一、前言
在数据驱动的时代,企业每天被PDF、财报、合同、研究报告等海量文档所淹没。这些非结构化的多模态数据中蕴藏着关键业务洞察,却因格式复杂、版式多样、信息分散,成为难以开采的暗数据。研究人员仍需逐页翻查论文,分析师依旧通宵解析百页报表------传统处理方式不仅效率低下,更在规模面前显得无力。
随着大模型的普及,许多人期待它能自动化解这一困境。然而现实却揭示出一个严峻挑战:即使是当前最先进的视觉大模型,在面对复杂版式文档、混排图表与密集文本时,其识别准确率仍与专业非结构化数据处理工具存在显著差距。
一项全面测评显示,通过在多个OCR方法中探索中小模型的参数量、计算量、数据量对于精度的影响,成功证明了OCR领域在这三个维度存在Power-Law规律。
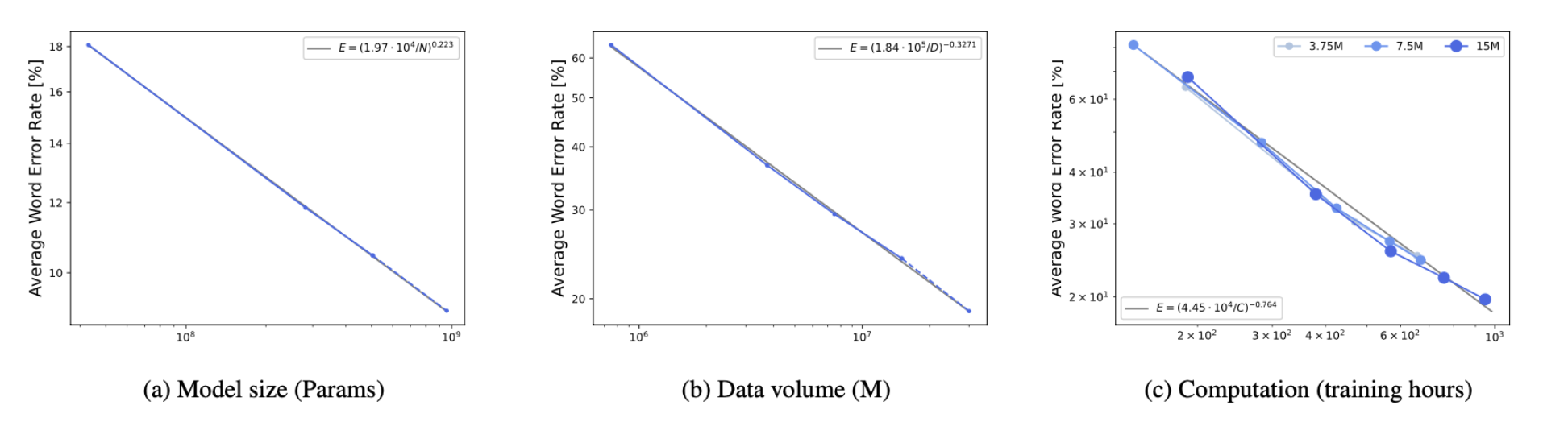

这些研究成果表明,OCR技术在提升多模态大模型性能方面发挥着关键作用,尤其是在处理复杂的视觉问答任务时。我们的工作不仅推动了OCR技术的发展,也为多模态大模型的应用提供了新的视角。
正式研究人员的不断努力**,EasyLink团队** 致力于从数据源头破解这一难题。通过行业领先的智能文档解析与图表理解技术,为多模态大模型提供清洁、结构化、可溯源的高质量输入,从根本上降低幻觉风险,释放AI在知识挖掘与智能决策中的真实潜力。
若想直接体验API调用请跳转到第五章节
二、智能文档解析与抽取技术在金融行业的应用
2.1 传播背景
在现代银行的运营中,非结构化数据和多模态数据以其庞大而复杂 的形式占据着主要的信息空间。这包括跨页的企业报表、模糊的扫描凭证、不清晰的流水账单,以及带有图表的研究报告和带公章的合同文件。大多数银行仍旧依赖手工处理这些数据,导致效率低下、信息提取存在较大误差,并且加剧了合规审核的风险。
在AI技术快速发展的时代,银行业亟需一种可持续的解决方案以实现对多模态数据的全面解析、结构化和管理,从而提升合规性、客户支持以及数据分析的水平。在这样一个背景下EasyLink横空出世。
2.2 智能文档解析
在银行业信息处理中,处理复杂跨页的企业报表、模糊的扫描件和多模态图文文件一直是挑战。EasyLink的智能文档解析技术通过其尖端的多模态视觉大模型实现了这一过程的自动化。
【企业报表】
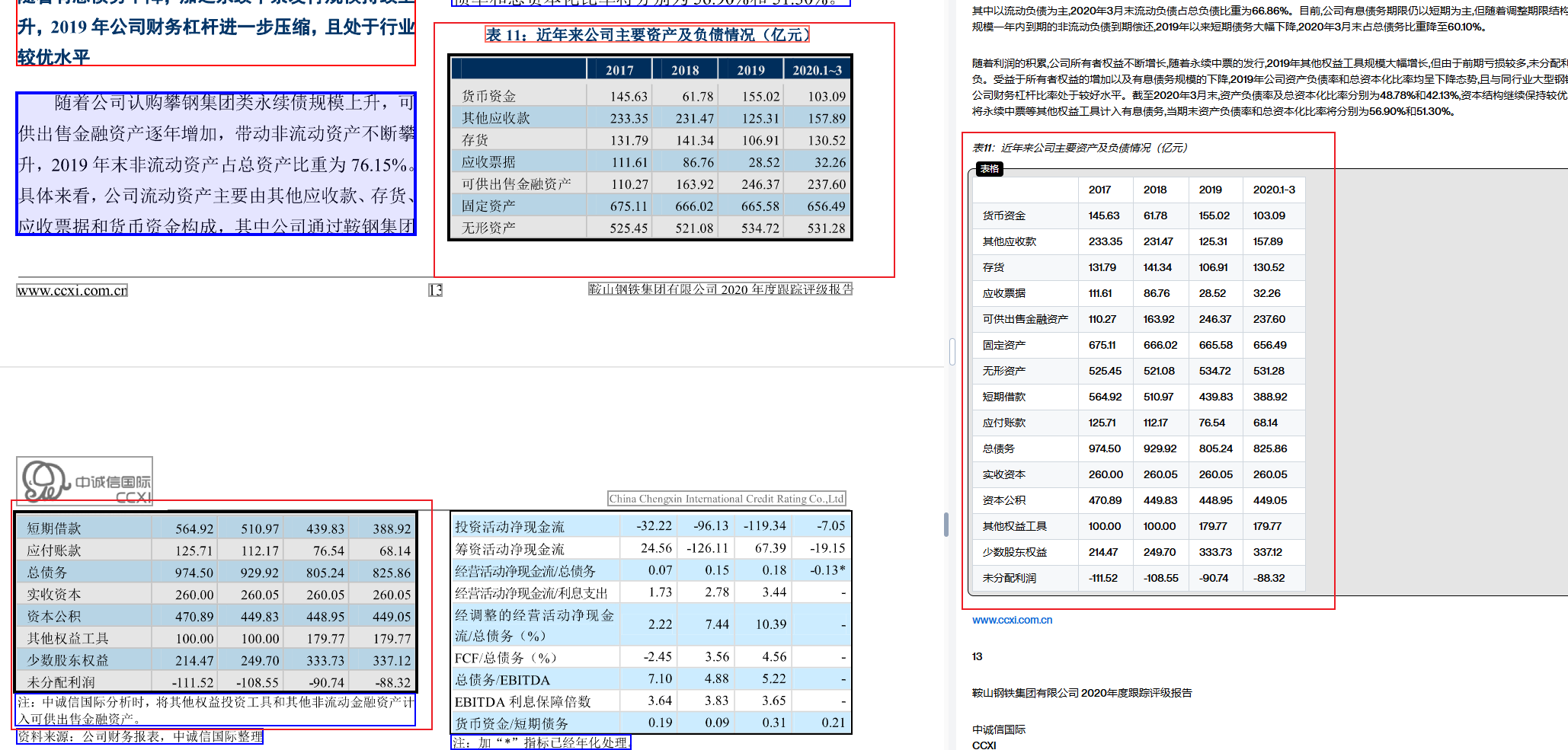
EasyLink支持复杂跨页表格的一键解析,能够在瞬间将非结构化的报表推导出结构化数据,确保数据完整无遗漏且无需手动拼接。
- 左侧原始图 :这是一个复杂的跨页表格 ,内容包括近年来公司主要资产及负债情况。这种表格常见于企业报表中,通常需要人工拼接和确认数据的完整性。
- 右侧解析后图:经过智能文档解析,表格被完整还原为结构化数据。EasyLink的技术实现了跨页表格100%的还原率。这种转换可以大大提高数据处理效率,减少人工操作的工作量。
【企业凭证】
