目录
[计算机内部 vs. 网络通信](#计算机内部 vs. 网络通信)
[3、TCP 如何实现可靠性?](#3、TCP 如何实现可靠性?)
[4、为什么还需要 UDP?------协议选择的工程权衡](#4、为什么还需要 UDP?——协议选择的工程权衡)
[1. TCP 的代价](#1. TCP 的代价)
[2. UDP 的优势](#2. UDP 的优势)
[3. 典型应用场景对比](#3. 典型应用场景对比)
[4. 重要观点](#4. 重要观点)
[二、TCP 协议格式:报头结构、字段含义与数据解析机制](#二、TCP 协议格式:报头结构、字段含义与数据解析机制)
[2、TCP 报头结构总览](#2、TCP 报头结构总览)
[1. 源端口号(Source Port) & 目的端口号(Destination Port)](#1. 源端口号(Source Port) & 目的端口号(Destination Port))
[2. 序列号(Sequence Number, 32 位)](#2. 序列号(Sequence Number, 32 位))
[3. 确认号(Acknowledgment Number, 32 位)](#3. 确认号(Acknowledgment Number, 32 位))
[4. 首部长度(Data Offset / Header Length, 4 位)](#4. 首部长度(Data Offset / Header Length, 4 位))
[5. 保留字段(Reserved, 6 位)](#5. 保留字段(Reserved, 6 位))
[6. 标志位(Control Flags, 6 位)](#6. 标志位(Control Flags, 6 位))
[7. 窗口大小(Window Size, 16 位)](#7. 窗口大小(Window Size, 16 位))
[8. 校验和(Checksum, 16 位)](#8. 校验和(Checksum, 16 位))
[9. 紧急指针(Urgent Pointer, 16 位)](#9. 紧急指针(Urgent Pointer, 16 位))
[10. 选项字段(Options, 0~40 字节)](#10. 选项字段(Options, 0~40 字节))
[4、TCP 报头的封装与解析机制](#4、TCP 报头的封装与解析机制)
[1. 内核中的实现方式](#1. 内核中的实现方式)
[2. 如何分离报头与有效载荷?](#2. 如何分离报头与有效载荷?)
[3. 如何交付给上层应用?](#3. 如何交付给上层应用?)
[三、TCP 序号与确认序号机制:可靠传输的核心逻辑](#三、TCP 序号与确认序号机制:可靠传输的核心逻辑)
[2、32 位序号(Sequence Number):字节级编号系统](#2、32 位序号(Sequence Number):字节级编号系统)
[1. 设计目标](#1. 设计目标)
[2. 工作原理](#2. 工作原理)
[3. 接收端如何处理?](#3. 接收端如何处理?)
[3、32 位确认序号(Acknowledgment Number):累积确认机制](#3、32 位确认序号(Acknowledgment Number):累积确认机制)
[1. 核心含义](#1. 核心含义)
[2. 丢包场景下的行为](#2. 丢包场景下的行为)
[6、补充:序号回绕与 PAWS 机制](#6、补充:序号回绕与 PAWS 机制)
[四、TCP 缓冲区与窗口机制详解:流量控制(Flow Control)的核心实现](#四、TCP 缓冲区与窗口机制详解:流量控制(Flow Control)的核心实现)
[1、引言:TCP 的"缓冲"哲学](#1、引言:TCP 的“缓冲”哲学)
[2、TCP 缓冲区的本质与作用(位于操作系统内核)](#2、TCP 缓冲区的本质与作用(位于操作系统内核))
[1. 发送缓冲区(Send Buffer)](#1. 发送缓冲区(Send Buffer))
[2. 接收缓冲区(Receive Buffer)](#2. 接收缓冲区(Receive Buffer))
[1. 发送缓冲区:应用是生产者,网络是消费者](#1. 发送缓冲区:应用是生产者,网络是消费者)
[2. 接收缓冲区:网络是生产者,应用是消费者](#2. 接收缓冲区:网络是生产者,应用是消费者)
[5、窗口大小(Window Size):流量控制的信号灯](#5、窗口大小(Window Size):流量控制的信号灯)
[1. 问题背景:为何需要流量控制?](#1. 问题背景:为何需要流量控制?)
[2. 窗口大小字段的定义](#2. 窗口大小字段的定义)
[3. 工作机制:动态调节发送速率](#3. 工作机制:动态调节发送速率)
[4. 窗口为零的特殊情况:零窗口(Zero Window)](#4. 窗口为零的特殊情况:零窗口(Zero Window))
[五、TCP 六大标志位](#五、TCP 六大标志位)
[2、TCP 六大标志位详解](#2、TCP 六大标志位详解)
[1. 建立连接:SYN (Synchronize)](#1. 建立连接:SYN (Synchronize))
[2. 确认应答:ACK (Acknowledgment)](#2. 确认应答:ACK (Acknowledgment))
[3. 终止连接:FIN (Finish)](#3. 终止连接:FIN (Finish))
[4. 紧急数据:URG (Urgent)](#4. 紧急数据:URG (Urgent))
[5. 立即交付:PSH (Push)](#5. 立即交付:PSH (Push))
[6. 重置连接:RST (Reset)](#6. 重置连接:RST (Reset))
[1. 关于 URG 的补充](#1. 关于 URG 的补充)
[2. PSH 的双向性](#2. PSH 的双向性)
[3. 组合拳](#3. 组合拳)
一、TCP协议的可靠性机制与传输层设计哲学
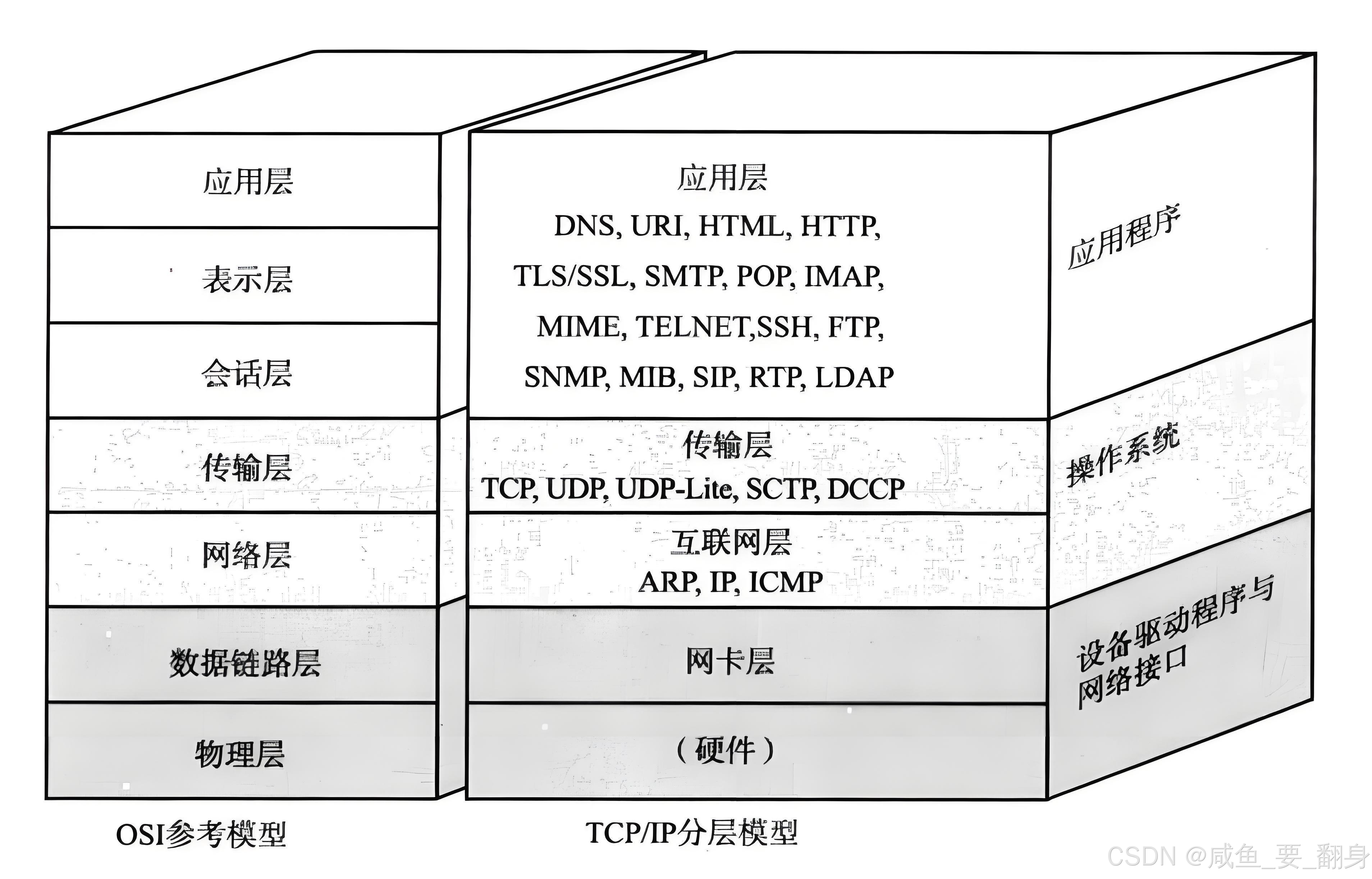
1、TCP协议概述
TCP(Transmission Control Protocol,传输控制协议) 是互联网协议族(TCP/IP)中传输层 的核心协议之一,也是当今互联网中使用最为广泛、最基础的可靠传输协议 。顾名思义,它能够对数据传输过程进行精准控制。
几乎所有对数据完整性、顺序性和可靠性有严格要求的应用都基于 TCP 构建,例如:
-
HTTP/HTTPS(Web 浏览)
-
FTP(文件传输)
-
SSH(远程登录)
-
SMTP/IMAP(电子邮件)
-
MySQL、PostgreSQL 等数据库通信
-
WebSocket、gRPC 等现代 RPC 框架
可以说,没有 TCP,就没有今天稳定、可预测的互联网应用生态。
2、为什么需要"可靠性"?------网络不可靠的本质
计算机内部 vs. 网络通信
在单台计算机内部(如冯·诺依曼体系结构),各硬件组件(CPU、内存、I/O 设备)通过极短距离的物理总线 (如系统总线、IO 总线)进行通信。由于距离短、环境可控,数据传输几乎不会出错,因此无需复杂的错误处理机制。
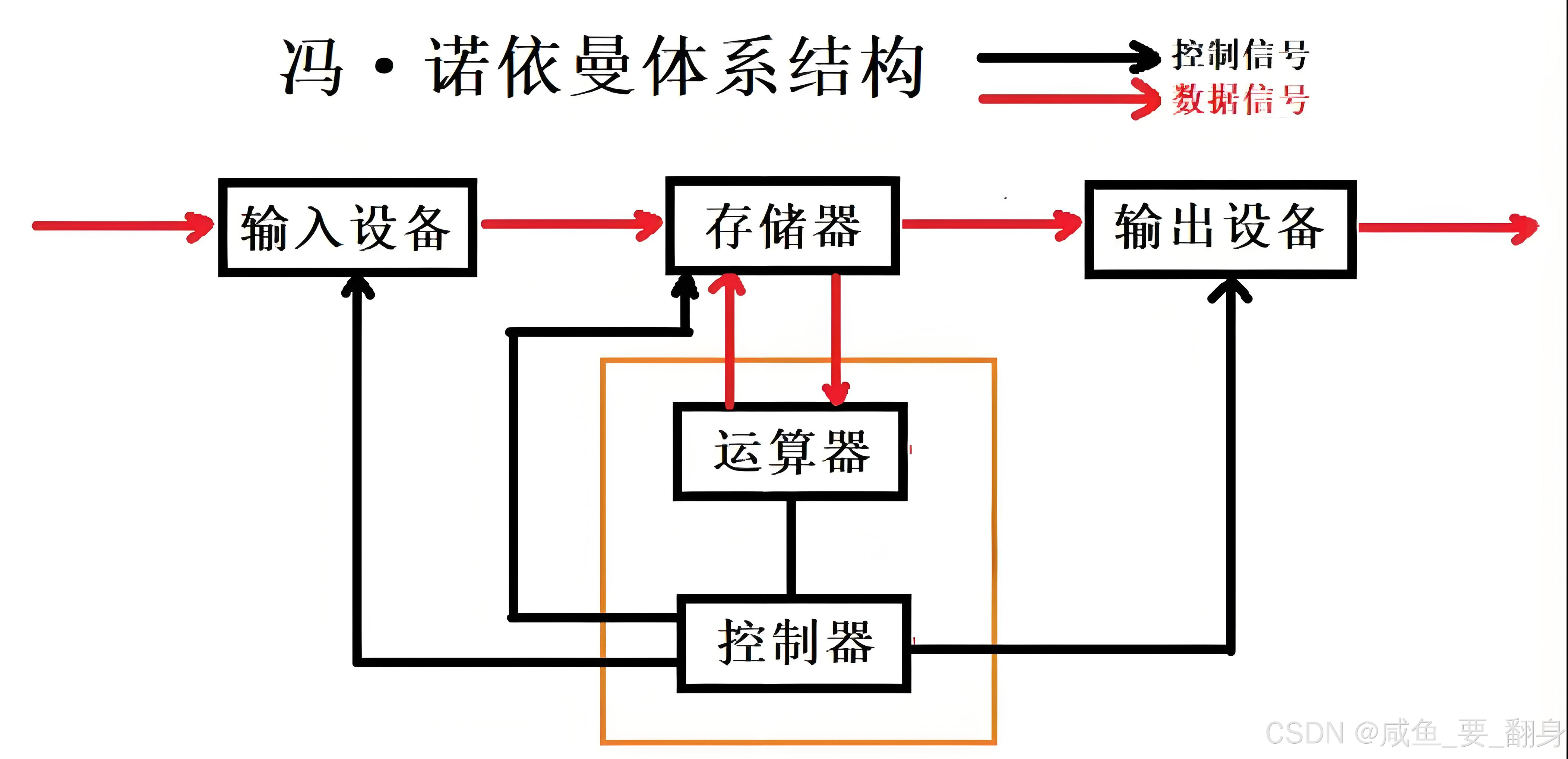
也就是说:虽然计算机的输入设备、输出设备、内存和CPU都集成在同一台机器中,但这些硬件组件实际上是相互独立的实体。为了实现数据交换,它们需要通过专门的连接线路进行通信。具体而言,连接内存与外部设备的线路称为I/O总线,而连接内存与CPU的线路则称为系统总线。由于这些硬件组件都位于同一台机器内部,其连接线路距离非常短,因此数据传输过程中出现错误的概率极低。
然而,当通信设备相隔千里时,连接设备的"线路"会变得异常冗长,数据传输过程中的错误率也会显著上升。为确保远端接收的数据准确无误,就必须引入可靠性机制。比如 当通信跨越地理距离(如从北京到纽约),数据需经过:
-
多跳路由器
-
不同物理介质(光纤、无线、铜缆)
-
拥塞的网络链路
-
可能故障的中间节点
此时,数据包可能遭遇:
-
丢包(Packet Loss):因缓冲区溢出、链路中断等丢失
-
乱序(Out-of-Order Delivery):不同路径导致到达顺序错乱
-
重复(Duplication):重传机制导致同一包多次到达
-
比特错误(Bit Corruption):电磁干扰等导致数据损坏
结论: 长距离、异构、动态的网络环境天然"不可靠",必须由上层协议(如 TCP)主动提供端到端的可靠性保障 。简而言之,网络不可靠的根本原因在于:远距离数据传输所使用的"线路"过长,导致数据在传输过程中容易产生各种问题。正是基于这一背景,TCP协议应运而生,它专门用于确保数据传输的可靠性。
3、TCP 如何实现可靠性?
