数据分析项目:Pandas + SQLAlchemy,从数据库到DataFrame的丝滑实战
文章目录
-
- [数据分析项目:Pandas + SQLAlchemy,从数据库到DataFrame的丝滑实战](#数据分析项目:Pandas + SQLAlchemy,从数据库到DataFrame的丝滑实战)
-
- 引言:为什么你的数据分析流程不够"丝滑"?
- 第一章:环境准备与核心概念理解
-
- [1.1 安装必要的库](#1.1 安装必要的库)
- [1.2 SQLAlchemy Core vs ORM:我们该用哪个?](#1.2 SQLAlchemy Core vs ORM:我们该用哪个?)
- [1.3 理解SQLAlchemy的引擎和连接](#1.3 理解SQLAlchemy的引擎和连接)
- [第二章:实战开始:从MySQL到Pandas DataFrame](#第二章:实战开始:从MySQL到Pandas DataFrame)
-
- [2.1 基础查询:最简单的数据获取](#2.1 基础查询:最简单的数据获取)
- [2.2 动态查询构建:应对灵活的分析需求](#2.2 动态查询构建:应对灵活的分析需求)
- 第三章:高级技巧:分页、大数据量与性能优化
-
- [3.1 高效分页查询](#3.1 高效分页查询)
- [3.2 大数据量处理:使用chunksize](#3.2 大数据量处理:使用chunksize)
- 第四章:完整实战:电商数据分析案例
-
- [4.1 案例背景](#4.1 案例背景)
- [4.2 完整代码实现](#4.2 完整代码实现)
- 第五章:性能优化与最佳实践
-
- [5.1 查询性能优化](#5.1 查询性能优化)
- [5.2 实际优化示例](#5.2 实际优化示例)
- [5.3 连接池最佳配置](#5.3 连接池最佳配置)
- 第六章:常见问题与解决方案
-
- [6.1 连接相关问题](#6.1 连接相关问题)
- [6.2 数据类型处理问题](#6.2 数据类型处理问题)
- 学习总结与进阶方向
- 学习交流与互动
刚开始用Python做数据分析时,你是不是也这样:先用pymysql把数据从MySQL里查出来,得到一个元组列表,然后再手动转成Pandas的DataFrame?每次都要写一堆转换代码,遇到复杂查询和分页更是头疼。直到我发现了SQLAlchemy + Pandas这对黄金搭档,才发现原来数据库查询可以这么优雅高效。
引言:为什么你的数据分析流程不够"丝滑"?
很多Python数据分析师或后端开发者都经历过这样的场景:接到一个分析需求,需要从MySQL数据库里拉取最近三个月的订单数据。于是你打开Jupyter Notebook,开始写代码:
python
import pymysql
import pandas as pd
# 第一步:建立连接
conn = pymysql.connect(
host='localhost',
user='root',
password='your_password',
database='sales_db',
charset='utf8mb4'
)
# 第二步:写SQL查询
sql = """
SELECT order_id, user_id, amount, order_date, status
FROM orders
WHERE order_date >= '2024-01-01'
"""
# 第三步:执行查询并转换
try:
with conn.cursor() as cursor:
cursor.execute(sql)
results = cursor.fetchall() # 得到的是元组列表
# 第四步:手动转成DataFrame
df = pd.DataFrame(results, columns=['order_id', 'user_id', 'amount', 'order_date', 'status'])
finally:
conn.close()
# 第五步:开始数据分析...
print(df.head())看起来没什么问题,对吧?但实际项目中,你会遇到:
- SQL注入风险:字符串拼接查询条件时容易出错
- 连接管理麻烦:每次都要手动开/关连接,忘记关闭会导致连接泄露
- 类型转换痛苦 :数据库的
DATETIME到Python的datetime需要手动处理 - 复杂查询难写:多表关联、子查询、窗口函数等写起来很繁琐
- 分页查询重复 :每次分页都要写
LIMIT offset, count
今天我要分享的SQLAlchemy + Pandas方案,能让你用更Pythonic的方式解决所有这些问题。 学完这篇教程,你将掌握:
- 如何用SQLAlchemy Core(不是ORM)高效查询数据库
- 如何直接将查询结果转为Pandas DataFrame
- 如何安全地构建动态查询条件
- 如何优雅地处理分页和大数据量查询
- 如何将分析结果写回数据库
准备好了吗?让我们开始吧!
