业务背景
大家好,我是卡卡,在大多数 C 端产品里,想要提升用户留存和消费能力,除了不断的营销活动之外,积分系统同样是一个非常重要、而且使用频率极高的基础模块。从签到、下单、活动任务、邀请、兑换商品、抽奖等场景来看,用户的很多核心行为,最终都会通过积分这种形式被承接和放大。
对运营来说,积分是最常用、也是最灵活的一种激励手段; 对用户来说,积分则是一种持续存在、可累计、可感知的长期权益。
也正因为这样,积分系统往往会在不知不觉中承担越来越多的职责。
在实际业务中,积分系统一开始看起来并不复杂:配置规则、触发发放、更新余额,好像逻辑也不难。但真正跑起来之后,很容易随着规则不断增加、活动频繁叠加、人工操作逐步介入,慢慢演变成一个既难维护、又不好追溯的系统。很多问题并不是立刻暴露出来,而是在出问题之后才发现,系统本身缺乏足够的约束能力和解释能力。
在这次的积分系统设计中,我们同样采用了基于事件驱动的整体思路。所有积分行为,都从明确的业务事件开始,由事件触发规则,由规则决定是否发放积分,再进入后续的结算、风控与审计流程。通过把"发生了什么"和"为什么会发积分"拆清楚,尽量让每一次积分变动都可解释、可回溯。
如果有之前看过我写过的那篇文章 《活动玩法越堆越乱,我重构了一套事件驱动的活动系统》, 可能会发现两者在整体思路上是相通的。无论是活动系统还是积分系统,本质上都是围绕"事件 + 规则"来展开,只不过积分系统对稳定性、风控和审计的要求要更高。
积分虽然不是直接的金钱,但它天然具备可累计、可放大、可被滥用的特性。一旦出现误发、刷分或者人工操作不当的问题,如果系统设计阶段没有把边界和约束考虑清楚,事后往往很难把问题完整还原出来。
那么我们今天就来一起梳理一下,如果要设计一套功能规则相对完善的积分系统,在整体设计上需要重点考虑哪些问题。
后面的内容将结合实际的业务拆分、表结构设计、核心流程实现,以及后台人工操作与审计页面,逐步展开这套积分系统的设计思路与具体落地方式。
业务现状回顾
在我们开始设计新的积分体系之前,先简单回顾一下之前业务里的积分是怎么做的。
早期的积分设计其实很常见,也很实用:
基本不存在规则级别的数据存储,积分发放形式相对固定。即使后来有了活动,或者加了一些延伸功能,本质上也只是在对应的业务代码里,直接加一段积分增加的逻辑。
在这种模式下,一个积分流水表,基本就能满足大部分需求,整体实现非常简单,也很好理解。
但问题也很明显,这套设计的耦合性非常高 。
每新增一种积分规则,就需要改代码、加判断、重新发版;规则越多,代码分支就越复杂,后期维护成本也会不断放大。
同时,由于积分规则是散落在代码里的,风险其实并不好把控:
一旦出现异常积分,往往只能看到流水结果,很难快速定位是哪条规则、哪段逻辑出了问题。
随着业务量逐渐变大,很多早期还能接受的设计,开始慢慢不再适用。
积分系统就是其中一个非常典型的例子。
一方面,比如我们运营希望基于用户侧增加更多积分获取玩法,用来提升活跃和留存;
另一方面,积分本身也开始承载更多规则诉求,比如需要支持动态配置的有效期,甚至不同来源、不同场景下的差异化策略。
在这种背景下,继续沿用原有那套"代码里直接加积分"的方式,已经很难支撑业务继续往前走。
也正是基于这些实际问题,才需要重新去设计一套能够长期运行、规则可扩展、同时具备审计和回溯能力的积分体系,而不是简单地在原有代码上继续打补丁。
设计思路拆解
我们在明确了为什么要重构积分系统之后,接下来要解决的第一个问题,其实是:
积分规则怎么设计,才能既灵活,又不失控。
很明显的一点是,我们如果希望积分规则可以被动态配置,那就不可能再继续把规则写死在代码里。
一旦规则和代码强耦合,后续每加一种玩法,基本都意味着改代码、发版本,这在实际业务中是很难持续的。
基于这一点,积分系统在设计上自然会走向一个方向:
规则和触发逻辑解耦,用事件驱动的方式来承载积分行为。
在实际设计中,我们会先在技术侧约定好一套积分系统支持的事件体系 ,比如哪些用户行为可以被视为积分事件。
这些事件一旦被定义和发布出来,后续的积分规则,就不再依赖具体业务代码,而是由运营基于这些事件进行组合和配置。
这样一来,技术侧只需要保证事件本身的稳定和完整,
而运营侧则可以围绕这些事件,灵活地配置不同的积分获取规则。
但有了事件还不够,真正复杂的地方在于:
一条积分规则本身,往往需要满足非常多的业务条件。
结合我之前项目以往遇到过的积分获取场景,在设计规则体系时,我们需要重点考虑几个维度。
首先是积分的计算方式。
有些场景下是固定积分,比如完成一次行为直接给固定数量;
而有些场景则需要按比例计算,比如消费金额的一定比例转化为积分。
其次是触发条件本身。
有的规则只要事件发生即可触发,有的则需要满足特定阈值,比如"消费满多少""充值达到某个金额"之后才生效。
同时,还需要考虑发放次数的限制问题。
是每次都可以触发,还是每天、每人、每个周期只能生效一次,这些都会直接影响规则的设计方式。
再往下,就是积分的有效期设计。
有的积分是长期有效的,有的则需要限定使用周期,甚至只能在特定活动或特定场景下使用,这些都需要在规则层面提前考虑清楚。
除此之外,还有一些更偏营销和运营的需求。
比如活动期间积分翻倍、阶段性加成、灰度测试不同积分策略等,这类需求如果没有提前纳入规则体系设计,后续实现起来会非常被动。
也正是基于这些实际需求,积分系统在规则设计上,不能只满足"能发积分",
而是要在一开始就具备足够的扩展空间,能够覆盖常见的业务玩法,同时又不会让系统变得不可控。
核心模块拆分
我们在明确了积分规则需要具备足够灵活性之后,接下来的问题就变得很现实了:
这些规则、事件、用户积分以及风险能力,应该如何在系统中被合理拆分。
在实际设计积分系统时,其实我们很容易陷入一个误区:
所有功能围绕用户积分展开,最后所有页面、接口和逻辑都堆在一起,系统看起来完整,但边界非常模糊。
为了避免这种情况,在拆分系统时,我们并打算从页面出发,而是先从职责和使用对象的角度去看这套系统。
整体来看,积分系统可以被拆成几类核心能力。
第一类是积分规则域 。
这是整个积分系统的"决策中枢",负责定义什么行为可以产生积分,以及这些积分该如何计算、如何生效。
积分事件、积分规则以及活动期间的积分倍率,本质上都属于这一层,它们只关心规则本身,而不关心具体的用户是谁。
第二类是用户积分域 。
这一部分关注的是积分规则落到具体用户之后的执行结果,包括当前积分状态、即将到期的积分情况,以及完整的积分流水和明细记录。
它更多是"结果层",用于承载用户视角下的积分变化。
第三类是风险管控与审计域 。
积分一旦具备动态配置能力,风险问题就必须被放到系统设计的一等公民位置。
异常积分、规则风险、高风险行为识别,以及人工操作的完整审计,都是这一层需要承担的职责。
最后,是整体运行态的可视化能力 。
也就是通过仪表盘的方式,将积分发放趋势、规则使用情况以及潜在风险集中呈现出来,用于辅助运营和风控判断。