TCP 并非"魔法",而是通过一系列精心设计的机制协同工作,构建出虚拟的可靠字节流通道。核心机制包括:
| 机制 | 功能说明 |
|---|---|
| 序列号(Sequence Number) | 为每个字节编号,确保接收方可识别顺序、检测乱序或重复 |
| 确认应答(ACK) | 接收方回传已成功接收的数据序号,发送方据此判断是否需重传 |
| 超时重传(Retransmission) | 若未收到 ACK,等待一定时间后自动重发数据 |
| 校验和(Checksum) | 检测数据在传输过程中是否发生比特错误 |
| 流量控制(Flow Control) | 通过滑动窗口防止发送方压垮接收方缓冲区 |
| 拥塞控制(Congestion Control) | 动态调整发送速率,避免网络过载(如慢启动、拥塞避免) |
这些机制共同作用,使得 TCP 能在不可靠的 IP 网络之上,提供有序、无差错、不重复、不丢失的字节流服务。
4、为什么还需要 UDP?------协议选择的工程权衡
TCP协议作为可靠的传输协议,确实能确保数据传输的可靠性。相比之下,UDP协议虽然不可靠,但其存在具有重要意义。也就是说, 既然 TCP 如此强大,为何还存在 UDP(User Datagram Protocol) 这种"不可靠"协议?
关键在于:"可靠"是有代价的。
1. TCP 的代价
-
延迟高:三次握手建立连接、ACK 等待、重传机制增加时延
-
开销大:头部至少 20 字节,包含序列号、ACK、窗口等字段
-
复杂度高:需维护连接状态、重传队列、拥塞控制算法等
2. UDP 的优势
-
无连接:无需握手,直接发送数据报
-
低延迟:适合实时性要求高的场景
-
头部小(仅 8 字节):节省带宽
-
简单灵活:应用层可自定义可靠性策略
3. 典型应用场景对比
-
TCP作为可靠传输协议,需要额外的工作机制来确保数据准确送达。传输过程中可能出现的丢包、乱序和校验失败等问题都会增加其可靠性保障的成本(包括时间和资源消耗)。
-
正是由于需要应对这些传输不可靠性,TCP的实现和使用复杂度远高于UDP,维护成本也显著提升。相比之下,UDP作为不可靠协议,无需处理传输中的各种异常情况,因此使用和维护都更加简单直接。
-
需要强调的是,尽管TCP协议更为复杂,但其传输效率未必低于UDP。TCP不仅内置了可靠性保障机制,还包含多种优化传输效率的设计方案。
| 协议 | 适用场景 | 原因 |
|---|---|---|
| TCP | Web、文件传输、数据库、邮件 | 数据完整性至关重要,容忍一定延迟 |
| UDP | 视频会议、在线游戏、DNS 查询、IoT 传感器上报 | 容忍少量丢包,但要求低延迟、高吞吐 |
4. 重要观点
-
"可靠"与"不可靠"并非优劣之分,而是设计取舍。
-
也就是说,"可靠"与"不可靠"是两个中性词,它们描述的都是协议的特点。
-
UDP 不是"坏"的 TCP,而是为不同需求而生的另一种工具。
-
正如锤子和螺丝刀各有用途,协议选择应匹配业务语义。
UDP与TCP各有所长,选择哪种协议取决于具体应用需求。对于数据传输可靠性要求高的场景,TCP是必然选择;而当允许少量数据丢失时,简单高效的UDP则更为适合。
5、思维扩展:单机即网络
有趣的是,单台计算机内部也可视为一个微型网络:
-
CPU、内存、磁盘、网卡等模块通过总线"通信"
-
它们之间也需遵循硬件协议(如 PCIe、SATA、USB 协议)
-
这些协议同样定义了数据格式、时序、错误检测等规则
**单个计算机本质上是一个微型网络,其内部硬件组件通过数据通信相互连接。这些设备间的交互同样遵循特定通信协议,只是这类协议更侧重于定义数据的语义含义。**区别仅在于:
-
距离极短 → 误码率极低
-
环境封闭 → 故障模式简单
-
同步性强 → 无需复杂重传
这进一步印证了:通信的本质是协调,而协调需要协议。无论是芯片间还是洲际网络,协议都是秩序的基石。
6、总结
-
TCP 是互联网可靠传输的基石,通过序列号、ACK、重传、校验和、流量与拥塞控制等机制,在不可靠的网络上构建可靠通道。
-
网络不可靠源于物理现实:长距离、多跳、异构环境必然引入错误。
-
UDP 的存在是工程理性的体现:在可接受丢包的场景下,牺牲可靠性换取性能与简洁性。
-
协议选择 = 业务需求 × 成本权衡,没有"最好",只有"最合适"。
理解 TCP 与 UDP 的设计哲学,不仅是掌握网络知识的关键,更是培养系统思维与工程判断力的重要一步。
延伸思考:现代 QUIC 协议(HTTP/3 底层)尝试在 UDP 上实现类似 TCP 的可靠性,同时解决 TCP 的"队头阻塞"等问题------这正体现了"在合适层级做合适的事"的网络设计智慧。
二、TCP 协议格式:报头结构、字段含义与数据解析机制
1、引言
TCP(Transmission Control Protocol)作为传输层的核心协议,其报文格式设计 直接决定了其可靠性、流量控制、连接管理等关键能力。理解 TCP 报头的结构,是深入掌握 TCP 工作原理的第一步。TCP 报文由两部分组成:
-
TCP 报头(Header):固定 + 可变长度,用于控制和管理传输
-
有效载荷(Payload):即应用层传递下来的实际数据
2、TCP 报头结构总览
TCP 报头最小为 20 字节 ,最大可达 60 字节(含选项字段)。其标准格式如下(按字节对齐):
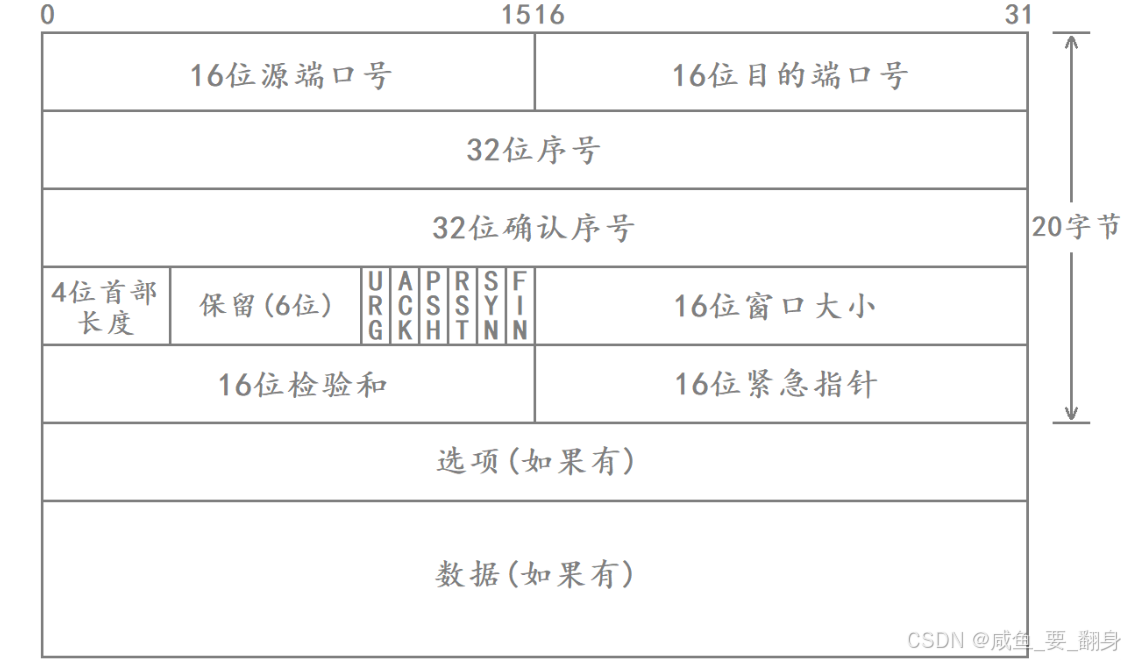
注: 所有字段均以大端序(Big-Endian) 存储。
TCP 报文由 报头(Header) 和 数据(Data) 两部分组成。报头结构(共 20 字节基础长度,可扩展),如下:
| 字段 | 长度 | 说明 |
|---|---|---|
| 源端口号 | 16位 | 发送方端口 |
| 目的端口号 | 16位 | 接收方端口 |
| 序列号(Sequence Number) | 32位 | 标识当前报文段第一个字节的序号,用于实现可靠传输和乱序重排 |
| 确认号(Acknowledgment Number) | 32位 | 表示期望收到的下一个字节的序号,即"已收到所有小于该值的字节" |
| 首部长度(Header Length) | 4位 | 占用4位,表示报头长度,单位是 4字节,所以最小为5(20字节),最大为15(60字节) |
| 保留位 | 6位 | 保留未用 |
| 标志位(Flags) | 6位 | 每个1位: URG:紧急指针有效 ACK:确认号有效 PSH:推送数据 RST:复位连接 SYN:同步序号,建立连接 FIN:结束连接 |
| 窗口大小(Window Size) | 16位 | 流量控制,表示接收方还能接收多少字节的数据 |
| 检验和(Checksum) | 16位 | 检查报头和数据的完整性 |
| 紧急指针(Urgent Pointer) | 16位 | 当URG=1时,指示紧急数据的偏移量 |
| 选项(Options) | 可变 | 如最大报文段长度(MSS)、时间戳等,总长度必须是4字节的倍数 |
注意:
-
TCP 报头最小为 20字节 (无选项),最大为 60字节(含选项)。
-
首部长度字段是 4位,因此取值范围是 0, 15,但实际最小是5(即20字节),因为至少需要20字节的基础头部。
-
所以实际有效范围是 5, 15 ,对应长度为 20, 60 字节。计算公式:
x * 4 = 头部长度(字节)→x ∈ [5,15]
3、各字段详解(超重要!!!)