第一章:环境准备与核心概念理解
1.1 安装必要的库
首先,确保你安装了以下Python库:
bash
# 基础数据库操作
pip install sqlalchemy pandas pymysql
# 可选:数据分析常用库
pip install numpy matplotlib为什么选择SQLAlchemy而不是纯pymysql?
让我用一个表格对比一下:
| 特性 | pymysql(纯驱动) | SQLAlchemy Core | 适用场景 |
|---|---|---|---|
| 学习曲线 | 简单直接 | 中等,需要理解表达式语言 | 新手从pymysql开始 |
| SQL构建 | 手动字符串拼接 | 表达式构建,类型安全 | 复杂查询选SQLAlchemy |
| 防SQL注入 | 需要手动使用参数化 | 自动防注入 | 安全性要求高选SQLAlchemy |
| 连接管理 | 手动管理 | 连接池自动管理 | 生产环境选SQLAlchemy |
| 类型系统 | 基础类型映射 | 丰富的类型系统 | 需要精确类型控制时 |
| 与Pandas集成 | 需要手动转换 | pd.read_sql()直接支持 |
数据分析项目首选 |
1.2 SQLAlchemy Core vs ORM:我们该用哪个?
很多初学者会混淆SQLAlchemy的两个主要组件:
- SQLAlchemy Core:数据库工具包,提供SQL表达式语言
- SQLAlchemy ORM:对象关系映射器,用于Python对象与数据库表的映射
对于数据分析项目,我强烈推荐使用SQLAlchemy Core,原因如下:
- 更接近SQL:数据分析师通常更熟悉SQL语法
- 性能更好:避免了ORM的对象加载开销
- 更灵活:可以执行任意复杂的SQL查询
- 学习成本低:不需要定义模型类
python
# SQLAlchemy Core 示例:像写SQL一样写查询
from sqlalchemy import create_engine, text
# 创建引擎(连接池已内置!)
engine = create_engine('mysql+pymysql://user:password@localhost/sales_db')
# 使用text()执行原生SQL
with engine.connect() as conn:
result = conn.execute(text("SELECT * FROM orders LIMIT 5"))
for row in result:
print(row)1.3 理解SQLAlchemy的引擎和连接
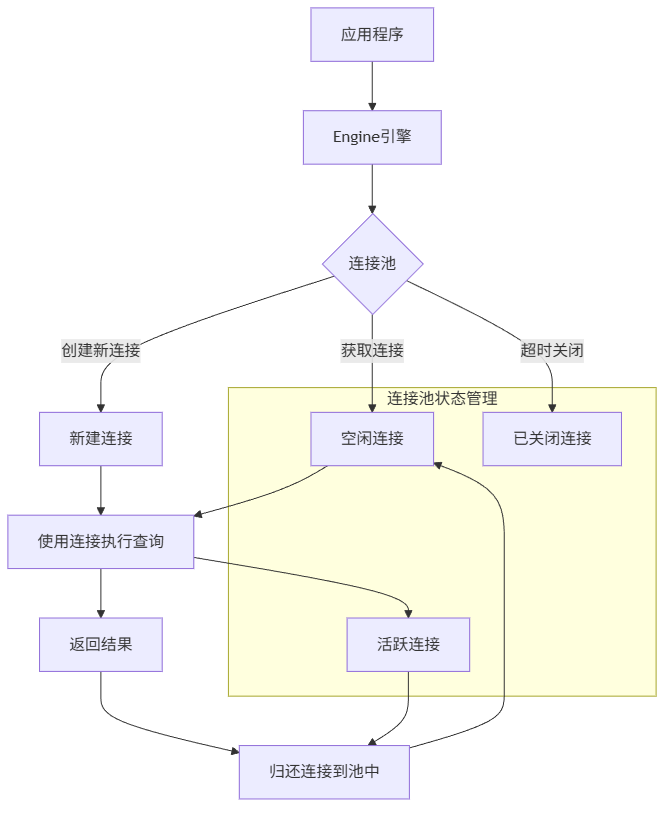
连接池就像共享单车:
- Engine:是共享单车公司,管理所有单车(连接)
- 连接池:是单车停放点,有可用单车就给你用
- 连接:就是单车本身,用完了要还回去(关闭)
关键配置参数(生产环境很重要!):
python
from sqlalchemy import create_engine
engine = create_engine(
# 连接字符串
'mysql+pymysql://user:password@localhost:3306/db_name',
# 连接池配置
pool_size=10, # 连接池中保持的连接数
max_overflow=20, # 超过pool_size最多可创建的连接数
pool_timeout=30, # 获取连接的超时时间(秒)
pool_recycle=3600, # 连接回收时间(秒),避免MySQL 8小时断开问题
# 编码设置
encoding='utf8mb4',
# 其他参数
echo=False, # 设为True可查看执行的SQL(调试用)
future=True # 使用2.0风格的API
)第二章:实战开始:从MySQL到Pandas DataFrame
2.1 基础查询:最简单的数据获取
让我们从一个真实的电商数据分析场景开始。假设我们有这样几张表:
sql
-- 用户表
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
is_vip BOOLEAN DEFAULT FALSE
);
-- 订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT NOT NULL,
amount DECIMAL(10, 2) NOT NULL,
order_date DATE NOT NULL,
status ENUM('pending', 'paid', 'shipped', 'delivered', 'cancelled'),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- 订单详情表
CREATE TABLE order_items (
item_id INT PRIMARY KEY AUTO_INCREMENT,
order_id INT NOT NULL,
product_name VARCHAR(200) NOT NULL,
