1. Kafka为什么这么快?
顺序I/O、索引、批量读写和文件压缩、零拷贝
1.1 顺序I/O
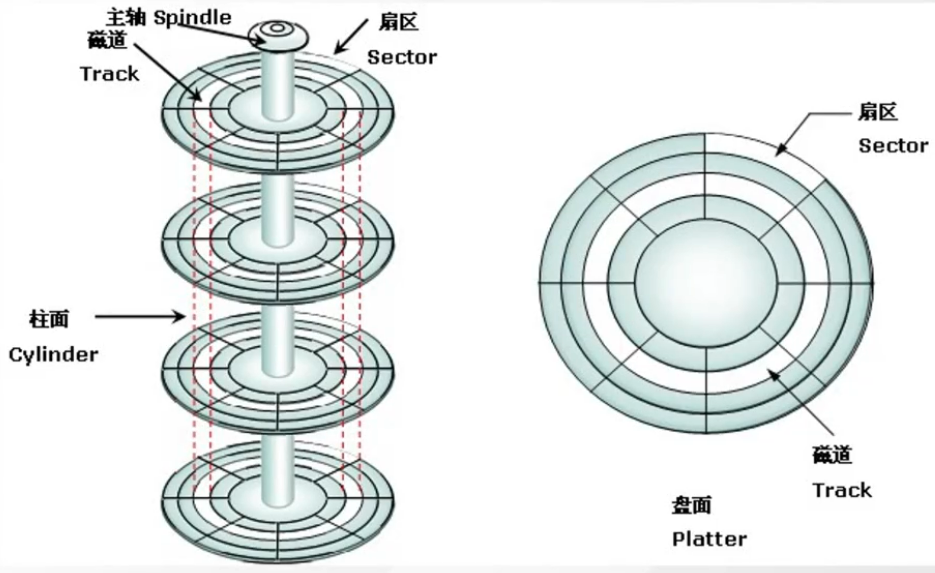
磁盘的构造如图。磁盘的盘片不停地旋转,磁头会在磁盘表面画出一个圆形轨迹,叫磁道。从内到外半径不同有很多磁道。然后又用半径线,把磁道分割成了扇区(两根射线之内的扇区组成扇面)。如果要读写数据, 必须找到数据对应的扇区,这个过程就叫寻址。
- **随机I/O:**读写的多条数据在磁盘上是分散的,寻址会很耗时。
- **顺序I/O:**读写的数据在磁盘上是集中的,不需要重复寻址的过程。
Kafka的message是不断追加到本地磁盘文件末尾的,而不是随机的写入 ,这使得 Kafka写入吞吐量得到了显著提升。
顺序IO到底有多快呢?下图显示,在一定条件下测试,磁盘的顺序读写可以达到53.2M每秒,比内存的随机读写还要快。

1.2 索引
在写入日志的时候,会建立关于Offset和时间的稀疏索引,提升了查找效率。
1.3 批量读写
Kafka无论是生产者发送消息还是消费者消费消息,都是批量操作的,大大提高读写性能。
1.4 零拷贝
操作系统虚拟内存的内核空间和用户空间:操作系统的虚拟内存分成了两块,一部分是内核空间,一部分是用户空间。这样就可以避免用户进程直接操作内核,保证内核安全。
- 内核空间:进程在内核空间可以执行任意命令,调用系统的一切资源
- 用户空间:必须要通过---些系统接口才能向内核发出指令
如果用户要从磁盘读取数据(比如kafka消费消息),必须先把数据从磁盘拷贝到内核缓冲区 ,然后在从内核缓冲区到用户缓冲区 ,最后才能返回给用户。
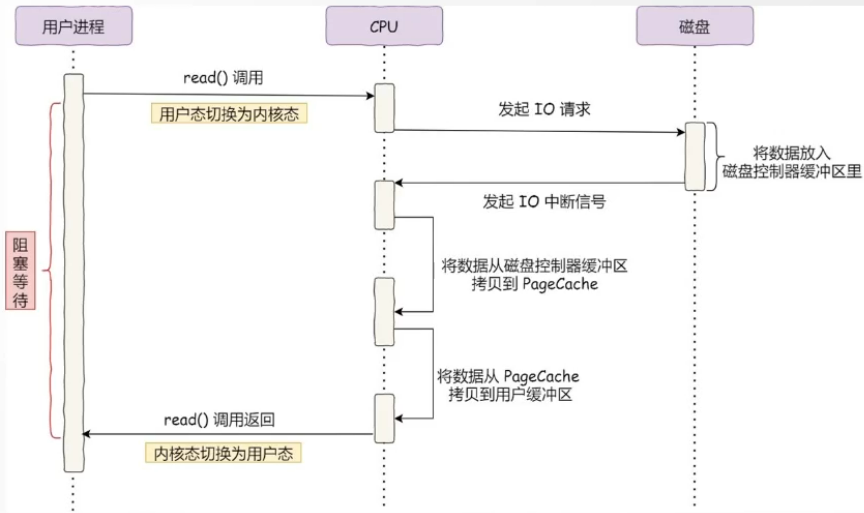
DMA拷贝 :没有DMA技术的时候,拷贝数据的事情需要CPU亲自去做, 这个时候它没法干其他的事情,如果传输的数据量大那就有问题了。DMA技术叫做直接内存访问(Direct Memory Access), 其实可以理解为CPU给自己找了一个小弟帮它做数据搬运的事情。在进行I/O设备和内存的数据传输的时候,数据搬运的工作全部交给DMA控制器,解放了 CPU的双手。
理解了这两个东西之后,我们来看下传统的I/O模型:
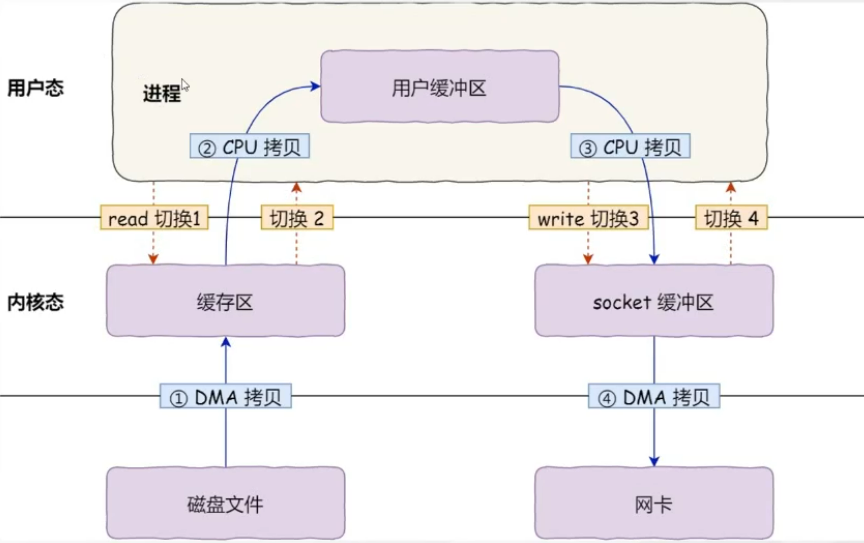
kafka要消费消息,要先把数据从磁盘拷贝到内核缓冲区,然后拷贝到用户缓冲区,再拷贝到socket缓冲区,再拷贝到网卡设备。这里面发生了 4次用户态和内核态的切换和4次数据拷贝,2次系统函数的调用(read、write),这个过程是非常耗费时间的。怎么优化呢?
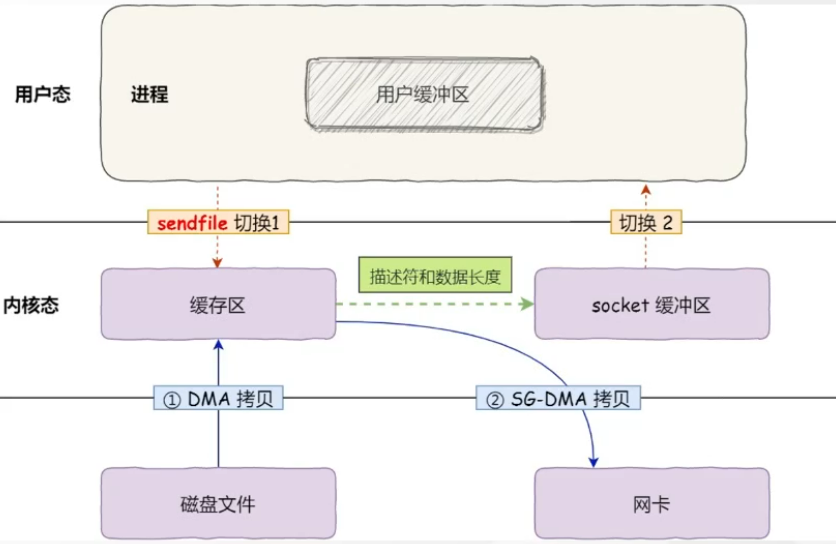