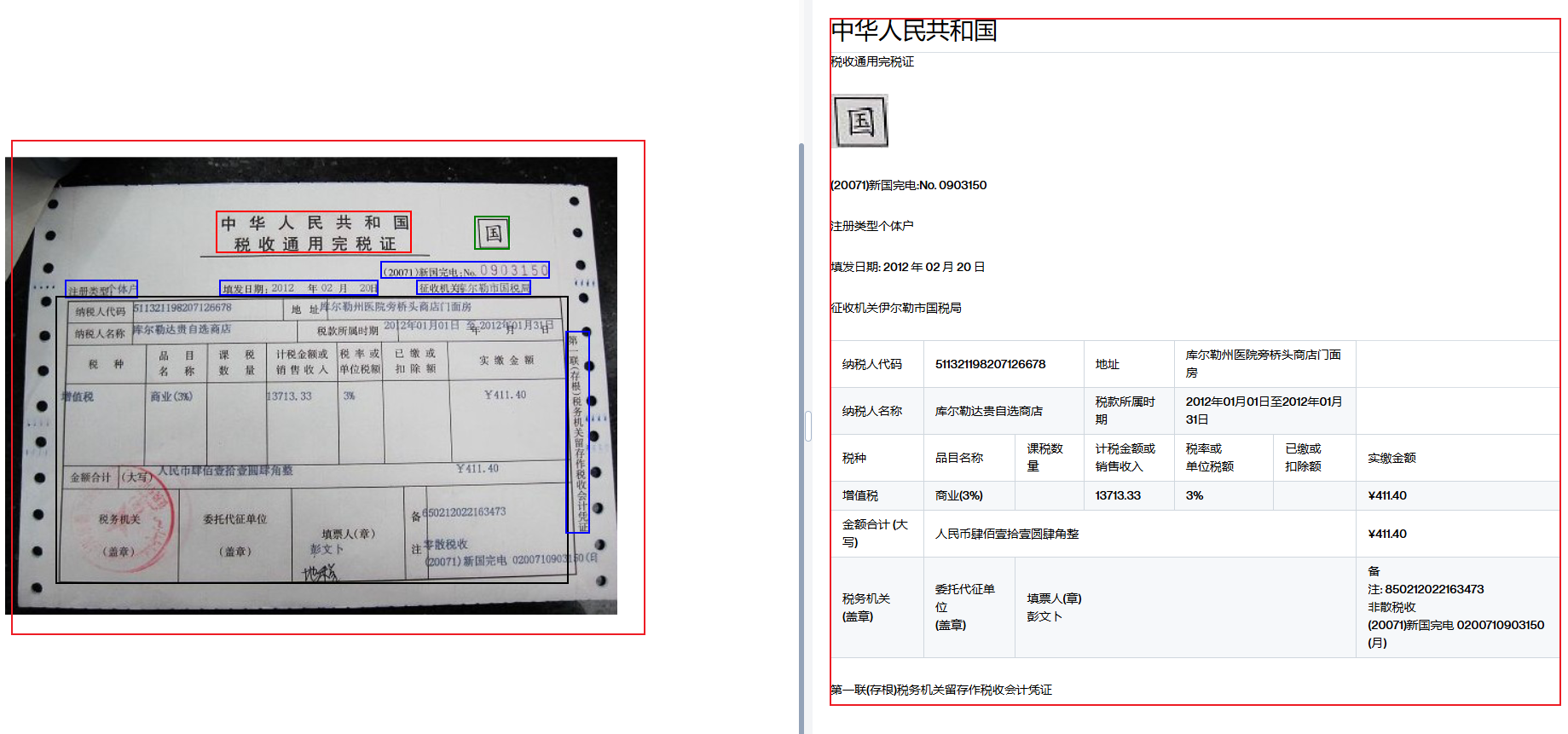
针对扫描件,EasyLink实现了文字、数字、格式的精准识别以保证凭证归档和理赔审核的严密性。这就像将模糊的扫描件重现为清晰的电子文档。
- 左侧原始凭证 :显示了一份扫描的税务完税证明,纸质凭证易受环境影响,信息容易被遮挡或模糊。
- 右侧解析后的结果 :通过EasyLink的技术,所有重要信息如文字、数字和格式都被精准识别并转化为清晰的电子文档。这样不仅方便归档,还能支持快速的理赔审核。
【流水处理】
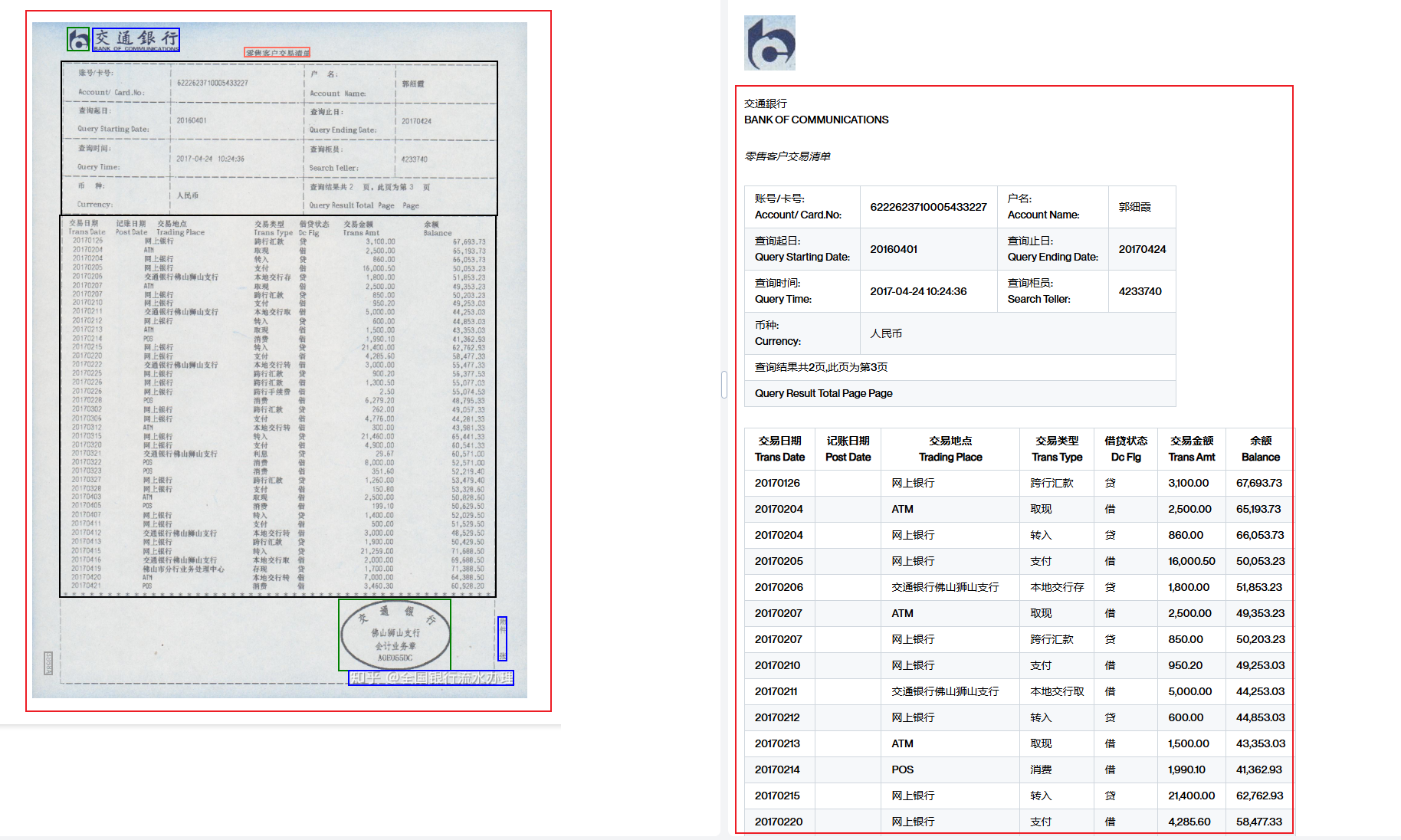
系统能够解析不清晰的流水表格,精准提取数值与交易信息,极大地方便了财务核算和银行客户的对账需求。
- 左侧原始流水表格 :这是一个银行流水的扫描件,纸质文件可能会因多种因素导致模糊不清,给数据提取带来难度。
- 右侧解析后的结果 :通过系统处理,所有交易信息和数值被精准提取并以结构化形式呈现。这样改进极大地方便了财务核算和银行客户对账需求。
【研究报告】
在报告中,EasyLink通过分析图表数据逻辑,将这些信息快速转化为结构化数据,从而给银行的决策提供实质性的数据支持。
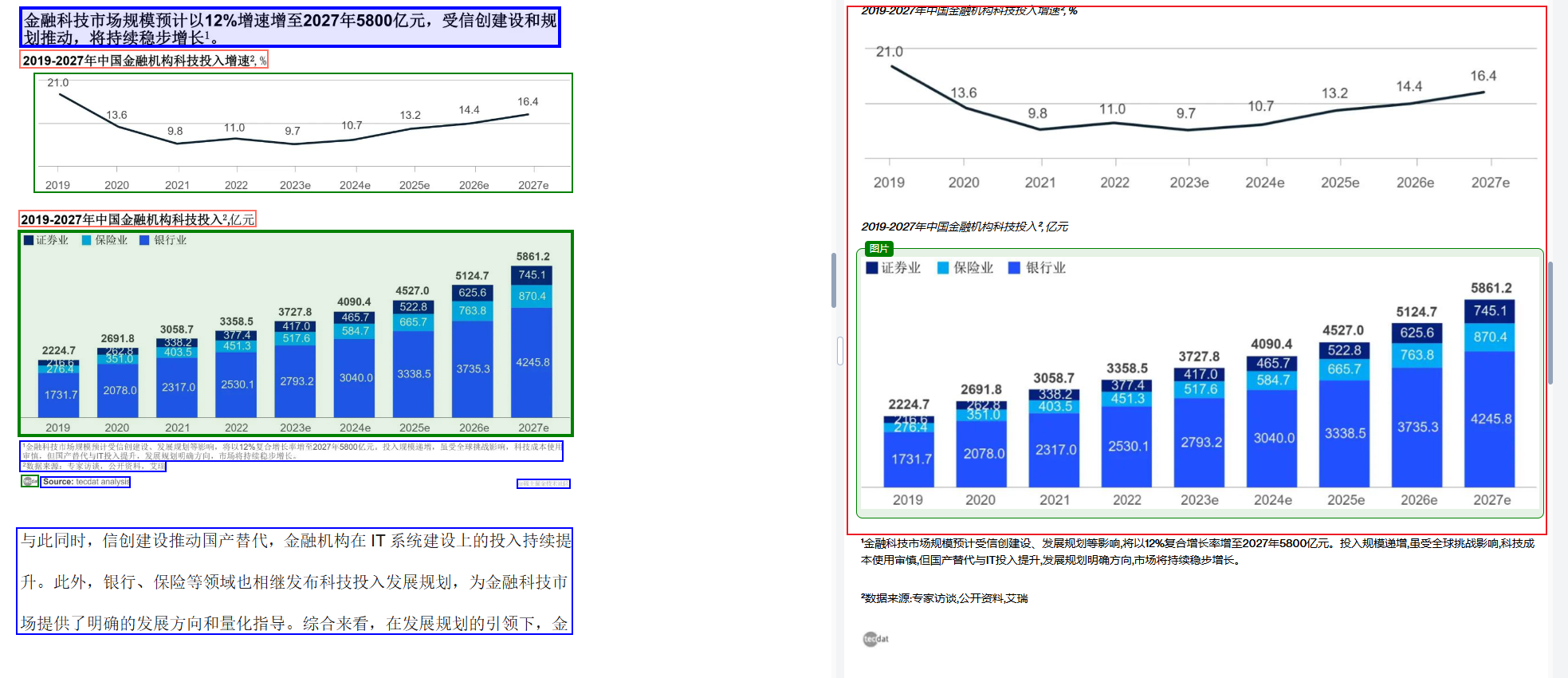
- 左侧原始报告 :包含预测市场规模和金融机构科技投入的数据图表。这些数据图表在纸质或PDF格式中可能难以直接用于分析。
- 右侧解析后的结果 :通过EasyLink,图表数据被快速转化为结构化数据,使信息更易于解读和使用。同时,这种处理为银行的决策提供了实质性的支持,帮助在战略规划上做出更精准的判断。
2.3 智能文档抽取
【合同处理】
下方展示的案例是关于如何处理那些原本难以辨认的合同扫描件。即使原始文件模糊不清 ,这个系统也能准确提取其中的文本和公章信息,并将它们转换成结构化的、清晰的数据格式。
此外,用户还可以自由设置需要的字段类型 ,并根据需求添加新的字段 。这种灵活的处理方式,使得原本难以阅读的合同信息变得简单易用,大大提高了工作效率。
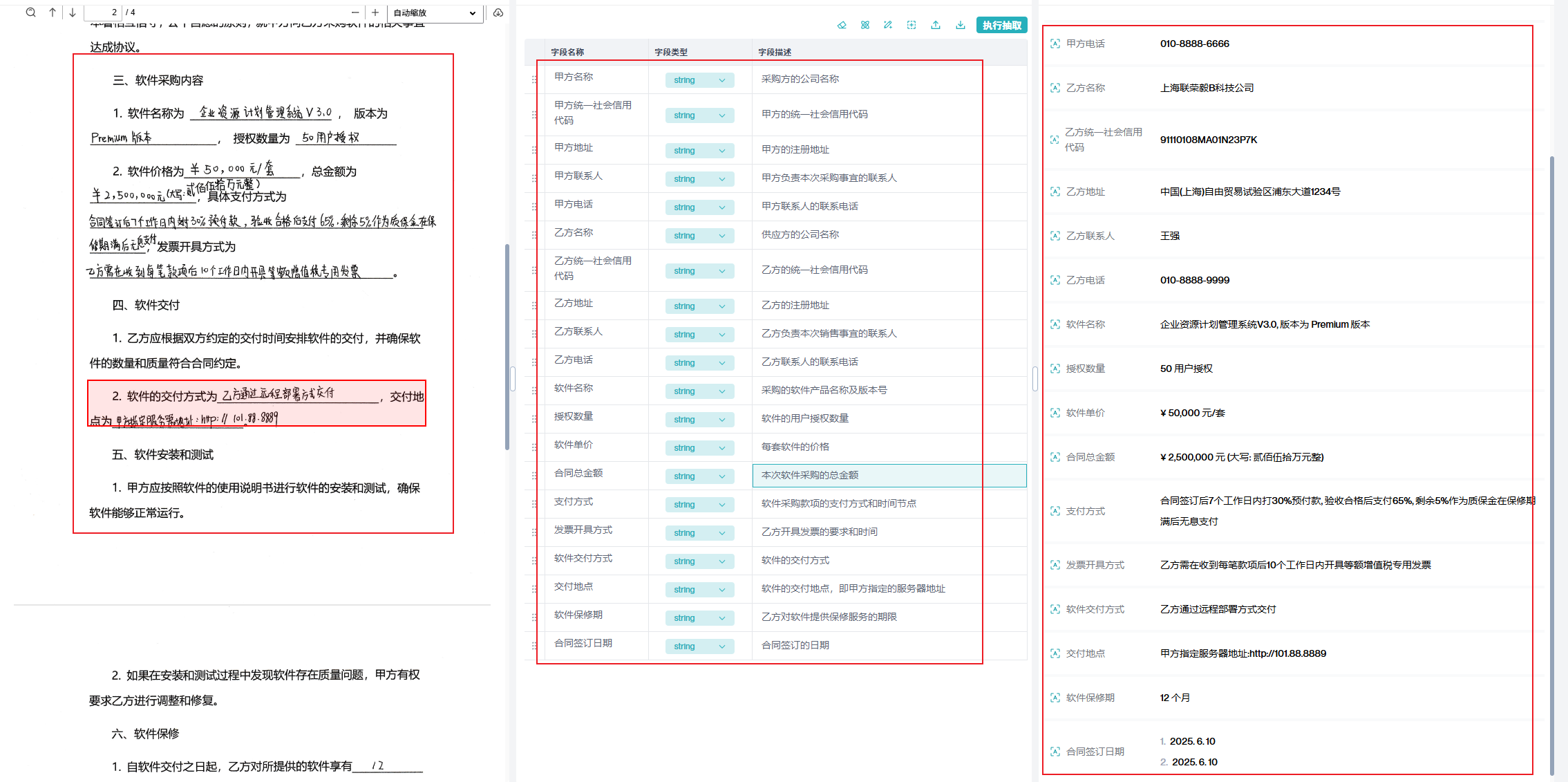
下方为案例演示:上传-》字段识别-》抽取
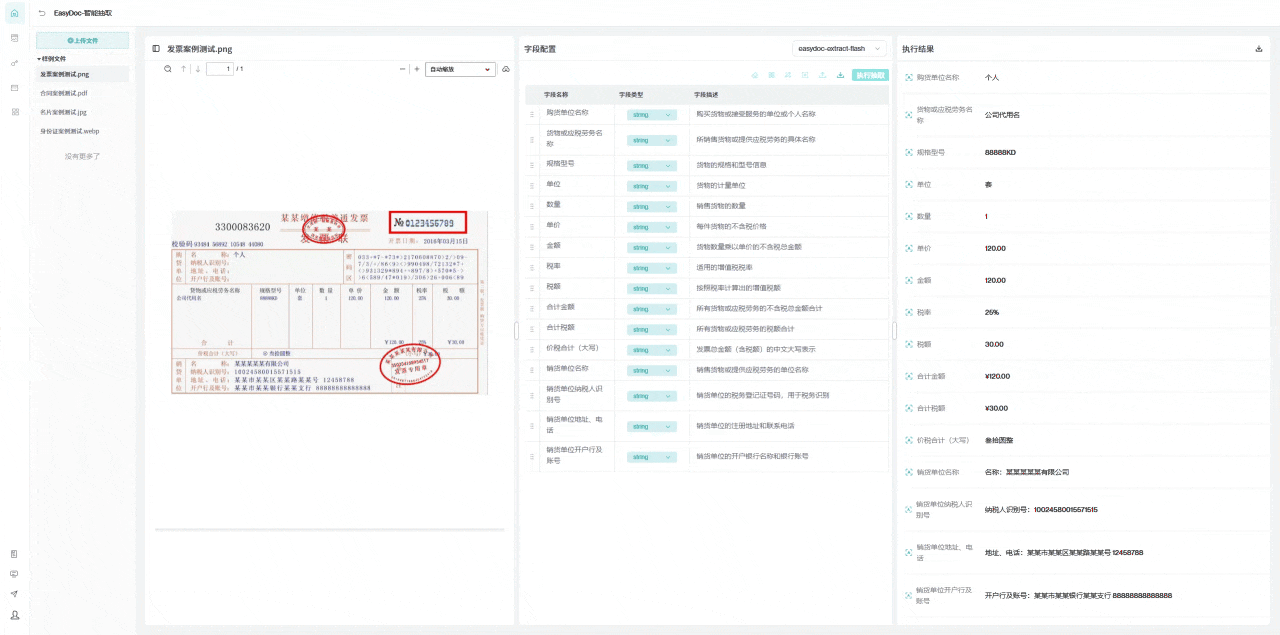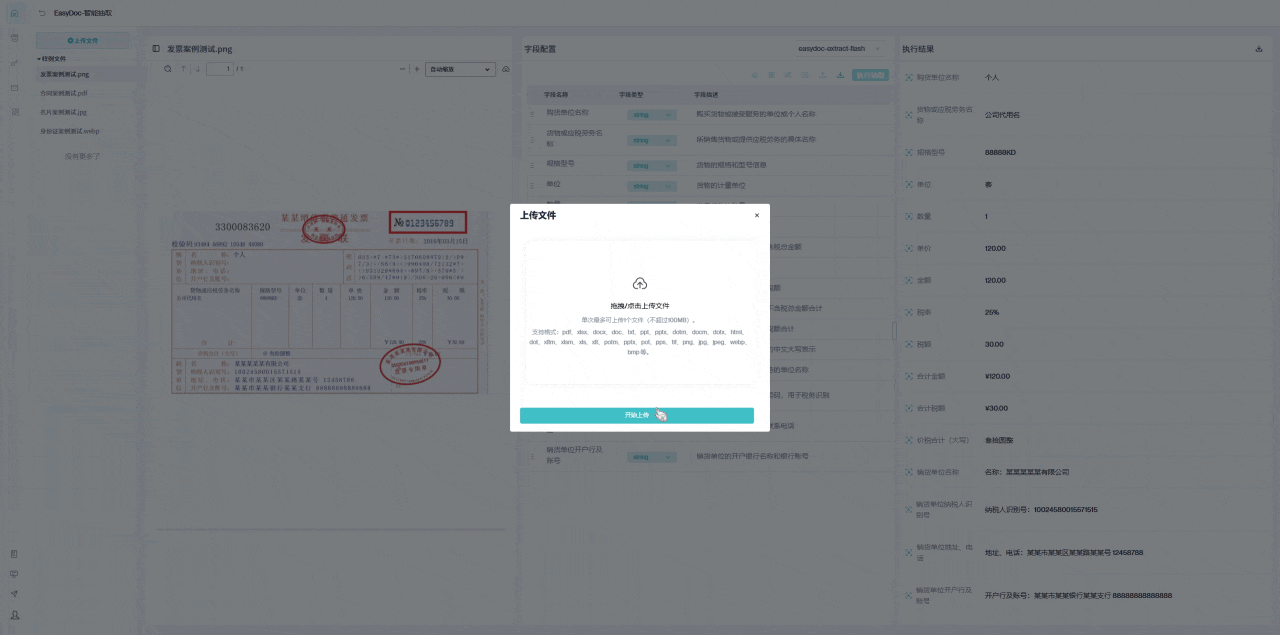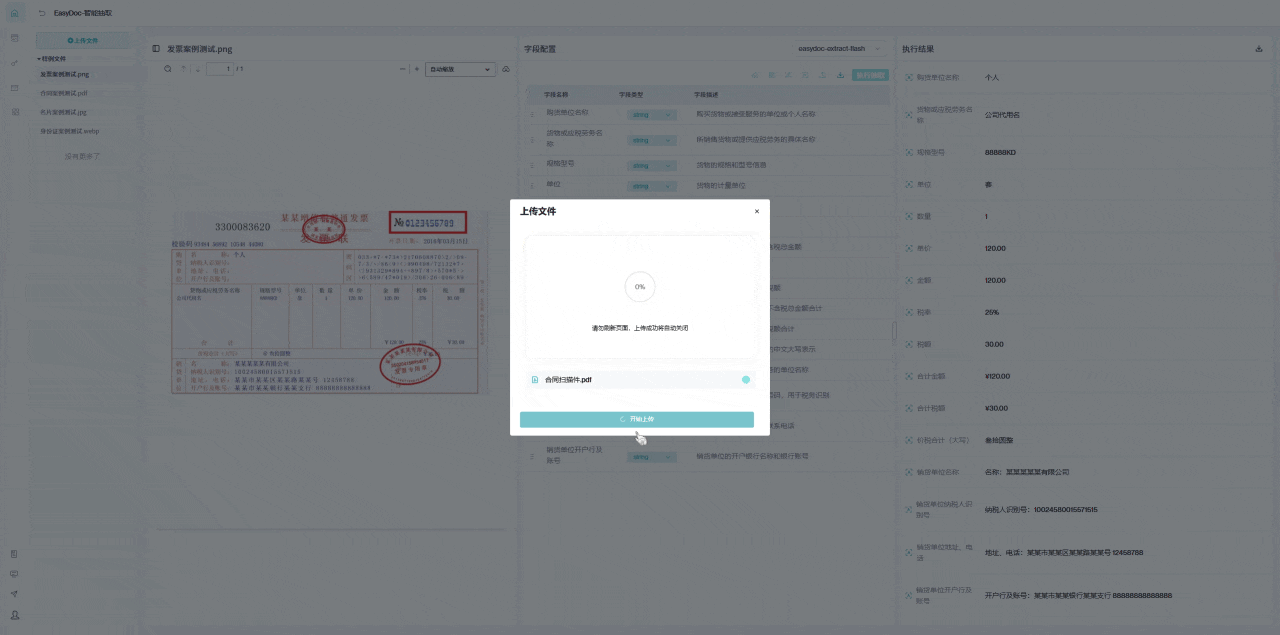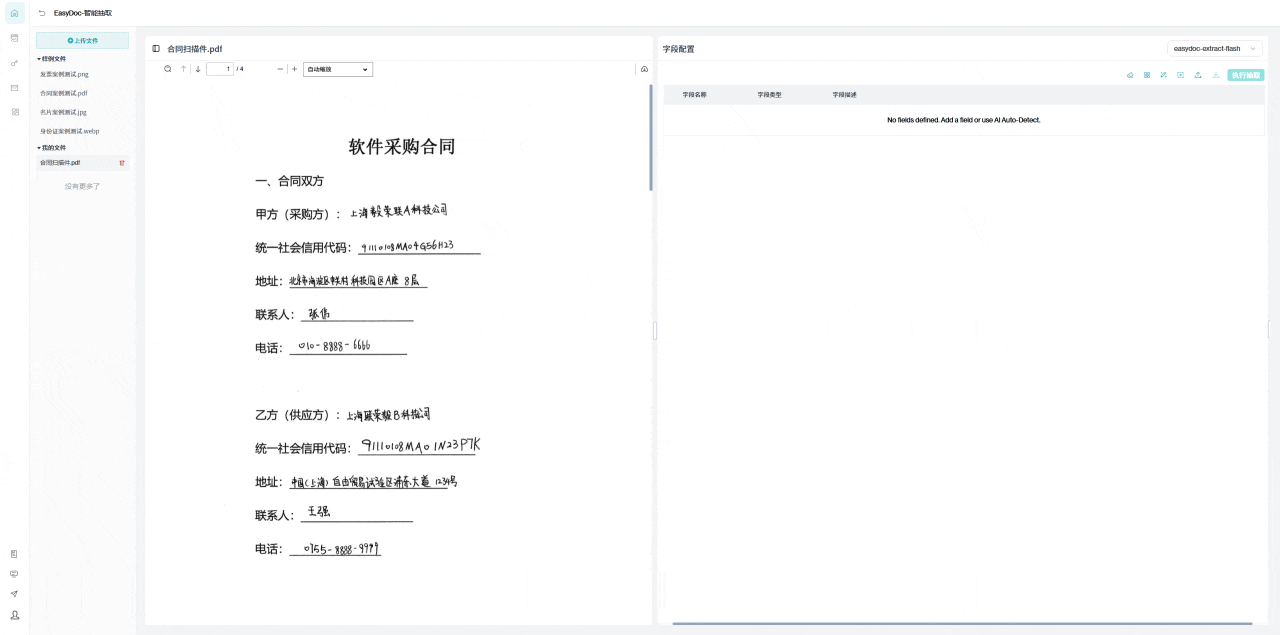

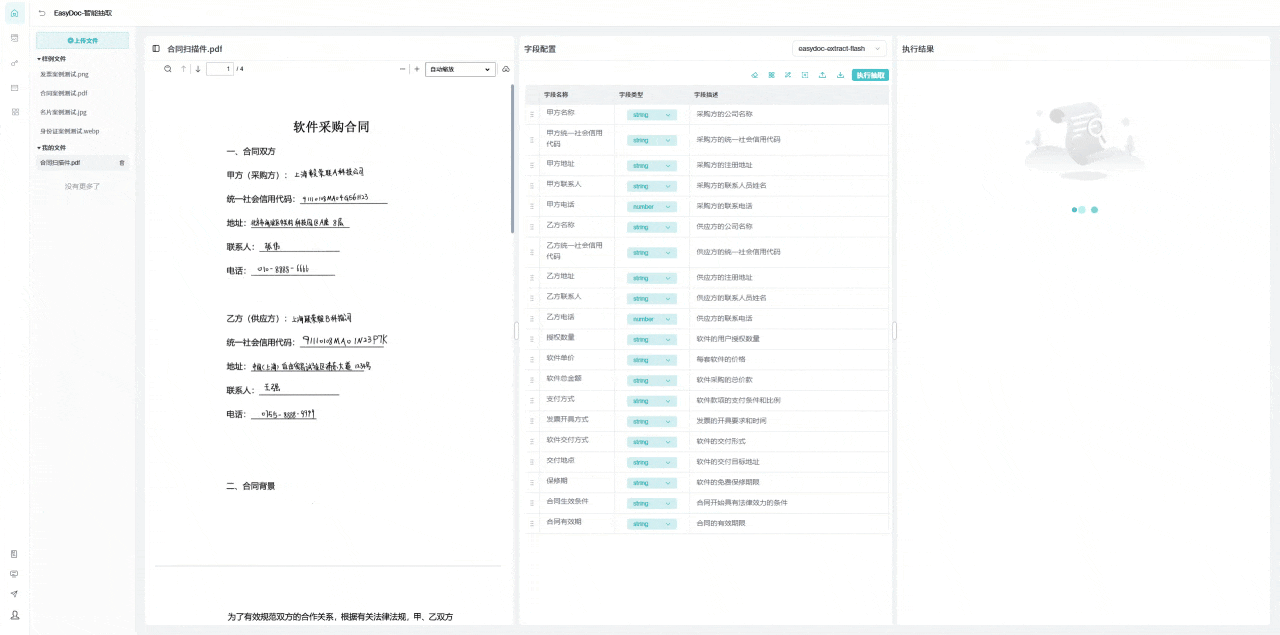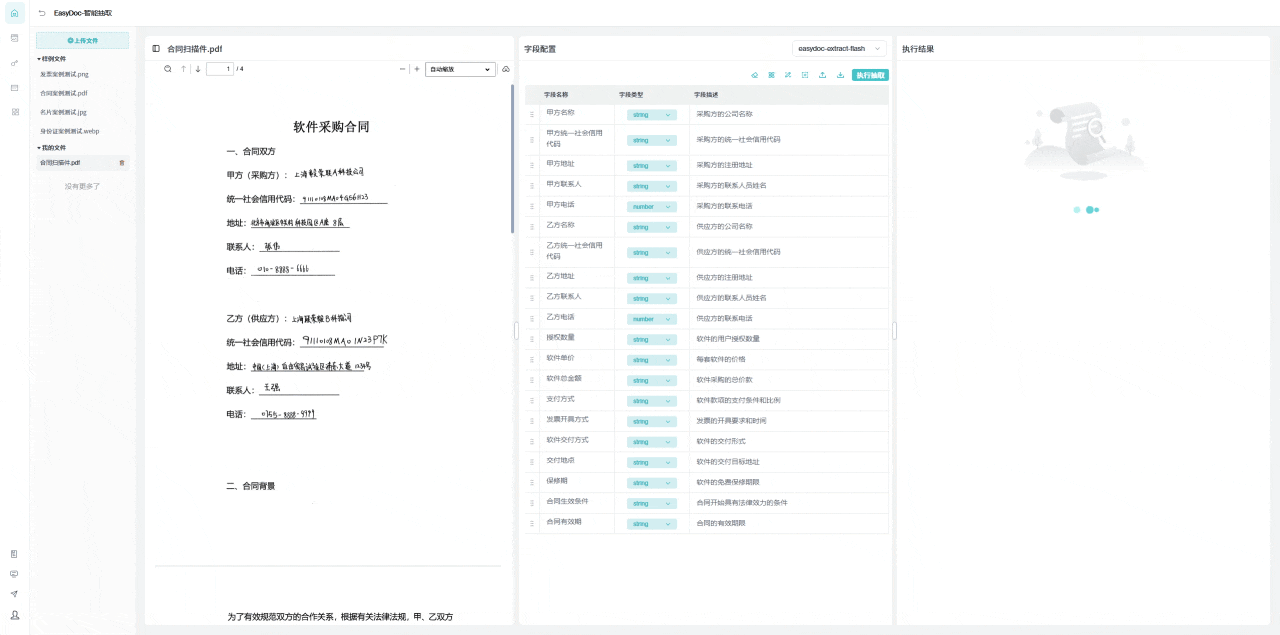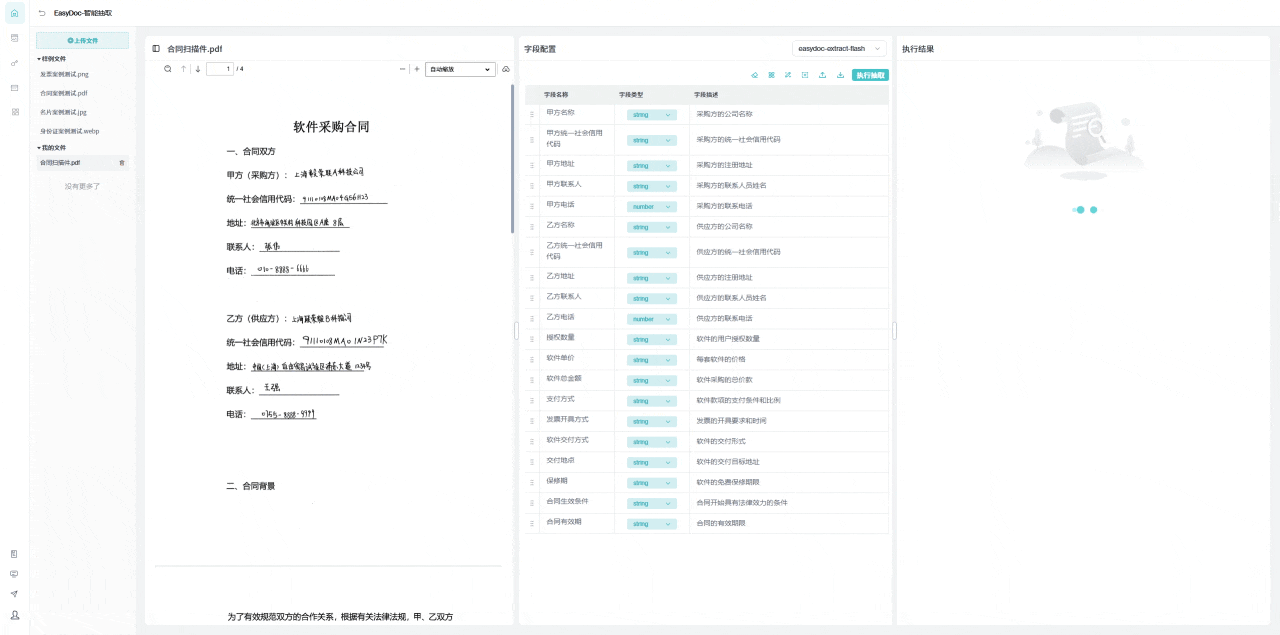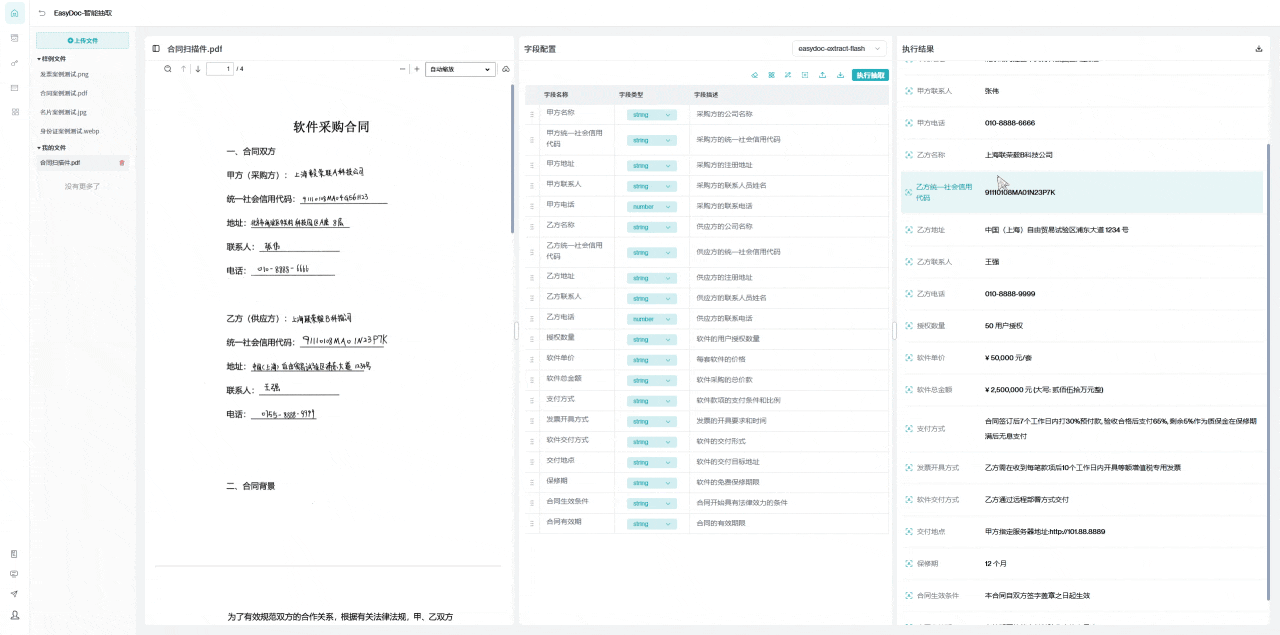