基于这样的拆分思路,后台管理系统也自然演化成几个相对独立的功能模块,而不是一个围绕"积分列表"不断堆功能的页面集合。
积分规则域(一):积分事件的定义与约束
在积分规则域中,最先需要确定的其实不是规则,而是事件。
在后台中,积分事件以一个非常克制的页面形式存在,比如下图所示:
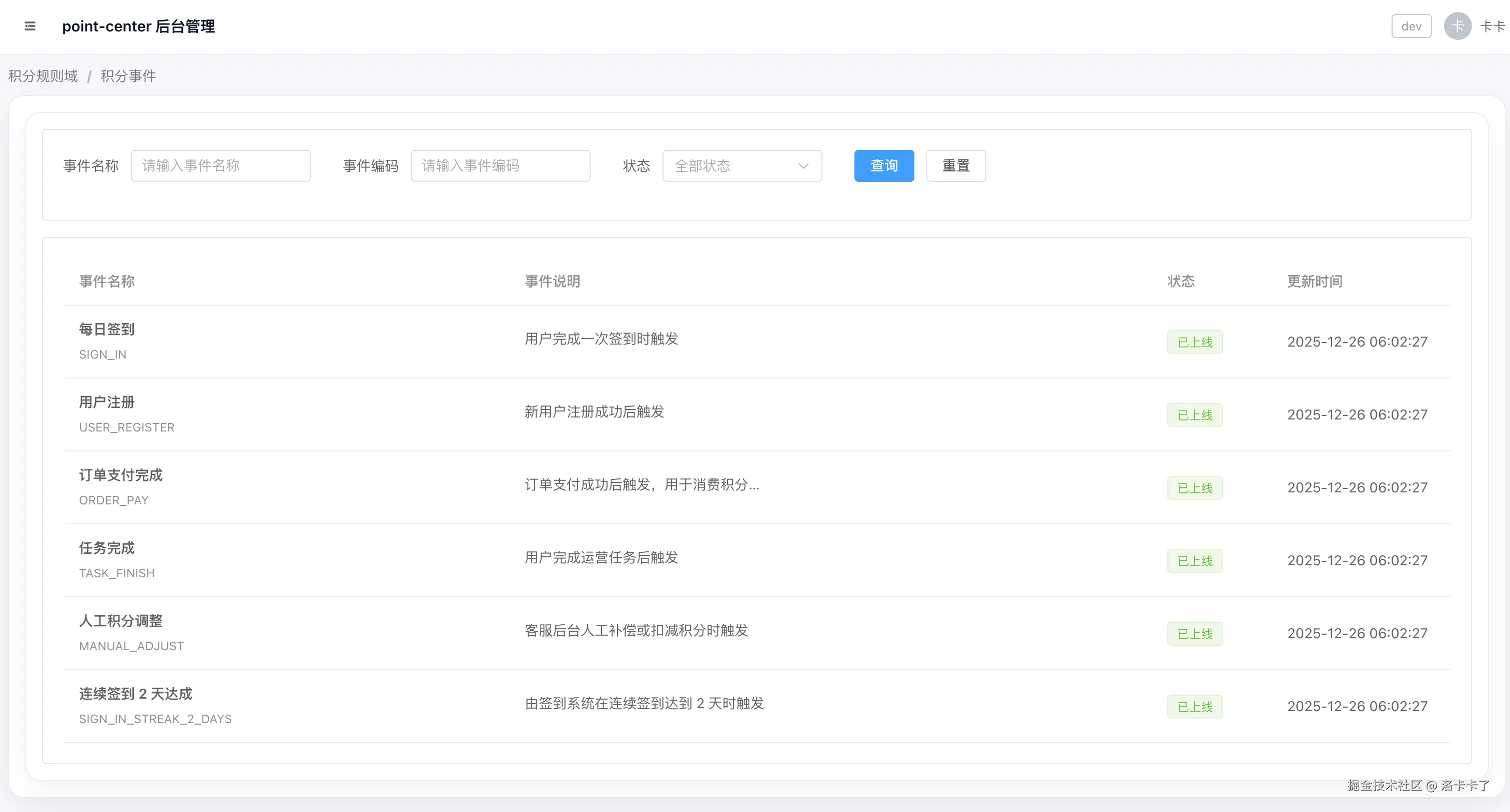
如图所示,事件列表只用于展示当前系统已经支持的积分事件,包括事件名称、事件编码、事件说明以及当前状态,支持基础的查询和筛选能力,但不提供新增和编辑功能。 这个设计本身是有明确边界的。
积分事件并不是运营配置出来的概念,而是对业务行为的一次抽象定义,例如用户签到、用户注册、订单支付完成、任务完成,或者人工积分调整等。
这些行为是否真实发生,完全取决于代码是否在对应的业务时机上报了事件。 如果仅仅在后台新增一个事件,但代码侧并没有对应的触发逻辑,那么即使后续配置了积分规则,这条规则也永远不会被触发。
基于这一点,积分事件的管理权被刻意放在了技术侧。 当业务需要新增一种积分事件时,实际的处理流程通常是:
- 技术侧先在业务代码中补充事件上报逻辑,确保事件在正确的业务时机被触发;
- 随后,在积分系统中新增对应的事件定义,并将事件发布上线;
- 等事件处于可用状态后,运营侧才能基于该事件去配置积分规则。
通过这样的方式,事件本身成为了技术侧与业务侧之间的一种稳定约定,而不是一个可以随意扩展的配置项。
积分事件字典表设计说明
对应后台中的积分事件页面,底层使用了一张事件字典表来承载事件的元信息,表结构如下:
sql
CREATE TABLE `point_event` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '事件ID(稳定引用键)',
`event_code` varchar(64) NOT NULL COMMENT '事件编码(技术标识,可调整但不建议频繁改)',
`event_name` varchar(128) NOT NULL COMMENT '事件名称(给人看的,如 订单支付完成)',
`event_desc` varchar(255) DEFAULT NULL COMMENT '事件说明(触发时机、注意事项)',
`status` varchar(16) NOT NULL DEFAULT 'OFFLINE' COMMENT '状态:OFFLINE=未上线,ONLINE=已上线可用,DEPRECATED=已废弃',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_event_code` (`event_code`)
) ENGINE=InnoDB COMMENT='积分事件字典表(技术维护,其他表引用 event_id)';表中各字段的职责划分也非常清晰:
event_code用于作为技术侧的稳定标识,在业务代码中进行事件上报时使用;event_name和event_desc主要用于后台展示和规则配置时的语义说明;status用于控制事件是否可以被规则引用,避免下线或废弃事件被继续使用;id作为内部稳定引用键,被积分规则等其他表通过event_id进行关联。
在规则体系内部,统一通过 event_id 来建立关联关系,而不是直接依赖 event_code,这样可以避免业务编码调整对规则数据产生影响。
同时需要注意的是,事件表本身只承担事件元信息的职责: 它定义的是"系统允许感知哪些行为",而不会直接参与积分计算或积分发放逻辑。
通过这种方式,积分事件在系统中的角色就非常清晰了: 它是一份由技术侧维护的事件白名单,用于限定积分系统的感知范围,防止规则体系无限膨胀、失去边界。
也正是有了这一层约束,后续的积分规则配置,才能建立在一个稳定、可控的事件体系之上,而不会出现规则配置失效或行为不可控的问题。
积分规则域(二):积分规则如何围绕事件进行配置
在事件体系确定之后,积分系统真正开始变复杂的地方,才刚刚开始。 因为接下来要解决的问题是:同一个事件发生之后,积分到底该怎么发。
在后台中,积分规则以一个相对完整的配置页面存在,如下图所示:
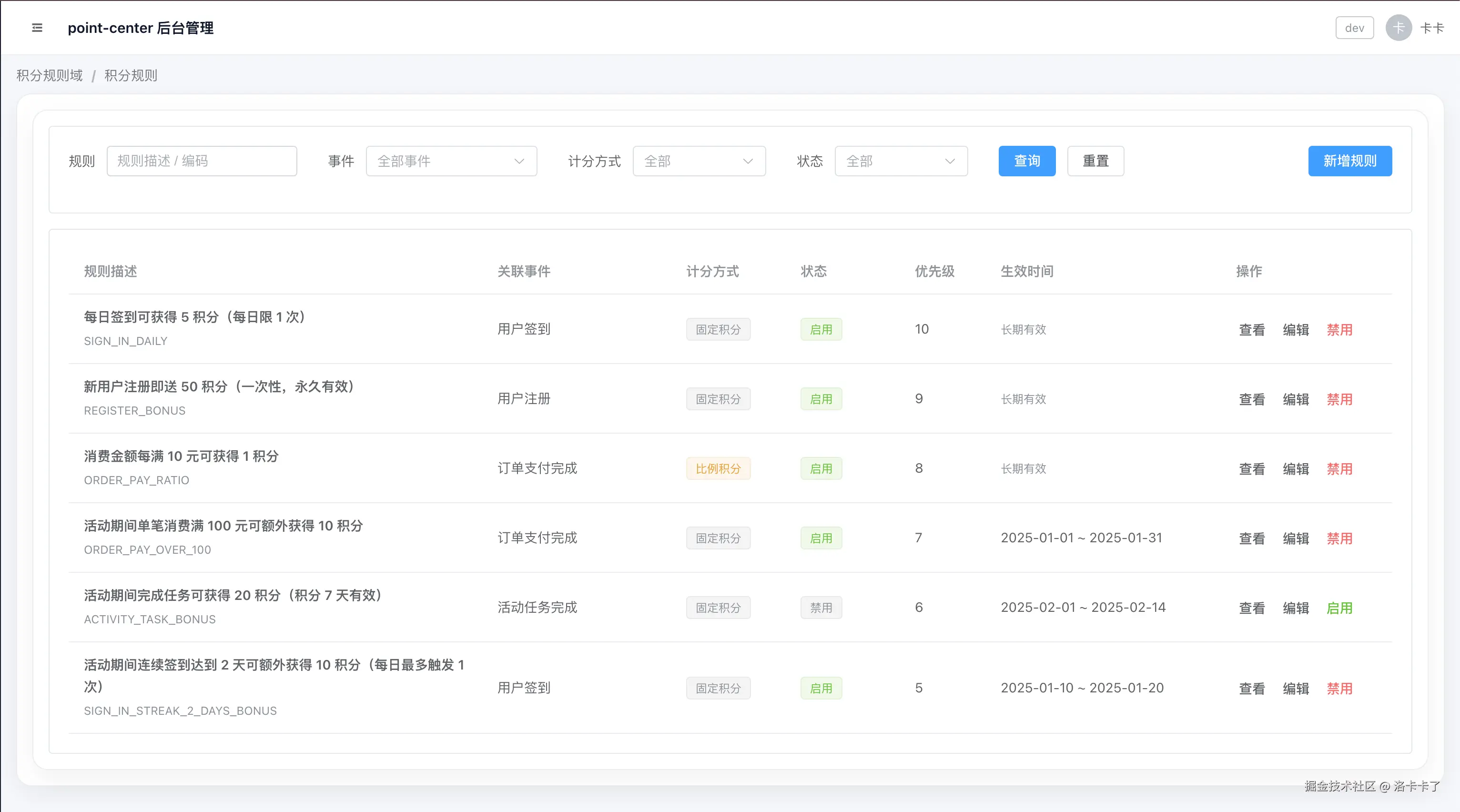
从列表页可以看到,每一条积分规则都会明确关联一个积分事件,同时还包含计分方式、优先级、状态以及生效时间等信息。 这也意味着,在同一个事件下,是允许存在多条积分规则的。
例如,"订单支付完成"这个事件下,既可以配置常规的消费返积分规则,也可以在活动期间额外配置一条加成规则。
正因为同一事件可能命中多条规则,所以规则本身必须具备明确的边界和执行顺序,而不是简单地"事件一触发就加积分"。
规则的基本信息与执行边界
在规则的基础信息配置中,首先需要确定的是规则本身的唯一性和可读性。如下图所示:
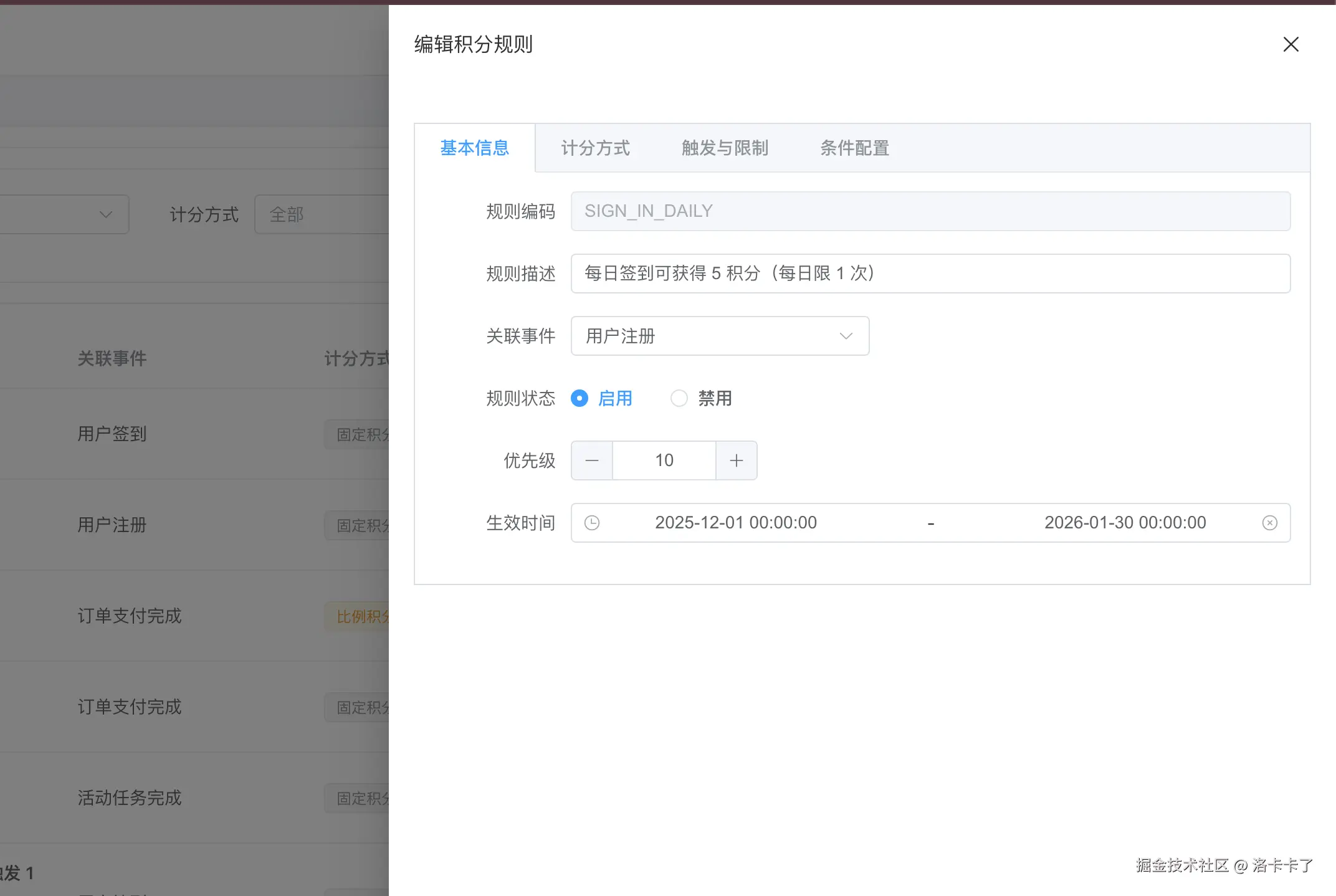
规则编码由服务端生成,用于作为规则的稳定标识; 规则描述则更多是给运营和后续维护人员看的,用来说明这条规则的业务含义。
规则与事件之间是一个明确的绑定关系,只有当对应事件被触发时,这条规则才有被执行的可能。
同时,在同一事件下引入了规则优先级的概念。 当多个规则同时满足触发条件时,优先级用于控制规则的执行顺序,避免出现规则冲突或重复发放的问题。
计分方式:固定积分与比例积分
规则配置中的一个核心能力,是积分的计算方式。如下图所示
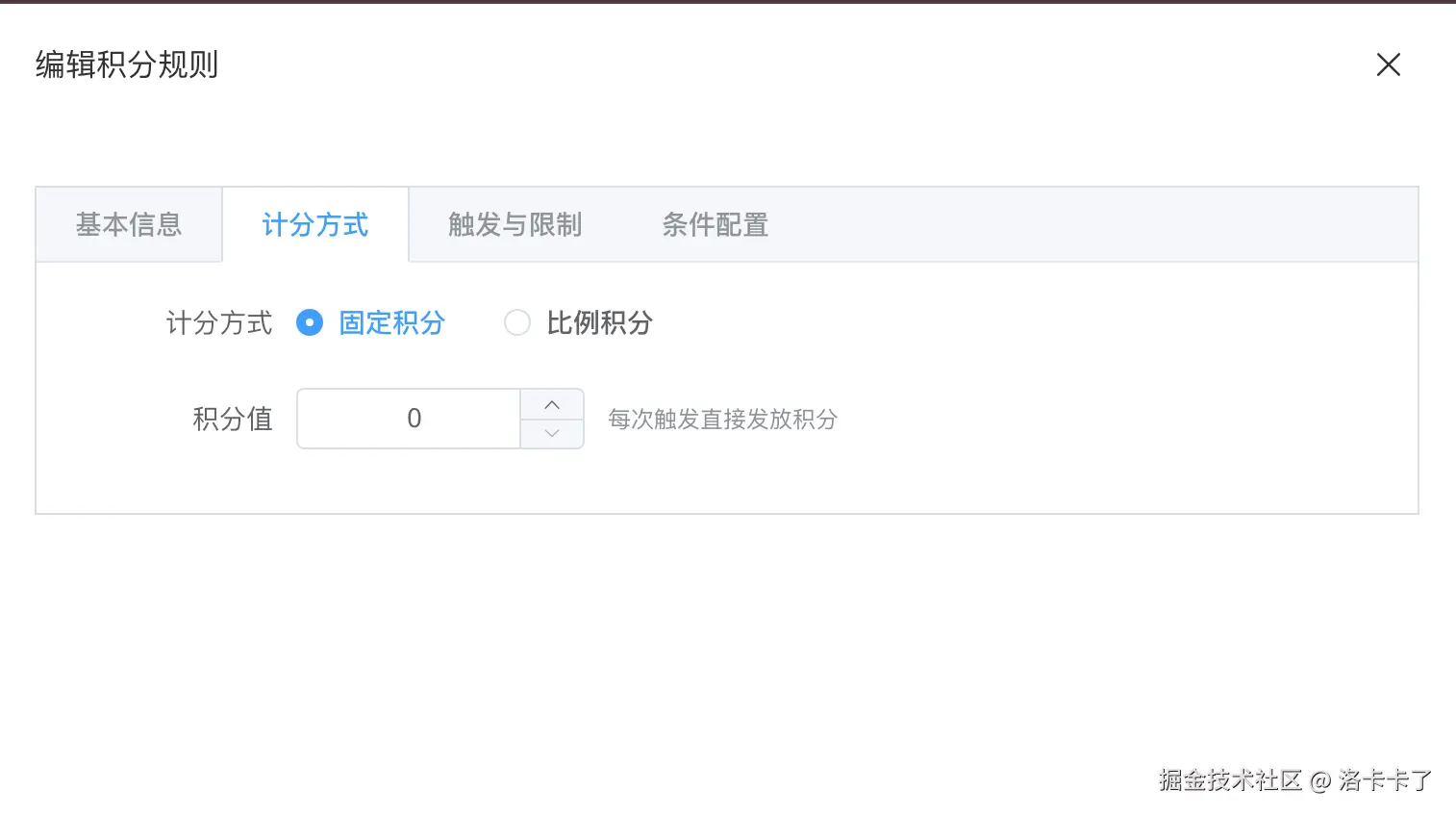
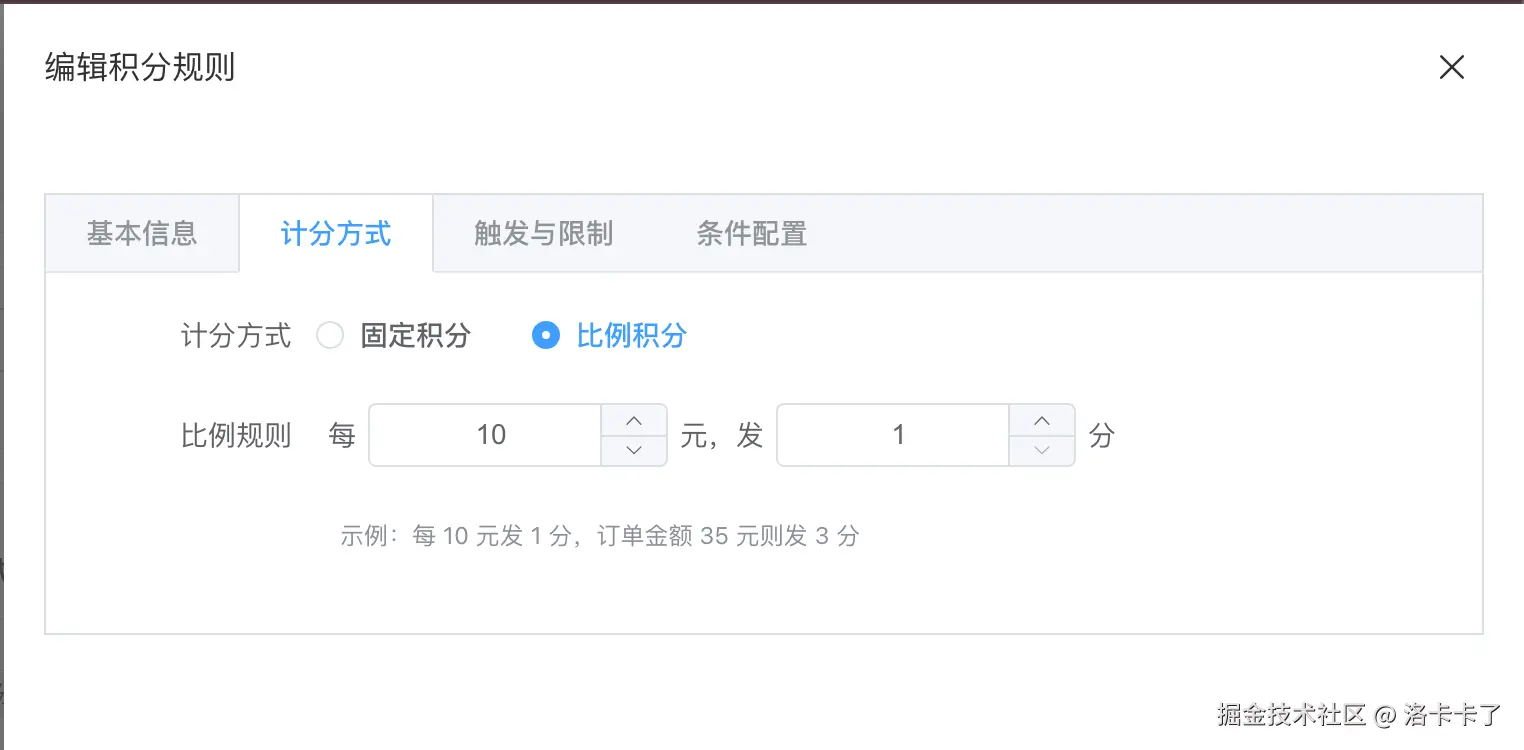
在我们实际业务中,并不是所有场景都适合用固定积分。 因此在设计时,我们将计分方式拆分为两种:
- 固定积分:每次规则生效时,直接发放固定数量的积分;
- 比例积分:根据事件携带的数据,按比例计算积分,例如"每消费 10 元发放 1 积分"。
这两种方式在后台配置层面是互斥的,但在规则模型层面是统一抽象的,方便后续扩展更多计算策略。
触发条件与发放限制
除了"怎么算积分",规则还必须回答两个问题: 什么时候发,以及最多能发多少次。
在规则配置中,引入了触发条件和发放限制两个概念。如下图所示:
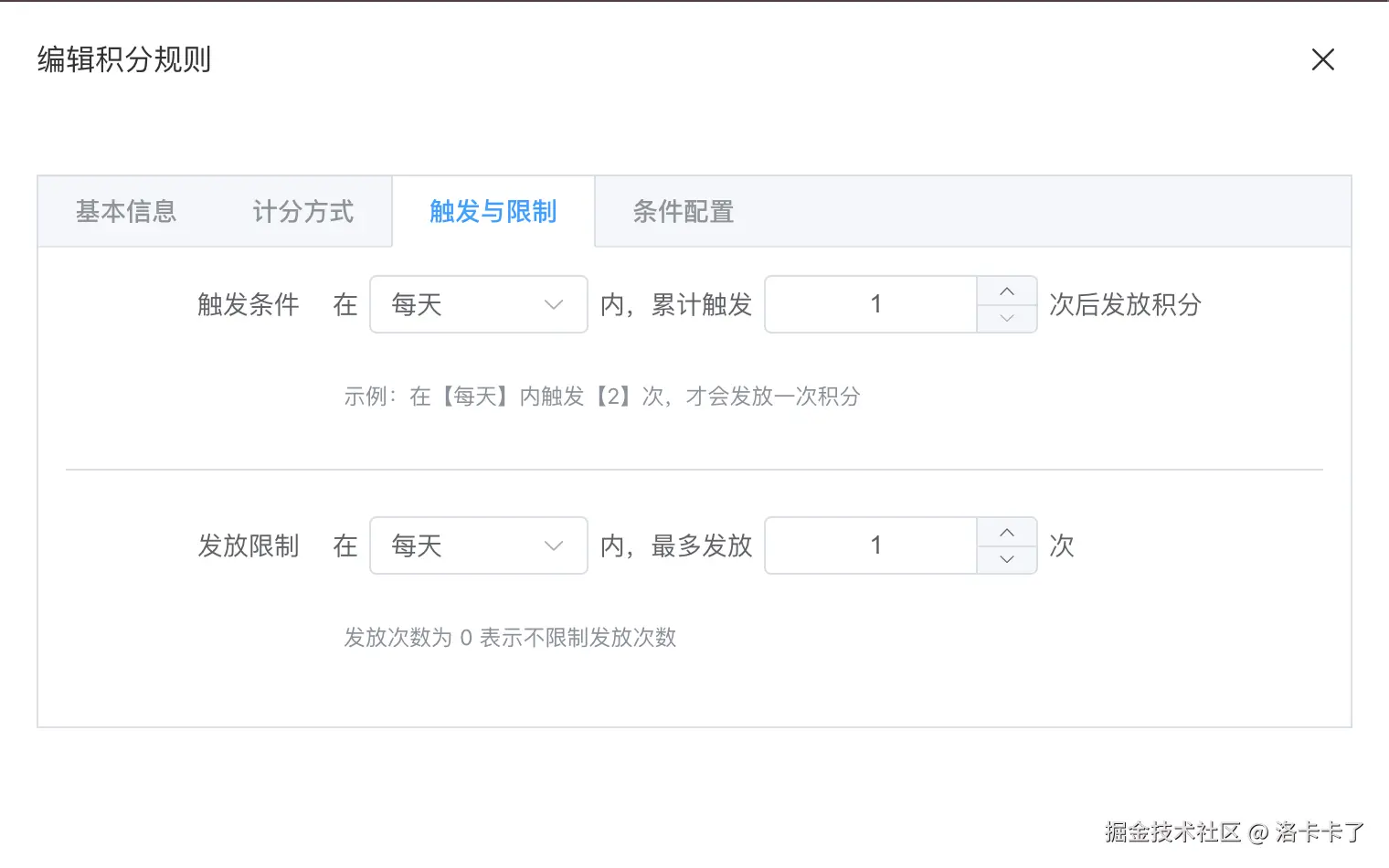
触发条件用于描述:在一个统计周期内,事件需要累计触发多少次,规则才会真正生效。 例如"每天签到 1 次即可发放积分",或者"连续触发 2 次后才发放一次积分"。
而发放限制更多是一个拦截机制,用来控制在同一个周期内,这条规则最多可以发放多少次积分。 这类限制在防刷和风控场景中非常关键,可以有效避免某些规则被频繁触发。
条件配置:让规则具备表达能力
在很多业务场景下,仅仅依赖事件本身是不够的。 例如消费返积分,往往需要满足"金额达到某个阈值"; 活动规则中,也可能要求满足特定渠道、特定用户类型等条件。
