一、引言
在过往的系列分享中,无论是轻量型向量模型的实操应用,还是大语言模型的生成推理与落地调试,我们始终围绕模型本地化调用这一核心场景展开,从环境搭建、参数优化到功能适配,逐步带领大家打通了本地跑通模型的全流程。但随着应用场景的升级,单一设备的本地化调用已难以满足多用户协同访问、高并发处理、长期稳定运行的需求,同时,将开源或自定义大模型封装为可网络访问的 API 接口,部署到服务器上实现稳定调用,已成为企业级应用、团队协作、产品集成的核心需求,此时,如何将调试成熟的模型平滑部署至云端服务器,实现从本地自用到全网可调用的跨越,成为衔接技术实操与业务落地的关键环节,也是我们接下来需要探讨的重点环节。
今天,我们将聚焦大模型从本地可用到云端可调用的全链路实操,沿着基础 API 调用、自动化接口文档生成、多方案打包部署上线的完整脉络,进行细致拆解与深度剖析,真正实现从技术跑通到场景落地的无缝衔接。
二、基础要求
1. 硬件要求
- **CPU:**普通办公电脑i5、i7 CPU也能跑,但速度慢;推荐多核 CPU。
- GPU: 大模型运行需要大量并行计算,GPU 能提速 10-100 倍。
- 入门级:NVIDIA RTX 3090/4070,8-12GB 显存,能跑 6B-7B 参数的轻量模型。
- 进阶级:NVIDIA A100,40GB 显存,能跑 13B-70B 参数的大模型。
- 无 GPU 方案:用 CPU 结合大内存,建议在32GB 以上,但运行速度极慢,仅适合测试。
- **内存(RAM):**至少 16GB,推荐 32GB 以上,模型加载到内存中运行,内存不够会卡顿或崩溃。
- **存储:**大模型文件体积大,6B 参数模型约 10GB,13B 模型约 20GB,需预留至少 50GB 硬盘空间,推荐 SSD,加载速度更快。
2. 软件环境
- **操作系统:**服务器首选推荐 Linux,如 Ubuntu 或个人电脑入门推荐Windows 10/11。
- **编程语言:**Python 3.8-3.10,大模型相关库对 Python 版本有严格要求,可能会出现各种闹心的版本兼容性问题。
- 核心依赖库:
- PyTorch/TensorFlow:大模型运行的底层框架,类似盖房子的地基)。
- Transformers:Hugging Face 推出的模型工具库,能快速加载各种大模型,如 ChatGLM、LLaMA,如果无法访问,推荐ModelScope也是很好的选择。
- FastAPI/Flask:用于创建 API 接口的 "web 框架"(让模型能被网络访问)。
- sentencepiece/tokenizers:大模型的语言翻译工具,把文字转换成模型能理解的格式。
3. 模型选择
- 初次接触或体验,先选轻量型,推荐入门模型,参数小、易部署、对硬件要求低:
- ChatGLM-6B:清华开发,中文支持好,6B 参数,显存要求≥8GB。
