整合自 Hugging Face 官方文档:Quanto 介绍博客![]() https://github.com/huggingface/blog/blob/main/quanto-introduction.md
https://github.com/huggingface/blog/blob/main/quanto-introduction.md
Quanto 官方 README![]() https://github.com/huggingface/optimum-quanto/blob/main/README.md
https://github.com/huggingface/optimum-quanto/blob/main/README.md
Transformers 集成文档![]() https://github.com/huggingface/transformers/blob/main/docs/source/en/quantization/quanto.md
https://github.com/huggingface/transformers/blob/main/docs/source/en/quantization/quanto.md
Optimum 量化概念指南![]() https://github.com/huggingface/optimum/blob/clap/docs/source/concept_guides/quantization.mdx
https://github.com/huggingface/optimum/blob/clap/docs/source/concept_guides/quantization.mdx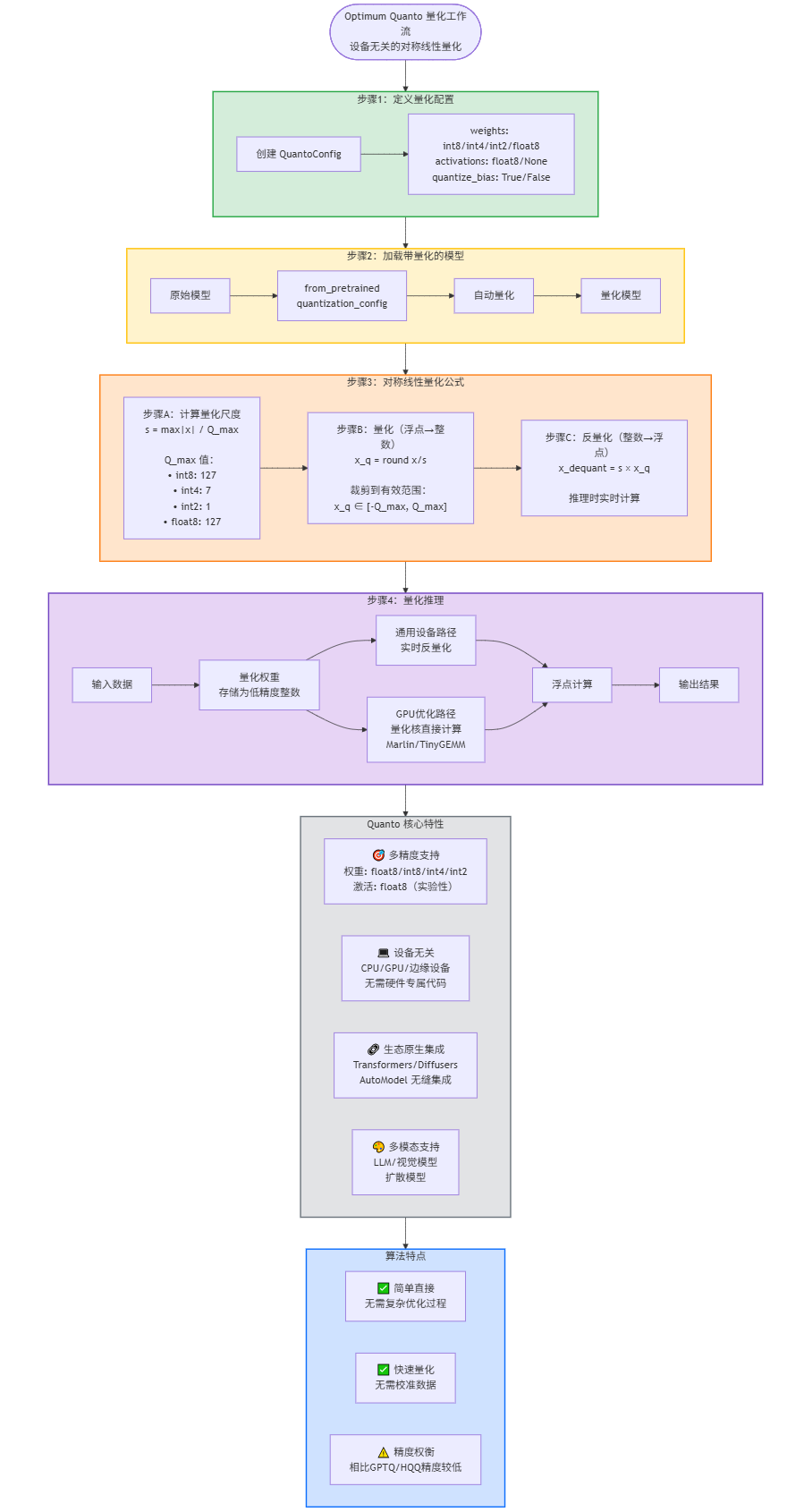
1. 什么是 Optimum Quanto?
