inline介绍
用inline修饰的函数叫做内联函数,编译时C++编译器会在调用的地方展开内联函数,这样调用内联函数就**++不需要建立栈帧++**了,就可以提高效率了
inline对于++编译器++ 来说只是一个建议而已,短小的函数才展开,长一点的基本不用,对于一些又长又臭的函数,比如递归等,就算你加了inline,编译器也会直接忽略不干
作用:inline经常替代宏定义函数(宏可定义常量和函数)
宏函数定义注意事项
既然讲到了宏函数,那么宏函数会有什么缺点,才会用inline来代替?如何正确定义宏函数呢?
举例**#define ADD(a,b) ((a)+(b))**
1,为什么没有分号?
如果我的宏定义变为**#define ADD(a,b) ((a)+(b))****;(有分号)**
我们需要理解的是宏定义的本身说明白一点就是替换,假如加了分号,那么会出现一些什么样的情况呢
cpp
int ret = ADD(1, 2); //int ret = ((1)+(2));;我们就会知道,一个语句里他会出现两个分号,但在一些场景下并不会造成什么错误
我们来看看会出现致命性错误的情况

很容易知道,当我们编写 cout << ADD(1, 2) << endl; 这句语句的时候,在编译的时候,他就会变成 cout <<((a)+(b)); << endl;
准确来说是
cpp
cout << ((1)+(2));
<< endl;所以就会出现错误
所以在一般宏定义函数中需要特别注意分号的使用
2,为什么要加外面的括号?
如果我的宏定义变为**#define ADD(a,b) (a)+(b)**
cpp
cout << ADD(1, 2) << endl;
cout << ADD(1, 2) * 2 << endl;在上述两行代码里,我们分别希望得到的结果是3和6,但看看结果究竟是不是3和6

第二句语句结果没有和我们的常规想法一致,那么问题出在哪里
问题就处在了符号优先级上了,还是一样的再替换后,得到的场景变跟我们平常的所认为的场景有出入
当我们编写 cout << ADD(1, 2) << endl; 这句语句的时候,在编译的时候,他就会变成 cout <<(1)+(2) << endl; 答案正常没有啥问题
但当我们编写 cout << ADD(1, 2) * 2 << endl; 这句语句的时候,在编译的时候,他就会变成 cout << (1) + (2) * 2 << endl; 显而易见,会先做乘法变成4,再接着做加法,最后变成5
3,为什么要加里面的括号?
如果我的宏定义变为**#define ADD(a,b) (a+b)**
cpp
int x = 1, y = 2;
cout << ADD(x & y, x | y) << endl;- 替换阶段:ADD(x & y, x | y) 被直接替换为
(x & y + x | y); - 运算优先级阶段:C++ 中
+优先级(13 级)远高于&和|(分别为 8、7 级 ),因此先算y + x:y + x = 2 + 1 = 3; - 再按优先级算
&(按位与):x & 3→1 & 3(二进制01 & 11)=01(十进制1);
- 最后算
|(按位或):1 | y→1 | 2(二进制01 | 10)=11(十进制3);
- 最终
cout输出3。
但我们想要的是((x & y)+(x | y)) 运算步骤,所以才需要在里面添加括号
虽然最后结果是一样的,但换成其他数据,或者其他顺算符来说的话,就会变得很难受
宏函数存在的原因
那么宏既然有这么多缺点,为什么还要有宏,最大的优点就是直接替换
经过替换后就无需构建栈帧,达到提高效率,因为普通调用函数的话是需要开销建立栈帧的
inline引入说明
所以为了解决宏的一些缺点,就创建了inline,inline既没有宏函数的坑,也不用建立栈帧,同时宏是无法调试的,inline可以调试
vs编译器在debug版本下面默认是不展开inline的,这样方便调试,如果需要展开内联
举例说明
++假设有个函数有100行,在函数中有10000个调用++
++当inline展开的时候,占100*10000个指令++
++当inline不展开的时候,占10000*1+100++
所以内联展开可能会导致可执行程序变大,这就是为什么inline只是一个建议
其次,inline不建议声明和定义分离到两个文件,分离会导致链接错误,直接放到头文件即可
nullptr引用
cpp
void f(int x) {
cout << "f(int x)" << endl;
}
void f(int* ptr) {
cout << "f(int* ptr)" << endl;
}
int main() {
f(0);
f(NULL);
return 0;
}其中两个f函数构成重载,按道理来说第一次调用应该调用f(int x),第二个应该调用f(int* ptr)
结果是不是这样
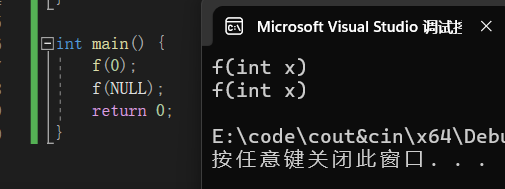
结果两次都只调用了第一个
原理是传统的C头文件(stddef.h)关于null的宏定义里面
cpp
/* NULL 宏的核心定义(分两种主流写法,本质等价) */
#ifdef __cplusplus
/* C++环境:NULL 通常定义为 0(C++不允许直接用(void*)0作为空指针常量) */
#define NULL 0
#else
/* C环境:优先定义为(void*)0(空指针常量的标准形式),兼容老编译器也会用0 */
#define NULL ((void *)0)
#endif两次调用都走f(int x)的核心原因:
f(0):0 是 int 字面量,完全匹配 int 参数;f(NULL):NULL 被替换成 0(int 常量),依然完全匹配 int 参数,而匹配 int * 需要额外的隐式转换,优先级更低;- C++ 里
NULL不是指针类型,只是 "值为 0 的整数",这是和 C 的关键区别(C 中NULL是(void*)0,但 C 没有重载,所以不会有这个问题)。
而在C++中引入了nullptr,nullptr是一个特殊的关键字,是一种特殊类型的字面量,它可以转换为任意其它类型的指针类型,使用nullptr定义空指针可以避免类型转换的问题,因为nullptr只能被隐式地转换为指针类型,而不能被转换为整数类型
NULL看着是 "空指针",但本质是数字 0,所以调用f(NULL)和调用f(0)是一回事 ,只有nullptr才是真正的 "空指针",能匹配第二个函数。

以上就是本博文的学习内容,如果有不正确的地方,还望各位大佬指点出来,谢谢阅读!