quantity INT NOT NULL,
price DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);现在,我们要获取2024年1月的所有订单数据:
python
import pandas as pd
from sqlalchemy import create_engine, text
from datetime import datetime
# 1. 创建引擎(一次创建,多次使用)
engine = create_engine('mysql+pymysql://root:password@localhost/sales_db')
# 2. 定义查询
query = text("""
SELECT
o.order_id,
u.username,
o.amount,
o.order_date,
o.status
FROM orders o
JOIN users u ON o.user_id = u.user_id
WHERE o.order_date BETWEEN :start_date AND :end_date
ORDER BY o.order_date DESC
""")
# 3. 设置查询参数
params = {
'start_date': '2024-01-01',
'end_date': '2024-01-31'
}
# 4. 直接读取到DataFrame(最简洁的方式!)
df_orders = pd.read_sql(
query,
engine,
params=params, # 安全地传递参数,防止SQL注入
parse_dates=['order_date'] # 自动解析日期字段
)
print(f"获取到 {len(df_orders)} 条订单记录")
print(df_orders.head())
print(df_orders.dtypes) # 查看数据类型,order_date已经是datetime64了!看到了吗?只需要4步,而且:
- 自动处理了连接(打开和关闭)
- 自动类型转换(字符串转datetime)
- 参数化查询(防SQL注入)
- 直接得到DataFrame(无需手动转换)
2.2 动态查询构建:应对灵活的分析需求
实际项目中,分析需求经常变化。今天要按日期筛选,明天要按状态筛选,后天要同时按多个条件筛选。
传统方式的痛点:
python
# ❌ 不推荐:字符串拼接(有SQL注入风险!)
def get_orders_unsafe(start_date=None, status=None):
sql = "SELECT * FROM orders WHERE 1=1"
if start_date:
sql += f" AND order_date >= '{start_date}'" # 危险!
if status:
sql += f" AND status = '{status}'" # 非常危险!
# ...SQLAlchemy的安全做法:
python
from sqlalchemy import create_engine, text, bindparam
from sqlalchemy.sql import select, and_
# 方法1:使用text()和bindparam(适合复杂SQL)
def get_orders_safe(start_date=None, end_date=None, status=None, min_amount=None):
# 基础查询
sql = """
SELECT * FROM orders
WHERE 1=1
"""
# 动态添加条件
conditions = []
params = {}
if start_date:
conditions.append("order_date >= :start_date")
params['start_date'] = start_date
if end_date:
conditions.append("order_date <= :end_date")
params['end_date'] = end_date
if status:
conditions.append("status = :status")
params['status'] = status
if min_amount:
conditions.append("amount >= :min_amount")
params['min_amount'] = float(min_amount)
# 组合所有条件
if conditions:
sql += " AND " + " AND ".join(conditions)
sql += " ORDER BY order_date DESC"
# 执行查询
return pd.read_sql(text(sql), engine, params=params)
# 方法2:使用SQL表达式语言(更Pythonic)
def get_orders_expression(engine, **filters):
