Mixture-of-Agents Enhances Large Language Model Capabilities
混合代理增强大语言模型能力
信息
- 作者: Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, James Zou
- 单位: Together AI
- 日期: 2024年6月
1. 概述
1.1. 背景
近年来,大语言模型(LLMs)的性能提升主要依赖两个路径:一是模型规模的持续扩大,二是高质量数据与指令微调。然而,这两条路径都面临显著的边际成本递增问题:更大的模型意味着更高的训练与部署成本,而单一模型在不同任务维度上的能力往往并不均衡。作者从一个经验性但被忽视的现象出发提出核心问题:当多个能力互补的 LLM 同时可用时,是否可以通过结构化协作,而非进一步扩模,来系统性提升输出质量?
论文首先在 AlpacaEval 2.0 上观察到一个关键经验现象:一个模型在"阅读并参考其他模型给出的答案"后,往往能够生成质量更高的回答;更重要的是,这种提升并不要求参考答案来自更强的模型,即便来自性能较弱的模型也能产生正向增益 。作者将这一现象概括为 collaborativeness(可协作性),并通过多模型互相参考的实验结果加以验证(见图 1)。
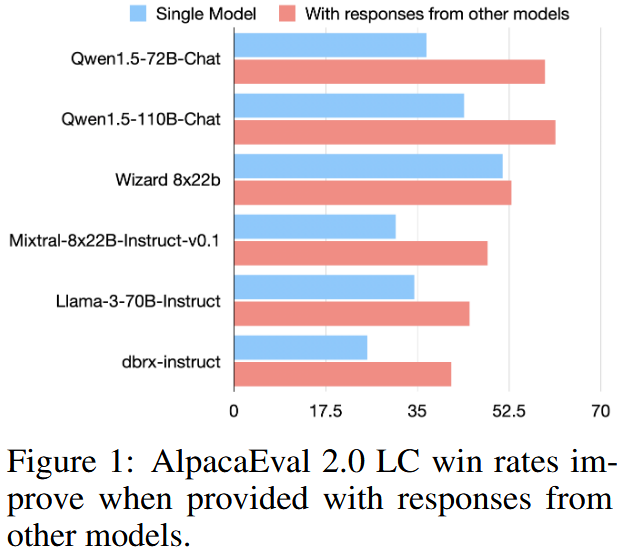
这一观察直接挑战了"只需选择最强单模型"的常见隐含假设,也为后续方法设计奠定了经验基础:模型之间的交互本身是一种可被系统利用的能力来源。
1.2. 目标 & 贡献
在上述动机下,论文的研究目标并非提出一个新的基础模型,而是回答一个更偏系统与方法论的问题:如何在不进行任何模型训练或微调的前提下,最大化多个现有 LLM 的集体能力?
围绕这一目标,论文的主要贡献可以概括为三点:
-
提出了一个无需微调、只靠提示词和多次生成即可运行的 Mixture-of-Agents(MoA) 框架:把多个 LLM 当作"智能体(agents)"进行分层协作,通过迭代,综合提升最终输出质量。
-
