CiteFix: 通过后处理引用校正提升RAG系统准确率
论文信息
| 项目 | 内容 |
|---|---|
| 论文标题 | CiteFix: Enhancing RAG Accuracy Through Post-Processing Citation Correction |
| 作者 | Harsh Maheshwari, Srikanth Tenneti, Alwarappan Nakkiran |
| 机构 | Amazon |
| 发表会议 | ACL 2025 Industry Track |
| 论文链接 | arXiv:2504.15629 |
1. 研究背景与问题定义
1.1 RAG系统中的引用准确性问题
检索增强生成(Retrieval-Augmented Generation, RAG)已成为大语言模型在企业级应用中的核心范式。然而,RAG系统存在一个被广泛忽视但影响深远的问题:LLM生成的响应中引用准确率严重不足。
根据行业研究数据,主流生成式搜索引擎的引用准确率仅约为74%。更值得关注的是,研究表明:
约80%的不可验证事实并非纯粹的幻觉(hallucination),而是引用归属错误(misattribution)------即LLM生成了正确的信息,但未能正确标注其来源文档。
这一发现具有重要的实践意义:相比于检测和修复幻觉,引用校正是一个更具可行性且回报更高的优化方向。
1.2 现有方法的局限性
当前针对RAG引用问题的研究存在以下不足:
- 上下文长度限制:基于T5等模型的方法受限于512 tokens的上下文窗口,难以处理长文档或多源检索场景
- 侧重检测而非校正:大多数研究聚焦于识别引用错误,缺乏高效的自动修复机制
- 计算成本过高:使用大型LLM进行引用验证在延迟和成本上难以满足生产环境需求
2. 方法论
2.1 系统架构概述
CiteFix采用后处理(post-processing) 策略,在不修改原有RAG架构的前提下,对LLM生成的响应进行引用校正。
核心工作流程
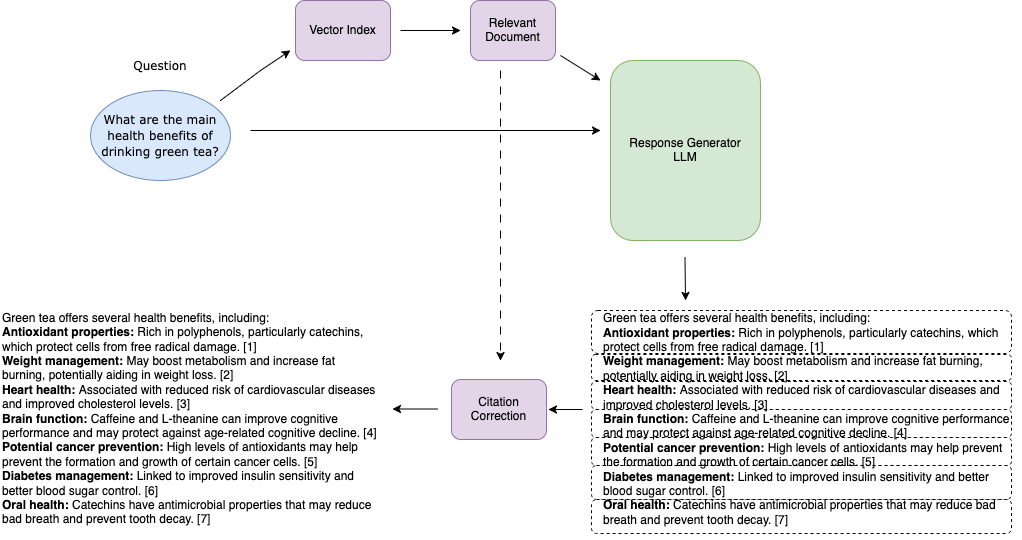
图1:CiteFix算法工作流程示意图
图解说明:该图展示了CiteFix的三阶段处理流程。左侧为RAG系统生成的原始响应(包含可能错误的引用),中间为事实点分割过程(虚线框表示独立事实单元),右侧为引用校正后的最终输出。箭头表示数据流向,每个事实点都会与检索文档集进行相似度匹配,最终选择最匹配的文档作为新引用。
整体流程包含以下步骤:
| 步骤 | 名称 | 输入 | 输出 | 作用 |
|---|---|---|---|---|
| 1 | 事实点分割 | LLM响应 A A A | 事实点集合 { x i } \{x_i\} {xi} | 将连续文本拆分为可独立验证的最小语义单元 |
| 2 | 相似度计算 | 事实点 x i x_i xi,文档集 { x ^ j } \{\hat{x}_j\} {x^j} | 相似度矩阵 S S S | 量化每个事实点与各文档的匹配程度 |
