视频讲解1:https://www.douyin.com/video/7591873594976767259
视频讲解2:BiliBili视频讲解
代码例子:https://github.com/KeepTryingTo/PyTorch-DeepLearning-Visual-LLM/upload/main/accelerate
GitHub: https://github.com/huggingface/accelerate
文档: https://huggingface.co/docs/accelerate
示例: https://github.com/huggingface/accelerate/tree/main/examples
人群计数框架:https://github.com/KeepTryingTo/CrowdCounting-framework-PyTorch
PyTorch Lightning教程就看这篇(视频教程 + 文字教程)

关于pytorch框架中单卡/多卡的分布式训练模式请看上面我们之前给出的人群计数框架。而我们今天要讲解的是accelerate库的使用方式,只需要简单的方式即可实现单卡/多卡的分布式训练。
目录
[②用 accelerator.prepare() 包装所有组件](#②用 accelerator.prepare() 包装所有组件)
介绍
- accelerate 是由 Hugging Face 开发的一个 轻量级、易用且功能强大 的库,用于简化在 单 GPU、多 GPU(DataParallel / DistributedDataParallel)、TPU、混合精度(FP16/BF16)以及 CPU 上训练 PyTorch 模型的流程。它让你几乎无需修改模型或训练循环代码,就能无缝地在各种硬件和分布式设置下运行。
- 每个分布式训练框架都有自己的作方式,可能需要编写大量自定义代码,以适应你的PyTorch训练代码和训练环境。Accelerate为你提供了友好的交互方式,让你无需学习每个分布式训练框架的具体细节。Accelerate会帮你处理这些细节,让你可以专注于训练代码,并将其扩展到任何分布式训练环境。
- 在这个教程中,你将学习如何用 Accelerate 适配现有的 PyTorch 代码,轻松地在分布式系统上进行训练!你将从一个基础的 PyTorch 训练循环开始(它假设所有训练对象都已设置好并且已经设置好),然后逐步将 Accelerate 集成进去。
CPU only
multi-CPU on one node (machine)
multi-CPU on several nodes (machines)
single GPU
multi-GPU on one node (machine)
multi-GPU on several nodes (machines)
TPU
FP16/BFloat16 mixed precision
FP8 mixed precision with Transformer Engine or MS-AMP
DeepSpeed support (Experimental)
PyTorch Fully Sharded Data Parallel (FSDP) support (Experimental)
Megatron-LM support (Experimental)
安装库和定义方式
(1)安装:pip install accelerate
(2)定义:
python
accelerator = Accelerator(
mixed_precision="fp16", # "no", "fp16", "bf16"
gradient_accumulation_steps=4,
log_with="wandb", # 支持 TensorBoard, Weights & Biases 等
project_dir="./logs", cpu=False, # 强制使用 CPU(即使有 GPU) # 更多...
)|-----------------------------|---|-----------------------------|
| 参数 | 说明 ||
| mixed_precision | "no"(默认)、"fp16"(NVIDIA GPU)、"bf16"(Ampere+ GPU / TPU) ||
| gradient_accumulation_steps | 梯度累积步数(模拟大 batch size) ||
| log_with | 日志后端:"tensorboard", "wandb", "comet_ml" ||
| dynamo_backend | 启用 torch.compile(如 "inductor") ||
| 方法 || 作用 |
| accelerator.print(...) || 仅主进程打印(避免多卡重复输出) |
| accelerator.is_main_process || 判断是否为主进程(用于保存、日志等) |
| accelerator.device || 获取当前设备(如 cuda:0) |
| accelerator.num_processes || 总进程数(GPU 数) |
| accelerator.sync_gradients || 检查当前 step 是否执行了梯度同步(用于梯度裁剪) |
命令行运行方式
单机多卡(自动检测) accelerate launch train.py
自定义配置(生成 config 文件) accelerate config(注意这个配置文件生成),如果我们要在多CPU或者多GPU上训练模型,可以通过设置这个默认的配置文件来完成(具体演示请看上面视频讲解),比如下面:
使用配置文件运行 accelerate launch --config_file my_config.yaml train.py
支持notebook的运行方式:
from accelerate import notebook_launcher
notebook_launcher(training_function)
统一的使用步骤
①第一步:准备你的模型、优化器、数据加载器
python
import torch from torch.utils.data import DataLoader
from transformers import AdamW, AutoModelForSequenceClassification
# 1. 模型
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
# 2. 优化器
optimizer = AdamW(model.parameters(), lr=2e-5)