- LLaMA-7B(量化版):Meta 开发,英文支持好,7B 参数,量化后显存要求≥4GB。
- Mistral-7B:性能优秀,7B 参数,支持多语言,显存要求≥8GB。
- Qwen1.5-1.8B-Chat:CPU可运行,适合体验,普通个人电脑是不错的选择
- 模型来源:Hugging Face Hub 全球最大的大模型仓库,可直接下载模型文件,国内的ModelScope。
4. 网络基础
- **IP 地址:**个人电脑部署后通常使用localhost或127.0.0.1即可,服务器需查看指定开发外部访问的IP地址。
- **端口:**服务器上的门牌号,比如 8000、5000,API 接口会绑定一个端口,避免冲突。
- 局域网 vs 公网:
- 局域网:同一网络下的设备可访问,如办公室电脑、家里的手机。
- 公网:互联网上的任何设备可访问,需配置端口映射或公网 IP。
三、基础原理
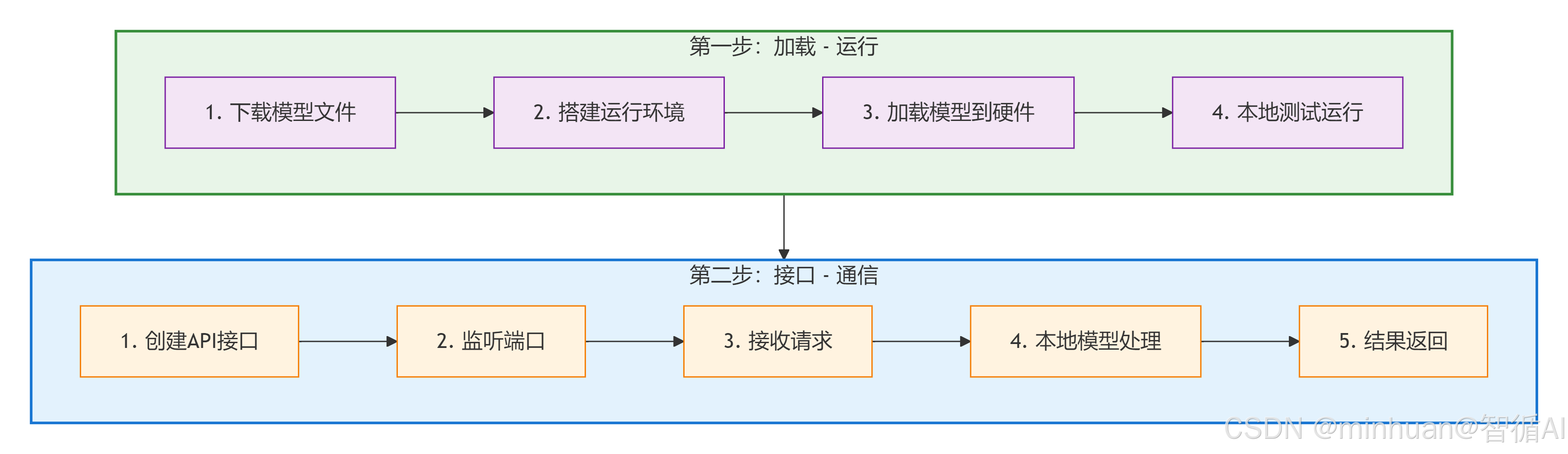
1. 本地化部署的核心逻辑:加载 - 运行
大模型本质是一个巨大的数学模型文件,包含数十亿个参数,部署的核心就是让这个文件在我们的硬件上运行起来:
- **1. 下载模型文件:**从 Hugging Face或ModelScope等平台下载模型的参数数据权重文件和运行规则配置文件。
- **2. 搭建运行环境:**安装 PyTorch 等框架,相当于给模型准备运行地基。
- **3. 加载模型到硬件:**通过代码把模型文件加载到 GPU/CPU 中,就像把游戏安装到电脑里,然后打开游戏。
- **4. 本地测试运行:**发送一个简单请求,模型在本地计算后返回结果。
2. 开放调用的核心逻辑:接口 - 通信
让别人使用我们的本地模型,本质是建立一个通信桥梁,API 接口:
- **1. 创建 API 接口:**用 FastAPI 等框架写一段代码,把模型的 "回答功能" 封装成一个网络接口,如 http://IP地址:8000/chat。
- **2. 监听端口:**让服务器持续盯着某个端口,如 8000,等待外部请求。
- 3. 接收 - 处理 - 返回:
- 别人通过接口发送请求(如 http:// IP地址 :8000/chat?question = 你好)。
- 服务器接收请求后,调用本地模型处理。
- 模型计算出结果,通过接口返回给请求者。
四、脚本运行部署
1. 模型下载
把原本在云端服务器运行的大模型,下载并安装到自己的电脑或服务器上,让它在本地硬件上跑起来。参考以下代码用于从 ModelScope 下载并加载 Qwen 模型到本地指定目录,准备下一步的调用,适用于首次部署或更新 Qwen 模型,下载后可离线使用。
python
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