1. 源端口号(Source Port) & 目的端口号(Destination Port)
-
长度:各 16 位(共 4 字节)
-
作用:
-
源端口:标识发送方应用进程(客户端或服务端)
-
目的端口:标识接收方应用进程(如 80 → HTTP,22 → SSH)
-
-
绑定规则:
-
服务端:显式绑定知名端口(如 nginx 绑定 80)
-
客户端:由操作系统自动分配临时端口(通常 1024~65535)
-
-
维护方式: 内核通过哈希表维护"端口号 ↔ 进程 ID(PID)"的映射关系,实现快速查找与交付。
2. 序列号(Sequence Number, 32 位)
-
表示本报文段第一个字节在整个 TCP 字节流中的偏移位置。
-
初始序列号(ISN)在三次握手时随机生成,防止旧连接数据干扰新连接。
-
作用:实现数据有序重组、检测重复/丢失包。
3. 确认号(Acknowledgment Number, 32 位)
-
表示期望收到的下一个字节的序列号。
-
仅当 ACK 标志位 = 1 时有效。
-
**例如:**若确认号为 1001,表示已成功接收序号 0~1000 的所有字节。
-
可靠性基石 :通过"序列号 + 确认号"机制,TCP 实现了累积确认 与选择性重传的基础。
4. 首部长度(Data Offset / Header Length, 4 位)
-
表示 TCP 报头长度,单位为 4 字节 。(注意这个单位!!!)
-
最小值:5(即 5 × 4 = 20 字节,最基本的报头,此时无选项)
-
最大值:15(即 15 × 4 = 60 字节,最基本的报头加上含 40 字节的其他选项)
-
用途:用于分离报头与有效载荷(见下文"报头解析机制")
5. 保留字段(Reserved, 6 位)
-
当前未使用,必须置为 0。
-
为未来扩展预留空间。
6. 标志位(Control Flags, 6 位)
| 标志位 | 含义 | 说明 |
|---|---|---|
| URG | Urgent | 紧急指针有效。配合紧急指针字段,指示有高优先级数据需立即处理(极少使用) |
| ACK | Acknowledgment | 确认号字段有效。除 SYN 报文外,几乎所有 TCP 报文都置此位 |
| PSH | Push | 提示接收方立即将缓冲区数据交给应用层,避免延迟(如 telnet 输入) |
| RST | Reset | 强制关闭连接或拒绝非法报文。常用于异常终止(如端口未监听) |
| SYN | Synchronize | 同步序列号,用于建立连接(三次握手中的前两次) |
| FIN | Finish | 发送方无更多数据发送 ,用于优雅关闭连接 |
典型组合:
-
SYN=1, ACK=0:客户端发起连接请求
-
SYN=1, ACK=1:服务端响应连接
-
FIN=1:一方请求关闭
-
RST=1:连接异常重置
7. 窗口大小(Window Size, 16 位)
-
表示接收方当前可用的接收缓冲区大小(字节数)。
-
用于流量控制(Flow Control):发送方不得发送超过此窗口的数据。
-
实际窗口可通过"窗口缩放选项(Window Scale)"扩展至 30 位(RFC 1323)。
8. 校验和(Checksum, 16 位)
-
覆盖范围 :TCP 报头 + 有效载荷 + 伪首部(Pseudo Header)
- 伪首部包含:源 IP、目的 IP、协议号(6)、TCP 长度
-
算法:16 位反码求和(非 CRC!)
-
作用 :检测传输过程中比特错误(如内存翻转、线路干扰)
-
若校验失败,直接丢弃该报文,不发送任何响应(由超时重传机制处理)
注意: 虽然早期文档有时误称为"CRC",但 TCP 实际使用的是Internet Checksum,一种简单高效的校验算法。
9. 紧急指针(Urgent Pointer, 16 位)
-
仅当 URG=1 时有效。
-
表示从当前序列号开始的偏移量 ,指向紧急数据的最后一个字节之后的位置。
-
例如:序列号=1000,紧急指针=5 → 紧急数据为 1000~1004。
-
现状:现代应用极少使用 URG 机制,多数系统将其忽略。
10. 选项字段(Options, 0~40 字节)
-
可选且变长,用于扩展 TCP 功能。
-
常见选项:
-
MSS(Maximum Segment Size):协商单个 TCP 段最大数据长度(不含 IP/TCP 头)
-
Window Scale:扩大窗口字段至 30 位,支持高速长距网络
-
SACK(Selective Acknowledgment):允许确认非连续数据块,提升重传效率
-
Timestamps:用于 RTT 测量和 PAWS(防序列号回绕)
-
-
填充(Padding):确保选项总长度为 4 字节对齐。
-
**注意:**由于首部长度字段最大为 60 字节,而基本头占 20 字节,故选项最多 40 字节。
关键说明
-
首部长度以4字节为单位计算(与报文宽度一致)
-
4位首部长度取值范围0000~1111,对应最大报头长度15×4=60字节
-
基本报头固定20字节,因此选项字段最多40字节
-
无选项时,首部长度值为20÷4=5(二进制0101)
4、TCP 报头的封装与解析机制
1. 内核中的实现方式
在操作系统内核实现中**,TCP报头本质上是一个位段结构体(bit-field struct)。封装TCP报头的过程包括:首先声明该结构体变量,然后逐一填充各个字段值,最后将完整的报头数据复制到数据包首部,从而完成TCP报头的封装过程。**例如(简化版 C 伪代码):
cpp
struct tcphdr {
uint16_t source; // 源端口
uint16_t dest; // 目的端口
uint32_t seq; // 序列号
uint32_t ack_seq; // 确认号
uint8_t doff:4; // 首部长度(4位)
uint8_t res1:6; // 保留(6位)
uint8_t flags:6; // 标志位(6位)
uint16_t window; // 窗口大小
uint16_t check; // 校验和
uint16_t urg_ptr; // 紧急指针
};封装时,内核填充该结构体,再将其拷贝到数据包头部,完成封装。
2. 如何分离报头与有效载荷?
**当TCP从底层接收到一个报文时,虽然无法直接确定报头长度,但报文的前20字节必定是TCP基本报头,其中包含4位的首部长度字段。TCP 在接收数据时,需先解析报头才能处理 payload。**其步骤如下:
-
读取前 20 字节 (固定头部),从中提取 4 位首部长度字段(doff)
-
计算实际报头长度:
header_len = doff * 4 -
若
header_len > 20,则继续读取header_len - 20字节作为选项字段(也就是除了基本头,剩下的报头字段就是选项字段,注意是报头字段) -
然后再者剩余的部分即为有效载荷(Payload)
示例: 若 doff = 8 → 报头长度 = 8 × 4 = 32 字节 → 选项占 12 字节 → 第 33 字节起为 payload。
3. 如何交付给上层应用?
网络通信中,应用层的每个进程都必须与特定端口号绑定:
-
服务器进程需要显式指定端口号,而客户端端口则由系统自动分配。
-
TCP协议通过在报文头部携带目标端口号,使接收方能够准确识别目标进程,从而将数据交付给对应的应用层处理。
TCP 依据目的端口号进行分发:
-
从报头中提取 目的端口号(dest port)
-
查询内核维护的 "端口-进程"映射表 (通常为哈希表)(系统内核通过哈希表维护端口号与进程ID的映射关系,这使得传输层能快速通过端口号定位目标进程)
-
找到对应的应用进程(socket)
-
将有效载荷放入该 socket 的接收缓冲区
-
若设置了 PSH 标志,则通知应用层立即读取
安全机制:只有绑定该端口的进程才能接收数据,其他进程无法窃听。
5、总结
| 特性 | 说明 |
|---|---|
| 最小报头 | 20 字节(无选项) |
| 最大报头 | 60 字节(含 40 字节选项) |
| 核心字段 | 序列号、确认号、ACK/SYN/FIN 标志、窗口、校验和 |
| 关键机制支撑 | 可靠性(序列号+ACK)、流量控制(窗口)、连接管理(SYN/FIN/RST) |
| 解析关键 | 首部长度字段(doff)决定报头边界 |
| 交付依据 | 目的端口号 + 内核端口映射表 |
TCP 报头虽仅几十字节,却承载了整个可靠传输体系的控制逻辑。理解其每一个字段的设计意图,是掌握网络编程、性能调优与故障排查的基石。
三、TCP 序号与确认序号机制:可靠传输的核心逻辑
1、什么是"真正的可靠"?
在网络通信中,"发送数据"并不等于"对方收到数据"。 由于链路可能丢包、乱序、损坏甚至中断,单向发送无法保证可靠性。
真正的可靠 = 发送方收到接收方的明确确认(ACK)
只有当发送方收到对端返回的确认消息,才能确信自己之前发送的数据已被成功接收。 这种"确认应答(Acknowledgment) "机制,是 TCP 实现可靠传输的基石。如下图所示:
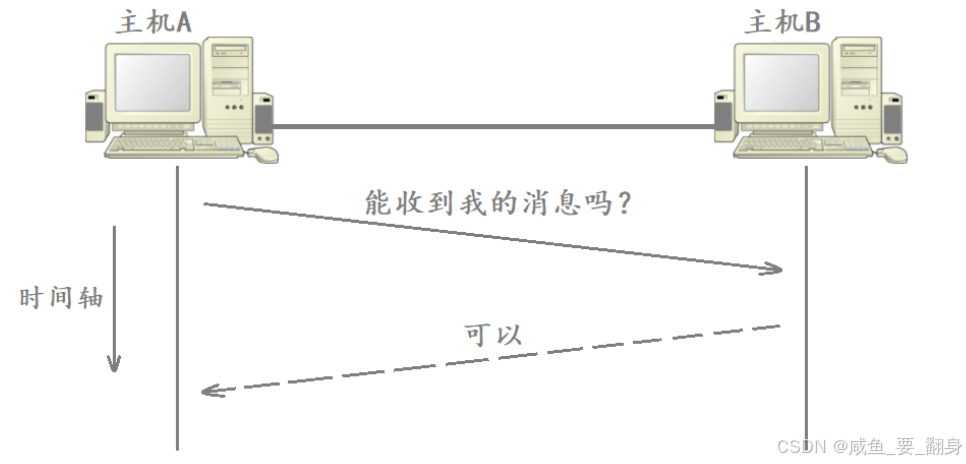
一个哲学困境:无限确认?
设想如下场景:
-
A 发送数据给 B;
-
B 收到后回复 ACK;
-
但 B 的 ACK 也可能丢失;
-
于是 A 需要确认 B 是否收到了 ACK;
-
B 又需确认 A 是否收到了"确认 ACK 的确认"......
