摘要
本周的学习重点是增强式学习(Reinforcement Learning, RL)中的Actor-Critic方法。主要深入讲解Actor-Critic框架的核心原理、优势函数的计算、Critic的价值估计方式,以及如何结合Actor和Critic来提升策略学习的稳定性和效率。并且重点围绕Actor-Critic的核心内容展开总结,包括价值函数估计(Monte Carlo vs. Temporal Difference)、优势函数的定义与作用、Actor-Critic的整体框架、训练细节,以及相关扩展如奖励塑造和稀疏奖励处理。
Abstract
This week's learning focus is on the Actor-Critic method in Reinforcement Learning (RL). It centers on an in-depth exploration of the core principles of the Actor-Critic framework, the computation of the advantage function, the value estimation approach of the Critic, and how the integration of Actor and Critic enhances the stability and efficiency of policy learning. The discussion is structured around summarizing key aspects of Actor-Critic, including value function estimation (Monte Carlo vs. Temporal Difference), the definition and role of the advantage function, the overall framework of Actor-Critic, training details, as well as related extensions such as reward shaping and sparse reward handling.
一. Actor-Critic方法的核心框架
Actor-Critic方法是政策梯度(Policy Gradient)算法的重要改进,它通过引入一个独立的Critic网络来估计状态价值函数,从而显著降低政策梯度中的方差问题,使训练过程更加稳定。这在实际应用中(如游戏AI、机器人控制)具有重要意义。