| 3 | 引用重分配 | 相似度矩阵 S S S | 校正后引用 | 为每个事实点选择最匹配的 C i C_i Ci 个文档 |
2.2 基础数学框架
设 q q q 为用户查询, { x ^ j } j = 0 R − 1 \{\hat{x}j\}{j=0}^{R-1} {x^j}j=0R−1 为检索到的 R R R 个文档, A A A 为LLM生成的响应。
核心相似度计算公式:
s i j = f ( x i , x ^ j ) (1) s_{ij} = f(x_i, \hat{x}_j) \tag{1} sij=f(xi,x^j)(1)
公式解读 : s i j s_{ij} sij 表示第 i i i 个事实点 x i x_i xi 与第 j j j 个文档 x ^ j \hat{x}_j x^j 之间的相似度分数。函数 f f f 是相似度度量函数,不同方法采用不同的 f f f 实现。该公式是所有校正算法的统一框架,通过改变 f f f 的定义来实现不同的匹配策略。
2.3 六种引用校正算法
论文提出了六种轻量级引用校正方法,按计算复杂度递增排列:
2.3.1 关键词匹配(Keyword Matching)
最基础的方法,使用token交集大小作为相似度函数:
f k e y w o r d ( x i , x ^ j ) = ∣ t o k e n s ( x i ) ∩ t o k e n s ( x ^ j ) ∣ f_{keyword}(x_i, \hat{x}_j) = |tokens(x_i) \cap tokens(\hat{x}_j)| fkeyword(xi,x^j)=∣tokens(xi)∩tokens(x^j)∣
公式解读:
- t o k e n s ( ⋅ ) tokens(\cdot) tokens(⋅) 函数将文本分词为token集合
- ∩ \cap ∩ 表示集合交集运算
- ∣ ⋅ ∣ |\cdot| ∣⋅∣ 表示集合元素个数
- 作用:统计事实点和文档之间共享的词汇数量,数值越大表示匹配度越高
- 优点:计算极快,无需额外模型
- 局限:无法处理同义词(如"汽车"与"轿车")和语境差异(如金融领域的"yield收益率"与农业领域的"yield产量")
2.3.2 关键词+语义上下文匹配(KSC)
在关键词匹配基础上引入语义相关性:
f ( x i , x ^ j ) = λ ⋅ f k e y w o r d ( x i , x ^ j ) + ( 1 − λ ) ⋅ r ( q , x ^ j ) (2) f(x_i, \hat{x}j) = \lambda \cdot f{keyword}(x_i, \hat{x}_j) + (1-\lambda) \cdot r(q, \hat{x}_j) \tag{2} f(xi,x^j)=λ⋅fkeyword(xi,x^j)+(1−λ)⋅r(q,x^j)(2)
公式解读:
- λ \lambda λ:平衡系数,控制关键词匹配与语义相关性的权重比例
- f k e y w o r d ( x i , x ^ j ) f_{keyword}(x_i, \hat{x}_j) fkeyword(xi,x^j):第一项,事实点与文档的关键词匹配分数
- r ( q , x ^ j ) r(q, \hat{x}_j) r(q,x^j):第二项,原始查询 q q q 与文档 x ^ j \hat{x}_j x^j 的检索相关性分数(来自RAG的检索阶段)
- 设计思路:当多个文档关键词匹配分数相近时,优先选择与用户原始查询更相关的文档
- 最优参数 :实验表明 λ = 0.8 \lambda=0.8 λ=0.8 时效果最佳,即以关键词匹配为主(80%权重),语义相关性为辅(20%权重)
2.3.3 BERT Score
使用LongFormer模型生成上下文嵌入,计算事实点与文档间的语义相似度:
f ( x i , x ^ j ) = 1 ∣ x i ∣ ∑ t i l ∈ x i max t ^ j k ∈ x ^ j e ( t i l ) ⊤ e ( t ^ j k ) (3) f(x_i, \hat{x}j) = \frac{1}{|x_i|} \sum{t_{il} \in x_i} \max_{\hat{t}{jk} \in \hat{x}j} e(t{il})^{\top} e(\hat{t}{jk}) \tag{3} f(xi,x^j)=∣xi∣1til∈xi∑t^jk∈x^jmaxe(til)⊤e(t^jk)(3)
公式解读:
- e ( t ) e(t) e(t):token t t t 的上下文嵌入向量(由LongFormer生成)
- t i l t_{il} til:事实点 x i x_i xi 中的第 l l l 个token
- t ^ j k \hat{t}_{jk} t^jk:文档 x ^ j \hat{x}_j x^j 中的第 k k k 个token
- e ( t i l ) ⊤ e ( t ^ j k ) e(t_{il})^{\top} e(\hat{t}_{jk}) e(til)⊤e(t^jk):两个token嵌入的点积,表示语义相似度
- max t ^ j k \max_{\hat{t}_{jk}} maxt^jk:对于事实点中的每个token,找到文档中与之最相似的token
- 1 ∣ x i ∣ ∑ t i l \frac{1}{|x_i|} \sum_{t_{il}} ∣xi∣1∑til:对所有token的最大相似度取平均
- 作用:解决关键词匹配无法处理的同义词和上下文语义问题
- 计算流程:事实点中每个词 → 在文档中找最相似的词 → 取相似度 → 所有词平均
2.3.4 微调BERT Score(FBS)
基于ColBERT思想,在特定领域数据上微调BERT模型,采用对比学习框架:
| 样本类型 | 定义 | 作用 |
|---|---|---|
