏幕上的搜索框,Actor 并不是百分之百确定该做什么,它的大脑(神经网络)会计算出不同操作的概率分布:
-
选项 A(点击搜索框):概率 40%
-
选项 B(点击返回键):概率 30%
-
选项 C(乱点屏幕):概率 30%
Actor 执行了点击搜索框的操作。模型并不知道这个选择是对是错,它只是根据当前的参数做出了选择。
2.2 第二步:Value Model 的预期
在动作执行的同时,作为辅导老师的 Value Model 也在观察屏幕。它基于历史经验,给出了一个预期值。
-
老师的独白 :这个购物首页通常比较复杂,干扰项很多。根据我对你(Actor)过去表现的了解,在这个状态下,你平均能拿 5分。
-
数学表达:
这个5分非常重要,它代表了基准线。后续所有的评价,都要看是否超过了这个基准。
2.3 第三步:环境反馈与裁判打分
Actor 执行点击搜索框后,手机界面发生了变化,搜索历史显示了出来。此时,环境反馈介入,训练好的高精度 Critic(裁判)给出了实际奖励 (Reward)。
-
裁判的评价:干得漂亮!进入搜索是买苹果的关键一步,逻辑完全正确。
-
数学表达:
2.4 第四步:优势函数Advantage
这是 PPO 算法中最具灵魂的一步。单纯知道得了8分是不够的,需要知道这8分含金量如何。我们需要计算 Actor 的表现是否超出了预期。
优势实际得分预期值
这个 +3 就是优势。它的物理含义是:你这次的操作比平常(预期)要好了 3 分!。如果是正数,说明这是一个惊喜 ,应当鼓励。如果是负数,说明这是一个失误,应当抑制。
2.5 延迟满足与稀疏奖励
假设点击搜索框立刻得到了 8 分。但在真实的 GUI 场景中,需要一种机制,把第 10 步得到的 100 分,回传 给第 1 步,告诉它:虽然你当时没拿分,但你是后面成功的功臣。这就是 GAE 的使命。
在构建 GAE 之前,我们需要引入两个参数:
-
(Gamma, 折扣因子):比如 0.99。意思是未来的 100 分,折算到现在可能只有 99 分(未来贬值)。
-
:Critic 对下一步状态的估分。
我们不再单纯看实际得分,而是看即时得分 + 下一步的潜力 。这被称为 TD Error ():
当前奖励未来预期当前预期
2.6 GAE 公式:加权累积
单看一步 () 波动太大(方差高),看完整场游戏再算总账(蒙特卡洛)又太慢(偏差大)。GAE 引入了一个精妙的参数 (Lambda) 来平衡这两者。这是一个递归累加的过程:
(Lambda):通常取 0.95。它决定了我们看多远。如果 :只看眼前一步(TD)。如果 :一直看到游戏结束(MC)。:主要看眼前,但也兼顾长远。
2.7 实战演算:回到买苹果场景
用 GAE 重新审视点击搜索框的优势计算。
设定: ,T时刻(点击搜索框) :即时奖励 。Critic 对当前的预期 。Critic 对下一步(弹出键盘)的预期 (Critic 意识到情况变好了!)。
第一步:计算局部的惊喜 (),,没得分,但状态变好了,带来了 +4 的惊喜。
第二步:计算 GAE 优势 (),假设下一时刻 () 的优势 经计算为 +2(后续步骤也表现不错)。,。
最终结论:简化版 算出的优势是 -5 (以为是错的)。GAE 版 算出的优势是 +5.62(正确识别出这是好动作)。
3 参数更新机制
3.1 PPO 更新的核心逻辑
当算出了优势 后,下一步就是修改 Actor 的神经元连接(参数 ),让它变聪明。
因为优势是正的 (+3)说明点击搜索框是个好动作,我们要增加这个动作在未来被选中的概率。
如果我们将时间快进,看看参数更新后的效果:
-
更新前概率:点击搜索框 (40%)、点击返回 (30%)、乱点 (30%)。
-
更新后概率:点击搜索框 (55% )、点击返回 (22.5% )、乱点 (22.5% )。
这就达到了我们的目的:模型记住了正确的操作。
3.2 假如搞砸了:负优势的处理
为了完整理解,我们假设 Actor 最初手滑选了 选项 B(点击返回键)。
-
预期 (Value):依然是 5 分(因为题目没变)。
-
实际 (Reward) :裁判判定任务失败(退出了APP),给出 -2分。
-
计算优势:
结果:优势是负数。数学公式会自动运作,让点击返回键这个动作的概率从 30% 降到 10%。模型通过惩罚学会了避坑。
3.3 PPO 的P:近端策略优化
既然 ,为什么不直接把概率拉满到 99%?这就是 PPO (Proximal Policy Optimization) 中 Proximal(近端/限制范围) 的智慧。Clip(裁剪机制):
-
普通 RL 的风险:如果步子迈得太大,万一这次成功只是运气好呢?直接把概率改到 99% 会导致模型过拟合甚至训练崩塌。
-
PPO 的策略 :即便优势很大,我限制你每次最多只能修改 20% 的幅度。
4 从标量乘向量看更新本质
4.1 参数更新公式
在代码底层,参数更新遵循以下简化公式:
新参数旧参数学习率优势力度与方向梯度如何增加概率
这里涉及两个核心数学对象的交互:
-
梯度 ():它是一个向量。含义是如果我想让刚才那个动作的概率变大,参数里的权重应该怎么改?