from sqlalchemy import Table, Column, Integer, String, Date, Numeric, MetaData
# 反射数据库表结构(不需要提前定义模型!)
metadata = MetaData()
orders_table = Table('orders', metadata, autoload_with=engine)
# 构建查询
query = select(orders_table)
# 动态添加过滤条件
where_clauses = []
if 'start_date' in filters:
where_clauses.append(orders_table.c.order_date >= filters['start_date'])
if 'end_date' in filters:
where_clauses.append(orders_table.c.order_date <= filters['end_date'])
if 'status' in filters:
where_clauses.append(orders_table.c.status == filters['status'])
if where_clauses:
query = query.where(and_(*where_clauses))
query = query.order_by(orders_table.c.order_date.desc())
# 执行查询
return pd.read_sql(query, engine)
# 使用示例
df1 = get_orders_safe(
start_date='2024-01-01',
status='delivered',
min_amount=100
)
df2 = get_orders_expression(
engine,
start_date='2024-01-01',
end_date='2024-01-31',
status='paid'
)第三章:高级技巧:分页、大数据量与性能优化
3.1 高效分页查询
当数据量很大时,一次性加载所有数据会消耗大量内存。我们需要分页查询。
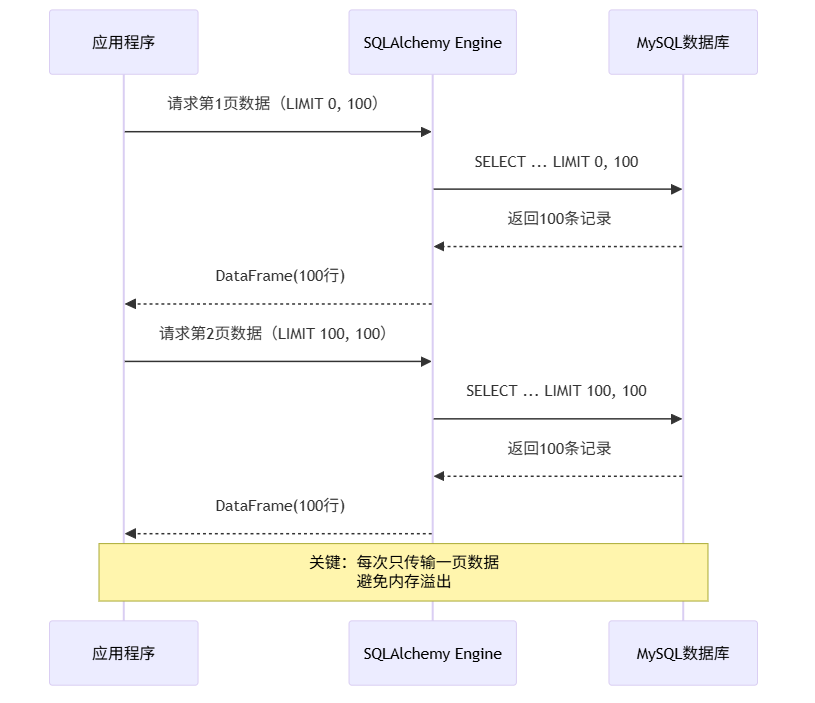
实现分页查询的两种方式:
python
def get_orders_paginated(page=1, page_size=100, **filters):
"""
分页查询订单数据
Args:
page: 页码,从1开始
page_size: 每页大小
**filters: 过滤条件
"""
# 计算偏移量
offset = (page - 1) * page_size
# 基础查询
sql = """
SELECT SQL_CALC_FOUND_ROWS *
FROM orders
WHERE 1=1
"""
# 添加过滤条件
conditions = []
params = {}
if 'start_date' in filters:
conditions.append("order_date >= :start_date")
params['start_date'] = filters['start_date']
if 'status' in filters:
conditions.append("status = :status")
params['status'] = filters['status']
if conditions:
sql += " AND " + " AND ".join(conditions)
# 添加分页
sql += " ORDER BY order_date DESC LIMIT :limit OFFSET :offset"
params['limit'] = page_size
params['offset'] = offset
# 执行分页查询
df_page = pd.read_sql(text(sql), engine, params=params)
# 获取总记录数(使用SQL_CALC_FOUND_ROWS)
total_count = pd.read_sql(
text("SELECT FOUND_ROWS() as total"),
engine
).iloc[0]['total']
# 计算总页数
total_pages = (total_count + page_size - 1) // page_size
return {
'data': df_page,
'page': page,
'page_size': page_size,
'total_count': total_count,
'total_pages': total_pages,
'has_prev': page > 1,
'has_next': page < total_pages
}
# 使用示例
result = get_orders_paginated(
page=1,
page_size=50,
start_date='2024-01-01',
status='delivered'
)
print(f"第{result['page']}页,共{result['total_pages']}页")
print(f"总记录数:{result['total_count']}")
print(result['data'].head())3.2 大数据量处理:使用chunksize
当查询结果非常大时(比如百万行),即使分页也可能内存不足。这时可以使用chunksize参数:
python
def process_large_dataset():
"""处理大数据集,避免内存溢出"""
# 查询语句
query = "SELECT * FROM orders WHERE order_date >= '2023-01-01'"
# 使用chunksize分批读取
chunk_size = 10000
total_rows = 0
# 创建一个空DataFrame用于存储汇总结果
summary_df = pd.DataFrame()
for chunk_df in pd.read_sql(
text(query),
engine,
chunksize=chunk_size,
parse_dates=['order_date']
):
print(f"处理第 {total_rows // chunk_size + 1} 个数据块,大小: {len(chunk_df)} 行")
# 在这里处理每个数据块
# 例如:计算每个数据块的统计信息
chunk_summary = pd.DataFrame({
'chunk': [total_rows // chunk_size + 1],
'min_date': [chunk_df['order_date'].min()],