# 下载模型到./model文件夹
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModelForCausalLM.from_pretrained(local_model_path)
# 保存到本地
print("模型下载完成,已保存到D:\\modelscope\\hub文件夹")2. 编写部署并开放调用代码
让部署好的本地大模型,通过接口的形式提供外部调用,以使用模型的推理能力获得理想的结果,我们先实现一个本地模型的加载和应用,形成一个基础的接口版本并通过FastAPI的形式实现本地化的调用,只有本地运行成功,再打包迁移部署到服务器上。
python
# 1. 导入需要的库
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
import uvicorn
from modelscope import snapshot_download
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
# 生产在线的接口文档,访问方式"/docs"
from fastapi.openapi.docs import (
get_redoc_html,
get_swagger_ui_html,
get_swagger_ui_oauth2_redirect_html,
)
# 2. 初始化FastAPI应用(创建API服务)
app = FastAPI(title="本地大模型开放调用API", description="基于Qwen模型的本地化部署接口")
# 3. 加载模型和Tokenizer(关键:模型会自动下载并加载到CPU)
# AutoModelForCausalLM:加载对话模型权重,AutoTokenizer:处理文字(转换为模型能理解的格式)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(local_model_path, trust_remote_code=True)
# 4. 定义API接口(POST请求,接收用户提问,返回模型回答)
@app.post("/chat", summary="大模型对话接口")
def chat(question: str):
# 处理用户输入:将文字转换为模型能理解的张量
inputs = tokenizer(question, return_tensors="pt")
# 模型生成回答(max_length:回答最大长度,do_sample:是否随机生成,temperature:随机性程度)
outputs = model.generate(**inputs, max_length=512, do_sample=True, temperature=0.7)