Optimum Quanto 是 Hugging Face 推出的量化库,专注于设备无关的线性量化,支持对模型权重(及实验性激活)进行低精度压缩,适配多模态模型(大语言模型、视觉模型、扩散模型)。它原生集成于 Hugging Face 生态(Transformers/Diffusers),支持多种低精度数据类型(float8、int8、int4、int2)。
2. 量化工作流
步骤 1:定义量化配置
创建QuantoConfig指定量化参数(目标精度、量化范围等):
python
from transformers import QuantoConfig
quant_config = QuantoConfig(weights="int8") # 目标权重精度(可选int8/int4/int2/float8)核心配置项(来自 Transformers 文档):
weights:模型权重的目标数据类型(必填)activations:激活的目标数据类型(实验性支持)quantize_bias:是否量化偏置张量(默认:False)
步骤 2:加载带量化的模型
在模型加载阶段通过from_pretrained()应用量化(生态无缝集成):
python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.1-8B",
torch_dtype="auto", # 自动匹配模型原始数据类型
device_map="auto", # 自动将模型分配到可用设备
quantization_config=quant_config # 关联Quanto量化配置
)Quanto 会在加载过程中自动完成权重量化,无需手动处理权重。
步骤 3:量化推理
模型以量化权重运行推理:
- 计算过程中:量化权重会按需实时反量化(适用于通用设备),或通过优化的量化核(如 GPU 端的 Marlin/TinyGEMM)直接计算。
- 输出接口:与未量化模型完全一致,无需修改推理代码。
3. 核心数学公式
Quanto 的基础是对称线性量化(轻量、设备无关),同时整合 HQQ(半二次量化)以降低低比特(int4/int2)量化的误差。
3.1 对称线性量化(Quanto 基础)
针对浮点张量 x(如模型权重):
1. 计算量化尺度(s)
尺度用于将浮点值映射到目标量化数据类型的范围:\(s = \frac{\text{max}(|x|)}{\text{目标数据类型的最大绝对值}}\)其中:
- \(\text{max}(|x|)\):原始浮点张量的最大绝对值
- 目标数据类型的最大绝对值:如 int8 为 127、int4 为 7、int2 为 1、float8_e4m3fn 为 127
2. 量化步骤
将浮点值转换为量化整数:\(x_q = \text{取整}\left( \frac{x}{s} \right)\)将 \(x_q\) 裁剪到目标数据类型的有效范围(如 int8 裁剪至\(-127, 127\)),避免溢出。
3. 反量化步骤(实时计算)
恢复近似浮点值以进行计算:\(x_{\text{反量化}} = s \cdot x_q\)
3.2 整合 HQQ 优化(低比特量化)
针对 int4/int2 等高压缩场景,Quanto 用 HQQ 最小化重建误差,增加二次正则项:\(\arg\min_{x_q} \sum_i \left( x_i - s \cdot x_{q,i} \right)^2 + \lambda \cdot R(x_q)\)其中:
- \(R(x_q)\):正则项(强化量化约束)
- \(\lambda\):正则系数(平衡重建精度与量化有效性)
4. 关键特性
- 多精度支持:权重支持 float8/int8/int4/int2;激活实验性支持 float8
- 设备无关性:适配 CPU、GPU(NVIDIA/AMD)及边缘设备,无需硬件专属代码
- 生态原生 :与
AutoModel/from_pretrained无缝集成,无需自定义模型包装器 - 模态灵活性:支持大语言模型、视觉模型(如 ViT)、扩散模型(如 Stable Diffusion)