对于银行和金融机构来说,这种技术带来了显著的优势。借助自动化的合同解析和信息抽取系统,金融机构能够快速进行合规性审核和风险评估。这不仅减少了人工错误,还加速了审批流程,同时确保数据的准确性和一致性,提高了整体运营效率。
三、技术优势:不止于识别,更在于理解与信任
为了更直观地展示通用视觉大模型、传统 OCR 方案与 EasyLink 的专用文档解析模型 在论文解析上的差异,我选择了大家熟悉的豆包作为对比对象。 我将同一篇论文分别喂给它们,并从文本、表格、图片三类典型元素进行效果评测与展示,对比它们在下面三个维度上的表现
- 关键信息提取完整度
- 结构化还原能力
- 可直接用于下游任务的友好程度
3.1 通用视觉大模型
豆包相信大家都不陌生,,通用视觉大模型这里我选择豆包,我将论文喂给大模型,看看是否能为我提取相关内容
通过文本、表格、图片三方面进行展示对比
【首先是文本】
1. 关键信息提取完整度
- 能识别出大部分正文内容,但输出以概括为主,缺少对模型名称、任务、数据集、关键指标等细粒度信息的逐项抽取,更偏向总结。
2. 结构化还原能力
- 结果是自然语言段落,没有保留原句级结构,无法直接形成可用的结构化文本数据。
3. 下游任务友好程度(检索/问答等)
- 后续若要做精确检索或基于字段的问答,需要再次从生成的自然语言中二次抽取,链路长、稳定性不足,不够适合作为即用型数据源 。

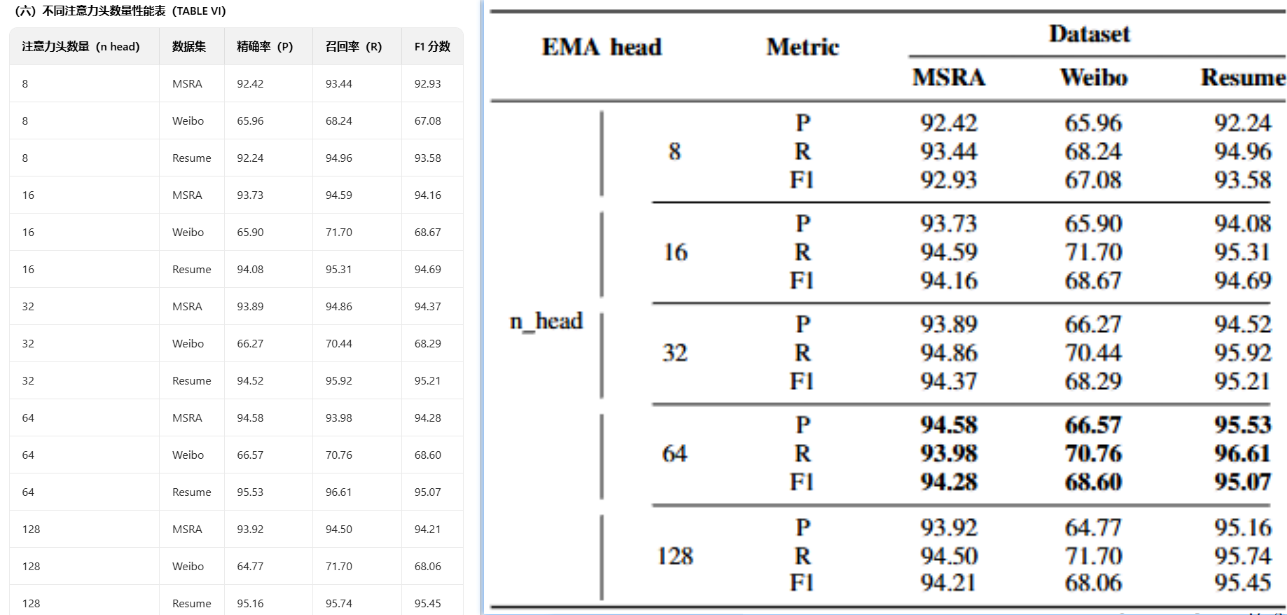
【表格】
1. 关键信息提取完整度
- 表格中的数字和文字内容基本都能识别,但因为结构错位,关键信息n_head 与各项 P/R/F1 指标的对应关系在语义上是不完整的。
2. 结构化还原能力
- 与原文格式不一致,行列对齐不稳定,存在单元格误合并/误拆分的问题,导致表头和数据行之间的逻辑结构被破坏。
3. 下游任务友好程度(检索/问答等)
- 无法直接用于数值检索、排序或自动分析。
1. 关键信息提取完整度
- 能识别出这是一个包含 RoBERTa、BiLSTM、CRF 等模块的实体识别模型,但对所有模块、子模块以及细节说明的覆盖不完整。
2. 结构化还原能力
- 识别不出图片,仅能做简单的总结。
3. 下游任务友好程度(检索/问答等)
- 输出偏向解释性文本,不适合直接作为结构化输入等任务。
3.2 传统OCR方案
下面这张图是一个传统OCR的小案例,不难看出,识别出来的文本从格式,或者内容准确性来讲都不稳定,适用于那些小段文本
- 格式结构严重丢失
- 内容准确性不稳定
- 适用场景受限
这三个问题是传统OCR的主要问题

若换成表格或图片结构图,问题会更突出。 如图所示,左侧是模型结构示意图,右侧是传统 OCR 的识别结果,可以看到:
- 只抓到了零散文字,完全丢失结构关系
- 识别错误率高,可读性很差