| 正样本 x + x^+ x+ | 事实点与其正确来源文档的配对 | 拉近正确配对的嵌入距离 |
| 负样本 x − x^- x− | 事实点与无关文档的配对 | 推远错误配对的嵌入距离 |
训练目标:使用交叉熵损失,最大化正样本相似度,最小化负样本相似度。通过微调,模型学会捕捉引用归属和事实蕴含的细微语义差异。
2.3.5 LLM匹配
使用轻量级LLM(如Qwen 2.5B)直接判断事实点与文档的匹配关系:
方法特点:
- 通过精心设计的提示词引导模型输出匹配分数
- 能捕捉复杂的语义关系和推理链条
- 权衡:准确度较高,但延迟显著增加(1.586秒/事实点 vs 0.015秒)
- 为控制成本,不使用链式思维(Chain-of-Thought)等复杂技术
2.3.6 注意力图复用(概念验证)
创新性地复用生成阶段LLM的注意力权重,分析模型在生成每个事实点时对输入文档的关注程度。
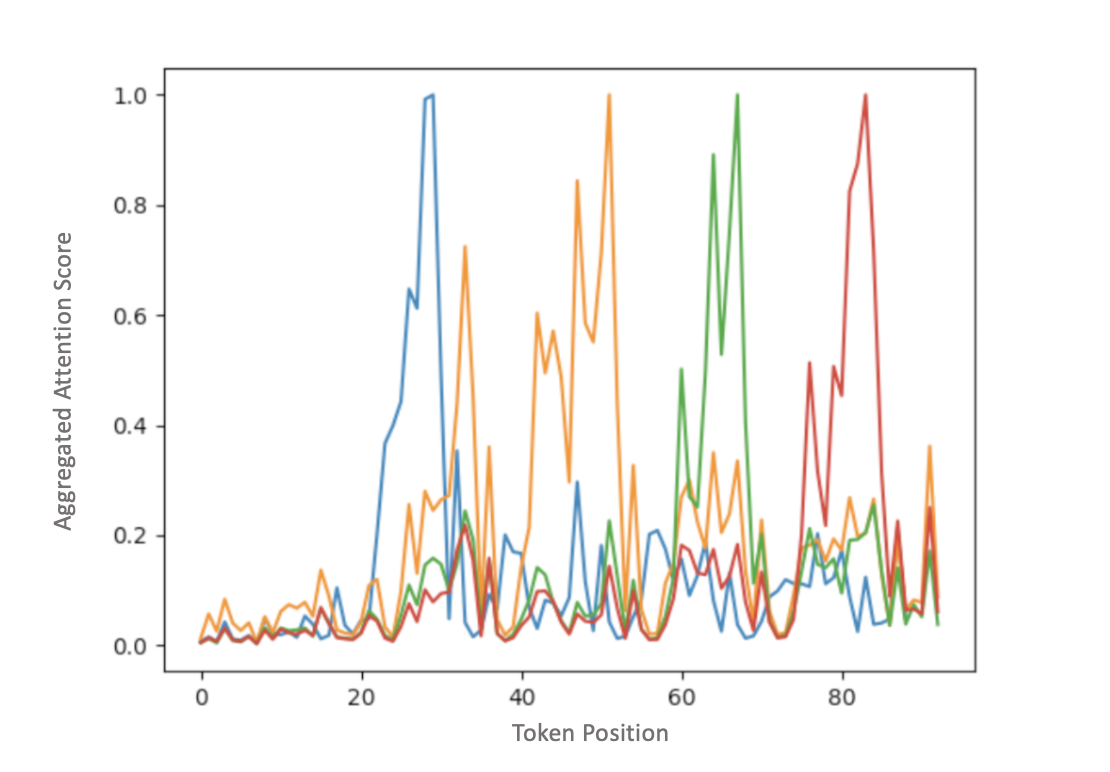
图2:LLM注意力图谱用于引用归属的可视化分析
图解说明:
- X轴:输入提示词(prompt)中的token位置,包含检索到的多个文档
- Y轴:生成输出时对所有输入token的注意力权重总和
- 峰值含义:峰值位置对应模型生成特定事实时实际参考的文档区域
- 应用价值:通过分析注意力分布,可以直接识别LLM在生成某个事实点时"看"了哪个文档
- 局限性:需要访问模型内部状态(注意力矩阵),在商业API(如GPT-4 API)场景中无法获取,仅适用于开源模型或自部署场景
3. 评估指标
3.1 平均问题级准确率(MQLA)
论文提出Mean Question-Level Accuracy (MQLA) 作为综合评估指标,涵盖以下维度:
| 评估维度 | 英文名 | 说明 | 阈值要求 |
|---|---|---|---|
| URL相关性 | Relevancy URL | 引用的URL与事实点的相关程度 | ≥ 0.8 |
| 关键词相关性 | Relevancy Keywords | 回答中的关键词是否相关 | ≥ 0.8 |
| 事实相关性 | Relevancy Facts | 回答中的事实是否相关 | ≥ 0.8 |
| 正确性 | Correctness | 事实是否可被引用验证(区分幻觉和错误引用) | ≥ 0.8 |
| 完整性 | Completeness | 响应是否完整覆盖查询意图 | ≥ 0.8 |
MQLA计算公式:
M Q L A = 1 N ∑ i = 1 N 1 所有相关性指标 ≥ 0.8 ∧ 幻觉事实数 ≤ 1 MQLA = \frac{1}{N}\sum_{i=1}^{N} \mathbb{1}\\text{所有相关性指标} \\geq 0.8 \\land \\text{幻觉事实数} \\leq 1 MQLA=N1i=1∑N1所有相关性指标≥0.8∧幻觉事实数≤1
公式解读:
- N N N:评估问题总数
- 1 ⋅ \mathbb{1}\\cdot 1⋅:指示函数,条件满足时为1,否则为0