因此在规则中引入了条件配置能力。如下图所示:
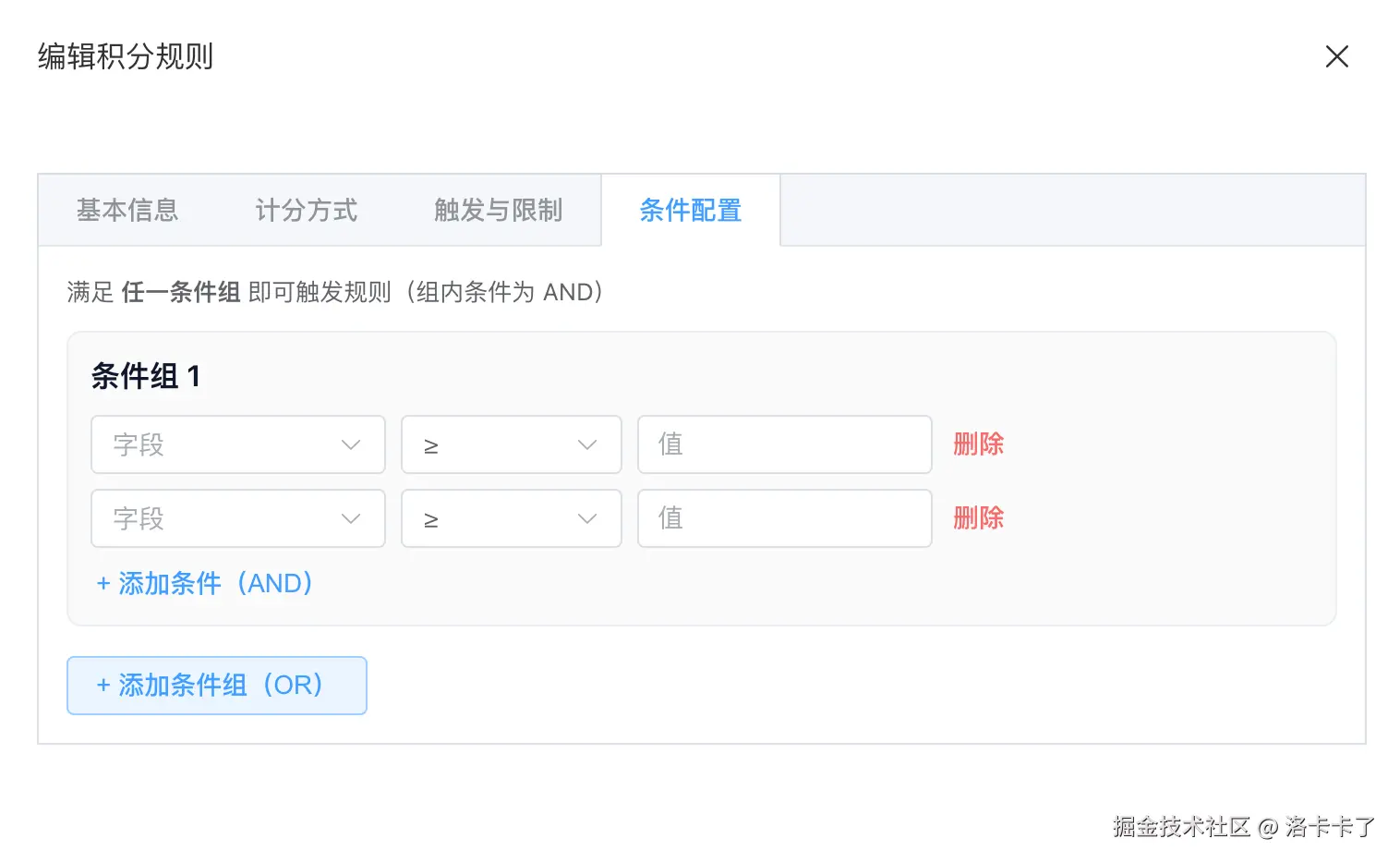
规则支持通过条件组的方式来组合多个条件: 同一条件组内为 AND 关系,不同条件组之间为 OR 关系。
这样一来,规则就可以表达出相对复杂的业务判断逻辑,而不需要把这些判断写死在代码中。
积分规则表结构设计说明
对应后台中的规则配置能力,底层使用了两张表来承载规则数据。
第一张是积分规则主表,用于描述规则的整体行为和执行策略:
sql
CREATE TABLE `point_rule` (
`rule_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '积分规则ID',
`rule_code` varchar(64) NOT NULL COMMENT '规则编码',
`rule_desc` varchar(255) NOT NULL COMMENT '规则描述',
`event_id` bigint(20) NOT NULL COMMENT '关联事件ID',
`calc_type` varchar(16) NOT NULL COMMENT '积分计算方式',
`base_points` int(11) DEFAULT NULL COMMENT '固定积分值',
`calc_base` int(11) DEFAULT NULL COMMENT '比例积分基数',
`calc_value` int(11) DEFAULT NULL COMMENT '比例积分值',
`trigger_threshold` int(11) NOT NULL COMMENT '触发阈值',
`trigger_window` varchar(16) NOT NULL COMMENT '触发统计窗口',
`grant_limit` int(11) NOT NULL COMMENT '发放次数限制',
`grant_window` varchar(16) NOT NULL COMMENT '发放次数窗口',
`expire_type` varchar(16) NOT NULL COMMENT '积分过期类型',
`expire_days` int(11) DEFAULT NULL COMMENT '积分有效天数',
`priority` int(11) NOT NULL COMMENT '规则优先级',
`status` varchar(16) NOT NULL COMMENT '规则状态',
`start_at` datetime DEFAULT NULL COMMENT '规则生效开始时间',
`end_at` datetime DEFAULT NULL COMMENT '规则生效结束时间',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`rule_id`)
);规则主表只描述这条规则是什么、何时生效、如何计算积分,而不关心具体的条件判断细节。
条件相关的判断逻辑,则被拆分到了独立的规则条件表中:
sql
CREATE TABLE `point_rule_condition` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`rule_id` bigint(20) NOT NULL COMMENT '关联规则ID',
`field` varchar(64) NOT NULL COMMENT '事件 payload 字段',
`op` varchar(16) NOT NULL COMMENT '运算符',
`value` varchar(255) NOT NULL COMMENT '比较值',
`value2` varchar(255) DEFAULT NULL COMMENT 'BETWEEN 第二个值',
`group_no` int(11) NOT NULL COMMENT '条件组编号',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
);通过将规则行为和条件判断拆分开来,规则模型在保持结构清晰的同时,也具备了足够的扩展能力。
我们小结一下这一层设计
通过这种设计,积分规则在系统中的角色非常明确:
- 事件负责告诉系统"发生了什么"
- 规则负责决定"是否发积分、怎么发、发多少"
- 条件负责限定"在什么前提下才允许生效"
也正是这种围绕事件展开、层次清晰的规则设计,才让积分系统在规则复杂度不断上升的情况下,依然保持可控和可维护。
积分规则域(三):活动加成与积分倍率的设计
在积分事件和积分规则都确定之后,实际我们实际业务中很快会遇到一类非常典型的需求: 在特定时间、特定场景下,对已有积分规则进行额外加成。
例如双倍积分日、节假日活动、阶段性促活活动等。 这些需求本质上并不是"新增一条积分规则",而是希望在原有规则之上,进行一次临时性的积分放大。
如果每次活动都通过复制规则、调整积分值来实现,不仅规则数量会迅速膨胀,也会让活动结束后的回收变得非常混乱。 因此,在设计上,我们将这类需求单独抽象成了积分倍率层。
活动倍率在后台中的表现形式
在后台中,积分倍率以"倍率活动"的形式存在,如下图所示:
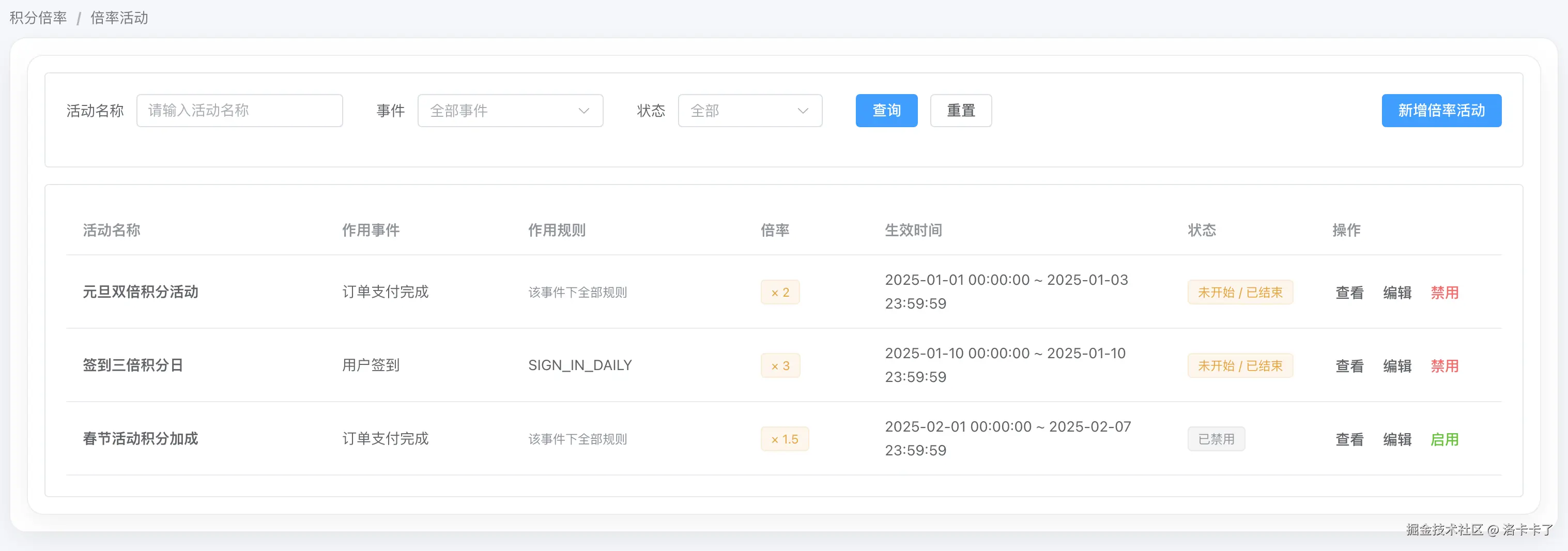
倍率活动本身只关注几件事情: 活动名称、作用事件、作用规则范围、倍率大小以及生效时间。
这里有一个非常重要的设计点: 倍率活动并不是随时可以编辑的配置项,尤其是在活动生效期间,通常是不允许直接修改的,或者需要走额外的审核流程。
这是因为倍率本身属于"放大器",一旦配置错误,影响范围会非常大。 相比积分规则,倍率更偏向于活动级别的控制能力,因此在权限和操作上都需要更加谨慎。
倍率的作用范围与边界
在倍率配置中,倍率可以作用在不同层级上,如下图所示:
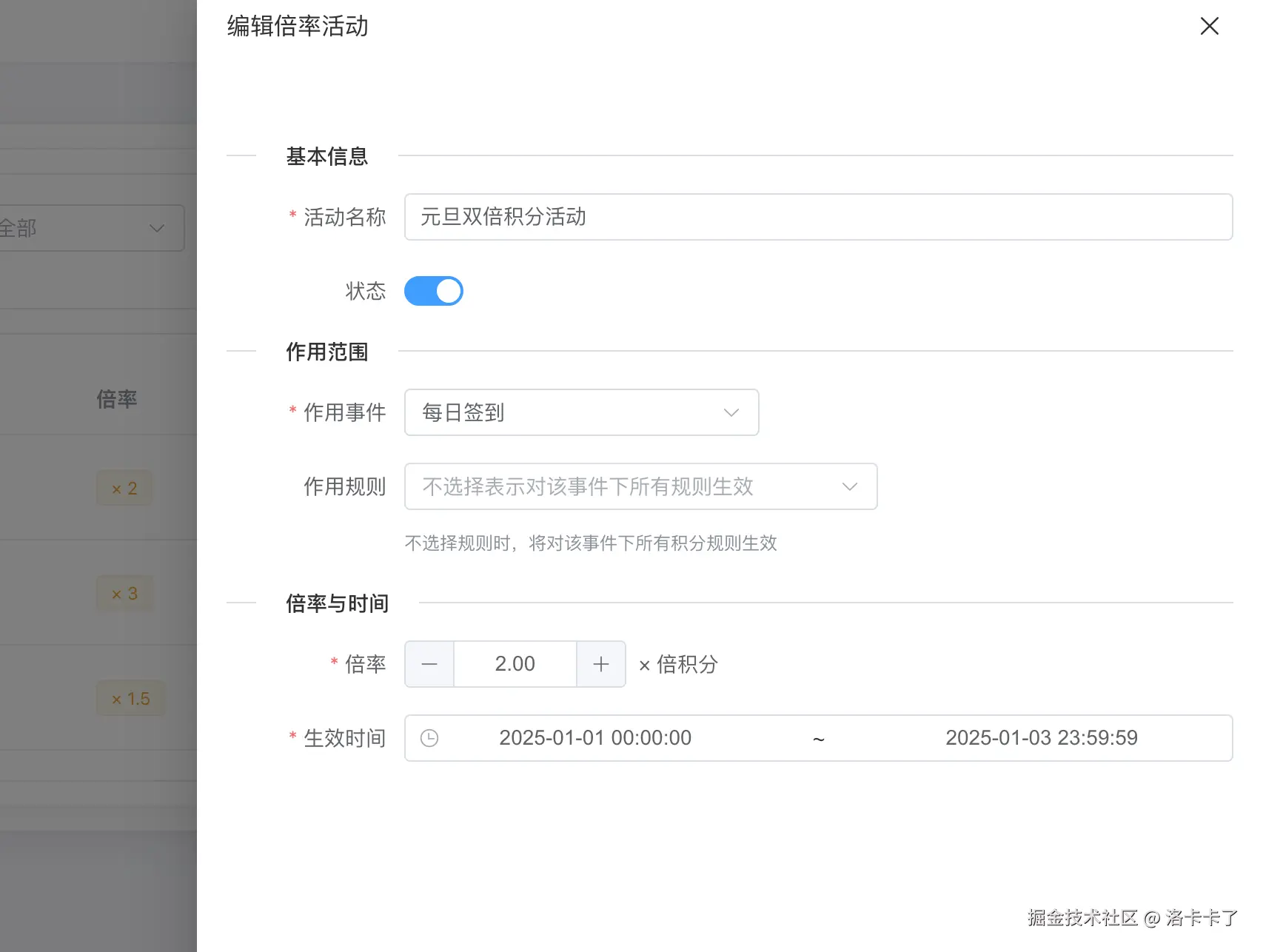
- 作用于某一个事件,表示该事件下的所有积分规则都会被放大;
- 也可以精确作用于某一条规则,只对指定规则生效。
这种设计让倍率既可以支持"全量活动",也可以支持"精准加成",而不需要在规则层面做额外拆分。
同时,倍率始终依赖明确的生效时间窗口。 一旦超过结束时间,倍率自然失效,不需要人工回滚规则状态,从而避免活动结束后遗留配置的问题。
积分倍率配置表设计说明
对应后台中的倍率活动配置,底层使用了一张独立的倍率配置表来承载相关数据:
sql
CREATE TABLE `point_multiplier_config` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '倍率配置ID',
`name` varchar(64) NOT NULL COMMENT '活动名称(如 双倍积分日)',