'max_date': [chunk_df['order_date'].max()],
'total_amount': [chunk_df['amount'].sum()],
'avg_amount': [chunk_df['amount'].mean()]
})
# 合并到汇总DataFrame
summary_df = pd.concat([summary_df, chunk_summary], ignore_index=True)
total_rows += len(chunk_df)
# 释放当前块的内存
del chunk_df
print(f"处理完成!总共处理了 {total_rows} 行数据")
return summary_df
# 执行大数据处理
summary = process_large_dataset()
print(summary)第四章:完整实战:电商数据分析案例
现在让我们把这些技术组合起来,完成一个真实的电商数据分析任务。
4.1 案例背景
假设我们是某电商平台的数据分析师,需要完成以下分析任务:
- 计算每月销售额趋势
- 分析用户购买行为(新老用户对比)
- 找出畅销商品
- 计算用户复购率
4.2 完整代码实现
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sqlalchemy import create_engine, text
from datetime import datetime, timedelta
class EcommerceAnalyzer:
"""电商数据分析器"""
def __init__(self, connection_string):
"""初始化分析器"""
self.engine = create_engine(connection_string)
print("✅ 数据库连接已建立")
def get_monthly_sales(self, start_date='2023-01-01', end_date='2024-12-31'):
"""计算月度销售额趋势"""
query = text("""
SELECT
DATE_FORMAT(order_date, '%Y-%m') as month,
COUNT(*) as order_count,
SUM(amount) as total_amount,
AVG(amount) as avg_order_value
FROM orders
WHERE order_date BETWEEN :start_date AND :end_date
AND status NOT IN ('cancelled')
GROUP BY DATE_FORMAT(order_date, '%Y-%m')
ORDER BY month
""")
df = pd.read_sql(
query,
self.engine,
params={'start_date': start_date, 'end_date': end_date}
)
# 转换月份为datetime类型,便于绘图
df['month'] = pd.to_datetime(df['month'] + '-01')
return df
def analyze_user_behavior(self):
"""分析用户购买行为"""
query = text("""
WITH user_stats AS (
SELECT
u.user_id,
u.username,
u.created_at as user_created,
u.is_vip,
COUNT(o.order_id) as total_orders,
SUM(o.amount) as total_spent,
MIN(o.order_date) as first_order_date,
MAX(o.order_date) as last_order_date
FROM users u
LEFT JOIN orders o ON u.user_id = o.user_id
AND o.status NOT IN ('cancelled')
GROUP BY u.user_id, u.username, u.created_at, u.is_vip
)
SELECT
CASE
WHEN total_orders = 0 THEN '未购买'
WHEN total_orders = 1 THEN '购买1次'
WHEN total_orders BETWEEN 2 AND 5 THEN '购买2-5次'
ELSE '购买5次以上'
END as purchase_frequency,
COUNT(*) as user_count,
AVG(total_spent) as avg_spent_per_user,
SUM(total_spent) as total_spent
FROM user_stats
GROUP BY purchase_frequency
ORDER BY
CASE purchase_frequency
WHEN '未购买' THEN 1
WHEN '购买1次' THEN 2
WHEN '购买2-5次' THEN 3
ELSE 4
END
""")
return pd.read_sql(query, self.engine)
def find_top_products(self, limit=10):
"""找出畅销商品"""
query = text("""
SELECT
product_name,
SUM(quantity) as total_quantity,
SUM(quantity * price) as total_sales,
COUNT(DISTINCT order_id) as order_count,
AVG(price) as avg_price
FROM order_items
GROUP BY product_name
ORDER BY total_sales DESC
LIMIT :limit
""")
return pd.read_sql(query, self.engine, params={'limit': limit})
def calculate_repeat_purchase_rate(self):
"""计算用户复购率"""
query = text("""
WITH user_order_counts AS (
SELECT
user_id,
COUNT(*) as order_count
FROM orders
WHERE status NOT IN ('cancelled')
GROUP BY user_id
)
SELECT
COUNT(*) as total_users,
SUM(CASE WHEN order_count > 1 THEN 1 ELSE 0 END) as repeat_users,