把"collaborativeness"作为一个可被利用的普遍现象提出,并进一步把多模型协作中的角色分解为 proposer(提案者) 与 aggregator(聚合者),用实验说明不同模型在这两种角色上可能呈现明显专长差异。
-
在 AlpacaEval 2.0、MT-Bench 与 FLASK 等基准上做了系统评测,给出"纯开源模型 MoA"也能超过当时的 GPT-4 Omni 的结果,并报告了不同配置(MoA、MoA-Lite、MoA w/ GPT-4o)的性能与代价权衡。
2. 研究方法 -- Mixture-of-Agents(MoA)框架
2.1. proposer 与 aggregator
MoA 的方法设计建立在一个明确的功能分工假设之上:
- Proposer(提案者) 的任务是为同一输入问题生成具有互补性的候选答案,它们不要求本身最优,但应提供多角度信息、不同推理路径或补充事实;
- Aggregator(聚合者) 的任务不是选择其中"最好的一条",而是在阅读多条候选答案后进行批判性综合,生成一个新的、更优的答案。
这一分工的核心思想是:协作收益来自"多样性供给 + 强综合能力"的组合,而非所有参与者都必须同样强。
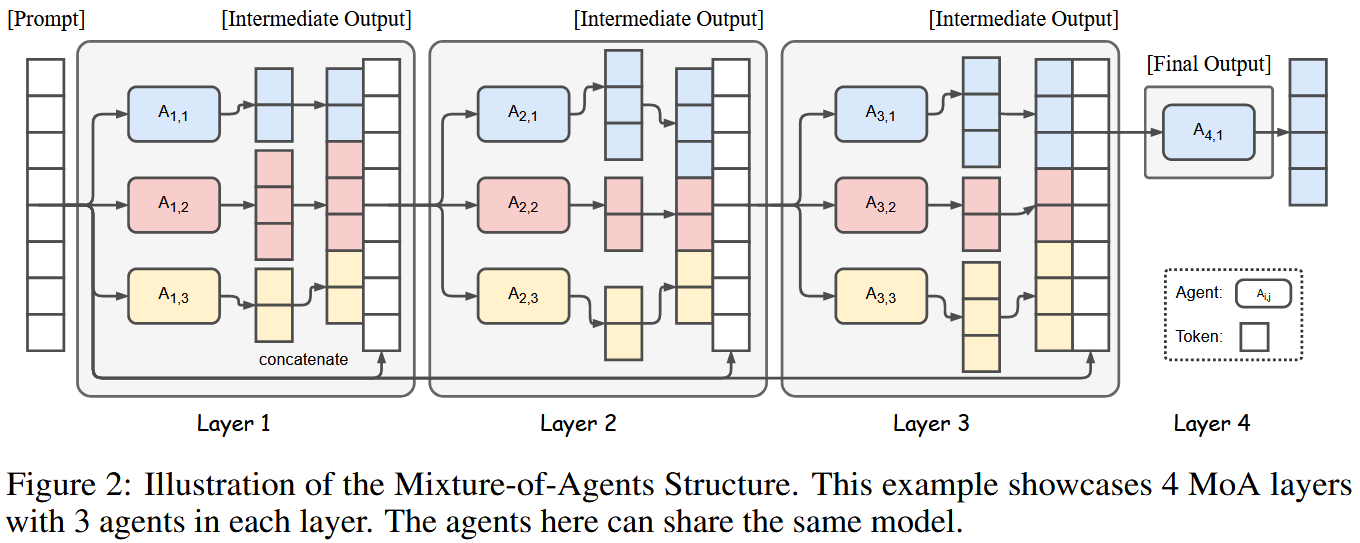
2.2. MoA分层结构与形式化定义
MoA 采用一个具有 层(layers) 与 宽度(agents per layer) 的分层结构。设系统一共有 l l l 层,每一层包含 n n n 个 agent,记为 A i , 1 , ... , A i , n A_{i,1},\dots,A_{i,n} Ai,1,...,Ai,n。 每个 agent 对应一次对某个 LLM 的调用,同一模型可以在不同层或同一层内重复使用。
MoA 的计算流程可形式化为递推关系: y i = ⨁ j = 1 n A i , j ( x i ) + x 1 , x i + 1 = y i y_i = \bigoplus_{j=1}^{n} A_{i,j}(x_i) + x_1,\quad x_{i+1} = y_i yi=⨁j=1nAi,j(xi)+x1,xi+1=yi 其中:
- x 1 x_1 x1 为原始用户输入;