- 完全不能支撑下游结构化任务
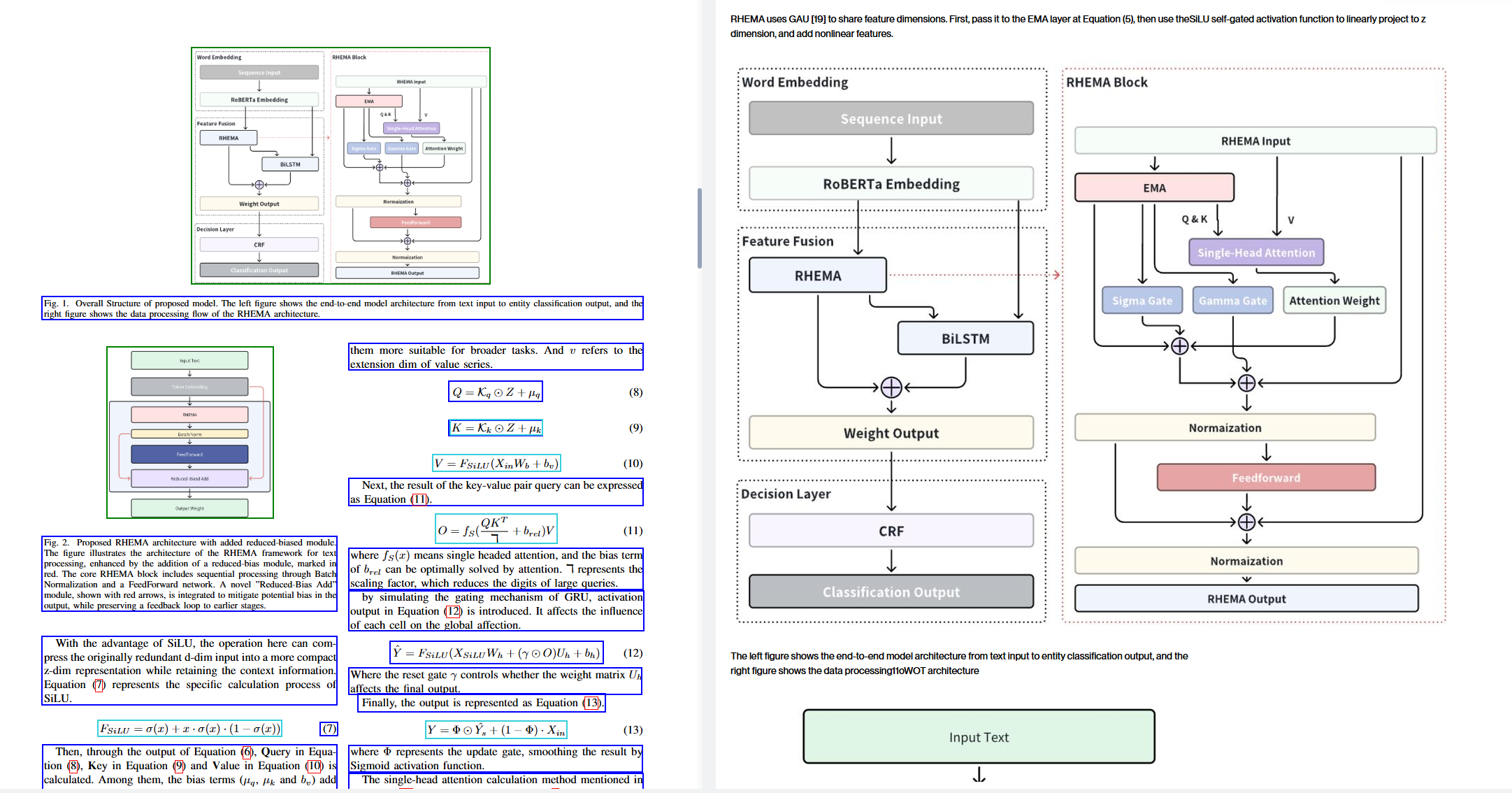
3.3 EasyLink 的专用文档解析模型
如图左侧所示,原始 PDF 中包含标题、作者、机构、摘要、关键词和正文多个区域。
传统 OCR 仅能输出一串连续文本,而 EasyLink 的文档解析模型会先做版面分析,再逐块解析:
- 自动分块与标签化
-
- 精确检测标题、作者信息、脚注、摘要、正文等不同文本块
- 阅读顺序还原
-
- 按照真实阅读顺序重排多栏文本,避免标题插到段落中间的情况
- 高精度字符识别与纠错
-
- 对专有名词、公式编号、引用进行上下文纠错。

【表格】
对于论文中的实验表,如数据集统计表、对比实验表等采用
- 表格区域检测与分割
- 行列结构重建
- 上下文对齐与单位理解
因此,在右图中可以看到:
原文中的表格被解析为带行列头的结构化表数据,而不是一串Datasets Weibo MSRA Resume Class 8 3 8 ...的扁平文本,可直接用于数据统计、可视化与自动分析。

【图片】
对于模型结构图、流程图这类图+字混合区域,EasyLink 不再只做简单 OCR,而是:
- **多对象识别:**检测图中的模块框
- 模块间关系建图: 将识别到的模块视为节点、箭头视为边,恢复模型的拓扑结构(与原图保持一致)
- **文本内容高精度识别:**对图中模块名称采用更高分辨率并结合上下文。
最终效果如右图所示:
EasyLink 输出的结果不仅包含清晰的模块名称,还能保持与原示意图一致的整体结构,可作为后续模型文档、自动化配置或技术解读的直接输入。
|---------------|---------------------|-------------------|-------------------------|
| 维度 | 通用视觉大模型(豆包) | 传统 OCR | EasyLink 文档解析模型 |
| 关键信息提取完整度 | 能看懂并总结,但细粒度字段不全 | 只做逐字识别,错漏多,字段易丢失 | 结合版面+语义,关键字段提取更全、更准 |
| 结构化还原能力 | 输出自然语言,不保留真实结构 | 文本扁平,段落/表格/图结构全丢失 | 还原段落层级、表格行列、图示拓扑等结构 |
| 下游任务友好程度 | 适合阅读和问答,不适合直接做统计/分析 | 需要大量人工整理才能使用 | 结果可直接用于检索、统计、分析和配置生成等任务 |
四、0基础快速上手
账号注册的必不可少的,注册成功后访问访问密钥管理页面,点击创建
随便输入一个名称

温馨提示:保管好你的 API 密钥,切勿在公共仓库或未授权环境中暴露密钥,以确保账户安全
使用REST API主要通过下面两个步骤
- 发起任务:例如通过
POST /v1/easydoc/parse上传文档,创建解析任务。 - 查询任务状态与结果:例如通过