- 判定规则:只有当一个问题的所有相关性指标都 ≥ 0.8,且幻觉事实数 ≤ 1 时,该问题得分为1,否则为0
- 设计意图:采用严格的二元判定,确保只有高质量回答才被计入,避免"部分正确"的模糊评估
4. 实验结果
4.1 实验设置
| 配置项 | 详情 |
|---|---|
| 数据集 | 50个代表性问题,涵盖多种查询类型 |
| 评估方式 | 双人专家人工审核 |
| 计算环境 | AWS g5.4xlarge实例 |
| 对比模型 | Model A(高成本)、Model B(中成本)、Model C(低成本)、Qwen 14B(开源) |
4.2 引用校正方法对比
以Model C为基准,各方法的性能对比如下:
| 方法 | MQLA提升 | 相关性URL | 事实正确引用提升 | p90延迟(秒/事实点) | 适用场景 |
|---|---|---|---|---|---|
| 无校正(基线) | - | - | - | - | - |
| 关键词匹配 | +12.7% | -0.9% | +12.0% | 0.014 | 延迟敏感场景 |
| KSC | +15.5% | -0.9% | +13.6% | 0.015 | 生产环境首选 |
| BERT Score | +2.6% | -1.0% | +3.2% | 0.389 | 不推荐 |
| 微调BERT | +15.8% | +1.5% | +13.7% | 0.389 | 资源充足场景 |
| LLM匹配 | +1.9% | +0.9% | +7.0% | 1.586 | 高精度需求 |
关键发现:
- KSC方法:以极低延迟(0.015秒)实现15.5%的准确率提升,是性价比最高的选择
- 微调BERT:准确率最高(+15.8%),且是唯一提升URL相关性的方法
- 原生BERT Score:效果不佳,说明通用语义相似度不等于引用归属能力
- LLM匹配:延迟最高但效果一般,不适合生产环境
4.3 跨模型泛化性分析
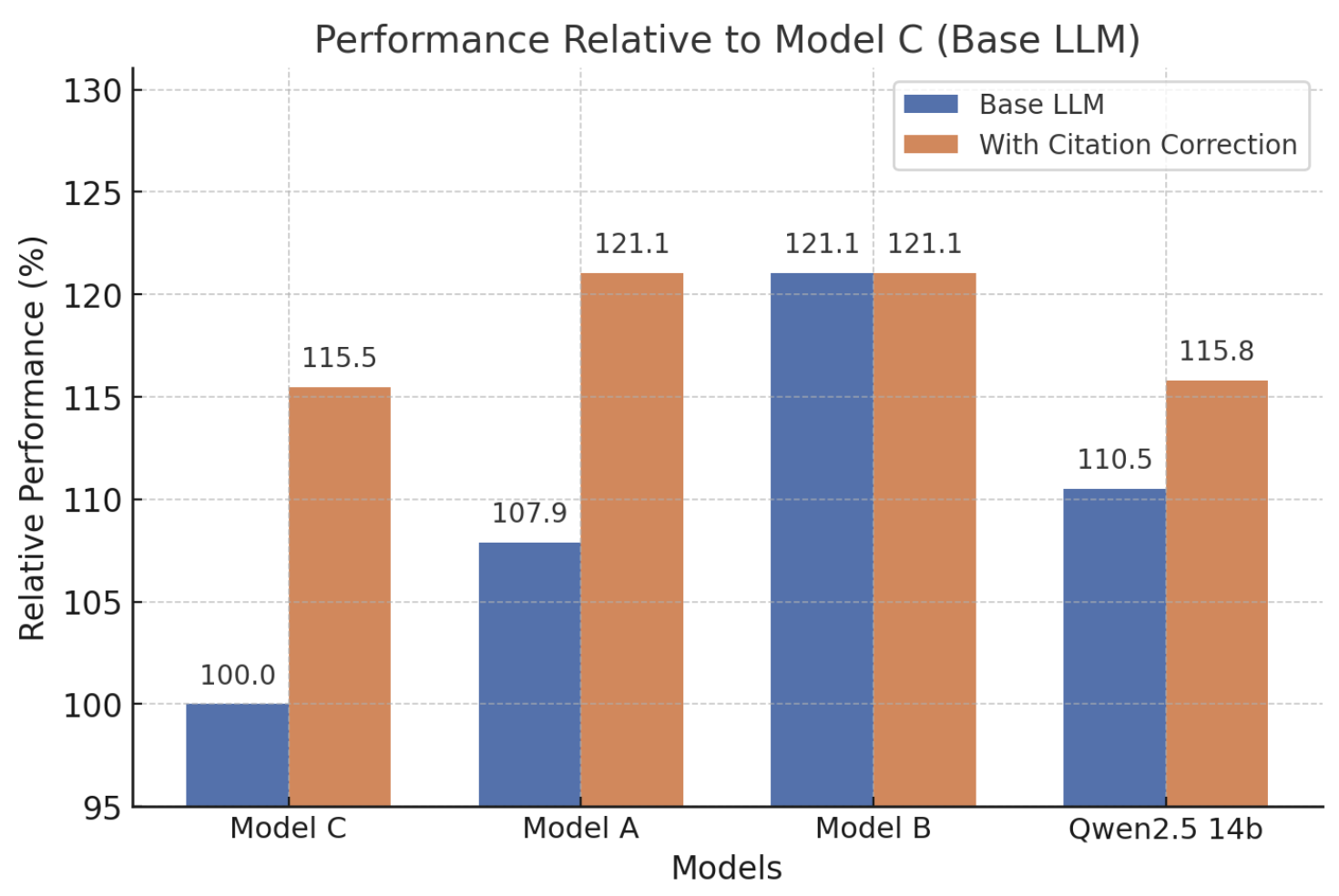
图3:不同LLM采用CiteFix后的MQLA相对提升百分比
图解说明:
- X轴:不同的LLM模型(Model A/B/C/Qwen 14B)
- Y轴:应用CiteFix后MQLA的相对提升百分比
- 柱状图含义:每组柱子代表不同校正方法在该模型上的效果
- 核心洞察:不同模型的最优校正策略存在差异,需要针对性选择
各模型的最优校正策略:
| 生成模型 | 最优校正方法 | MQLA提升 | 成本对比 | 原因分析 |
|---|---|---|---|---|
| Model C | 微调BERT | +15.8% | 基线 | 低成本模型引用能力弱,需要强校正 |
| Model B | 微调BERT | +21.0% | +220% | 中等模型引用能力适中 |
| Model A | KSC | +21.0% | +1100% | 高成本模型本身引用较准,轻量校正即可 |