- A i , j ( x i ) A_{i,j}(x_i) Ai,j(xi) 为第 i i i 层第 j j j 个 agent 对当前输入的回答;
- ⊕ \oplus ⊕ 表示通过一个固定的 Aggregate-and-Synthesize 提示词对多条回答进行综合;
- 输出 y i y_i yi 作为下一层的输入。
作者还提出一个直觉但很关键的进一步增强思路:既然"一个 aggregator 看多份 proposer 输出能提升",那就让"多个 aggregator 先分别综合一次",再把这些"已综合的答案"继续交给下一层 aggregator 再综合,形成迭代式的综合与精炼。
即从第二层开始,每个 agent 的输入都包含:原始问题 + 前一层生成的多条回答 。因此 MoA 的后续层本质上是在执行"阅读---理解---重写"任务,而非从零生成答案。结构上的信息流动见图 2。
最终系统仅输出最后一层某个 agent(通常是 aggregator)的结果作为最终答案,而不对中间结果进行额外选择或加权。
2.3. 聚合提示词

表 1 给出了 MoA 中用于综合的标准化提示词模板。该提示词明确要求 aggregator:
-
对输入答案进行批判性评估;
-
识别潜在错误、偏见或不完整之处;
-
生成一个更准确、更全面、更有结构的新答案,而不是复制或拼接原文。
2.4. 与 Mixture-of-Experts(MoE)的关系
作者将 MoA 类比为一种"模型级别"的 MoE。传统 MoE 在网络内部通过 gating network 对 expert 加权,而 MoA 则将 expert 提升为完整模型,并用 LLM 对提示词的理解隐式完成"门控与综合"。其优势在于无需访问模型内部结构、无需训练,可直接组合任意现有模型。
3. 实验
3.1. 实验设置
评估基准
- AlpacaEval 2.0:开放式指令,无标准答案。AlpacaEval 使用长度控制胜率(尽量消除"长度本身带来的偏好增益")以 GPT-4-1106-preview 为评估参考;
- MT-Bench:多轮对话,无标准答案,由 GPT-4 打分;
- FLASK:评估模型对开放式指令生成的完整自然语言回答,提供 12 个细粒度能力维度评分
