算法和数据结构--时间复杂度和空间复杂度
一、引言
相信大家都一定听说过"屎山代码"这个词,我们在网络段子里或者程序员工作中一定听到或者遇到过,相反的,一些写得好代码可谓是既简洁美观,又高效实用。同样的,在我们日常敲代码过程中,也常常会发现,我们用不一样的思路写的代码,有的用时多,有的用时少,内存在占用也不一样。当我们去面对一个算法想去了解或者对比时间和内存消耗的时候直接去测试可能会因为环境等等原因比较麻烦,那么有没有一种衡量算法时间和空间消耗的方法呢?
这时候,时间复杂度和空间复杂度的概念便产生了。
本篇文章就带大家认识了解时间复杂度和空间复杂度这两个衡量算法优劣的概念,轻轻松松的看破各种算法。
二、时间复杂度的认识
1.什么是时间复杂度
时间复杂度 是衡量算法执行效率的一个核心指标,它描述了算法运行时间随输入规模增长的变化趋势,而非具体的执行时间。
简单来说,它关注的是:当输入的数据量(比如数组长度、元素个数)变大时,算法需要的操作次数会以什么样的速率增加。
简单理解,大家可以把它类比为数学里面的函数曲线来理解。像一次函数,x增大时候,y也跟着增大,当不论如何变大,它的增长速率是不变的,还算较为平滑。如果是二次三次函数呢,那样y的值就会随x增大快速增加,如果是指数函数那便是y的值的爆炸增加。算法也是一样,好的算法,时间复杂度低,那么当数据增加的时候,它的时间增加就相对平滑,如果时间复杂度高,那样当数据量增加的时候,它的运行时间就会爆炸的增加。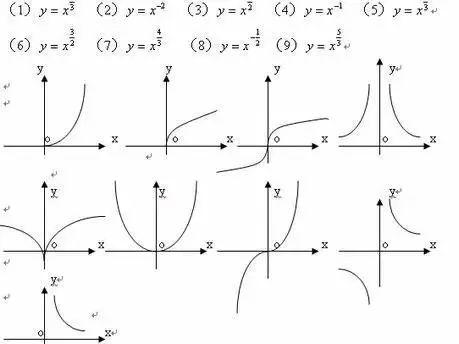
2.时间复杂度的表达
- 它通常用大 O 记号来表示,比如 \(O(1)\)、\(O(n)\)、\(O(n^2)\) 等。
- 计算时会忽略常数项和低阶项,只保留影响趋势的最高阶项。比如一个算法的实际操作次数是 \(3n^2 + 5n + 10\),它的时间复杂度就是 \(O(n^2)\)。
举两个直观例子:
- 访问数组中第 k 个元素,不管数组多长,只需要 1 次操作 → 时间复杂度 \(O(1)\)。
- 遍历一个长度为 n 的数组,数组越长,遍历的次数就越多,操作次数和 n 成正比 → 时间复杂度 \(O(n)\)。
三、空间复杂度的认识
1. 什么是空间复杂度
空间复杂度是衡量算法运行过程中临时占用内存空间 的核心指标,描述的是内存使用量随输入规模增长的变化趋势,而非具体占用的字节数。
简单来说,它关注的是:当输入的数据量(比如数组长度、元素个数)变大时,算法额外需要的临时存储空间会以什么样的速率增加。
可以类比成 "搬家打包":输入规模是要搬的物品数量,空间复杂度就是你需要准备的额外箱子数量 ------ 好的算法用的 "箱子" 增长平缓,差的算法可能随着物品变多,需要的箱子数会猛增。
2. 空间复杂度的表达
- 它同样用大 O 记号表示,比如 \(O(1)\)、\(O(n)\)、\(O(n^2)\) 等。
- 计算时会忽略常数项和低阶项,只保留影响趋势的最高阶项。比如一个算法额外用了 \(2n + 3\) 个临时变量,它的空间复杂度就是 \(O(n)\)。
举两个直观例子:
- 计算两个数的和,不管这两个数多大,只需要固定几个临时变量 → 空间复杂度 \(O(1)\)。
- 新建一个长度为 n 的数组来存储原数组的每个元素 → 临时空间随 n 增长,空间复杂度 \(O(n)\)。
四、常见复杂度的对比与实际意义
1. 常见复杂度的增长速度排序
从 "高效" 到 "低效",常见复杂度的增长趋势是:\(O(1) < O(\log n) < O(n) < O(n\log n) < O(n^2) < O(2^n) < O(n!)\)
可以这么理解:
- O(1)/O(log n):就算数据量从 10 涨到 100 万,耗时 / 内存几乎没变化(比如查字典的索引、二分查找);
- O(n)/O(n log n):数据量翻倍,耗时 / 内存也跟着翻倍(比如遍历数组、排序算法里的快排);
- O(n²)/O(2ⁿ):数据量稍微变大,耗时 / 内存直接 "起飞"(比如双重循环遍历、暴力破解密码)。
2. 复杂度在实际开发中的作用
写代码时,复杂度的选择直接影响程序的 "上限":
- 如果你写了个 O (n²) 的算法处理 10 条数据,可能只花 0.1 秒;但如果处理 10 万条数据,可能要花几个小时(直接卡死);
- 而如果换成 O (n log n) 的算法,处理 10 万条数据可能只需要 1 秒。
这也是为什么 "屎山代码" 跑小数据没问题,跑大数据就崩溃 ------ 它的复杂度太高了。
五、如何优化复杂度?