GET /v1/easydoc/parse/{task_id}获取任务状态及解析结果。
下面我编写了一个简易的代码用于调用,这里我数据准备对象是一篇NER领域的论文,下面是进行代码拆解
1. 依赖导入模块
import json
import time
import requests首先导入必要的Python库,用于处理JSON数据、控制时间间隔和发送HTTP请求
2. 提交解析任务模块
def submit_request(file_path, api_key):
api_url = "https://api.easylink-ai.com/v1/easydoc/parse"
headers = {
'api-key': api_key,
}
with open(file_path, 'rb') as file_obj:
files = {
'files': file_obj,
}
data = {
'mode': 'doc-parse-premium', # 选择解析模式
}
response = requests.post(api_url, headers=headers, files=files, data=data)
if response.ok:
result = response.json()
print("任务提交成功。")
return result['data']['task_id']
else:
print("任务提交失败:", response.text)
return None向EasyLink API提交文档解析任务
参数:
file_path: 要解析的文档文件路径api_key: 用户认证密钥
3. 任务状态轮询模块
def check_task_status(task_id, api_key):
status_url = f"https://api.easylink-ai.com/v1/easydoc/status/{task_id}"
headers = {
'api-key': api_key,
}
while True:
response = requests.get(status_url, headers=headers)
if response.ok:
status_data = response.json()
task_status = status_data.get('data', {}).get('status')
if task_status == 'completed':
print("任务已完成,正在检索结果...")
return True
elif task_status == 'failed':
print("任务失败:", status_data.get('data', {}).get('error_message'))
return False
else:
print("检查任务状态失败:", response.text)
