TL;DR
- 场景:DecisionTreeClassifier 过拟合、树太大/内存飙升、样本不均衡需要可控剪枝与权重
- 结论:优先用 max_depth + min_samples_leaf 做基线;0.19+ 用 min_impurity_decrease 替代 min_impurity_split 
- 产出:学习曲线调参流程(按 score 对比)+ 版本矩阵 + 常见错误速查卡

版本矩阵
| 参数 | 版本/说明 |
|---|---|
| max_depth | 0.17 / 1.8(文档)None 时可能长到"叶子纯/无法再分"或受 min_samples_split 约束;工程上用它先把树"截断",降低过拟合与内存占用。 |
| min_samples_leaf | 1.8(文档)控制叶子最小样本数,抑制"只靠极少样本的叶子";官方建议可从 5 起步,int 或 float(比例)都支持。 |
| min_samples_split | 0.17 / 1.8(文档)控制节点允许分裂的最小样本数;同样支持 float(比例)用来适配不同规模数据集。 |
| max_features | 0.17(文档)影响每次分裂评估的特征子集;注意:实现上为找到有效划分,可能会"实际检查超过 max_features"的情况(老版本文档明确提示)。 |
| min_impurity_decrease | 0.19+ / 1.8(文档)0.19 引入:只有当分裂带来的 impurity decrease ≥ 阈值才分裂;用来替代 min_impurity_split。 |
| min_impurity_split | 0.19 起弃用(文档)0.19 起已弃用;在较新版本中可能直接报 "unexpected keyword" 的 TypeError(迁移到 min_impurity_decrease)。 |
| class_weight | 1.8(文档)支持 dict / "balanced";用于样本不均衡时改变分裂的"有效权重",会影响剪枝阈值的实际意义。 |
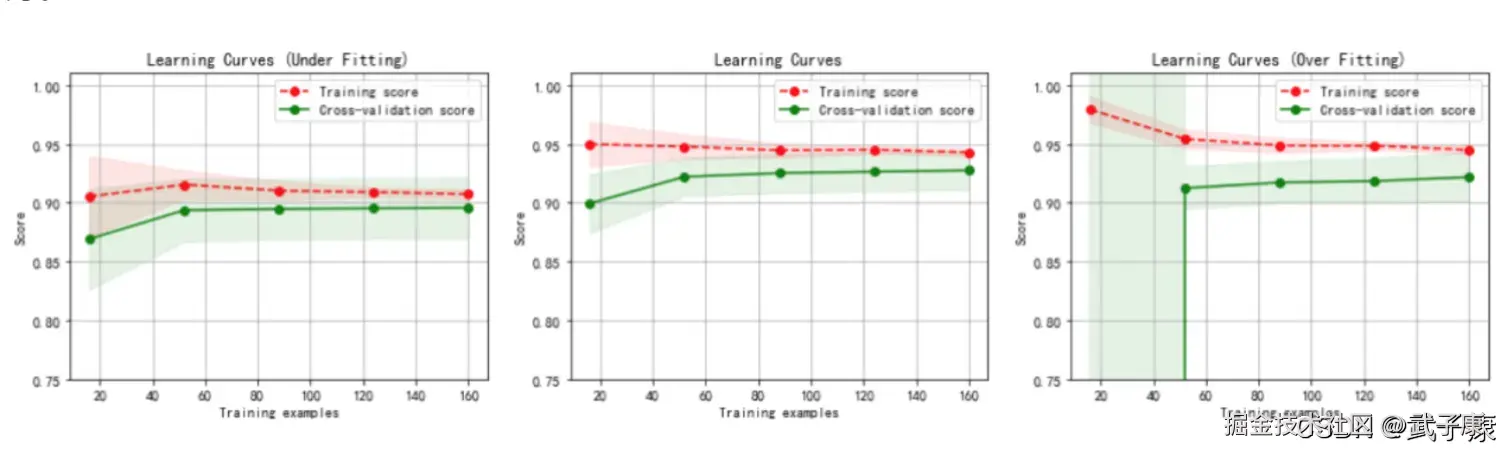
剪枝参数
max_depth
限制树的最大深度是决策树剪枝中最常用的参数之一,主要用于控制树的生长规模,防止模型过拟合。具体做法是设定一个最大深度阈值,当树的生长达到这个深度时就会停止继续分裂。
这个参数在高维特征空间且样本量较少的情况下特别有效。这是因为决策树每增加一层深度,理论上需要的样本量就会呈指数级增长。例如:
- 当深度为2时,可能需要至少4个样本才能支持所有节点的分裂
- 深度为3时,样本需求增加到8个
- 深度为4时,需要16个样本 以此类推,深度每增加1层,样本需求就翻倍。因此限制最大深度可以避免模型在样本不足的情况下过度学习噪声。
在实际应用中,这个参数在以下场景特别实用:
- 单个决策树模型中,防止过拟合
- 集成算法(如随机森林、GBDT)中,控制基学习器的复杂度
- 处理高维稀疏数据时,保证模型泛化能力
建议的使用方法是:
- 初始设置max_depth=3作为基准
- 观察模型在验证集上的表现
- 如果欠拟合,可以逐步增加深度(如4或5)
- 每次调整后都要重新评估模型性能
- 通常深度设置在3-8之间较为合理,超过10层往往会导致过拟合
需要注意的是,最优深度值会因数据集特征而异,需要通过交叉验证来确定最合适的参数。同时,可以配合其他剪枝参数(如min_samples_split)一起使用,以获得更好的效果。
min_samples_leaf
min_samples_leaf 是决策树算法中一个重要的超参数,它控制着树的分支行为。具体来说:
- 分支约束条件:
- 在决策树构建过程中,当考虑某个特征进行分支时,算法会检查:如果按照该特征进行分支,产生的每个子节点是否都能包含至少 min_samples_leaf 个样本
- 如果不满足这个条件,可能出现两种情况:
- 该分支会被完全禁止(不会发生)
- 或者算法会调整分支阈值,使得分支后的子节点都能满足最小样本数要求
- 例如:当 min_samples_leaf=10 时,任何可能导致某个子节点样本数少于10的分支都会被阻止
- 与其他参数的协同:
- 通常需要与 max_depth 参数配合使用
- 在回归树中,这种组合能产生特别好的效果:
- 可以有效地平滑预测结果
- 防止树生长得过深导致过拟合
- 示例:在房价预测中,这种组合可以减少预测结果的波动性
- 参数设置建议:
- 初始值建议从5开始尝试
- 对于样本分布不均衡的情况:
- 可以使用浮点数表示比例(如0.1表示10%)
- 这样能自动适应不同规模的数据集
- 实际应用场景:
- 金融风控模型中,设为50可以防止对小群体过度拟合
- 电商推荐系统中,设为0.05可以保持对长尾商品的覆盖
- 参数影响:
- 设置过小(如1):
- 可能导致过拟合
- 会产生很多只包含个别样本的叶子节点
- 设置过大:
- 可能欠拟合
- 会限制模型捕捉数据细节的能力
- 理想效果:
- 确保每个叶子都有足够代表性
- 避免产生方差过大的预测结果
- 在医疗诊断模型中,适当设置可以平衡敏感性和特异性
- 调优技巧:
- 可以通过学习曲线观察模型在验证集上的表现
- 通常与min_samples_split一起调整
- 对于大数据集(>10万样本),可能需要设置更大的值
min_samples_split
一个节点必须要包含至少 min_samples_split 个训练样本,这个节点才允许被分支,否则分支就不会发生。
max_features
max_features 是决策树算法中的一个重要超参数,它用于控制每个节点分裂时考虑的最大特征数量。具体来说:
-
参数作用机制:
- 在每次节点分裂时,算法会从所有特征中随机选取不超过
max_features数量的特征进行评估 - 超过该参数设定值的特征会被直接忽略,不参与当前节点的分裂计算
- 默认情况下,对于分类树通常设置为
sqrt(n_features),回归树设置为n_features
- 在每次节点分裂时,算法会从所有特征中随机选取不超过
-