`event_id` bigint(20) NOT NULL COMMENT '事件ID,关联 point_event.id',
`rule_code` varchar(64) DEFAULT NULL COMMENT '可选:仅对某条规则生效',
`multiplier` decimal(10,2) NOT NULL COMMENT '倍率值',
`start_at` datetime NOT NULL COMMENT '开始时间',
`end_at` datetime NOT NULL COMMENT '结束时间',
`status` varchar(16) NOT NULL COMMENT '状态',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='积分倍率配置表';在这张表中,各字段的职责划分非常清晰:
event_id用于限定倍率的作用事件范围;rule_code用于进一步缩小作用规则范围(为空表示作用于事件下所有规则);multiplier用于描述倍率大小;start_at和end_at明确限定倍率的生效时间窗口;status用于控制倍率活动是否启用。
倍率配置表本身并不参与规则判断,也不关心积分是如何计算的。 它只在规则执行完成之后,对最终积分结果进行一次放大处理。
为什么要把倍率单独拆出来
我们通过将活动倍率从积分规则中拆分出来,整个积分系统的职责边界会变得非常清晰:
- 事件负责描述"发生了什么"
- 规则负责决定"是否发积分、发多少"
- 倍率负责在特定时间内"放大结果"
这种分层设计,使得活动类需求可以快速上线和下线,而不会对原有规则体系造成结构性影响。
也正是因为倍率被限制在清晰的作用范围和时间窗口内,积分系统在面对频繁活动调整时,依然能够保持稳定和可控。
总结一下
到这里,积分规则域的三层结构已经完整展开:
- 积分事件:限定系统能感知的行为范围
- 积分规则:围绕事件定义积分发放逻辑
- 积分倍率:在规则之上进行活动级别的加成控制
在这一层设计完成之后,积分系统的"规则决策部分"已经基本成型。 接下来,就可以开始关注积分是如何真正落到账户上的,以及在过程中如何保证可审计和可回溯。
积分执行层:一次事件是如何被结算成积分的
在前面几节中,我们已经把积分事件、积分规则、倍率活动都拆分清楚了。 但这些配置本身并不会"自动产生积分"。
真正关键的问题在于: 当业务侧上报一个事件时,这个事件是如何一步步被结算为积分,并且保证安全、可控、可回溯的?
这一节,我们就从一次标准的事件上报开始,完整梳理积分系统内部的执行流程。
一次积分事件的上报格式
在业务侧,所有积分相关行为最终都会被抽象成一次事件上报,请求格式大致如下:
json
{
"eventCode": "ORDER_PAY",
"userId": 10001,
"sourceId": "ORDER_202502010001",
"eventTime": "2025-02-01T12:30:00",
"payload": {
"amount": 126.50,
"channel": "APP",
"payType": "WX"
}
}这个结构有几个非常重要的设计点:
eventCode用于标识业务行为类型sourceId用于幂等控制,防止重复结算eventTime用于规则时间窗口判断payload承载规则判断和比例计算所需的业务数据
在积分系统中,我们不会关心业务的上下文细节,只关心这些已经被标准化的事件信息。
积分结算的整体执行流程
当事件进入积分系统后,整体执行流程可以抽象为下面几个步骤:
text
1. 校验事件是否合法、是否可用
2. 查询该事件下所有可用的积分规则
3. 按规则逐条判断是否命中
4. 计算基础积分(固定 / 比例)
5. 应用活动倍率(如双倍积分)
6. 判断是否超过发放限制
7. 记录积分流水与明细
8. 更新用户积分账户余额大概逻辑流程如下:
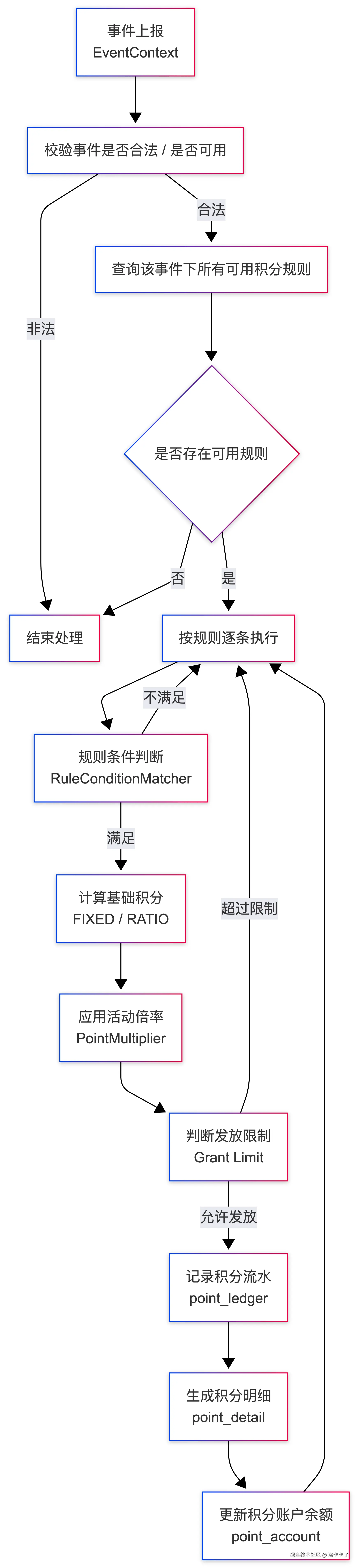
这个流程并不复杂,但每一步都有明确的边界和数据支撑。
下面我们按模块拆开来看。
规则命中判断:条件不是写在代码里的
在积分规则执行之前,系统首先会判断规则是否在当前事件上下文中生效。
这里我们并没有把规则条件写死在代码里,而是通过一张规则条件表来进行动态匹配。
规则条件的设计遵循两个非常重要的约定:
- 同一个条件组内,是 AND 关系
- 不同条件组之间,是 OR 关系
也就是说,一条规则可以表达出类似这样的逻辑:
(金额 ≥ 100 且 渠道 = APP) 或 (金额 ≥ 200)
在执行时,我们只做一件事: 拿事件 payload 中的数据,与条件表进行匹配判断。
如果规则没有配置任何条件,则默认视为"无条件规则",始终生效。
触发次数与发放次数:我们刻意拆开的两件事
在设计积分系统时,有一个点非常容易被忽略: 规则被触发,并不等于积分一定会被发放。
很多早期的积分实现,往往把这两件事情混在一起: 事件来了 → 判断条件 → 直接加积分。 一开始用着没问题,但一旦规则稍微复杂一点,就会开始失控。
所以在这一版设计里,我们刻意把这两件事情拆开来处理: 一次是"触发是否达标",一次是"是否还能发放"。
触发统计:这条规则被"碰到"了多少次?
先看触发统计这一层,它解决的是类似下面这些需求:
- 连续签到 3 次,才给一次积分
- 累计完成 N 次某个行为后,再发奖励
也就是说,规则不是一来就生效,而是要"攒次数"。
为此我们单独设计了一张规则触发统计表:
sql
CREATE TABLE `point_rule_trigger` (
`user_id` bigint(20) NOT NULL COMMENT '用户ID',
`rule_id` bigint(20) NOT NULL COMMENT '规则ID',
`trigger_key` varchar(32) NOT NULL COMMENT '触发统计周期Key(如 2025-01-01)',
`trigger_count` int(11) NOT NULL DEFAULT '0' COMMENT '当前周期内已触发次数',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最近一次触发时间',
PRIMARY KEY (`user_id`,`rule_id`,`trigger_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='积分规则触发统计表(用于触发N次才发积分)';这张表的关注点非常单一: 在某个统计周期内,这条规则被这个用户触发了多少次。
- 周期用
trigger_key表示,比如按天、按周 - 每次事件命中规则,就累加一次
- 是否"达到触发阈值",只和这张表有关
它不关心积分发没发,只负责数次数。
发放限制:这个周期内还能不能再发?