| Qwen 14B | KSC | +15.8% | 开源 | 开源模型表现与商业模型相当 |
4.4 错误类型分析
论文对引用错误进行了细粒度分类,揭示了错误的本质:
| 模型 | 不可验证事实占比 | 引用错位占比 | 纯幻觉占比 | 解读 |
|---|---|---|---|---|
| Model A | 90.8% | 9.1% | 0.1% | 几乎所有错误都是引用问题 |
| Model B | 66.6% | 34.4% | 33.4% | 错误类型较均衡 |
| Model C | 80.6% | 19.4% | - | 80%的错误可通过CiteFix修复 |
| Qwen 14B | 76.2% | 13.8% | 29.2% | 开源模型幻觉比例较高 |
核心洞察:
- Model C中80.6%的错误为引用错位而非幻觉
- 这意味着模型生成了正确的信息,只是没有正确标注来源
- CiteFix专门针对这类错误设计,应用后可将错误率大幅降低
4.5 成本效益分析
| 对比场景 | 结论 | 量化数据 |
|---|---|---|
| Model C + CiteFix vs Model A | Model C成本降低12倍 ,推理速度快3倍 ,性能超越Model A | MQLA: 15.8% vs 原生 |
| Model B + CiteFix vs Model A | Model B成本降低80%,性能持平或更优 | 成本节省显著 |
实践意义:通过CiteFix,企业可以使用低成本模型达到甚至超越高成本模型的引用准确率,显著降低RAG系统的运营成本。
5. 技术贡献与创新点
5.1 核心贡献
| 贡献 | 详细说明 | 影响 |
|---|---|---|
| 首次系统性研究RAG引用准确性 | 揭示了引用错位是主要错误类型(80%),而非传统认知中的幻觉 | 改变了RAG优化的研究方向 |
| 提出六种轻量级后处理方法 | 无需修改原有RAG架构,即插即用 | 降低了部署门槛 |
| 实现显著的成本效益提升 | 低成本模型+CiteFix可超越高成本模型的原生性能 | 为企业节省大量成本 |
5.2 方法论创新
- 事实点粒度的引用分析:相比于文档级别的验证,细粒度分析提供更精准的校正能力
- 注意力图复用的概念验证:为未来利用模型内部状态进行引用归属提供了方向
- 混合匹配策略:KSC方法巧妙结合词汇匹配和语义相关性,以极低成本获得高收益
6. 局限性与未来方向
6.1 当前局限
| 局限性 | 说明 | 潜在影响 |
|---|---|---|
| 事实点分割依赖 | 分割质量直接影响下游校正效果 | 复杂句式可能分割不准确 |
| 领域适应成本 | 微调BERT方法需要领域标注数据 | 新领域部署成本增加 |
| 多文档引用 | 当事实点需要多个文档联合支撑时处理复杂度增加 | 综合性事实可能校正不完整 |
