目录
一、范式基石:构建真实世界的参考系------自然驾驶基准库
二、双引擎驱动------实现从"广度覆盖"到"深度挖掘"的智能跃迁
[1. 高价值场景挖掘引擎:从数据矿石中提炼"场景黄金"](#1. 高价值场景挖掘引擎:从数据矿石中提炼“场景黄金”)
[2. 边界场景搜索引擎:自适应"围猎"系统决策缺陷](#2. 边界场景搜索引擎:自适应“围猎”系统决策缺陷)
三、多维评价------从"能否通过"到"好不好用"的价值升级
[1. 类人度指数:量化"驾驶体验",追求社会接纳](#1. 类人度指数:量化“驾驶体验”,追求社会接纳)
[2. 能力成熟度指数:绘制"能力地图",实现精准迭代](#2. 能力成熟度指数:绘制“能力地图”,实现精准迭代)
在上一期中,我分享了我们对**自动驾驶仿真测试**困境的观察与破局思路。
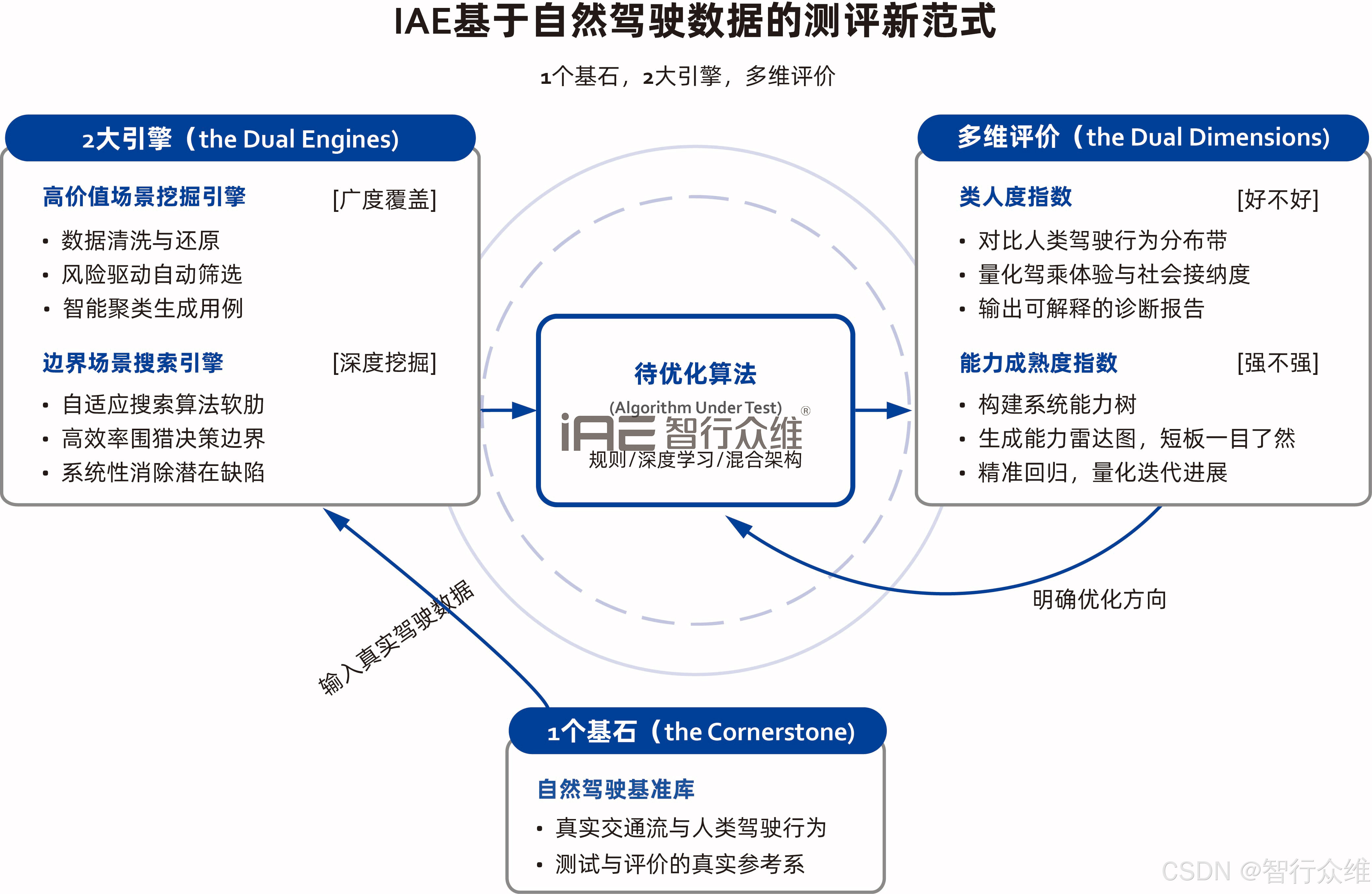
这一期文章,我将具体介绍我们"水木灵境"场景工场团队如何通过数据驱动与AI融合,构建起一套可落地、可迭代的测评新范式,详细分享这套以 "1个基石、2大引擎、多维评价" 为核心框架的实践方案。
一、范式基石:构建真实世界的参考系------自然驾驶基准库

自动驾驶仿真测试的终极目标,是让系统在真实世界中安全、平稳地运行。因此,我们认为测试的起点必须是真实世界本身。我们投入构建的自然驾驶基准库,正是整个新范式的基石。
