目录
三、MemoryAttentionLayer.forward
[3.1 RoPEAttention](#3.1 RoPEAttention)
[3.1.1 _separate_heads](#3.1.1 _separate_heads)
[3.1.2 compute_cis](#3.1.2 compute_cis)
[3.1.2.1 什么意思?](#3.1.2.1 什么意思?)
[3.1.2.2 init_t_xy](#3.1.2.2 init_t_xy)
[3.1.2.3 有没有通俗一点的方式理解RoPE?](#3.1.2.3 有没有通俗一点的方式理解RoPE?)
[3.1.2.4 如何理解](#3.1.2.4 如何理解)
一、前言
这一篇直接被旋转位置编码RoPE给卡住了。然后我就去找了些相关的教程。结果发现还是看不懂,这个先标记一下。
https://zhuanlan.zhihu.com/p/780744022
而且看着看着又跑去看这个傅里叶分析的教程了,也没完全看懂。。但是感觉不明觉厉。
感觉这个旋转位置编码跟前面那篇看的那个位置编码也不能说完全没有相似之处,前面那篇是一个像素位置x方向32维,y方向32维构成64个不同的波长,然后位置除以波长,然后是把位置编码加上去。这一篇是x方向64维,y方向64维,但是是位置乘以频率,而且不是直接加位置编码了,是先转复数表示,然后再乘上去。为什么SAM2要用不同的位置编码呢,两者又有什么不同?现在这两个位置编码都不是很理解,先标记一下。
二、MemoryAttention.forward
在_prepare_memory_conditioned_features中调用了
使用记忆注意力机制融合当前特征和记忆特征
pix_feat_with_mem = self.memory_attention(
curr=current_vision_feats,
curr_pos=current_vision_pos_embeds,
memory=memory,
memory_pos=memory_pos_embed,
num_obj_ptr_tokens=num_obj_ptr_tokens,
)
sam2/modeling/memory_attention.py
python
class MemoryAttention(nn.Module):
"""
记忆注意力模块:结合当前输入和记忆信息的Transformer解码器层堆叠
支持自注意力和交叉注意力机制,用于处理视频分割等需要时序记忆的任务
"""
def __init__(
self,
d_model: int, # 模型维度(特征通道数)
pos_enc_at_input: bool, # 是否在输入时添加位置编码
layer: nn.Module, # Transformer解码器层
num_layers: int, # 解码器层堆叠数量
batch_first: bool = True, # 是否使用batch-first格式 (batch, seq, feature)
):
super().__init__()
self.d_model = d_model # 保存模型维度
# 克隆多个相同的解码器层,形成深度网络
self.layers = get_clones(layer, num_layers)
self.num_layers = num_layers # 保存层数
# 层归一化,用于最终输出标准化
self.norm = nn.LayerNorm(d_model)
self.pos_enc_at_input = pos_enc_at_input # 是否输入时加位置编码
self.batch_first = batch_first # 保存batch格式标志
def forward(
self,
curr: torch.Tensor, # 当前帧特征 (自注意力输入)
memory: torch.Tensor, # 记忆特征 (交叉注意力输入)
curr_pos: Optional[Tensor] = None, # 当前帧位置编码
memory_pos: Optional[Tensor] = None, # 记忆特征位置编码
num_obj_ptr_tokens: int = 0, # 对象指针token数量(用于特定注意力模式)
):
# curr: [torch.Size([4096, B, 256]),]
# curr_pos: [torch.Size([4096, B, 256]),]
# memory: torch.Size([4100, B, 64])
# memory_pos_embed: torch.Size([4100, B, 64])
# num_obj_ptr_tokens:4
# 处理输入为列表的情况(兼容某些特定输入格式)
if isinstance(curr, list):
assert isinstance(curr_pos, list), "位置编码必须是列表格式"
assert len(curr) == len(curr_pos) == 1, "列表长度必须为1"
# 从列表中提取张量
curr, curr_pos = (
curr[0],
curr_pos[0],
)
# curr: torch.Size([4096, B, 256])
# curr_pos: torch.Size([4096, B, 256])
# 确保当前输入和记忆输入的batch size一致
assert (
curr.shape[1] == memory.shape[1]
), "Batch size must be the same for curr and memory"
# 初始化输出为当前输入
output = curr
# output: torch.Size([4096, B, 256])
# 如果在输入阶段添加位置编码,则将位置编码加到当前特征上
# 使用0.1的缩放因子控制位置编码的影响强度
# self.pos_enc_at_input: True
if self.pos_enc_at_input and curr_pos is not None:
output = output + 0.1 * curr_pos
# output: torch.Size([4096, B, 256])
# 如果需要batch-first格式,则将维度从(seq, batch, feature)转换为(batch, seq, feature)
# self.batch_first: True
if self.batch_first:
# 转置第0维和第1维
output = output.transpose(0, 1)
# output: torch.Size([B, 4096, 256])
curr_pos = curr_pos.transpose(0, 1)
# curr_pos: torch.Size([B, 4096, 256])
memory = memory.transpose(0, 1)
# memory: torch.Size([B, 4100, 64])
memory_pos = memory_pos.transpose(0, 1)
# memory_pos: torch.Size([B, 4100, 64])
# 遍历所有解码器层,逐层处理
for layer in self.layers:
kwds = {}
# 如果交叉注意力使用RoPE(旋转位置编码),则设置排除rope的token数量
# 这通常用于避免对某些特殊token(如对象指针token)应用旋转位置编码
if isinstance(layer.cross_attn_image, RoPEAttention):
kwds = {"num_k_exclude_rope": num_obj_ptr_tokens}
# 调用单个解码器层进行前向传播
# tgt: 目标序列 (当前特征)
# memory: 记忆序列
# pos: 记忆序列的位置编码(作为key的位置编码)
# query_pos: 查询的位置编码
output = layer(
tgt=output,
memory=memory,
pos=memory_pos,
query_pos=curr_pos,
**kwds,
)
# 对最终输出应用层归一化,稳定训练过程
normed_output = self.norm(output)
# 如果之前转换为batch-first格式,则转回原始格式(seq, batch, feature)
if self.batch_first:
normed_output = normed_output.transpose(0, 1)
curr_pos = curr_pos.transpose(0, 1)
return normed_output # 返回归一化后的输出三、MemoryAttentionLayer.forward
output = layer(
tgt=output,
memory=memory,
pos=memory_pos,
query_pos=curr_pos,
**kwds,
)
sam2/modeling/memory_attention.py
python
class MemoryAttentionLayer(nn.Module):
"""
Transformer解码器层:实现自注意力、交叉注意力和前馈网络
用于MemoryAttention模块的单个层,支持灵活的位置编码配置
"""
def __init__(
self,
activation: str, # 激活函数类型(如'relu', 'gelu')
cross_attention: nn.Module, # 交叉注意力模块
d_model: int, # 模型维度(特征通道数)
dim_feedforward: int, # 前馈网络中间层维度
dropout: float, # dropout概率
pos_enc_at_attn: bool, # 是否在自注意力中添加位置编码
pos_enc_at_cross_attn_keys: bool, # 是否在交叉注意力key中添加位置编码
pos_enc_at_cross_attn_queries: bool, # 是否在交叉注意力query中添加位置编码
self_attention: nn.Module, # 自注意力模块
):
super().__init__()
self.d_model = d_model
self.dim_feedforward = dim_feedforward
self.dropout_value = dropout
self.self_attn = self_attention # 自注意力实例
self.cross_attn_image = cross_attention # 交叉注意力实例
# 前馈网络实现:Linear -> Activation -> Dropout -> Linear
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
# 三个层归一化:分别用于自注意力、交叉注意力和前馈网络后
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
# 三个dropout:对应三个子层的残差连接
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation_str = activation
self.activation = get_activation_fn(activation) # 获取激活函数
# 位置编码添加位置配置标志
self.pos_enc_at_attn = pos_enc_at_attn # 自注意力是否加pos enc
self.pos_enc_at_cross_attn_queries = pos_enc_at_cross_attn_queries # 交叉注意力query是否加pos enc
self.pos_enc_at_cross_attn_keys = pos_enc_at_cross_attn_keys # 交叉注意力key是否加pos enc
def _forward_sa(self, tgt, query_pos):
"""
自注意力前向传播
Args:
tgt: 目标序列(当前帧特征)
query_pos: 位置编码
"""
# tgt: torch.Size([B, 4096, 256])
# query_pos: torch.Size([B, 4096, 256])
# 预层归一化(pre-norm)结构
tgt2 = self.norm1(tgt)
# tgt2: torch.Size([B, 4096, 256])
# 如果需要,将位置编码加到query和key上
# pos_enc_at_attn: False
q = k = tgt2 + query_pos if self.pos_enc_at_attn else tgt2
