在日常MySQL数据库运维中,我们经常需要查询库表结构、监控性能、清理冗余数据等,重复编写SQL不仅耗时还易出错。本文整理了一批高频实用的SQL语句,涵盖库表管理、性能监控、索引优化等核心场景,直接复制即可使用,帮你提升运维效率。
一、库表基础信息查询
这部分SQL主要用于快速获取数据库、表的基础信息,适用于日常巡检或需求对接时的信息确认。
-
查看所有业务库
排除MySQL默认的系统库(如
information_schema、sys),直接定位业务相关数据库,避免误操作系统表。sqlselect schema_name from information_schema.schemata where schema_name not in ('information_schema','sys','mysql','performance_schema');
-
统计所有数据库大小
按数据库维度计算存储占用(单位:MB),快速识别大容量库,为存储规划提供依据。
sqlselect table_schema, sum(data_length + index_length) / 1024 / 1024 as 'database size (mb)' from information_schema.tables group by table_schema;
-
查询指定库表的字段详情
以
maria库为例,查看所有表的字段名、字段类型及排序规则,常用于表结构文档生成或字段映射确认。sqlselect table_schema,table_name,column_name,column_type,collation_name from information_schema.columns where table_schema='maria';
-
查看单表详细信息
用
\G格式化输出,清晰展示表的引擎、字符集、创建时间等关键属性,排查表结构异常时常用。sqlselect * from information_schema.tables where table_schema='maria' and table_name='student_info'\G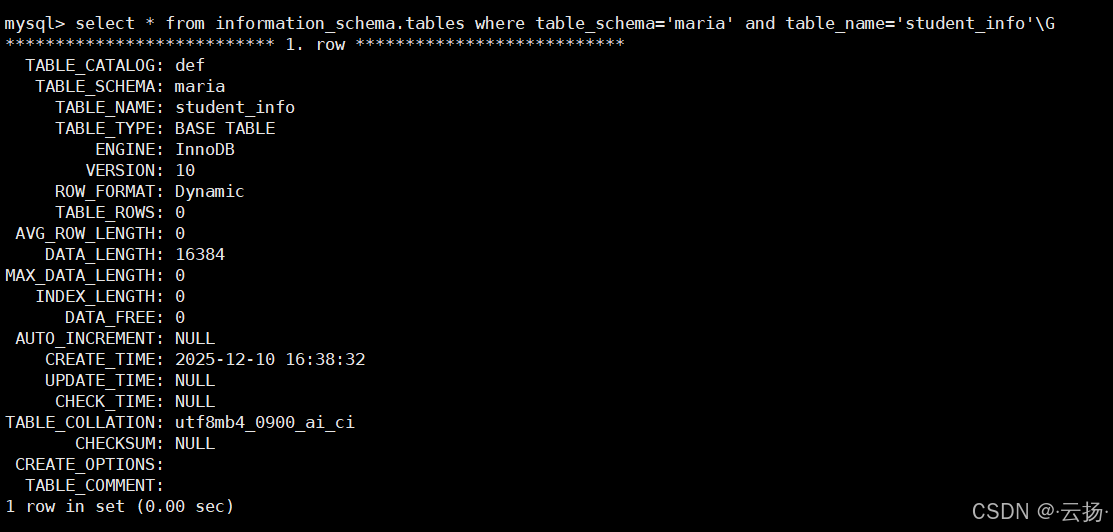