接下来是发放限制这一层,它解决的是另一类问题:
- 每天最多发放 1 次
- 每周最多发放 3 次
- 防止同一规则被疯狂刷分
这里我们同样单独设计了一张表,而不是复用触发表:
sql
CREATE TABLE `point_rule_grant` (
`user_id` bigint(20) NOT NULL COMMENT '用户ID',
`rule_id` bigint(20) NOT NULL COMMENT '规则ID',
`grant_key` varchar(32) NOT NULL COMMENT '发放周期Key(如 2025-01-01)',
`grant_count` int(11) NOT NULL DEFAULT '0' COMMENT '当前周期内已发放次数',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最近一次发放时间',
PRIMARY KEY (`user_id`,`rule_id`,`grant_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='积分规则发放限制表(用于限制每日/每周发放次数)';这张表只做一件事: 在当前发放周期内,这条规则已经真正发放了多少次积分。
- 不关心规则有没有被触发
- 不关心触发条件是否满足
- 只在"准备发积分"之前做一次拦截判断
如果已经达到上限,哪怕触发条件满足,也会被直接拦掉。
为什么一定要拆成两张表?
这里其实是一个很典型的系统设计取舍。
如果把触发次数和发放次数揉在一起:
- 连续触发类规则会变得很难理解
- 发放限制逻辑会越来越绕
- 后期加新规则,几乎只能改代码
而拆开之后,规则执行的语义会非常清晰:
- 先判断:触发次数够不够
- 再判断:这个周期还能不能发
- 两个阶段各自有明确的数据支撑
这样一来,不管是"连续签到""满 N 次奖励",还是"每天最多一次",都可以通过组合配置完成,而不需要在代码里写特殊判断。
这也是后续规则体系能够持续扩展、却不失控的一个关键点。
基础积分计算与倍率叠加
当规则被确认命中之后,系统会先计算基础积分:
- 固定积分:直接取配置值
- 比例积分:根据 payload 中的金额字段进行向下取整计算
基础积分计算完成后,并不会立刻入账。 系统还会额外做一步:查询是否命中积分倍率活动。
倍率的作用非常明确:
- 不修改规则
- 不修改基础计算逻辑
- 只在最终结果上做一次放大
最终得到的,是一个"倍率前积分 + 实际生效倍率 + 最终积分值"的完整计算结果。
为什么要区分流水、明细和账户
在积分真正入账的时候,我们并不是简单地去更新一个"余额字段"。 相反,每一次积分结算,都会同时写入三类数据:积分流水、积分明细和积分账户。
这三张表看起来都和"积分"有关,但在设计上承担的是完全不同的职责。
积分流水(Ledger):把每一次变动讲清楚
积分流水更像是一份审计级账本 。 它关注的不是"现在还剩多少分",而是这一次积分为什么会变成这样。
对应的表结构如下:
sql
CREATE TABLE `point_ledger` (
`tx_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '积分流水ID,全局唯一',
`user_id` bigint(20) NOT NULL COMMENT '用户ID',
`rule_id` bigint(20) NOT NULL COMMENT '积分规则ID',
`source_id` varchar(64) NOT NULL COMMENT '业务来源ID(订单ID/签到ID等,用于幂等)',
`change_amount` int(11) NOT NULL COMMENT '本次积分变动值',
`before_balance` int(11) NOT NULL COMMENT '变动前余额',
`origin_amount` int(11) NOT NULL COMMENT '倍率前的原始积分值',
`applied_multiplier` decimal(10,2) NOT NULL COMMENT '实际生效倍率',
`multiplier_id` bigint(20) DEFAULT NULL COMMENT '命中的倍率配置ID',
`after_balance` int(11) NOT NULL COMMENT '变动后余额',
`type` varchar(16) NOT NULL COMMENT 'EARN/SPEND/EXPIRE/ADJUST',
`remark` varchar(255) DEFAULT NULL COMMENT '备注说明',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`tx_id`),
UNIQUE KEY `uk_rule_source` (`rule_id`,`source_id`)
) ENGINE=InnoDB COMMENT='积分流水表(审计账本)';这张表记录的是事实:
- 这笔积分来自哪条规则
- 对应哪个业务来源(用于幂等)
- 发放前后余额如何变化
- 有没有命中倍率,倍率是多少
只要流水在,任何一笔积分都能被完整解释清楚。
积分明细(Detail):这些积分以后怎么用
和流水不同,积分明细站在的是资产视角。 它关注的是:这些积分以后怎么消费、什么时候过期。
表结构如下:
sql
CREATE TABLE `point_detail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '积分明细ID',
`user_id` bigint(20) NOT NULL COMMENT '用户ID',
`ledger_tx_id` bigint(20) NOT NULL COMMENT '关联的积分流水ID',
`amount` int(11) NOT NULL COMMENT '本次获得的积分数量',
`remain_amount` int(11) NOT NULL COMMENT '当前剩余可用积分',
`expired_at` datetime DEFAULT NULL COMMENT '过期时间,NULL表示永久有效',
`status` varchar(16) NOT NULL DEFAULT 'NORMAL' COMMENT 'NORMAL/CONSUMED/EXPIRED',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='积分明细表(资产池,用于过期与消费)';每一条明细,都是一笔"可被消费的积分资产"。
- FIFO 消费
- 定时过期
- 部分使用、部分剩余
这些能力全部依赖积分明细来完成。 如果只有流水而没有明细,积分系统在"使用"和"过期"阶段几乎无法扩展。
积分账户(Account):只负责给出当前结果
积分账户是一张非常克制的表。 它不关心规则、不关心倍率,也不参与任何计算逻辑。
sql
CREATE TABLE `point_account` (