# 执行自注意力,value是归一化后的tgt2
# q: torch.Size([B, 4096, 256])
# k: torch.Size([B, 4096, 256])
# v: torch.Size([B, 4096, 256])
# 进入RoPEAttention.forward
tgt2 = self.self_attn(q, k, v=tgt2)
# 残差连接和dropout
tgt = tgt + self.dropout1(tgt2)
return tgt
def _forward_ca(self, tgt, memory, query_pos, pos, num_k_exclude_rope=0):
"""
交叉注意力前向传播
Args:
tgt: 目标序列(当前帧特征)
memory: 记忆序列(历史帧特征)
query_pos: 当前帧位置编码
pos: 记忆帧位置编码
num_k_exclude_rope: 排除RoPE的key数量
"""
kwds = {}
# 如果指定排除RoPE的token数量,检查并传递参数
if num_k_exclude_rope > 0:
assert isinstance(self.cross_attn_image, RoPEAttention), "必须是RoPEAttention"
kwds = {"num_k_exclude_rope": num_k_exclude_rope}
# 预层归一化
tgt2 = self.norm2(tgt)
# 执行交叉注意力,可选地在query和key上添加位置编码
tgt2 = self.cross_attn_image(
q=tgt2 + query_pos if self.pos_enc_at_cross_attn_queries else tgt2, # query
k=memory + pos if self.pos_enc_at_cross_attn_keys else memory, # key
v=memory, # value是记忆本身
**kwds, # 额外参数(如RoPE排除)
)
# 残差连接和dropout
tgt = tgt + self.dropout2(tgt2)
return tgt
def forward(
self,
tgt, # 目标序列(当前帧特征)
memory, # 记忆序列(历史帧特征)
pos: Optional[Tensor] = None, # 记忆位置编码
query_pos: Optional[Tensor] = None, # 当前帧位置编码
num_k_exclude_rope: int = 0, # 排除RoPE的key数量
) -> torch.Tensor:
"""
完整前向传播:自注意力 -> 交叉注意力 -> 前馈网络
"""
# tgt: torch.Size([B, 4096, 256])
# query_pos: torch.Size([B, 4096, 256])
# memory: torch.Size([B, 4100, 64])
# pos: torch.Size([B, 4100, 64])
# 1. 自注意力层:当前帧内部特征交互
tgt = self._forward_sa(tgt, query_pos)
# 2. 交叉注意力层:当前帧与记忆帧的特征交互
tgt = self._forward_ca(tgt, memory, query_pos, pos, num_k_exclude_rope)
# 3. 前馈网络层:非线性特征变换
tgt2 = self.norm3(tgt) # 预层归一化
# Linear -> Activation -> Dropout -> Linear
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
# 残差连接和dropout
tgt = tgt + self.dropout3(tgt2)
return tgt # 返回处理后的特征
MemoryAttentionLayer是 MemoryAttention 模块的单层实现,遵循标准Transformer解码器结构,但提供了更灵活的位置编码配置:1. 核心结构(标准Transformer解码器层):
自注意力:当前帧特征内部的上下文建模
交叉注意力:当前帧与记忆库的特征交互(核心创新点)
前馈网络:非线性特征变换和通道维度压缩
2. 位置编码的灵活配置: 通过三个布尔标志精确控制位置编码的添加位置:
pos_enc_at_attn:自注意力的Q/K是否加位置编码
pos_enc_at_cross_attn_queries:交叉注意力Query是否加位置编码
pos_enc_at_cross_attn_keys:交叉注意力Key是否加位置编码这种设计允许模型自适应地学习不同时序/空间依赖关系。
3. 预层归一化(Pre-Norm)结构:
在每个子层之前应用LayerNorm(而非之后)
实践表明Pre-Norm在深层网络中训练更稳定
配合残差连接形成:
Output = Input + Dropout(SubLayer(Norm(Input)))4. 特殊处理:
RoPE支持:对交叉注意力中的特殊token(如对象指针)可排除旋转位置编码
Dropout:三个子层后都有dropout防止过拟合
激活函数:可配置(ReLU/GELU等)
5. 在视频分割中的作用: 在SAM2等模型中,该层实现了时序信息融合的核心机制:
当前帧特征通过自注意力增强上下文理解
通过交叉注意力从记忆库中检索相关历史信息
前馈网络整合并精炼融合后的特征
多层堆叠后形成强大的时序建模能力
3.1 RoPEAttention
在类MemoryAttentionLayer的_forward_sa中调用了
执行自注意力,value是归一化后的tgt2
tgt2 = self.self_attn(q, k, v=tgt2)
sam2/modeling/sam/transformer.py
python
class RoPEAttention(Attention):
"""带有旋转位置编码(RoPE)的注意力机制。"""
def __init__(
self,
*args,
rope_theta=10000.0, # RoPE编码的基数,控制位置编码的频率
# 是否重复q的RoPE编码以匹配k的长度
# 这在交叉注意力处理记忆时是必需的
rope_k_repeat=False,
feat_sizes=(32, 32), # 特征图的尺寸[w, h],对应512分辨率下stride为16的特征
**kwargs,
):
super().__init__(*args, **kwargs)
# 创建部分应用的compute_axial_cis函数,固定维度和theta参数
# internal_dim // num_heads是每个注意力头的维度
self.compute_cis = partial(
compute_axial_cis, dim=self.internal_dim // self.num_heads, theta=rope_theta
)
# 预计算轴向的复数频率张量,用于RoPE编码
freqs_cis = self.compute_cis(end_x=feat_sizes[0], end_y=feat_sizes[1])
self.freqs_cis = freqs_cis
self.rope_k_repeat = rope_k_repeat
def forward(
self, q: Tensor, k: Tensor, v: Tensor, num_k_exclude_rope: int = 0
) -> Tensor:
"""
前向传播函数。
参数:
q: Query张量
k: Key张量
v: Value张量
num_k_exclude_rope: 不需要应用RoPE编码的key数量(从末尾开始排除)
用于处理记忆向量等不需要位置编码的部分
"""
# q: torch.Size([B, 4096, 256])
# k: torch.Size([B, 4096, 256])
# v: torch.Size([B, 4096, 256])
# 输入线性投影,将q,k,v映射到内部维度
q = self.q_proj(q)
k = self.k_proj(k)
v = self.v_proj(v)
# q: torch.Size([B, 4096, 256])
# k: torch.Size([B, 4096, 256])
# v: torch.Size([B, 4096, 256])
# 将q,k,v拆分为多个注意力头
q = self._separate_heads(q, self.num_heads)
k = self._separate_heads(k, self.num_heads)
v = self._separate_heads(v, self.num_heads)
# q: torch.Size([B, 1, 4096, 256])
# k: torch.Size([B, 1, 4096, 256])
# v: torch.Size([B, 1, 4096, 256])
# 应用旋转位置编码(RoPE)
w = h = math.sqrt(q.shape[-2]) # 计算特征图的宽和高(假设为方形)
# w: 64.0 h: 64.0
self.freqs_cis = self.freqs_cis.to(q.device) # 将频率张量移动到与q相同的设备
# self.freqs_cis: torch.Size([1024, 128])
# 如果预计算的频率张量长度与当前q长度不匹配,则重新计算
if self.freqs_cis.shape[0] != q.shape[-2]:
self.freqs_cis = self.compute_cis(end_x=w, end_y=h).to(q.device)
# 如果q和k的长度不同,需要启用rope_k_repeat来重复q的编码以匹配k
if q.shape[-2] != k.shape[-2]:
assert self.rope_k_repeat
# 计算需要应用RoPE的key数量(排除末尾不需要编码的部分)
num_k_rope = k.size(-2) - num_k_exclude_rope
# 对q和k的前num_k_rope部分应用旋转位置编码
q, k[:, :, :num_k_rope] = apply_rotary_enc(
q,
k[:, :, :num_k_rope],
freqs_cis=self.freqs_cis,
repeat_freqs_k=self.rope_k_repeat,
)
# 设置dropout概率(训练时使用配置的dropout,推理时为0)
dropout_p = self.dropout_p if self.training else 0.0
# 使用PyTorch的SDPA(Scaled Dot Product Attention)计算注意力
# 根据硬件和能力自动选择Flash Attention、高效内存或数学实现
with torch.backends.cuda.sdp_kernel(
enable_flash=USE_FLASH_ATTN, # 启用Flash Attention(如果可用)
# 如果Flash Attention关闭,则需要启用数学内核
enable_math=(OLD_GPU and dropout_p > 0.0) or MATH_KERNEL_ON,
enable_mem_efficient=OLD_GPU, # 在老GPU上启用内存高效实现
):
out = F.scaled_dot_product_attention(q, k, v, dropout_p=dropout_p)
# 将多个注意力头的输出重新组合
out = self._recombine_heads(out)
# 最后的输出投影
out = self.out_proj(out)
return out这段代码实现了一个带有旋转位置编码(RoPE)的多头注意力机制,主要特点和功能如下:
RoPE位置编码:
通过旋转位置编码(Rotary Position Embedding)为query和key添加相对位置信息
使用
compute_axial_cis计算轴向的复数频率,这是RoPE编码的核心位置编码可以动态计算,适应不同尺寸的特征图
灵活的交叉注意力支持:
支持query和key长度不同的场景(如交叉注意力)
rope_k_repeat参数控制是否在长度不匹配时重复query的编码
num_k_exclude_rope参数允许部分key(如记忆向量)跳过位置编码多头注意力计算:
继承自基础
Attention类,复用了头的分离(_separate_heads)和重组(_recombine_heads)逻辑使用PyTorch 2.0+的
scaled_dot_product_attention实现高效的注意力计算根据硬件条件自动选择Flash Attention、内存高效或数学实现
视频分割/对象跟踪应用:
特征图尺寸参数
feat_sizes默认为(32, 32),对应512×512输入下16倍下采样的特征这种设计使其非常适合处理2D空间特征,如视频帧或图像特征图
典型应用场景:在视频对象分割模型中,该注意力机制可以处理不同帧之间的特征交互,通过RoPE编码保留空间位置关系,同时支持对记忆库中的历史特征进行交叉注意力。
3.1.1 _separate_heads
python
def _separate_heads(self, x: Tensor, num_heads: int) -> Tensor:
# x: torch.Size([B, 4096, 256])
b, n, c = x.shape
# b: 2, n:4096, c:256 b=2是因为调试中添加了2个对象
x = x.reshape(b, n, num_heads, c // num_heads)
# x: torch.Size([B, 4096, 1, 256])
# x.transpose(1, 2): torch.Size([B, 1, 4096, 256])
return x.transpose(1, 2) # B x N_heads x N_tokens x C_per_head3.1.2 compute_cis
self.freqs_cis = self.compute_cis(end_x=w, end_y=h).to(q.device)
sam2/modeling/position_encoding.py
python
def compute_axial_cis(dim: int, end_x: int, end_y: int, theta: float = 10000.0):
"""
计算2D轴向的旋转位置编码(RoPE)复数频率张量。
参数:
dim: 特征维度总数(将被平均分配给x和y轴)
end_x: x轴(宽度)方向的坐标数量
end_y: y轴(高度)方向的坐标数量
theta: RoPE编码的基数,控制位置编码的频率
"""
# dim: 256
# end_x: 64.0
# end_y: 64.0
# theta: 10000.0
# 计算x轴的频率向量:生成dim//4个不同的频率,用于控制不同维度上的旋转速度
# 频率随着维度索引增加而降低,形成几何级数,使不同维度捕获不同尺度的位置信息
freqs_x = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim))
# freqs_x: torch.Size([64]) 数值里面有10的负1、负2、负3、负4这些数量级
# 计算y轴的频率向量(与x轴相同,因为dim是平均分配的)
# 例如:dim=256时,生成64个频率值,每个值对应一个复数平面的旋转角速度
freqs_y = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim))
# freqs_y: torch.Size([64])
# 初始化x和y方向的坐标网格
# t_x: shape为[end_x],包含0到end_x-1的整数坐标
# t_y: shape为[end_y],包含0到end_y-1的整数坐标
t_x, t_y = init_t_xy(end_x, end_y)
# t_x: torch.Size([4096])
# t_y: torch.Size([4096])
# 计算x轴方向的外积:每个位置坐标与每个频率值组合,生成位置-频率矩阵
# freqs_x最终shape: [end_x, dim//4],每个元素是该位置在该频率下的旋转角度
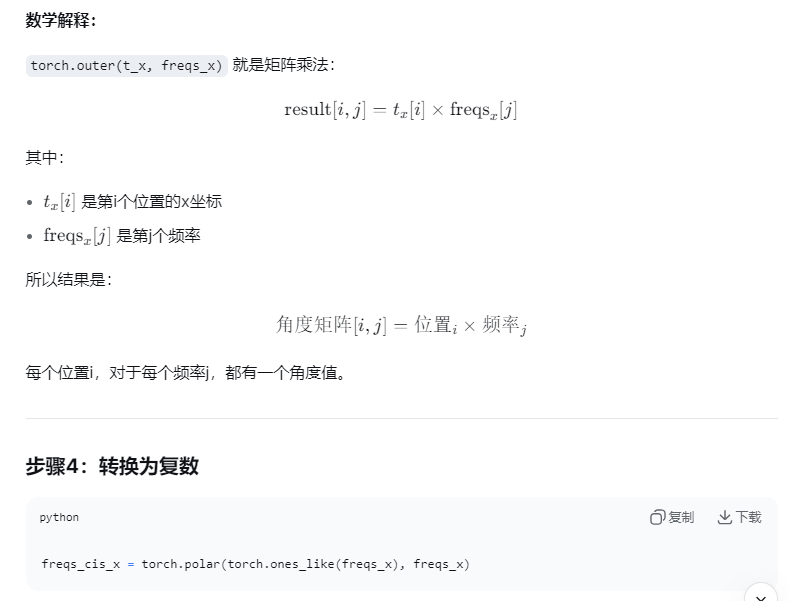
freqs_x = torch.outer(t_x, freqs_x)
# freqs_x: torch.Size([4096, 64])
# 计算y轴方向的外积
# freqs_y最终shape: [end_y, dim//4]
freqs_y = torch.outer(t_y, freqs_y)
# freqs_y: torch.Size([4096, 64])
# 将x轴的旋转角度转换为复数形式(模长为1的复数)
# torch.polar(r, angle)创建模为r、角度为angle的复数,这里模恒为1,只保留旋转信息
# freqs_cis_x shape: [end_x, dim//4],每个元素是模为1的复数
freqs_cis_x = torch.polar(torch.ones_like(freqs_x), freqs_x)
# freqs_cis_x: torch.Size([4096, 64])
# 将y轴的旋转角度转换为复数形式
freqs_cis_y = torch.polar(torch.ones_like(freqs_y), freqs_y)
# freqs_cis_y: torch.Size([4096, 64])
# 将x和y方向的复数频率在最后一维拼接
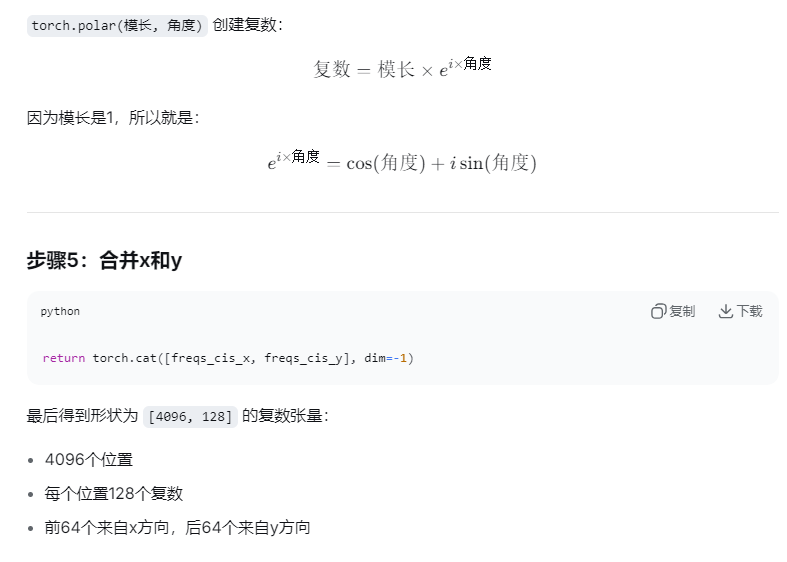
# 最终shape: [end_x * end_y, dim//2],其中dim//4来自x,dim//4来自y
# return torch.Size([4096, 128])
return torch.cat([freqs_cis_x, freqs_cis_y], dim=-1)这个函数是旋转位置编码(RoPE)的核心组件,用于生成2D空间的位置编码。其主要功能如下:
频率生成:
生成一系列几何级数的频率值(基于theta参数),这些频率决定了不同特征维度上的旋转速度
频率从高频到低频分布,使模型能够捕捉到从细粒度到粗粒度的位置信息
轴向位置编码:
将2D空间的位置编码分解为x轴和y轴两个独立的一维编码
通过
init_t_xy生成坐标网格,然后与频率向量做外积,得到每个位置在每个频率下的旋转角度复数表示:
使用复数形式(
torch.polar)表示旋转,模长为1保证只编码方向信息这种表示方式使得RoPE可以通过复数乘法高效地实现位置编码的"旋转"操作
维度分配:
总特征维度
dim被平均分配给x轴和y轴(各dim//2)每
dim//4个频率负责一个轴向的编码,最终通过拼接形成完整的2D位置编码典型应用:在视觉Transformer中,该函数为特征图的每个位置生成唯一的旋转位置编码,使注意力机制能够感知2D空间中的相对位置关系,特别适用于处理图像、视频帧等结构化数据。
3.1.2.1 什么意思?
freqs_x = 1.0 / (theta ** (torch.arange(0, dim, 4): (dim // 4).float() / dim))
在
compute_axial_cis函数中,freqs_x = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim))是生成频率向量的核心代码,我来为您拆解计算逻辑:
代码拆解
pythontorch.arange(0, dim, 4) # 生成 [0, 4, 8, 12, ..., dim-4] 的整数序列 [: (dim // 4)] # 取前 dim//4 个元素(实际上arange已经保证了长度为 dim//4) .float() # 转换为浮点数 / dim # 每个元素除以 dim theta ** (...) # 以 theta 为底,指数为上述结果 1.0 / (...) # 取倒数得到最终频率
完整计算步骤(以
dim=256为例)
torch.arange(0, 256, 4)
生成:
[0, 4, 8, 12, ..., 252]长度:
256/4 = 64个元素
[: (256 // 4)]
- 取前64个元素(结果不变)
.float()
- 转换为浮点类型:
[0.0, 4.0, 8.0, ..., 252.0]
/ 256
归一化:
[0.0, 0.0156, 0.03125, ..., 0.984375]这些值代表维度索引的相对位置
theta ** (...)
计算:
10000^0.0, 10000^0.0156, 10000^0.03125, ..., 10000^0.984375结果呈几何级数增长(因为指数在增加)
1.0 / (...)
- 取倒数得到最终频率:
[1.0, 0.1, 0.01, ..., 一个很小的数]
数学本质
其中:
i 是维度索引(i=0,4,8,...,dim−4 )
θ=10000 是基数,控制频率范围
频率从高频到低频递减
为什么这样设计?
维度索引 i 频率值 位置敏感度 捕获的信息 小(如0) 高(如1.0) 敏感到小位移 局部细节 大(如252) 低(如~0.01) 只响应大位移 全局结构 几何级数递减确保不同维度以不同尺度感知位置,类似多分辨率分析。高频维度能区分相邻位置,低频维度能编码远距离关系,形成层次化的位置感知能力。
这些频率如何工作?
生成的
freqs_x不是一个直接使用的编码值,而是 旋转速度的"指令集" 。后续流程如下:1. 与位置坐标相乘
freqs_x = torch.outer(t_x, freqs_x) # [4096, 64]
t_x是位置坐标[0, 1, 2, ..., 4095](展平后的像素索引)外积操作使每个位置获得一组专属的旋转角度
位置 p 的第 i 个角度 =
p × freq_i2. 转换为复数
freqs_cis_x = torch.polar(torch.ones_like(freqs_x), freqs_x)
torch.polar(1, angle)将角度转换为 模为1的复数cos(angle) + i·sin(angle)这个复数的物理意义:单位圆上的旋转算子
复数乘法等价于向量旋转,计算效率极高
3. 应用于Query/Key向量
在注意力计算时,RoPE不会直接加编码,而是旋转特征向量:
# 假设 q 是 [4096, 64] 的Query向量(已转为复数形式) q_rotated = q * freqs_cis_x # 逐元素复数乘法,实现旋转
位置 p 的特征会按
p × freq_i的角度旋转位置不同 → 旋转角度不同 → 点积结果不同 → 注意力权重不同
为什么用复数而不是实数?
