前言
在构建检索增强生成(Retrieval-Augmented Generation, RAG)系统时,文本分词和预处理是影响系统性能的关键环节之一。特别是在中文环境中,由于中文语言的特殊性(词语之间没有明显的分隔符),分词质量直接影响到后续的检索准确性和生成质量。
本文档旨在介绍一种基于 jieba 分词库的通用中文文本分词和预处理方案,专门针对 RAG 系统的应用场景进行了优化,确保能够高效、准确地对各种类型的中文文本进行分词处理,并将其应用于 RAG 系统中的向量检索等关键步骤。
通过此文档的阅读,你将收获
- 掌握一套完整的基于 jieba 的中文文本分词和预处理流程
- 理解如何结合词性标注提高分词准确性
- 学会设计适用于 RAG 系统的文本去噪方法
- 了解倒装句识别和处理技术
- 熟悉将分词结果转换为向量表示的方法
- 能够根据实际需求调整分词策略和参数配置
适用范围
本方案主要适用于以下场景:
- 中文 RAG 系统的文本预处理阶段
- 需要高质量中文分词的自然语言处理任务
- 对文本语义理解有较高要求的应用场景
- 需要结合词性信息进行文本分析的任务
- 面向业务文本(如操作手册、流程描述等)的处理场景
具体方案
1. 文本标准化
在进行分词之前,首先需要对原始文本进行标准化处理,包括:
-
去除特殊字符(空格、标点符号、emoji 等)
-
统一大小写(对于包含英文的部分)
-
修正常见的中文错别字
def normalize(self, text: str, options: Optional[Dict[str, Any]] = None) -> str:
"""
标准化文本
"""
# 合并默认选项和用户提供的选项
config = self.default_options.copy()
if options:
config.update(options)result = text # 1. 去除特殊字符 if config["remove_special_chars"]: result = self._remove_special_characters(result) # 2. 统一大小写 if config["to_lower_case"]: result = result.lower() # 3. 修正错别字 if config["fix_typos"]: result = self._fix_typographical_errors(result) return result
去噪处理
为了提高分词质量,我们需要对文本进行去噪处理,主要包括:
-
停用词过滤:去除对语义贡献较小的虚词
-
词性过滤:去除助词、叹词、拟声词等干扰项
-
长度过滤:过滤掉过短的无效词汇
-
重复词去重:消除连续重复的词汇
def _apply_denoising_rules(self, atomic_words: List[AtomicWord], config: Dict[str, Any]) -> List[AtomicWord]:
"""
应用去噪规则
"""
if not atomic_words:
return []result = atomic_words.copy() # 1. 停用词过滤 result = self._filter_stopwords(result, config["stopwords"], config["core_word_whitelist"]) # 2. 词性过滤 result = self._filter_by_pos_type(result, config["filter_pos_types"], config["core_word_whitelist"]) # 3. 长度过滤 result = self._filter_by_length(result, config["min_word_length"], config["core_word_whitelist"]) # 4. 重复词汇去重 result = self._remove_duplicate_words(result) return result
3. 基于 jieba 的分词与词性标注
我们采用 jieba 分词库进行分词和词性标注,并将 jieba 的词性标签映射为我们自定义的标准词性类型:
def tag(self, text: str) -> List[AtomicWord]:
"""
对文本进行词性标注
"""
if not isinstance(text, str) or not text:
return []
# 使用jieba.posseg进行词性标注
tagged_words = pseg.cut(text)
result = []
for index, (word, pos) in enumerate(tagged_words, start=1):
# 将jieba词性映射为标准词性
standard_pos = self._pos_map.get(pos, PosType.NOUN)
atomic_word = AtomicWord(