与max_depth的区别:
max_depth是通过限制树的垂直深度来防止过拟合max_features则是通过限制特征选择空间来防止过拟合- 两者都是预剪枝(pre-pruning)策略,但作用维度不同
-
使用注意事项:
- 当特征维度很高时(如>50),建议设置该参数
- 设置过低可能导致模型欠拟合,常见取值范围是0.3-0.8
- 在特征重要性差异较大时,可能丢失重要特征
-
替代方案:
- PCA(主成分分析):通过线性变换保留方差最大的维度
- ICA(独立成分分析):寻找统计独立的特征表示
- 特征选择方法:
- 基于统计的方法(如卡方检验)
- 基于模型的方法(如L1正则化)
- 递归特征消除(RFE)
-
实际应用示例:
- 在处理文本数据(词向量维度可能上千)时
- 在基因表达数据(特征数远大于样本数)分析中
- 推荐先使用特征重要性分析,再决定是否使用该参数
最佳实践是先用完整特征集训练基线模型,通过特征重要性分析后,再决定是否使用max_features或采用其他降维方法。
min_impurity_decrease
限制信息增益的大小,信息增益小于设定数值小于设定数值的分支不会发生,这是0.19 版本中更新的功能,在 0.19 版本之前时使用 min_impurity_split。
确认最优的剪枝参数
那具体怎么来确定每个参数写什么值?这时候,我们要使用确定超参数的曲线来进行判断,继续使用我们已经训练好的决策模型 CLF。 超参数的学习曲线,是一条以超参数的取值为衡坐标,模型的度量指标为纵坐标的曲线,它是来衡量不同超参数取值下模型的表现的线。在我们建好的决策树里,我们的模型度量指标就是score。
python
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1,criterion="entropy",random_state=30,splitter="random")
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, ytest) # 记录下不同 max_depth 下模型在测试集分数
test.append(score)
plt.plot(range(1,11),test,color="red",label="学习曲线")
plt.ylabel("socre")
plt.xlabel("max_depth")
plt.legend()
plt.show();运行结果如下图所示: 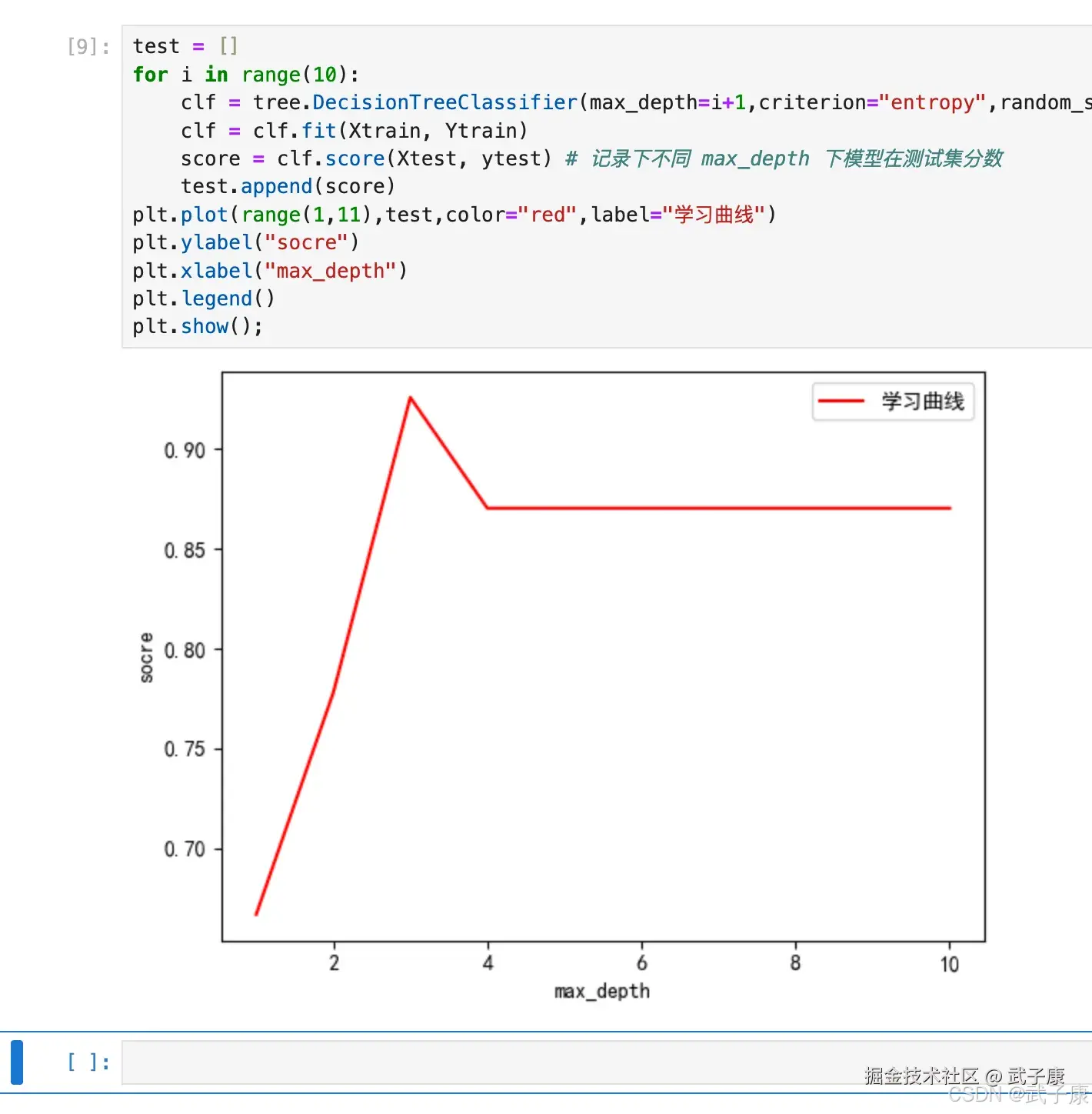
最后总结
思考:
- 剪枝参数一定能够提升模型在测试集上的表现吗?调参是没有绝对的答案的,一切都需要看数据的本身。 无论如何,剪枝参数的默认值会让树无尽的生长,这些树在某些数据集上可能非常巨大,对内存的消耗也非常巨大。