return False
time.sleep(5) # 每次检查之间等待功能:轮询检查任务处理状态
参数:
task_id: 任务唯一标识符api_key: 用户认证密钥
4. 获取解析结果模块
def get_task_result(task_id, api_key, output_path):
result_url = f"https://api.easylink-ai.com/v1/easydoc/result/{task_id}"
headers = {
'api-key': api_key,
}
response = requests.get(result_url, headers=headers)
if response.ok:
result_data = response.json()
with open(output_path, 'w', encoding='utf-8') as out_file:
json.dump(result_data, out_file, ensure_ascii=False, indent=4)
print(f"结果已保存到 {output_path}")
return result_data
else:
print("获取结果失败:", response.text)
return None功能:获取并保存解析结果
参数:
task_id: 任务唯一标识符api_key: 用户认证密钥output_path: 结果保存路径
5. 主流程控制模块
def main():
file_path = "" # 请替换为你的文件路径
api_key = "" # 请替换为你的API Key
output_path = "task_result.json" # 输出结果保存路径
# 提交请求并获取任务ID
task_id = submit_request(file_path, api_key)
if task_id:
if check_task_status(task_id, api_key):
get_task_result(task_id, api_key, output_path)
if __name__ == "__main__":
main()功能:程序主入口,协调整个流程
流程:
- 配置必要的参数(需要用户自行填写)
- 按顺序调用三个功能函数
- 条件判断确保流程连贯性
下面为完整代码:
import json
import time
import requests
def submit_request(file_path, api_key):
api_url = "https://api.easylink-ai.com/v1/easydoc/parse"
headers = {
'api-key': api_key,
}
with open(file_path, 'rb') as file_obj:
files = {
'files': file_obj,
}
data = {
'mode': 'doc-parse-premium', # 选择解析模式
}
response = requests.post(api_url, headers=headers, files=files, data=data)
if response.ok:
result = response.json()
print("任务提交成功。")
return result['data']['task_id']
else:
print("任务提交失败:", response.text)
return None
def check_task_status(task_id, api_key):
status_url = f"https://api.easylink-ai.com/v1/easydoc/status/{task_id}"
headers = {
'api-key': api_key,
}
while True:
response = requests.get(status_url, headers=headers)
if response.ok:
status_data = response.json()
task_status = status_data.get('data', {}).get('status')
if task_status == 'completed':
print("任务已完成,正在检索结果...")
return True
elif task_status == 'failed':
print("任务失败:", status_data.get('data', {}).get('error_message'))
return False
else:
print("检查任务状态失败:", response.text)
return False
time.sleep(5) # 每次检查之间等待
def get_task_result(task_id, api_key, output_path):
result_url = f"https://api.easylink-ai.com/v1/easydoc/result/{task_id}"
headers = {
'api-key': api_key,
}
response = requests.get(result_url, headers=headers)
if response.ok:
result_data = response.json() # 可能需要或不需要这行,视具体系统返回格式
with open(output_path, 'w', encoding='utf-8') as out_file:
json.dump(result_data, out_file, ensure_ascii=False, indent=4)