-
优势 ():它是一个标量。含义是这个动作到底好不好?好就乘正数(照做),不好就乘负数(反着来)。
4.2 微观计算演示:权重 为例
假设 Actor 模型极度简化,内部只有一个关键权重 。
-
情境:在 时,模型选择点击搜索框的概率是 40%。
-
反向传播 :计算出的梯度值是 +0.5。
梯度的含义:如果把 增加一点,动作概率就会上升。
假设优势为正 (),设定学习率 。
权重变大了,动作概率随之上升。模型受到正向激励。这就是利用梯度更新参数的本质:利用梯度的方向性,配合优势的正负号和大小,来精准调节动作发生的概率。
5 强化学习与监督学习差异
5.1 为什么 RL 需要乘一个优势?
在监督学习中直接算 Loss,没见过要乘什么优势值。
-
监督学习:梯度本身包含了错了多少(误差)。
-
强化学习:梯度只包含了方向,必须人为乘上好坏程度(优势)。
在分类任务(如辨别猫狗)中:预测0.6(猫);真值1.0(猫);梯度中的隐含项为预测真值。
误差本身决定了步长,不需要额外的乘数。
5.2 强化学习:黑夜中的探索
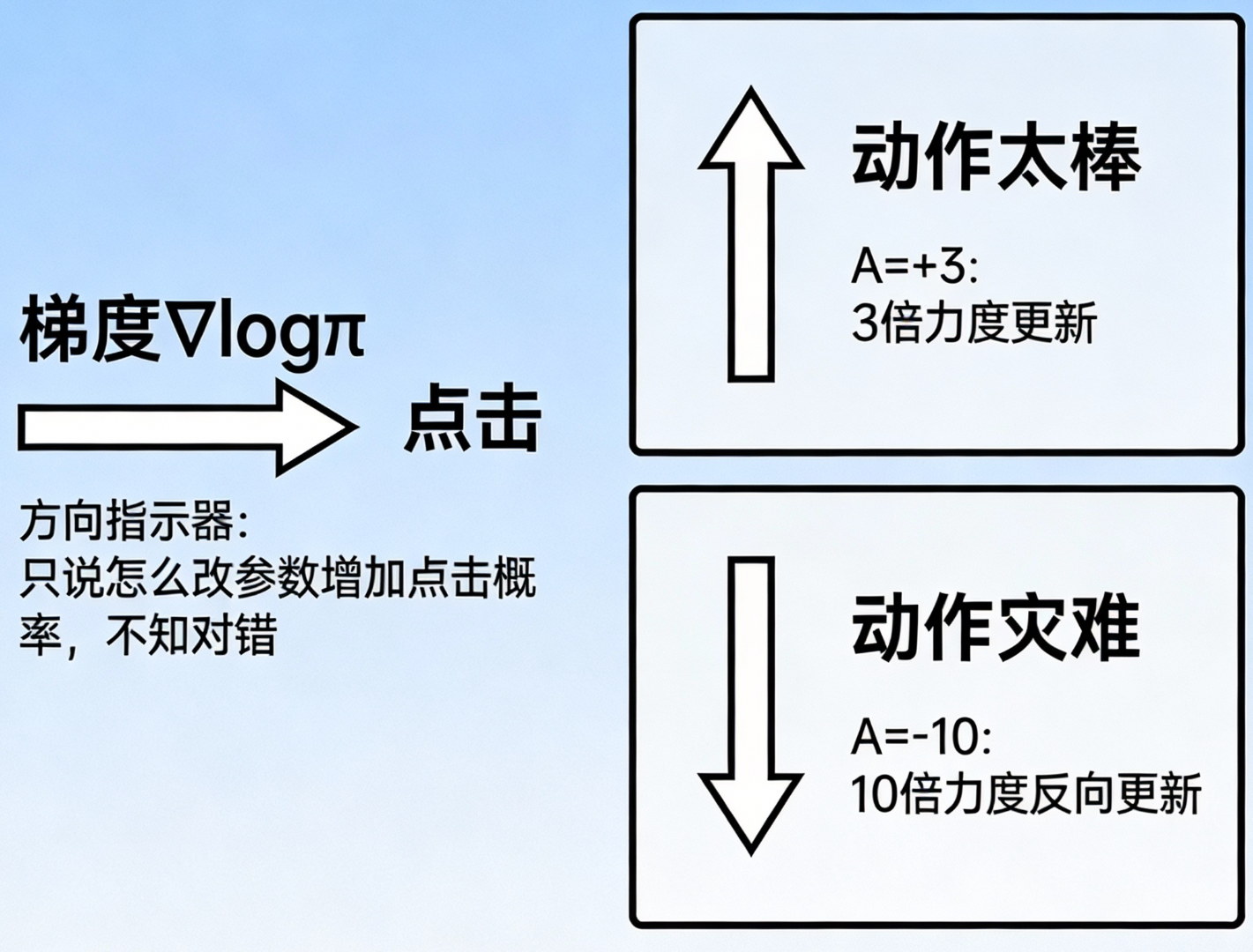
在 GUI 操作中,没有标准答案告诉模型这一步必须点哪里。模型只能试探。
梯度的局限性 :RL 中的梯度 纯粹是一个方向指示器。它只告诉你怎么改参数能增加'点击'的概率,但它完全不知道点击是对还是错。
优势函数的作用:
-
:告诉梯度,刚才那个动作太棒了,请以 3 倍力度执行更新!
-
:告诉梯度,刚才那个动作是灾难,请以 10 倍力度反向更新!