这看似陷入无限递归 ,永远无法 100% 确保最后一条消息被接收。**实线表示数据可被对方可靠接收,虚线表示传输可靠性无法保证,**如下图所示:
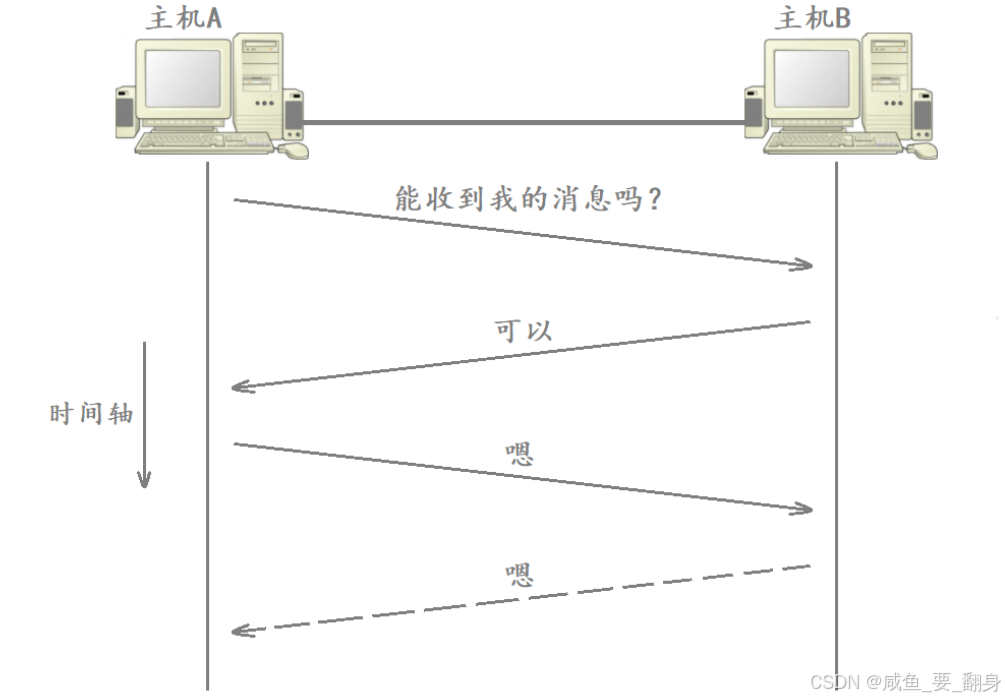
现实解法
-
我们不要求"所有消息"都可靠,只要求"核心数据"可靠。
-
对于 ACK 这类控制报文,即使丢失,发送方也会因超时而重传原始数据,从而间接触发新的 ACK。(这个是核心原理!!!)
-
因此,通过"数据重传 + 累积确认"机制,系统在有限步骤内达成最终一致性。
-
以发送方视角的话,TCP 的设计让发送方"负责到底",直到收到确认为止: 主要是以发送方为主体(只关心发送方的发送和接收情况),发送方发送了报文,要求接收方必须应答回来,也就是说发送方必须得接收到接收方的回答,这才能确认发送方发送的报文成功地传到了接收方那里!!!否则就使用"数据重传 + 累积确认"机制。
-
更具体的表述:TCP 发送方发送数据后,会等待接收方返回确认(ACK)。只有当发送方收到对应序号的 ACK,才能认为该数据已被接收方成功接收。若未在合理时间内收到 ACK(或通过重复 ACK 推断丢包),则触发重传机制。ACK 采用累积确认方式,且接收方可能延迟发送 ACK。这一机制共同保障了 TCP 的可靠有序传输。(原理步骤!!!)
-
这就是 TCP 的务实哲学:用可接受的成本,实现工程意义上的"足够可靠"。
-
发送方需要接收到来自接收方的确认(ACK) ,才能认为之前发送的数据已被对方成功接收。
-
如果在一定时间内(由重传超时 RTO 决定)没有收到 ACK,发送方会重传该数据,这是 TCP 可靠传输的核心机制之一。
-
TCP 使用的是累积确认(Cumulative Acknowledgment):ACK 号表示"期望收到的下一个字节序号",也就是说,接收方通过一个 ACK 可以确认它已经成功收到了该序号之前的所有数据。
简单来说就是:
-
互联网通信的可靠性存在固有局限:只有收到对方响应时,才能确认上一次发送的数据已被可靠接收。由于通信过程中总会存在最新发送的未响应消息,因此绝对可靠性在理论上无法实现。
-
在实际应用中,我们无需追求所有消息的可靠性保证,只需确保核心数据交换时每个关键消息都有对应响应即可。
-
对于非关键数据(如响应消息本身),即使丢失也不会影响通信质量------若接收方未收到响应,会自动触发上次发送数据的重传机制。
-
TCP协议采用了一种称为确认应答的机制来确保数据传输的可靠性。
-
值得注意的是,这种机制并非保证通信过程中所有消息的可靠性,而是通过发送方收到接收方的应答消息,来确认上一次发送的数据已被对方成功接收。如下所示:
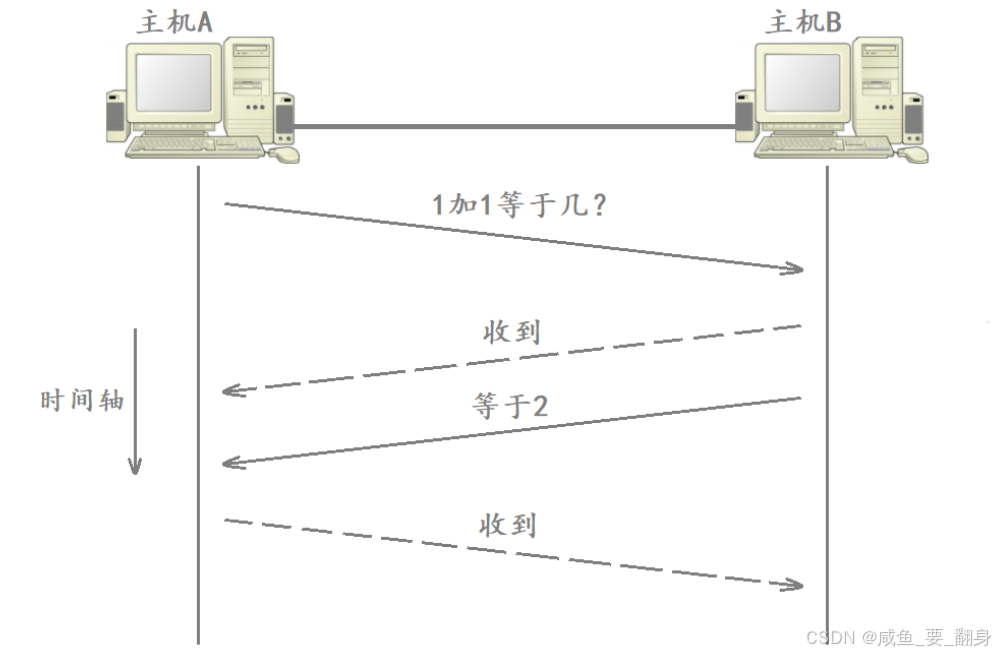
总的来说
核心问题:
-
TCP 是否完全可靠?答案是:不完全可靠!
-
"100%可靠"是一个理想化说法,现实中无法保证最新报文一定被收到。
正确理解可靠性:
-
对历史消息可以保证可靠性:只要发送方收到了 ACK,就说明之前的数据已经成功送达。
-
最新的报文永远无法得到应答:因为最后一个报文可能在通信结束前丢失,且没有后续报文来触发 ACK。
结论:TCP 的可靠性不是"绝对"的,而是通过"确认应答机制"来实现"历史消息的可靠性"。
关键机制:确认应答(ACK)机制
-
每次接收方收到数据后,会发送一个 ACK 报文,告知发送方:"我已收到到某个序号为止的所有数据"。
-
这种机制使得发送方知道哪些数据已被成功接收,从而决定是否重传。
-
核心思想:通过确认应答来确保数据不丢失。
注意:不应对应答做应答!(避免无限循环)
2、32 位序号(Sequence Number):字节级编号系统
1. 设计目标
-
唯一标识每个字节 :TCP 将整个连接视为一个无结构的字节流,而非独立报文。
-
支持乱序重组:网络路径不同可能导致报文乱序到达,需按序交付应用层。(由于网络传输路径的差异,连续发送的多个报文可能会以不同于发送顺序的次序到达接收端)
-
检测重复/丢失:通过序号判断是否收到新数据、旧数据或缺失数据。
-
在网络通信中,如果必须等待前一次数据的响应才能发送下一个数据,这种串行通信方式的效率显然很低。
-
为了提高效率,通信双方可以采用连续发送多个数据报文的方式,只需确保每个发送的报文都能收到对应的响应即可。这种方式既保证了数据的可靠传输,又提升了通信效率。
-
为了确保报文的有序性(这是可靠传输的重要特征之一),TCP协议在报头中使用32位序号字段来维护报文顺序。
2. 工作原理
-
每个 TCP 报文的 序号字段 = 该报文中第一个字节在整个字节流中的偏移量。
-
初始序号(ISN, Initial Sequence Number)在三次握手时随机生成(防旧连接干扰)。
-
序号空间为 32 位(0 ~ 2³²−1),用完后回绕(配合时间戳防混淆)。
示例:
**TCP协议为每个传输的字节数据分配唯一的序列号。**例如,当发送端需要传输3000字节数据时,若每次发送1000字节,则需要使用三个TCP报文。这三个报文的32位序号字段将分别记录其携带数据的首个字节序号:1、1001和2001。假设 A 向 B 发送 3000 字节数据,每次发 1000 字节:
| 报文 | 有效载荷(字节) | 序号(Sequence Number) |
|---|---|---|
| #1 | 0--999 | 1 |
| #2 | 1000--1999 | 1001 |
| #3 | 2000--2999 | 2001 |
**注意:**序号从 1 开始仅为示例,实际 ISN 是随机值(如 2894567890)。
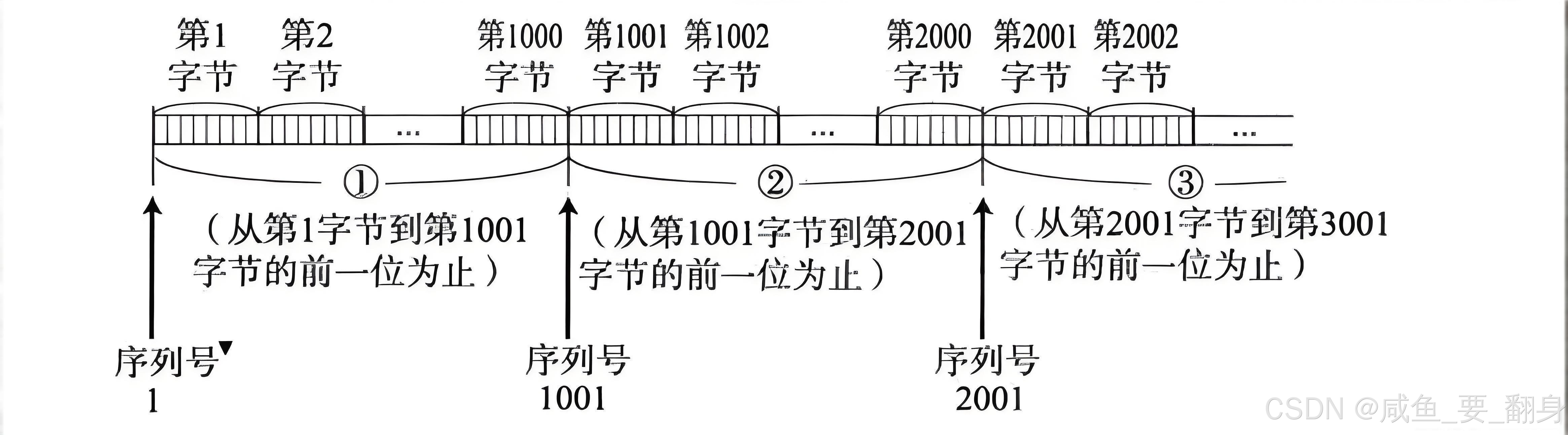
3. 接收端如何处理?