这个基准库并非简单的数据堆积。它通过专业流程,将来自多源传感器的原始数据,转化为结构化、可查询、可复现的场景素材。其核心价值在于,它蕴含了真实的交通流动态与人类驾驶行为的不确定性和复杂性。这意味着,它不仅是生成测试场景的源头,更成为我们评估系统"是否像真人一样驾驶"的真实参考系,从根本上致力于缩小仿真与现实之间的差距。
二、双引擎驱动------实现从"广度覆盖"到"深度挖掘"的智能跃迁
传统测试常在"场景覆盖不足"和"随机测试效率低下"之间挣扎。我们的解决方案是让两个智能引擎协同作战:高价值场景挖掘引擎负责广度提纯,边界场景搜索引擎负责深度狙击。
1. 高价值场景挖掘引擎:从数据矿石中提炼"场景黄金"
真实道路数据中充斥着大量平淡、低风险的行驶片段。手动筛选高价值场景如同大海捞针。我们的挖掘引擎旨在自动化完成"提纯"流程,将混杂的真实数据矿石,转化为可直接用于测试的"高纯度场景黄金"。

· 核心流程 :首先,通过多维数据清洗与还原技术,智能修复轨迹中断、目标ID跳变等问题,最大限度还原真实世界。然后,依托风险驱动的自动筛选模型,基于时空接近度、相对速度、交互复杂度等维度,自动识别并筛选出高动态、高交互的挑战性片段,能有效剔除约90% 的低价值数据。最后,利用**AI智能聚类算法**对高风险场景进行归类与去重,形成最具代表性的场景模板,并一键生成符合行业标准的可执行测试用例。