`user_id` bigint(20) NOT NULL COMMENT '用户ID',
`balance` int(11) NOT NULL DEFAULT '0' COMMENT '当前积分余额',
`version` int(11) NOT NULL DEFAULT '0' COMMENT '乐观锁版本号',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB COMMENT='用户积分账户表(仅存当前余额)';它只解决一个问题: 用户现在还有多少积分。
所有复杂逻辑都已经在流水和明细层完成,账户表只负责存最终结果,保证高并发下的查询性能。
三张表为什么必须同时存在
这三张表看起来有些"重复",但它们解决的是完全不同层面的事情:
- 流水:保证过程可审计
- 明细:保证资产可管理
- 账户:保证查询够快
在一次积分结算中,这三者必须在同一个事务内同时成功。 只有这样,积分系统才能做到:
- 结果一致
- 过程可追溯
- 出问题能回查
这也是后面风控审计、人工补偿、异常排查能够成立的基础。
原子性与一致性保证
整个积分结算过程是放在一个事务中完成的:
- 任意一步失败,整体回滚
- 账户余额更新使用乐观锁,防止并发冲突
- 流水表通过
(rule_id, source_id)做幂等约束,防止重复发放
这样一来,即使在高并发场景下,积分系统依然可以做到:
- 不多发
- 不漏发
- 可追溯
小结
到这里,我们已经完整走完了一次积分事件从"上报"到"落账"的全过程。
在这一层设计中,我们刻意避免了三件事情:
- 把规则写死在代码里
- 把所有限制混在一个判断里
- 只用一个表记录积分变化
通过事件、规则、倍率、触发统计、发放限制、流水、明细、账户的分层设计,积分系统才能在复杂业务下依然保持清晰和可控。
查看用户积分:从规则执行到结果可追溯
当积分规则、结算逻辑全部跑通之后,下一步真正要面对的问题其实是:
这些积分,最终落到用户身上,到底是什么样子?
因此,在 point-center 中,我们专门设计了一套以用户为中心的积分视图,用于承接所有规则执行后的结果。
用户积分列表:先看"结果",而不是规则
在后台的「用户积分」模块中,默认展示的是一个用户维度的积分列表。如图所示:
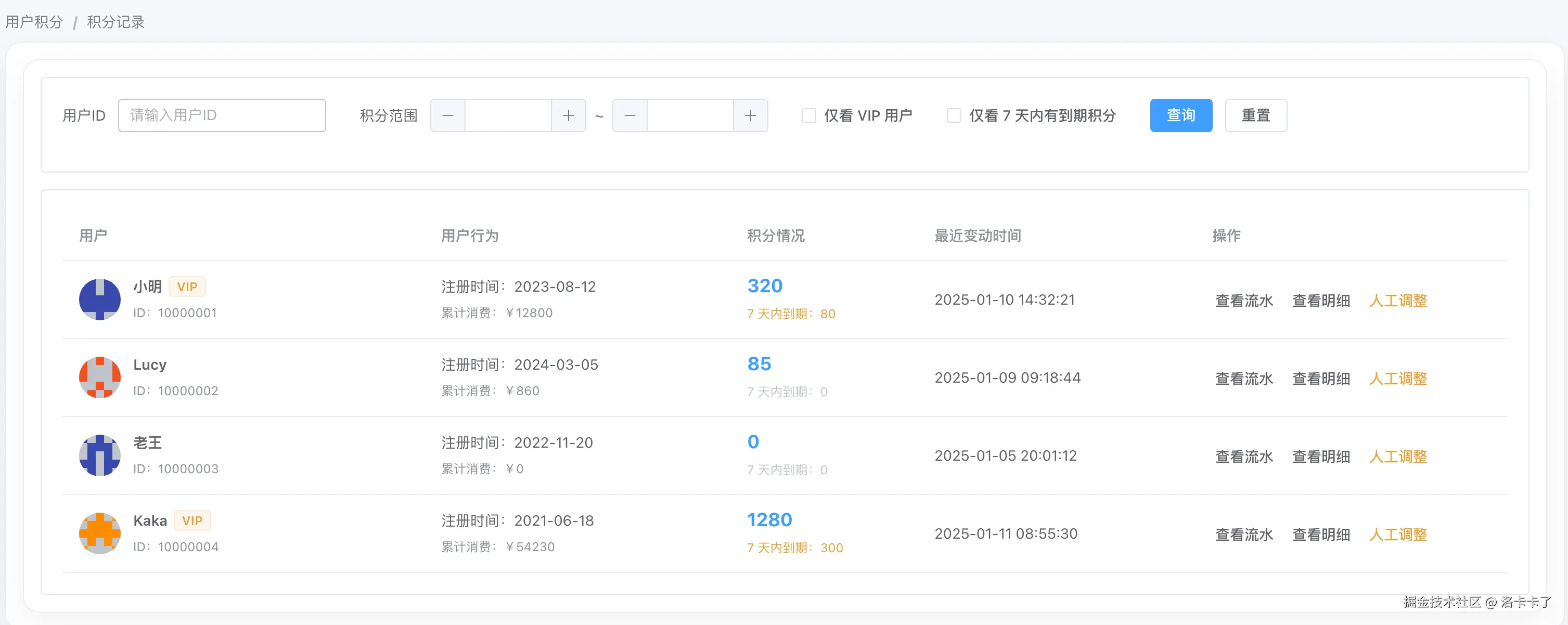
这个页面只关心几件事情:
- 用户当前可用积分是多少
- 最近一次积分变动发生在什么时候
- 是否存在即将到期的积分
- 是否是 VIP、是否存在风险标签
如上图所示,列表中不会直接暴露复杂的规则信息,而是以运营和客服最关心的结果状态为主:
- 当前积分(汇总值)
- 7 天内即将到期的积分数量
- 最近一次积分变动时间
- 可直接进入「流水」「明细」「人工调整」
这个设计的核心原则是:
规则是给系统用的,结果才是给人看的。
积分流水:回答"这一次积分是怎么来的"
在用户列表中点击「查看流水」,进入的是积分流水视图(Ledger) 。
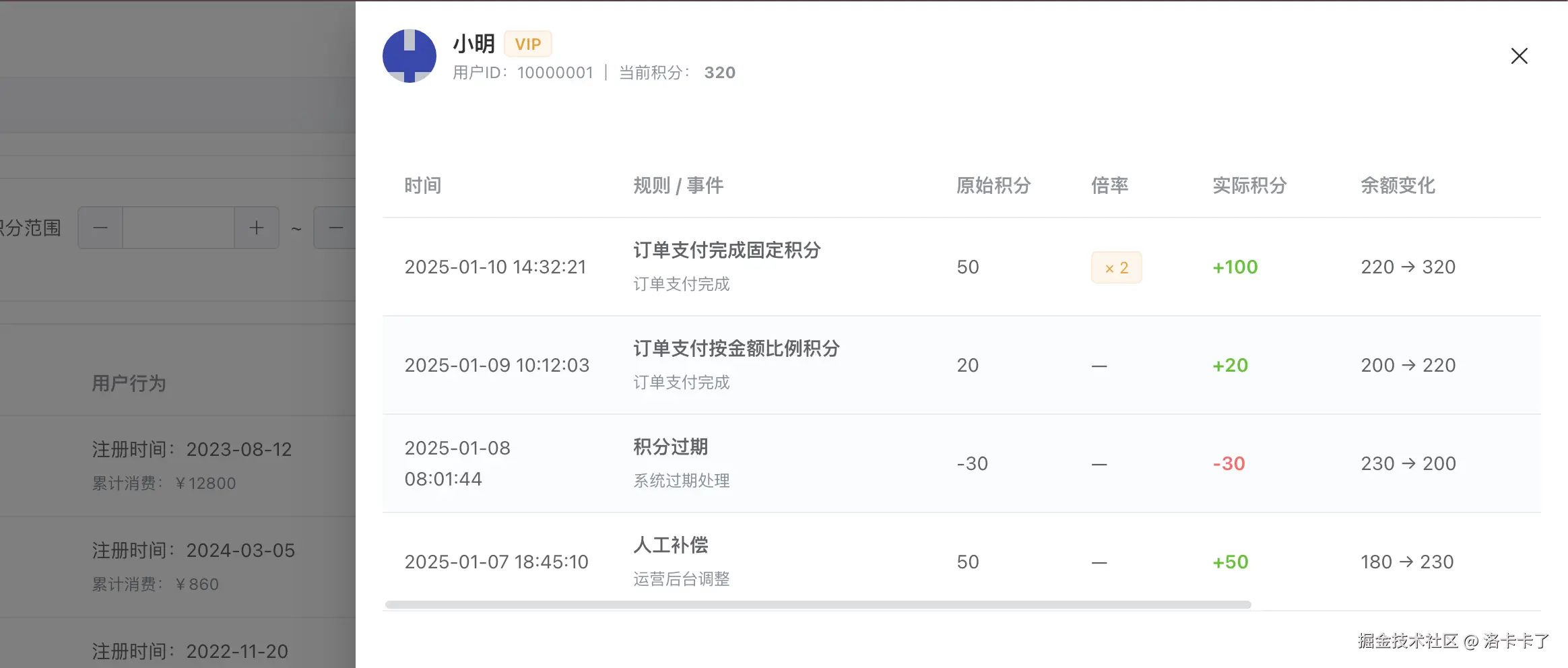
这一层展示的是一次次积分变动的过程记录,比如:
- 由哪条规则触发
- 对应的业务事件是什么
- 原始积分是多少
- 是否命中了倍率
- 最终实际生效了多少积分
- 余额是如何变化的
从页面上可以清楚看到类似这样的信息:
- 「订单支付完成固定积分」
- 原始积分 50
- 命中活动倍率 ×2
- 实际积分 +100
- 余额从 220 变为 320
这正好对应我们在设计时对 point_ledger 的定位:
它是一个审计级账本,用于解释"为什么这次积分会变成这样"。
无论是客服排查、运营核对,还是风控回溯,流水永远是第一入口。
积分明细:回答"这些积分以后怎么用"
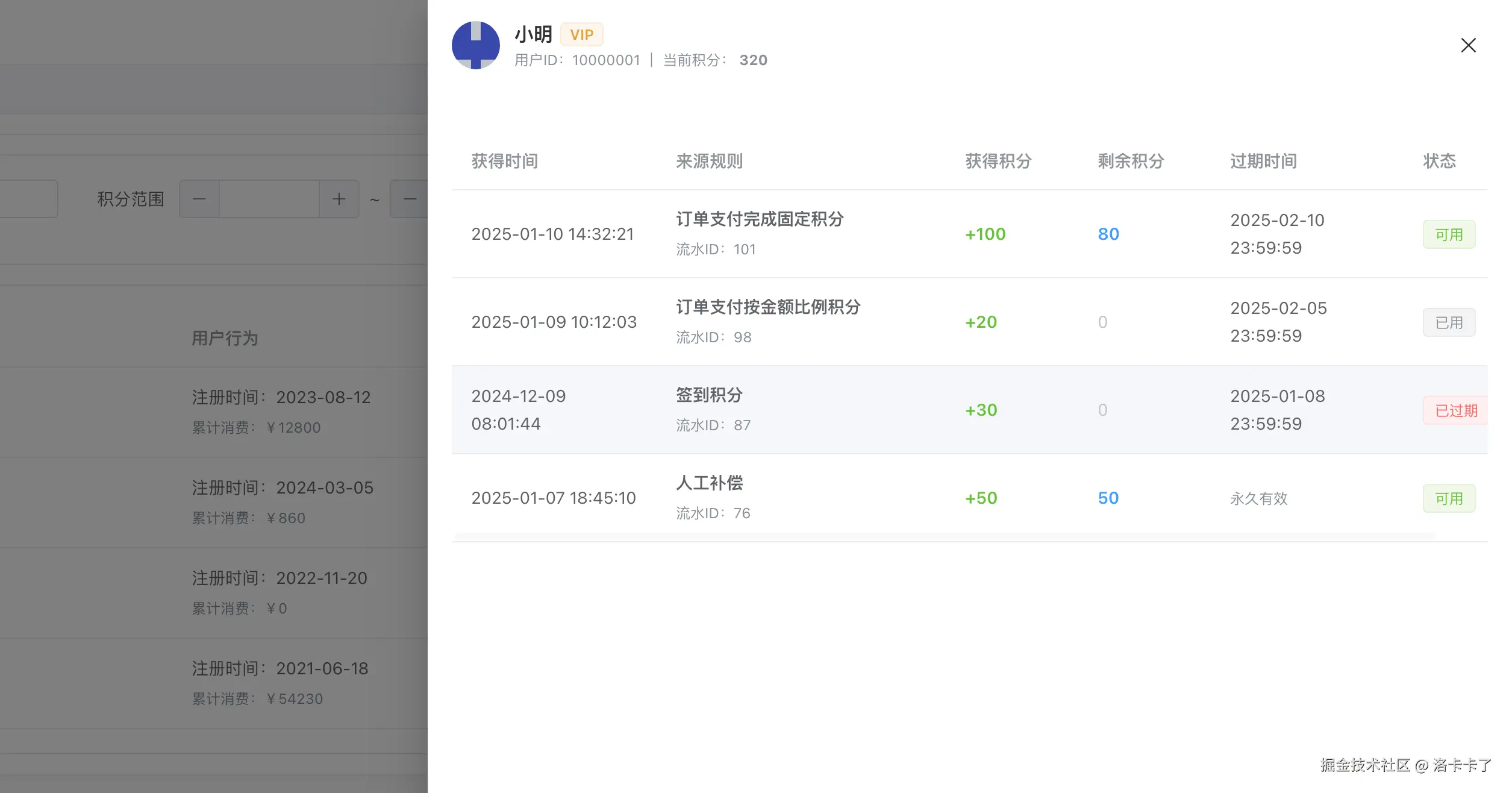
与流水不同,「查看明细」进入的是积分明细视图(Detail) 。
这里关注的已经不是"发生了什么",而是:
- 这批积分还剩多少
- 是否已经被使用
- 是否已经过期
- 如果有过期,是哪一次发放的积分过期了
页面中可以清楚看到:
- 每一条积分明细对应一次流水
- 明确的过期时间(或永久有效)
- 当前剩余可用积分
- 状态:可用 / 已用 / 已过期
这正是 point_detail 表存在的意义:
用于支撑 FIFO 消费、过期处理、精确扣减。
也正因为有这层明细存在,系统才能做到:
- 扣积分时优先扣即将过期的
- 定时任务只处理已到期的那一批积分
- 不会出现"余额对得上,但明细对不上"的问题
为什么还需要「人工调整积分」
再完整的规则系统,也无法覆盖所有现实场景。
在实际运营中,人工调整积分通常出现在这些情况下:
- 用户投诉,需要补偿积分
- 活动异常,规则漏发,需要人工补发
- 风控介入,需要扣除异常获取的积分
- 历史问题修正,需要人工修账
因此在用户列表中,我们提供了「人工调整」入口。
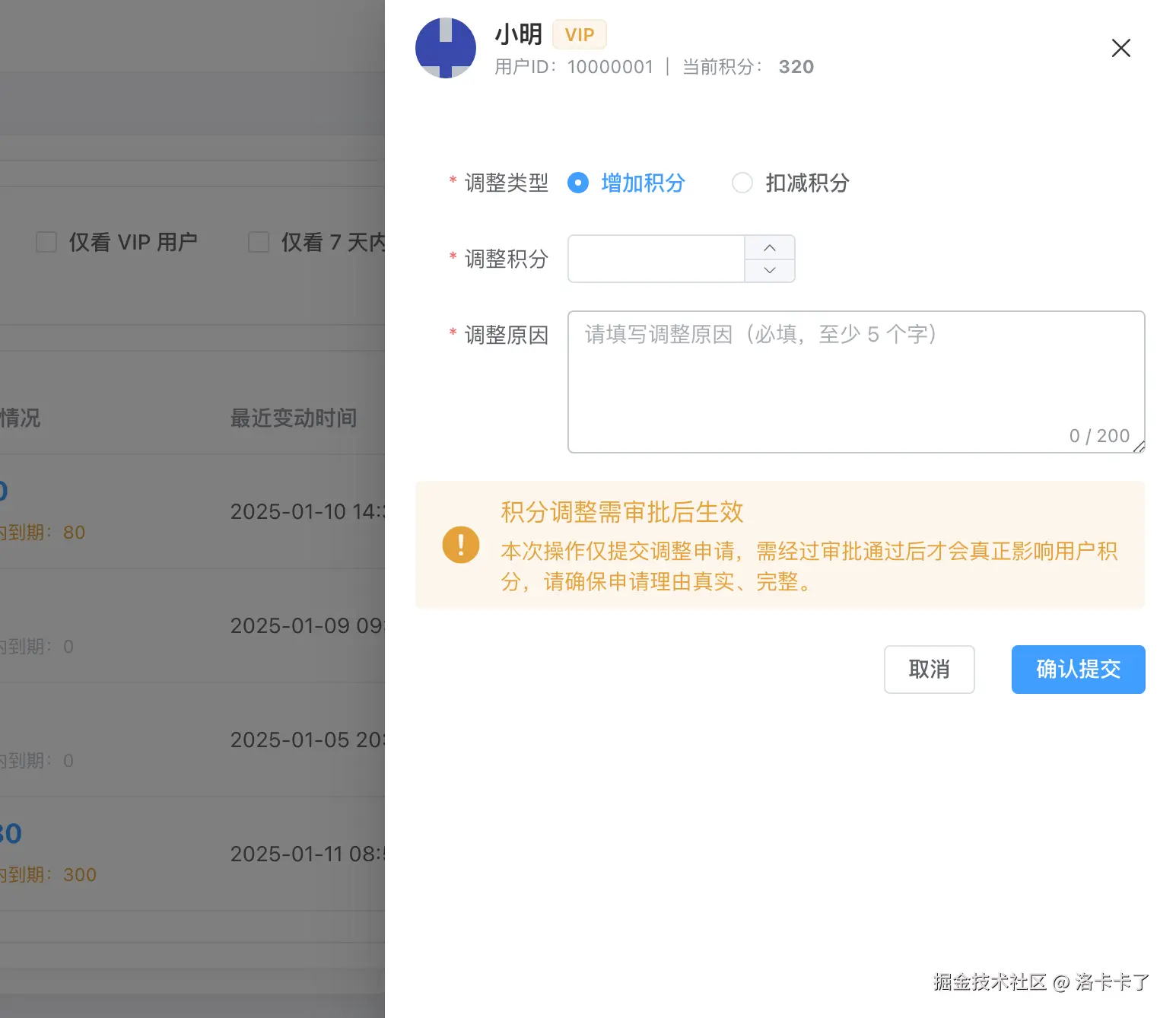
人工调整不是直接改余额
从页面上可以看到,人工调整并不是一个"随便加减"的操作,而是一个受控流程:
- 明确区分「增加积分 / 扣减积分」
- 必填调整原因,且有最少字数限制
- 明确提示:需要审批后生效
- 每一次人工操作都会进入流水与审计体系
这类操作在系统内部同样会:
- 写入 point_ledger(类型为 ADJUST)
- 生成对应的 point_detail(如果是增加)
- 更新 point_account 余额
- 进入人工操作审计模块,供风控回溯
这样设计的目的只有一个:
人工兜底可以存在,但必须可追溯、可审计、可回放。
从数据看积分系统的真实运行状态
在规则和结算逻辑跑通之后,其实还有一个非常关键的问题需要被回答清楚: 这套积分系统现在到底在怎么运转?
单看规则配置本身,其实很难判断系统是不是健康的。真正有价值的视角,来自于积分在真实用户行为中的流转情况。所以在后台中,我们简单设计了一层积分分析视图,用来从整体数据层面观察积分系统的运行状态,如下图所示:
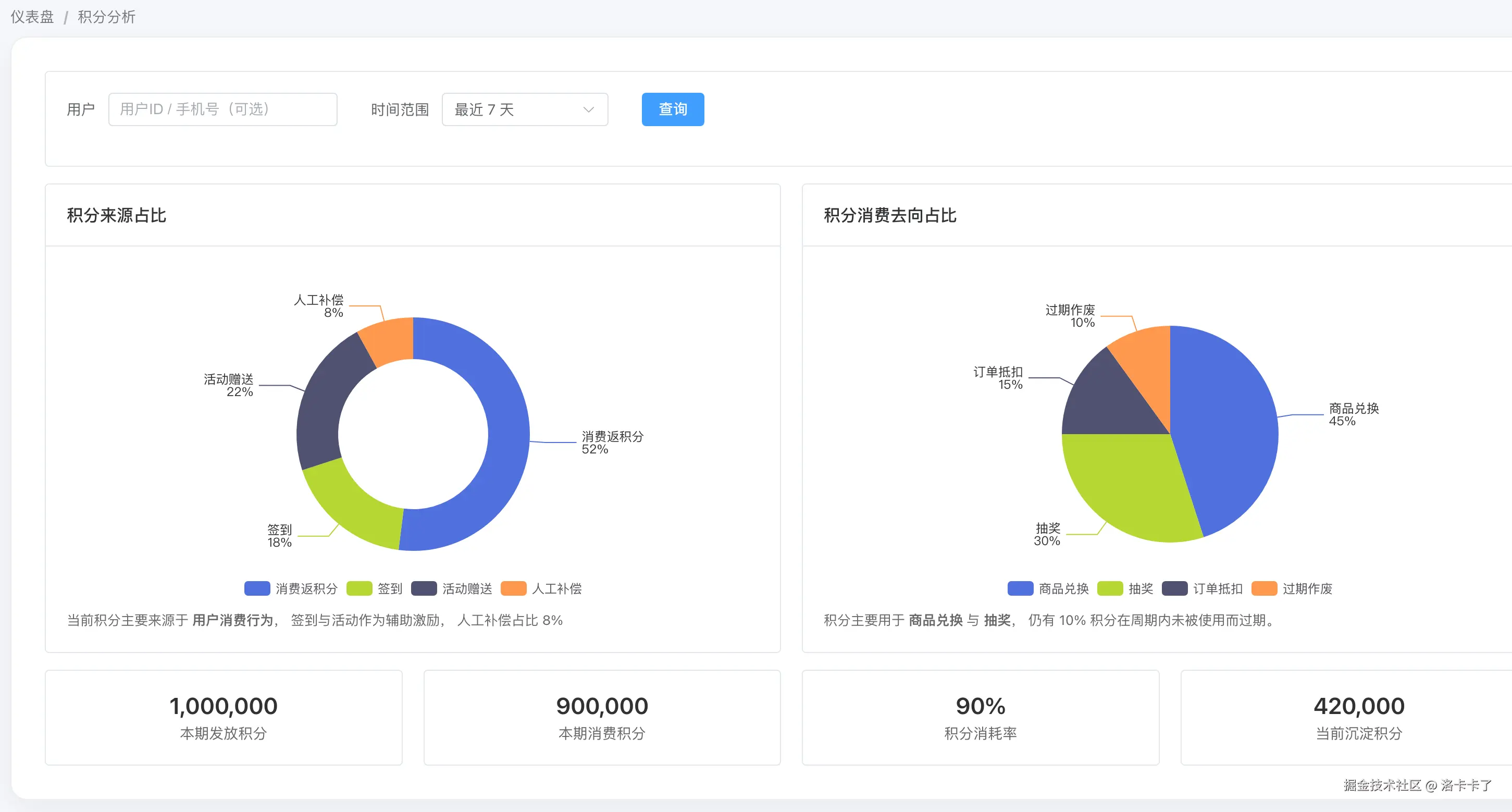
从这个页面里,我们可以直观看到积分主要来源于哪些行为,比如是消费返积分为主,还是签到、活动赠送占比较高;同时也能看到积分最终被用在了哪里,是商品兑换、抽奖,还是大量因为过期而被消耗掉。这些数据本身并不直接参与规则判断,但它们会非常明显地反映出当前积分体系的结构是否合理。
更重要的是,这个视图并不只是给技术或风控看的,它对运营同样非常关键。运营在配置规则时,不能只关心规则有没有生效,还需要结合这些数据去理解用户的积分画像:哪些用户在高频赚积分,哪些用户长期囤积分却不使用,哪些积分规则发放量很大,但实际转化效果并不好。
这些信息,都会直接影响后续规则的调整方向。比如是否需要引导积分消费、是否需要限制某些发放过快的规则、是否要针对不同用户行为设计差异化玩法。也正是基于这样一层数据观察,后面的风控判断和规则优化才不是拍脑袋,而是有迹可循的系统性决策。
积分风控层:为积分体系增加一道安全保障
在积分规则和结算逻辑逐渐完善之后,我们很快会遇到一个现实问题:
我们设计的积分系统,真的安全吗?