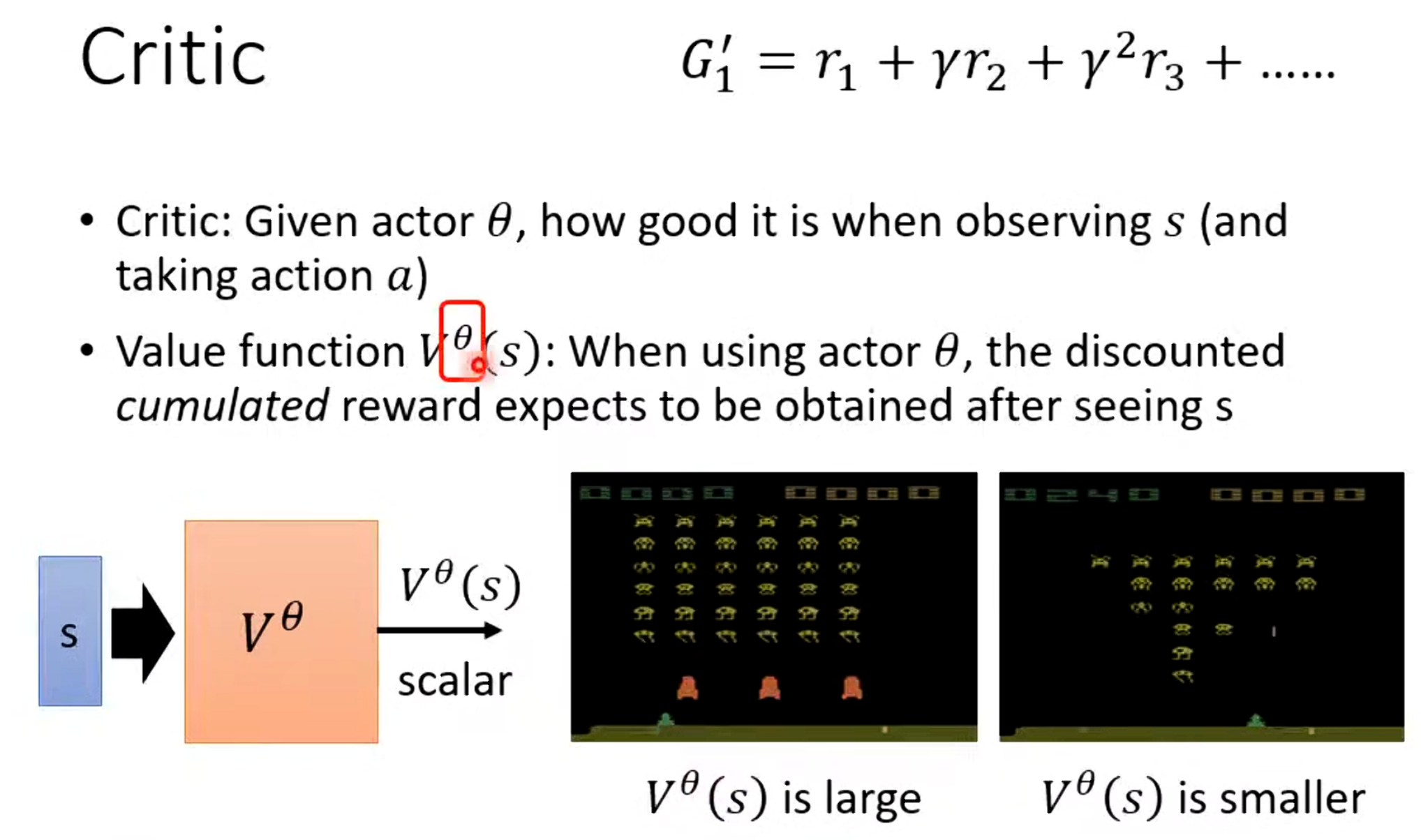
Actor-Critic方法的核心思想是将策略优化分为两个部分:
Actor:即策略网络(Policy Network),负责根据当前状态输出动作概率分布,并采样动作执行。Actor的目标是最大化预期累计奖励。
Critic:即价值网络(Value Network),负责估计从当前状态开始的预期折扣累计奖励(价值函数 )。Critic提供一个"基准"来评估动作的好坏。
在传统政策梯度中,我们直接使用实际回报作为优势来更新Actor,但这会导致高方差(因为实际回报受随机性影响大)。Actor-Critic通过Critic估计的价值函数来构造更稳定的优势函数A(s, a),从而指导Actor的更新。
Actor-Critic结合了政策基方法(Policy-based)的优势(能处理连续动作空间、高维状态)和价值基方法(Value-based)的优势(低方差 bootstrapping)。
二. 价值函数估计:Monte Carlo 与 Temporal Difference
Critic的核心任务是学习价值函数,其中