-
接收端收到这些报文后,传输层会根据报文头中的32位序列号对报文进行排序重组。经过排序后,报文将被存入TCP接收缓冲区,确保其顺序与发送端完全一致(接收方根据序号将乱序报文重排序,放入接收缓冲区);
-
应用层读取时,看到的是连续、有序的字节流,如同本地文件读写;
-
在报文重组过程中,接收端可以通过当前报文的32位序号及其有效载荷长度,准确计算出下一个预期报文的序号。(注意!!!这个特点很重要!!!)
3、32 位确认序号(Acknowledgment Number):累积确认机制
1. 核心含义
-
确认序号 = 期望收到的下一个字节的序号
-
表示:"我已成功接收所有序号 < 确认序号 的字节"
-
TCP报头中的32位确认序号用于向对端表明当前已接收的数据范围,并指示下一次数据传输的起始位置。
-
关键特性:累积确认(Cumulative ACK): 即使中间有未收到的报文,确认号只反映连续已收数据的末尾+1 。(这是非常重要的一个特性!!!)
延续上例:
-
B 收到序号为 1 的报文(含 1000 字节)→ 已收 1~1000;
-
B 返回 ACK 报文,确认序号 = 1001;
-
含义:
-
"1~1000 我都收到了"
-
"下次请从 1001 开始发"
-
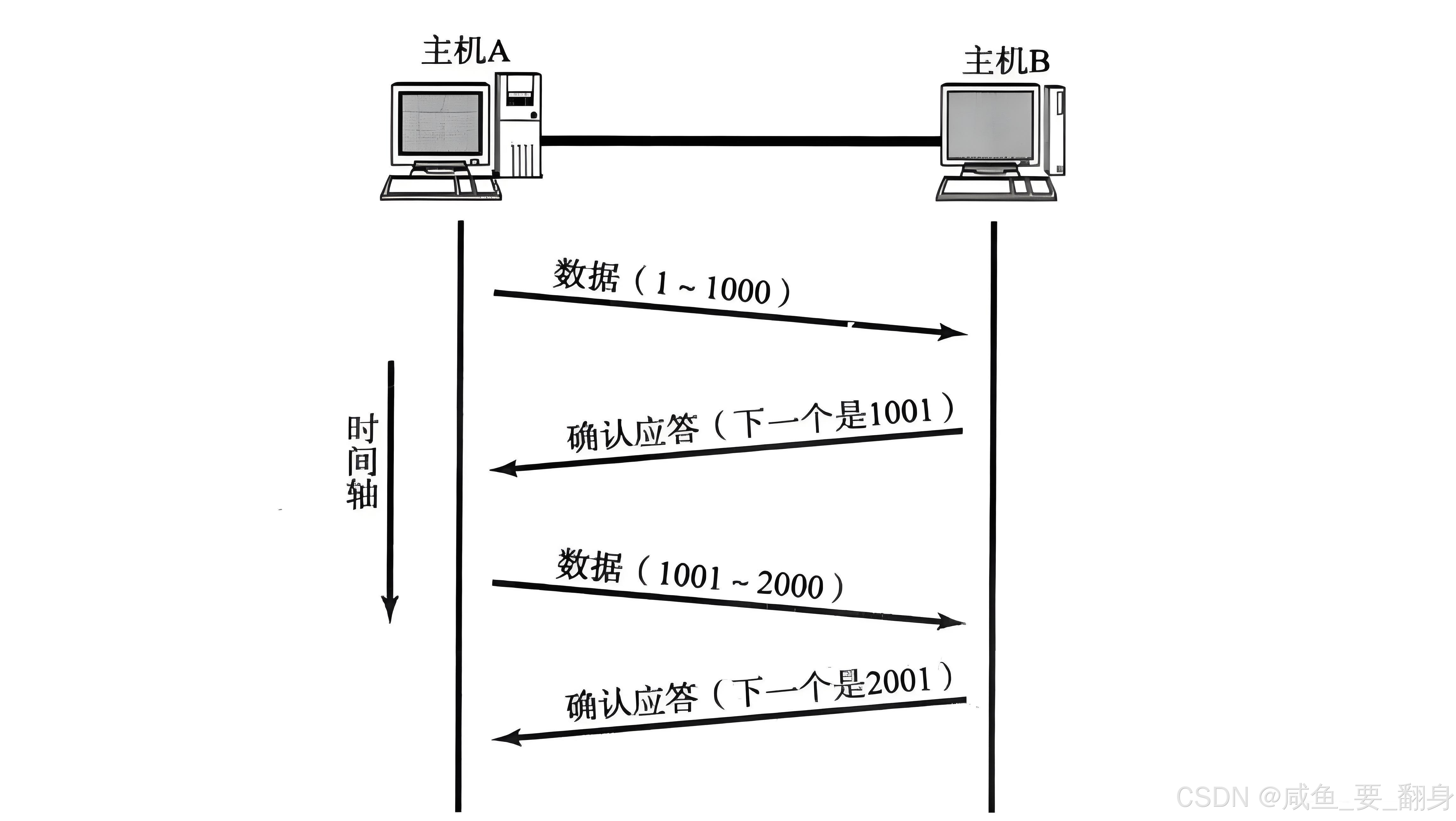
当主机B收到主机A发送的32位序号为1且包含1000字节数据的报文时,主机B确认已接收序列号1-1000的数据。因此,主机B在响应报文中将32位确认序号设置为1001。
这一机制实现了双重功能:
-
通知主机A:序列号1001之前的数据已成功接收
-
指示主机A:后续数据传输应从序列号1001开始
对于主机A后续发送的其他报文,主机B在响应报文中填写确认序号时遵循相同的规则。
**注意:**响应报文同样以完整的TCP报文形式传输,即使不包含有效载荷,也至少包含TCP报头部分。
2. 丢包场景下的行为
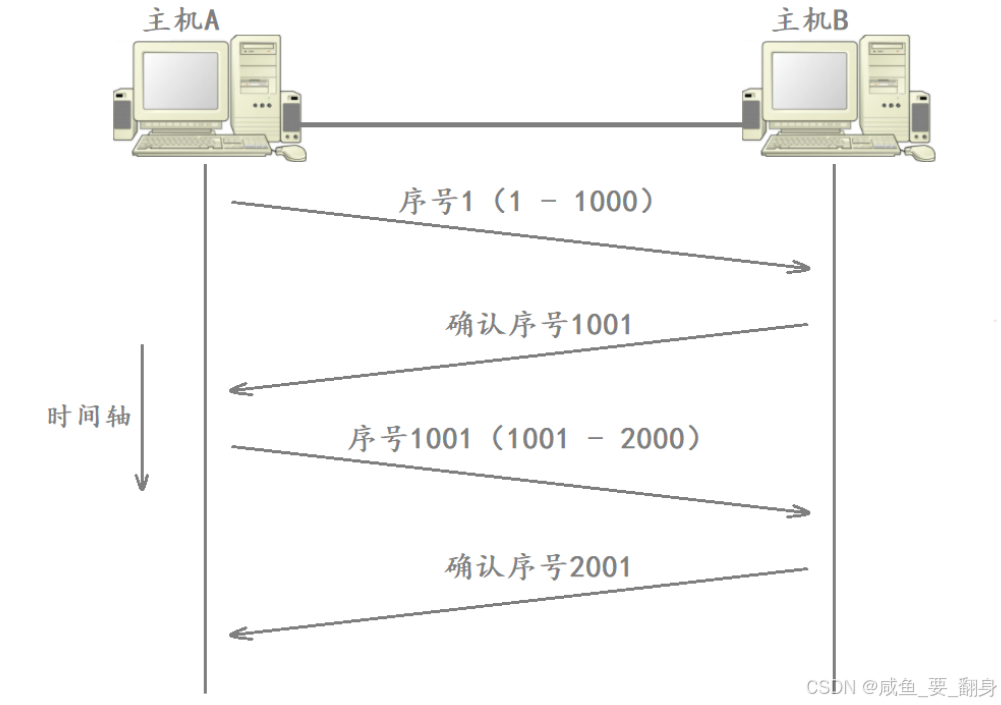
以刚才的例子说明,假设 主机A向主机B发送了三个报文,每个报文的有效载荷均为1000字节,对应的32位序号分别为1、1001和2001。,但 1001 的包丢失,B 只收到 1 和 2001:
-
B 的接收缓冲区:1--1000 + 2001--3000 → 存在缺口(1001--2000)(即:若这三个报文在传输过程中发生丢包,只有序号为1和2001的报文成功送达主机B。当主机B进行报文重组时,会发现仅接收到1-1000和2001-3000的字节数据。)
-
B 仍只能确认 1001(因为 1001 之前的连续数据只到 1000),也就是说此时,主机B在响应报头中会将32位确认序号设为1001,以此告知主机A:下次传输应从序列号为1001的字节数据开始。
-
因此,主机B必须响应1001,所以 B 发送 ACK=1001 给 A。
-
当主机A收到该确认序号后,发现确认序号并不是3001,跟预想的不一样(因为 TCP 是按序交付的),即可判定序号为1001的报文已丢失,并选择重传该数据。(这一步非常重要!!!)
-
通过这种方式,发送端能够根据接收端返回的确认序号,准确判断传输过程中可能丢失的报文。

也就是说,A 收到 ACK=1001 后:
-
若后续又收到 ACK=1001(重复 ACK,因为之前已经收到过1001确认序号了,此时A预想是要收到确认序号2001的才对),可判断中间包丢失;
-
触发快速重传(Fast Retransmit) 或等待超时重传(RTO)
重要原则
-
确认序号绝不能跳过未收到的数据!
-
若 B 错误地发送 ACK=3001,则 A 会误以为全部数据已送达,导致 1001--2000 永久丢失。(也就是说,主机B的响应确认序号不能设为3001,因为1001-2000的序列号数据尚未收到。若直接响应3001,意味着主机B已确认接收所有3001之前的数据,这与实际情况不符。)
4、为何需要两套序号?------全双工通信的本质
如果通信是单向的 (如 A → B),理论上只需一套序号**(发送端将序号视为32位发送序号,接收端将该序号视为32位确认序号)**:
-
A 用序号标记数据;
-
B 用同一序号空间作为确认号。
但 TCP 是全双工(Full-Duplex) 协议,双方可能同时进行数据发送:
-
A ↔ B 可同时双向传输数据
-
每一方既是发送者,也是接收者
-
每个报文必须包含:
-
32位发送序号:标识本端当前发送数据的序号
-
32位确认序号:确认对方已接收的数据位置
-
-
这种设计使得:
-
双方都需要维护确认应答机制
-
单一序号系统无法满足需求
-
必须采用两套序号系统
-
因此,每个 TCP 报文必须同时携带:
| 字段 | 作用 |
|---|---|
| 序号(Seq) | 标识本报文所承载的本端发送数据的起始字节 |
| 确认序号(Ack) | 确认对端已成功发送的数据进度 |
核心功能说明:
-
32位序号: ✓ 确保数据有序到达 ✓ 为对方提供确认依据
-
32位确认序号: ✓ 标识已接收数据范围 ✓ 指示对方下次发送起始位置
关键特性:
-
序号与确认序号共同实现确认应答机制
-
通过序号比对可检测报文丢失情况
示例:双向通信(重点理解!!!)
cpp
A → B: Seq=100, Ack=200, Data="Hello"
B → A: Seq=200, Ack=105, Data="Hi"-
A 告诉 B:"我发的是第 100 字节开始的数据,且我已收到你发到 199 的数据"
-
B 告诉 A:"我发的是第 200 字节开始的数据,且我已收到你发到 104 的数据"
结论 :两套序号是支持并发双向可靠传输的必要设计。
5、序号与确认序号的协同:确认应答机制的数据化表达
| 机制 | 依赖字段 | 功能 |
|---|---|---|
| 按序交付 | 序号(Seq) | 接收方重组乱序报文 |
| 丢失检测 | 确认序号(Ack) | 发送方判断是否需重传 |
| 流量推进 | 确认序号(Ack) | 告知发送方"窗口可前移" |
| 连接同步 | 初始序号(ISN) | 防止历史连接数据污染新连接 |
闭环反馈 :序号 → 接收方生成确认序号 → 发送方据此调整发送策略 → 形成自适应可靠传输环路。(非常重要的思想!!!)