ROUND(
SUM(CASE WHEN order_count > 1 THEN 1 ELSE 0 END) * 100.0 / COUNT(*),
2
) as repeat_rate_percent
FROM user_order_counts
""")
return pd.read_sql(query, self.engine)
def save_analysis_to_db(self, df, table_name):
"""将分析结果保存回数据库"""
# 添加分析时间戳
df['analysis_time'] = datetime.now()
# 使用pandas的to_sql方法
df.to_sql(
name=table_name,
con=self.engine,
if_exists='append', # 追加模式
index=False,
chunksize=1000
)
print(f"✅ 分析结果已保存到表: {table_name}")
def generate_report(self):
"""生成完整分析报告"""
print("=" * 60)
print("📊 电商数据分析报告")
print("=" * 60)
# 1. 月度销售趋势
print("\n1. 月度销售趋势分析:")
monthly_sales = self.get_monthly_sales()
print(monthly_sales.tail()) # 显示最近几个月
# 2. 用户行为分析
print("\n2. 用户购买行为分析:")
user_behavior = self.analyze_user_behavior()
print(user_behavior)
# 3. 畅销商品
print("\n3. 畅销商品TOP 10:")
top_products = self.find_top_products(10)
print(top_products)
# 4. 复购率
print("\n4. 用户复购率分析:")
repeat_rate = self.calculate_repeat_purchase_rate()
print(repeat_rate)
# 保存分析结果到数据库
self.save_analysis_to_db(monthly_sales, 'monthly_sales_analysis')
self.save_analysis_to_db(user_behavior, 'user_behavior_analysis')
return {
'monthly_sales': monthly_sales,
'user_behavior': user_behavior,
'top_products': top_products,
'repeat_rate': repeat_rate
}
# 使用示例
if __name__ == "__main__":
# 配置数据库连接
connection_string = "mysql+pymysql://root:password@localhost:3306/sales_db"
# 创建分析器
analyzer = EcommerceAnalyzer(connection_string)
# 生成报告
report = analyzer.generate_report()
# 可视化:月度销售额趋势
plt.figure(figsize=(12, 6))
plt.plot(report['monthly_sales']['month'], report['monthly_sales']['total_amount'], marker='o')
plt.title('月度销售额趋势')
plt.xlabel('月份')
plt.ylabel('销售额')
plt.xticks(rotation=45)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()第五章:性能优化与最佳实践
5.1 查询性能优化
| 优化点 | 问题表现 | 解决方案 | 效果预估 |
|---|---|---|---|
| N+1查询问题 | 循环中执行查询,产生大量小查询 | 使用JOIN一次性获取所有数据 | 性能提升10-100倍 |
| **SELECT *** | 查询不需要的列,浪费带宽和内存 | 只SELECT需要的列 | 减少50-90%数据传输 |
| 无索引查询 | 全表扫描,数据量大时极慢 | 为WHERE条件字段添加索引 | 查询速度提升100-1000倍 |
| 内存溢出 | 一次性加载百万行数据 | 使用chunksize分批处理 | 内存使用减少90%+ |
| 连接泄露 | 连接数持续增长,最终耗尽 | 使用with语句自动管理连接 | 避免连接池耗尽 |
5.2 实际优化示例
python
def optimized_query_example():
"""优化前后的查询对比"""
# ❌ 不优化的写法(N+1查询问题)
def get_orders_with_users_naive():
"""低效:先查订单,再循环查用户"""
orders_df = pd.read_sql("SELECT * FROM orders LIMIT 100", engine)
user_names = []
for _, order in orders_df.iterrows():
# 每次循环都执行一次查询!
user_df = pd.read_sql(
text("SELECT username FROM users WHERE user_id = :user_id"),
engine,
params={'user_id': order['user_id']}
)
user_names.append(user_df.iloc[0]['username'] if not user_df.empty else 'Unknown')
orders_df['username'] = user_names
return orders_df
# ✅ 优化的写法(使用JOIN一次查询)
def get_orders_with_users_optimized():
"""高效:使用JOIN一次性获取"""
query = text("""
SELECT
o.order_id,
o.amount,
o.order_date,
o.status,
u.username -- 一次性获取用户名
FROM orders o
JOIN users u ON o.user_id = u.user_id
LIMIT 100
""")
return pd.read_sql(query, engine)
# 测试性能
import time
print("测试查询性能...")