是折扣累计回报
。
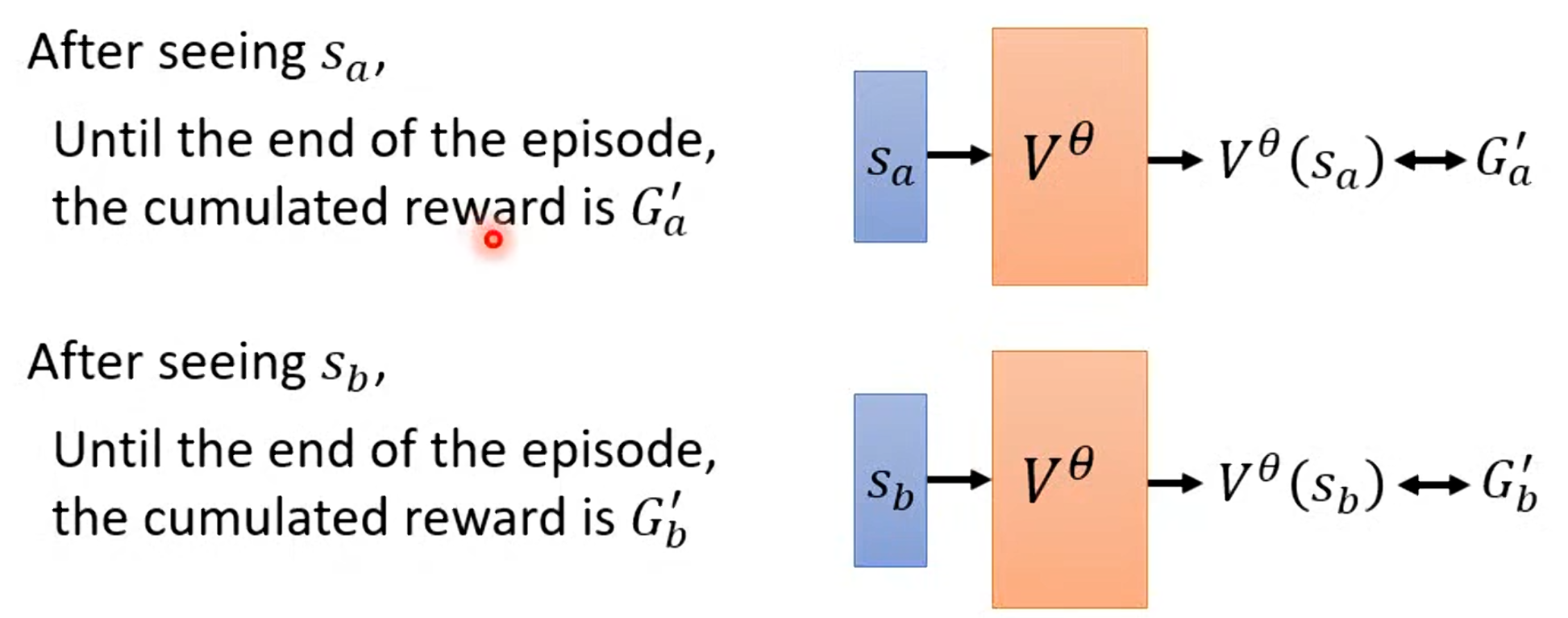
1. Monte Carlo (MC) 方法
通过完整运行一个episode,计算实际折扣回报作为目标。
其更新规则:
其优点:无偏估计(unbiased),真实反映episode回报。
其缺点:方差大(variance high),因为每个episode的随机性不同;必须等到episode结束才能更新(延迟高)。
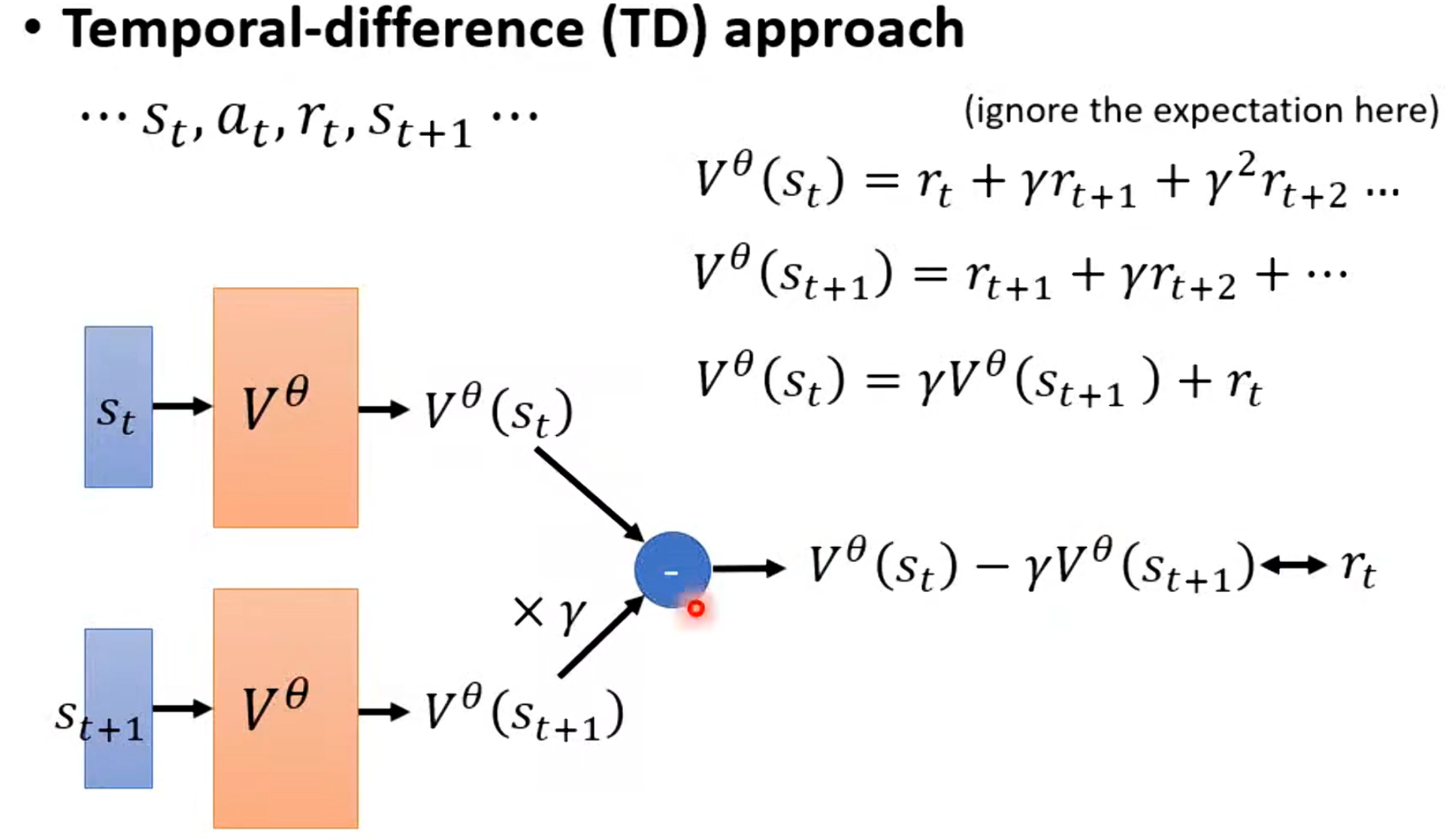
2. Temporal Difference (TD) 方法
使用bootstrapping:当前价值估计部分依赖下一个状态的价值估计。
TD目标:
更新规则:
优点:方差低(low variance),可以在线更新(每步都可学习)。
缺点:有偏估计(biased),因为依赖当前不完美的V估计。
以一个例子来说明:假设某个状态平均回报为0.75,MC需要多episode平均才能接近,而TD可以快速收敛但可能有偏差。视频中指出,在Actor-Critic中,通常采用TD方法来估计价值,因为它更适合与Actor的在线交互。

三. 优势函数(Advantage Function)的定义与作用
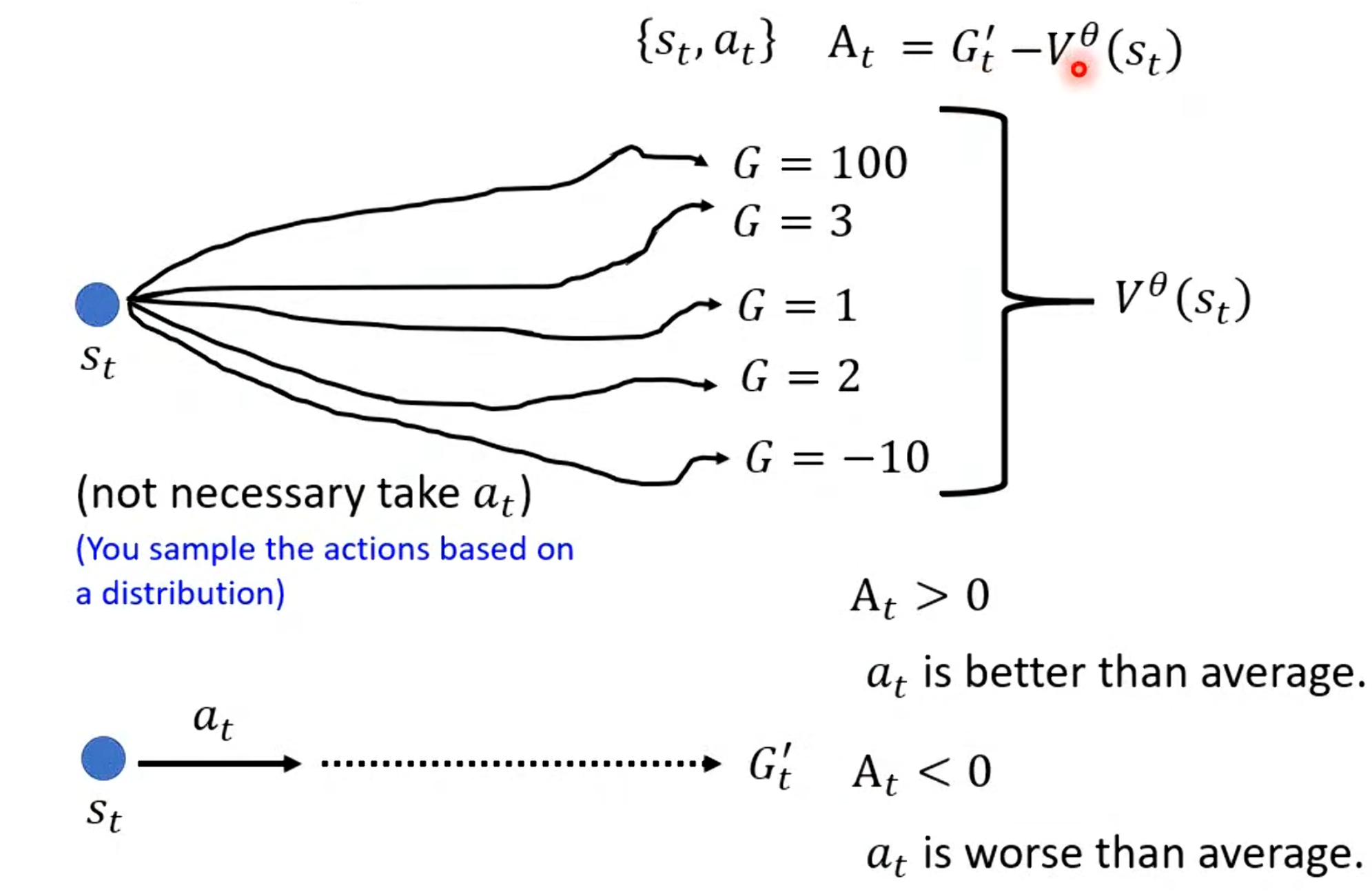
优势函数是Actor-Critic的桥梁,它量化了"在状态s下执行动作a比平均好多少"。
公式:A(s, a) = Q(s, a) - V(s)
其中 Q(s, a)是动作-状态价值函数(预期从s执行a后的回报)。
在实践中:
使用MC:
使用TD(更常见):
其中优势非零的,因为是单次采样值,而V(s)是平均值,二者差值反映了该动作的相对优劣。即使平均回报为零,具体动作仍可能有正/负优势,从而产生梯度信号指导Actor改进。
优势函数的引入大大降低了政策梯度的方差:相比直接用(总是正值,导致梯度方向单一),优势可正可负,提供更精确的信用分配。
Actor的更新损失:,其中
时鼓励该动作,
时抑制。
四. Actor-Critic的整体算法流程与训练细节
Actor-Critic的交互过程如下:
-
Actor根据当前策略从状态
采样动作
-
执行动作,环境返回
-
Critic计算TD误差:
-
使用
Critic网络通常是一个输入状态、输出标量价值的神经网络。Actor是输入状态、输出动作分布的网络。
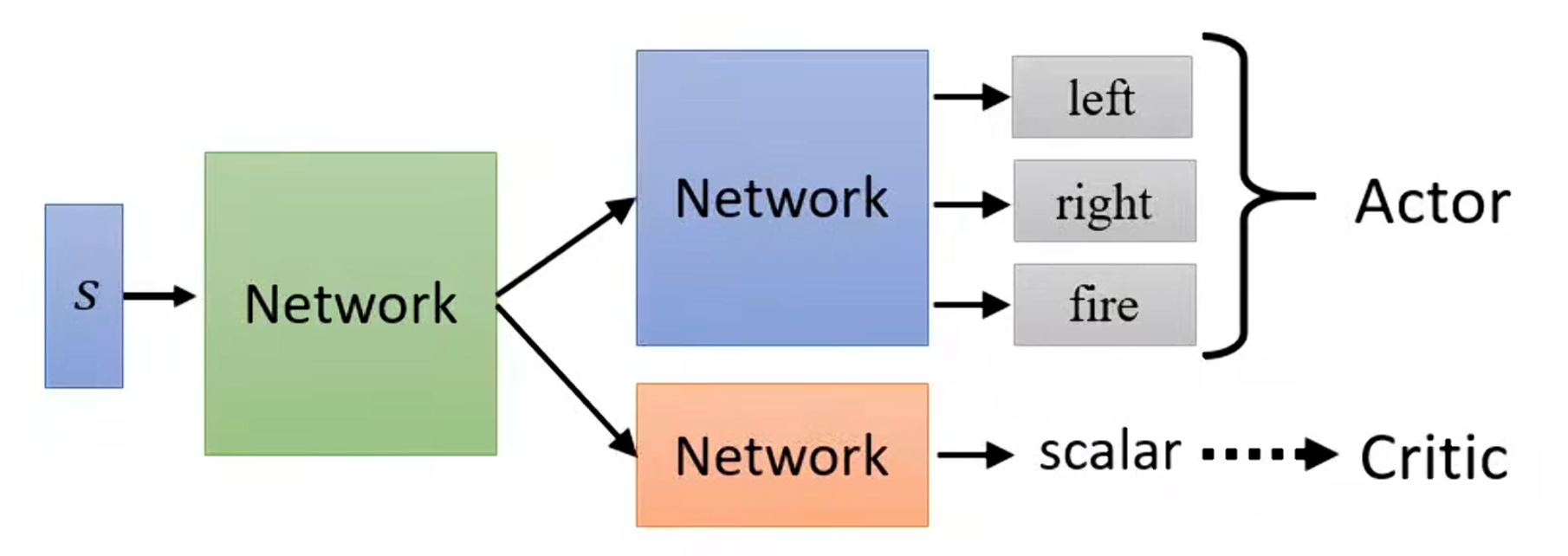
