*一维码的读取:
•创建一维条形码识别模型:create_bar_code_model ()
•设置一维条形码识别模型的参数:set_bar_code_param()
•在图像中查找并识别一维条形码:find_bar_code()
•获取一维条形码识别的详细结果:get_bar_code_result()
•查询图形窗口支持的字体列表:query_font()
•设置图形窗口的字体样式:set_font()
•清除一维条形码句柄:clear_bar_code_model()
cs
*// 关闭实时更新
dev_update_off ()
*// 获取图像
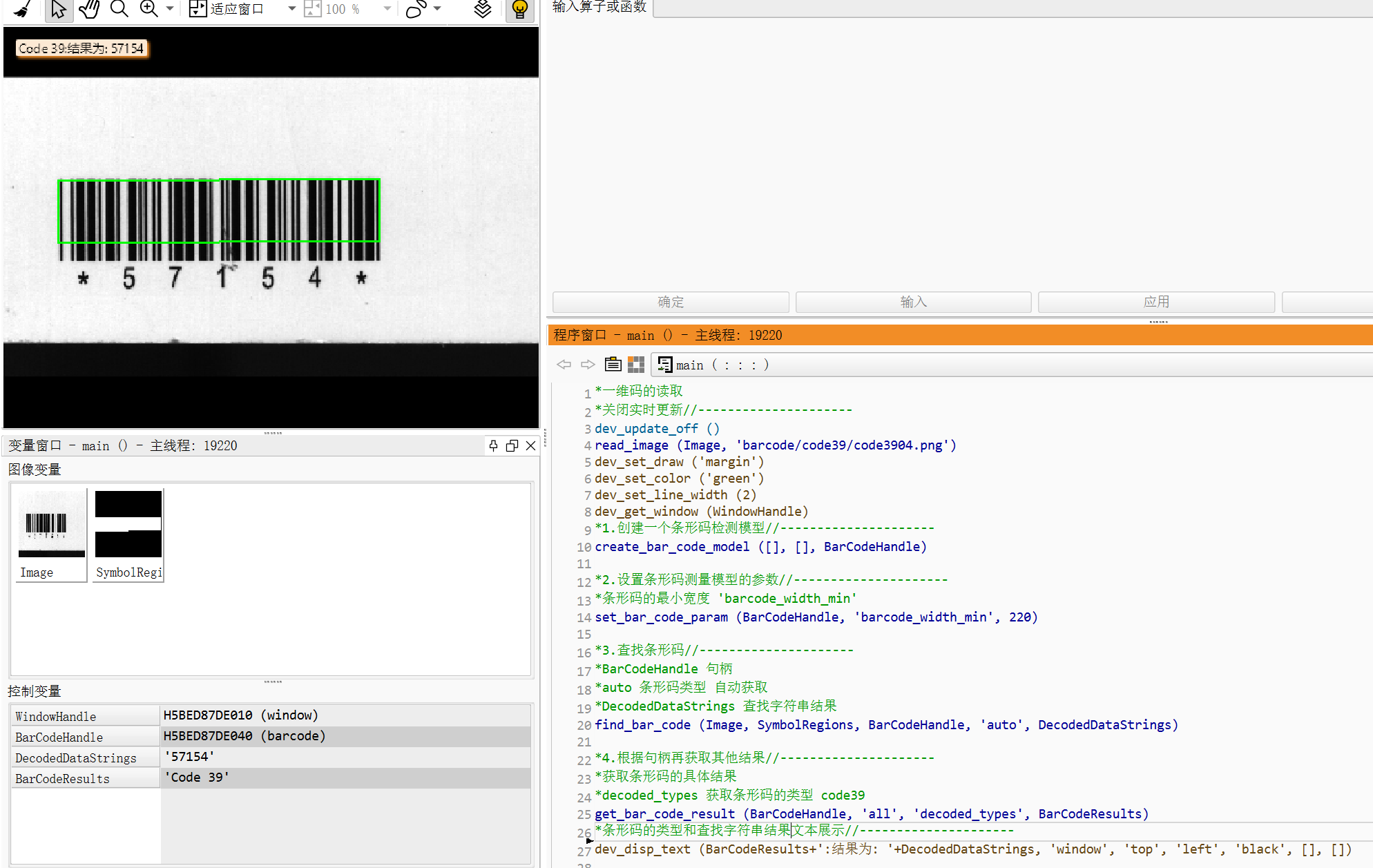
read_image (Image, 'barcode/code39/code3904.png')
*// 设置填充模式
dev_set_draw ('margin')
*// 设置颜色
dev_set_color ('green')
*// 设置线宽
dev_set_line_width (2)
*// 获取窗体句柄
dev_get_window (WindowHandle)
*// 1.创建一个条形码检测模型
create_bar_code_model ([], [], BarCodeHandle)
*// 2.设置条形码测量模型的参数
*// 条形码的最小宽度 'barcode_width_min'
set_bar_code_param (BarCodeHandle, 'barcode_width_min', 220)
*// 3.查找条形码
*// BarCodeHandle 句柄
*// auto 条形码类型 自动获取
*// DecodedDataStrings 查找字符串结果
find_bar_code (Image, SymbolRegions, BarCodeHandle, 'auto', DecodedDataStrings)
*// 4.根据句柄再获取其他结果
*// 获取条形码的具体结果
*// decoded_types 获取条形码的类型 code39
get_bar_code_result (BarCodeHandle, 'all', 'decoded_types', BarCodeResults)
*// 展示原图
dev_display (Image)
*// 条形码的类型和查找字符串结果文本展示
dev_disp_text (BarCodeResults+':结果为: '+DecodedDataStrings, 'image', 12, 12, 'black', [], [])*批量条码检测_含未检测到条码处理:
code39:属于非定长 离散型的条形码 一般适用于工业、物流、图书编号 包括:数字(0~9)、大写字母(A~Z)、特殊字符(+-/%)等
code32:属于code39的子集 一般适用于医疗行业 药品的标识 数字(0~9)
2/5 interved:交错条形码 一般适用于仓库、物流 仅限数字:只能编码数字 (0-9),不能编码字母或符号 高密度:由于是交错编码,它在数字条形码中相对紧凑 需要校验码:通常使用一个模 10 的校验码来确保数据准确性 可变长度:可以编码偶数位长度的数据(因为数字是成对编码的)
•查找元素在元组中的位置(索引) 不存在显示-1:tuple_find
•比较两个对象是否相等:test_equal_obj
•将 Code 39 格式的解码字符串转换为 Code 32 格式:convert_decoded_string_code39_to_code32
cs
*// 获取窗体句柄
dev_get_window (WindowHandle)
*// 获取当前窗体支持的字体类型
query_font (WindowHandle, Font)
*// 查找元素是否存在元组当中 不存在显示-1
tuple_find (Font, '新宋体', Indices)
*// 判断
if (Indices!=-1)//元素存在
*// 设置字体
*// set_font (WindowHandle, Font)
set_display_font (WindowHandle, 16, '新宋体', 'true', 'false')
else
set_display_font (WindowHandle, 16, 'mono', 'true', 'false')
endif
*// 创建一个条形码检测模型
create_bar_code_model ([], [], BarCodeHandle)
*// 设置条形码测量模型的参数
*// 条形码的最小宽度 'barcode_width_min'
set_bar_code_param (BarCodeHandle, 'barcode_width_min', 220)
*// 条形码的最小高度 'barcode_height_min'
set_bar_code_param (BarCodeHandle, 'barcode_height_min', 30)
*// 读取路径下的所有资源
list_files ('E:/桌面/演示素材/图片集/条形码', 'files', Files)
*// 通过正则表达式来进行筛选元组
*// '.*'代表所有的
*// '.(jpg|png|bmp)' 正则表达式字符串
tuple_regexp_select (Files, '.(jpg|png|bmp)', Selection)
*// 创建一个空对象
gen_empty_obj (EmptyObject)
*// 设置填充模式
dev_set_draw ('margin')
*// 循环遍历所有图片
for Index := 0 to |Selection|-1 by 1
*// 读取图片
read_image (Image,Selection[Index])
*// 查找条形码
*// BarCodeHandle 句柄
*// auto 条形码类型 自动获取
*// DecodedDataStrings 查找字符串结果
find_bar_code (Image, SymbolRegions, BarCodeHandle, 'auto', DecodedDataStrings)
*// 比较两个对象是否相等
test_equal_obj (EmptyObject, SymbolRegions, IsEqual)
*// 判断两个对象相等/不相等
if (IsEqual)
dev_display (Image)
dev_disp_text ('未找到条形码', 'window', 'top', 'left', 'black', [], [])
else
dev_display (Image)
dev_display (SymbolRegions)
*// 获取条形码的具体结果
*// 参数1 条形码处理句柄
*// 参数2 所有识别到的条形码
*// 参数3 解码后的条码类型
*// 参数4 输出参数
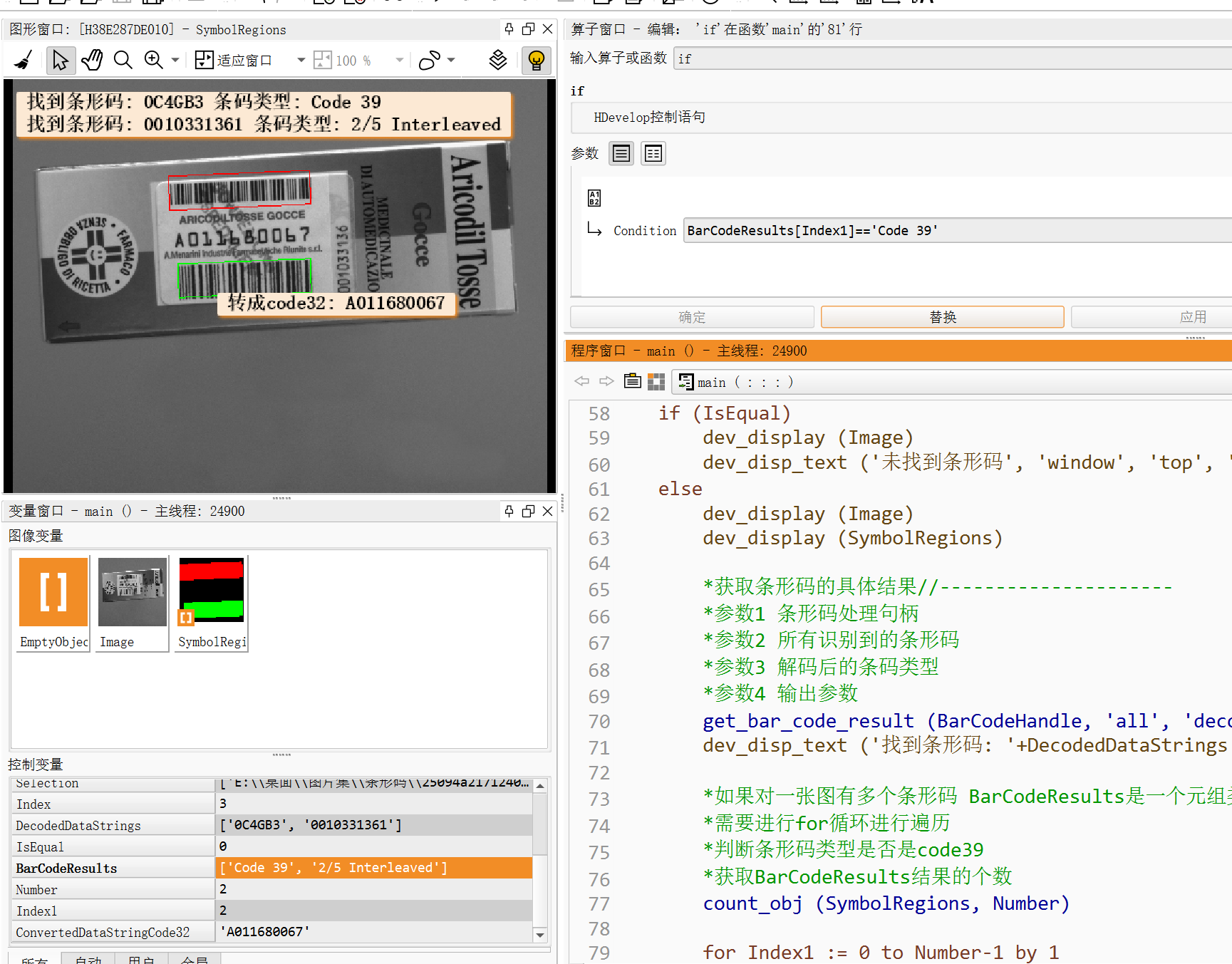
get_bar_code_result (BarCodeHandle, 'all', 'decoded_types', BarCodeResults)
dev_disp_text ('找到条形码: '+DecodedDataStrings +' 条码类型: '+BarCodeResults, 'window', 'top', 'left', 'black', [], [])
*// 如果对一张图有多个条形码 BarCodeResults是一个元组类型
*// 需要进行for循环进行遍历
*// 判断条形码类型是否是code39
*// 获取BarCodeResults结果的个数
count_obj (SymbolRegions, Number)
for Index1 := 0 to Number-1 by 1
if (BarCodeResults[Index1]=='Code 39')
*// 把code39类型转成code32
convert_decoded_string_code39_to_code32 (DecodedDataStrings[Index1], ConvertedDataStringCode32)
dev_disp_text ('转成code32: '+ConvertedDataStringCode32, 'window', 200, 200, 'black', [], [])//'A011680067' A是校验码
endif
endfor
endif
stop ()
endfor*兼容多种二维码识别:
•创建二维条形码识别模型:create_data_code_2d_model()
•设置二维条形码模型参数:set_data_code_2d_param()
•查找并识别二维码:find_data_code_2d ()
•获取二维条形码的结果:get_data_code_2d_results()
•由 XLD 轮廓生成区域:gen_region_contour_xld ()
•清除二维条形码句柄:clear_data_code_2d_model()
cs
*// 清空窗口
dev_clear_window ()
*// 创建条码模型的通用方法
*// 参数1 条码的类型
*// 'Data Matrix ECC 200'数据矩阵码简称D码 (L型)
create_data_code_2d_model ('Data Matrix ECC 200', [], [], DataCodeHandle)
*// 创建一个QR码 'QR Code' (回字型)
create_data_code_2d_model ('QR Code', [], [], DataCodeHandle1)
*// 创建一个PDF417码 'PDF417' 是一种高容量的二维堆叠式条码符号制式
create_data_code_2d_model ('PDF417', [], [], DataCodeHandle2)
*// 默认读取图片资源
list_image_files ('E:/桌面/演示素材/图片集/二维码', 'default', [], ImageFiles)
*// 通过正则表达式来进行筛选元组
*// 如果过滤的条件是多个条件 可以使用一个元组表示多个条件集合
*// .(jpg|png) 筛选字符串包含.png和.jpg的字符串
*// 'ignore_case' 不管大小写
*// Selection 筛选之后的图片
tuple_regexp_select (ImageFiles, ['.(jpg|png)','ignore_case'], Selection)
*// 获取窗体句柄
dev_get_window (WindowHandle)
*// 遍历所有图片
for Index := 0 to |Selection|-1 by 1
read_image (Image, Selection[Index])
*// 查找数据矩阵码D码
*// 参数3 查找码的句柄
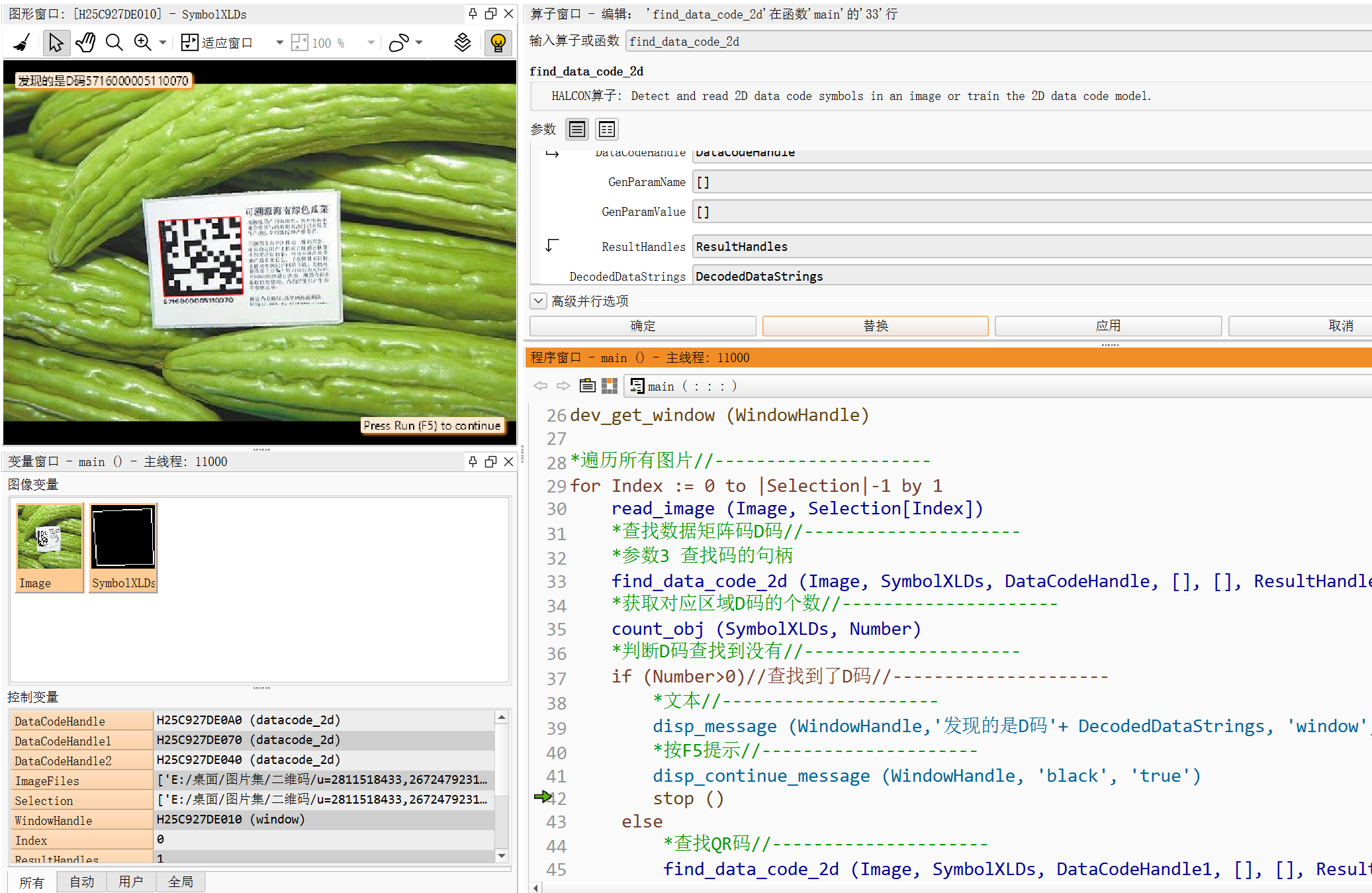
find_data_code_2d (Image, SymbolXLDs, DataCodeHandle, [], [], ResultHandles, DecodedDataStrings)
*// 获取对应区域D码的个数
count_obj (SymbolXLDs, Number)
*// 显示图像
dev_display (Image)
*// 判断D码查找到没有
if (Number>0)//查找到了D码
*// 显示文本提示
disp_message (WindowHandle,'发现的是D码'+ DecodedDataStrings, 'window', 12, 12, 'black', 'true')
*// 按F5提示继续
disp_continue_message (WindowHandle, 'black', 'true')
stop ()
else
*// 未找到D码,查找QR码
find_data_code_2d (Image, SymbolXLDs, DataCodeHandle1, [], [], ResultHandles, DecodedDataStrings)
*// 获取对应区域QR码的个数
count_obj (SymbolXLDs, Number1)
*// 判断QR码查找到没有
if (Number1>0)//查找到了QR码
disp_message (WindowHandle,'发现的是QR码'+ DecodedDataStrings, 'window', 12, 12, 'black', 'true')
*// 按F5提示继续
disp_continue_message (WindowHandle, 'black', 'true')
stop ()
else
*// 未找到QR码,查找PDF417码
find_data_code_2d (Image, SymbolXLDs, DataCodeHandle2, [], [], ResultHandles, DecodedDataStrings)
*// 获取对应区域PDF417码的个数
count_obj (SymbolXLDs, Number2)
*// 判断PDF417码查找到没有
if (Number2>0)//查找到了PDF417码
disp_message (WindowHandle,'发现的是PDF417码'+ DecodedDataStrings, 'window', 12, 12, 'black', 'true')
*// 按F5提示继续
disp_continue_message (WindowHandle, 'black', 'true')
stop ()
endif
endif
endif
endfor*OCR字符提取:
OCR整体流程
-
区域提取:分割图像中单个字符的独立区域(核心:保证每个字符对应一个区域)
-
加载分类器:读取预训练的MLP字符分类模型(.omc格式)
-
字符识别:调用单字符/多字符识别算子获取结果
-
结果处理:显示识别结果 + 释放分类器句柄(避免内存泄漏)
分类器类型说明
-
Reject分类器:匹配度不足时返回"reject",避免错误识别(如Document_0-9_Rej.omc)
-
NoReject分类器:匹配度不足时强制匹配最相似字符,无"reject"结果(如Industrial_0-9A-Z_NoRej.omc)
分类器实现方式
-
可视化助手生成:通过Halcon OCR助手标注字符、训练,导出.omc文件(新手推荐)
-
纯代码构建:
-
create_ocr_class_mlp():构建MLP分类模型
-
train_class_mlp():训练模型
-
write_ocr_class_mlp():保存模型到本地
-
read_ocr_class_mlp():加载本地模型
-
clear_ocr_class_mlp():释放模型句柄(工程化必备)
识别算子区别
-
do_ocr_single_class_mlp:逐区域识别单个字符,便于调试/逐字符显示
-
do_ocr_multi_class_mlp:批量识别所有区域,效率更高(批量处理推荐)
•灰度范围矩形滤波:gray_range_rect()
•单字符识别:do_ocr_single_class_mlp()

cs
*// ====================== 初始化配置 ======================
*// 读取示例图像(雕刻字符图像)
read_image (Image, 'engraved')
*// 获取图像宽高(保留用于扩展,如窗口自适应)
get_image_size (Image, Width, Height)
*// 获取显示窗口句柄
dev_get_window (WindowHandle)
*// 设置显示参数:区域仅画边缘、轮廓颜色为绿色
dev_set_draw ('margin')
dev_set_color ('green')
dev_clear_window () // 清空窗口,避免残留内容
dev_display (Image) // 显示原始图像
stop () // 调试:查看原始图像
*// ====================== 图像预处理(增强字符对比度) ======================
*// 7x7矩形窗口灰度范围滤波:计算窗口内最大-最小灰度值,增强字符与背景差异
gray_range_rect (Image, ImageResult, 7, 7)
*// 图像反转:满足OCR"白色背景、黑色字符"的识别要求(核心预处理步骤)
invert_image (ImageResult, ImageInvert)
dev_display (ImageResult) // 显示滤波后图像
stop () // 调试:查看滤波结果
*// ====================== 字符区域分割(核心:分离单个字符) ======================
*// 二值化:分割灰度值128~255的区域(字符区域)
threshold (ImageResult, Region1, 128, 255)
*// 连通域分析:拆分独立字符候选区域
connection (Region1, ConnectedRegions)
*// 面积筛选:过滤噪点小区域,保留2000~99999像素的有效字符区域
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 2000, 99999)
dev_display (SelectedRegions) // 显示筛选后字符区域
stop () // 调试:查看分割结果
*// ====================== 字符区域排序(保证从左到右识别) ======================
*// 按区域左上角点的列坐标升序排序,避免字符识别顺序错乱
*// 参数说明:
*// - 'first_point':排序参考点(区域左上角)
*// - 'true':升序(从左到右)
*// - 'column':排序维度(列坐标)
sort_region (SelectedRegions, SortedRegions, 'first_point', 'true', 'column')
dev_display (SortedRegions) // 显示排序后字符区域
stop () // 调试:查看排序结果
*// ====================== 区域坐标计算(用于文本显示定位) ======================
*// 将字符区域转为最小外接矩形,便于计算中心坐标
shape_trans (SortedRegions, RegionTrans, 'rectangle1')
*// 计算每个矩形区域的面积和中心坐标(Row/Column为数组,对应各区域中心)
area_center (RegionTrans, Area, Row, Column)
*// 计算所有区域中心行坐标的平均值,统一文本显示的行位置
meanRow := mean(Row)
*// ====================== OCR字符识别 ======================
*// 加载内置工业级NoReject分类器(支持0-9、A-Z字符)
read_ocr_class_mlp ('Industrial_0-9A-Z_NoRej.omc', OCRHandle)
*// 统计排序后字符区域数量
count_obj (SortedRegions, Number)
*// 1. 单字符遍历识别(调试专用,逐字符查看结果)
dev_display (ImageInvert) // 显示反转后图像(OCR识别的源图像)
for Index := 1 to Number by 1
*// 取出第Index个字符区域
select_obj (SortedRegions, ObjectSelected, Index)
*// 单字符识别:返回最匹配的1个结果
do_ocr_single_class_mlp (ObjectSelected, ImageInvert, OCRHandle, 1, Class, Confidence)
*// 在字符区域中心附近显示识别结果(行:平均行+80,列:区域中心列-10)
disp_message (WindowHandle, Class, 'image', meanRow+80, Column[Index-1]-10, 'black', 'true')
stop () // 调试:逐字符查看识别结果
endfor
*// 2. 多字符批量识别(效率更高,批量处理推荐)
do_ocr_multi_class_mlp (SortedRegions, ImageInvert, OCRHandle, ClassAll, ConfidenceAll)
*// 显示批量识别结果(行:平均行+120,列:第一个区域中心列-10)
disp_message (WindowHandle, '批量识别结果:' + ClassAll, 'image', meanRow+120, Column[0]-10, 'black', 'true')
stop () // 调试:查看批量识别结果
*// ====================== 资源释放(工程化必备) ======================
*// 释放OCR分类器句柄,避免内存泄漏
clear_ocr_class_mlp (OCRHandle)
*// 恢复默认显示颜色
dev_set_color ('green')
*// 最终提示
disp_message (WindowHandle, 'OCR识别完成!', 'window', 'bottom', 'left', 'black', 'true')希望对大家有所帮助, 感谢大家的关注和点赞。