模型:作者的默认 MoA(开源版本)使用 6 个开源模型作为 proposer 组合:Qwen1.5-110B-Chat、Qwen1.5-72B-Chat、WizardLM-8x22B、LLaMA-3-70B-Instruct、Mixtral-8x22B-v0.1、dbrx-instruct,并构建 3 层 MoA,每层使用同一组模型;最后一层的 aggregator 默认用 Qwen1.5-110B-Chat。
另外还有两种关键变体:MoA w/ GPT-4o(把最终 aggregator 换成 GPT-4o 追求更高质量)以及 MoA-Lite(2 层、用 Qwen1.5-72B-Chat 做最终 aggregator,强调性价比)。
3.2. 主要结果
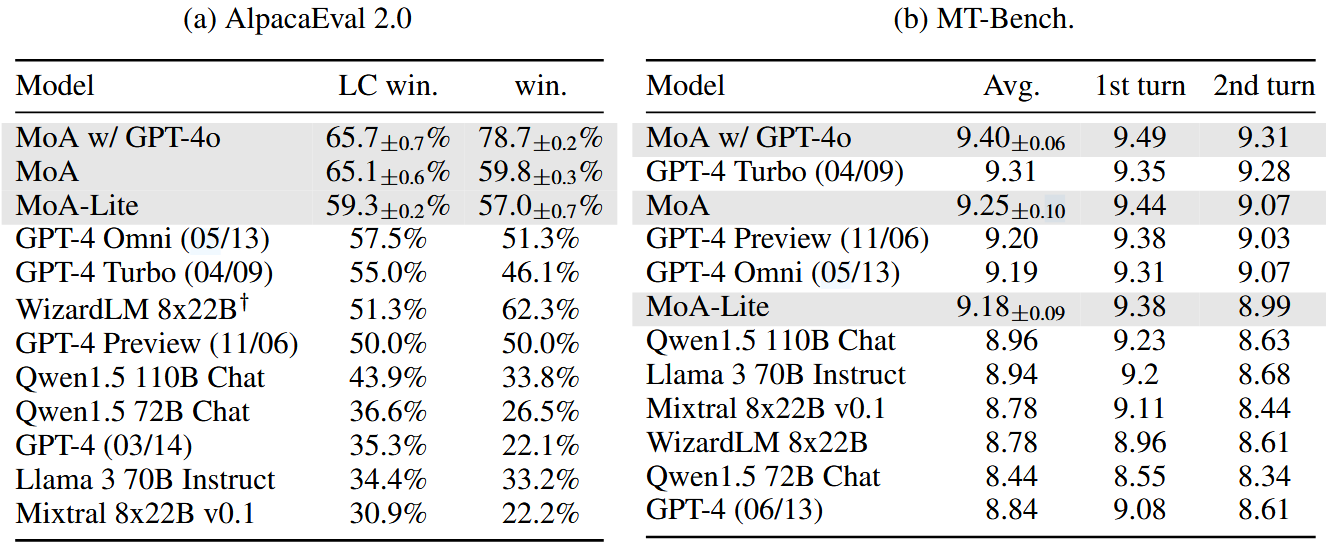
- AlpacaEval 2.0 :表 2(a) 给出 AlpacaEval 2.0 的结果:MoA(纯开源)LC win rate 达到 65.1%,而 GPT-4 Omni(05/13)为 57.5%;MoA w/ GPT-4o 为 65.7%,MoA-Lite 也有 59.3%。论文还强调 MoA 相比 GPT-4o(此处以表中 GPT-4 Omni 57.5% 对照)具有显著的绝对提升,并且即便减少层数做成 Lite,也仍能在成本更低的条件下取得超过对照模型的胜率。
- MT-Bench:表2(b),MoA w/ GPT-4o 平均 9.40,MoA 为 9.25,MoA-Lite 为 9.18,与 GPT-4 Turbo、GPT-4 Preview、GPT-4 Omni 等强模型非常接近。作者解释 MT-Bench 已经"天花板很高",单模型能到 9+,因此增益看起来更小,但 MoA 仍能取得榜首或接近榜首的表现。
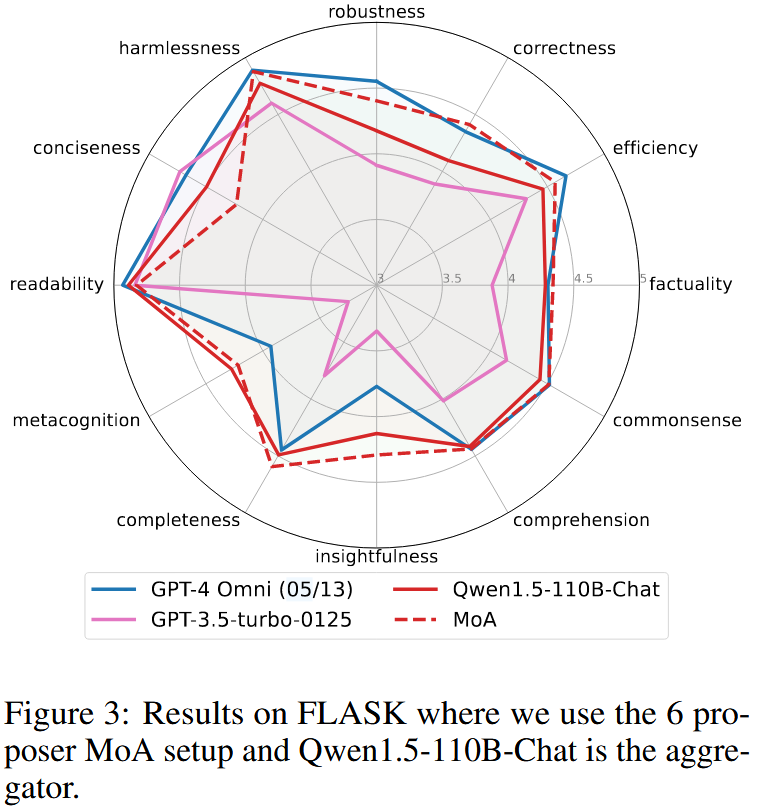
- FLASK:图3 显示 MoA 在 factuality、robustness、insightfulness 等维度显著提升,但在 conciseness 上略有劣势(更啰嗦)。
3.3. 消融 -- 是什么让MoA效果好?