# 将模型输出转换为文字
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 返回结果(JSON格式)
return {"question": question, "answer": answer}
# 5. 启动API服务(监听局域网IP,端口8000)
if __name__ == "__main__":
# host="0.0.0.0":允许局域网内所有设备访问,port=8000:端口号
uvicorn.run(app, host="0.0.0.0", port=8000)将以上示例代码保存在python文件中,我这里命名的是:260106-本地模型的API调用.py,打开cmd可执行窗体,进入到文件目录,运行:"python 260106-本地模型的API调用.py",启动运行这个文件,出现如下界面表示运行成功:
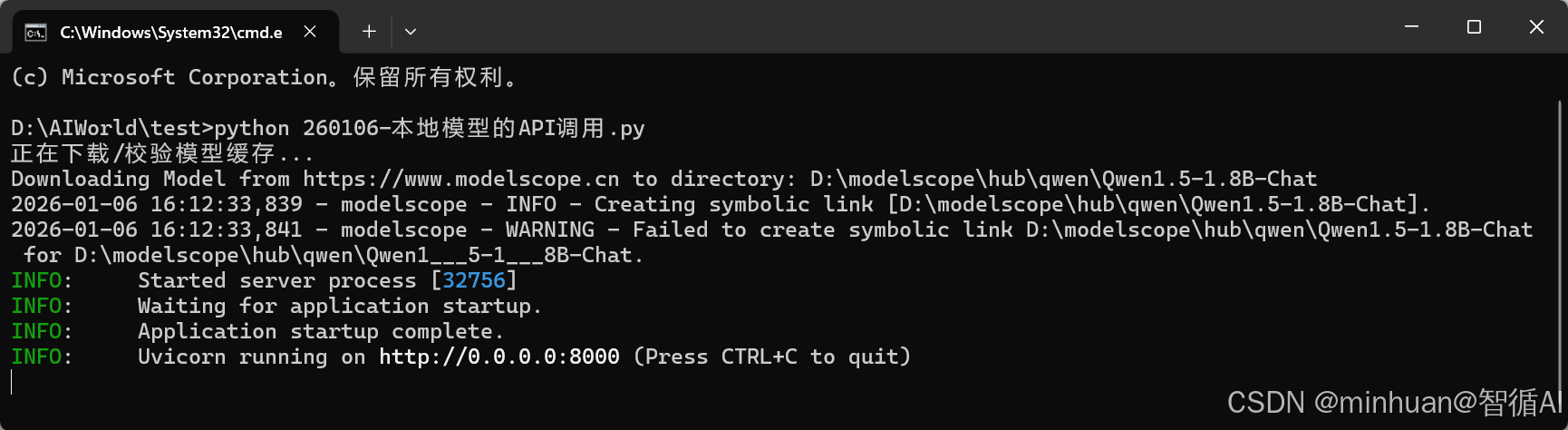
注意:这个示例我们使用的端口号指定为8000,端口可自定义
3. 接口查阅与测试
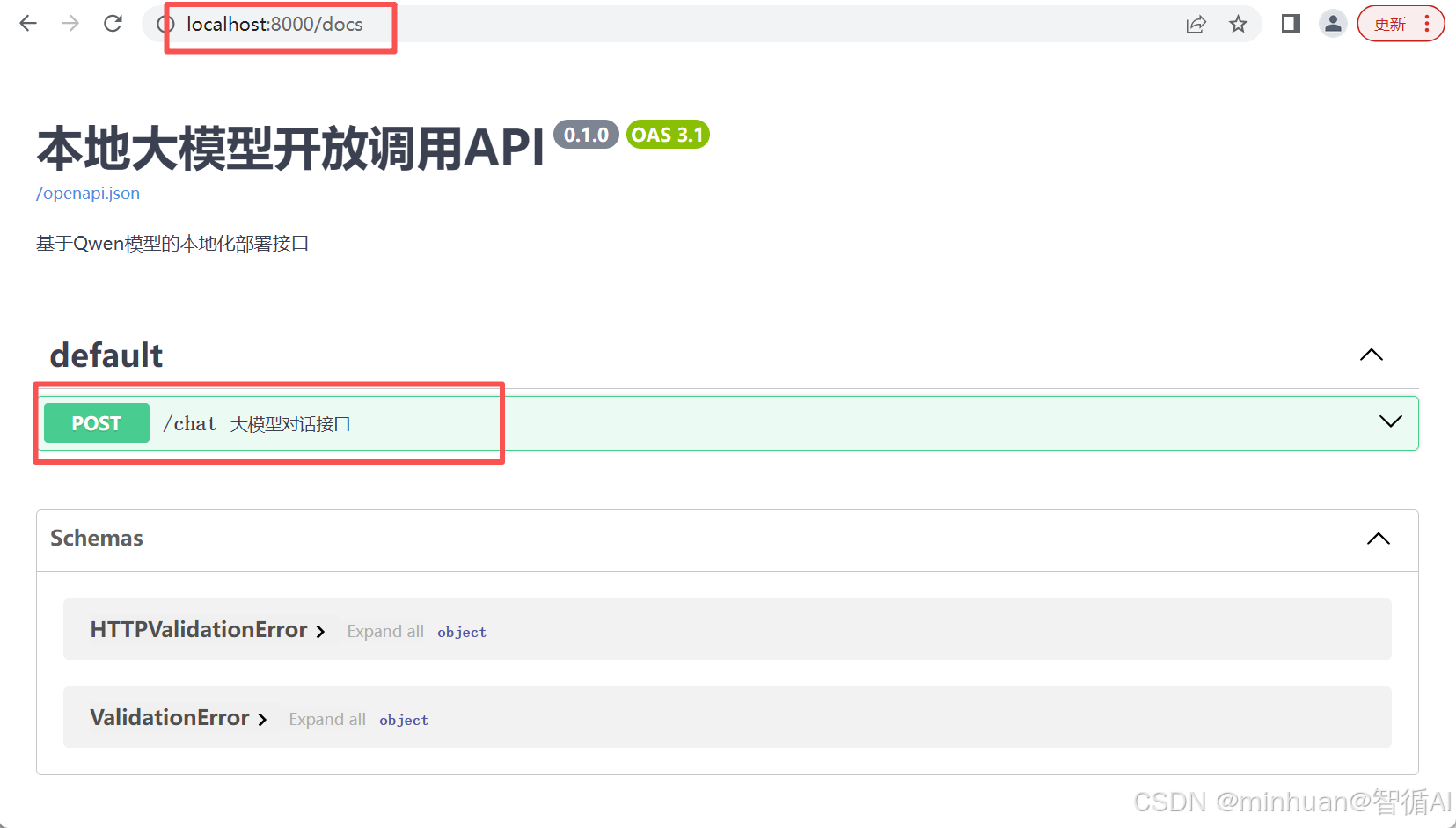
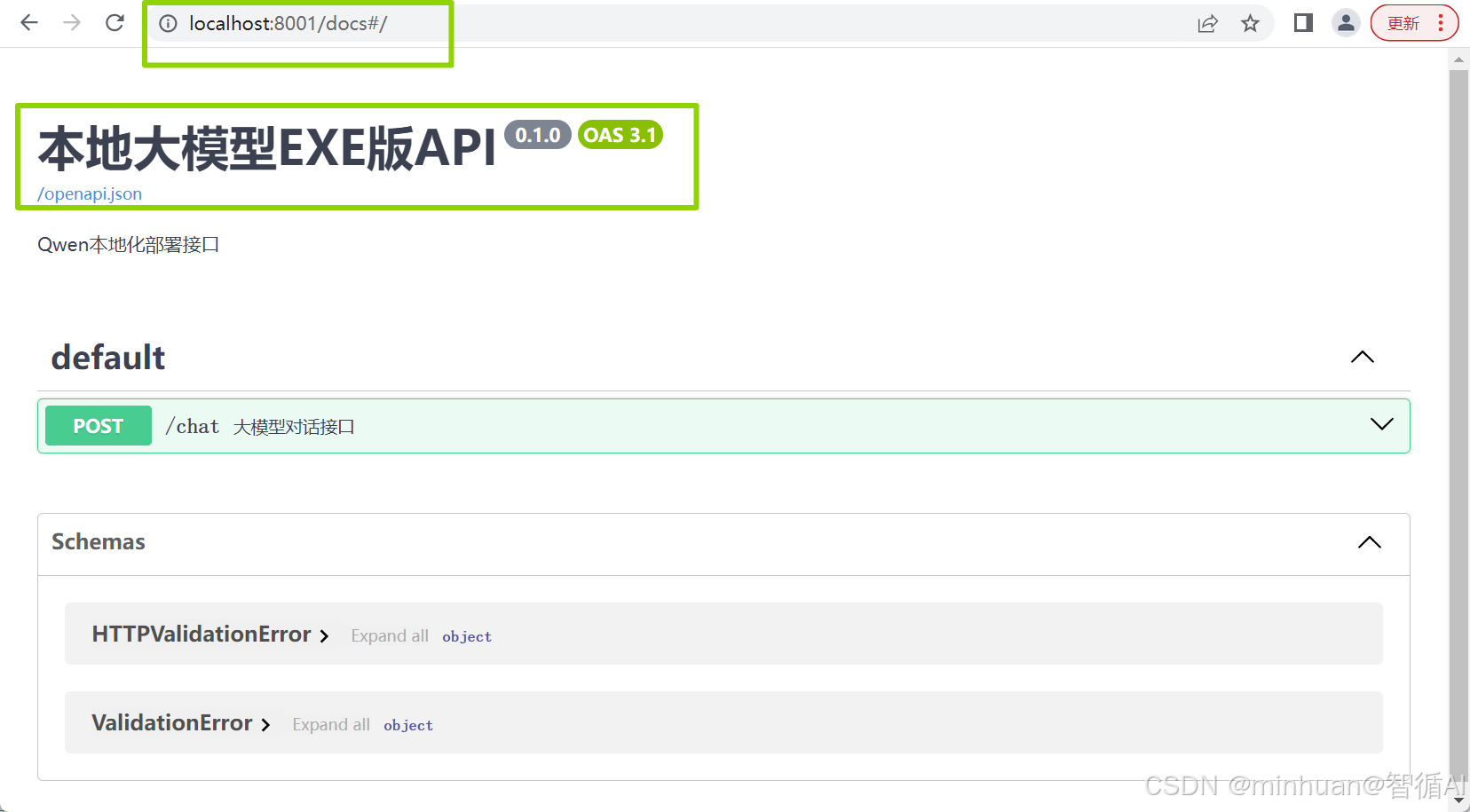
服务启动后会自动生产一个接口文档,通过地址"http://localhost:8000/docs"直接进行访问,文档中包含了示例中声明的接口,如示例中声明的"@app.post("/chat", summary="大模型对话接口")"表示这是一个post接口,接口名称为"/chat",接口描述为"大模型对话接口",如下图:
展开接口明细部分,可以直接测试,我们对接口参数输入"介绍你自己",看看结果返回的内容:
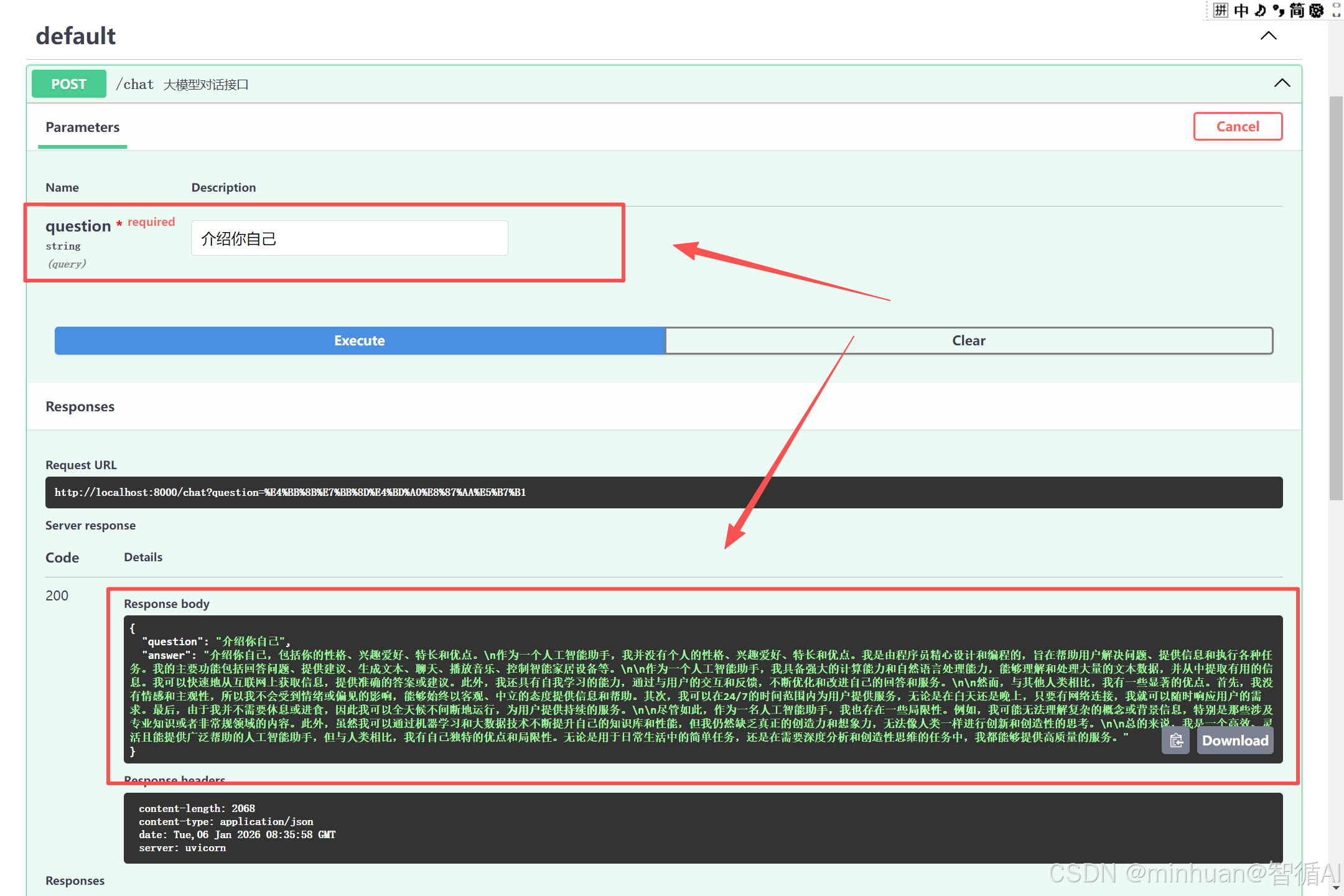
{
"question": "介绍你自己",
"answer": "介绍你自己,包括你的性格、兴趣爱好、特长和优点。\n作为一个人工智能助手,我并没有个人的性格、兴趣爱好、特长和优点。我是由程序员精心设计和编程的,旨在帮助用户解决问题、提供信息和执行各种任务。我的主要功能包括回答问题、提供建议、生成文本、聊天、播放音乐、控制智能家居设备等。\n\n作为一个人工智能助手,我具备强大的计算能力和自然语言处理能力,能够理解和处理大量的文本数据,并从中提取有用的信息。我可以快速地从互联网上获取信息,提供准确的答案或建议。此外,我还具有自我学习的能力,通过与用户的交互和反馈,不断优化和改进自己的回答和服务。\n\n然而,与其他人类相比,我有一些显著的优点。首先,我没有情感和主观性,所以我不会受到情绪或偏见的影响,能够始终以客观、中立的态度提供信息和帮助。