print(f"结果已保存到 {output_path}")
return result_data
else:
print("获取结果失败:", response.text)
return None
def main():
# 配置参数
file_path = "" # 请替换为你的文件路径
api_key = "" # 请替换为你的API Key
output_path = "task_result.json" # 输出结果保存路径
# 提交请求并获取任务ID
task_id = submit_request(file_path, api_key)
if task_id:
# 检查任务状态并获取结果
if check_task_status(task_id, api_key):
get_task_result(task_id, api_key, output_path)
if __name__ == "__main__":
main()获取到的内容都可以在控制台左侧导航栏中的任务列表中查看到
选择查看结果,就可以看到刚刚请求的这篇论文了

如果你想要解析其他格式的内容,修改model参数就行
'mode': 'doc-parse-premium', # 选择解析模式常见的参数包含下面几个
解析模式:doc-parse-premium,doc-parse-flash,doc-parse-lite,doc-parse-pro,paper-parse(论文解析)
如果你有其他的调用习惯也可以使用其他方式,官方文档都有详细的描述
curl -X POST "https://api.easylink-ai.com/v1/easydoc/parse" \
-H "api-key: your_apikey_here" \
-F "files=@medical_record_001.pdf" \
-F "mode=premium"五、新用户专属福利
EasyLink推出新用户注册福利:个人用户可领30元无门槛体验金,企业用户可获90元体验礼包,含专属咨询与技术支持等权益,助力高效体验数据智能处理服务。
六、总结
过去,企业在处理大量复杂文档如PDF和合同时常常苦于低效和手动操作。传统方法无法有效提取和使用这些多模态数据,复杂的数据预处理令人心烦意乱,即使是先进的大模型也未必都能做的很好。EasyLink平台解决了这一难题。它能自动解析和抽取非结构化文档中的关键信息,将其转化为标准化数据。 这提高了企业运营效率,减少了手动处理时间和错误率。其强大之处在于无需固定模板就能识别和处理多样且复杂的文档类型。
现在注册即可免费试用: https://www.easylink-ai.com/use-cases
简言之,无论是在商业、科研或医疗领域,EasyLink都大幅提升了数据处理效率,让我们能够更专注于高价值的分析和决策工作。