-
某库中所有表详情
sqlselect table_schema,table_name,engine,table_collation from information_schema.tables where table_schema='maria';
-
批量操作某个前缀的表
sqlselect concat('select count(*) from martin.',table_name,';') from information_schema.tables where table_schema='maria' and table_name like 'a_%';
-
某个库的字符集和排序规则
sqlselect default_character_set_name, default_collation_name from information_schema.schemata where schema_name = 'maria';
-
每张表的平均行长度
sqlselect table_schema, table_name, avg_row_length from information_schema.tables where table_schema = 'maria';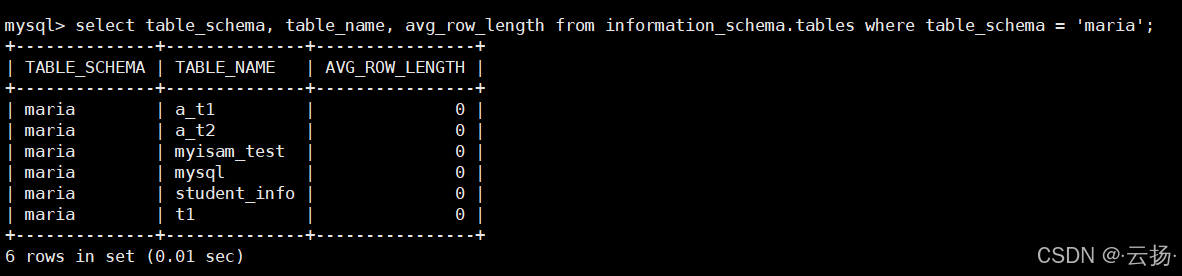
-
自增值的使用情况
sqlselect table_schema, table_name, auto_increment, (auto_increment / pow(2, 31)) * 100 as 'auto increment usage (%)' from information_schema.tables where table_schema = 'maria' and auto_increment is not null;
10. 表的创建时间和更新时间sqlselect table_schema, table_name, create_time, update_time from information_schema.tables where table_schema = 'maria';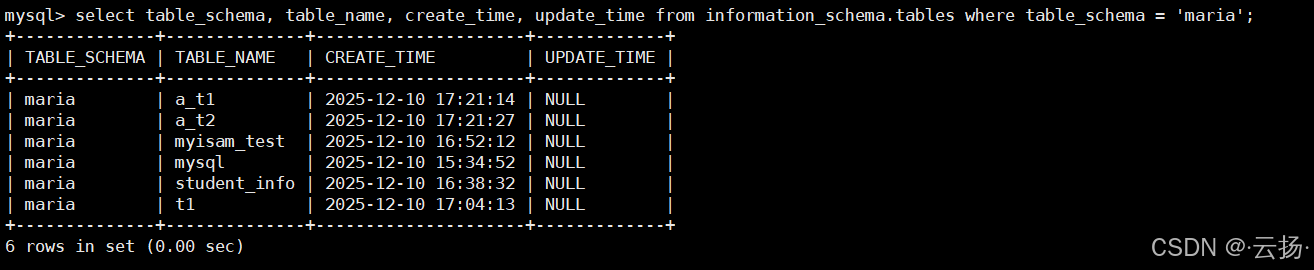
