文章目录
前言
(8)滑动窗口
流量控制时关注的是接收缓冲区,而滑动窗口就要关注发送缓冲区了
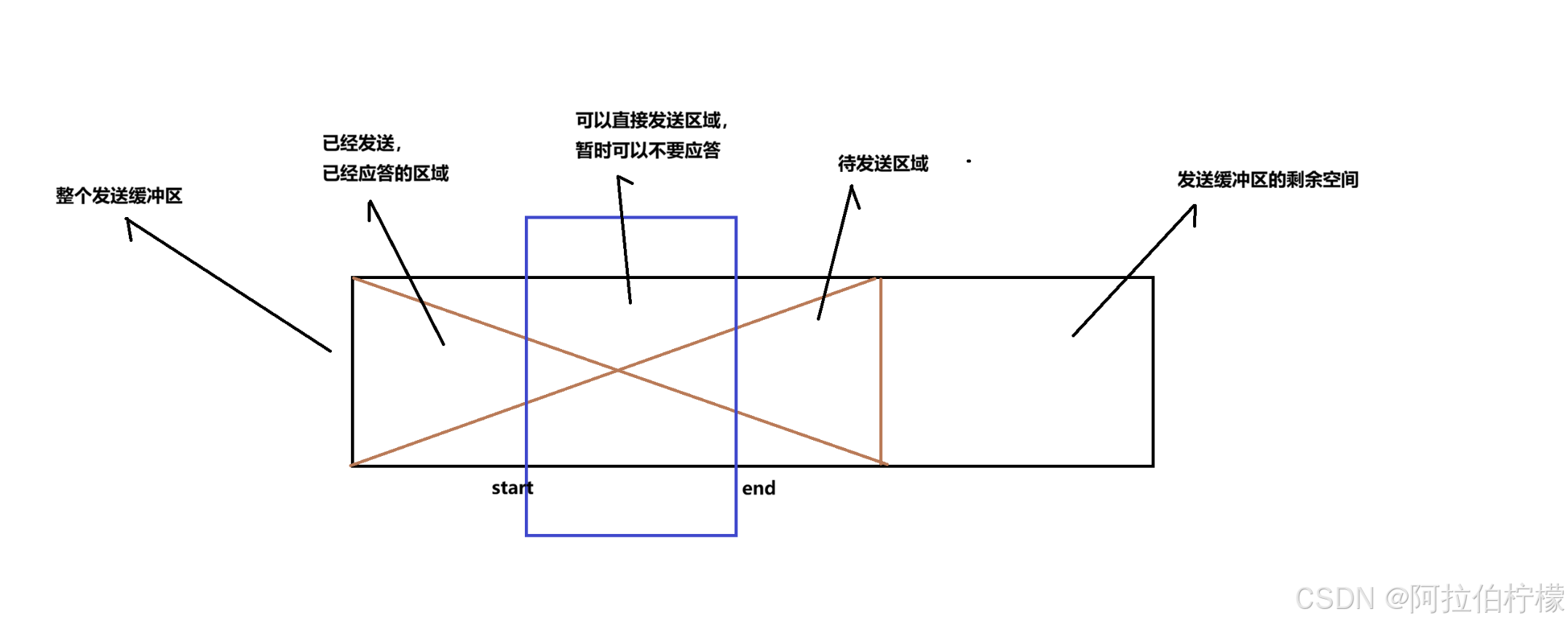
滑动窗口将整个发送缓冲区分割成上图四个部分。
- 滑动窗口只是一个由start与end构建起来的一个下标范围,这个范围限定的发送缓冲区的空间就叫滑动窗口。
- 滑动的本质是start 与 end 在做+=运算
- start = 确认序号, end = start + 对端16位窗口大小 。satrt 与 end 每次与对方报文交换都在进行动态的调整