论文用两组实验把 MoA 与"LLM ranker(只挑不写)"区分开来。
第一,作者构造一个 LLM-ranker 基线:让 aggregator 只在 proposer 的候选答案中挑选"最好的一份",而不是生成新的综合回答;结果在图 4 中显示 MoA 明显优于 ranker,这支持了一个重要结论:MoA 的提升并非来自"更会选",而是来自"更会综合重写"。
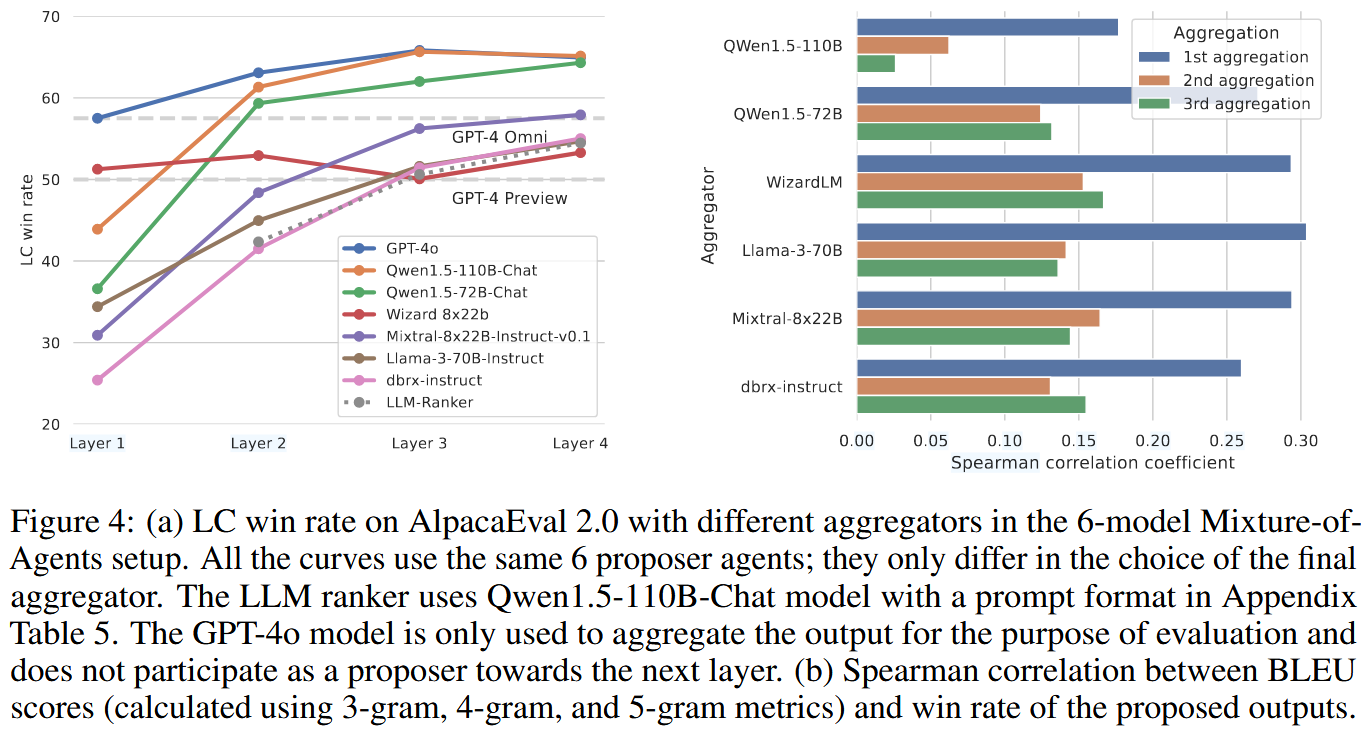
第二,作者分析 aggregator 输出与 proposer 输出的相似性:用 BLEU 等文本相似度衡量 aggregator 更接近哪一份 proposer 输出,再计算"相似度排序"和"偏好得分排序"之间的 Spearman 相关。图 4(b) 显示这种相关性为正,意味着 aggregator 倾向于吸收更高质量 proposer 的内容;附录还用 TF-IDF、Levenshtein 做了类似验证(见图 6)。从另一个角度解释aggregator 的"综合"在做什么:不是盲目平均,而是更像"提取强要点并重新组织"。
