写在前面
本系列推文为《R for Data Science (2)》的中文翻译版本。所有内容都通过开源免费的方式上传至Github,欢迎大家参与贡献,详细信息见:
Books-zh-cn 项目介绍:
Books-zh-cn:开源免费的中文书籍社区
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 网站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目录
-
17.1 介绍
-
17.2 创建日期/时间
17.1 介绍
本章将向你展示如何在 R 中处理日期和时间。 乍看之下,日期和时间似乎很简单。 你在日常生活中经常使用它们,而且它们似乎不会引起太多困惑。 然而,你对日期和时间了解得越多,就越会发现它们的复杂之处!
先来思考一下:一年有多少天,一天有多少小时。 你或许记得大多数年份有 365 天,但闰年有 366 天。 你知道判断闰年的完整规则吗? 一天的小时数则稍不明显:大多数日子有 24 小时,但在使用夏令时(DST)的地区,每年会有一天只有 23 小时,另一天则有 25 小时。
日期和时间之所以复杂,是因为它们必须协调两种自然现象(地球自转和绕太阳公转)与一系列地缘政治现象(包括月份、时区和夏令时)。 本章不会涵盖日期和时间的每一个细节,但会为你打下扎实的实践技能基础,帮助你应对常见的数据分析挑战。
我们将首先展示如何从不同输入创建日期时间,然后介绍在获得日期时间后如何提取年、月、日等组成部分。 接着,我们将深入探讨处理时间跨度的棘手主题,根据不同的使用目标,时间跨度有多种表现形式。 最后,我们将简要讨论时区带来的额外挑战。
17.1.1 先决条件
本章将重点介绍 lubridate 包,它能让你在 R 中更轻松地处理日期和时间。 根据 tidyverse 的最新版本,lubridate 已成为核心 tidyverse 的一部分。 我们还需要 nycflights13 包来提供练习数据。
library(tidyverse)
library(nycflights13)17.2 创建日期/时间
有三种类型的日期/时间数据用于指代特定时刻:
-
A date 。 Tibbles 会将其显示为
<date>。 -
A time within a day。 Tibbles 会将其显示为
<time>。 -
A date-time 是日期加上时间: 它能唯一标识某个时刻(通常精确到秒)。 Tibbles 会将其显示为
<dttm>。 Base R 将其称为 POSIXct, 但这个名称并不直观.
本章我们将重点关注日期和日期时间,因为 R 没有原生类来存储时间。 如果你需要处理时间,可以使用 hms 包。
你应始终使用能满足需求的最简单数据类型。 这意味着如果可以用 date 代替 date-time,就应该使用 date。 Date-times 要复杂得多,因为需要处理时区问题,我们将在本章末尾讨论这一点。
要获取当前 date 或 date-time,可以使用 today() 或 now():
today()
#> [1] "2025-12-23"
now()
#> [1] "2025-12-23 23:18:35 UTC"除此之外,以下部分将介绍四种常见的创建 date/time 的方法:
-
使用 readr 读取文件时。
-
从字符串解析。
-
从独立的 date-time 组件组合。
-
从已有的 date/time 对象转换。
17.2.1 导入期间
如果你的 CSV 文件包含 ISO8601 格式的 date 或 date-time,你无需进行额外操作;readr 会自动识别它:
csv <- "
date,datetime
2022-01-02,2022-01-02 05:12
"
read_csv(csv)
#> # A tibble: 1 × 2
#> date datetime
#> <date> <dttm>
#> 1 2022-01-02 2022-01-02 05:12:00如果你之前没听说过 ISO8601 ,它是一种国际标准,用于书写日期,其日期组成部分按从大到小的顺序排列,并用 - 分隔。 例如,在 ISO8601 标准中,2022 年 5 月 3 日写作 2022-05-03。ISO8601 日期也可以包含时间,其中时、分、秒用 : 分隔,而日期和时间部分则用 T 或空格分隔。 例如,2022 年 5 月 3 日下午 4:26 可以写作 2022-05-03 16:26 或 2022-05-03T16:26。