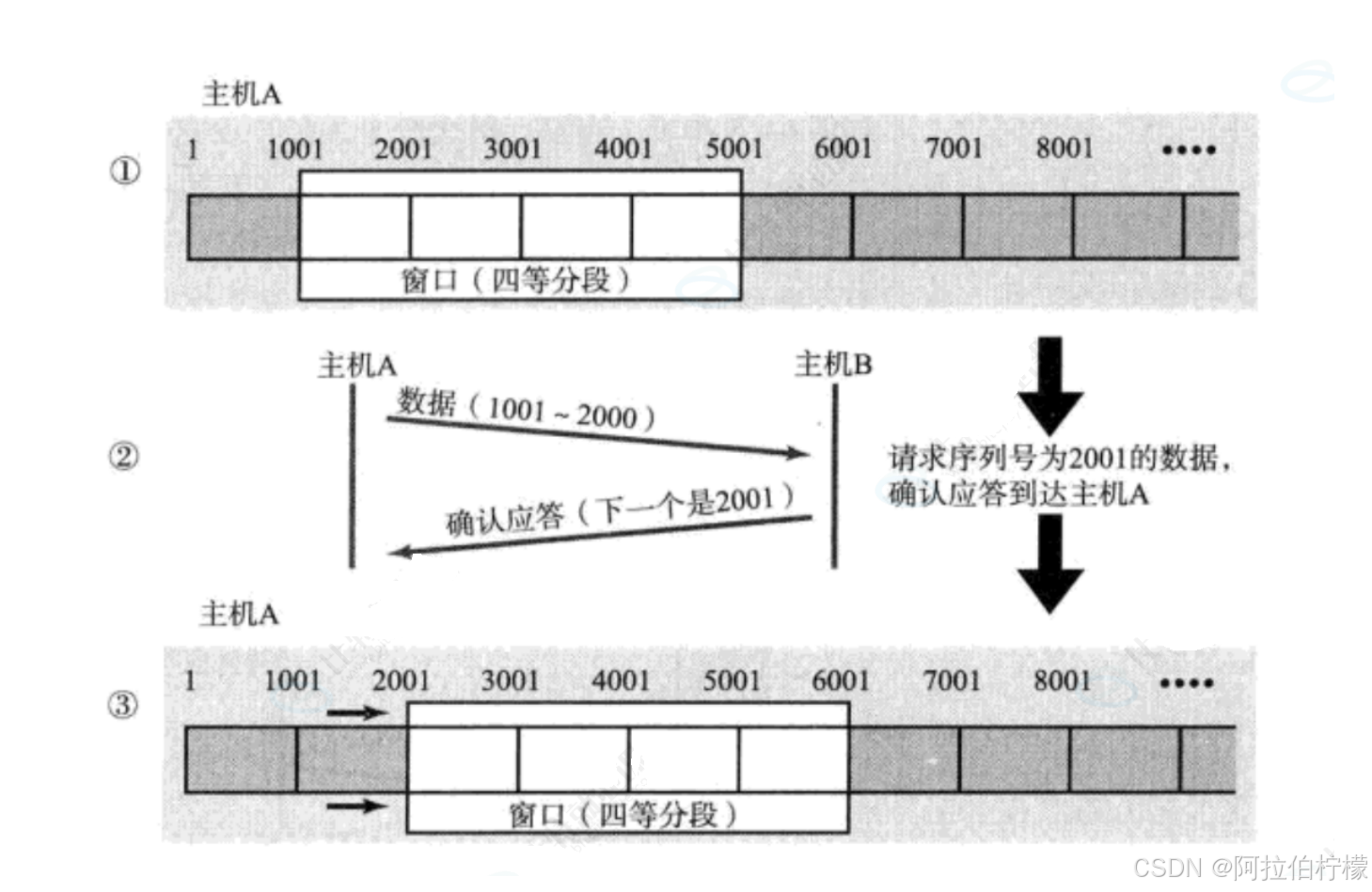
- 流量控制是通过滑动窗口实现的
- 滑动窗口只能向右移动,不能向左移动
- 滑动窗口大小 可以变大,可以变小,可以为0,这取决于对方的接收能力
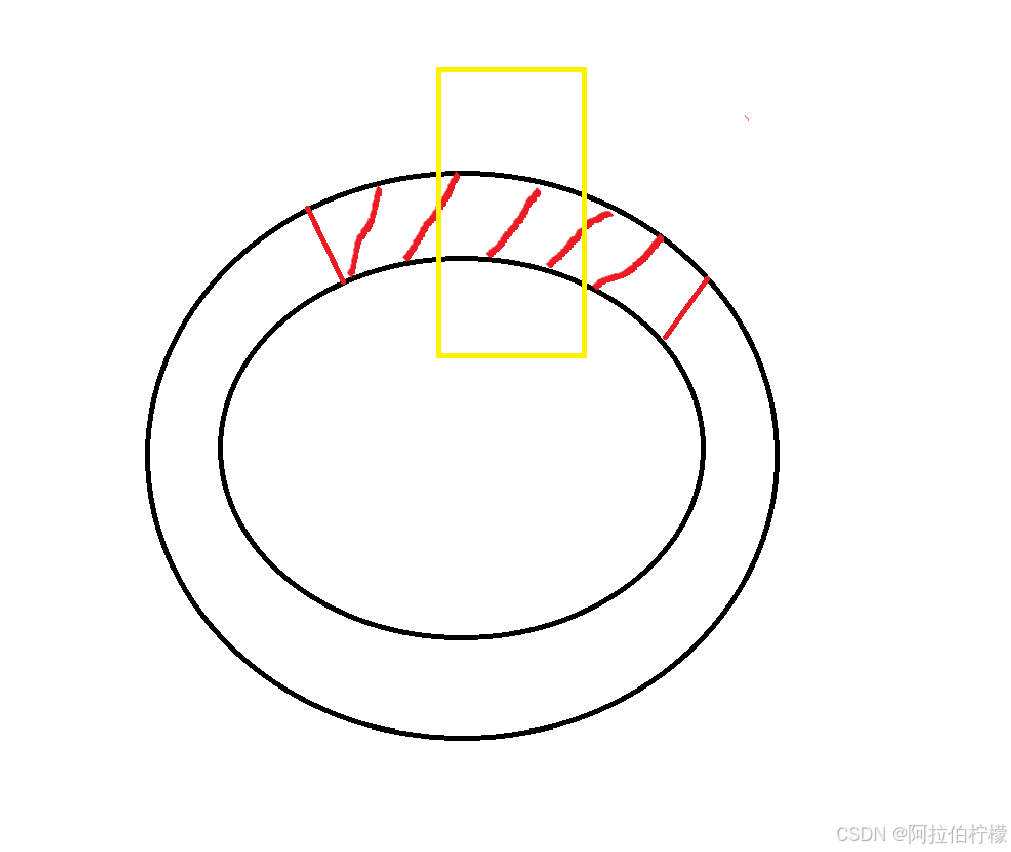
- 滑动窗口超过发送缓冲区并不会越界 ,我们将发送缓冲区想象成环形结构,所以对于已经发送、已经确认的区域其数据已经被删除,可以被未来覆盖掉。但是发送缓冲区会满 ,表现为就是应用层堵塞。这也是基于环形队列的生产者消费者模型的一种体现。
- 为什么不将滑动窗口的数据合并成一个大报文,而是一条一条的发送?