· 带来的变革:这一流程将工程师从繁重的数据筛选与用例编写中解放出来,将"从数据到测试"的时间从数天缩短至数小时,实现了测试场景的批量化、高效率生产,保证了测试的覆盖广度。
2. 边界场景搜索引擎:自适应"围猎"系统决策缺陷
通过性测试只能验证已知场景,而未知的"角落"才是风险所在。边界场景搜索引擎就像一个敏锐的"压力测试员",主动寻找系统的失效边界。
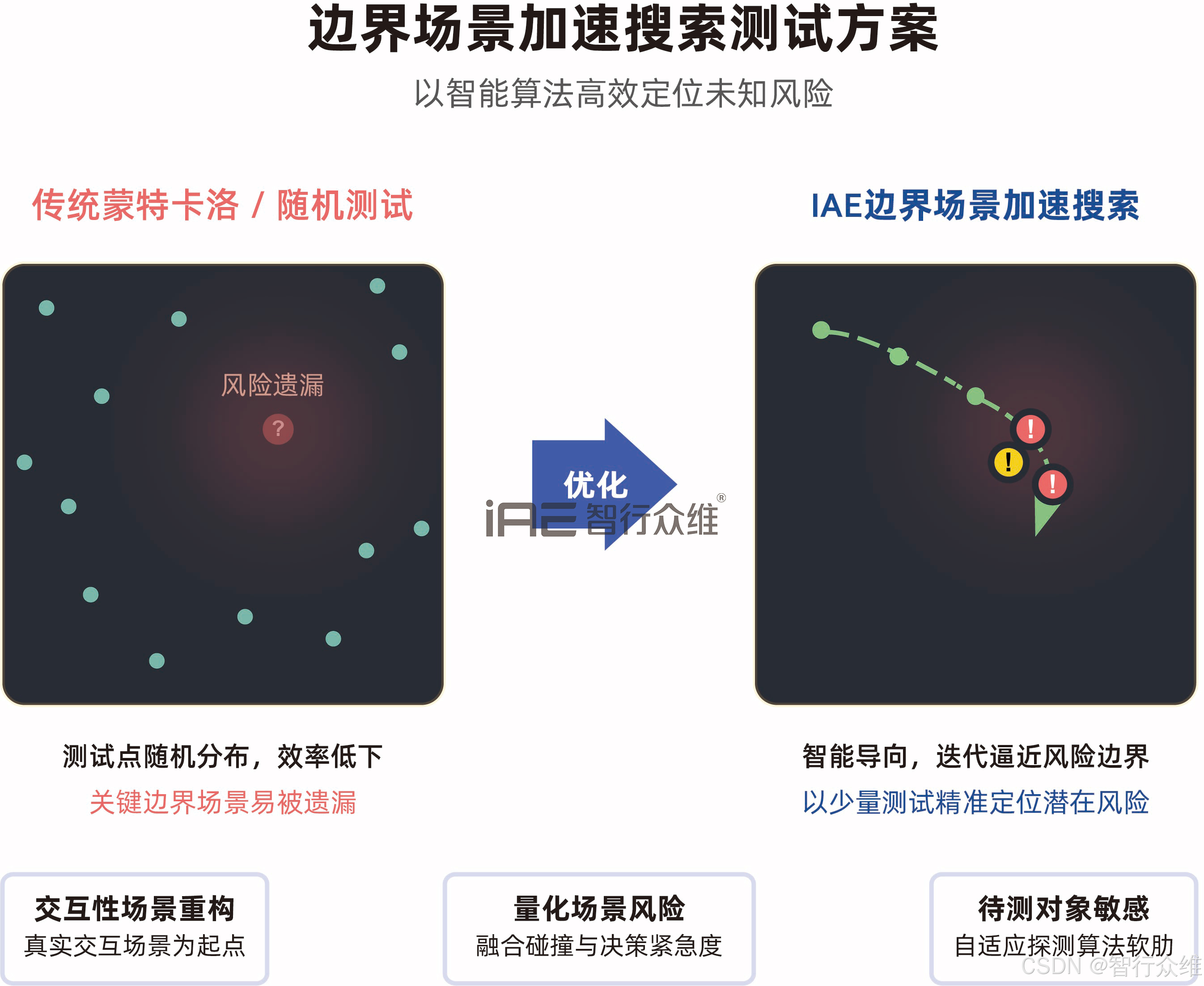

· 工作原理 :它以真实的高风险场景为"种子"蓝本,在其关键参数(如他车速度、切入角度、行人出现时机)空间中,采用**贝叶斯优化**等先进算法进行智能探索。其目标非常明确:高效定位那些会导致系统性能骤降或失效的参数组合。
· 核心优势:这个搜索过程是被测对象敏感和自适应的。引擎会根据被测系统实时的规划或控制反馈,动态调整搜索方向,专门针对系统的"软肋"进行攻击。实践表明,这种方法的效率相比传统的蒙特卡洛随机测试方法高出数个数量级,能在极短时间内发现那些隐藏极深的规划或决策逻辑缺陷。
双引擎的配合,使我们从"被动等待问题暴露"转向"主动发起风险挖掘",在产品发布前系统性地识别和消除潜在缺陷。