6、补充:序号回绕与 PAWS 机制
由于序号是 32 位,高速网络下可能快速回绕(如 1 Gbps 链路约 34 秒回绕一次)。为防止"旧连接的重复报文被误认为新数据",TCP 引入:
-
时间戳选项(Timestamps)
-
PAWS(Protect Against Wrapped Sequence numbers)算法
通过比较时间戳,丢弃"序号合法但时间过旧"的报文,确保语义正确性。
7、总结
| 概念 | 说明 |
|---|---|
| 真正的可靠 | 基于确认应答(ACK),非盲目信任发送 |
| 序号(Seq) | 标识本端发送数据的字节偏移,用于乱序重组 |
| 确认序号(Ack) | 标识对端已连续接收的数据边界,驱动重传与窗口滑动 |
| 累积确认 | 只确认连续前缀,不确认乱序到达的后续数据 |
| 两套序号必要性 | 支持全双工双向可靠通信 |
| 工程可靠性 | 不追求 100% 理论可靠,而是通过重传+确认实现"足够可靠" |
一句话精髓 :TCP 的可靠性,不是靠"永不丢包",而是靠"丢包可知、丢包可补"。
理解序号与确认序号,就掌握了 TCP 可靠传输的"心跳"与"神经信号"。这是深入理解滑动窗口、拥塞控制、重传策略等高级机制的前提。
四、TCP 缓冲区与窗口机制详解:流量控制(Flow Control)的核心实现
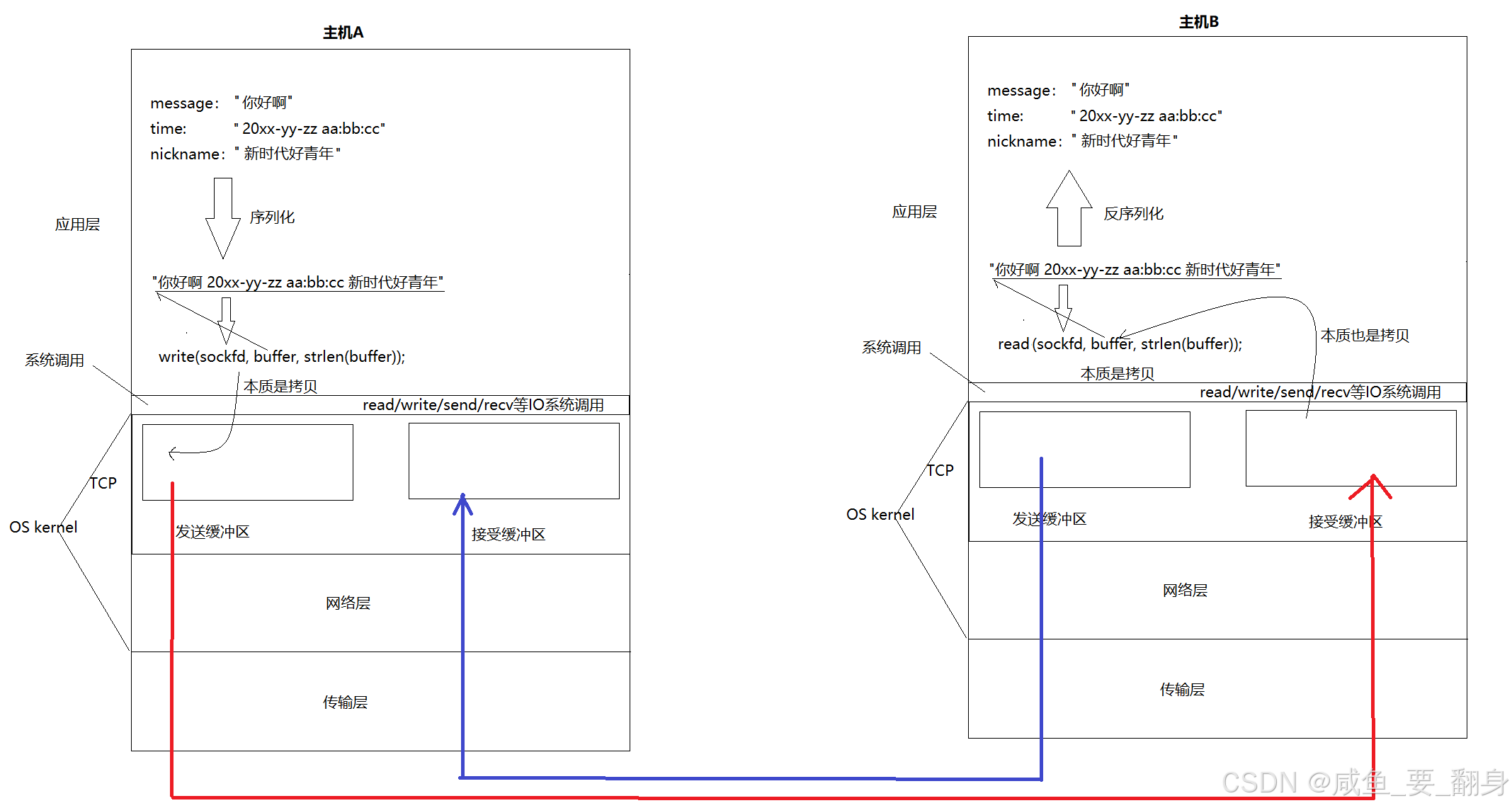
1、引言:TCP 的"缓冲"哲学
TCP(Transmission Control Protocol)之所以被称为"传输控制协议",不仅因为它提供可靠性,更因为它主动管理数据流动的节奏 。而这一能力的核心载体,就是 发送缓冲区(Send Buffer) 与 接收缓冲区(Receive Buffer)。
这两个缓冲区是 TCP 传输层内部的关键内核数据结构 ,它们将应用层的读写操作 与底层网络的实际传输 解耦,使得上层无需关心网络瞬时状态,同时为流量控制、拥塞控制、乱序重组、重传机制等提供了基础支撑。
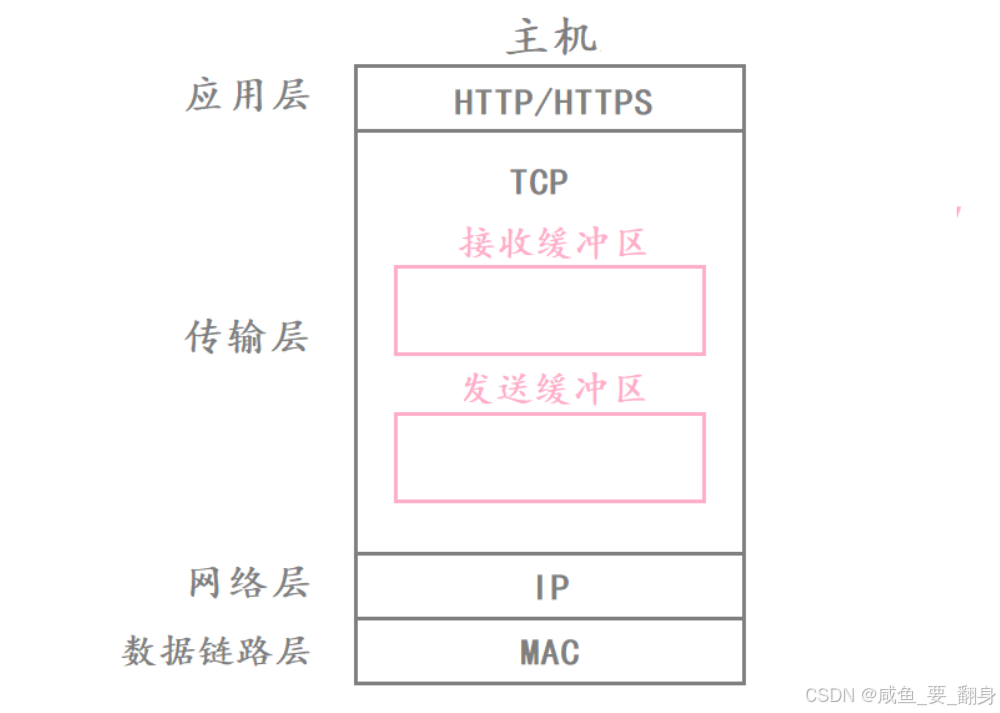
2、TCP 缓冲区的本质与作用(位于操作系统内核)
1. 发送缓冲区(Send Buffer)
-
位置:位于发送方 TCP 层内部
-
来源 :由应用层通过
write()/send()系统调用写入 -
行为:
-
发送缓冲区用来暂时保存还未发送的数据
-
应用层调用
write()后,数据被拷贝到发送缓冲区,函数即可返回(非阻塞或异步语义的基础) -
TCP 协议栈按需从缓冲区取出数据,封装成 TCP 段并交由 IP 层发送
-
未被确认(ACKed)的数据必须保留在缓冲区中,以便在丢包时重传
-
关键点 :write() 成功 ≠ 数据已发送到网络,仅表示"已交给 TCP 管理"。
2. 接收缓冲区(Receive Buffer)
-
位置:位于接收方 TCP 层内部
-
去向 :由应用层通过
read()/recv()系统调用读取 -
行为:
-
接收缓冲区用来暂时保存接收到的数据
-
网络层收到 TCP 报文后,经校验、确认、重排后,存入接收缓冲区
-
应用层调用
read()时,从该缓冲区拷贝数据到用户空间 -
即使应用层未及时读取,正确报文也不会被丢弃
-
关键点 :read() 阻塞 ≠ 网络无数据,而是"接收缓冲区为空"。
3、缓冲区存在的核心意义
实现方式
-
利用 窗口大小(Window Size) 字段。
-
接收方通过设置窗口大小,告诉发送方自己还能接收多少数据。
-
发送方根据窗口大小调整发送速率,防止接收方缓冲区溢出。
**示例:**如果窗口大小为 1000,则发送方最多发送 1000 字节的数据,直到收到新的窗口更新。
| 场景 | 问题 | 缓冲区的作用 |
|---|---|---|
| 丢包重传 | 网络可能丢包 | 发送缓冲区保留未确认数据,供重传使用 |
| 处理速度不匹配 | 应用处理慢 vs 网络接收快 | 接收缓冲区暂存数据,避免因来不及处理而丢弃 |
| 乱序到达 | 报文路径不同导致乱序 | 接收缓冲区用于缓存并重组有序字节流 |
| 解耦上下层 | 应用不应感知网络细节 | 缓冲区作为"中间层",隔离应用与网络波动 |
类比文件 I/O :应用层通过write/send等系统调用将数据写入TCP发送缓冲区,而非直接发送到网络。同理,应用层通过read/recv调用从TCP接收缓冲区读取数据,而不是直接从网络获取。
-
就像
fwrite()不直接写磁盘,而是写入 C 标准库缓冲区; -
TCP 的
write()也不直接发网络,而是写入内核 TCP 缓冲区。
当数据被写入TCP发送缓冲区后,相应的write/send函数即可立即返回。至于缓冲区中数据的实际发送时机和传输方式,完全由TCP协议自行控制。
TCP被称为传输控制协议,正是因为它自主管理着所有数据传输细节。无论是数据的收发方式,还是传输过程中遇到的各种问题处理,都由TCP协议独立决策。用户只需完成两个基本操作:将数据写入发送缓冲区,以及从接收缓冲区读取数据。通信双方的TCP层结构相同,都包含发送缓冲区和接收缓冲区。
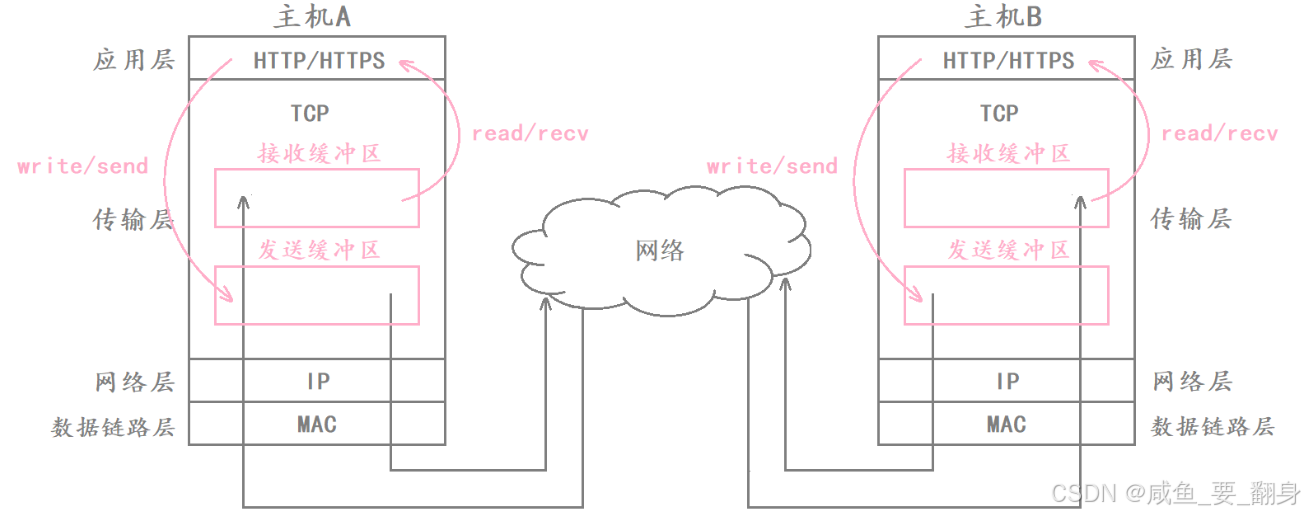
发送缓冲区的作用:
-
临时存储已发送的数据,以备可能的重新传输需求
-
在网络传输出现错误时,确保能快速获取原始数据进行重发
-
仅当接收方确认成功接收后,缓冲区内的对应数据才会被释放
接收缓冲区的作用:
-
暂存到达但尚未处理的数据,避免因处理速度不足导致数据丢失
-
确保有效传输的数据不会被随意丢弃,提高网络资源利用率
-
同时承担TCP数据包重新排序的功能,保证数据按正确顺序处理
4、生产者-消费者模型视角
TCP 缓冲区天然契合经典的生产者-消费者模型:
1. 发送缓冲区:应用是生产者,网络是消费者
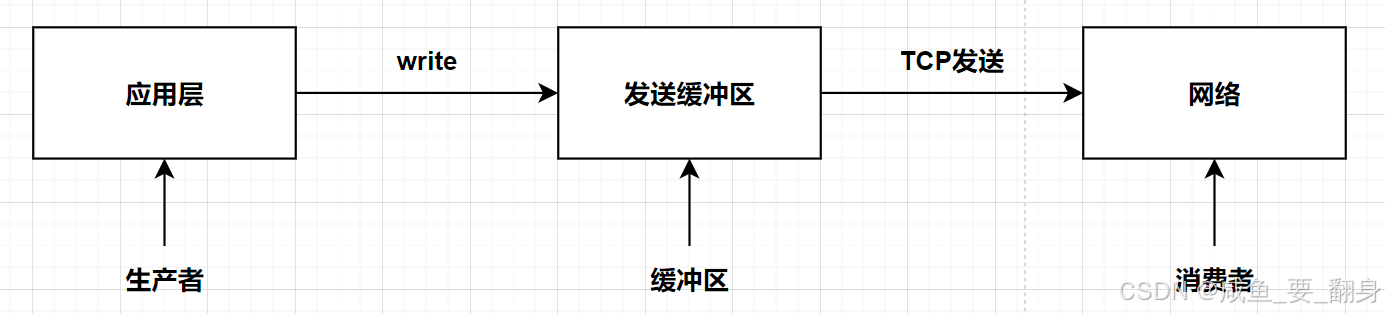
-
