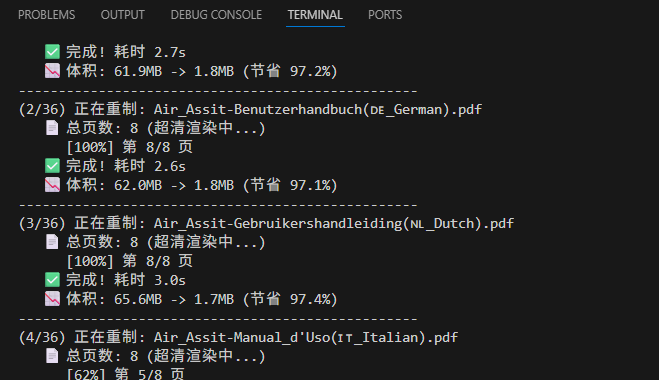
1.功能
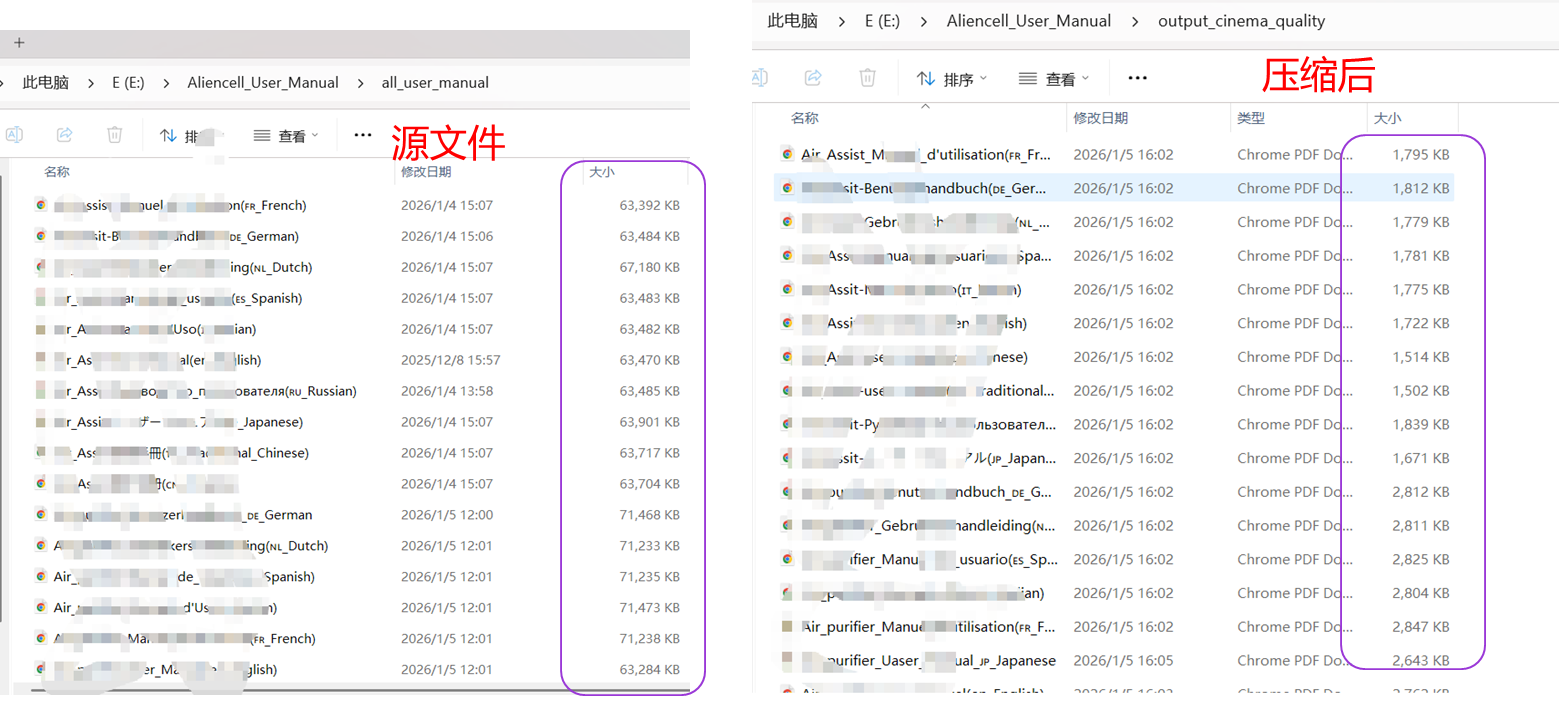
编写Python代码,批量压缩pdf文档,压缩率可达到90%
2.处理思路
先把pdf转成图片,然后压缩图片,再把压缩好的图片合成pdf(以下描述来自AI)
具体思路:
- 栅格化(PDF转图片) :
代码读取 PDF 的每一页,强制把页面上的所有内容(文字、矢量图、遮罩)渲染成一张 位图数据(Pixmap) 。- 代码对应:
page.get_pixmap(...)