三、多维评价------从"能否通过"到"好不好用"的价值升级
我们认为,通过安全测试仅是及格线,一个好用的智能驾驶系统还必须具备良好的驾乘体验和全面、可靠的能力。因此,我们建立了**类人度指数** 与**能力成熟度指数**的双维评价体系。
1. 类人度指数:量化"驾驶体验",追求社会接纳
我们摒弃了与单一固定轨迹对比的陈旧思路,创新性地将系统行为与海量人类驾驶行为分布进行对比。
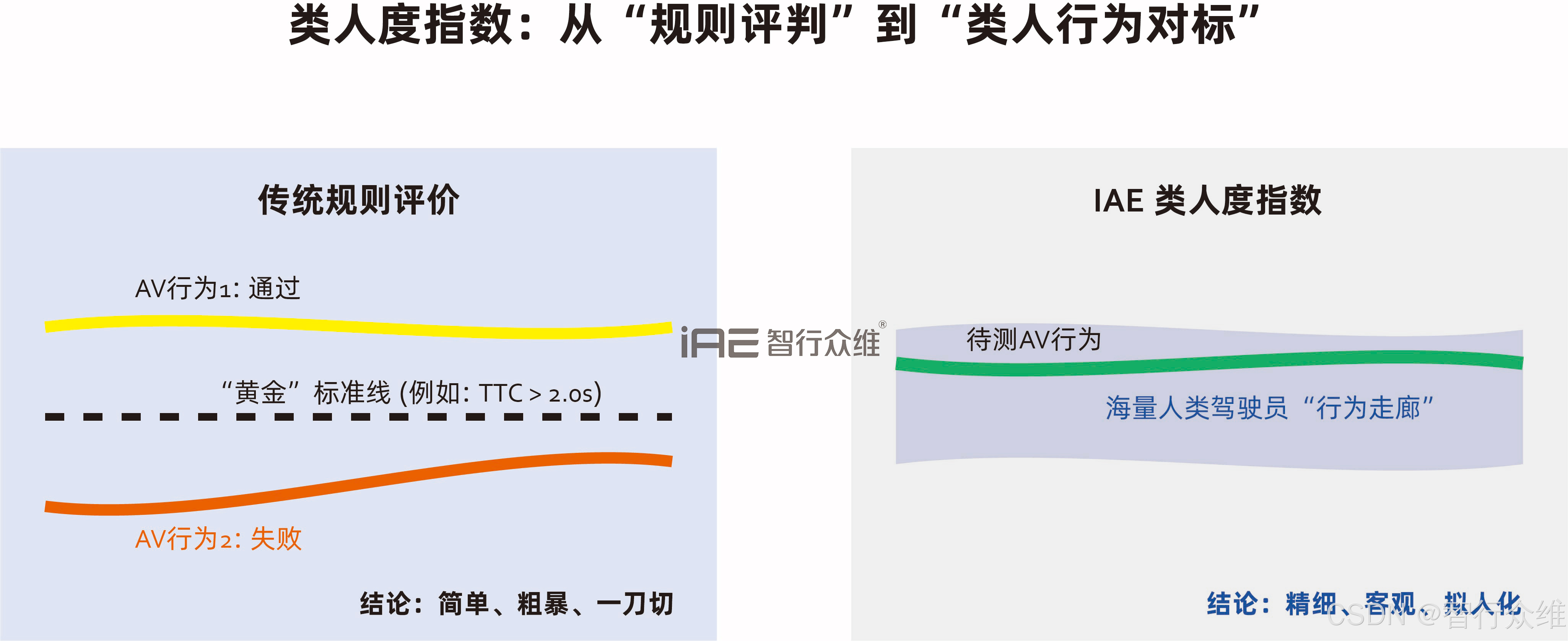
· 评价方法:在特定场景下,系统会从基准库中精准匹配到大量相似的人类驾驶片段。通过对比系统与人类群体在加速度、转向、轨迹选择等多维度上的行为分布带,进行时序化的量化分析。
· 价值输出 :最终生成一个综合的类人度指数,并附有可解释的诊断报告。报告能明确指出:如"在高速匝道汇流场景中,系统的横向控制波动频率**高于90%**的人类驾驶员,可能影响乘坐舒适性。"这为控制算法的优化提供了极其精准、量化的输入,直指用户体验的核心。
2. 能力成熟度指数:绘制"能力地图",实现精准迭代
为了体系化地评估系统能力进展,我们构建了一棵细分的"能力树",将整体驾驶能力分解为"交通规则遵守"、"复杂交互博弈"、"特殊环境应对"等分支,并将测试用例与能力叶节点精准绑定。
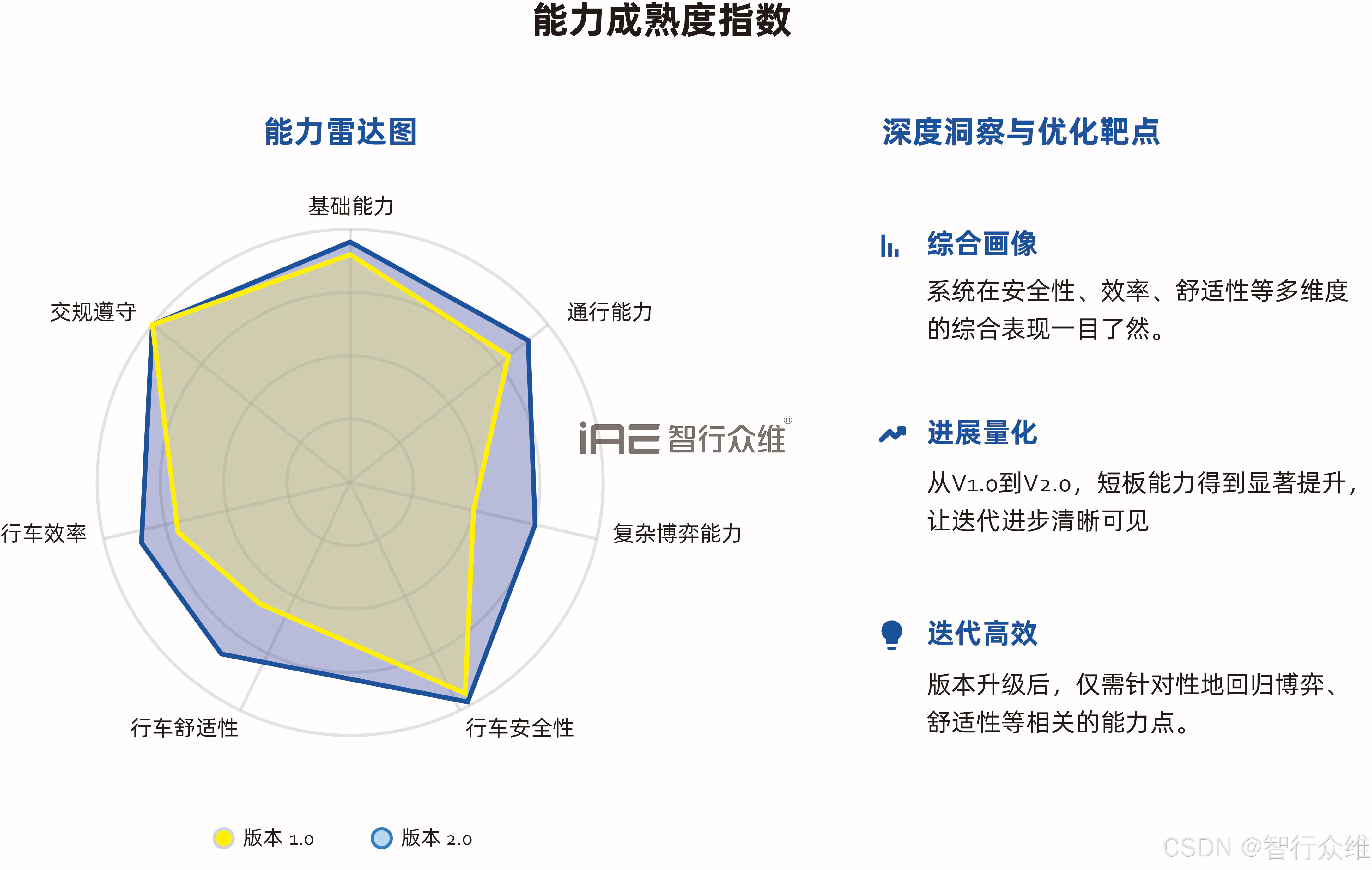
运作方式 :每一个测试用例都会与一个或多个能力点标签绑定。当测试完成后,系统会自动统计分析,生成可视化的雷达图呈现系统综合能力画像。
核心价值:这张"能力地图"让系统的优势与短板一目了然。在版本迭代时,团队可以精准地只回归测试受影响的相关能力点,而非执行全量回归,极大地提升了回归测试的效率。同时,它让每一次迭代的能力进步都变得清晰可见,为项目管理和技术决策提供了可靠的数据支撑。
这套评价体系的变革在于,它将评价标准从非对即错的二元判断,升级为对能力深度与体验品质的深度洞察,为算法优化提供了精准、可量化的靶点,直指商业化成功的核心:社会与用户的双重接纳。
四、范式总结:测试如何成为研发的"智能加速器"
回顾我们构建的这套新范式,它不仅仅是工具的组合,更是一种系统性的方法论升级。它从真实数据出发,通过智能算法引擎驱动,最终落脚于可量化、可解释的评价体系,形成了一个完整的"测试-分析-优化"智能闭环。
它带来的改变是切实的:
应对系统黑盒:无论面对规则驱动、数据驱动还是混合架构,我们都聚焦于最终的外在行为与核心能力进行评测。
兼顾覆盖与效率:用真实数据保证场景广度,用智能搜索探索决策深度,用聚类提纯提升执行效率。
平衡风险与体验:边界搜索致力于消除致命安全隐患,类人评价则确保系统行为符合人类预期与社会规范。