属性是模型训练之后,能够调用查看的模型的各种性质,对决策树来说,最重要的是 feature_importances,能够查看各个特征对模型的重要性。 sklearn 中许多算法的接口都是相似的,比如说我们之前已经用到 fit 和 score,几乎对每个算法都可以使用,除了两个接口之外,决策树最常用的接口还有 apply 和 predict。
- apply 中输入测试集返回每个测试样本所在的叶子节点的索引
- predict 输入测试集返回每个测试样本的标签,返回的内容一目了然并且非常容易 这里不得不提的是,所有接口中要求输入 Xtrain、Xtest 的部分,输入的特征的矩阵必须至少是一个二维矩阵,sklearn 不接受任何一维矩阵作为特征矩阵被输入。如果你的数据的确只有一个特征,那必须用 reshape(-1,1)来给矩阵增维。
样本不均匀的问题
对于分类问题,永远都逃不过一个问题就是样本不均匀。 样本不均衡是指在一组数据集中,标签的一类天生占有很大的比例,但我们有捕捉出某种特定分类的需求的状况。 比如,我们现在要对潜逃人员和普通人进行分类,潜在犯罪占总人口比例是相当低的,也许是 2%,这样 98% 都是普通人,而我们的目标是要捕获潜在犯罪者。这样的标签分布会带来很多问题。 首先,分类模型天生会倾向于多数的类,让多数类更容易被判断正确,少数类被牺牲掉。因为对于模型而言,样本量越大的标签可以学习的信息越多,算法就会更依赖于从多数类中学习到的信息来进行判断,若我们希望捕获少数类,模型就会失败。 其次,模型评估指标会失去意义,这种分类状况下,即使模型什么也不做,全把所有人当作不会犯罪的人,准确率也会非常的高。这使得模型的评估标准的 Accuracy 变得毫无意义,根本无法达到我们要的"识别犯罪的人"的建模目的。 所以现在,我们要让算法意识到数据的标签不是均衡的,通过施加一些惩罚或者改变样本本身,来让模型捕获少数类的方向建模。
我们可以使用上采样和下采样来达到这个目的,所用的方法就叫做SMOTE,这种方法通过将少数的特征重新组合,创造出更多少数类样本。但这些采样方法会增加样本的总数,对于决策树这个样本总是对计算速度影响巨大的算法来说,我们完全不想轻易的增加样本数量,所以我们要寻求另一条路:改进我们的模型评估指标,使用更加针对于少数类的指标来优化模型。
class_weight
在决策中,存在着调节样本均衡的参数:class_weight 和接口 fit 中可以设定的 sample_weight。 在决策树中,参数 class_weight 默认 None,此模式表示假设数据集中的所有标签是均衡的,即自动认为标签比例是:1:1,所以当样本不均衡的时候,我们可以使用形如:
json
{
"标签的值 1": 权重1,
"标签的值 2": 权重2
}用这种字典输入真实的样本标签比例,来让算法意识到样本是不平衡的,或者使用 balanced 模型。 有了权重之后,样本量就不再是单纯的记录数目,而是受输入的权重影响了,因此这时候剪枝,就需要搭配 min_weight_fraction_leaf 这个基于权重的剪枝参数来使用。 另请注意,基于权重的剪枝参数(例如 min_weight_fraction_leaf)将比不知道样本权重的标准(比如 min_samples_leaf)更少偏向主导类。如果是样本是加权的,则使用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重总和的一小部分。