对于其他日期时间格式,你需要使用 col_types 以及 col_date() 或 col_datetime(),并指定日期时间格式。 readr 使用的日期时间格式是多种编程语言通用的标准,它用 % 后跟一个字符来描述日期组成部分。 例如,%Y-%m-%d 指定了一个日期格式为年、-、月(数字形式)、-、日。 表 Table 17.1 列出了所有选项。
Table 17.1: readr 能理解的所有日期格式
| Type | Code | Meaning | Example |
|---|---|---|---|
| Year | %Y |
4 digit year | 2021 |
%y |
2 digit year | 21 | |
| Month | %m |
Number | 2 |
%b |
Abbreviated name | Feb | |
%B |
Full name | February | |
| Day | %d |
Two digits | 02 |
%e |
One or two digits | 2 | |
| Time | %H |
24-hour hour | 13 |
%I |
12-hour hour | 1 | |
%p |
AM/PM | pm | |
%M |
Minutes | 35 | |
%S |
Seconds | 45 | |
%OS |
Seconds with decimal component | 45.35 | |
%Z |
Time zone name | America/Chicago | |
%z |
Offset from UTC | +0800 | |
| Other | %. |
Skip one non-digit | : |
%* |
Skip any number of non-digits |
这段代码显示了一些应用于一个非常模糊的日期的选项:
csv <- "
date
01/02/15
"
read_csv(csv, col_types = cols(date = col_date("%m/%d/%y")))
#> # A tibble: 1 × 1
#> date
#> <date>
#> 1 2015-01-02
read_csv(csv, col_types = cols(date = col_date("%d/%m/%y")))
#> # A tibble: 1 × 1
#> date
#> <date>
#> 1 2015-02-01
read_csv(csv, col_types = cols(date = col_date("%y/%m/%d")))
#> # A tibble: 1 × 1
#> date
#> <date>
#> 1 2001-02-15请注意,无论你如何指定日期格式,一旦将其导入 R,它总是以相同的方式显示。
如果你使用 %b 或 %B 并处理非英语日期,还需要提供 locale() 参数。 可查看 date_names_langs() 中内置的语言列表,或使用 date_names() 创建自定义语言设置。
17.2.2 从字符串
日期时间规范语言功能强大,但需要仔细分析日期格式。 另一种方法是使用 lubridate 的辅助函数,它们能在你指定组成部分的顺序后自动判断格式。 使用时,只需识别你的日期中年、月、日出现的顺序,然后按相同顺序排列 "y"、"m" 和 "d"。 即可得到能解析该日期的 lubridate 函数名称。 例如:
ymd("2017-01-31")
#> [1] "2017-01-31"
mdy("January 31st, 2017")
#> [1] "2017-01-31"
dmy("31-Jan-2017")
#> [1] "2017-01-31"ymd() 等创建 data。 要创建 date-time,请在解析函数的名称中添加下划线和一个或多个 "h","m" 和 "s":
ymd_hms("2017-01-31 20:11:59")
#> [1] "2017-01-31 20:11:59 UTC"