从系统设计上看,规则没问题、逻辑也没问题,但在真实运行中,积分系统面对的是不受控的用户行为、不断变化的活动策略,以及不可避免的人工操作。
这也是我们最终决定引入「积分风控层」的原因。
为什么单靠规则系统不够?
积分规则解决的是一件事:
在什么情况下,给多少积分。
但它并不擅长回答这些问题:
- 这条规则最近发放的积分是不是异常地多?
- 某个用户的积分增长,是否明显偏离正常水平?
- 人工补偿、人工扣减,有没有被滥用?
- 多个规则、倍率叠加在一起,会不会放大风险?
举几个真实容易出现的场景。
场景一:规则没错,但被"刷"了
比如一条比例积分规则:
- 每消费 10 元给 1 积分
- 本身逻辑完全合理
但如果某个用户在极短时间内高频触发,或者被脚本反复调用接口,规则并不会觉得这是异常的,它只会老老实实算分、发分。
等发现问题时,积分已经发出去了。
场景二:倍率和活动叠加,放大了风险
再比如:
- 一条长期有效的比例积分规则
- 恰好命中了一个双倍积分活动
从配置角度看,每一项都是"合法的", 但叠加在一起,就可能导致:
- 短时间内积分发放规模异常放大
- 单条规则成为积分系统的主要风险来源
规则系统本身,很难主动意识到这种"组合风险"。
场景三:人工调整,本身就是高风险操作
人工调整是积分系统里必须存在的一环,但它天然带有风险:
- 人为操作,无法完全避免误操作
- 补偿、扣减一旦量级较大,影响直接反映在用户资产上
- 如果缺乏监控和审计,很容易成为系统隐患
所以只要存在人工操作,就一定要有对应的风控视角。
场景四:数值异常,往往是问题的第一信号
在实际运营中,很多问题不是"明确的错误",而是数值开始变得不正常:
- 某条规则的发放量突然飙升
- 某个用户积分短时间内暴涨
- 某类规则的发放趋势明显偏离历史水平
这些情况,如果只依赖人工事后排查,成本会非常高。
所以,积分风控解决的是什么?
在我们的设计里,积分风控层并不是用来"代替规则"的,而是承担一个更偏守门人的角色:
- 对积分发放行为做整体观察
- 对异常趋势进行提前暴露
- 对高风险规则和用户进行标记
- 为人工干预和审计提供依据
换句话说:
规则负责把积分发出去, 风控负责盯着发得对不对、稳不稳。
这也是后面我们会看到的一系列风控页面存在的前提。
积分风控层:为积分体系加上一层安全保障
在真正把积分系统跑到线上之前,其实有一个问题是绕不开的: 积分一旦发出去,基本就是"真钱"。
不管是能抵扣现金、兑换商品,还是影响用户等级,只要积分具备价值,它就一定会被盯上。
我自己在做积分系统时,遇到过几类非常典型的问题: 比如某个规则配置不当,被用户短时间刷出大量积分; 比如活动倍率叠加时没控制好,积分发放突然暴涨; 再比如人工补偿操作没有审计,最后根本说不清是谁、因为什么给了用户这笔积分; 还有一种更常见的,是数据本身没有问题,但数值"看起来就很不对劲",运营或风控却没法第一时间发现。
这些问题如果等到用户已经把积分用掉,再回头查,成本会非常高。 所以在设计积分系统时,我一开始就把它当成一个需要风控兜底的资产系统来看,而不是一个简单的"加减数值"。
基于这个前提,我在积分服务中心里单独拆出了一层 积分风控模块 ,专门用来做三件事: 看趋势、找异常、兜人工操作。
后台整体结构说明
在后台结构上,积分相关的页面我并没有全部堆在"用户积分"下面,而是单独划分出了一个 积分风控管控区,配合一个整体的积分大盘,用来从不同视角观察系统状态。
下面我结合页面简单讲一下每一块在系统里承担的角色。
积分大盘:先看整体是不是"健康的"
如图所示,积分大盘并不是用来做精细操作的,它的定位非常明确,就是一句话: 今天积分系统是不是在正常工作。
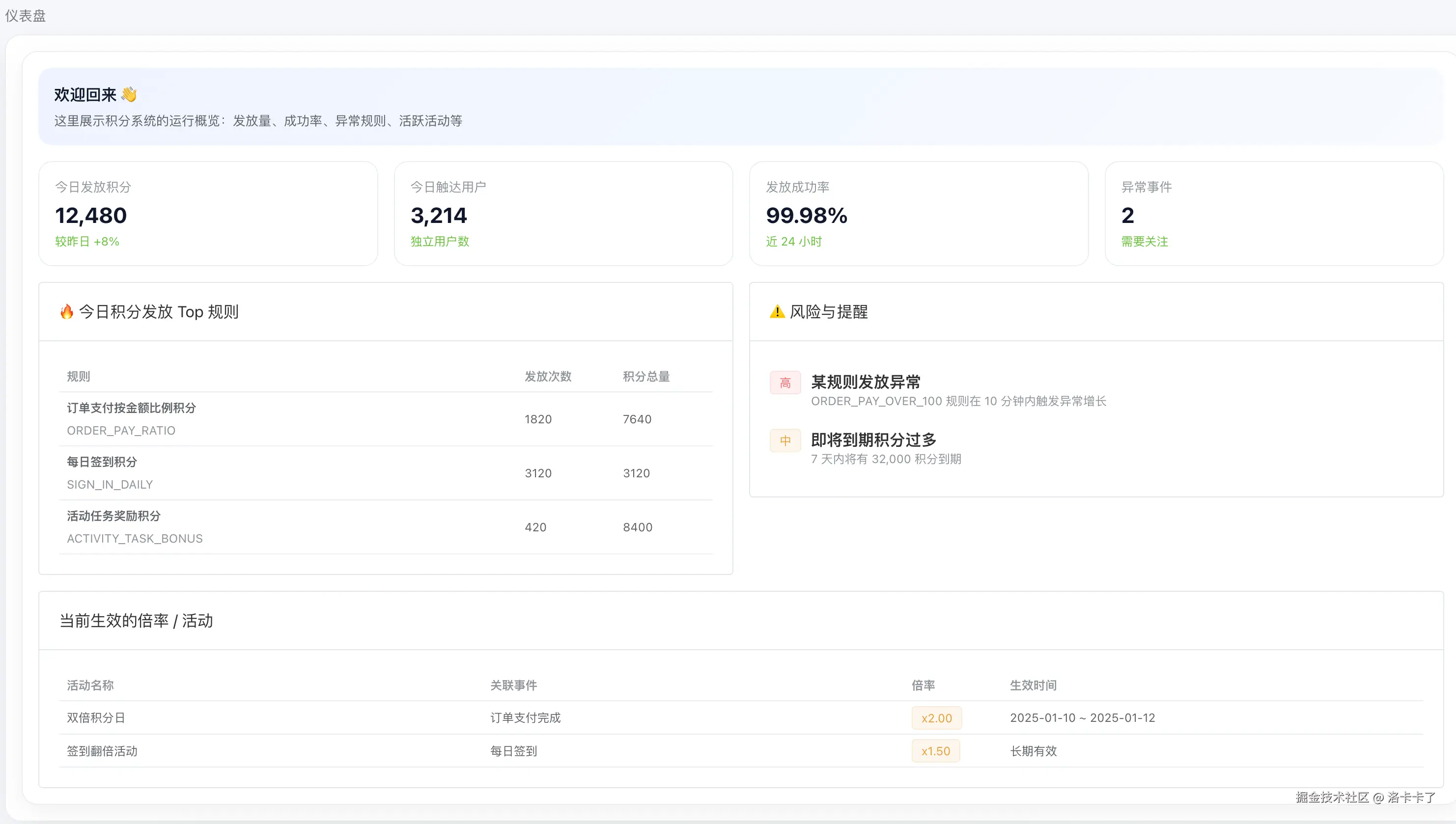
在这个页面里,我重点放了几类指标: 当天积分发放总量、触达用户数、发放成功率,以及是否存在异常事件。 同时还会列出当天积分发放最多的规则,以及当前正在生效的倍率和活动。
这些信息的价值不在于"查某一个用户",而在于快速感知系统状态。 只要我们发现发放量、命中规则或者倍率活动和我们的预期不一致,就应该立刻往下钻,而不是等用户来反馈。
积分风控管控模块
如果说积分大盘是"全局视角",那风控模块更多就是问题定位区。
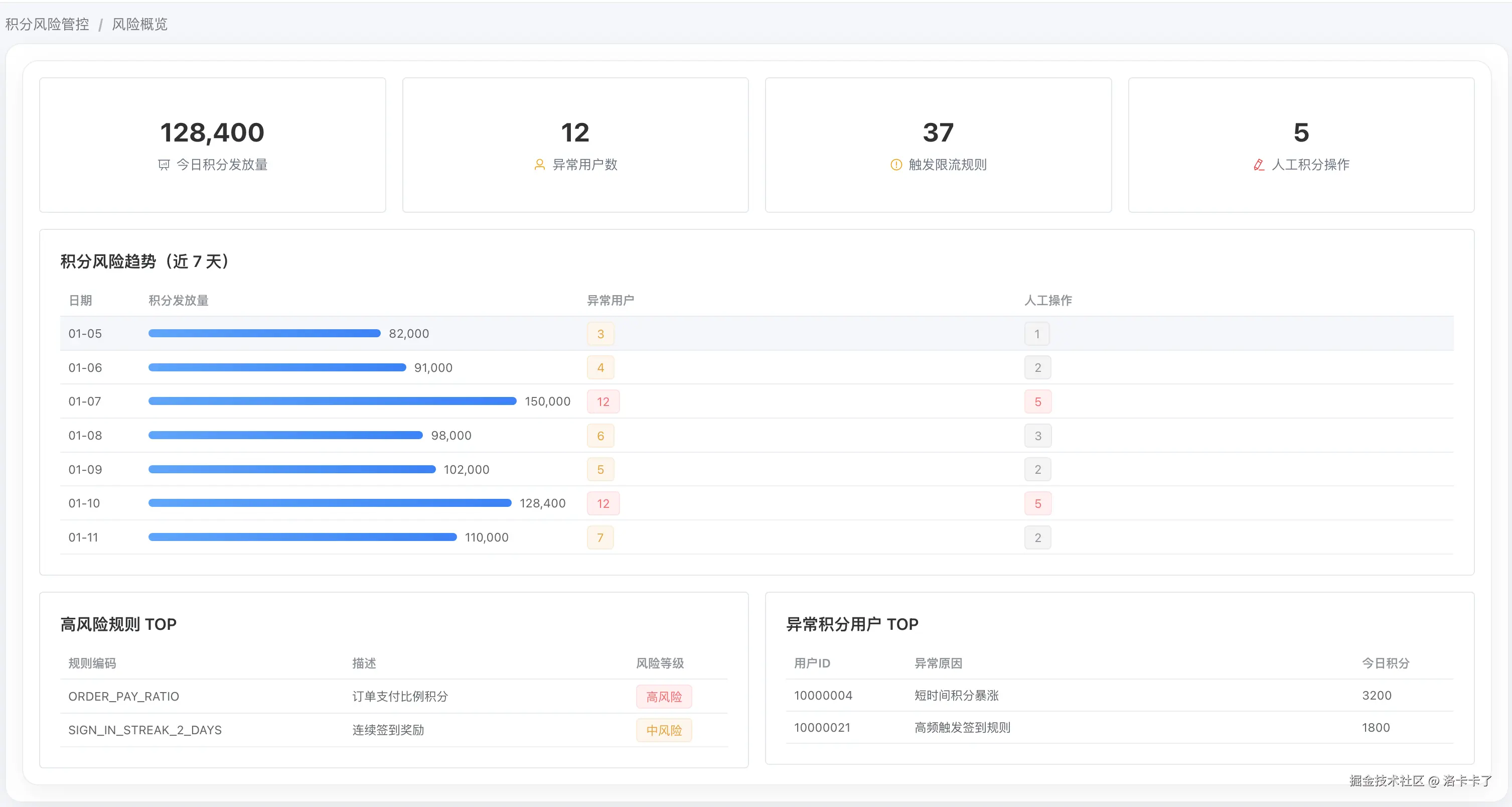
风险概览:把异常集中到一个视图里
风险概览页面的核心作用,是把分散在各处的异常信号集中展示出来。 比如当天积分发放总量、异常用户数、触发限流的规则数量,以及人工积分操作的次数。
再往下,会看到近 7 天的风险趋势,把积分发放量、异常用户、人工操作放在同一个时间轴里,其实一眼就能看出是否存在"异常共振"的情况。
这个页面的设计目标很简单: 不要求我们立刻知道问题原因,但要让我们知道"这里不太对劲"。
异常积分记录:把可疑的用户直接拎出来
当系统识别到积分异常时,并不会悄悄处理,而是会生成一条异常积分记录,统一进入这个列表。

在这个页面里,我们可以直接看到: 是哪一个用户、命中了哪条规则、异常指标是多少、异常类型是什么,以及当前处理状态。
这一步非常关键的一点是: 异常并不等于错误,它只是告诉我们这个行为值得被关注。
有些异常可能是正常活动导致的,有些则可能是规则配置问题,或者刷行为的前兆。 是否需要处理,交给风控或运营来判断,但系统必须把问题暴露出来。
高风险规则:从规则而不是用户反推问题
很多时候,问题并不在某个用户身上,而是在规则本身。
所以我单独做了一个 高风险规则视图,从规则维度出发,把近 7 天发放积分异常集中的规则拉出来,并结合风险因子进行标记,比如: 是否是比例积分、是否命中倍率活动、是否存在无限发放、是否高频触发等。

这个页面的意义在于: 帮我们判断,是不是规则设计本身就有风险,而不是等用户一个个冒出来再处理。
人工操作审计:给人工操作上的最后一道约束
最后一块,是人工操作审计。
在积分系统里,人工补给或扣除几乎是不可避免的: 用户投诉、活动补偿、数据修正,都会涉及人工调整。
但只要是人工操作,就一定要有审计。
在这个页面中,所有非自动产生的积分变动都会被完整记录,包括: 操作人、操作对象、积分变动值、是否被判定为风险操作,以及对应的时间点。
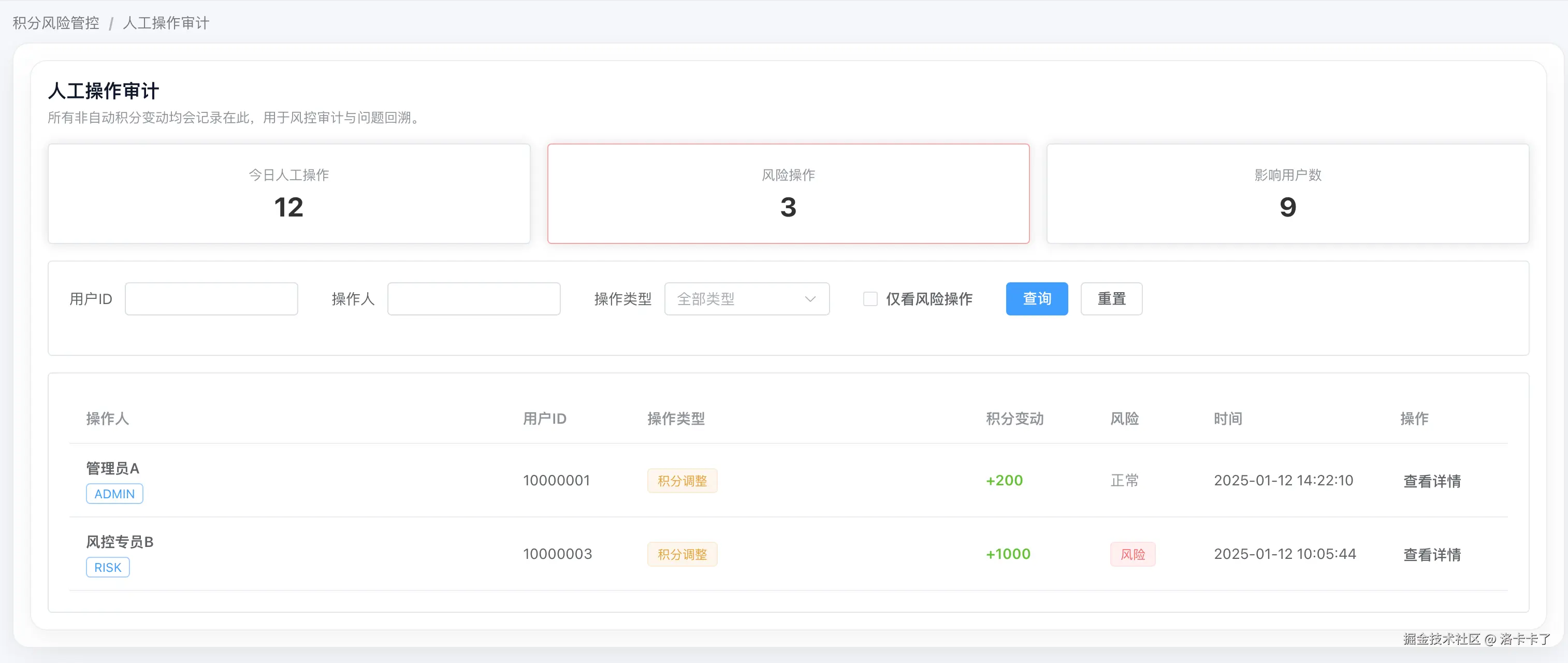
同时我还会单独统计当天人工操作次数、风险操作次数和影响用户数,避免人工操作在系统中"悄悄发生"。
这一步并不是为了限制运营,而是为了在出问题时能清楚地还原发生了什么。
小结一下
积分系统一旦具备价值,就一定要被当成资产系统来设计。 而资产系统,永远不能只关心"怎么算",还必须关心"会不会出事、出了事怎么看"。
所以在这个积分体系里,风控层并不是一个附加功能,而是从一开始就被当成核心模块来设计的。 它不直接参与积分计算,但决定了这个系统能不能长期、安全地跑下去。
风控规则的设计原则:高风险规则并不是一张表
在积分系统中,我们并没有把「高风险规则」当成一个独立维护的业务实体来看。 相反,它更像是一个基于现有数据和策略,在运行时计算出来的判断结果。
换句话说,高风险规则并不对应数据库里的某一张表,而是一个派生视图。
这一点,可能和很多人一开始的直觉其实是相反的。
为什么没有单独设计一张「高风险规则表」
在设计积分风控模块时,很多人的第一反应通常是:
要不要建一张
high_risk_rule表? 把规则、风险等级、风险原因都存下来?
但在真正落地设计之后,我们反而刻意没有这样做。
原因很简单------ 高风险规则本身,并不是一个稳定的业务数据实体。
高风险规则不是事实数据
在积分系统里,我们通常会把数据分成两类。
一类是事实数据,比如:
- 积分规则配置(
point_rule) - 积分流水(
point_ledger) - 积分明细(
point_detail)
这些数据一旦产生,就具备明确的业务含义,可以长期存储、反复使用,也具备审计价值。
而「高风险规则」并不属于这一类。
它本质上是一个结论,回答的是这样的问题:
在某一个时间点 , 基于当前规则配置、近期积分行为以及风控策略, 这条规则现在风险高不高?
也就是说,它描述的是一种判断结果,而不是一个业务事实。
风险是"算出来的",不是"存出来的"
以高风险规则页面为例,它展示的数据并不是凭空出现的,而是来源于三类已有数据:
第一类:规则配置数据 来自 point_rule 表,用于判断规则的基础属性,比如是不是比例积分、有没有发放上限、是否长期有效等。
第二类:倍率与活动数据 来自 point_multiplier_config 表,用于判断规则是否存在倍率叠加、活动放大的风险。
第三类:积分发放行为数据 来自 point_ledger / point_detail 表,用于统计规则在一定时间窗口内(比如近 7 天)的实际发放规模和波动情况。
在这些数据的基础上,我们再通过一层风控评估逻辑进行综合判断,把原始数据转化为:
- 风险等级
- 风险因子说明
- 关键统计指标
最终生成高风险规则页面所需的数据结构。
高风险规则页面的数据从哪里来
从系统结构上看,高风险规则页面并不是直接读取某一张表,而是一个典型的"派生视图":
规则配置(point_rule)
+
倍率活动(point_multiplier_config)
+
积分发放行为(point_ledger / point_detail)
+
风控评估逻辑(RiskEvaluator)
↓
高风险规则视图(HighRiskRuleDTO)对应到接口层,比如我们会提供这样一个接口:
ini
GET /risk/high-rules?days=7返回的其实是一组已经完成风控评估的 DTO,而不是数据库记录,例如:
json
[
{
"ruleId": 1,
"ruleCode": "ORDER_PAY_RATIO",
"ruleDesc": "订单支付按金额比例积分",
"riskLevel": "HIGH",
"riskFactors": [
"比例积分规则",
"命中双倍积分活动",
"近7日发放积分超过阈值"
],
"metrics": {
"points7d": 420000,
"hitMultiplier": true
}
}
]高风险规则页面本质上展示的是一组经过风控评估后的 DTO(Data Transfer Object) ,而非直接映射数据库表结构。
为什么不一开始就把风险结果落表呢
如果我们一开始就把高风险规则直接存成表,会立刻遇到一系列现实问题:
- 同一条规则,今天是高风险,明天还是吗?
- 风控策略调整后,历史风险数据要不要重算?
- 风险等级变化,是更新原记录,还是新增一条?
- 不同时间窗口下的风险结论,怎么共存?
这些问题本质上都指向同一个结论:
风险评估结果是动态的,而数据库表更适合存放稳定事实。
在当前阶段,把高风险规则设计为实时评估 + 即时展示,反而边界更清晰,也更利于风控策略的演进。
那我们什么时候才值得落表呢
只有在一种情况下,高风险规则才有必要被存下来:
当风险评估结果需要被确认、处理或审计的时候。
比如:
- 风控人员确认某条规则确实存在问题
- 需要给出人工判断结论或备注
- 需要对风险处理过程进行留痕和回溯
但即便如此,真正落表的也不是"高风险规则本身",而是:
某一次风险评估的结果快照(Snapshot) , 而不是当前实时的风险状态。
设计上的一句总结
所以,在积分系统的风控设计中,我们更倾向于这样理解:
高风险规则不是一张表,而是一次风险评估的结果。
它来自已有数据的组合判断, 会随着时间、行为和策略变化而变化, 也正因如此,它更适合作为一个派生视图存在,而不是被固化为业务主数据。
积分过期处理:扫描结算 + 消费时校验的双重保障
在积分过期的设计上,我们并没有把是否过期这件事完全交给定时任务,而是拆成了两条相互配合的处理链路 : 一条负责账务结算 ,一条负责使用时兜底校验。
一、过期扫描:只负责"把账算清楚"
首先,系统会通过定时任务对积分明细表进行过期扫描,但这个扫描并不是全表遍历,也不是单纯依赖 expired_at 字段,而是只关注仍然具备业务意义的积分资产。
扫描条件通常类似于:
- 当前状态仍然是有效状态(如
status = 'ACTIVE') - 仍有剩余可用积分(
remain_amount > 0) - 已经超过过期时间(
expired_at <= NOW())
通过这种组合条件,定时任务的扫描范围被严格限定在"确实可能发生过期的积分明细"之内,既避免了无效扫描,也不会反复处理已经结算过的记录。
一旦发现某条积分明细满足过期条件,系统并不会只做字段更新,而是会按一次完整的账务流程来处理这次过期:
- 写入一条
EXPIRE类型的积分流水,用于审计和追溯; - 将对应积分明细的剩余积分清零,并更新状态为已过期;
- 同步扣减用户积分账户中的可用余额。
整个过程通常放在同一个事务中完成,确保流水、明细、账户余额三者始终一致。 也正因为有了这一步,系统中的"历史账务状态"才能长期保持干净、可追溯。
二、消费时校验:确保不会"用到脏积分"
但仅靠定时扫描,其实还不够。
因为定时任务是按批次、按时间片执行的,不可能保证在积分刚刚过期的那一秒,就已经完成结算。如果用户正好在这个时间窗口内发起了积分消费请求,就可能出现一个问题:
账务上还没来得及结算,但业务上积分已经过期了,能不能用?
因此,在积分消费链路中,我们会做一层实时过期校验,作为兜底保障。
在实际消费时,系统并不会直接根据账户余额扣减,而是基于积分明细进行消费分配(例如 FIFO)。在选取可用积分明细时,会同时校验:
- 明细是否仍然有效;
- 是否存在过期时间;
- 当前时间是否已经超过
expired_at。
如果发现某条明细在消费时已经过期,即使定时任务还没有处理到它,也会被直接排除在可消费范围之外,从而保证不会出现"过期积分被使用"的情况。
这种设计的核心思路是:
- 定时任务负责把账算清楚、状态整理干净;
- 消费链路负责保证业务行为的绝对正确性。
两者各司其职,相互兜底,使积分过期既具备一致性,又不会对系统性能或工程复杂度造成过高压力。
积分生命周期小结:从产生到消亡
整体来看,我们并不是把积分当成一个简单的"数值字段",而是把它当作一类有完整生命周期的资产来设计。
一次积分的生命周期,大致会经历四个阶段:
产生 → 可用 → 消费 / 过期 → 结算完成
在积分产生阶段,系统通过事件驱动的方式触发规则计算,将积分拆分为三层数据同时落地: 流水用于审计,明细用于资产管理,账户用于快速查询余额。
在可用阶段,积分以明细形式存在,具备明确的剩余数量和过期时间,既可以被消费,也可能继续等待结算。
在消费阶段,系统并不会简单地扣减账户余额,而是基于积分明细进行选择与扣减,并在消费链路中实时校验是否过期,确保业务行为永远正确。
在过期阶段,积分不会"悄悄消失",而是通过定时扫描被显式结算: 生成过期流水、更新明细状态、同步账户余额,形成一条完整、可追溯的账务记录。
也正是因为将扫描结算 与消费时校验拆成两条独立但互相兜底的链路,积分系统才能在以下几件事之间取得平衡:
- 不依赖高频定时任务,避免性能风险;
- 不依赖"刚好扫到",避免业务正确性问题;
- 不引入复杂调度机制,控制工程复杂度;
- 同时保证账务一致性与可审计性。
从设计角度看,这套积分生命周期并不是追求"技术上最炫"的方案,而是更关注一件事:
积分在任何时刻,都处于一个可解释、可追溯、可控制的状态。
写在最后:关于这套积分系统的一点总结
最后再说一下,我们这套积分系统的设计过程,我也并不是一开始就定了非常完整版方案,而是根据实际业务中遇到的问题,一步步去补齐能力、调整边界、完善细节的。也行当前设计的这套方案也是有缺陷 并不满足大部分业务需求,可能还要进一步完善哈。
我们最初的积分模型,可能只有一张流水表就够用; 再往后,有了活动、有了规则、有了倍率; 再后来,开始关心风险、审计、异常、回溯。
当积分真正变成一种可运营、可调控、可审计的业务资产时,原本那种在代码里加减积分的方式,就已经不够用了。
所以整套设计中,我们始终围绕几个核心问题展开:
- 积分是因为什么产生的?
- 积分是按什么规则计算的?
- 积分在什么情况下不该被发放?
- 积分如果出问题,能不能回溯清楚?
- 积分是不是随时都处在一个可解释的状态?
基于这些问题,我们最终把积分系统拆成了几个清晰的层次:
- 用事件限定系统"能感知哪些业务行为";
- 用规则描述积分的计算方式与边界条件;
- 用倍率承载活动期间的加成逻辑;
- 用流水 / 明细 / 账户分离审计、资产和结果;
- 用风控视图与审计链路兜住系统的安全底线。
这些设计并不一定是唯一正确答案,但它们有一个共同点: 每一层都有明确职责,每一个决策都能解释清楚为什么这样做。
关于积分系统设计,几个容易踩坑的点
如果要总结一些在实践中反复验证过的经验,大概有这几点:
- 不要把积分当成一个简单数值,它本质上是一种有生命周期的资产;
- 不要让运营规则直接依赖代码细节,中间一定要有事件和规则的隔离层;
- 不要把所有限制条件混在一起,触发、发放、倍率、过期要拆清楚;
- 不要忽视审计能力,没有审计的积分系统,迟早会出问题;
- 不要过早追求"全自动风控",可解释性永远比复杂度更重要。
很多系统不是一开始就设计错了,而是缺少边界,最后被复杂度慢慢拖垮。
最后附上本次文章 Demo 设计的后台目录结构
scss
积分服务中心(point-center)
├── 仪表盘
│ └── 积分发放概览 / 风险趋势 / Top 规则
│
├── 积分规则域
│ ├── 积分事件
│ ├── 积分规则
│ └── 积分倍率(活动加成)
│
├── 用户积分
│ ├── 用户积分列表
│ │ ├── 当前积分
│ │ ├── 即将到期积分(7 天)
│ │ └── VIP / 风险筛选
│ ├── 积分流水(Drawer)
│ └── 积分明细(Drawer)
│
└── 风险管控
├── 风险概览
├── 异常积分记录
│ └── 异常详情(串联流水 / 明细)
├── 高风险规则
│ └── 风险因子视图(派生)
└── 人工操作审计
└── 操作详情 / 风控回溯如果用一句话来概括我们这套系统的目标,那就是:
让积分这件事,从能跑变成可控、可查、可解释。
至于是否要一步到位把所有模块都做齐,答案反而很简单: 按业务复杂度逐步演进,比一开始追求完美更重要。
这也是我们在这套积分系统设计中,始终坚持的一个原则。