在Linux操作系统里面提供了一个sendfile函数(并不是所有操作系统都支持sendfile),可以实现"零拷贝"。这个时候就不需要经过用户缓冲区了,直接把数据拷贝到网卡(这里画的是支持SG-DMA拷贝的情况)。因为这个只有DMA拷贝,没有CPU拷贝,所以叫做"零拷贝"。零拷贝至少可以提高一倍的性能。
2. Kafka如何保证消息不丢失?
(1)Producer设置ACK级别,设置为-1,保证最高级别的可靠性,但性能会下降。
(2)Producer设置retries参数(重试次数)。
(3)Broker集群,有N个Broker,至少设置N个副本
java
//表示分区副本的个数,replication.factor >1 当leader 副本挂了,
//follower副本会被选举为leader继续提供服务
replication.factor
//表示 ISR 最少的副本数量,通常设置 min.insync.replicas >1,
//这样才有可用的follower副本执行替换,保证消息不丢失
min.insync.replicas
//是否可以把非 ISR 集合中的副本选举为 leader 副本
unclean.leader.election.enable = false (4)Consumer把自动提交改成手动提交
java
enable.auto.commit = false(5)Producer发送消息时使用 producer.send(msg, callback) 方法,该方法支持回调函数,可以在消息发送失败后进行重试
3. Kafka如何避免重复消费?
Producer开启事务。
事务协调者(Transaction Coordinator)是Kafka Broker内置的一个组件。它负责管理生产者和消费者之间的事务性操作,确保消息生产和消费的原子性和一致性。
事务协调者的主要职责包括:
- 事务状态管理:跟踪每个事务的状态(例如,开启、准备提交、已提交、已中止等),并确保这些状态在Broker之间保持一致。
- 幂等性和恰好一次语义:通过与生产者协作,确保每条消息只能被写入一次,即使在网络故障或重试的情况下也不会重复写入。
- 跨分区事务支持:允许生产者在一个事务中向多个主题和分区发送消息,并保证这些操作要么全部成功,要么全部失败。
- 消费偏移量管理:在事务性消费场景下,协调者还负责管理消费者的偏移量提交,确保只有当所有相关操作都成功完成时才会更新偏移量。
Producer发送消息前,启用事务配置,设置参数 enable.idempotence = true 开启幂等性,设置唯一事务ID(可为UUID)。
Producer初始化事务,开启事务,执行业务逻辑并发送消息,提交事务。
在开启事务到提交事务操作之间进行错误捕获,发生异常后事务终止。