word=word,
pos=standard_pos,
index=index
)
result.append(atomic_word)
return resultjieba 提供了丰富的词性标注,我们将它们归类为以下标准类型:
- 动词(VERB)
- 名词(NOUN)
- 形容词(ADJECTIVE)
- 时间词(TIME_WORD)
- 副词(ADVERB)
- 以及其他辅助词性
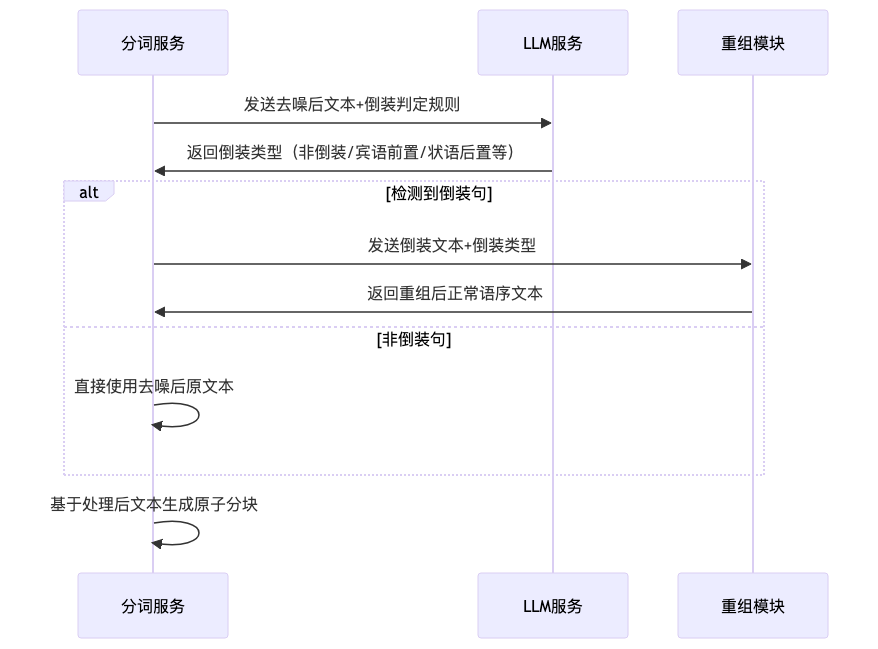
4. 倒装句识别与处理
在某些业务场景中,文本可能存在倒装句现象,会影响语义理解和检索效果。我们采用 LLM 辅助的方式识别和重组倒装句:
def _detect_inversion_type(self, clean_text: str) -> str:
"""
识别倒装类型
"""
prompt = f"""你是通用文本语序分析助手,仅基于以下规则识别文本是否为倒装句(宾语前置/状语后置/定语后置/语义倒装):
1. 仅分析去噪后的纯净业务文本,无需考虑业务场景;
2. 倒装句判定仅基于语序逻辑,不考虑词汇语义;
3. 若非倒装句,回复"非倒装";若是倒装句,回复具体倒装类型(如"宾语前置")。
待分析文本:{clean_text}
请输出判定结果(仅文字,无额外说明):"""
result = self.llm_service.generate(prompt)
return result.strip()5. 原子分块生成
将处理后的文本分解为原子分块单元,每个单元包含词汇、词性等信息,并可以生成对应的向量表示:
async def _generate_atomic_chunks(self, processed_text: str, is_inverted: bool, config: ChunkingConfig) -> List[AtomicChunk]:
"""
生成原子分块单元
"""
if not processed_text:
return []
# 1. 原子分词与词性标注
atomic_words = word_segment_service.process(processed_text)
# 2. 过滤残留噪声(二次校验)
filtered_words = self._filter_residual_noise(atomic_words)
# 3. 生成原子分块单元
atomic_chunks = []
for index, word in enumerate(filtered_words, start=1):
chunk = AtomicChunk(
id=self._generate_chunk_id(word.pos, index),
word=word.word,
pos=word.pos,
pos_idx=index,
is_inverted=is_inverted,
chunk_type="baseType"
)
# 4. 如果启用向量化,使用embedding服务生成向量
if config["enable_vectorization"]:
chunk.vector = embedding_service.generate_embedding(word.word)
atomic_chunks.append(chunk)
return atomic_chunks流程总览
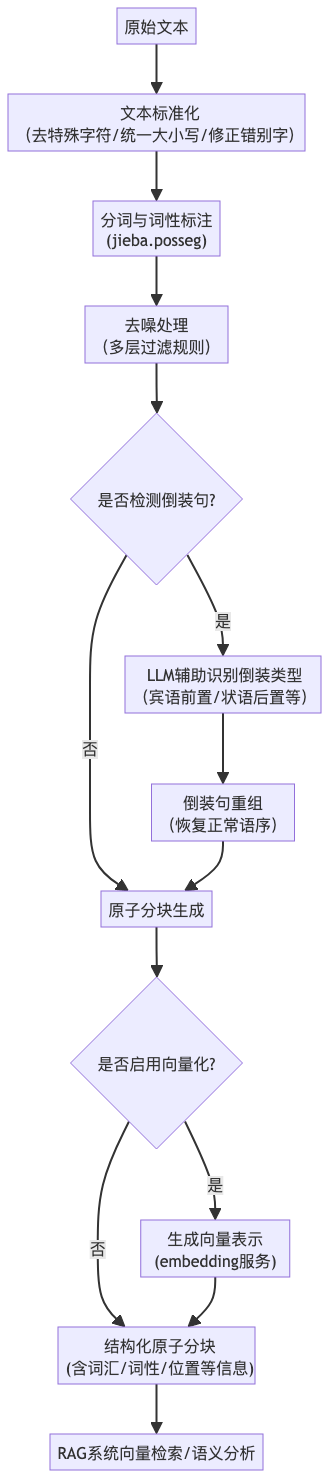
词性映射关系

去噪处理规则

倒装句处理流程
成果展示
通过上述方案处理后的文本具备以下特点:
- 高质量分词:利用 jieba 分词库和词性标注,确保分词准确性
- 有效去噪:过滤掉停用词、无意义词性词汇等噪声,保留核心语义单元
- 倒装处理:识别并重组倒装句,使语序更加规范
- 结构化表示:将文本转化为结构化的原子分块单元,便于后续处理
- 向量表示:可选地为每个分块单元生成向量表示,支持向量检索
示例输入:
当用户在页面上点击"提交"按钮时,系统将验证表单字段的有效性,并在发现错误时显示相应的错误消息。处理后得到的原子分块(部分展示):
- 用户 (n) - 名词
- 点击 (v) - 动词
- 提交 (v) - 动词
- 按钮 (n) - 名词
- 系统 (n) - 名词
- 验证 (v) - 动词
- 表单 (n) - 名词
- 字段 (n) - 名词
- 有效性 (a) - 形容词
总结
本文介绍了一套完整的基于 jieba 的 RAG 系统中文分词解决方案,具有以下优势:
- 全面性:涵盖了从文本标准化到原子分块生成的完整流程
- 灵活性:各个处理模块都可以独立配置和替换
- 准确性:结合词性标注和多层去噪策略,提高了分词准确性
- 实用性:特别针对 RAG 系统的需求进行了优化,可直接应用于生产环境
- 可扩展性:模块化设计使得系统易于扩展新的功能
这套方案已经在 RAG 项目中得到了验证,显著提升了检索准确性和生成质量。未来还可以进一步结合领域词典、自定义词性标注等方式进行优化,以适应更多特定领域的应用场景。