start = time.time()
df1 = get_orders_with_users_naive()
naive_time = time.time() - start
print(f"❌ 不优化版本耗时: {naive_time:.2f}秒")
start = time.time()
df2 = get_orders_with_users_optimized()
optimized_time = time.time() - start
print(f"✅ 优化版本耗时: {optimized_time:.2f}秒")
print(f"性能提升: {naive_time/optimized_time:.1f}倍")
return df2
# 执行优化测试
optimized_df = optimized_query_example()5.3 连接池最佳配置
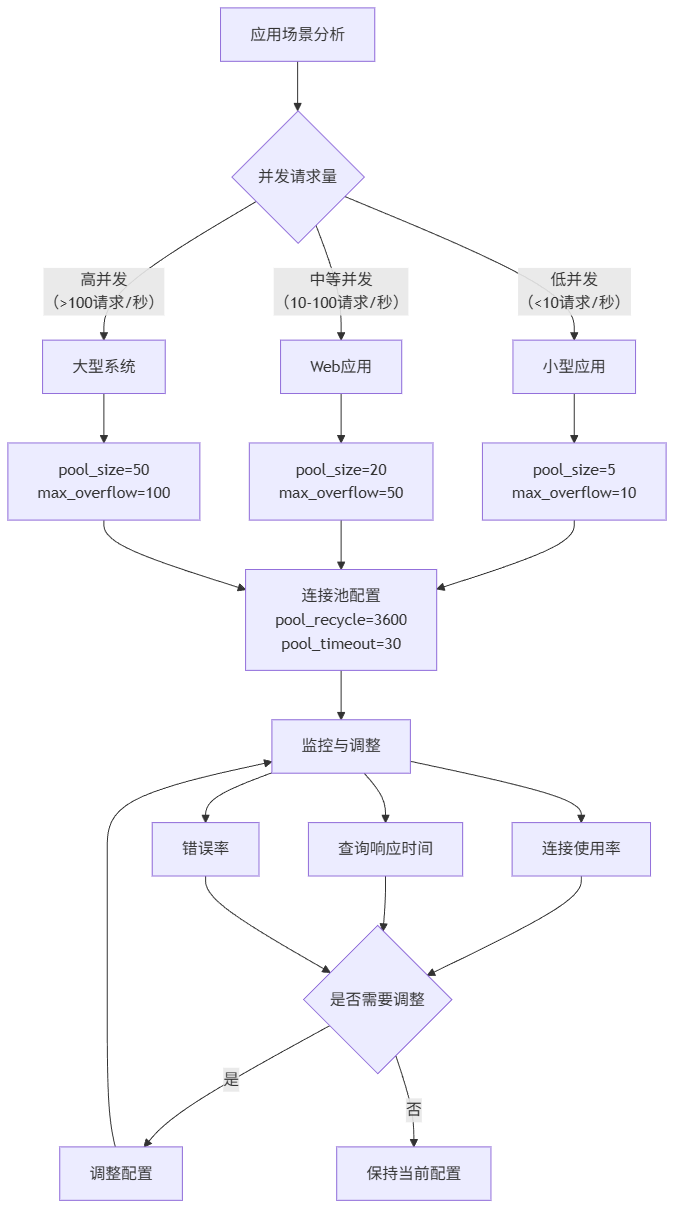
生产环境连接池配置建议:
python
def create_production_engine():
"""创建生产环境数据库引擎"""
# 根据应用类型选择配置
app_type = 'web_application' # 可选: 'data_analysis', 'web_application', 'batch_processing'
configs = {
'data_analysis': {
'pool_size': 5,
'max_overflow': 10,
'pool_timeout': 60, # 数据分析查询可能较慢
'pool_recycle': 1800 # 30分钟回收
},
'web_application': {
'pool_size': 20,
'max_overflow': 50,
'pool_timeout': 30, # Web请求需要快速响应
'pool_recycle': 3600 # 1小时回收
},
'batch_processing': {
'pool_size': 10,
'max_overflow': 20,
'pool_timeout': 300, # 批处理可能很慢
'pool_recycle': 7200 # 2小时回收
}
}
config = configs.get(app_type, configs['web_application'])
engine = create_engine(
'mysql+pymysql://user:password@localhost/production_db',
pool_size=config['pool_size'],
max_overflow=config['max_overflow'],
pool_timeout=config['pool_timeout'],
pool_recycle=config['pool_recycle'],
echo_pool=True, # 记录连接池事件(调试用)
isolation_level='READ_COMMITTED', # 事务隔离级别
connect_args={
'charset': 'utf8mb4',
'connect_timeout': 10
}
)
return engine第六章:常见问题与解决方案
6.1 连接相关问题
python
# 问题1:连接超时(MySQL默认8小时断开空闲连接)
def handle_connection_timeout():
"""处理连接超时问题"""
# 解决方案:设置pool_recycle
engine = create_engine(
'mysql+pymysql://user:pass@localhost/db',
pool_recycle=3600, # 1小时回收连接,避免MySQL断开
pool_pre_ping=True, # 执行前检查连接是否有效
)
return engine
# 问题2:连接池耗尽(Too many connections)
def handle_connection_pool_exhaustion():
"""处理连接池耗尽问题"""
# 解决方案:确保连接正确关闭
def safe_query():
# 使用with语句确保连接自动关闭
with engine.connect() as conn:
df = pd.read_sql("SELECT * FROM table", conn)
# ... 处理数据
return df
# 连接自动关闭并返回到连接池
# 监控连接使用情况
def monitor_connections(engine):
# 获取连接池状态
pool = engine.pool
print(f"连接池状态:")
print(f" 当前连接数: {pool.checkedin() + pool.checkedout()}")
print(f" 使用中连接: {pool.checkedout()}")
print(f" 空闲连接: {pool.checkedin()}")
print(f" 连接池大小: {pool.size()}")6.2 数据类型处理问题
python
# 问题:Pandas与MySQL数据类型不匹配
def handle_data_type_issues():
"""处理数据类型转换问题"""
# 常见问题1:DATETIME转换
df = pd.read_sql(
"SELECT * FROM orders",
engine,
parse_dates=['order_date', 'created_at'], # 指定日期字段
dtype={
'amount': 'float32', # 指定金额为float32
'user_id': 'int32', # 指定用户ID为int32
'status': 'category' # 状态字段转为分类类型,节省内存
}
)
# 常见问题2:处理NULL值
df_filled = df.fillna({
'amount': 0,
'description': ''
})
# 常见问题3:写入数据库时的类型处理
df_to_save = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, None], # 包含None
'score': [95.5, 88.0, 92.3]
})
# 保存到数据库,处理NULL值
df_to_save.to_sql(
'students',
engine,
if_exists='replace',
index=False,
dtype={
'age': 'INTEGER', # MySQL的INTEGER类型
'score': 'DECIMAL(5,2)' # 指定精度
},
method='multi' # 批量插入
)
return df学习总结与进阶方向
总结回顾
通过这篇教程,我们掌握了:
- SQLAlchemy Core基础:学会了用Pythonic的方式构建SQL查询
- Pandas无缝集成 :用
pd.read_sql()直接获取DataFrame - 安全查询构建:使用参数化查询防止SQL注入
- 大数据量处理:分页查询和chunksize分批处理
- 性能优化技巧:避免N+1查询,合理使用索引
- 生产环境配置:连接池配置和监控
关键收获
- SQLAlchemy Core比ORM更适合数据分析:更灵活,性能更好
- 连接池是生产环境必备:自动管理连接,避免资源泄露
- Pandas的
read_sql是神器:一行代码完成查询和转换 - 动态查询要安全:永远不要用字符串拼接SQL
进阶学习方向
如果你已经掌握了本文内容,可以继续学习:
- SQLAlchemy ORM:用于Web开发中的模型定义
- Alembic数据库迁移:管理数据库结构变更
- 异步数据库访问 :使用
asyncpg或aiomysql提高并发性能 - 数据仓库集成:连接Redshift、BigQuery等数据仓库
- 查询性能分析:使用EXPLAIN分析SQL执行计划
学习交流与互动
恭喜你完成了Pandas + SQLAlchemy的学习!这只是数据分析的开始,实际项目中还会遇到更多有趣的问题。
欢迎在评论区分享你的学习心得和遇到的问题:
- 你在使用Pandas读取MySQL数据时,遇到过哪些报错?
- 文中的电商分析案例,你成功运行了吗?
- 对于大数据量处理,你还有什么更好的方法?
- 在实际项目中,你通常用SQLAlchemy Core还是ORM?为什么?
我会认真阅读每一条评论,并为初学者提供针对性的解答。记住,学习编程最好的方式就是多动手实践!
推荐学习资源: