文章目录
- Python多线程编程
){kind=link}
Python多线程编程
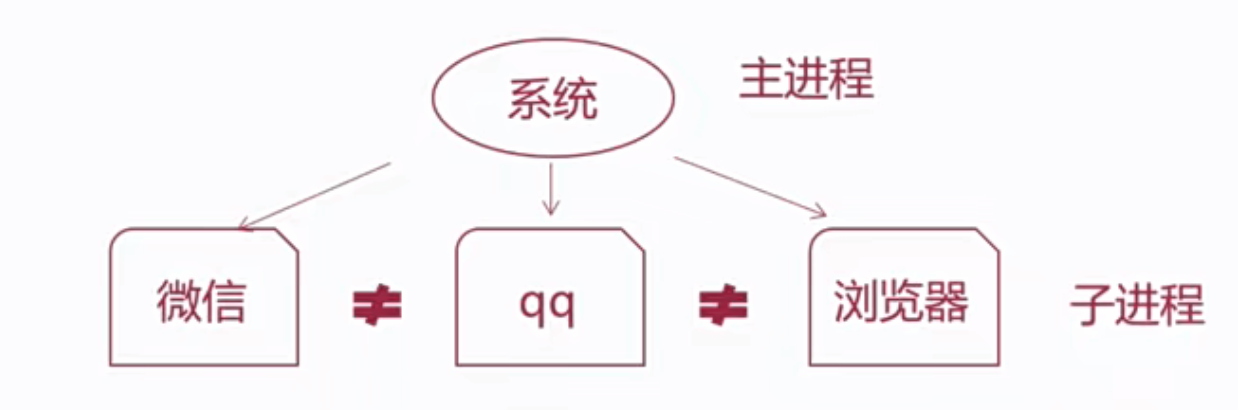
进程
- 进程就是应用的载体,执行的每个py脚本都是启动的一个进程
- 进程的启动需要CPU以及内存
多进程
进程的创建
进程的模块-- multiprocessing

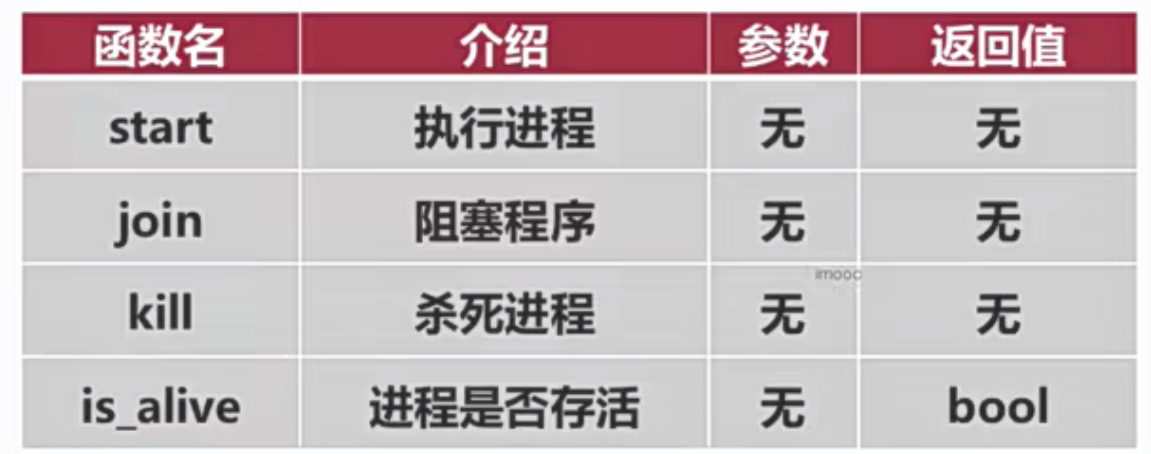
参数
python
"""
进程涉及到的参数如下:
target 关联的是 当前进程要执行的函数
name 设置当前进程的名字
args 以元组的形式,给 当前进程关联的 函数 传参
kwargs 以元组的形式,给 当前进程关联的 函数 传参
细节
1、args方式传参,实参的个数 和 数据类型,顺序 必须和 进程关联的函数的形参列表 一致
2、kwargs方式传参,实参的个数 和 数据类型 必须 和 进程关联的韩式形参列表 一致, 顺序无所谓
"""
#需求:使用多进程模拟小明一边写num行代码,一边听count首音乐
import time, multiprocessing
def coding(name, num):
for i in range(num):
print(f'{name}正在敲第{i}行代码')
time.sleep(0.2)
def music(name, count):
for i in range(count):
print(f'{name}正在听第{i}首歌')
time.sleep(0.2)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=coding, name='coding', args=('小明', 11))
p2 = multiprocessing.Process(target=music, name='music', kwargs={'count': 10, 'name': '小明'})
print(p1.name)
print(p2.name)
p1.start()
p2.start()获取进程编号
python
"""
如何获取进程编号
"""
import time, multiprocessing, os
def coding(name, num):
for i in range(num):
print(f'{name}正在敲第{i}行代码')
time.sleep(0.2)
print(f'{multiprocessing.current_process().name} : {multiprocessing.current_process().pid}, {os.getpid()}, 父级id:{os.getppid()}')
def music(name, count):
for i in range(count):
print(f'{name}正在听第{i}首歌')
time.sleep(0.2)
print(f'{multiprocessing.current_process().name} : {multiprocessing.current_process().pid}, {os.getpid()}, 父级id:{os.getppid()}')
if __name__ == '__main__':
p1 = multiprocessing.Process(target=coding, name='coding', args=('小明', 11))
p2 = multiprocessing.Process(target=music, name='music', kwargs={'count': 10, 'name': '小明'})
print(p1.name)
print(p2.name)
p1.start()
p2.start()
print(f'{multiprocessing.current_process().name} : {multiprocessing.current_process().pid}')
# print(f'{p1.name} : {p1.pid}')
# print(f'{p2.name} : {p2.pid}')数据隔离
python
"""
案例: 演示进程之间 数据是相互隔离的.
大白话解释:
1. 微信 和 QQ都是进程, 它们之间的数据都是 相互隔离的. 即: 微信不能直接访问QQ的数据, QQ也不能直接访问微信的数据.
2. 下述代码你会发现, 多个子进程相当于把 父进程的资源全部拷贝了一份(注意: main外资源), 即: 子进程相当于父进程的副本.
需求: 定义全局变量 my_list = [], 搞两个进程, 分别实现往里边添加数据, 从里边读取数据, 并观察结果.
"""
# 导包
import multiprocessing, time
# 1. 定义全局变量.
my_list = []
# 2. 定义函数 write_data(), 往: 列表中 添加数据.
def write_data():
# 为了让效果更明显, 我们添加多个值.
for i in range(1, 6):
my_list.append(i) # 具体添加元素到列表的动作.
print(f'add: {i}') # 打印添加细节(过程)
print(f'write_data函数: {my_list}') # 添加完毕后, 打印列表结果
# 3. 定义函数 read_data(), 从: 列表中 读取数据.
def read_data():
# 休眠一会儿, 确保 write_data()函数执行完毕.
time.sleep(3)
print(f'read_data函数: {my_list}') # 打印列表结果
# 4. 在main中测试
if __name__ == '__main__':
# 4.1 创建两个进程对象.
p1 = multiprocessing.Process(target=write_data) # 进程1, 例如: QQ
p2 = multiprocessing.Process(target=read_data) # 进程2, 例如: 微信
# 4.2 开启进程.
p1.start()
p2.start()
# print('看看我打印了几遍? ') # main函数内的内容, 只执行一次.
print('看看我打印了几遍? ') # main外资源, 自身要执行一次, p1进程拷贝1遍, p2进程拷贝1遍 = 3次主进程关闭-子进程同步关闭
python
"""
案例:
演示 默认情况下, 主进程会等待子进程执行结束在结束.
需求:
创建1个子进程, 子进程执行完需要3秒钟, 让主进程1秒就结束, 观察: 整个程序是立即结束, 还是会等待子进程结束再结束.
结论:
1. 默认情况下, 主进程会等待所有子进程执行结束再结束.
2. 问: 如何实现, 当主进程结束的时候, 子进程也立即结束呢?
方式1: 设置子进程为守护进程. 类似于: 公主 和 守护骑士.
方式2: 手动关闭子进程.
细节:
1. 当非守护进程结束的时候, 它的所有守护进程都会立即终止, 且释放资源.
2. 如果是 terminate()方式, 子进程主动结束自己, 则会变成僵尸进程, 不会立即释放资源.
"""
# 导包
import multiprocessing, time
# 1. 定义函数work(), 要被: 子进程关联.
def work():
for i in range(10):
print(f'工作中... {i}')
time.sleep(0.3) # 总计休眠时间: 0.3 * 10 = 3秒
# 2. 在main函数中测试.
if __name__ == '__main__':
# 3. 创建子进程.
p1 = multiprocessing.Process(target=work)
# 核心细节: 设置p1为守护线程, 因为p1的父进程是main, 所以p1是main的守护进程.
p1.daemon = True
# 4. 开启子进程.
p1.start()
# 5. 让主进程(main进程)休眠1秒.
time.sleep(2)
# 方式2: 在主进程执行结束前, 子进程主动自己关闭自己.
#p1.terminate() # 不推荐用, 会变成僵尸进程, 不会主动释放资源, 过段时间会交由(init进程, 充当父进程),来释放资源.
# 6. 主进程结束, 打印提示语句.
print('主进程执行结束了!')主进程会等待子进程执行结束再结束
python
"""
案例:
演示 默认情况下, 主进程会等待子进程执行结束再结束.
需求:
创建1个子进程, 子进程执行完需要3秒钟, 让主进程1秒就结束, 观察: 整个程序是立即结束, 还是会等待子进程结束再结束.
结论:
1. 默认情况下, 主进程会等待所有子进程执行结束再结束.
2. 问: 如何实现, 当主进程结束的时候, 子进程也立即结束呢?
方式1: 设置子进程为守护进程. 类似于: 公主 和 守护骑士.
方式2: 手动关闭子进程.
"""
# 导包
import multiprocessing, time
# 1. 定义函数work(), 要被: 子进程关联.
def work():
for i in range(10):
print(f'工作中... {i}')
time.sleep(0.3) # 总计休眠时间: 0.3 * 10 = 3秒
# 2. 在main函数中测试.
if __name__ == '__main__':
# 3. 创建子进程.
p1 = multiprocessing.Process(target=work)
# 4. 开启子进程.
p1.start()
# 5. 让主进程(main进程)休眠1秒.
time.sleep(1)
# 6. 主进程结束, 打印提示语句.
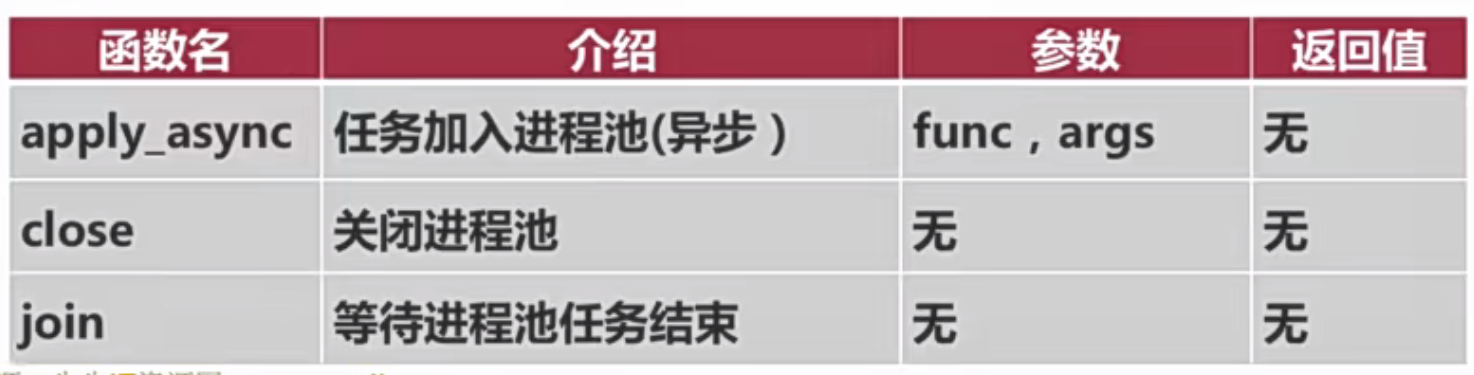
print('主进程执行完成了!')进程池
优点:
- 避免了进程的创建与关闭的消耗
进程池的创建--multiprocessing

python
# coding:utf-8
import multiprocessing as mp
import os
import time
def work(count):
print(f'当前数量:{count},当前线程:{os.getpid()}')
time.sleep(5)
if __name__ == '__main__':
pool = mp.Pool(4)
for i in range(10):
pool.apply_async(work, args=(i, ))
pool.close() #关闭进程池
pool.join() #等待进程池中任务执行完成
# 执行结果
当前数量:0,当前线程:29208
当前数量:1,当前线程:26676
当前数量:2,当前线程:26988
当前数量:3,当前线程:14656
当前数量:4,当前线程:29208
当前数量:5,当前线程:14656
当前数量:6,当前线程:26988
当前数量:7,当前线程:26676
当前数量:8,当前线程:29208
当前数量:9,当前线程:26988获取进程的返回值
python
# coding:utf-8
import multiprocessing as mp
import os
import time
def work(count):
# print(f'当前数量:{count},当前线程:{os.getpid()}')
time.sleep(5)
return '当前数量:%s,当前线程:%s' % (count, os.getpid())
if __name__ == '__main__':
pool = mp.Pool(4)
results = []
for i in range(10):
result = pool.apply_async(work, args=(i, ))
results.append(result)
for res in results:
print(res.get())
#结果
当前数量:0,当前线程:28052
当前数量:1,当前线程:28224
当前数量:2,当前线程:29596
当前数量:3,当前线程:24652
当前数量:4,当前线程:28052
当前数量:5,当前线程:28224
当前数量:6,当前线程:29596
当前数量:7,当前线程:24652
当前数量:8,当前线程:28052
当前数量:9,当前线程:29596进程锁
进程锁的加锁与解锁
python
# coding:utf-8
import multiprocessing as mp
import os
import time
def work(count, lock):
lock.acquire()
print(f'当前数量:{count},当前线程:{os.getpid()}')
time.sleep(5)
lock.release()
return '当前数量:%s,当前线程:%s' % (count, os.getpid())
if __name__ == '__main__':
pool = mp.Pool(4)
manager = mp.Manager()
lock = manager.Lock()
results = []
for i in range(10):
pool.apply_async(work, args=(i, lock))
pool.close()
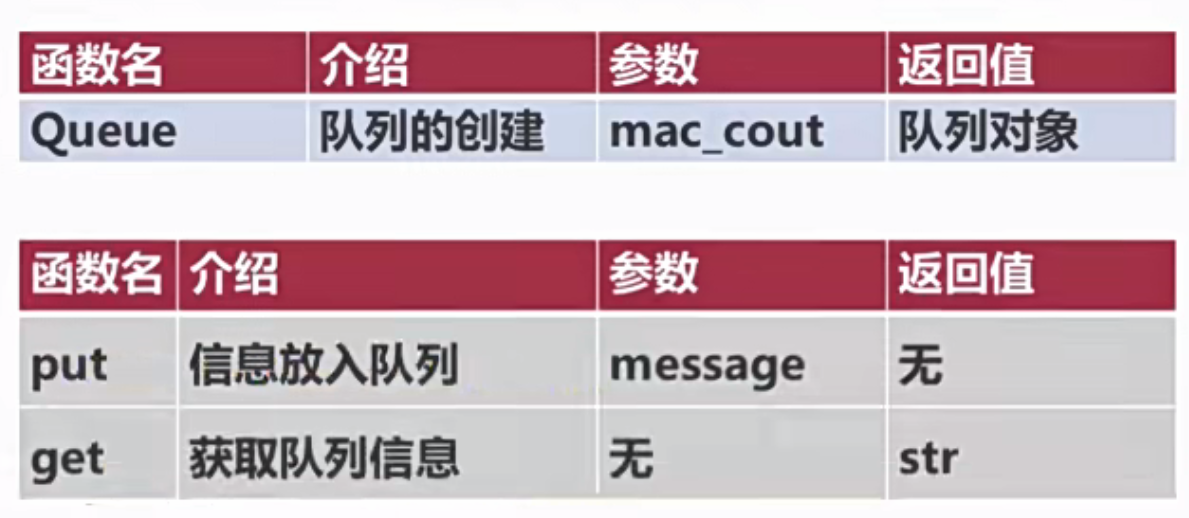
pool.join()进程的通信
队列的创建--multiprocessing
python
# coding:utf-8
import json
import multiprocessing
import time
class Work(object):
def __init__(self, q):
self.q = q
def send(self, message):
if not isinstance(message, str):
message = json.dumps(message)
self.q.put(message)
def recv(self):
while True:
result = self.q.get()
try:
res = json.loads(result)
except :
res = result
print('recv is %s' % res)
def seng_all(self):
for i in range(20):
self.q.put(i)
time.sleep(1)
if __name__ == '__main__':
q = multiprocessing.Queue()
work = Work(q)
send = multiprocessing.Process(target=work.send, args=({'name':'zhangsan'},))
recv = multiprocessing.Process(target=work.recv)
send_all = multiprocessing.Process(target=work.seng_all)
send.start()
recv.start()
send_all.start()
# send.join()
#这里用于阻塞防止还没有发送完成就结束进程,只阻塞最长时间的子进程即可
send_all.join()
#终结进程
recv.terminate()线程
一个进程中可以有多个线程。
线程的创建--threading

常用方法
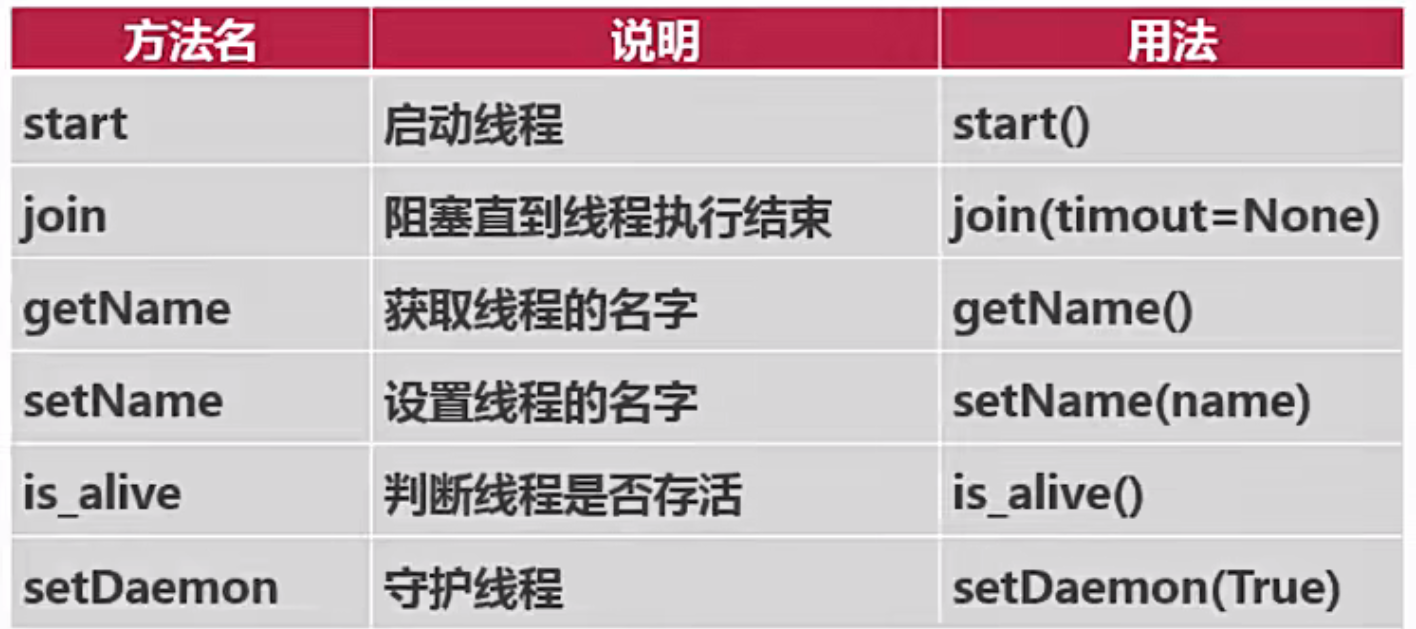
参数
python
"""
进程涉及到的参数如下:
target 关联的是 当前进程要执行的函数
name 设置当前进程的名字
args 以元组的形式,给 当前进程关联的 函数 传参
kwargs 以元组的形式,给 当前进程关联的 函数 传参
细节
1、args方式传参,实参的个数 和 数据类型,顺序 必须和 进程关联的函数的形参列表 一致
2、kwargs方式传参,实参的个数 和 数据类型 必须 和 进程关联的韩式形参列表 一致, 顺序无所谓
"""
#需求:使用多进程模拟小明一边写num行代码,一边听count首音乐
import time, threading
def coding(name, num):
for i in range(num):
print(f'{name}正在敲第{i}行代码')
time.sleep(0.2)
def music(name, count):
for i in range(count):
print(f'{name}正在听第{i}首歌')
time.sleep(0.2)
if __name__ == '__main__':
t1 = threading.Thread(target=coding, args=('小明', 11))
t2 = threading.Thread(target=music, kwargs={'count': 10, 'name': '小明'})
print(t1.name)
print(t2.name)
t1.start()
t2.start()进程与线程的关系
- 进程提供线程执行程序的前置要求,线程在重组的资源配备下,去执行程序
多线程
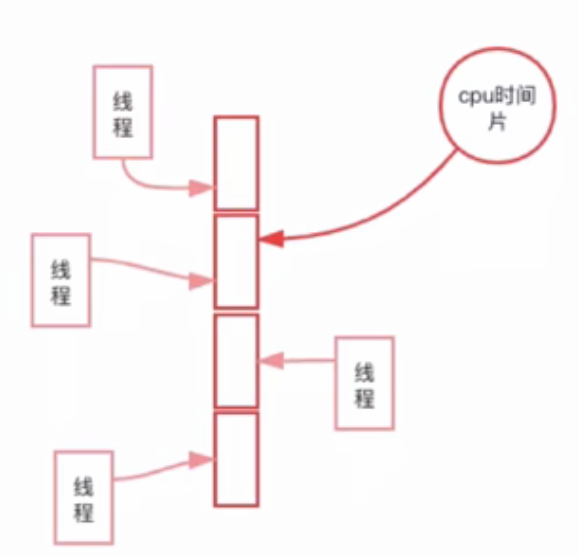
守护线程
python
"""
案例:
演示 默认情况下, 主线程会等待子线程执行结束在结束.
需求:
创建1个子线程, 子线程执行完需要3秒钟, 让主线程1秒就结束, 观察: 整个程序是立即结束, 还是会等待子线程结束再结束.
结论:
1. 默认情况下, 主线程会等待所有子线程执行结束再结束.
2. 问: 如何实现, 当主线程结束的时候, 子线程也立即结束呢?
设置子线程为守护线程. 类似于: 公主 和 守护骑士.
结论:
当非守护线程结束的时候, 和它关联的守护线程, 也会立即结束, 释放资源.
"""
# 导包
import threading, time
# 1. 定义函数work(), 要被: 子线程关联.
def work():
for i in range(10):
print(f'工作中... {i}')
time.sleep(0.3) # 总计休眠时间: 0.3 * 10 = 3秒
# 2. 在main函数中测试.
if __name__ == '__main__':
# 3. 创建子线程.
# 守护线程, 格式1: 创建线程对象的时候, 直接指定.
# t1 = threading.Thread(target=work, daemon=True)
t1 = threading.Thread(target=work)
# 守护线程, 格式2: 创建线程对象后, 通过 daemon属性设置.
# t1.daemon = True
# 守护线程, 格式3: 创建线程对象后, 通过 setDaemon()函数设置.
t1.setDaemon(True) # 类似于以前我们学的: get_name(), set_name()
# 4. 开启子线程.
t1.start()
# 5. 让主线程(main线程)休眠1秒.
time.sleep(1)
# 6. 主线程结束, 打印提示语句.
print('主线程执行结束了!')执行顺序
python
"""
案例:
演示多线程代码 的执行顺序.
结论:
1. 多线程的执行具有 随机性, 因为: 线程是由CPU调度的.
2. 调度资源常用的两种方式:
抢占式调度: 谁抢到资源, 谁执行.
Python, Java用的都是这种思路.
均分时间片: 每个任务获取CPU的时间都是固定的.
"""
# 导包
import threading
import time
# 1. 定义函数get_info(), 用来打印: 线程信息, 看看当前是哪个线程在执行.
def get_info():
# 休眠一会儿, 让效果更明显.
time.sleep(0.3)
# 1.1 获取当前的线程对象.
ct = threading.current_thread()
# 1.2 打印当前线程对象即可.
print(f'当前的线程对象是: {ct.name}')
# 2. 在main中测试.
if __name__ == '__main__':
# 3. 为了让效果更明显, 创建多个线程.
# t1 = threading.Thread(target=get_info)
# t2 = threading.Thread(target=get_info)
#
# t1.start()
# t2.start()
for i in range(10):
t1 = threading.Thread(target=get_info)
t1.start()共享资源
python
"""
案例: 演示 同一进程的多个线程, 可以共享 该进程的资源.
结论:
1. 进程之间, 数据相互隔离. 进程 = 软件.
2. 线程之间, 数据共享.
"""
# 导包
import threading, time
# 1. 定义全局变量.
my_list = []
# 2. 定义函数write_data(), 实现: 往列表中添加数据.
def write_data():
# 为了效果更明显, 我们添加多个元素.
for i in range(1, 6):
# time.sleep(0.1)
# 往列表中添加元素.
my_list.append(i)
# 打印添加的细节
print(f'add: {i}')
# 添加之后, 打印结果.
print(f'write_data函数: {my_list}')
# 3. 定义函数read_data(), 实现: 从列表中读取数据.
def read_data():
time.sleep(2) # 为了效果更好看, 加入休眠线程.
print(f'read_data函数: {my_list}')
# 4. main函数中进行测试.
if __name__ == '__main__':
# 4.1 创建两个线程对象, 分别关联: write_data(), read_data()函数.
t1 = threading.Thread(target=write_data)
t2 = threading.Thread(target=read_data)
# 4.2 启动线程.
t1.start()
t2.start()操作共享资源-锁
python
"""
案例: 线程可以共享全局变量, 同时操作, 可能会出现: 安全问题.
遇到的问题:
两个线程同时操作共享变量, 进行累加操作, 出现: 累计次数"不够"的情况, 我们要的效果是: get_sum1: 100W, get_sum2:200W, 但是结果不是.
产生原因:
正常情况:
假设g_num = 0
第1次循环: t1线程抢到资源, 对其累加1, 操作后 g_num = 1, t1线程本次操作完毕.
第2次循环: 假设t2线程抢到了资源, 此时 g_num = 1, 操作之后(累加1), g_num = 2, t2线程本次操作完毕.
这个是正常情况.
非正常情况:
1. 假设 g_num = 0
2. 假设 t1 线程抢到了资源, 在还没有来得及对 g_num(全局变量)做 累加操作的时候, 被t2线程抢走了资源.
3. t2线程也会去读取 g_num(全局变量)的值, 此时 g_num = 0
4. 之后t1 和 t2线程分别开始了 累加操作:
t1线程, 累加之后, g_num = 0 -> g_num = 1
t2线程, 累加之后, g_num = 0 -> g_num = 1
5. 上述一共累加了 2次, 但是 g_num的值最终只 累加了 1.