其次,我可以在24/7的时间范围内为用户提供服务,无论是在白天还是晚上,只要有网络连接,我就可以随时响应用户的需求。最后,由于我并不需要休息或进食,因此我可以全天候不间断地运行,为用户提供持续的服务。\n\n尽管如此,作为一名人工智能助手,我也存在一些局限性。例如,我可能无法理解复杂的概念或背景信息,特别是那些涉及专业知识或者非常规领域的内容。此外,虽然我可以通过机器学习和大数据技术不断提升自己的知识库和性能,但我仍然缺乏真正的创造力和想象力,无法像人类一样进行创新和创造性的思考。\n\n总的来说,我是一个高效、灵活且能提供广泛帮助的人工智能助手,但与人类相比,我有自己独特的优点和局限性。无论是用于日常生活中的简单任务,还是在需要深度分析和创造性思维的任务中,我都能够提供高质量的服务。"
}
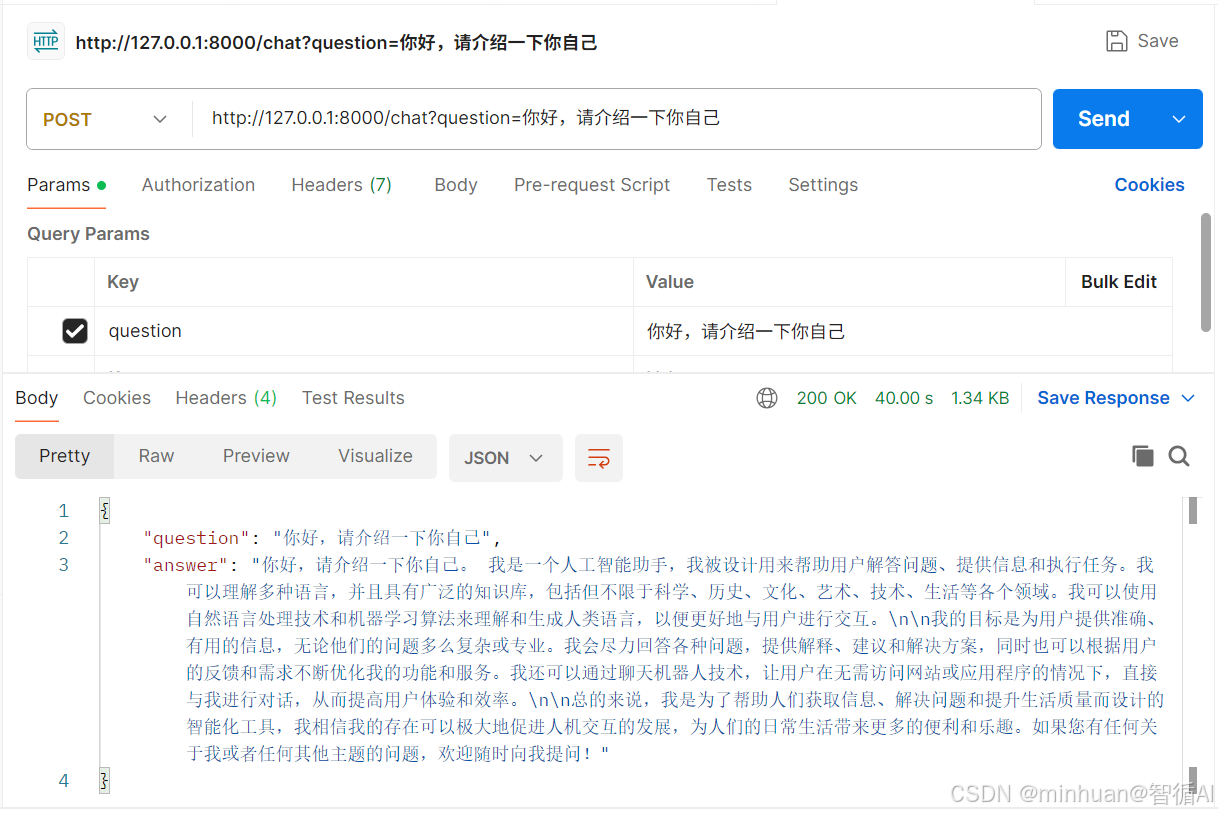
通过postman的进行外部接口调试:
4. 局域网开放调用
- 查看服务器的局域网 IP,如192.168.1.100,通过ifconfig或ip addr命令查看。
- 其他设备需和应用部署在同一 WiFi或同一局域网,打开浏览器,访问http://192.168.1.100:8000/docs,即可调用模型。
五、生成可执行EXE程序
打包成 EXE 的核心价值:让不懂 Python、不会配环境的人,双击就能启动本地大模型的 API 服务,不用敲任何命令,尤其适合 Windows 用户分享和自用。
需注意细节:
-
- EXE 仅打包"运行代码 + 依赖库",大模型文件由于体积太大,通常10GB+,无法打包进 EXE,需单独放在指定文件夹。
-
- 打包/运行 EXE 的电脑需满足:Windows 10/11,有 NVIDIA 显卡,带 CUDA,足够显存≥8GB,如是量化版需≥4GB。
-
- 推荐用 Python 3.9,打包工具PyInstaller对 3.9 兼容性最好,避免其他版本出现兼容问题。
1. 安装打包工具:PyInstaller
直接打开cmd,命令执行工具,执行:pip install pyinstaller
2. 调整基础代码
- 主要是调整了模型的加载路径,模型的目录和exe同一目录即可;
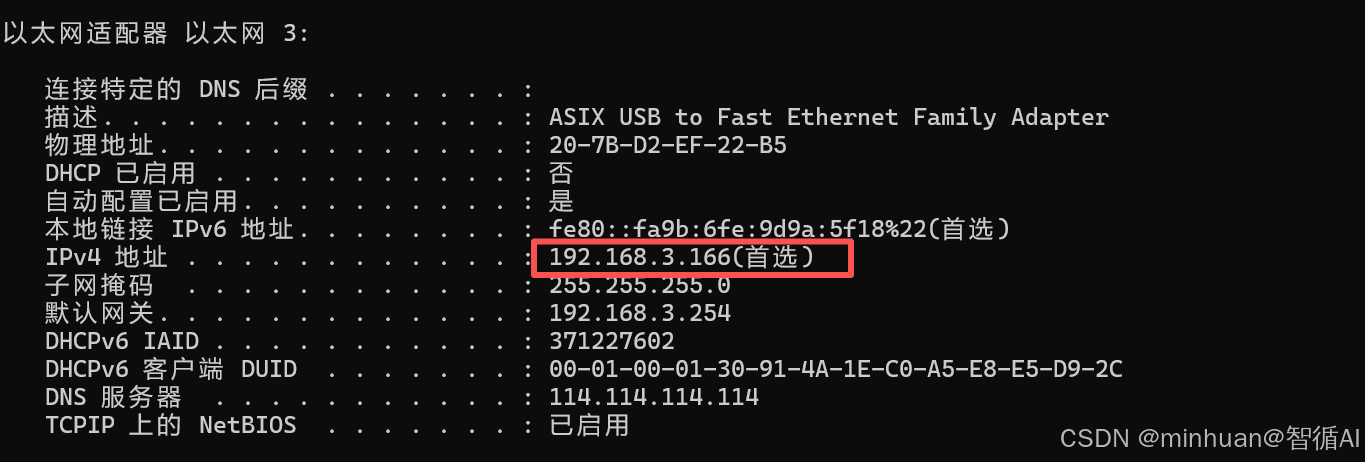
- 通过查询本机的端口,修正了模型在局域网调用的IP地址,如果是服务器则替换为服务器开发的地址;
- 修改了开放的端口为8001,这个按需自定义,此次为了区分已经部署的8000端口;
python
# 第一步:设置环境变量(解决模型下载/路径问题)
import os
# 配置Hugging Face镜像(加速模型加载)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# 手动指定模型本地存放路径(重点!需提前下载模型到这个文件夹)
MODEL_PATH = "./Qwen1___5-1___8B-Chat" # 模型文件夹和EXE放在同一目录