# 3. 数据集 & DataLoader train_dataset = ...
# your dataset
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True)②用 accelerator.prepare() 包装所有组件
python
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader
)③训练过程
python
for epoch in range(num_epochs):
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
# ❗ 关键:用 accelerator.backward() 替代 loss.backward()
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()④保存模型(自动处理分布式)
python
# 保存完整模型(仅主进程保存,避免重复)
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
accelerator.save(unwrapped_model.state_dict(), "model.pth")⑤使用梯度累积
python
accelerator = Accelerator(gradient_accumulation_steps=4)
optimizer.zero_grad()
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(model): # 自动处理累积逻辑
outputs = model(**batch)
loss = outputs.loss / accelerator.gradient_accumulation_steps
accelerator.backward(loss)
optimizer.step()
optimizer.zero_grad()⑥加载保存的模型
python
from accelerate import Accelerator
accelerator = Accelerator()
model = MyModel()
model = accelerator.prepare(model)
# 加载状态字典
state_dict = torch.load("model.pth", map_location="cpu")
model.load_state_dict(state_dict)完整的训练例子
python
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.optim import AdamW
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
from accelerate import Accelerator
import os
# ----------------------------
# 1. 配置 & 初始化 Accelerator
# ----------------------------
def main():
# 可通过 accelerate config 生成配置文件,或直接在代码中指定
accelerator = Accelerator(
mixed_precision="fp16", # 启用混合精度(若 GPU 支持)
gradient_accumulation_steps=2, # 梯度累积步数
log_with="all", # 自动支持 TensorBoard/W&B(如有安装)
project_dir="./cifar100_output"
)
# 仅主进程创建输出目录
if accelerator.is_main_process:
os.makedirs(accelerator.project_dir, exist_ok=True)
# ----------------------------
# 2. 数据准备
# ----------------------------
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5071, 0.4867, 0.4408), (0.2675, 0.2565, 0.2761)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5071, 0.4867, 0.4408), (0.2675, 0.2565, 0.2761)),
])
trainset = torchvision.datasets.CIFAR100(
root='./data', train=True, download=True, transform=transform_train
)
testset = torchvision.datasets.CIFAR100(
root='./data', train=False, download=True, transform=transform_test
)
train_loader = DataLoader(trainset, batch_size=64, shuffle=True, num_workers=4)
test_loader = DataLoader(testset, batch_size=128, shuffle=False, num_workers=4)
# ----------------------------
# 3. 模型、优化器、损失函数
# ----------------------------
model = torchvision.models.resnet18(pretrained=False, num_classes=100)
optimizer = AdamW(model.parameters(), lr=2e-4, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