实数编码方式 复数旋转方式 加法: x + pos_encoding乘法: x * cis(angle)维度耦合,信息易损失 维度独立,保模旋转 难以捕获相对位置 相对位置自然体现 核心优势 :对于任意两个位置 p 和 q ,它们的相对旋转角度是
(p-q) × freq_i,只与距离有关,与绝对位置无关 。这使得模型对 平移不变性 更鲁棒。
2D轴向设计的精妙之处
return torch.cat([freqs_cis_x, freqs_cis_y], dim=-1) # [4096, 128]将x轴和y轴的频率拼接后:
前64维:负责编码水平方向的位置关系
后64维:负责编码垂直方向的位置关系
模型可独立学习两个轴向的依赖模式,符合图像的各向异性
相比1D RoPE直接展平为
[height*width],轴向分离保留了二维空间结构,在视觉任务中表现更优。
一句话总结
这行代码是RoPE的"频率发生器",用几何级数生成递减的频率向量,为每个维度分配不同的旋转速度,使高频捕获局部细节、低频捕获全局布局,最终通过复数旋转在注意力机制中注入平移不变的相对位置信息。
3.1.2.2 init_t_xy
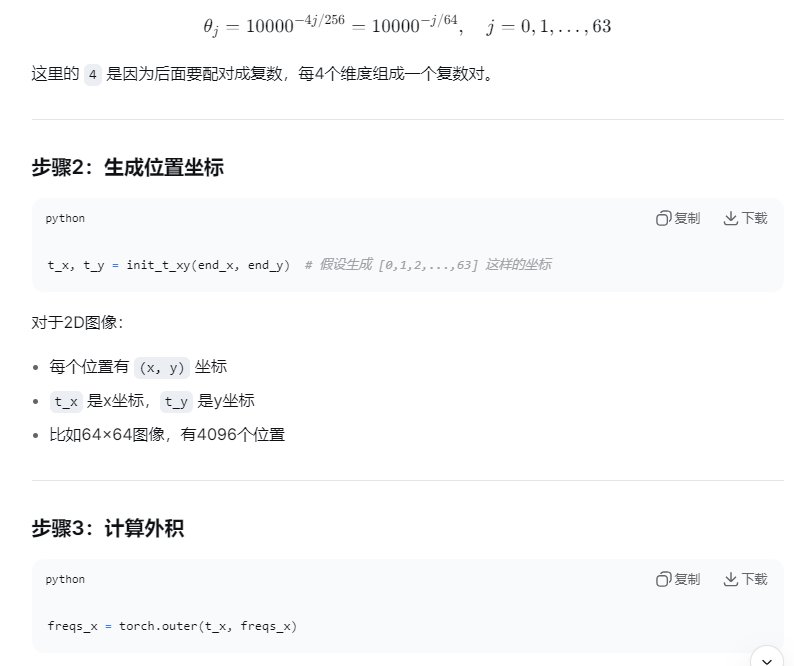
t_x, t_y = init_t_xy(end_x, end_y)
sam2/modeling/position_encoding.py
python
def init_t_xy(end_x: int, end_y: int):
"""
生成2D特征图的x和y坐标张量(行优先顺序)。
参数:
end_x: x轴(宽度)方向的坐标数量
end_y: y轴(高度)方向的坐标数量
返回:
t_x: x坐标张量,shape为[end_x * end_y]
t_y: y坐标张量,shape为[end_x * end_y]
"""
# end_x: 64.0
# end_y: 64.0
# 生成从0到end_x * end_y - 1的连续整数张量,作为展平后的像素索引
# shape: [end_x * end_y],数据类型为float32
t = torch.arange(end_x * end_y, dtype=torch.float32)
# t:torch.Size([4096]) 数值是0到4095
# 计算每个位置的x坐标(列索引)
# 通过取模运算得到在宽度方向上的位置,形成周期性模式: 0,1,2,...,end_x-1,0,1,2,...
t_x = (t % end_x).float()
# t_x: torch.Size([4096]) 周期性的0到63
# 计算每个位置的y坐标(行索引)
# 通过向下取整的除法得到在高度方向上的位置,每end_x个像素行号增加1
# 例如: 0,0,0,...,1,1,1,...,2,2,2,...(每个值重复end_x次)
t_y = torch.div(t, end_x, rounding_mode="floor").float()
# t_y: torch.Size([4096])
return t_x, t_y这个函数是生成2D网格坐标的辅助函数,主要功能如下:
展平索引生成:
首先生成一个长度为
end_x * end_y的一维索引张量,代表展平后的2D特征图的所有位置这是为了方便后续向量化计算,避免使用嵌套循环
坐标解耦:
将一维索引按行优先顺序(C语言风格)分解为独立的x(列)和y(行)坐标
例如:对于4×3的特征图,索引0-3对应第0行的4个列,索引4-7对应第1行的4个列,以此类推
向量化设计:
返回的是两个一维张量而非二维网格,这种设计可以直接用于后续的外积和广播操作
t_x在x方向周期性变化,t_y在y方向阶梯性变化效率优化:
所有操作都是向量化完成,计算效率远高于Python循环
这种坐标生成方式是RoPE编码实现2D位置感知的基础组件
典型应用:在RoPE编码中,这些坐标与频率向量做外积,生成每个位置对应的旋转角度,从而让模型能够区分2D空间中的不同位置。
3.1.2.3 有没有通俗一点的方式理解RoPE?