mdy_hm("01/31/2017 08:01")
#> [1] "2017-01-31 08:01:00 UTC"你也可以通过提供时区来强制从 date 创建 date-time:
ymd("2017-01-31", tz = "UTC")
#> [1] "2017-01-31 UTC"这里我使用了 UTC 时区,你可能也知道它被称为 GMT(格林威治标准时间),即经度 0° 的时间。该时区不采用夏令时,这使得计算更为简便。
17.2.3 从各个组件
有时,你会遇到 date-time 的各个组成部分分散在多个列中,而不是单个字符串。flights 数据集中的情况正是如此:
flights |>
select(year, month, day, hour, minute)
#> # A tibble: 336,776 × 5
#> year month day hour minute
#> <int> <int> <int> <dbl> <dbl>
#> 1 2013 1 1 5 15
#> 2 2013 1 1 5 29
#> 3 2013 1 1 5 40
#> 4 2013 1 1 5 45
#> 5 2013 1 1 6 0
#> 6 2013 1 1 5 58
#> # ℹ 336,770 more rows要从这类输入创建 date/time,请对 dates 使用 make_date(),对 date-times 使用 make_datetime():
flights |>
select(year, month, day, hour, minute) |>
mutate(departure = make_datetime(year, month, day, hour, minute))
#> # A tibble: 336,776 × 6
#> year month day hour minute departure
#> <int> <int> <int> <dbl> <dbl> <dttm>
#> 1 2013 1 1 5 15 2013-01-01 05:15:00
#> 2 2013 1 1 5 29 2013-01-01 05:29:00
#> 3 2013 1 1 5 40 2013-01-01 05:40:00
#> 4 2013 1 1 5 45 2013-01-01 05:45:00
#> 5 2013 1 1 6 0 2013-01-01 06:00:00
#> 6 2013 1 1 5 58 2013-01-01 05:58:00
#> # ℹ 336,770 more rows让我们对 flights 中的四个时间列进行同样的处理。 时间的表示格式有些特殊,因此我们使用模运算来提取小时和分钟部分。 创建 date-time 变量后,我们将重点关注本章后续部分要探索的变量。
make_datetime_100 <- function(year, month, day, time) {
make_datetime(year, month, day, time %/% 100, time %% 100)
}
flights_dt <- flights |>
filter(!is.na(dep_time), !is.na(arr_time)) |>
mutate(
dep_time = make_datetime_100(year, month, day, dep_time),
arr_time = make_datetime_100(year, month, day, arr_time),
sched_dep_time = make_datetime_100(year, month, day, sched_dep_time),
sched_arr_time = make_datetime_100(year, month, day, sched_arr_time)
) |>
select(origin, dest, ends_with("delay"), ends_with("time"))
flights_dt
#> # A tibble: 328,063 × 9
#> origin dest dep_delay arr_delay dep_time sched_dep_time