应用不断"生产"数据到缓冲区(上层应用持续向缓冲区写入数据(生产者))
-
TCP 协议栈作为"消费者",按网络状况和窗口大小决定何时发送(网络层持续从缓冲区读取数据进行封装(消费者))
-
发送缓冲区充当数据交换的中介
2. 接收缓冲区:网络是生产者,应用是消费者
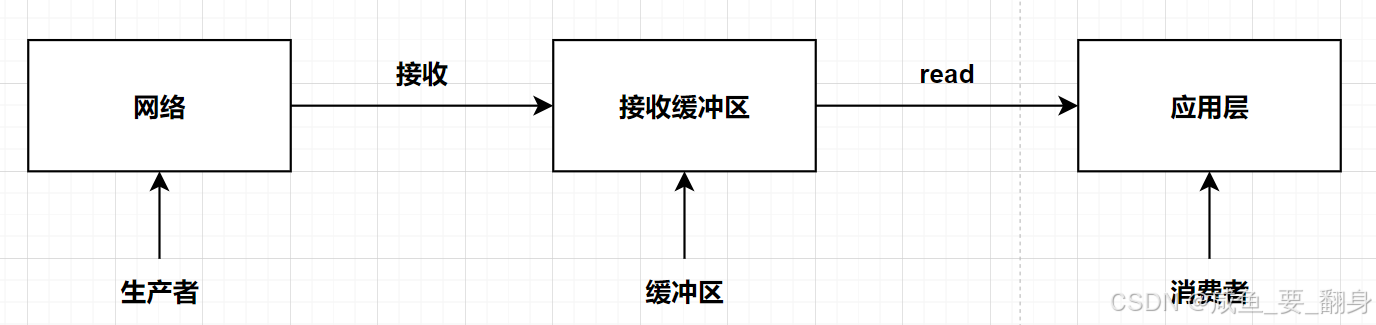
-
网络不断"生产"数据到缓冲区(网络层持续向缓冲区写入数据(生产者))
-
应用作为"消费者",按自身节奏读取处理(上层应用持续从缓冲区读取数据处理(消费者))
-
接收缓冲区作为数据交换的媒介
通过引入这两个缓冲区,系统实现了:
-
上层应用与底层通信的解耦
-
双生产者消费者模型的并行运作
-
对并发操作和负载不均衡情况的支持
优势:
-
支持异步处理(生产与消费速率可不同)
-
提升系统吞吐(避免频繁上下文切换)
-
实现忙闲均衡(突发流量可被缓冲吸收)
5、窗口大小(Window Size):流量控制的信号灯
当发送端向对端传输数据时,实际上是将自身发送缓冲区的数据传送到对端的接收缓冲区。由于缓冲区容量有限,若接收端处理速度低于发送端传输速度,接收缓冲区最终会被填满,导致后续数据丢失并引发重传等一系列连锁反应。TCP报头中的16位窗口大小字段正是为解决这一问题而设计。该字段表示接收端缓冲区剩余空间容量,即当前主机的数据接收能力。
接收端在响应发送端时,会通过窗口大小字段告知其当前缓冲区剩余空间。发送端据此动态调整数据传输速率:
-
窗口值越大,表明接收端处理能力越强,发送端可提高传输速率
-
窗口值越小,表示接收端处理能力不足,发送端应降低传输速率
-
当窗口值为零时,说明接收缓冲区已满,发送端应暂停数据传输
实际应用观察:
-
调用read/recv读取数据时若被阻塞,本质是TCP接收缓冲区为空,程序实际阻塞于接收缓冲区
-
调用write/send写入数据时若被阻塞,则是TCP发送缓冲区已满,程序实际阻塞于发送缓冲区 这与生产者消费者模型的阻塞原理一致:当生产者或消费者被阻塞时,必定是由于某些条件尚未就绪所致。
1. 问题背景:为何需要流量控制?
若发送方持续高速发送,而接收方处理缓慢,接收缓冲区终将溢出,导致:
-
新到报文被丢弃
-
触发不必要的重传
-
浪费带宽,降低整体效率
注意:不能依赖"丢包再重传"来解决接收方过载问题 ------这是拥塞控制的范畴,而流量控制(Flow Control)专治"接收方跟不上"。
2. 窗口大小字段的定义
-
位置:TCP 报头中的 16 位字段
-
含义 :表示当前接收方接收缓冲区中剩余可用空间的字节数
-
单位:字节(Byte)
-
最大值:65535 字节(16 位限制)
注意 :现代 TCP 可通过 窗口缩放选项(Window Scale, RFC 1323) 将窗口扩展至约 1 GB。
3. 工作机制:动态调节发送速率
-
接收方在每次发送 ACK 时,附带当前接收窗口大小(rwnd)
-
发送方根据该值,限制未确认数据总量 ≤ rwnd; 即:
LastByteSent - LastByteAcked ≤ rwnd -
若 rwnd = 0:
-
发送方暂停发送新数据
-
启动坚持定时器(Persist Timer),定期探测窗口是否恢复
-
示例:
-
接收缓冲区总大小:64 KB
-
已接收但未被应用读取的数据:40 KB
-
→ 剩余空间 = 24 KB → 窗口大小 = 24576
-
发送方最多只能发送 24 KB 未确认数据
4. 窗口为零的特殊情况:零窗口(Zero Window)
当接收缓冲区满时,接收方通告 window = 0 ,发送方必须停止发送。但若此后接收方应用读取了部分数据,窗口恢复,此时却因网络原因导致接收方通告窗口恢复的ACK 丢失,发送方将永远等待接收方的窗口恢复ACK。
解决方案:坚持定时器(Persist Timer)
-
发送方定期发送 仅含 ACK 的探测报文(Zero Window Probe)
-
接收方回复当前真实窗口大小
-
从而打破死锁
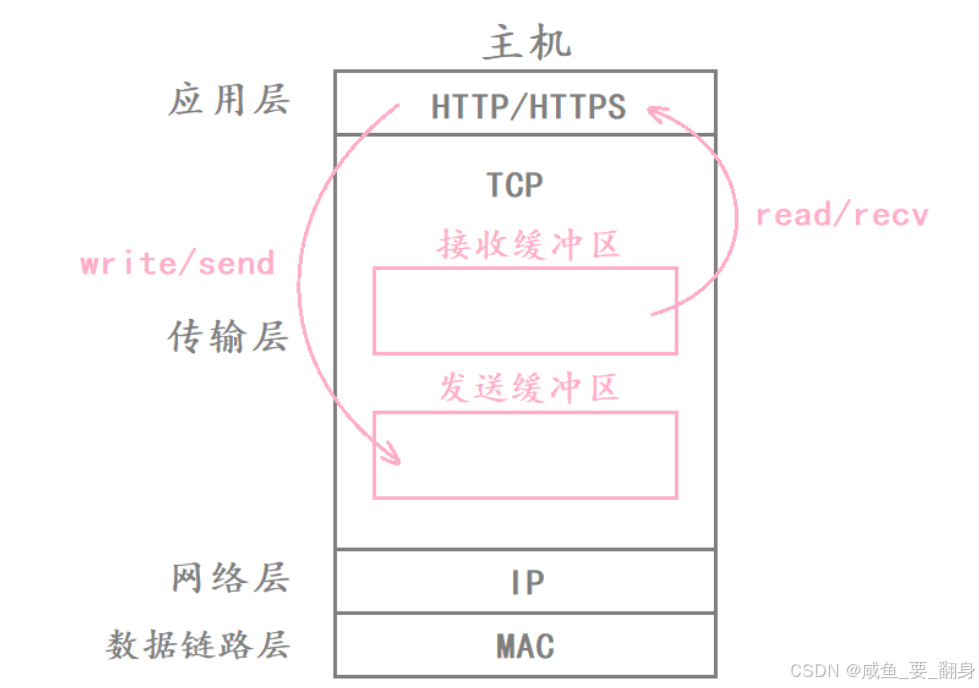
6、系统调用与缓冲区的关联
| 系统调用 | 行为 | 阻塞条件 |
|---|---|---|
write(fd, buf, len) |
将数据拷贝到发送缓冲区 | 发送缓冲区满(且 socket 为阻塞模式) |
read(fd, buf, len) |
从接收缓冲区拷贝数据到用户空间 | 接收缓冲区为空(且 socket 为阻塞模式) |
非阻塞模式下 :若条件不满足,函数立即返回 -1 并置 errno = EAGAIN / EWOULDBLOCK
7、总结:缓冲区与窗口的协同价值
| 组件 | 功能 | 所属机制 |
|---|---|---|
| 发送缓冲区 | 暂存待发/未确认数据 | 可靠性 + 重传基础 |
| 接收缓冲区 | 暂存已收/未读数据 + 乱序重组 | 可靠性 + 流量控制基础 |
| 窗口大小字段 | 通告接收能力 | 流量控制(Flow Control) 的核心信号 |
核心思想 :TCP 通过缓冲区 + 窗口通告 ,实现了端到端的自适应速率匹配------发送方"看接收方脸色行事",既避免压垮对方,又最大化利用可用带宽。
8、延伸思考
-
窗口 vs 拥塞窗口(cwnd)
-
接收窗口(rwnd):由接收方能力决定(流量控制)
-
拥塞窗口(cwnd):由网络状况决定(拥塞控制)
-
实际发送上限 = min(rwnd, cwnd)
-
-
**滑动窗口协议:**窗口机制是"滑动窗口协议"的具体实现,允许连续发送多个未确认报文,大幅提升吞吐。
-
**性能调优:**在高带宽延迟积(BDP)网络中(如卫星链路),需增大缓冲区和窗口,否则无法打满带宽。
理解 TCP 缓冲区与窗口机制,就掌握了流量控制的灵魂,也为深入理解拥塞控制、高性能网络编程奠定了坚实基础。
五、TCP 六大标志位
1、为什么要存在标志位?
