【生产级实战】Linux 集群时间同步详解(NTP + Cron,超详细)
- 一:概述
- 二:方案
- 三:部署
-
- 1)时间服务器(hadoop102)配置
- [2)客户端节点(hadoop103 / hadoop104)配置](#2)客户端节点(hadoop103 / hadoop104)配置)
- 3)验证时间同步效果
- 总结
一:概述
👍本文将以 CentOS 集群 为例,详细讲解 内网环境下的 NTP 集群时间同步方案,一步一步带你从原理到落地。
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。测试环境为了尽快看到效果,采用1分钟同步一次。
二:方案
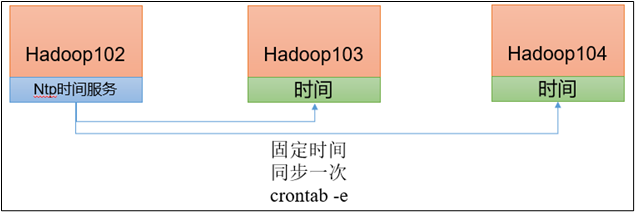
✅方案设计:
-
选 1 台服务器作为时间服务器
-
其他节点定时向该服务器同步时间
✅示例集群:
- hadoop102 → 时间服务器(NTP Server)
- hadoop103 → 客户端
- hadoop104 → 客户端
✅同步策略:
-
测试环境:每 1 分钟同步一次
-
生产环境:可调整为 5~10 分钟
三:部署
1)时间服务器(hadoop102)配置
-
查看 ntpd 服务状态
bash[lmc@hadoop102 ~]$ sudo systemctl status ntpd -
启动 ntpd 服务
bash[lmc@hadoop102 ~]$ sudo systemctl start ntpd -
设置 ntpd 开机自启
bash[lmc@hadoop102 ~]$ sudo systemctl enable ntpd -
验证是否已设置为开机启动
bash[lmc@hadoop102 ~]$ sudo systemctl is-enabled ntpd -
配置 NTP 服务文件
bash[lmc@hadoop102 ~]$ sudo vim /etc/ntp.confbash# 允许 192.168.2.0 网段的机器同步时间 restrict 192.168.2.0 mask 255.255.255.0 nomodify notrap # 当外部时间源不可用时,使用本地时间作为时间源 server 127.127.1.0 fudge 127.127.1.0 stratum 10 # 集群在内网环境,禁止使用公网时间服务器 #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst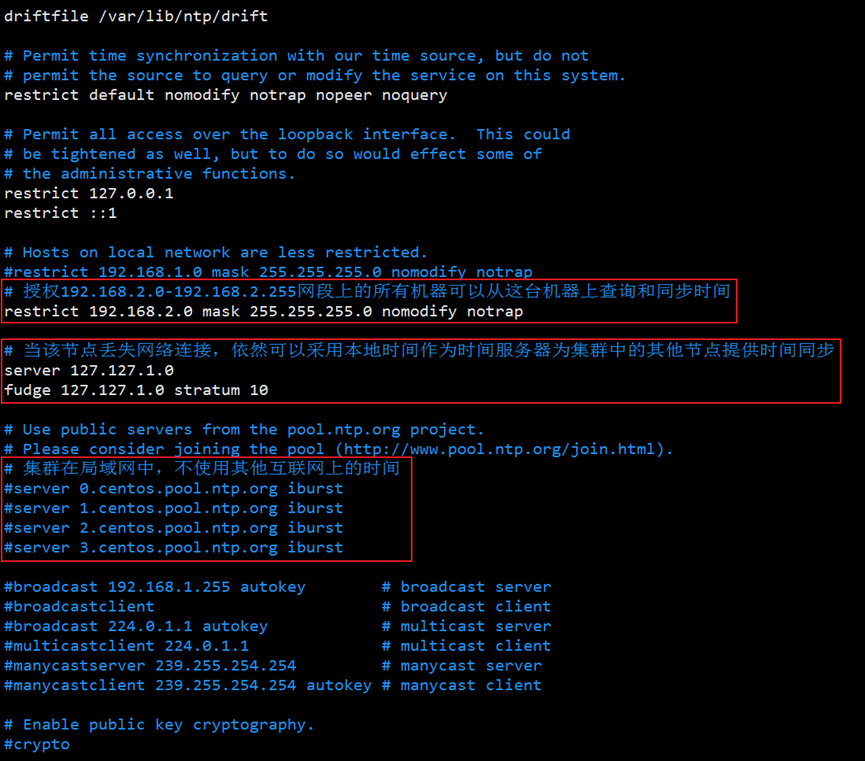
-
配置硬件时间同步
含义:系统时间同步的同时,同步硬件时钟,防止重启后时间回退。
bash[lmc@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpdbash# 添加这一行即可 SYNC_HWCLOCK=yes -
重启 ntpd 服务
含义:系统时间同步的同时,同步硬件时钟,防止重启后时间回退。
bash[lmc@hadoop102 ~]$ sudo systemctl restart ntpd
2)客户端节点(hadoop103 / hadoop104)配置
此处以
hadoop103举例,hadoop104同样配置即可
-
关闭客户端 ntpd 服务
bash[lmc@hadoop103 ~]$ sudo systemctl stop ntpd [lmc@hadoop103 ~]$ sudo systemctl disable ntpd -
配置定时任务同步时间
bash[lmc@hadoop103 ~]$ sudo crontab -ebash# 添加这一行即可 */1 * * * * /usr/sbin/ntpdate hadoop102 -
查看定时任务是否生效
bash[lmc@hadoop103 ~]$ sudo crontab -l
3)验证时间同步效果
-
手动修改某台客户端时间
bashsudo date -s "2022-08-08 10:08:05" -
等待 1 分钟后查看时间 如果时间恢复为与
hadoop102一致,说明同步成功 ✅bashdate
总结
在内网集群环境中,应选取一台服务器作为 NTP 时间服务器,其余节点通过定时任务同步时间,确保整个集群时间高度一致,为分布式系统稳定运行打下基础。
生产环境建议(经验总结):
- 时间服务器 只保留 1 台
- 客户端 只用 ntpdate + cron
- 不要多台互相同步
- Hadoop / Kafka / ZK 集群部署前 先同步时间