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 训练集分数高、测试集分数低 | 树太深/叶子太"尖",典型过拟合 | 对比 train/test score;看树深度与叶子数 | 限制 max_depth;增大 min_samples_leaf(可从 5 起);必要时同步提高 min_samples_split |
| 模型占内存大、训练/推理慢 | 默认参数导致树"长满且不剪枝" | 观察训练耗时、内存;看叶子节点数量 | 通过 max_depth/min_samples_leaf/min_samples_split 控制复杂度;必要时限制 max_leaf_nodes(若使用) |
| 传了 min_impurity_split 报 TypeError | 参数已弃用/被移除 | 报错信息含 "unexpected keyword 'min_impurity_split'" | 改用 min_impurity_decrease;同时记录 sklearn 版本,避免代码与环境不一致 |
| min_impurity_decrease 不生效/几乎不分裂 | 阈值设太大,分裂被整体抑制 | 看树深度骤降;分数明显下降 | 从 0.0 起步逐步增大;配合学习曲线找拐点;不要单独把阈值抬太高 |
| 调参曲线抖动大、复现差 | random_state 未固定或 splitter="random" 引入波动 | 多次跑同一配置结果不同 | 固定 random_state;对比 splitter="best" 与 "random" 的方差(你正文里用 random) |
| 样本不均衡下 Accuracy 很高但"抓不到少数类" | 指标选择不对;模型偏多数类 | 看混淆矩阵/召回率而非 Accuracy | 使用 class_weight="balanced" 或按比例给 dict;评估改用 recall/PR-AUC 等少数类指标(而非只看 score) |
| 报 "Expected 2D array, got 1D array" | X 输入维度不符合 sklearn 约定 | 堆栈含 shape/2D array 提示 | 单特征时 reshape(-1, 1);保证 Xtrain/Xtest 是二维矩阵(你正文末尾已提示) |
| max_features 设置后效果变差或不稳定 | 特征子集过小导致欠拟合;或实现为找有效分裂会额外检查特征 | 看分数下降/方差上升;查看特征重要性 | 提高 max_features 或回到默认;在高维稀疏场景优先用 max_depth/min_samples_leaf 控复杂度,再尝试 max_features |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解