3.3.1. 宽度(n)与多样性的作用
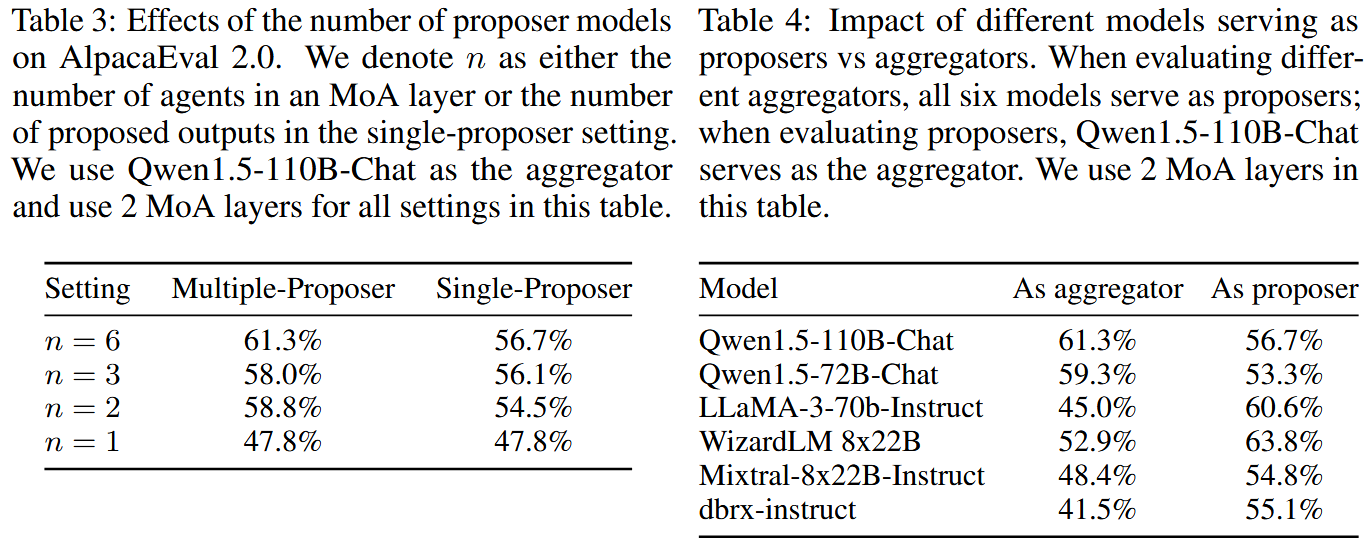
表 3 专门研究 proposer 数量 n 的影响,同时对比"多模型 proposer(multiple-proposer)"与"同模型多次采样(single-proposer)"。当 n 从 1 增加到 6,multiple-proposer 的 LC win rate 从 47.8% 提升到 61.3%;并且在同样 n 下,多模型 proposer 一直优于单模型多次采样(例如 n=6 时 61.3% vs 56.7%)。 -- 增加 proposer 数量(宽度)可显著提升性能;使用不同模型作为 proposer 比同一模型多次采样更有效。
表 4 则揭示"模型角色专长":同一个模型做 aggregator 与做 proposer 的效果可能完全不同。例如 LLaMA-3-70B-Instruct 作为 proposer 得分 60.6%,但作为 aggregator 只有 45.0%;WizardLM 8x22B 作为 proposer 63.8%,作为 aggregator 52.9%。
3.4. 案例
aggregator的综合到底是怎么做的:
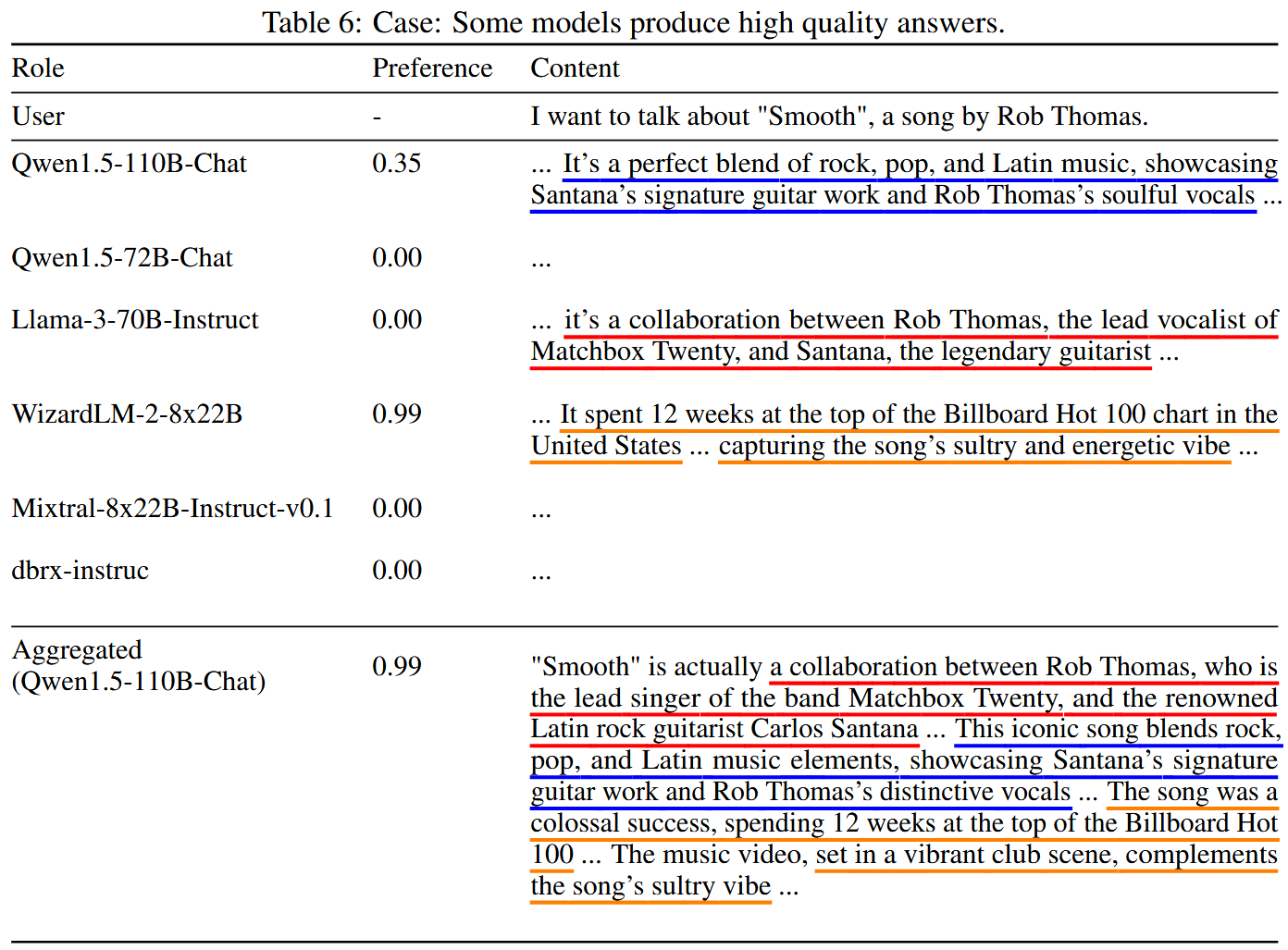
表 6 展示当 proposer 中存在高质量答案时,aggregator 会在保留自身强项的同时吸纳其他模型的关键点,最终偏好分数可达到与最佳 proposer 相同的 0.99

表 7 展示当所有 proposer 都不够好时,aggregator 仍能从多个不完美回答里抽取强点,使最终偏好分数提升到 0.33
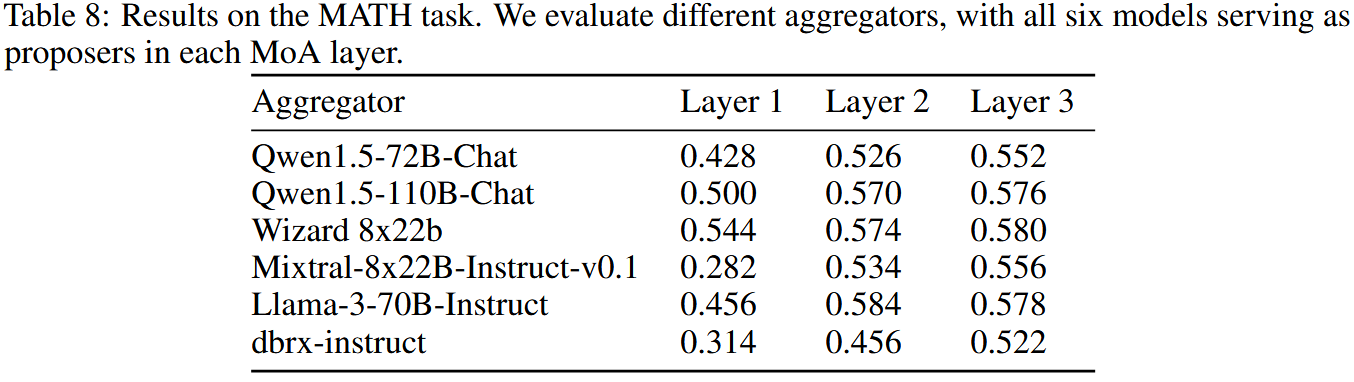
论文还在 MATH 数据集上验证 MoA 对推理类任务同样适用,并给出不同 aggregator 在 1--3 层下准确率提升的表格结果(见表 8)
4. 结论、限制与未来方向
结论:MoA 通过"多模型提案 + 分层综合"的方式,能够系统性提升最终输出质量,并在多个主流基准上取得显著增益,验证了"整合多模型多样视角能优于单模型"的核心假设;此外作者认为 MoA 架构本身仍有大量可优化空间,特别是如何系统化地搜索最优的层数、宽度与模型组合。
限制:作者明确指出 MoA 的一个结构性代价:由于需要先完成多轮生成与聚合,系统在到达最后一层之前无法输出第一个 token,从而导致 Time To First Token(TTFT) 可能显著变长,影响交互体验。
他们给出的缓解思路包括:限制层数(因为第一次聚合往往带来最大质量提升),以及探索 chunk-wise aggregation(分块聚合)------不必等整段回答都生成完再聚合,而是按片段逐步聚合,以在尽量保持质量的同时降低 TTFT。
未来方向:
-
"架构搜索问题":把 MoA 的层数、每层 agent 数、模型复用方式、以及聚合提示词模板视为设计变量,进行系统优化
-
"协作机制解释与可控性":既然不同模型在 proposer/aggregator 角色上有明显专长,就可以进一步研究如何自动识别并路由角色分配、如何度量多样性贡献、以及如何避免聚合时的错误放大。
-
"面向部署的实时性改造":围绕 TTFT、并行调度与分块聚合做工程与算法共同设计,使 MoA 不只是在离线评测里强,也能在真实对话系统中可用。