因为在数据链路层不允许发送大的报文(最大1500字节左右),有效载荷长度不能超过MTU(1500)-----后面文章会讲。
滑动窗口的异常丢包问题
(1)数据包已经抵达, 但ACK应答丢失:
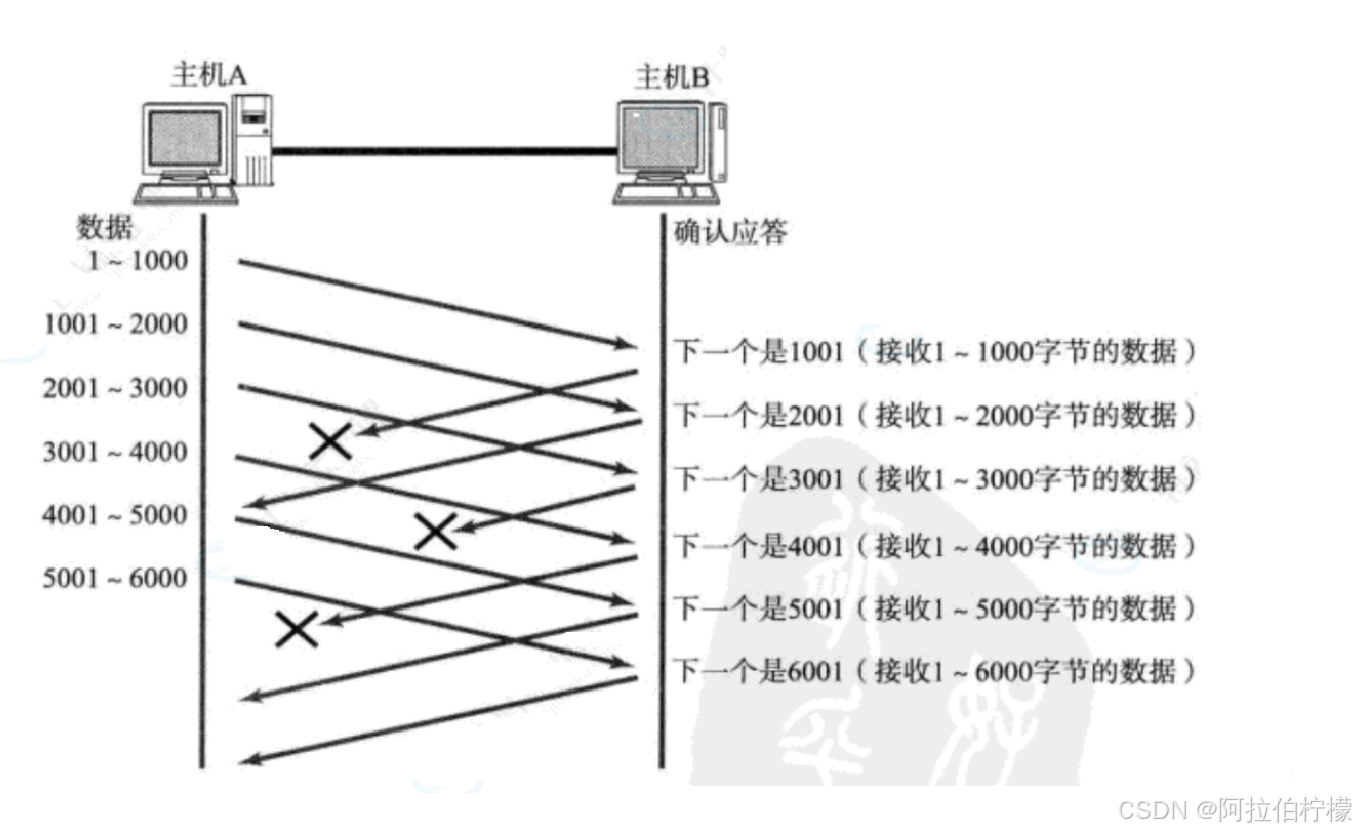
在这种情况下, 部分ACK丢了并不要紧, 因为可以通过后续的ACK进行确认 ,即主机B已经收到数据,且最新确认序号之前的数据都已经收到。
(2)数据包没有抵达,直接丢失:
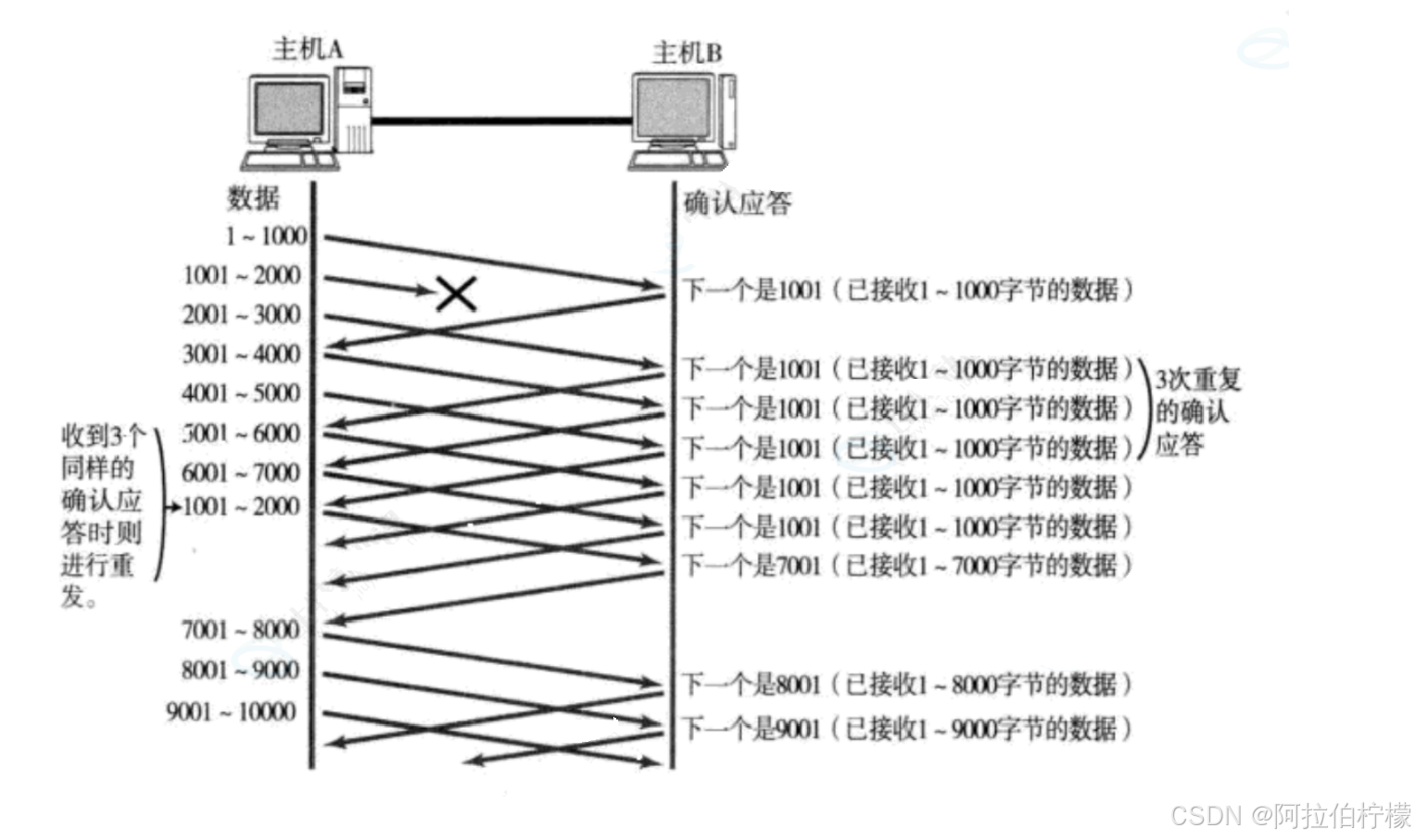
1.滑动窗口最左侧丢失,如上图序号1
- 滑动窗口不会右移。
- 若1001 ~ 2000丢失,主机A会收到连续的确认序号为1001的报文 (主机B已经将2001 ~ 5000的数据存放到接受缓冲区中),此时主机A知道至少1001~2000的报文丢失 ,所以主机A可以对该报文进行补发或者超时补发,待补发完成后,主机B的确认序号直接变成5001,A的滑动窗口直接移动到5001处
- 窗口内已经发送的数据并不会立即删除 即不会立即从滑动窗口移出来,还要为超时重传做准备
2.滑动窗口中间丢失,如上图序号2、3
- 可以转化为最左侧丢失问题。
- 若2001~3001丢失,则3、4的确认序号都是2001,此时,窗口start移动到2001处,问题转化为最左侧丢失问题。
3.滑动窗口最右侧丢失,如上图序号4
- 可以转化为最左侧丢失问题。
- 若4001~5000丢失,则确认序号为4001,此时窗口start移动到4001处,问题转化为最左侧丢失问题。
总结: 滑动窗口数据丢包问题
- 只有窗口左侧数据应答了,窗口才会移动,并且所有问题都可以转化为最左侧丢失问题
- TCP基于流量控制并发发送的场景中若主机A连续收到了3个及以上重复的确认序号 ,那么主机A会立即对该丢失报文进行重传,这种机制被称为"高速重发机制 "(也叫"快重传 ")。对比之下,超时重传是用来兜底的。双重保障体现出TCP连接的可靠性。
(9)拥塞控制
在实际网络通信中,不仅要考虑对端的接受能力,还要考虑网络问题
- 虽然TCP通过滑动窗口能够高效可靠的发送大量的数据. 但是如果在刚开始阶段就发送大量的数据, 仍然可能引发问题.因为网络上有很多的计算机, 可能当前的网络状态就已经比较拥堵. 在不清楚当前网络状态下, 贸然发送大量的数据, 是很有可能引起雪上加霜的。
- 网络问题可能导致发送端发送9000个报文,但实际只有1000个到达接收端,少量报文丢失重发即可这是正常的网络抖动。但大量报文丢失则是网络拥塞问题,此时不能重传,因为在全局角度看同一时刻可能哟成百上千个客户端在访问服务器,若重传则会加重网络拥堵。
TCP引入慢启动 机制, 先发少量的数据, 探探路, 摸清当前的网络拥堵状态, 再决定按照多大的速度传输数据;
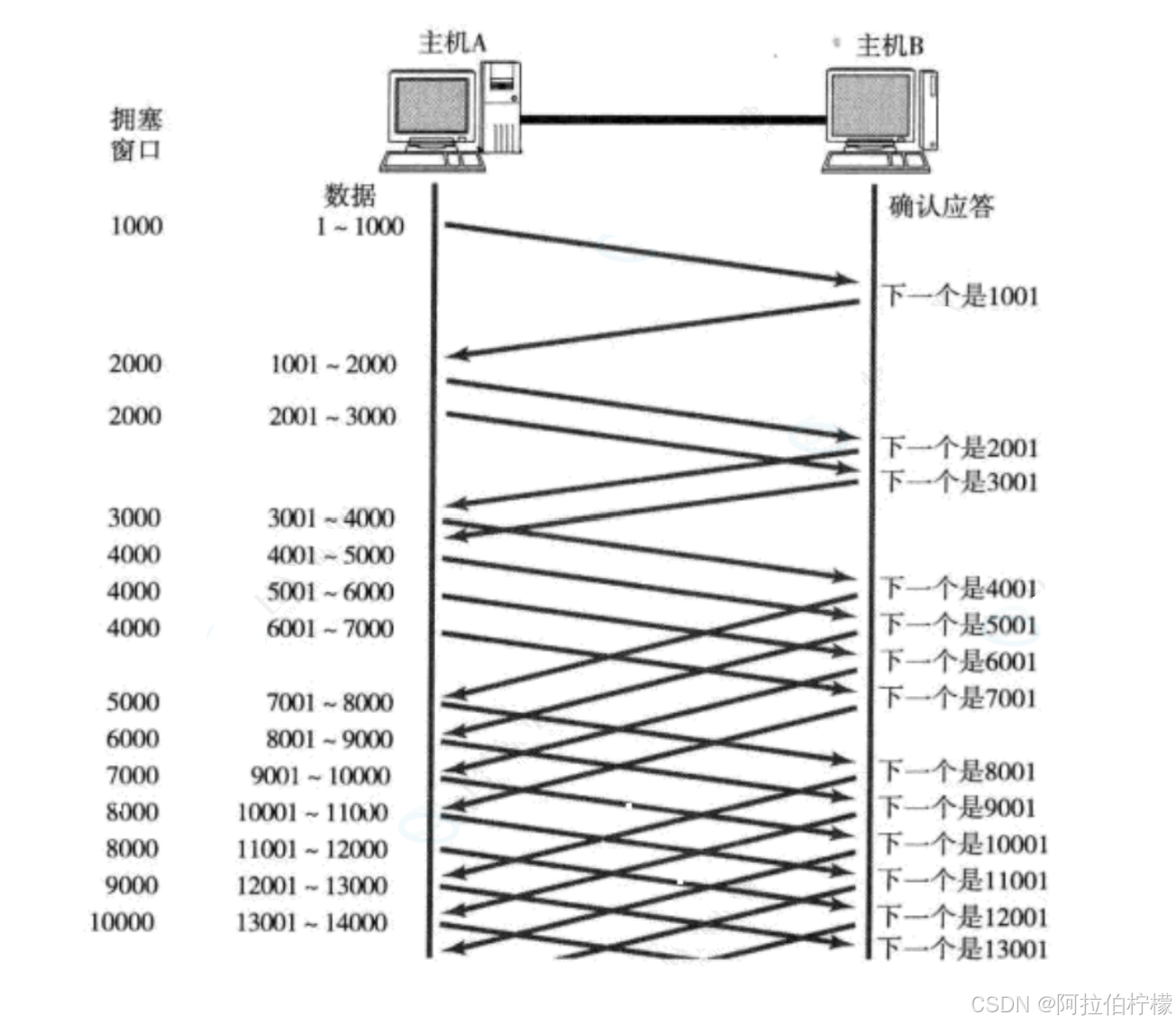
- 拥塞窗口 :由发送方根据自己感知到的网络拥塞程度 动态计算得出。它代表"网络能承受多少 "。
当发送的报文数量超过拥塞窗口时,很有可能会造成网络拥挤
接收窗口 :由接收方根据自己可用缓冲区大小告知发送方。它代表"我能接收多少"。 - 发送开始的时候, 定义拥塞窗口大小为1
- 每次收到⼀个ACK应答, 拥塞窗口加1,相当于乘2
- 每次发送数据包的时候, 将拥塞窗口和接收端主机反馈的窗口(接收窗口)大小做比较, 取较小的值作为实际发
送的窗口 即 滑动窗口 = min (对端接收窗口, 拥塞窗口)
上面这样的拥塞窗口增长速度 , 是指数级别的 . "慢启动" 只是指初使时慢, 但是增长速度非常快,这有助于加快网络通信的恢复
- 为了不增长的那么快, 因此不能使拥塞窗口单纯的加倍
- 此处引入⼀个叫做慢启动的阈值
- 当拥塞窗口超过这个阈值的时候, 不再按照指数方式增长, 而是按照线性方式增长
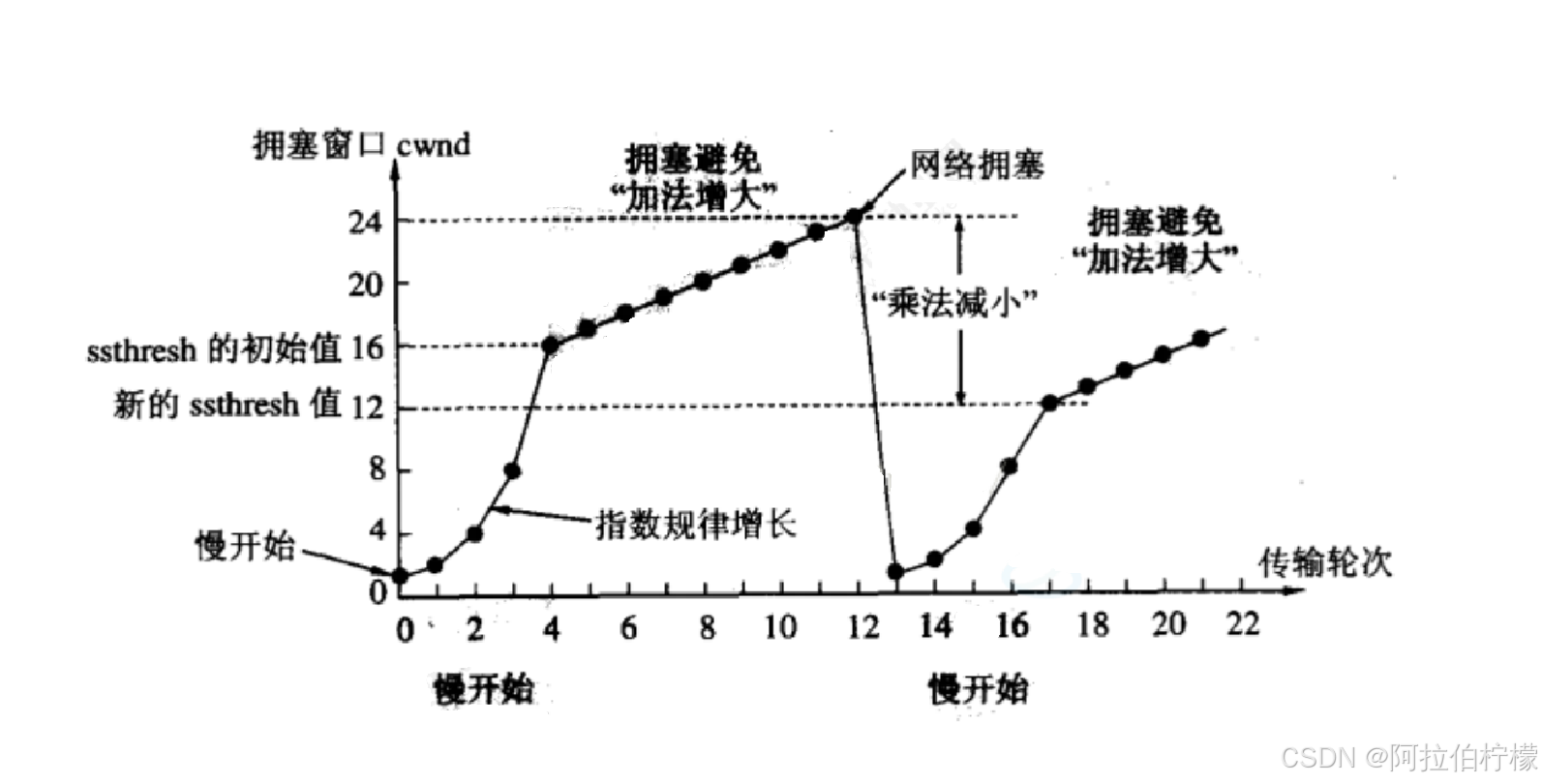
- 当TCP开始启动 的时候, 慢启动阈值等于对端接收窗口最大值
- 在每次超时重发 的时候, 慢启动阈值会变成原来阈值的⼀半(乘法减小), 同时拥塞窗口置回1
- 拥塞控制算法:慢启动 + 加法增大 + 乘法减小
- 为什么拥塞窗口要一直增大,即使超过了对端接收窗口?
拥塞窗口不在TCP报头中体现,在主机中自己维护,它是网络健康情况的评估值 ,而网络的拥挤健康状态是一直变化的,因此这就决定了拥塞窗口是一直变化的
(10)延时应答
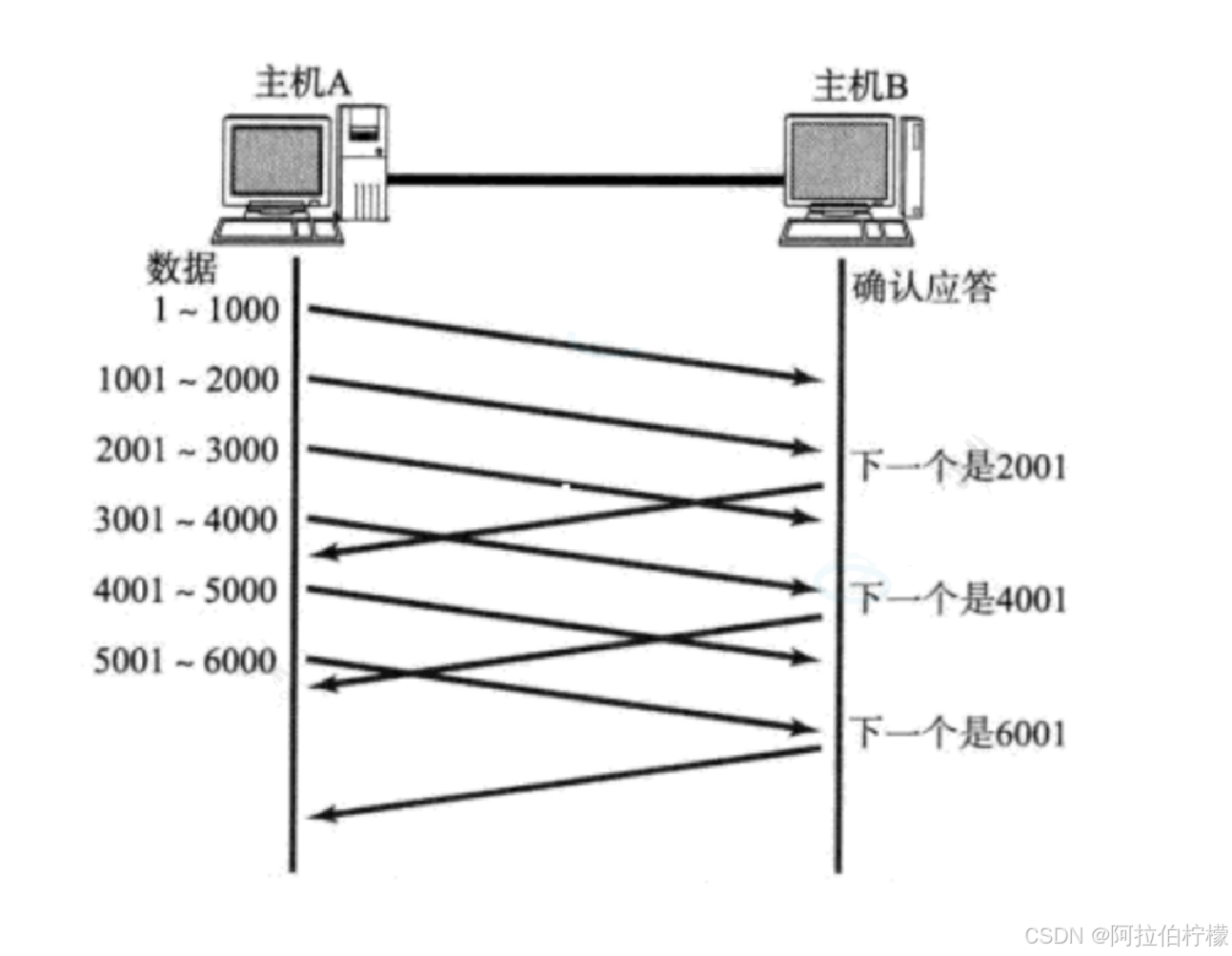
如果接收端当收到数据后立即返回ACK应答, 这时候返回的窗口可能比较小
- 假设接收端缓冲区为1M. ⼀次收到了500K的数据; 如果立刻应答, 返回的窗口就是500K
- 但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;
- 在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大⼀些, 也能处理过来;
- 如果接收端稍微等⼀会再应答, 比如等待200ms再应答, 那么这个时候返回的窗口大小就是1M
窗口越大, 网络吞吐量就越大, 传输效率就越高 . 我们要在保证网络不拥塞的情况下尽量提高传输效率
也并不是所有的包都可以延迟应答
- 数量限制:每隔N个包就应答⼀次,一般N为2,依操作系统不同
- 时间限制:超过最大延迟时间就应答⼀次,一般时间为200ms,依操作系统不同
(11)TCP的面向字节流
当创建⼀个TCP的socket时, 同时在内核中 创建⼀个 发送缓冲区 和⼀个 接收缓冲区
- 调用write时, 数据会先写入发送缓冲区中
- 如果发送的字节数太长, 会被拆分成多个TCP的数据包发出
- 如果发送的字节数太短, 就会先在缓冲区里等待, 等到缓冲区长度差不多了, 或者其他合适的时机发送出去
- 接收数据的时候, 数据也是从网卡驱动程序到达内核的接收缓冲区
- 然后应用程序可以调用read从接收缓冲区拿数据
- TCP的⼀个连接, 既有发送缓冲区, 也有接收缓冲区, 那么对于这一个连接, 既可以读数据, 也可以写数据 . 这个概念叫做 全双工
由于缓冲区的存在, TCP程序的读和写不需要一 一匹配:
- 写100个字节数据时, 可以调用⼀次write写100个字节, 也可以调用100次write, 每次写⼀个字节
- 读100个字节数据时, 也完全不需要考虑写的时候是怎么写的, 既可以一次read 100个字节, 也可以⼀次read⼀个字节, 重复100次;
(12)应用层读取数据时粘包问题
因为TCP的面向字节流,就引出了应用层读取数据的粘包问题
什么是粘包 和拆包 ?

- 首先要明确, 粘包问题中的 "包" , 是指的应用层的数据包
- 在TCP的协议头中, 没有如同UDP⼀样的 "报文长度" 这样的字段, 但是有一个序号这样的字段.