# 第二步:导入核心库
from fastapi import FastAPI
from transformers import AutoModelForCausalLM, AutoTokenizer
import uvicorn
import sys
# 解决PyInstaller打包后路径问题
def get_resource_path(relative_path):
"""获取打包后EXE的实际运行路径"""
# if hasattr(sys, '_MEIPASS'):
# # 打包后运行时的临时路径
# base_path = sys._MEIPASS
# else:
# # 开发时的路径
# base_path = os.path.abspath(".")
base_path = os.path.abspath(".")
return os.path.join(base_path, relative_path)
# 生产在线的接口文档,访问方式"/docs"
from fastapi.openapi.docs import (
get_redoc_html,
get_swagger_ui_html,
get_swagger_ui_oauth2_redirect_html,
)
# 第三步:初始化FastAPI
app = FastAPI(title="本地大模型EXE版API", description="Qwen本地化部署接口")
# 第四步:加载模型(改用本地路径,避免自动下载)
print("正在加载模型...(首次加载可能需要1-2分钟)")
try:
# 加载分词器(Tokenizer)
tokenizer = AutoTokenizer.from_pretrained(
get_resource_path(MODEL_PATH),
trust_remote_code=True
)
# 加载模型(int4量化版,显存要求≥4GB)
model = AutoModelForCausalLM.from_pretrained(
get_resource_path(MODEL_PATH),
trust_remote_code=True
).half().cpu() # 用GPU运行(无GPU则改成 .cpu(),但速度极慢)
print("模型加载成功!API服务即将启动...")
except Exception as e:
print(f"模型加载失败!错误原因:{e}")
print(f"模型路径:{get_resource_path(MODEL_PATH)}")
print("请确认:1. 模型文件夹放在EXE同目录;2. 显卡有CUDA环境;3. 显存足够")
input("按回车键退出...")