一、用「时钟」来理解RoPE
想象一下,你有一个12小时的时钟:
1. 基本类比
词向量 = 时针指向的位置(比如3点钟方向)
位置信息 = 把时针拨动一定的角度
相对位置 = 两个时钟时针之间的角度差
2. 具体例子
假设我们有两个词:
第一个词在位置1:它的时针原本指向3点,我们把它顺时针拨动1个小时(30度)
第二个词在位置4:它的时针原本指向3点,我们把它顺时针拨动4个小时(120度)
现在计算它们的「注意力关系」:
位置1的词:时针在4点方向(30度)
位置4的词:时针在7点方向(120度)
它们的角度差是90度,这正好是位置差(4-1=3小时)的90度
关键点:注意力分数只取决于两个指针的角度差(相对位置),而不是它们各自的绝对时间。
二、RoPE在做什么?(三步理解)
第一步:把词向量变成「指针」
每个词原本是一个数字向量(比如0.3, -0.2, 0.7, ...)
RoPE把这个向量分成一对一对的,每对看成一个「指针」的坐标
比如把0.3, -0.2看成一个指针,0.3是x坐标,-0.2是y坐标
第二步:根据位置旋转指针
位置1:所有指针旋转一个小角度
位置2:所有指针旋转两倍的小角度
位置3:所有指针旋转三倍的小角度
依此类推...
第三步:计算注意力时自然包含位置信息
当计算两个词的「相关性」时(内积)
实际上计算的是两个旋转后指针的相似度
旋转角度差自动包含了位置差信息
三、为什么这么设计?
1. 解决了什么问题?
传统的Transformer需要显式地告诉模型:「这是第一个词,这是第二个词...」
方法:给每个词加一个位置编号(位置编码)
问题:模型要花精力学习「如何理解这些编号」
RoPE的思路:「不要让模型去理解编号,而是让位置直接影响计算过程」
2. 类比:跳舞的队伍
想象一个舞蹈队形:
每个舞者(词)有固定的动作(词向量)
根据他们站的位置(位置),调整动作的朝向(旋转)
当两个舞者互动时(计算注意力),他们动作的匹配度自然包含了距离信息
离得近的舞者(位置差小) → 动作朝向相似 → 互动分数高
离得远的舞者(位置差大) → 动作朝向不同 → 互动分数低
四、RoPE的三个关键特性
1. 相对性(最重要的)
注意力分数只依赖于两个词的位置差,而不是绝对位置。
例子:
位置5和位置8的注意力分数
位置105和位置108的注意力分数
如果位置差都是3,这两个分数理论上是相同的
这让模型能更好地理解「距离」概念。
2. 外推性(可以处理更长的文本)
因为旋转是连续的,即使遇到训练时没见过的位置(比如第10000个词),我们也能知道该怎么旋转指针。
就像你知道:
旋转1小时是30度
旋转100小时就是3000度(虽然钟表上回到了相同位置,但角度值是知道的)
3. 保持距离不变
旋转不会改变指针的长度,只改变方向。
就像你旋转一个钟表的时针,它的长度不变
这保证了数值的稳定性
五、生活中的类比
类比1:座位安排
想象一个圆桌会议:
每个人(词)有固定的观点(词向量)
根据座位号(位置),稍微调整一下观点的表达角度(旋转)
当两个人交流时,他们观点的匹配度自然包含了「他们坐得多远」的信息
类比2:拼图游戏
每个拼图片(词)有自己的图案(词向量)
根据它在拼图中的位置,旋转一定角度
当两片拼图靠近时,旋转角度差小,容易拼接
当两片拼图离得远时,旋转角度差大,不容易拼接
六、实际应用中的简单理解
对大语言模型的意义:
知道词序:让模型明白「猫追老鼠」和「老鼠追猫」是不同的
理解距离:让模型知道「不...好」中间隔一个词和隔十个词的区别
处理长文本:即使文章很长,也能保持位置关系的合理性
为什么现在的大模型都用它?
简单有效:计算不复杂,效果很好
长度灵活:理论上可以处理无限长的文本
理论优美:数学性质漂亮,有保证
七、可视化理解
想象一个二维平面,每个词是一个点:
初始位置: 旋转后(位置1): 旋转后(位置2): A A' (旋转10度) A'' (旋转20度) • ↗ ↗↗ B B' (旋转10度) B'' (旋转20度) • ↗ ↗↗计算A和B的相关性:
原始:直接计算A和B的相似度
RoPE:计算A'和B'的相似度(包含了位置1的信息)
或者计算A''和B''的相似度(包含了位置2的信息)
关键是:A'和B'的相似度 与 A''和B''的相似度 是一样的,因为它们的相对角度没变。
总结一下最核心的理解:
RoPE就是把每个词向量想象成很多小指针,然后根据词的位置旋转这些指针。当计算两个词的相关性时,旋转的角度差自动包含了它们的位置距离信息。
这样:
模型不需要学习位置编码,位置信息直接融入计算
天然理解相对位置,位置差3永远意味着相同的旋转角度差
处理长文本能力强,旋转可以无限继续
3.1.2.4 如何理解