二、表结构与存储引擎优化
针对表结构合理性、存储引擎一致性的检查与调整,保障数据库稳定性。
-
查找非InnoDB引擎的表
InnoDB支持事务和行锁,是当前主流引擎。此SQL可快速定位使用MyISAM等旧引擎的表,便于统一引擎类型。
sqlselect table_schema,table_name,engine from information_schema.tables where table_schema not in('information_schema','sys','mysql','performance_schema') and engine<>'InnoDB';
-
批量生成修改存储引擎的语句
无需手动编写
alter table语句,直接生成所有非InnoDB表的引擎修改SQL,执行前建议备份数据。sqlselect distinct concat('alter table ',table_schema,'.',table_name,' engine=innodb',';') from information_schema.tables where (engine <> 'innodb' and table_schema not in ('information_schema','sys','mysql','performance_schema'));
-
定位无主键的表
主键是表的核心标识,无主键会影响查询效率和数据唯一性。此SQL可排查所有业务库中缺少主键的表。
sqlSELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_SCHEMA NOT IN ('information_schema', 'mysql', 'performance_schema','sys') AND TABLE_NAME NOT IN (SELECT DISTINCT TABLE_NAME FROM information_schema.COLUMNS WHERE COLUMN_KEY = 'PRI');
三、性能监控与问题排查
日常监控数据库连接、事务、碎片等情况,及时发现性能瓶颈或异常进程。
-
查看当前活跃连接数
通过
threads_connected参数了解数据库当前连接负载,判断是否需要调整连接池配置。sqlshow status where `variable_name` = 'threads_connected';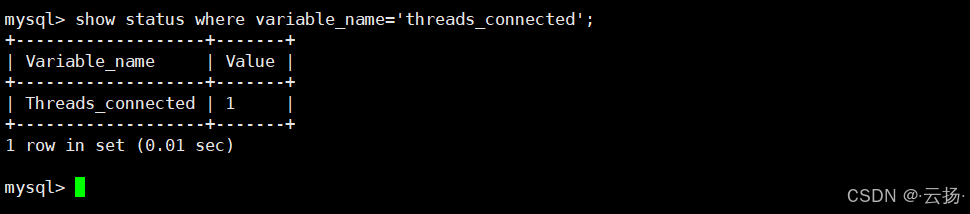
-
排查长时间运行的进程
筛选运行时间超过10秒的进程,避免长事务占用资源导致锁等待,可结合
kill语句终止异常进程。sqlselect * from information_schema.processlist where time > 10;
-
统计表碎片率
碎片过多会导致磁盘空间浪费和查询变慢,此SQL按碎片率排序,优先清理高碎片表(可通过
optimize table优化)。sqlselect table_name, data_free / (data_free + data_length + index_length) as 'fragmentation_rate', data_free,data_length,index_length from information_schema.tables where table_schema = 'maria' order by fragmentation_rate desc;
-
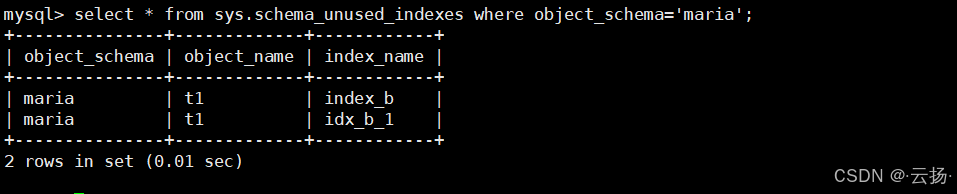
查看冗余与未使用索引
冗余索引会增加写入开销,未使用索引则浪费空间。通过以下语句清理无效索引,提升性能。
sql-- 查看冗余索引 select * from sys.schema_redundant_indexes ; -- 查看未使用索引 select * from sys.schema_unused_indexes where object_schema='maria';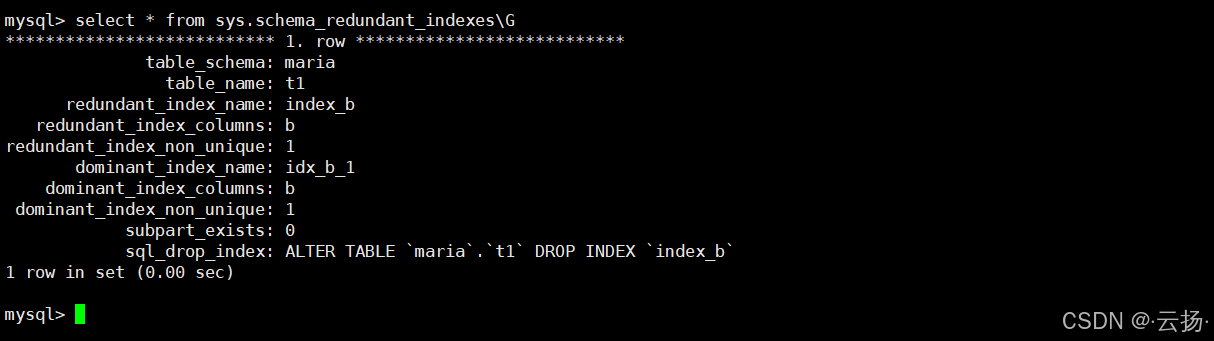
-
查询当前运行的事务