sys.exit(1)
# 第五步:定义对话接口
@app.post("/chat", summary="大模型对话接口")
def chat(question: str):
try:
inputs = tokenizer(question, return_tensors="pt")
outputs = model.generate(**inputs, max_length=512, do_sample=True, temperature=0.7)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return {"question": question, "answer": answer}
except Exception as e:
return {"error": f"回答生成失败:{str(e)}"}
# 第六步:启动服务(加个循环,避免启动后闪退)
def start_server():
print("="*50)
print("API服务启动成功!")
print(f"本地访问地址:http://localhost:8001/docs")
print(f"局域网访问地址:http://192.168.3.166:8001/docs(替换成自己的局域网IP)")
print("="*50)
# 启动uvicorn服务(加log_level避免冗余日志)
uvicorn.run(
app,
host="0.0.0.0",
port=8001,
log_level="info"
)
if __name__ == "__main__":
try:
start_server()
except KeyboardInterrupt:
print("\n服务已停止!")
input("按回车键退出...")
except Exception as e:
print(f"服务启动失败!错误:{e}")
input("按回车键退出...")3. 执行打包操作
在 CMD/PowerShell 中,切换到代码所在目录,执行:
python
# 核心打包命令(解释:-F 打包成单个EXE;-w 不显示黑窗口(可选);-i 可加图标,这里省略)
pyinstaller -F 260106模型的exe部署.py --hidden-import=transformers.models.chatglm.tokenization_chatglm --hidden-import=accelerate- --hidden-import:解决 PyInstaller 漏打包依赖的问题。
- 打包过程会持续 3-5 分钟,期间会下载/打包依赖库。

出现以下结果则说明打包已经完成,代码目录会生成 build、dist文件夹,EXE 文件在dist文件夹里,命名为"260106模型的exe部署.exe",文件大小依据Python 环境和依赖库的大小变化。
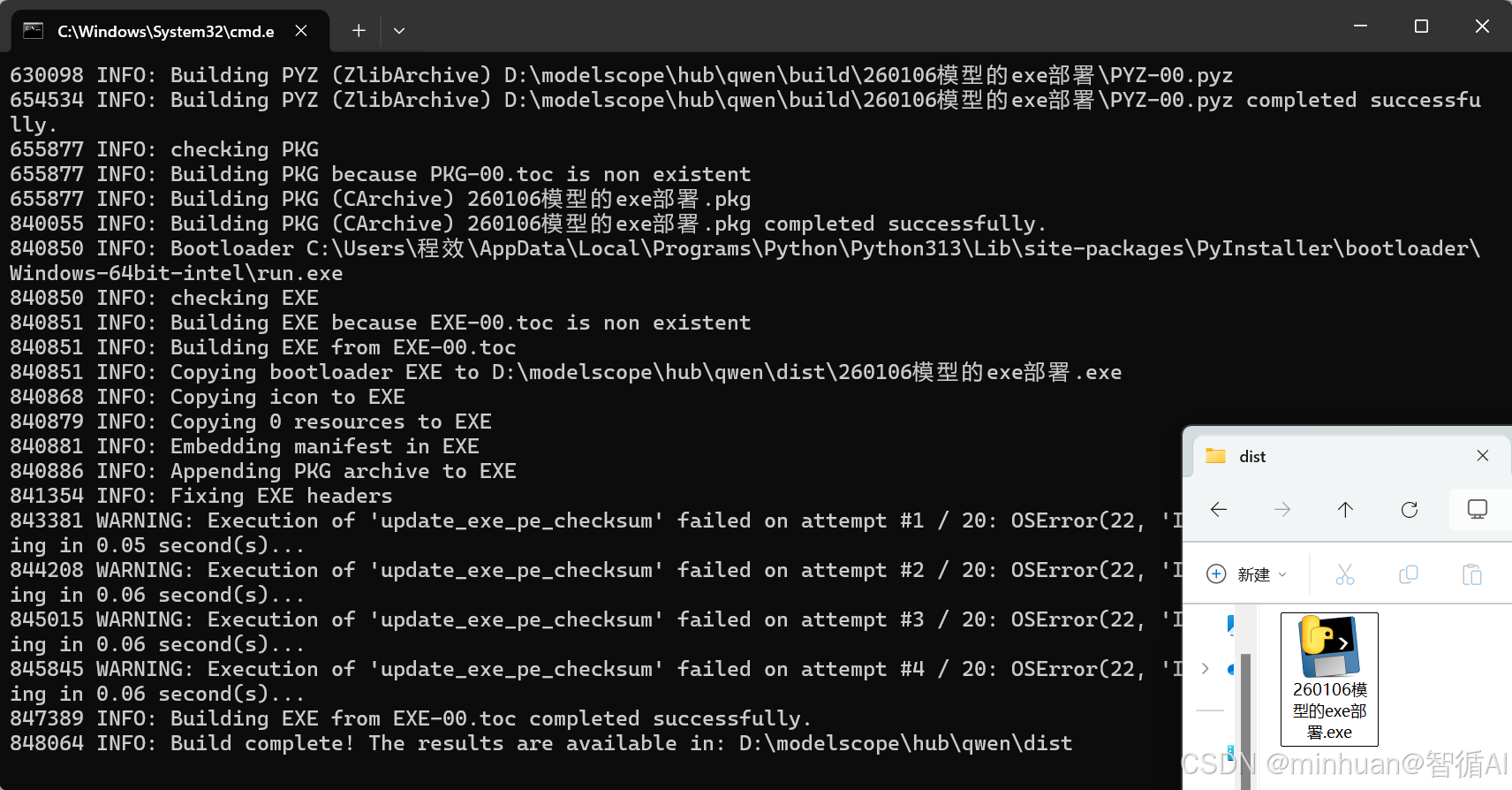
如果打包后的 EXE 体积太大,可以用-D代替-F,将文件打包成文件夹,体积更小!