Critic的角色,它不仅仅是"评论家",而是为Actor提供稳定的学习信号。在实际实现中,Actor和Critic可以共享部分网络层(参数共享),减少计算量。
此外,Actor需保持一定随机性(如通过熵正则化),防止过早收敛到次优策略。
五. 奖励塑造与稀疏奖励处理
在稀疏奖励环境下(如围棋,只在结束时有奖励),纯Actor-Critic学习是有困难的。这就要提到奖励塑造(Reward Shaping):人为设计中间奖励信号,引导Agent学习。例如,在射击游戏中,不仅击中敌人给大奖励,还可以为"接近敌人"给小奖励。另一种高级方法就是好奇心机制(Curiosity):将预测误差作为内在奖励,鼓励Agent探索未知状态。这些技巧与Actor-Critic结合,都能显著加速收敛。
总结
Actor-Critic方法作为策略梯度算法的重要演进,通过融合策略基于方法与价值基于方法的优势,显著提升了增强式学习在连续控制与高维状态空间中的训练效率与稳定性。其核心在于利用Critic网络提供低方差的价值估计,并借助优势函数为Actor提供清晰的动作优劣信号,从而实现更精准的信用分配与策略优化。本讲不仅系统阐述了从价值估计、优势计算到整体训练流程的关键技术细节,还探讨了奖励塑造、内在好奇心等应对稀疏奖励挑战的实用策略。