sqlselect * from information_schema.innodb_trx;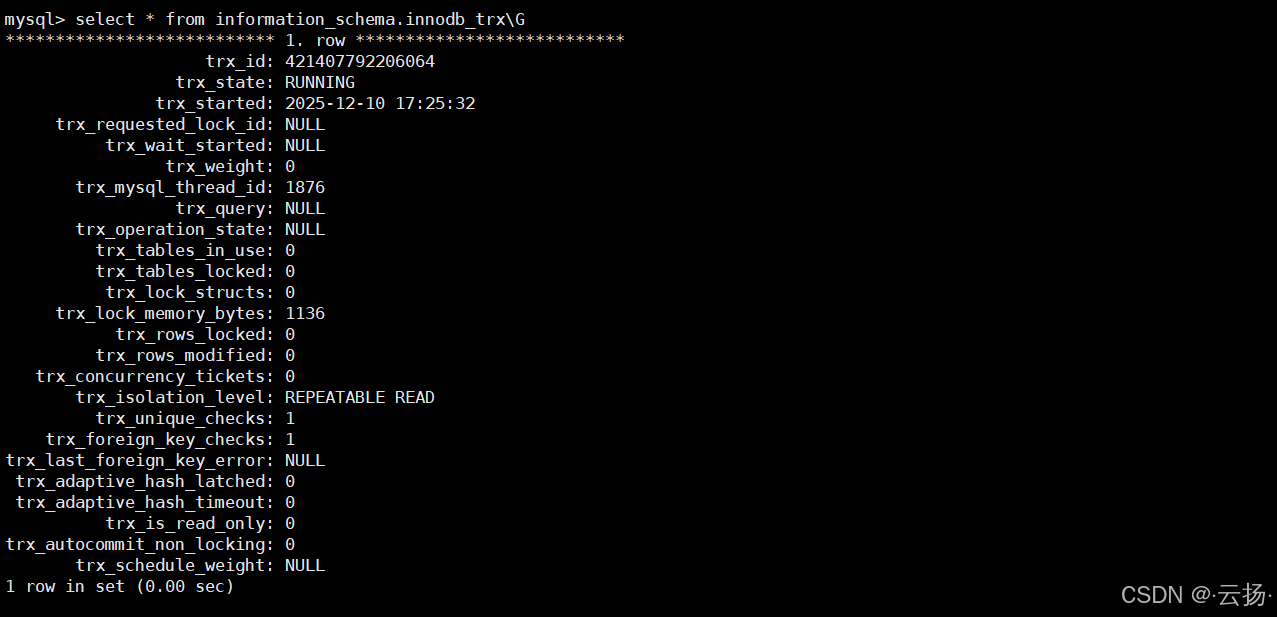
四、用户与SQL统计
管理数据库用户权限、统计SQL执行情况,保障数据安全与查询效率。
-
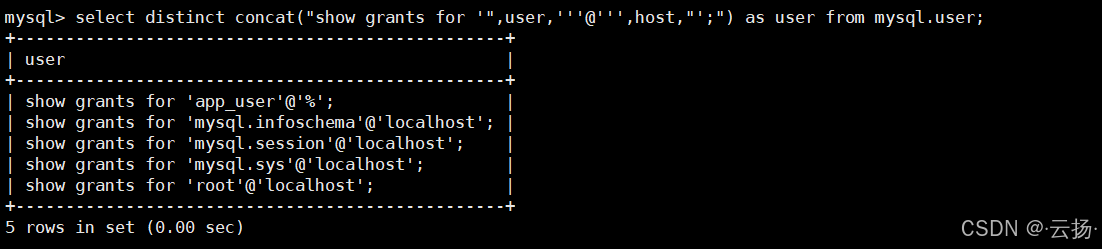
查看所有MySQL用户及权限语句
快速获取所有用户账号,并生成权限查询语句,便于权限审计。
sql-- 查看所有用户 select distinct concat("'",user,'''@''',host,"';") as user from mysql.user; -- 生成权限查询语句 select distinct concat("show grants for '",user,'''@''',host,"';") as user from mysql.user;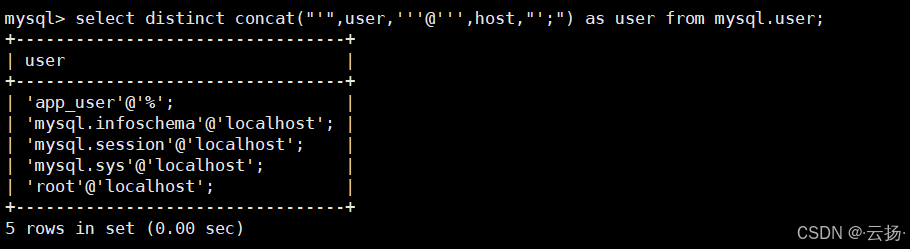
-
统计用户连接数
定位连接数过高的用户,排查是否存在异常连接或连接池配置不当的问题。
sqlselect user, host, count(*) as 'connections' from information_schema.processlist group by user, host;
-
查看最常执行的10条SQL
通过
performance_schema统计高频SQL,分析是否存在慢查询或可优化的重复语句。sqlselect digest_text, count_star, sum_timer_wait / count_star as avg_timer_wait from performance_schema.events_statements_summary_by_digest order by count_star desc limit 10;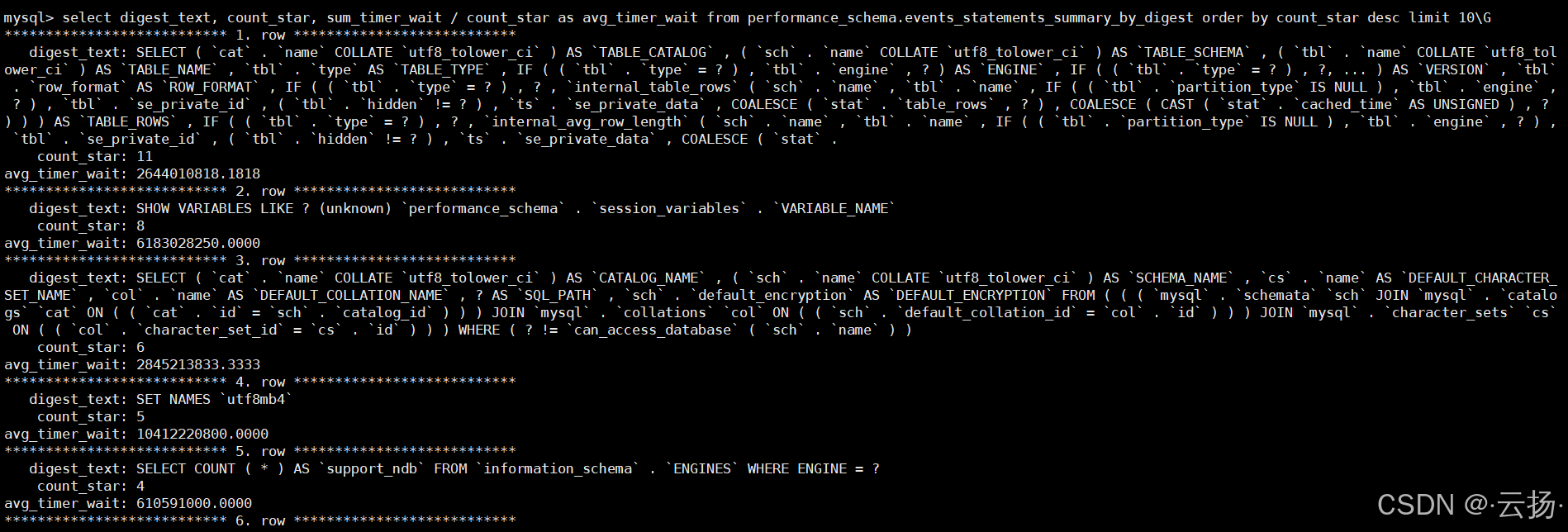
总结
以上SQL语句覆盖了MySQL运维的核心场景,无论是日常巡检、问题排查还是性能优化,都能直接复用。建议根据实际业务库名(如文中的maria)替换关键字,也可将常用语句整理成脚本,进一步提升工作效率。