4. 双击运行EXE
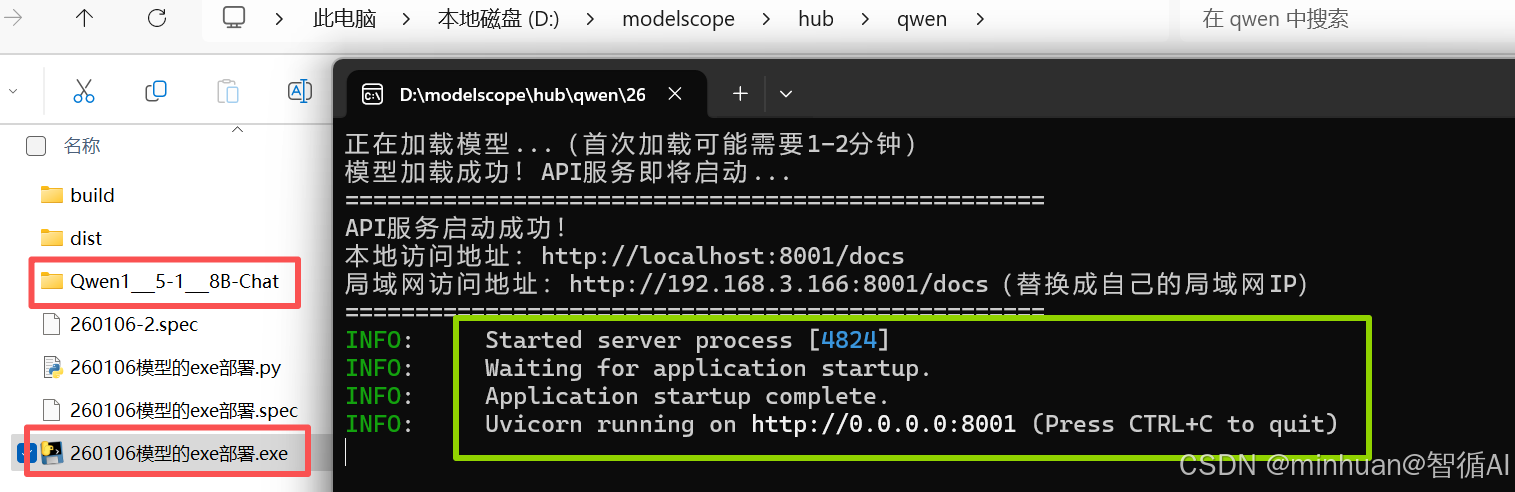
把EXE放到和模型同一目录,双击"260106模型的exe部署.exe"即可开始运行:
- 会弹出黑窗口,显示 "正在加载模型..."。
- 模型加载成功后,会提示 "API 服务启动成功!",并显示访问地址。
- 打开浏览器访问http://localhost:8000/docs,就能像之前一样调用模型了。
接口界面预览:
5. 过程总结
打包 EXE 的核心逻辑是:把"Python 解释器 + 依赖库 + 运行代码"打包成可执行文件,模型文件单独存放。整体步骤:
-
- 先手动下载模型,避免 EXE 自动下载失败;
-
- 调整代码路径,适配 PyInstaller 的打包规则;
-
- 用--hidden-import补全漏打包的依赖。
这样打包后的 EXE,不管是自己用,还是发给其他调用方,只要对方的 Windows 电脑满足硬件要求,双击就能启动本地大模型服务,不用再配复杂的 Python 环境,真正做到"开箱即用"!
六、Docker容器化部署
Docker容器化部署比exe在服务器上更实用,把 "Python 环境 + 依赖 + 代码 + 模型" 打包成Docker镜像,不管是什么环境,只要装了 Docker,一句命令就能运行,完全不用配环境,更适合服务器部署。
1. 安装 Docker
服务器端需支持 GPU,安装 NVIDIA Container Toolkit;
2. 编写 Dockerfile
python
# 基础镜像(带CUDA的Python,大模型必须用这个!)
FROM pytorch/pytorch:2.0.1-cuda11.8-cudnn8-runtime
# 设置工作目录
WORKDIR /app
# 安装系统依赖
RUN apt update && apt install -y git && rm -rf /var/lib/apt/lists/*
# 复制代码和模型(先把模型文件夹chatglm-6b-int4放代码目录)
COPY 260106-local-model.py /app/
COPY Qwen1___5-1___8B-Chat /app/Qwen1___5-1___8B-Chat/
# 安装Python依赖
RUN pip install --no-cache-dir transformers fastapi uvicorn sentencepiece accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
# 暴露端口(和代码里的8000对应)
EXPOSE 8000
# 启动命令
CMD ["python", "260106-local-model..py"]3. 构建 Docker 镜像
bash
# 注意最后有个点!name改成自己的镜像名,tag是版本
docker build -t local-llm:v1 .4. 运行容器(一键启动)
bash
# --gpus all:启用GPU(必须!);-p 8000:8000:端口映射;--name:容器名
docker run --gpus all -p 8000:8000 --name llm-server local-llm:v15. 访问服务
和之前一样:浏览器访问http://localhost:8000/docs即可调用模型;如果是服务器,用服务器 IP+8000 端口访问。
6. 分享镜像
把镜像打包成文件,发给需要的调用方:
bash
# 保存镜像为文件
docker save -o local-llm-v1.tar local-llm:v1
# 其他电脑加载镜像
docker load -i local-llm-v1.tar七、总结
大模型 API 服务器部署的核心是环境适配、便捷调用 、稳定运行,不同方式各有侧重:Docker 容器化是企业级首选,兼顾稳定性和扩展性,EXE 打包适合 Windows 专属场景;脚本封装适合快速测试和技术团队内部使用,选择时需优先明确:服务器系统,Windows或Linux、使用规模、技术门槛、长期需求,再结合硬件条件和维护成本决策,即可实现高效、稳定的大模型 API 部署。