| API黑盒限制 | 注意力图复用方法在商业API场景不可用 | 最优方法无法在GPT-4等API上使用 |
6.2 未来研究方向
- 端到端引用生成:将引用校正能力整合到模型训练阶段,从源头提升引用质量
- 多语言扩展:验证方法在非英语场景的有效性
- 实时校正:在生成过程中动态调整引用,而非后处理
- 与幻觉检测的协同:构建统一的RAG质量保障框架,同时处理幻觉和引用错误
7. 实践启示
7.1 企业RAG部署建议
| 场景 | 推荐方法 | 理由 |
|---|---|---|
| 延迟敏感(<50ms) | KSC | 延迟仅0.015秒,效果接近最优 |
| 资源充足 | 微调BERT | 更稳定的跨模型泛化性能 |
| 成本敏感 | 低成本模型 + KSC | 可超越高成本模型原生性能 |
| 高精度需求 | 微调BERT + 人工审核 | 最高准确率 |
7.2 方法选择决策树
开始
├─ 是否有领域标注数据?
│ ├─ 是 → 微调BERT(最优效果)
│ └─ 否 → KSC(无需训练)
│
├─ 延迟要求是否严格(<20ms)?
│ ├─ 是 → 关键词匹配或KSC
│ └─ 否 → 可考虑BERT Score
│
└─ 是否使用开源模型?
├─ 是 → 可尝试注意力图复用
└─ 否 → KSC或微调BERT7.3 评估框架建议
建立包含以下维度的RAG评估体系:
| 维度 | 指标 | 重要性 |
|---|---|---|
| 响应相关性 | 回答是否切题 | ⭐⭐⭐ |
| 事实准确性 | 信息是否正确 | ⭐⭐⭐⭐ |
| 引用准确率 | 来源是否正确标注 | ⭐⭐⭐⭐⭐ |
| 响应完整性 | 是否覆盖所有方面 | ⭐⭐⭐ |
| 延迟与成本 | 系统效率 | ⭐⭐⭐ |
8. 总结
CiteFix通过高效的后处理算法,在不显著增加延迟和成本的前提下,有效解决了RAG系统中的引用不准确问题。其核心价值在于:
- 揭示问题本质:80%的"错误"是引用错位而非幻觉,这是一个可修复的问题
- 提供实用方案:KSC方法以0.015秒延迟实现15.5%准确率提升
- 降低部署成本:低成本模型+CiteFix可超越高成本模型
- 增强可信度:正确的引用让用户可以验证AI生成的内容
参考文献
- Zhang, T., et al. (2020). BERTScore: Evaluating Text Generation with BERT. ICLR 2020.
- Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. SIGIR 2020.
- Beltagy, I., et al. (2020). Longformer: The Long-Document Transformer. arXiv:2004.05150.
- Gao, L., et al. (2023). Enabling Large Language Models to Generate Text with Citations. EMNLP 2023.