1. 时间复杂度的优化思路
核心是 "减少不必要的操作":
- 比如从 "双重循环遍历"(O (n²))改成 "用哈希表存值"(O (n));
- 比如把 "顺序查找"(O (n))改成 "二分查找"(O (log n))。
2. 空间复杂度的优化思路
核心是 "复用空间,减少临时存储":
- 比如数组排序时,不用额外开新数组(原地排序,O (1) 空间),而不是新建数组存结果(O (n) 空间);
- 比如用 "变量交替存储" 代替 "数组存储所有中间结果"(比如斐波那契数列不用数组存,只用两个变量)。
六、总结
时间复杂度和空间复杂度,其实是衡量算法 "性价比" 的两把尺子:
- 时间复杂度看 "跑得多快",空间复杂度看 "占多少内存";
- 实际开发中经常需要 "trade-off(权衡)":比如用一点额外空间(提高空间复杂度),换更快的运行速度(降低时间复杂度),这就是常说的 "空间换时间"。
七、实例分析(C语言版)
对于复杂度理解一定要多看代码,下面我们列出几个简单例子帮助大家快速入门。
例子 1:O (1) 复杂度 ------ 求两数之和
核心特点:无论输入的两个数多大,操作次数永远是 1 次,时间 / 空间复杂度都为 O (1)。
c
c
#include <stdio.h>
// 求a和b的和,固定1次运算
int add(int a, int b)
{
return a + b; // 仅1次加法操作,与a、b大小无关
}
int main()
{
int x = 10, y = 20;
printf("%d + %d = %d\n", x, y, add(x, y)); // 输出30
return 0;
}复杂度分析:
- 时间复杂度:O (1)(固定 1 次操作,无循环);
- 空间复杂度:O (1)(仅用 2 个输入变量 + 1 个返回值,无额外临时存储)。
例子 2:O (n) 复杂度 ------ 计算数组元素总和
核心特点:操作次数和数组长度 n 成正比,n 越大,循环次数越多。
c
c
#include <stdio.h>
// 计算数组所有元素的和,循环n次
int arraySum(int arr[], int n)
{
int sum = 0;
for (int i = 0; i < n; i++)
{
sum += arr[i]; // 循环n次,每次1次加法
}
return sum;
}
int main()
{
int arr[] = {1, 2, 3, 4, 5};
int len = sizeof(arr) / sizeof(arr[0]);
printf("数组总和:%d\n", arraySum(arr, len)); // 输出15
return 0;
}复杂度分析:
- 时间复杂度:O (n)(单层循环,循环次数 = 数组长度 n);
- 空间复杂度:O (1)(仅用 sum、i 两个临时变量,与 n 无关)。
例子 3:O (n) 复杂度 ------ 生成斐波那契数列前 n 项(入门版)
核心特点:单层循环,操作次数和要生成的项数 n 成正比,直观体现 O (n) 时间复杂度,同时展示 O (n) 空间的使用场景。
c
c
#include <stdio.h>
// 生成斐波那契数列前n项,存入数组(斐波那契:0,1,1,2,3,5,...)