在 TCP 通信的世界里,报文的种类繁多。除了传输数据的"普通快递",还有建立连接的"握手信封"、断开连接的"告别信"以及处理紧急情况的"警报单"。
**核心逻辑:**不同的报文对应着不同的处理逻辑。操作系统内核需要知道:收到的这个包,是应该交给应用程序处理数据,还是应该由内核自己执行"握手"或"断连"动作?
为了区分这些报文的种类,TCP 报头中设计了 6 个标志位(Flags) 。它们就像报文的"身份标签",每个标志位只占 1 个比特(bit) 。0 表示假(关闭),1 表示真(开启)。
2、TCP 六大标志位详解
这六个标志位各司其职,共同保障了 TCP 连接的建立、可靠传输、流量控制和连接终止。
1. 建立连接:SYN (Synchronize)
-
含义: 同步序列号。
-
作用: 它是连接建立的"发起者"。当 SYN=1 时,表明这是一个连接请求报文。
-
场景: 只有在 连接建立阶段(三次握手) 才会被设置。正常通信传输数据时,SYN 不会被设置。
-
细节: 客户端发送 SYN 包给服务器,携带一个随机的初始序列号(ISN),目的是让双方同步一下"计数器",以便后续按序传输。
2. 确认应答:ACK (Acknowledgment)
-
含义: 确认收到。
-
作用: 对收到的报文进行确认。只要 ACK=1,确认号(Acknowledgment Number)字段就有效。
-
场景: 这是出现频率最高的标志位。 除了三次握手中的第一个 SYN 包(因为此时还没有收到对方数据,无需确认),其余绝大多数报文(包括握手的后两步、数据传输、挥手)都会设置 ACK。
-
补充: TCP 支持"捎带应答"机制,即发送数据的同时,可以顺便把刚才收到数据的确认信息一起发回去,提高效率。
3. 终止连接:FIN (Finish)
-
含义: 结束传输。
-
作用: 表明发送方已经没有数据要发送了,希望释放连接。
-
场景: 只有在 连接断开阶段(四次挥手) 才会被设置。
-
细节: FIN=1 代表着一种"优雅"的关闭。它告诉对方:"我数据发完了,准备关了,但你还有数据要发的话,我还能接着收。"这保证了数据不会丢失。
4. 紧急数据:URG (Urgent)
在网络通信过程中,TCP协议通过序号机制确保数据的有序传输。即使发送端将数据分割成多个TCP报文段发送,接收端也能根据报文序号重新排序,确保数据最终按序到达接收缓冲区。这种有序传输机制是TCP的核心特性,接收端上层应用同样需要按顺序读取数据。然而,当发送端需要传输"紧急数据"并要求接收端优先处理时,就需要使用特殊的机制。此时需要借助TCP报文头中的URG标志位和16位紧急指针。当URG标志位设为1时,16位紧急指针用于定位紧急数据的位置;通常情况下,这个指针无需关注。紧急指针表示的是紧急数据在报文段中的偏移量。
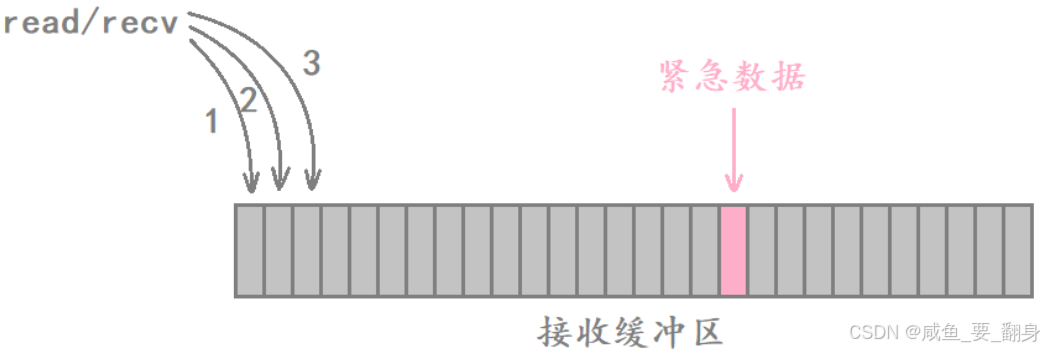
-
含义: 紧急指针有效。
-
作用: 告诉接收方,数据中包含"紧急数据",不要按部就班排队,要优先处理。
-
机制: 当 URG=1 时,TCP 报头中的"16位紧急指针"字段才有效。该指针会指出紧急数据在数据流中的位置。
-
场景: 比如你在远程登录服务器运行一个大程序,突然想通过键盘输入
Ctrl+C中断它。如果不使用 URG,这个中断指令会排在数据流的末尾(等待很久),而使用 URG 可以让中断指令"插队"立即被处理。 -
注: 在现代网络编程中,URG 的使用相对较少,很多情况下被带外数据(OOB)机制*替代或简化。*
需要注意的是,由于紧急指针只能标识一个位置,因此每次只能发送一个字节的紧急数据(其具体含义我们就不讨论了,了解即可)。
在接收端,可以通过recv函数的MSG_OOB选项(OOB代表带外数据out-of-band)来读取紧急数据,如下:

相应地,发送端也可以通过send函数的MSG_OOB选项发送紧急数据,如下:

5. 立即交付:PSH (Push)
-
含义: 推送数据。
-
作用: 告诉接收端的 TCP 协议:"别等了,把接收缓冲区里的数据赶紧交给上层应用,不要在缓冲区里堆积。"
-
场景: 交互式应用(如 Telnet、SSH)。当用户每敲入一个字符,都希望对方立即响应,而不是等待缓冲区填满再发送。
-
**深度解析(缓冲区水位线):**为了减少操作系统在内核态和用户态之间频繁切换的开销,TCP 接收缓冲区通常有一个"水位线"机制。
-
默认情况: 数据到了接收方会先在缓冲区"攒一攒",等数据量达到一定阈值(水位线)再一次性交给应用层。
-
PSH=1 时: 就像快递员按了"催促铃",强制接收方立刻将缓冲区数据交付给应用层,无需等待水位线。
-
关于数据读取机制,存在一个常见误解:通常认为调用read/recv函数时,只要接收缓冲区中有数据就能立即返回,若缓冲区为空则会阻塞等待。然而实际情况更为复杂,TCP接收缓冲区和发送缓冲区都设有水位线机制。
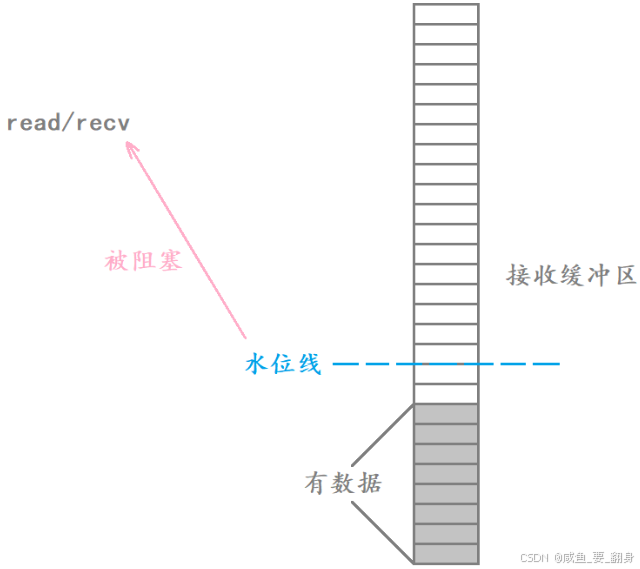
举例说明: 假设TCP接收缓冲区的水位线设置为100字节,那么只有当缓冲区中累积达到100字节数据时,read/recv函数才会读取并返回这些数据。这种设计避免了频繁的数据读取操作(每次内核态与用户态切换都会带来性能开销),从而提升整体读取效率。
因此,read/recv函数的返回并非简单地取决于缓冲区是否为空,而是需要达到预设的数据量阈值。当PSH标志位被置为1时,即使缓冲区数据未达水位线,接收方操作系统也会优先将现有数据交付给上层应用。这也解释了为什么read/recv函数实际读取的字节数可能与预期值存在差异。
6. 重置连接:RST (Reset)
-
含义: 重置连接。
-
作用: 用于异常情况下的强制断开或拒绝连接。
-
场景:
-
拒绝非法连接: 当客户端向服务器发送一个 SYN 请求,但服务器对应端口并没有服务在监听,服务器会直接返回一个 RST=1 的包,拒绝建立连接。
-
连接已失效: 通信中途,一方(如服务器)崩溃重启了,另一方(客户端)还保持着旧的连接状态。当客户端再次发数据给服务器时,服务器发现这个连接"不认识",就会回一个 RST,要求对方重新建立连接。
-
防御与重置: 防火墙常利用 RST 来中断不希望的连接。
-
3、标志位速查表
| 标志位缩写 | 中文含义 | 核心作用 | 典型触发场景 |
|---|---|---|---|
| SYN | 同步序列号 | 发起连接请求 | 三次握手的第一步 |
| ACK | 确认应答 | 确认数据已收到 | 除第一次握手外,几乎伴随所有报文 |
| FIN | 连接结束 | 请求断开连接 | 四次挥手阶段,数据发送完毕 |
| RST | 连接重置 | 异常断开/拒绝连接 | 端口未开放、连接状态不一致 |
| PSH | 数据推送 | 立即交付数据 | 交互式应用(如 SSH),要求实时响应 |
| URG | 紧急数据 | 标记高优先级数据 | 需要插队处理的控制指令(较少用) |
4、补充要点
1. 关于 URG 的补充
-
上面提到"紧急指针只能标识一个位置,因此紧急数据只能发送一个字节"。
-
这在早期的 BSD 实现中确实如此,紧急指针指向的是紧急数据的最后一个字节。
-
但在实际应用中,URG 机制比较复杂,且不同操作系统的实现(如 Linux 和 Windows)对紧急数据的处理方式(是包含在数据流中还是带外传输)存在差异。
-
因此,在现代网络编程中,URG 很少被直接使用,更多是依赖应用层协议自己定义"优先级"字段。
2. PSH 的双向性
-
PSH 标志位是双向的。不仅客户端可以发给服务器(比如敲命令),服务器也可以发给客户端(比如回显命令结果)。
-
只要发送方希望接收方尽快处理数据,就可以设置 PSH。
3. 组合拳
**这些标志位不是互斥的,经常组合出现。**例如:
-
SYN + ACK: 这是三次握手中服务器对客户端 SYN 包的响应,表示"我收到了你的请求,并同意建立连接"。
-
FIN + ACK: 在四次挥手中常见,表示"我同意关闭连接"并确认之前收到的数据。
通过理解这六个标志位,你就掌握了 TCP 协议控制流的核心"语言"。它们就像是 TCP 连接的"指挥官",指挥着数据如何可靠、有序地到达目的地。