- 站在传输层的角度, TCP是⼀个⼀个报文过来的. 按照序号排好序放在缓冲区中
- 站在应用层的角度, 看到的只是⼀串连续的字节数据那么应用程序看到了这么⼀连串的字节数据, 就不知道从哪个部分开始到哪个部分, 是⼀个完整的应用层数据包
如何避免粘包问题?
- 对于定长的包, 保证每次都按固定大小读取即可; 例如上面的Request结构, 是固定大小的, 那么就从缓冲区从头开始按sizeof(Request)依次读取即可
- 对于变长的包, 可以在包头的位置, 约定⼀个包总长度的字段, 从而就知道了包的结束位置
- 对于变长的包, 还可以在包和包之间使用明确的分隔符(应用层协议, 是我们自己来定的, 只要保证分隔符不和正文冲突即可);
UDP是否存在粘包问题?
- 对于UDP, 如果还没有上层交付数据, UDP的报文长度仍然在. 同时, UDP是⼀个⼀个把数据交付给应用层. 就有很明确的数据边界
- 站在应用层的站在应用层的角度, 使用UDP的时候, 要么收到完整的UDP报文, 要么不收. 不会出现"半个"的情况
- 即UDP绝对没有TCP意义上的"粘包"问题,因为它传输的是有明确边界的数据报
(13)TCP异常情况
- 进程终止: 进程终止会释放文件描述符, 仍然可以发送FIN. 和正常关闭没有什么区别
- 机器重启: 和进程终止的情况相同
- 机器掉电/网线断开: 接收端认为连接还在, ⼀旦接收端有写⼊操作, 接收端发现连接已经不在了, 就会进行reset. 即使没有写入操作, TCP自己也内置了⼀个保活定时器, 会定期询问对方是否还在. 如果对方不在, 也会把连接释放
- 应用层的某些协议, 也有⼀些这样的检测机制. 例如HTTP长连接中, 也会定期检测对方的状态. 例如QQ, 在QQ断线之后, 也会定期尝试重新连接
(14)TCP总结
TCP之所以这么复杂,是因为既要保证可靠性, 同时又尽可能的提高性能.
可靠性:
- 校验和
- 序列号(按序到达)
- 确认应答
- 超时重发
- 连接管理
- 流量控制
- 拥塞控制
提高性能:
- 滑动窗口
- 快速重传
- 延迟应答
- 捎带应答
基于TCP应用层协议:HTTP、HTTPS、SSH、Telnet、FTP、SMTP、自定义的应用层协议等等
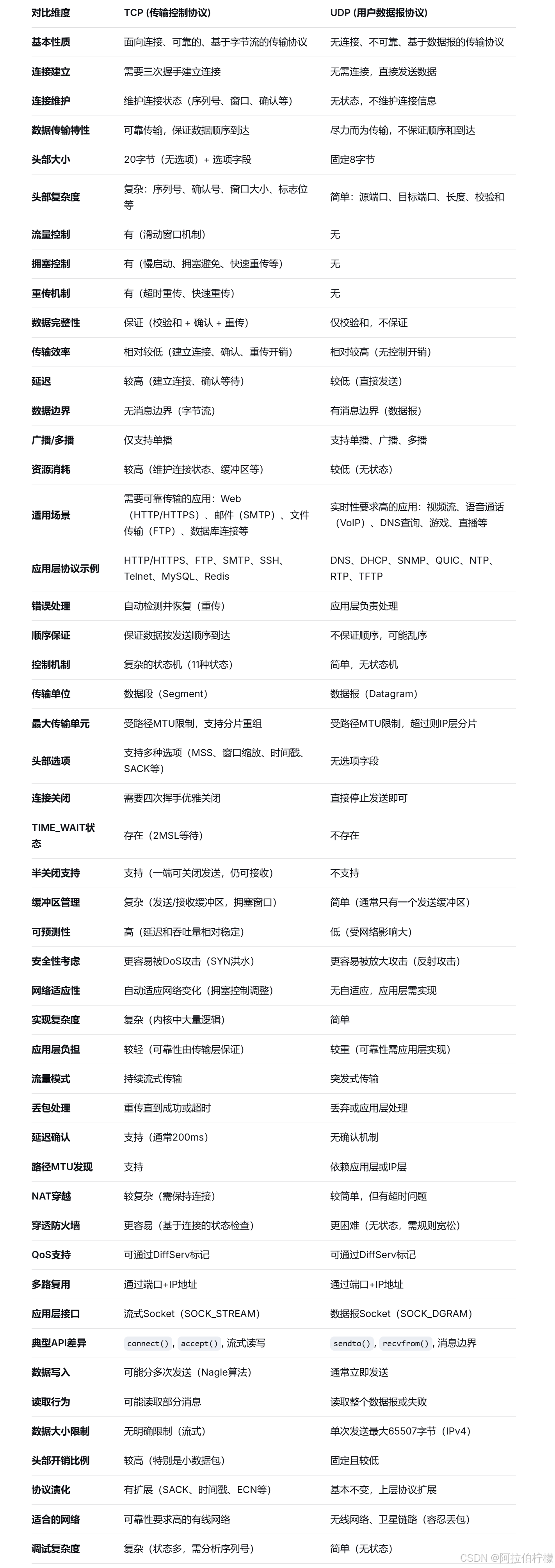
(15)TCP/UDP对比