- 代码对应:
- 重编码(图片转JPEG) :
把这张位图数据,使用 JPEG 算法 进行有损压缩。这一步通过丢弃颜色细节来减小体积。- 代码对应:
pix.tobytes("jpeg", ...)
- 代码对应:
- 重组装(图片转PDF) :
新建一个空白 PDF 页面,把压缩后的 JPEG 数据流直接填进去,最后保存。- 代码对应:
new_page.insert_image(...)
- 代码对应:
总结: 原理就是 PDF页 -> 渲染为像素点 -> 压缩成JPEG -> 塞回新PDF。
3.准备工作:
python版本:
- python3.8版本以上
安装第三方库:
powershell
pip install pymupdf参考代码:
python
import os
import fitz # PyMuPDF
import time
# === 💎 超清重制配置 (影院级) ===
# 1. 清晰度 (缩放倍数)
# 2.5 = 180 DPI (还有点糊)
# 3.0 = 216 DPI (非常清晰,类似 iPad 阅读体验)
# 如果还觉得糊,可以极端点设为 4.0 (300 DPI 打印级),但体积会翻倍
ZOOM_FACTOR = 3.0
# 2. 图片质量 (1-100)
# 85 是高保真分界线,文字边缘会很干净
JPG_QUALITY = 85
def rasterize_pdf(input_path, output_path):
try:
doc_src = fitz.open(input_path)
doc_out = fitz.open()
total_pages = len(doc_src)
print(f" 📄 总页数: {total_pages} (超清渲染中...)")
for page_num, page in enumerate(doc_src):
# 1. 超清渲染 (3倍分辨率)
# alpha=False 强制白底,防止透明变黑
mat = fitz.Matrix(ZOOM_FACTOR, ZOOM_FACTOR)
pix = page.get_pixmap(matrix=mat, alpha=False)
# 2. 高保真压缩
img_data = pix.tobytes("jpeg", jpg_quality=JPG_QUALITY)
# 3. 创建页面
new_page = doc_out.new_page(width=page.rect.width, height=page.rect.height)
# 4. 插入图片
new_page.insert_image(page.rect, stream=img_data)
# 释放内存 (大图很吃内存,必须及时释放)
pix = None
# 进度条
print(f" [{(page_num+1)/total_pages*100:.0f}%] 第 {page_num + 1}/{total_pages} 页", end="\r")
print("")
# 保存
doc_out.save(output_path, garbage=4, deflate=True)
doc_out.close()
doc_src.close()
return True
except Exception as e:
print(f" ❌ 出错: {e}")
return False
def run_rasterize_batch(input_folder, output_folder):
if not os.path.exists(output_folder):
os.makedirs(output_folder)
files = [f for f in os.listdir(input_folder) if f.lower().endswith('.pdf')]
print(f"📸 启动【超清重制】模式")
print(f"⚙️ 参数: 倍数={ZOOM_FACTOR}x (~{int(72*ZOOM_FACTOR)} DPI) | 画质 Q={JPG_QUALITY}")
print("-" * 50)
for i, f in enumerate(files):
input_file = os.path.join(input_folder, f)
output_file = os.path.join(output_folder, f)
start_time = time.time()
file_size_org = os.path.getsize(input_file)
print(f"({i+1}/{len(files)}) 正在重制: {f}")
if rasterize_pdf(input_file, output_file):
if os.path.exists(output_file):
file_size_new = os.path.getsize(output_file)
ratio = (1 - (file_size_new / file_size_org)) * 100
duration = time.time() - start_time
print(f" ✅ 完成! 耗时 {duration:.1f}s")
print(f" 📉 体积: {file_size_org/1024/1024:.1f}MB -> {file_size_new/1024/1024:.1f}MB (节省 {ratio:.1f}%)")
else:
print(f" ❌ 失败")
print("-" * 50)
if __name__ == "__main__":
# 路径
input_dir = r"E:\Aliencell_User_Manual\all_user_manual"
output_dir = r"E:\Aliencell_User_Manual\output_cinema_quality"
run_rasterize_batch(input_dir, output_dir)
- 如果想要提高图片质量或者更改清晰度修改参数JPG_QUALITY或者ZOOM_FACTOR
- 将所有pdf文件放在input_dir ,然后创建一个输出的文件夹。注意更改路径和名称,名称不要用中文
powershell
input_dir = r"E:\Aliencell_User_Manual\all_user_manual"
output_dir = r"E:\Aliencell_User_Manual\output_cinema_quality" - 运行效果