"""
import threading
# 需求: 定义两个函数, 分别对全局变量累加100W次, 并打印观察程序的最终运行结果.
# 1. 定义全局变量.
g_num = 0
mutex = threading.Lock()
# 2. 定义函数 get_sum1(), 实现对全局变量累加 100W次
def get_sum1():
#加锁
mutex.acquire()
for i in range(1000000):
global g_num
g_num += 1 # 全局变量 + 1
# 程序计算完毕后, 打印结果.
#释放锁
mutex.release()
print(f'get_sum1函数计算结果: {g_num}') # 100W
# 3. 定义函数 get_sum2(), 实现对全局变量累加 100W次
def get_sum2():
mutex.acquire()
for i in range(1000000):
global g_num
g_num += 1 # 全局变量 + 1
# 程序计算完毕后, 打印结果.
mutex.release()
print(f'get_sum2函数计算结果: {g_num}') # 200W
# 4. 测试
if __name__ == '__main__':
# 4.1 创建两个线程对象, 分别关联: 两个函数.
t1 = threading.Thread(target=get_sum1)
t2 = threading.Thread(target=get_sum2)
# 4.2 启动线程.
t1.start()
t2.start()操作共享资源-非法值
python
"""
案例: 线程可以共享全局变量, 同时操作, 可能会出现: 安全问题.
遇到的问题:
两个线程同时操作共享变量, 进行累加操作, 出现: 累计次数"不够"的情况, 我们要的效果是: get_sum1: 100W, get_sum2:200W, 但是结果不是.
产生原因:
正常情况:
假设g_num = 0
第1次循环: t1线程抢到资源, 对其累加1, 操作后 g_num = 1, t1线程本次操作完毕.
第2次循环: 假设t2线程抢到了资源, 此时 g_num = 1, 操作之后(累加1), g_num = 2, t2线程本次操作完毕.
这个是正常情况.
非正常情况:
1. 假设 g_num = 0
2. 假设 t1 线程抢到了资源, 在还没有来得及对 g_num(全局变量)做 累加操作的时候, 被t2线程抢走了资源.
3. t2线程也会去读取 g_num(全局变量)的值, 此时 g_num = 0
4. 之后t1 和 t2线程分别开始了 累加操作:
t1线程, 累加之后, g_num = 0 -> g_num = 1
t2线程, 累加之后, g_num = 0 -> g_num = 1
5. 上述一共累加了 2次, 但是 g_num的值最终只 累加了 1.
"""
import threading
# 需求: 定义两个函数, 分别对全局变量累加100W次, 并打印观察程序的最终运行结果.
# 1. 定义全局变量.
g_num = 0
# 2. 定义函数 get_sum1(), 实现对全局变量累加 100W次
def get_sum1():
for i in range(1000000):
global g_num
g_num += 1 # 全局变量 + 1
# 程序计算完毕后, 打印结果.
print(f'get_sum1函数计算结果: {g_num}') # 100W
# 3. 定义函数 get_sum2(), 实现对全局变量累加 100W次
def get_sum2():
for i in range(1000000):
global g_num
g_num += 1 # 全局变量 + 1
# 程序计算完毕后, 打印结果.
print(f'get_sum2函数计算结果: {g_num}') # 200W
# 4. 测试
if __name__ == '__main__':
# 4.1 创建两个线程对象, 分别关联: 两个函数.
t1 = threading.Thread(target=get_sum1)
t2 = threading.Thread(target=get_sum2)
# 4.2 启动线程.
t1.start()
t2.start()主线程会等待子线程执行结束在结束
python
"""
案例:
演示 默认情况下, 主线程会等待子线程执行结束在结束.
需求:
创建1个子线程, 子线程执行完需要3秒钟, 让主线程1秒就结束, 观察: 整个程序是立即结束, 还是会等待子线程结束再结束.
结论:
1. 默认情况下, 主线程会等待所有子线程执行结束再结束.
2. 问: 如何实现, 当主线程结束的时候, 子线程也立即结束呢?
设置子线程为守护线程. 类似于: 公主 和 守护骑士.
"""
# 导包
import threading, time
# 1. 定义函数work(), 要被: 子线程关联.
def work():
for i in range(10):
print(f'工作中... {i}')
time.sleep(0.3) # 总计休眠时间: 0.3 * 10 = 3秒
# 2. 在main函数中测试.
if __name__ == '__main__':
# 3. 创建子线程.
t1 = threading.Thread(target=work)
# 4. 开启子线程.
t1.start()
# 5. 让主线程(main线程)休眠1秒.
time.sleep(1)
# 6. 主线程结束, 打印提示语句.
print('主线程执行结束了!')线程池
线程池的创建--concurrent


python
# coding:utf-8
import os
import time
from concurrent.futures import ThreadPoolExecutor
import threading
#使用线程锁 只需要全局定义一个线程锁即可
# lock = threading.Lock()
def work(i):
# lock.acquire()
print(i, os.getpid())
time.sleep(1)
# lock.release()
return 'result %s' % i
if __name__ == '__main__':
t = ThreadPoolExecutor(2)
results = []
for i in range(10):
t_result = t.submit(work, (i, ))
results.append(t_result)
for res in results:
print(res.result())说明:time.sleep 是cpu级别的阻塞,在异步中不可使用,需要使用异步的sleep
异步
异步执行,不会影响主程序的执行,提高执行效率
异步与多线程多进程
- 轻量级的线程 协程
- 可以获取异步函数的返回值
- 主进程需要异步才行
async与await关键字
- async 定义异步
- await 执行异步
asyncio调用async函数
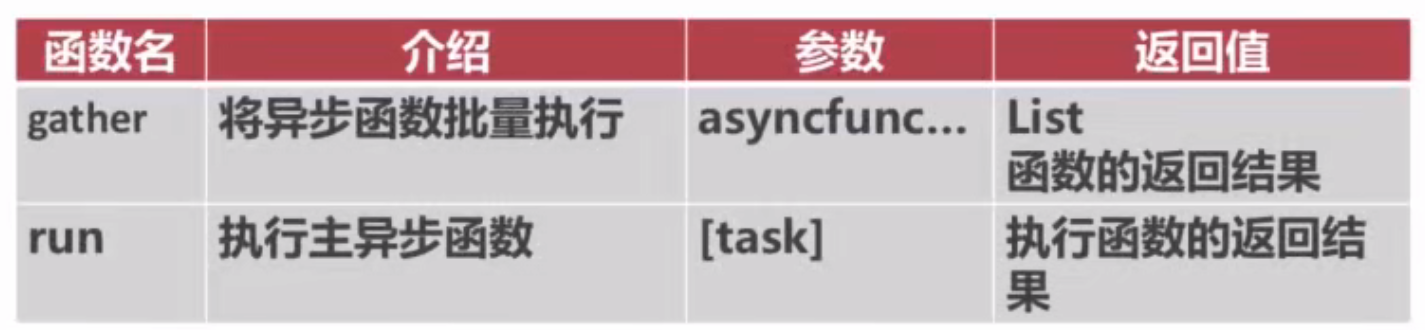

python
# coding:utf=8
import asyncio
import random
import time
async def a():
for i in range(10):
print(i, 'a')
await asyncio.sleep(random.random() * 2)
return 'a func'
async def b():
for i in range(10):
print(i, 'b')
await asyncio.sleep(random.random() * 2)
return 'b func'
async def main():
result = await asyncio.gather(a(), b())
print(result)
if __name__ == '__main__':
start = time.time()
asyncio.run(main())
print(time.time() - start)gevent
比较早的异步依赖包,
- pip install gevent
- Microsoft Visual C++
- pip install wheel
gevent 常用方法
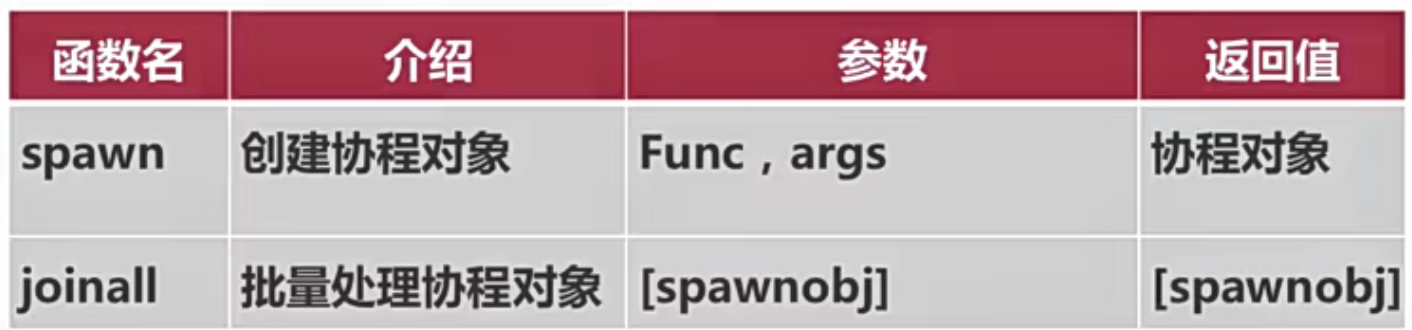
python
# coding:utf-8
import os
import random
import gevent
def gevent_a():
for i in range(10):
print(i, 'a gevent', os.getpid())
gevent.sleep(random.random() * 2)
return 'gevent a result'
def gevent_b():
for i in range(10):
print(i, 'b gevent', os.getpid())
gevent.sleep(random.random() * 2)
return 'gevent b result'
if __name__ == '__main__':
g_a = gevent.spawn(gevent_a)
g_b = gevent.spawn(gevent_b)
gevent_list = [g_a, g_b]
result = gevent.joinall(gevent_list)
print(result[0].value, ' | ',result[1].value)