void generateFibonacci(int n, int fib[])
{
if (n >= 1) fib[0] = 0; // 第1项为0
if (n >= 2) fib[1] = 1; // 第2项为1
// 从第3项开始,每项=前两项之和,循环n-2次(总循环次数≈n)
for (int i = 2; i < n; i++)
{
fib[i] = fib[i-1] + fib[i-2];
}
}
int main()
{
int n = 8; // 生成前8项
int fib[n]; // 存储结果的数组(C99及以上支持变长数组)
generateFibonacci(n, fib);
printf("斐波那契数列前%d项:", n);
for (int i = 0; i < n; i++)
{
printf("%d ", fib[i]); // 输出:0 1 1 2 3 5 8 13
}
printf("\n");
return 0;
}复杂度分析:
- 时间复杂度:O (n)(单层循环,循环次数 = n-2,忽略常数项后为 O (n));
- 空间复杂度:O (n)(额外用长度为 n 的数组存储结果,空间随 n 增长)。
例子 4:O (n²) 复杂度 ------ 打印 n×n 矩阵(双重循环)
核心特点:有两层嵌套循环,操作次数约为 n×n 次,n 增大时操作次数急剧增加。
c
c
#include <stdio.h>
// 打印n行n列的矩阵(元素为行号+列号)
void printMatrix(int n)
{
for (int i = 0; i < n; i++)
{ // 外层循环n次
for (int j = 0; j < n; j++)
{ // 内层循环n次
printf("%d ", i + j); // 总操作次数n×n次
}
printf("\n");
}
}
int main()
{
printMatrix(3); // 打印3×3矩阵
/* 输出:
0 1 2
1 2 3
2 3 4
*/
return 0;
}复杂度分析:
- 时间复杂度:O (n²)(双重循环,总操作次数 = n²);
- 空间复杂度:O (1)(仅用 i、j 两个循环变量,无额外存储)。
例子 5:O (log n) 复杂度 ------ 计算 2 的 n 次方(优化版)
核心特点:每次循环将 "计算规模" 减半,循环次数约为 log₂n 次(比如 n=8 时,循环 3 次;n=16 时,循环 4 次)。
c
c
#include <stdio.h>
// 计算2^n(n为非负整数),优化版:每次乘2,循环log2(n)次
int powerOfTwo(int n)
{
if (n == 0) return 1; // 2^0=1
int result = 1;
int base = 2;
while (n > 0)
{
if (n % 2 == 1)
{
result *= base; // 仅当n为奇数时乘一次
}
base *= base; // 底数翻倍(2→4→8→...)
n /= 2; // n减半(规模缩小)
}
return result;
}
int main()
{
printf("2^5 = %d\n", powerOfTwo(5)); // 输出32
printf("2^10 = %d\n", powerOfTwo(10)); // 输出1024
return 0;
}复杂度分析:
- 时间复杂度:O (log n)(每次 n 减半,循环次数 = log₂n);
- 空间复杂度:O (1)(仅用 result、base、n 三个临时变量)。
简单例子总结(一目了然)
| 算法功能 | 时间复杂度 | 空间复杂度 | 核心逻辑 |
|---|---|---|---|
| 两数之和 | O(1) | O(1) | 无循环,固定 1 次操作 |
| 数组求和 | O(n) | O(1) | 单层循环,次数 = 输入规模 n |
| 生成斐波那契前 n 项 | O(n) | O(n) | 单层循环,次数≈n,数组存结果 |
| 打印 n×n 矩阵 | O(n²) | O(1) | 双重循环,次数 = n×n |
| 计算 2 的 n 次方 | O(log n) | O(1) | 循环中规模减半,次数 = log₂n |
九、结语
到这里,关于时间复杂度和空间复杂度的核心知识与实战例子就全部梳理完毕了。
其实这两个概念一点都不 "抽象"------ 时间复杂度看的是 "算法跑得多快",核心看循环的层数和规模变化;空间复杂度看的是 "算法占多少内存",核心看是否用了随输入规模增长的临时存储。而我们举的所有简单 C 语言例子,都是为了帮你把 "O (1)、O (n)、O (log n)" 这些符号,和实际代码的逻辑对应起来。
掌握它们的意义,不在于死记硬背公式,而在于养成 "写代码前先想效率" 的思维:遇到问题时,能先预判不同解法的复杂度差异,避开 "小数据能跑、大数据崩溃" 的坑;优化代码时,能精准找到核心瓶颈 ------ 是循环太多导致时间复杂度过高,还是冗余存储导致空间浪费。
对于新手来说,不用一开始就追求 "最优复杂度",先能写出正确的代码,再慢慢对照本文的例子,尝试优化循环、减少冗余存储,就能逐步提升。随着实践增多,你会发现:判断一个算法的优劣,一眼看穿 "屎山代码" 的低效之处,都会变得越来越轻松。