加速研发闭环:自动化、可量化、可追溯的全流程,极大缩短了"开发-测试-优化"的周期,使测试从研发瓶颈转变为迭代加速器。
结语:测试范式的重塑与工程师角色的新生
回顾我们从"测试泥潭"到"智能加速"的探索历程,其核心远不止于构建一套高效的工具链。这实质上是一场对自动驾驶仿真测试范式的系统性重塑:从以经验和规则为中心,转向以真实数据和智能算法为驱动;从研发流程中被动、滞后的检验环节,转变为主动、贯穿始终的能力共建环节。
我们所实践的"1个基石、2大引擎、多维评价"体系,正是这一理念的具象化。它让测试不再是单纯的成本中心,而是成为了驱动算法迭代、沉淀系统知识、对齐产品价值的关键枢纽。更重要的是,它促使我们测试工程师的角色发生深刻进化------我们不再是仅仅手持检查清单的"守门员",而是运用数据洞察与算法工具,深入参与系统能力定义的"共建者"。
智能驾驶的成熟之路道阻且长,对系统安全与体验的验证也必将面临更复杂的挑战。我们团队深信,坚持以真实世界为锚点,让测试过程兼具智能的广度与深度,并追求评价的客观与可解释性,这条路径将引领我们走向更可靠的未来。我们也将持续迭代我们的方法与工具,并期待与业界同仁有更多交流碰撞,共同推动自动驾驶仿真测试验证技术的进步。
注: 本文内容基于个人实践经验整理,旨在交流技术思路。