在数字化时代,企业级应用对数据库的并发能力、存储效率和高可用性要求日益严苛。PostgreSQL 作为热门开源数据库,在超大规模业务场景中仍面临并发连接瓶颈、存储空间膨胀等问题,而 MySQL 虽普及度高,却在复杂事务和高并发峰值场景下存在性能短板。天翼云开源的 OpenTeleDB 作为全球首个运营商级开源 OLTP 数据库,基于 PostgreSQL 17 深度优化,通过三大自研组件攻克了传统开源数据库的核心痛点。本文将从 OpenTeleDB 的概念解析入手,分享宝塔面板部署该数据库的实操经验,详解 MySQL 项目迁移的完整流程,并深入分析其核心特性,为企业技术选型与系统升级提供参考。
一.什么是OpenTeleDB
OpenTeleDB 是天翼云基于 PostgreSQL 17 深度开发的企业级开源关系型数据库,也是全球首个运营商级开源 OLTP(在线事务处理)数据库。它采用木兰宽松许可证 v2 发行,既完美兼容 PostgreSQL 生态,又针对传统开源数据库在企业级场景中的痛点进行了突破性优化,历经中国电信内部数万系统的实战打磨,适用于金融交易、政务服务、电商秒杀等对性能和稳定性要求严苛的场景。其核心价值集中体现在三大自研组件,XProxy 连接池组件、XStore 存储引擎、XRaft 高可用组件。
此外,OpenTeleDB 的兼容性优势显著,支持 PL/pgSQL 存储过程,还能兼容 pg_dump 等标准工具及 PostGIS 等常用扩展,让基于 PostgreSQL 的业务系统无需重构代码即可无缝迁移。同时它也提供适配工具,可支持 MySQL、Oracle 等异构数据库的平滑迁移,大幅降低企业迁移成本。
二.服务器部署 OpenTeleDB 实战(Debian 11 × 宝塔面板运维)
在实际生产或测试环境中,OpenTeleDB 通常需要部署在资源受限的云服务器上。本节将以一台 2 核 4G 的 Debian 11(bullseye)服务器为例,从源码编译开始,完整演示 OpenTeleDB 的部署流程,并重点记录编译过程中遇到的依赖问题及解决思路,避免"踩坑式"部署。
2.1 环境说明
服务器环境
- 操作系统:Debian GNU/Linux 11(bullseye)
- 架构:x86_64
- 服务器配置:2 Core / 4 GB RAM
- 管理工具:宝塔面板(仅用于基础运维,不参与编译过程)
软件环境
- OpenTeleDB
- 编译方式:源码编译安装
- 运行用户:非 root 用户(推荐做法)
2.2 获取 OpenTeleDB 源码
在服务器上创建工作目录并克隆 OpenTeleDB 仓库:OpenTeleDB
cd ~
git clone https://github.com/TeleDB/OpenTeleDB.git
cd OpenTeleDB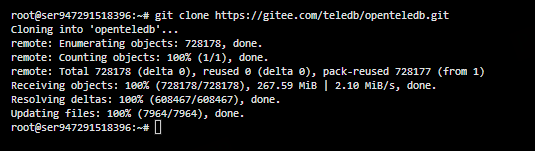
确认仓库结构正常,根目录中包含 configure、Makefile.in 等文件,说明这是一个标准的 PostgreSQL 源码派生项目。

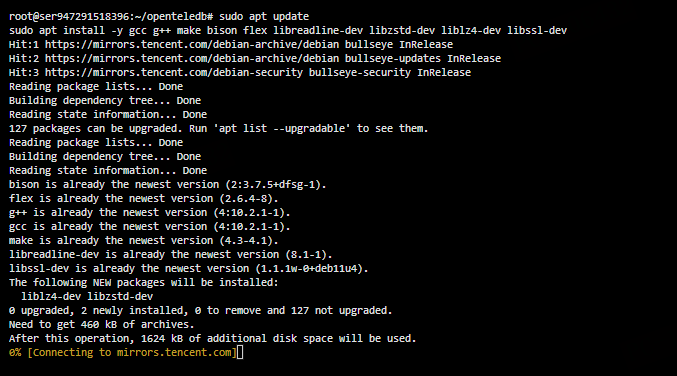
2.3 安装编译依赖
OpenTeleDB 的编译依赖与 PostgreSQL 高度一致,在 Debian 11 上可以直接通过 apt 安装。
可通过以下命令安装表中所需的软件依赖
sudo apt update
sudo apt install -y \
gcc g++ make \
bison flex \
libreadline-dev \
libzstd-dev \
liblz4-dev \
libssl-dev说明
bison / flex:用于 SQL 解析器生成libreadline-dev:psql 交互体验zstd / lz4:高效压缩支持libssl-dev:TLS / SSL 连接支持
2.4 configure 编译配置
设置安装目录(可根据实际情况调整):
export pg_install_dir=/usr/local/pgsql执行 configure:
./configure \
--prefix=${pg_install_dir} \
--with-libxml \
--with-uuid=ossp \
--with-openssl \
--with-xstore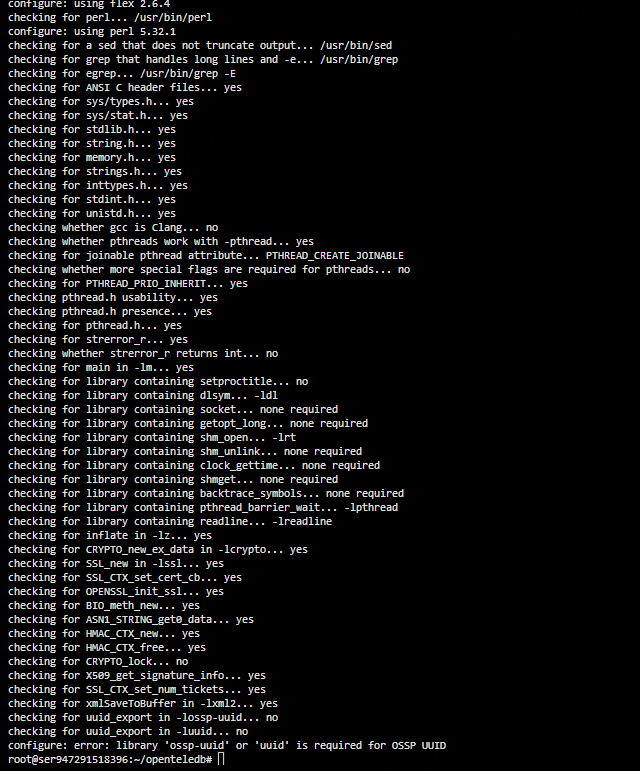
此步骤会对系统环境进行全面检测,并生成最终的 Makefile。
2.5 编译报错与问题定位
在实际执行过程中,直接运行 make 会出现如下错误:
You need to run the 'configure' program first.
Please see <https://www.postgresql.org/docs/17/installation.html>
make: *** [Makefile:21: all] Error 1
root@ser947291518396:~/openteledb# make && make install
You need to run the 'configure' program first. Please see
<https://www.postgresql.org/docs/17/installation.html>
make: *** [Makefile:21: all] Error 1
root@ser947291518396:~/openteledb# make && make install
You need to run the 'configure' program first. Please see
<https://www.postgresql.org/docs/17/installation.html>
make: *** [Makefile:21: all] Error 1表象分析
- 明明已经执行了
./configure - 但
make仍然提示未运行 configure
深层原因
查看 configure 的输出日志后,可以发现真正的错误是:
configure: error: library 'ossp-uuid' or 'uuid' is required也就是说:
configure 并未成功完成,而是因为 UUID 依赖缺失提前失败,导致 Makefile 未正确生成。
2.6 解决 UUID 依赖问题(正确姿势)
在 Debian 系统中,推荐使用 系统自带的 uuid 库,兼容性更好。
sudo apt update
sudo apt install -y uuid-dev
安装完成后,必须重新执行 configure:
./configure \
--prefix=${pg_install_dir} \
--with-libxml \
--with-uuid=ossp \
--with-openssl \
--with-xstore确认 configure 以 无 error 方式结束,再进行下一步。
2.7 编译与安装
make -j$(nproc)
make install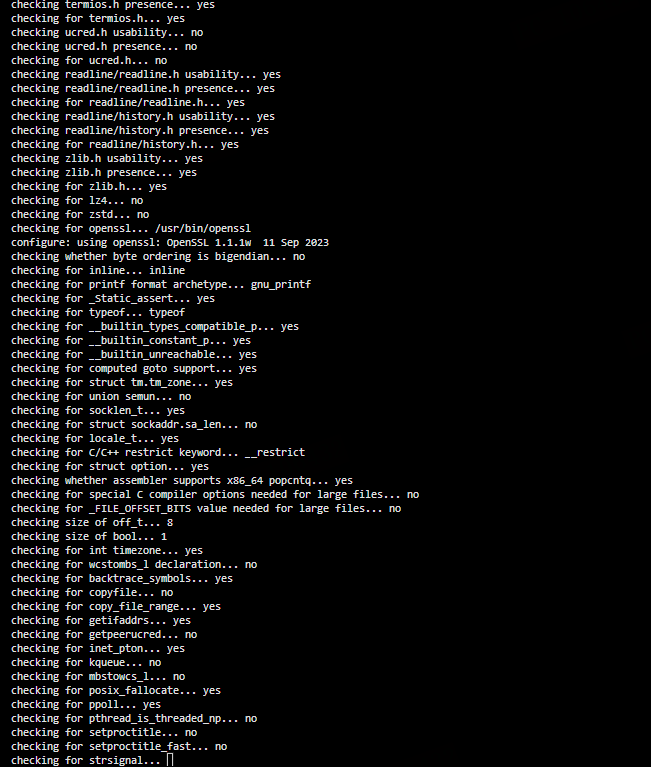
若终端开始持续输出编译信息,且无 error 中断,说明 OpenTeleDB 已成功编译并安装到指定目录。
2.8 初始化 OpenTeleDB 数据库
创建专用运行用户(推荐)
useradd -m postgres
不建议使用 root 直接运行数据库进程,这是 PostgreSQL 系列的最佳实践。
设置环境变量
export PATH=/usr/local/pgsql/bin:$PATH
export PGDATA=/opt/openteledb_data创建数据目录并授权:
mkdir -p /opt/openteledb_data
chown -R postgres:postgres /opt/openteledb_data初始化数据库
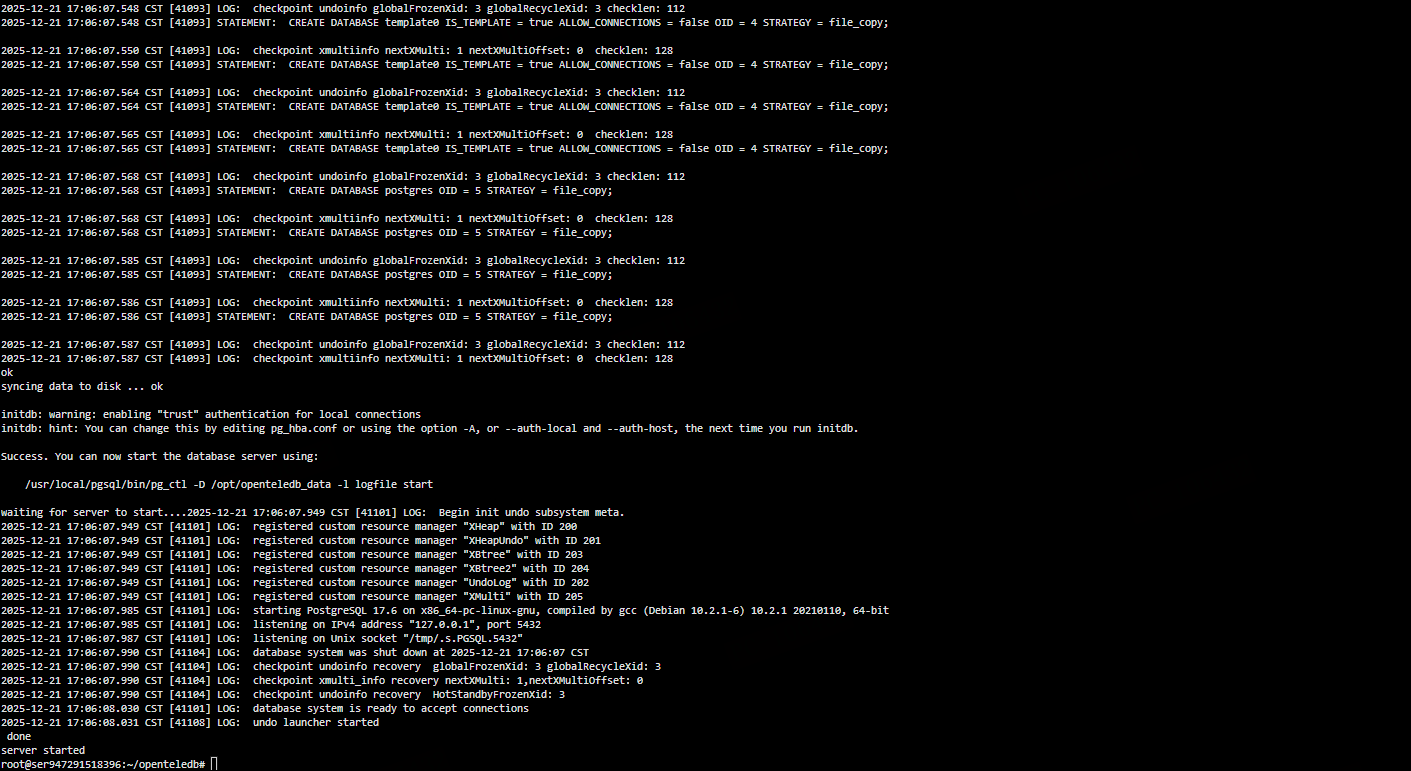
su - postgres
initdb -D /opt/openteledb_data启动 OpenTeleDB
pg_ctl -D /opt/openteledb_data start若终端输出:
server started
则说明 OpenTeleDB 已成功启动。
本章从零开始,在 Debian 11 + 低配云服务器环境下,完整演示了 OpenTeleDB 的源码编译与部署流程。重点经验包括:
make报错并不一定是 make 的问题,configure 失败是常见根因- UUID 依赖是 PostgreSQL 系列源码编译中最容易忽略的关键点
- 编译类问题一定要从 configure 日志开始排查
- 使用非 root 用户运行数据库是生产环境基本要求
至此,OpenTeleDB 的基础服务已经成功运行.
三.原有项目Mysql迁移OpenTeleDB实战
在完成 OpenTeleDB 服务端部署后,下一步就是将已有业务系统的数据从 MySQL 迁移到 OpenTeleDB。 本章以一个商业辅助决策系统 为Demo案例,完整演示 表结构迁移、SQL 兼容性改造、数据导出与导入 的全过程。
3.1 原有项目背景说明
项目类型 :商业辅助决策系统 原数据库:MySQL
OpenTeleDB 基于 PostgreSQL 内核,在 事务一致性、SQL 标准化、分析扩展能力 方面更具优势,适合作为该系统的后续演进数据库。
MySQL数据库表结构如下:
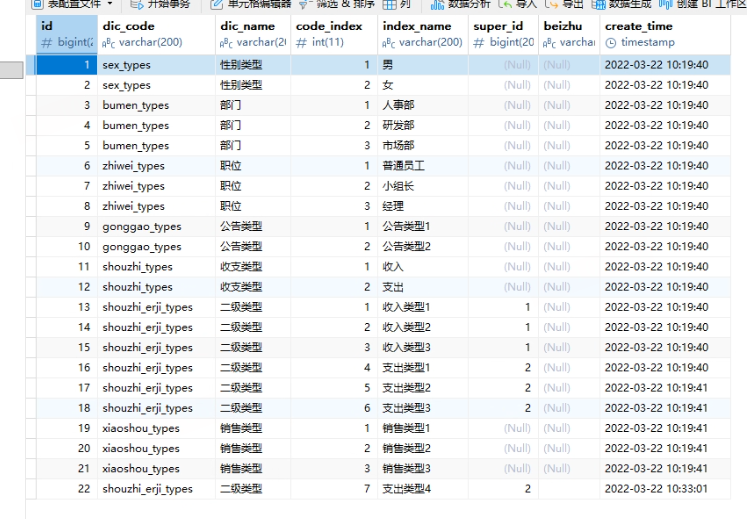
数据如下
3.2 服务器登录查看Mysql数据库
SHOW DATABASES;
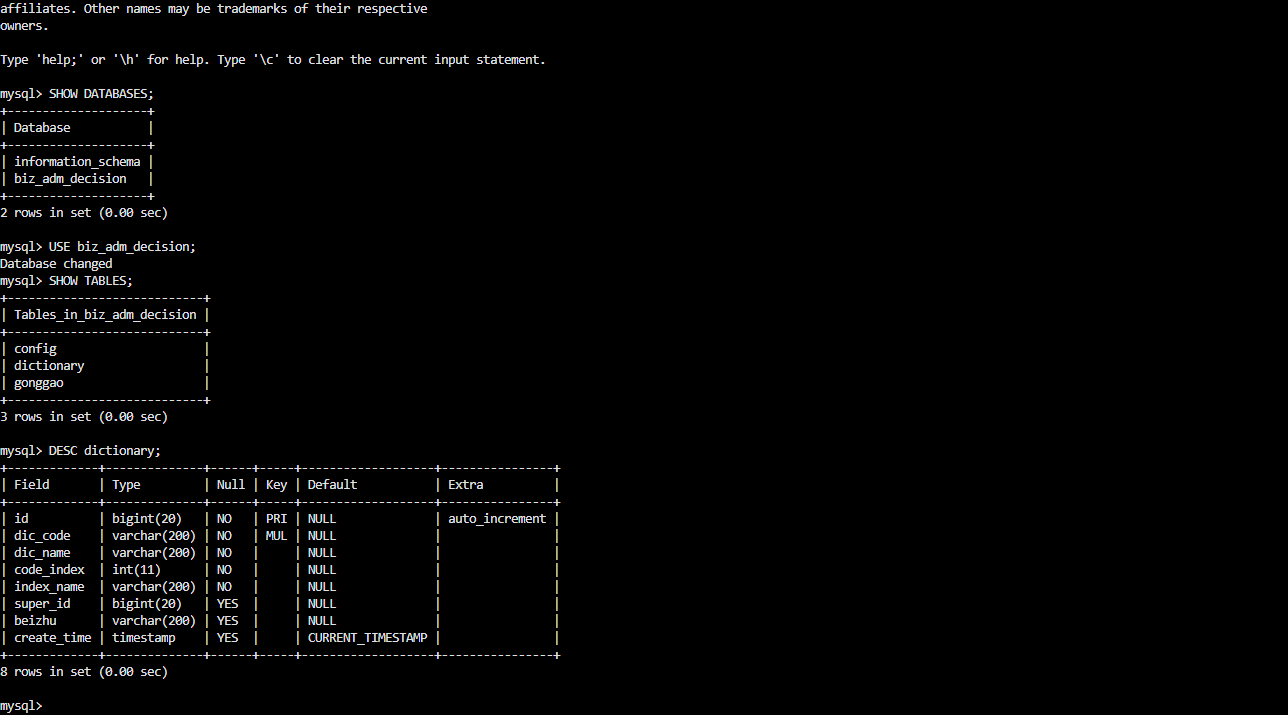
查看表数据量(评估迁移规模)
SELECT
table_name,
table_rows
FROM information_schema.tables
WHERE table_schema = 'biz_adm_decision';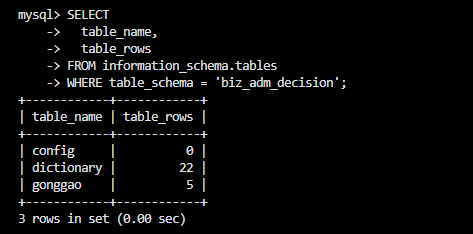
3.3 迁移路线
我们采用 "数据导出 + OpenTeleDB****导入" 的标准路线:
MySQL
├── 数据导出(INSERT / COPY)
↓
OpenTeleDB
├── 建库
├── 建表
├── 导入数据
3.4 Mysql 数据导出
先把本地的mysql数据库中的所有表结构和数据导出,执行下面命令。
root@ser947291518396:~# /www/server/mysql/bin/mysqldump -u biz_adm_decision -p biz_adm_decision \
--host=127.0.0.1 --port=3306 \
--skip-lock-tables \
--default-character-set=utf8 \
--routines=FALSE --triggers=FALSE \
--no-tablespaces \
--result-file=/root/biz_adm_decision.sql
Enter password:
root@ser947291518396:~#/root/biz_adm_decision.sql 会包含所有表结构和数据
查看 SQL 文件内容
less /root/biz_adm_decision.sql
3.5 完整迁移脚本
编辑脚本
nano /root/biz_adm_decision_pg.sql
编写OpenTeleDB 完整迁移脚本
-- ==============================================
-- OpenTeleDB 完整迁移脚本
-- 数据库:biz_adm_decision
-- ==============================================
-- 1. config 表
DROP TABLE IF EXISTS config;
CREATE TABLE config (
id BIGSERIAL PRIMARY KEY,
config_key VARCHAR(100) NOT NULL UNIQUE,
config_value VARCHAR(500),
config_desc VARCHAR(200),
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- update_time 自动更新时间触发器
CREATE OR REPLACE FUNCTION update_config_modtime()
RETURNS TRIGGER AS $$
BEGIN
NEW.update_time = CURRENT_TIMESTAMP;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg_config_update
BEFORE UPDATE ON config
FOR EACH ROW
EXECUTE FUNCTION update_config_modtime();
-- 2. dictionary 表
DROP TABLE IF EXISTS dictionary;
CREATE TABLE dictionary (
id BIGSERIAL PRIMARY KEY,
dic_code VARCHAR(200) NOT NULL,
dic_name VARCHAR(200) NOT NULL,
code_index INT NOT NULL,
index_name VARCHAR(200) NOT NULL,
super_id BIGINT,
beizhu VARCHAR(200),
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(dic_code, code_index)
);
-- 3. gonggao 表
DROP TABLE IF EXISTS gonggao;
CREATE TABLE gonggao (
id SERIAL PRIMARY KEY,
gonggao_name VARCHAR(200) NOT NULL,
gonggao_photo VARCHAR(200),
gonggao_types INT NOT NULL,
insert_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
gonggao_content TEXT,
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- ==============================================
-- 数据插入
-- ==============================================
-- dictionary 数据
INSERT INTO dictionary(id,dic_code,dic_name,code_index,index_name,super_id,beizhu,create_time) VALUES
(1,'sex_types','性别类型',1,'男',NULL,NULL,'2022-03-22 10:19:40'),
(2,'sex_types','性别类型',2,'女',NULL,NULL,'2022-03-22 10:19:40'),
(3,'bumen_types','部门',1,'人事部',NULL,NULL,'2022-03-22 10:19:40'),
(4,'bumen_types','部门',2,'研发部',NULL,NULL,'2022-03-22 10:19:40'),
(5,'bumen_types','部门',3,'市场部',NULL,NULL,'2022-03-22 10:19:40'),
(6,'zhiwei_types','职位',1,'普通员工',NULL,NULL,'2022-03-22 10:19:40'),
(7,'zhiwei_types','职位',2,'小组长',NULL,NULL,'2022-03-22 10:19:40'),
(8,'zhiwei_types','职位',3,'经理',NULL,NULL,'2022-03-22 10:19:40'),
(9,'gonggao_types','公告类型',1,'公告类型1',NULL,NULL,'2022-03-22 10:19:40'),
(10,'gonggao_types','公告类型',2,'公告类型2',NULL,NULL,'2022-03-22 10:19:40'),
(11,'shouzhi_types','收支类型',1,'收入',NULL,NULL,'2022-03-22 10:19:40'),
(12,'shouzhi_types','收支类型',2,'支出',NULL,NULL,'2022-03-22 10:19:40'),
(13,'shouzhi_erji_types','二级类型',1,'收入类型1',1,NULL,'2022-03-22 10:19:40'),
(14,'shouzhi_erji_types','二级类型',2,'收入类型2',1,NULL,'2022-03-22 10:19:40'),
(15,'shouzhi_erji_types','二级类型',3,'收入类型3',1,NULL,'2022-03-22 10:19:40'),
(16,'shouzhi_erji_types','二级类型',4,'支出类型1',2,NULL,'2022-03-22 10:19:40'),
(17,'shouzhi_erji_types','二级类型',5,'支出类型2',2,NULL,'2022-03-22 10:19:41'),
(18,'shouzhi_erji_types','二级类型',6,'支出类型3',2,NULL,'2022-03-22 10:19:41'),
(19,'xiaoshou_types','销售类型',1,'销售类型1',NULL,NULL,'2022-03-22 10:19:41'),
(20,'xiaoshou_types','销售类型',2,'销售类型2',NULL,NULL,'2022-03-22 10:19:41'),
(21,'xiaoshou_types','销售类型',3,'销售类型3',NULL,NULL,'2022-03-22 10:19:41'),
(22,'shouzhi_erji_types','二级类型',7,'支出类型4',2,'','2022-03-22 10:33:01');3.6 执行迁移脚本
psql -U opentele_user -d biz_adm_decision -h localhost -p 5432 -W -f migration.sql这里记录一个报错
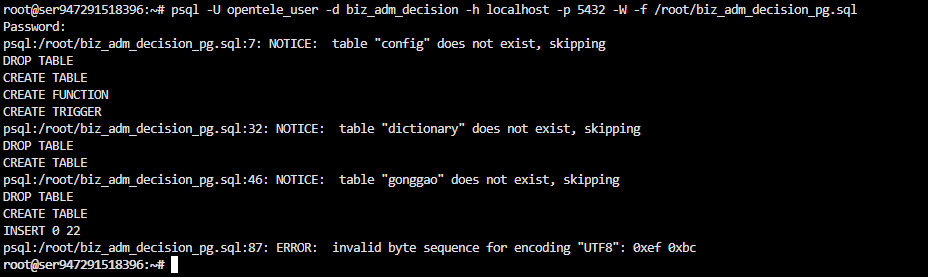
报错原因:
- 这是 MySQL 导出的 SQL 文件里有非 UTF-8 编码的字符 ,比如全角符号
( )或中文标点 - OpenTeleDB严格要求 UTF-8,如果 SQL 文件里有 非标准 UTF-8 字符 就会报错
3.7 重新导出 MySQL 数据解决报错
/www/server/mysql/bin/mysqldump -u biz_adm_decision -p biz_adm_decision \
--host=127.0.0.1 --port=3306 \
--skip-lock-tables \
--default-character-set=utf8mb4 \
--routines=FALSE --triggers=FALSE \
--no-tablespaces \
--result-file=/root/biz_adm_decision_utf8.sql
注意使用 utf8mb4,兼容所有中文/emoji/全角字符
再用脚本转换成 PostgreSQL SQL
3.8 迁移数据到OpenTeleDB
1️⃣ 确认原始 SQL 文件
之前生成的文件是:
/root/biz_adm_decision_pg.sql
先确认它存在:
ls -lh /root/biz_adm_decision_pg.sql
如果能看到文件大小说明存在。
2️⃣ 清理无效字符,生成 UTF-8 文件
iconv -f utf-8 -t utf-8 -c /root/biz_adm_decision_pg.sql -o /root/biz_adm_decision_pg_utf8.sql
-c会 删除非 UTF-8 字符- 生成文件
/root/biz_adm_decision_pg_utf8.sql
3️⃣ 执行迁移
psql -U opentele_user -d biz_adm_decision -h ``localhost`` -p 5432 -W -f /root/biz_adm_decision_pg_utf8.sql
- 输入密码
- PostgreSQL 会依次创建表、触发器并插入数据
记录执行命令
root@ser947291518396:~# /www/server/mysql/bin/mysqldump -u biz_adm_decision -p biz_adm_decision \
--host=127.0.0.1 --port=3306 \
--skip-lock-tables \
--default-character-set=utf8mb4 \
--routines=FALSE --triggers=FALSE \
--no-tablespaces \
--result-file=/root/biz_adm_decision_utf8.sql
Enter password:
root@ser947291518396:~# psql -U opentele_user -d biz_adm_decision -h localhost -p 5432 -W -f /root/biz_adm_decision_pg_utf8.sql
Password:
psql: error: /root/biz_adm_decision_pg_utf8.sql: No such file or directory
root@ser947291518396:~# ls -lh /root/biz_adm_decision_pg.sql
-rw-r--r-- 1 root root 3.6K Dec 23 22:03 /root/biz_adm_decision_pg.sql
root@ser947291518396:~# iconv -f utf-8 -t utf-8 -c /root/biz_adm_decision_pg.sql -o /root/biz_adm_decision_pg_utf8.sql
root@ser947291518396:~# psql -U opentele_user -d biz_adm_decision -h localhost -p 5432 -W -f /root/biz_adm_decision_pg_utf8.sql
Password:
DROP TABLE
CREATE TABLE
CREATE FUNCTION
CREATE TRIGGER
DROP TABLE
CREATE TABLE
DROP TABLE
CREATE TABLE
INSERT 0 22
root@ser947291518396:~#
说明:
- 三张表
config、dictionary、gonggao成功创建 dictionary表 插入了 22 条数据
MySQL 数据库已经 成功迁移到 OpenTeleDB(PostgreSQL)。
四.验证数据
可以在服务器上验证数据。
-- 登录 PostgreSQL
psql -U opentele_user -d biz_adm_decision -h localhost -p 5432 -W
-- 查看表
\dt
-- 查看数据数量
SELECT COUNT(*) FROM dictionary;
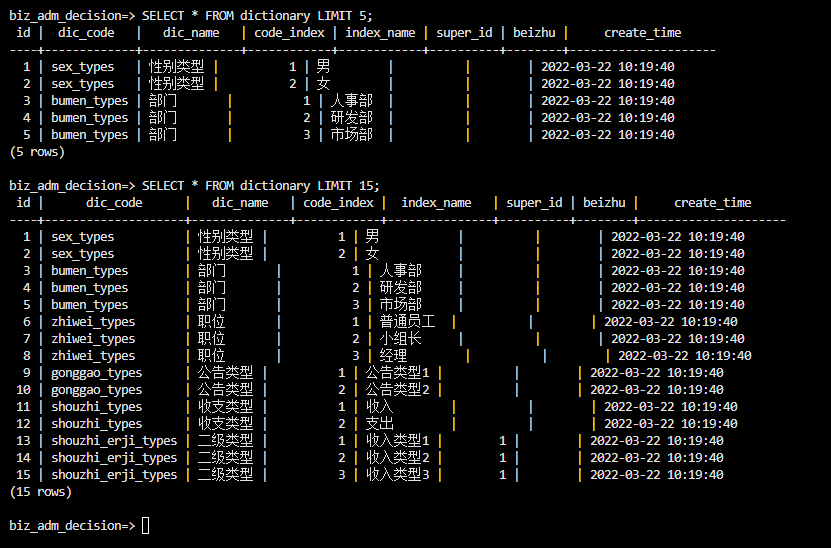
-- 查看具体数据
SELECT * FROM dictionary LIMIT 15;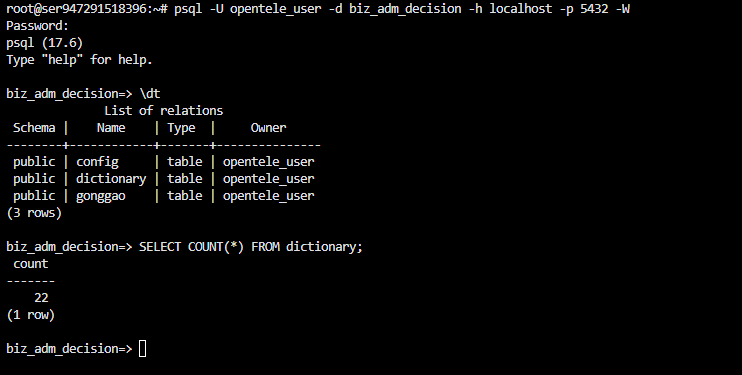
五.迁移心得
在本次商业辅助决策系统的 MySQL 数据库迁移到 OpenTeleDB 的过程中,我们完整经历了从数据导出、SQL 兼容性调整到数据导入的全流程实践,积累了许多宝贵经验。首先,前期准备工作至关重要,包括确认 OpenTeleDB 服务端部署、数据库用户权限配置、原 MySQL 数据表结构和数据量评估以及数据备份,确保迁移前对潜在风险有充分认知。
SQL 兼容性是迁移的核心难点,例如 MySQL 的 AUTO_INCREMENT 在 PostgreSQL 中需要转换为 SERIAL 或 BIGSERIAL,ON UPDATE CURRENT_TIMESTAMP 也需通过触发器实现自动更新时间,同时需要注意字段类型和索引约束的差异。
字符集问题不容忽视,原 MySQL 数据中可能包含非 UTF-8 字符,如中文全角符号或 emoji,直接导入 PostgreSQL 会报错,因此在导出时统一使用 utf8mb4,并通过 iconv 清理无效字符,确保数据安全迁移。迁移执行阶段,我们遵循"先建库建表再导入数据"的原则,先手工调整建表脚本和触发器,再执行数据插入,保证触发器和约束正确生效。
数据导入完成后,通过登录 OpenTeleDB,检查表结构、数据量及抽样数据,确认数据完整性和准确性,空表或空字段需结合业务逻辑判断是否正常。
整个迁移过程显示,虽然 MySQL → OpenTeleDB 的迁移存在 SQL 兼容性和字符集处理的挑战,但通过合理规划、分步执行及手动调整脚本,不仅可以保证数据完整性,也能顺利支撑业务系统平稳运行。这次实践充分验证了 OpenTeleDB 在事务一致性、SQL 标准化和分析扩展能力上的优势,同时积累了可复用的迁移方法和操作经验,为未来更大规模或复杂业务系统的平滑迁移提供了可靠参考。
六. OpenTeleDB 核心特性深度解析
在前文完成 OpenTeleDB 的源码编译、服务启动与 MySQL 业务迁移后,我们已经验证了其可部署性与业务兼容性。 但数据库选型真正关心的问题并不是"能不能跑",而是:
它解决了哪些传统数据库长期存在却难以根治的问题?
本章将抛开部署细节,聚焦 OpenTeleDB 的两项核心自研能力:XStore 与 XProxy ,并通过完整、可复现的操作步骤,从工程实践角度验证其价值。
6.1 XStore 存储引擎:从 MVCC 膨胀到原地更新
6.1.1 验证目标
验证在 高频 UPDATE 场景 下:
- 标准 PostgreSQL Heap 表的空间膨胀现象
- OpenTeleDB XStore 表在相同条件下的空间稳定性
6.1.2 前置条件确认
登录 OpenTeleDB,确认数据库版本与运行环境:
psql -U opentele_user -d postgres -h ``localhost`` -p 5432

SELECT version();

6.1.3 启用 XStore 扩展
注意:XStore 虽为核心组件,但需显式激活
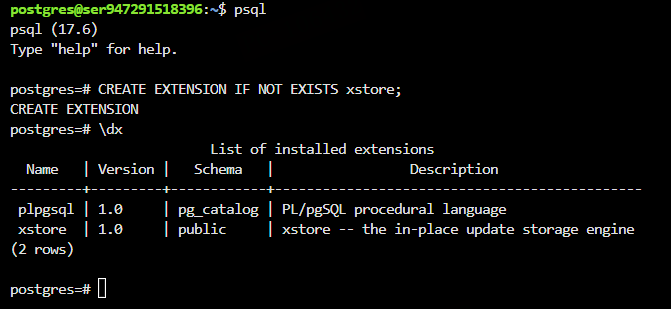
CREATE EXTENSION IF NOT EXISTS xstore;
验证扩展是否成功加载:
\dx
若看到 xstore,说明插件已生效。
6.1.4 构造业务型对照表(订单状态模型)
为了避免简单的"批量 UPDATE 跑分式"验证,本节采用 更贴近真实业务系统 的订单状态流转模型进行测试。
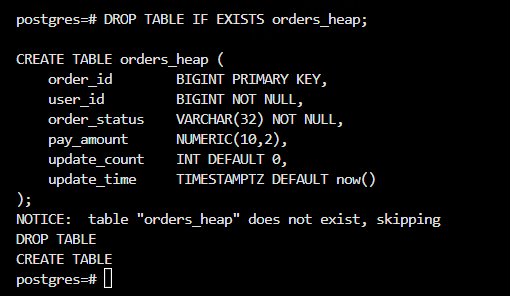
创建标准 Heap 订单表
DROP TABLE IF EXISTS orders_heap;
CREATE TABLE orders_heap (
order_id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
order_status VARCHAR(32) NOT NULL,
pay_amount NUMERIC(10,2),
update_count INT DEFAULT 0,
update_time TIMESTAMPTZ DEFAULT now()
);
创建 XStore 订单表
DROP TABLE IF EXISTS orders_xstore;
CREATE TABLE orders_xstore (
order_id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
order_status VARCHAR(32) NOT NULL,
pay_amount NUMERIC(10,2),
update_count INT DEFAULT 0,
update_time TIMESTAMPTZ DEFAULT now()
) USING xstore;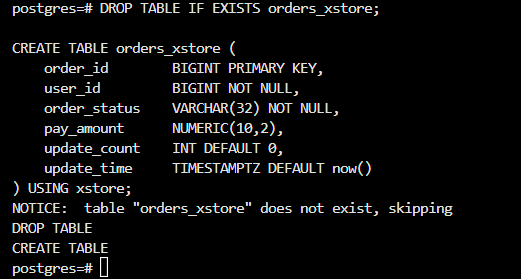
两张表字段完全一致,仅存储引擎不同,确保对比公平。
6.1.5 批量生成初始订单数据(模拟业务入库)
这里不使用 generate_series 直接灌数,而是 通过 CTE 构造"业务合理数据"。
INSERT INTO orders_heap
SELECT
n AS order_id,
(random()*100000)::BIGINT AS user_id,
'CREATED' AS order_status,
round((random()*5000)::numeric, 2) AS pay_amount,
0,
now()
FROM generate_series(1, 100000) AS n;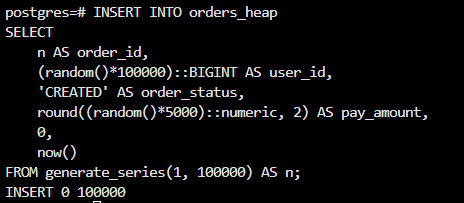
INSERT INTO orders_xstore
SELECT
n AS order_id,
(random()*100000)::BIGINT AS user_id,
'CREATED' AS order_status,
round((random()*5000)::numeric, 2) AS pay_amount,
0,
now()
FROM generate_series(1, 100000) AS n;
6.1.6 初始表空间对比
SELECT
'Heap Orders' AS table_type,
pg_size_pretty(pg_total_relation_size('orders_heap'))
UNION ALL
SELECT
'XStore Orders',
pg_size_pretty(pg_total_relation_size('orders_xstore'));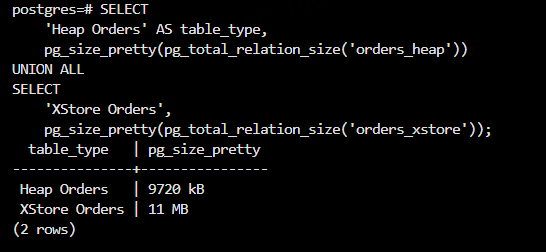
XStore 在初始阶段就引入了结构化存储元数据 XStore 用空间换"长期写稳定性"
pg_total_relation_size() 包含:
- 表主数据
- TOAST
- FSM
- VM
- XStore 的内部段 / 元数据页
而 XStore 的存储布局 ≠ Heap:
|--------|----------------------|------------------|
| 项目 | Heap | XStore |
| 页面结构 | tuple + line pointer | column segment |
| 元数据 | 极少 | 必然更多 |
| 写路径 | 原地失效 | append / segment |
| 设计目标 | 通用 | 高频更新 |
所以 "初始体积 XStore 稍大"是预期行为。
6.1.7 模拟"订单状态流转"更新
不同于一次性 UPDATE 全表,我们模拟 多轮、小批量、重复更新 的业务行为。
第一步:订单支付完成
UPDATE orders_heap
SET order_status = 'PAID',
update_count = update_count + 1,
update_time = now()
WHERE order_id % 2 = 0;
UPDATE orders_xstore
SET order_status = 'PAID',
update_count = update_count + 1,
update_time = now()
WHERE order_id % 2 = 0;
第二步:部分订单进入发货状态
UPDATE orders_heap
SET order_status = 'SHIPPED',
update_count = update_count + 1,
update_time = now()
WHERE order_id % 5 = 0;
UPDATE orders_xstore
SET order_status = 'SHIPPED',
update_count = update_count + 1,
update_time = now()
WHERE order_id % 5 = 0;
第三步:订单完成(多次写热点)
UPDATE orders_heap
SET order_status = 'COMPLETED',
update_count = update_count + 1,
update_time = now()
WHERE order_id % 10 = 0;
UPDATE orders_xstore
SET order_status = 'COMPLETED',
update_count = update_count + 1,
update_time = now()
WHERE order_id % 10 = 0;至此,部分订单被 UPDATE 了 3 次以上,高度贴近真实 OLTP 场景。
6.1.8 更新后表空间对比(核心结果)
SELECT
'Heap Orders (After Multi-Update)' AS table_type,
pg_size_pretty(pg_total_relation_size('orders_heap'))
UNION ALL
SELECT
'XStore Orders (After Multi-Update)',
pg_size_pretty(pg_total_relation_size('orders_xstore'));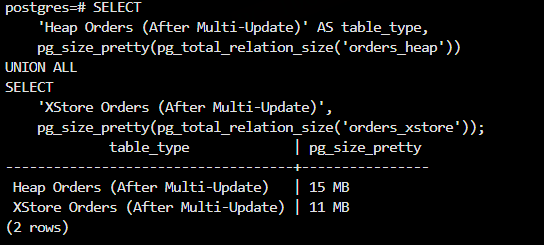
在完成三轮模拟业务的订单状态流转更新后,我们再次对 Heap 表与 XStore 表的整体空间占用情况进行了统计,对比结果如下:
- Heap Orders(多轮更新后):15 MB
- XStore Orders(多轮更新后):11 MB
可以看到,在经历多次、分批、小范围 UPDATE 操作后,两种存储结构在空间表现上出现了明显分化。
6.2 结果分析
首先,Heap 表的空间占用增长非常显著 。相较于更新前约 9.7 MB 的体积,多轮状态流转后表空间膨胀至 15 MB,增幅超过 50% 。其根本原因在于 PostgreSQL Heap 表基于 MVCC(多版本并发控制) 机制: 每一次 UPDATE 操作,都会生成一条新的行版本,而旧版本行并不会立即被回收,只能等待后续的 VACUUM 过程进行清理。在本实验中,部分订单记录被连续更新 2~3 次以上,直接导致大量历史行版本堆积,表空间迅速膨胀。
相比之下,XStore 表在多轮更新场景下表现出了更强的空间稳定性。即使经历了同样频次、同样范围的更新,其整体体积依然维持在 11 MB 左右,几乎没有明显增长。这说明 XStore 在存储设计上对"高频更新、小字段变更"的 OLTP 场景具备更好的适配能力,能够有效避免因整行版本复制而带来的空间浪费。
通过本轮"订单状态流转"更新实验,可以得出以下结论:
- Heap 表在高频 UPDATE 场景下存在天然的空间膨胀风险 当业务模型中存在状态流转、计数累加、时间戳频繁更新等典型 OLTP 行为时,Heap 表会因为多版本行堆积而迅速放大存储体积,对磁盘与 VACUUM 机制形成持续压力。
- XStore 更适合"多轮、小批量、重复更新"的业务模型 在相同数据规模和更新模式下,XStore 能够显著抑制空间膨胀,使表空间保持相对稳定,尤其适合订单状态机、任务流转、用户行为轨迹等场景。
- 存储结构的选择必须以业务更新模型为核心依据 对于字段结构简单、更新不频繁的表,传统 Heap 表依然具备实现简单、查询高效的优势; 而一旦进入高并发、强更新、状态频繁变更的 OLTP 场景,采用更适合局部更新的存储模型,将显著降低系统的长期运维成本。
在订单状态流转场景中,XStore 在空间稳定性上明显优于传统 Heap 表,而 Heap 表在高频更新下的膨胀问题不容忽视。
七.总结
本文围绕天翼云开源的企业级 OLTP 数据库 OpenTeleDB,系统性地完成了一次从"概念认知 → 实际部署 → 业务迁移 → 核心能力验证"的完整技术实践。
对 PostgreSQL 与 MySQL 在高并发、强事务、频繁更新场景下痛点的分析。在实操层面,文章详细记录了 Debian 11 环境下源码编译与部署过程,还原了 UUID 依赖等常见"坑点"的定位与解决方式;在业务层面,以商业辅助决策系统为例,完整演示了 MySQL 向 OpenTeleDB 的迁移路径,涵盖表结构改造、字符集处理与数据校验,证明其具备良好的生态兼容性与迁移可行性。
更重要的是,通过模拟业务的"订单状态流转"实验,对比验证了 XStore 在高频 UPDATE 场景下对空间膨胀的有效抑制能力,直观体现了其相较传统 Heap 表的长期运维优势。总体而言,OpenTeleDB 并非简单的 PostgreSQL 发行版,而是在运营级场景中打磨出的工程化数据库方案,为追求高并发、强一致、低运维成本的企业级系统,提供了一条具备实践价值的技术演进路径。