#> <chr> <chr> <dbl> <dbl> <dttm> <dttm>
#> 1 EWR IAH 2 11 2013-01-01 05:17:00 2013-01-01 05:15:00
#> 2 LGA IAH 4 20 2013-01-01 05:33:00 2013-01-01 05:29:00
#> 3 JFK MIA 2 33 2013-01-01 05:42:00 2013-01-01 05:40:00
#> 4 JFK BQN -1 -18 2013-01-01 05:44:00 2013-01-01 05:45:00
#> 5 LGA ATL -6 -25 2013-01-01 05:54:00 2013-01-01 06:00:00
#> 6 EWR ORD -4 12 2013-01-01 05:54:00 2013-01-01 05:58:00
#> # ℹ 328,057 more rows
#> # ℹ 3 more variables: arr_time <dttm>, sched_arr_time <dttm>, ...利用这些数据,我们可以可视化一年中起飞时间的分布情况:
flights_dt |>
ggplot(aes(x = dep_time)) +
geom_freqpoly(binwidth = 86400) # 86400 seconds = 1 day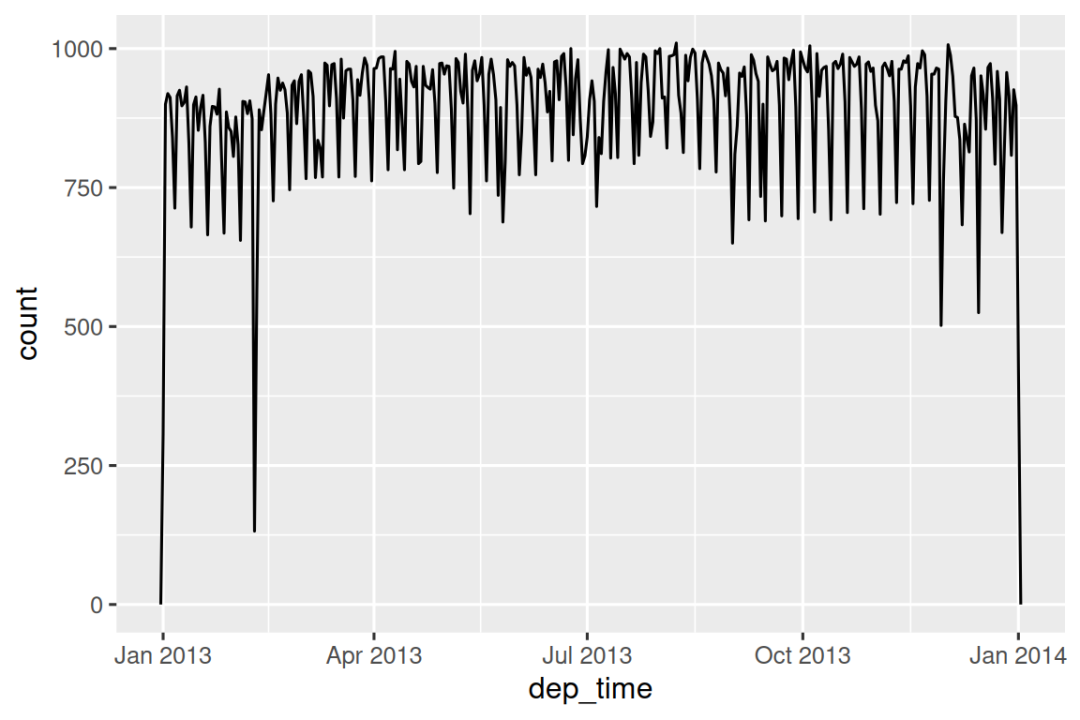
或者在一天之内:
flights_dt |>
filter(dep_time < ymd(20130102)) |>
ggplot(aes(x = dep_time)) +
geom_freqpoly(binwidth = 600) # 600 s = 10 minutes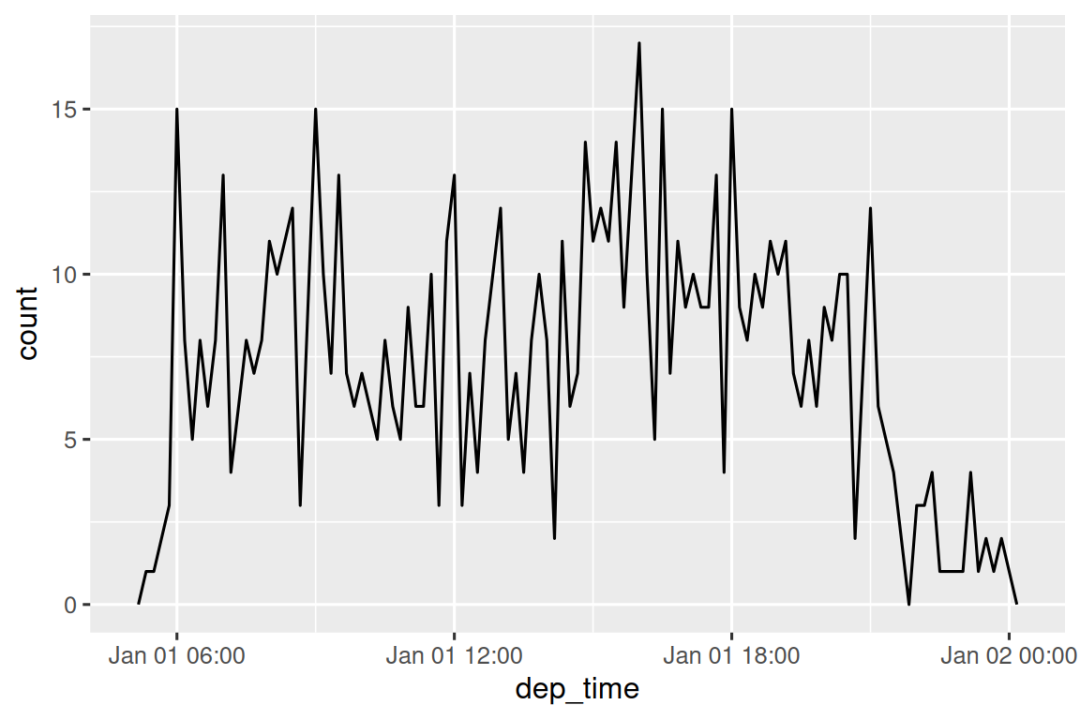
请注意,当您在数字上下文中(如直方图中)使用 date-times 时,1 表示 1 秒,因此 binwidth 为 86400 表示一天。 对于 dates,1 表示 1 天。
17.2.4 从其他类型
你可能需要在 date-time 和 date 之间进行转换。 这可以通过 as_datetime() 和 as_date() 函数来实现:
as_datetime(today())
#> [1] "2025-12-23 UTC"
as_date(now())
#> [1] "2025-12-23"有时你会遇到以数字偏移量形式表示的 date/times,其基准是 "Unix Epoch",1970-01-01。 如果偏移量以秒为单位,请使用 as_datetime();如果以天为单位,则使用 as_date()。
as_datetime(60 * 60 * 10)
#> [1] "1970-01-01 10:00:00 UTC"
as_date(365 * 10 + 2)
#> [1] "1980-01-01"17.2.5 练习
-
如果解析包含无效日期的字符串会发生什么?
ymd(c("2010-10-10", "bananas")) -
today()函数中的tzone参数有什么作用? 为什么它很重要? -
针对以下每个日期时间,请分别说明如何使用 readr 的列规范解析以及 lubridate 函数进行解析。
d1 <- "January 1, 2010" d2 <- "2015-Mar-07" d3 <- "06-Jun-2017" d4 <- c("August 19 (2015)", "July 1 (2015)") d5 <- "12/30/14" # Dec 30, 2014 t1 <- "1705" t2 <- "11:15:10.12 PM"
-
如果能被 4 整除,那就是闰年,除非它能被 100 整除,除非它能被 400 整除。换句话说,在每一组 400 年里,有 97 个闰年。
-
你可能会好奇 UTC 代表什么。它是英文 "Coordinated Universal Time" 与法文 "Temps Universel Coordonné" 之间的折中简称。
-
无需猜测是哪个国家提出了这个经度系统。
--------------- 未完待续 ---------------
本期翻译贡献:
@TigerZ生信宝库