# ----------------------------
# 4. 使用 accelerator.prepare() 包装所有组件
# ----------------------------
model, optimizer, train_loader, test_loader = accelerator.prepare(
model, optimizer, train_loader, test_loader
)
# ----------------------------
# 5. 训练循环
# ----------------------------
num_epochs = 10
for epoch in range(num_epochs):
model.train()
total_loss = 0.0
progress_bar = tqdm(train_loader, disable=not accelerator.is_local_main_process)
for batch in progress_bar:
images, labels = batch
with accelerator.accumulate(model): # 自动处理梯度累积和同步
outputs = model(images)
loss = criterion(outputs, labels)
accelerator.backward(loss) # 替代 loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item()
progress_bar.set_description(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item():.4f}")
avg_loss = total_loss / len(train_loader)
accelerator.print(f"Epoch {epoch+1} - Average Train Loss: {avg_loss:.4f}")
# ----------------------------
# 6. 验证(仅主进程打印结果)
# ----------------------------
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 聚合多卡结果(如果使用分布式)
correct_tensor = torch.tensor(correct, device=accelerator.device)
total_tensor = torch.tensor(total, device=accelerator.device)
correct_tensor = accelerator.gather(correct_tensor).sum()
total_tensor = accelerator.gather(total_tensor).sum()
acc = correct_tensor.item() / total_tensor.item()
accelerator.print(f"Validation Accuracy: {acc:.4f}")
# ----------------------------
# 7. 保存模型(仅主进程保存,避免重复)
# ----------------------------
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
save_path = os.path.join(accelerator.project_dir, "cifar100_resnet18.pth")
accelerator.save(unwrapped_model.state_dict(), save_path)
accelerator.print(f"Model saved to {save_path}")
if __name__ == "__main__":
main()单卡训练:
python train.py(默认在cuda:0上运行)
多卡训练:
自动配置(交互式)
accelerate config
或直接运行(自动使用所有可见 多GPU)
accelerate launch train.py
指定多块GPU设备
accelerate launch --multi_gpu --num_processes 2 train.py
Epoch 1/10, Loss: 3.1554: 100%|███████████████| 782/782 00:27\<00:00, 28.47it/s
Epoch 1 - Average Train Loss: 3.8729
Validation Accuracy: 0.1898
Epoch 2/10, Loss: 3.3115: 15%|██▎ | 118/782 00:02\<00:16, 41.05it/s
运行accelerate报错解决
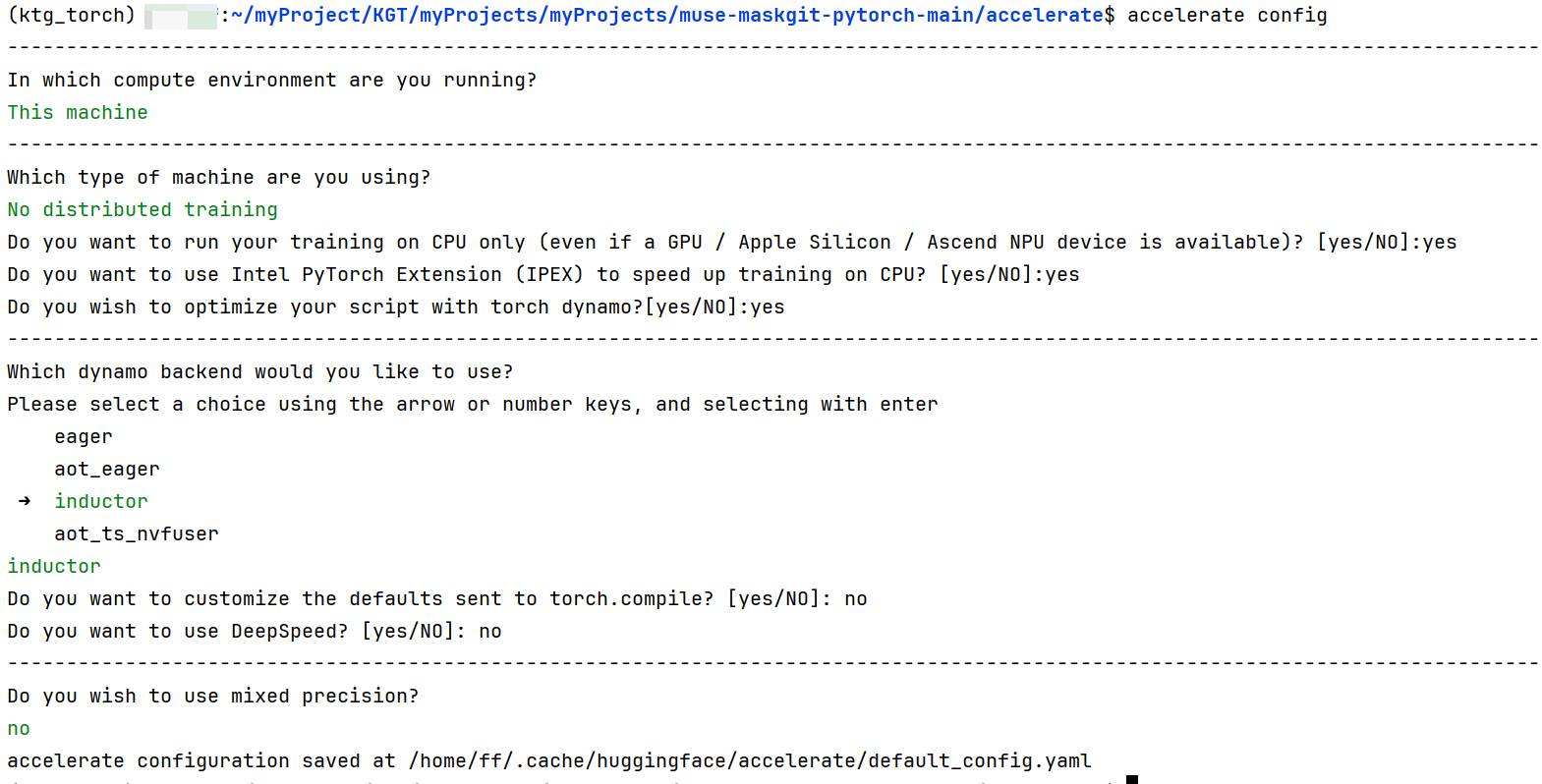
(1)如果你运行accelerate config报错:-bash: /home/ff/bin/accelerate:/home/ff/bin/python:解释器错误: 没有那个文件或目录
(2)是由于执行的是全局环境的accelerate,然而由于我们是下载自己创建的虚拟环境中的,直接执行:rm -f /home/ff/bin/accelerate
(3)重新激活自己的虚拟环境(conda activate xxx),执行accelerate config即可得到如下结果:
打开生成的默认配置default_config.yaml信息:
python
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: 'NO'
downcast_bf16: 'no'
dynamo_config:
dynamo_backend: INDUCTOR
enable_cpu_affinity: false
ipex_config:
ipex: true
machine_rank: 0
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: true