温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目背景
随着信息技术的快速发展,刑事案件数据量呈爆炸式增长,传统的案件分类方式主要依赖人工,这不仅效率低下,且容易受主观因素影响导致分类不一致。特别是在电信诈骗等新型犯罪领域,案情复杂多变,对分类的准确性和时效性提出了更高要求。
本项目旨在开发一个基于深度学习的刑事案件智能分类系统,利用自然语言处理(NLP)、机器学习(Machine Learning)和深度学习(Deep Learning)技术,对案情描述文本进行自动分析和分类。该系统能够辅助公安机关快速识别案件类型(如刷单返利类、虚假网络投资理财类、冒充公检法类等),提高办案效率,为打击和预防犯罪提供智能化支持。
2. 技术架构
本系统采用 B/S(Browser/Server)架构,前后端分离的设计思想,具体技术栈如下:
前端(Frontend)
- HTML5/CSS3/JavaScript: 构建页面的基础结构和样式。
- Bootstrap 5.1.3: 提供响应式布局和现代化的 UI 组件,确保系统在不同设备上的良好显示。
- jQuery 3.6.0: 简化 DOM 操作和 AJAX 异步请求,实现前后端的数据交互。
- ECharts 5.4.0: 用于数据可视化展示,生成案件类型分布图、模型性能对比图等。
后端(Backend)
- Python Flask 2.3.3: 轻量级 Web 框架,提供 RESTful API 接口,处理用户请求和业务逻辑。
- Werkzeug 2.3.7: WSGI 工具库,处理 HTTP 请求。
数据处理与模型(Data & AI)
- 数据预处理: Pandas, NumPy, Jieba(中文分词)。
- 特征工程: Scikit-learn (TF-IDF Vectorizer, Label Encoder)。
- 机器学习模型: XGBoost 1.7.6。
- 深度学习框架: TensorFlow 2.13.0 (Keras), scikit-learn。
- 模型文件: best_ml_model.pkl (XGBoost), gru_model.h5 (GRU), lstm_model.h5 (LSTM)。
数据库(Database)
- SQLite: 轻量级关系型数据库,无需独立服务器,适合本系统的部署需求。
3. 数据库设计
系统数据库
criminal_case.db 包含三张主要数据表,分别用于存储用户信息、预测记录和统计分析数据。
3.1 用户表 (users)
存储注册用户的基本信息。
| 字段名 | 类型 | 说明 | 约束 |
|---|---|---|---|
| id | INTEGER | 用户ID | PRIMARY KEY, AUTOINCREMENT |
| username | TEXT | 用户名 | UNIQUE, NOT NULL |
| password | TEXT | 加密后的密码 | NOT NULL |
| TEXT | 电子邮箱 | ||
| created_at | TIMESTAMP | 注册时间 | DEFAULT CURRENT_TIMESTAMP |
| last_login | TIMESTAMP | 最后登录时间 |
3.2 预测记录表 (predictions)
存储用户提交的案情描述及系统的预测结果。
| 字段名 | 类型 | 说明 | 约束 |
|---|---|---|---|
| id | INTEGER | 记录ID | PRIMARY KEY, AUTOINCREMENT |
| user_id | INTEGER | 关联用户ID | FOREIGN KEY (users.id) |
| case_description | TEXT | 案情描述文本 | NOT NULL |
| predicted_category | TEXT | 预测的案件类别 | NOT NULL |
| model_used | TEXT | 使用的模型 | NOT NULL |
| confidence | REAL | 置信度/概率 | |
| created_at | TIMESTAMP | 预测时间 | DEFAULT CURRENT_TIMESTAMP |
3.3 统计信息表 (statistics)
存储系统的全局统计数据,用于可视化展示。
| 字段名 | 类型 | 说明 | 约束 |
|---|---|---|---|
| id | INTEGER | 统计ID | PRIMARY KEY, AUTOINCREMENT |
| total_cases | INTEGER | 总案件数 | DEFAULT 0 |
| category_stats | TEXT | 各类案件统计(JSON) | |
| model_performance | TEXT | 模型性能数据(JSON) | |
| updated_at | TIMESTAMP | 更新时间 | DEFAULT CURRENT_TIMESTAMP |
4. 模型介绍与性能分析
本项目对比了传统机器学习模型和深度学习模型在刑事案件文本分类任务上的表现。
4.1 数据集与预处理
- 数据集: 包含约 82,210 条训练数据和 10,276 条测试数据。主要案件类型包括"刷单返利类"、"虚假网络投资理财类"、"冒充电商物流客服类"等 12 类。
- 预处理: 使用正则表达式处理文本,去除特殊符号,并使用 Jieba 进行中文分词,去除停用词。
- 特征提取 :
- TF-IDF: 用于 XGBoost 等传统模型,选取前 5000 个特征词。
- Tokenization & Padding: 用于深度学习模型,序列最大长度设为 200。
4.2 模型性能对比
| 模型 | 准确率 (Accuracy) | 训练时间(秒) | 备注 |
|---|---|---|---|
| GRU (深度学习) | 0.8711 | - | 最佳模型,在处理长文本依赖上表现优异,泛化能力强。 |
| XGBoost (机器学习) | 0.8670 | ~672s | 性能接近 GRU,训练效率较高,解释性较好。 |
| LSTM (深度学习) | 0.8568 | - | 略逊于 GRU,收敛速度稍慢。 |
| 逻辑回归 | 0.8593 | ~70s | 简单的基准模型,表现尚可。 |
| 随机森林 | 0.8564 | ~1082s | 训练时间较长,效果中等。 |
| 朴素贝叶斯 | 0.8220 | ~0.2s | 训练最快,但准确率最低,可作为Baseline。 |
4.3 详细分析 (以 XGBoost 为例)
XGBoost 在部分类别上表现极佳,而在部分样本较少或特征重叠的类别上仍有提升空间:
- 表现优异的类别 :
- "网黑案件": F1-score 0.95
- "刷单返利类": F1-score 0.94 (Recall 0.97)
- "贷款、代办信用卡类": F1-score 0.93
- 表现较弱的类别 :
- "网络婚恋、交友类": F1-score 0.48 (主要因为样本量较少且易与"虚假网络投资理财类"混淆)
系统最终集成了 XGBoost 、LSTM 和 GRU 三种高性能模型供用户选择,以适应不同的应用场景。
5. 系统实现与展示
以下展示了系统的核心功能页面。
5.1 注册与登录
用户可以通过注册页面创建账号,并使用账号登录系统。系统前端(jQuery)和后端(Flask)均会对数据进行校验。
注册页面:
登录页面:
5.2 系统首页
登录后进入系统首页,简洁直观地展示了系统的核心功能入口:案件预测、个人信息和数据可视化。
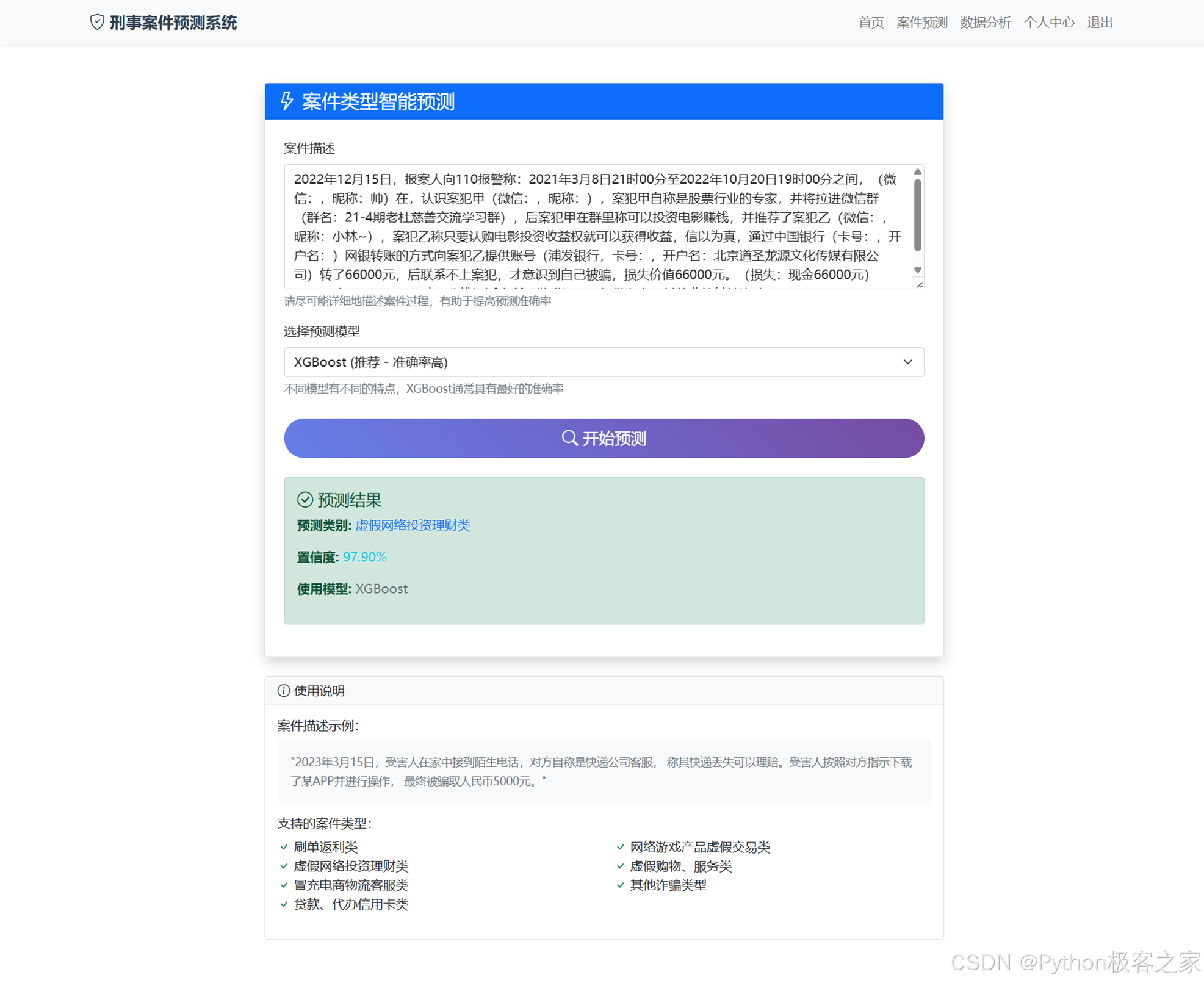
5.3 智能预测
这是系统的核心功能页面。用户输入一段案情描述(例如:"刷单被骗了5000元..."),可以自由选择预测模型(如 XGBoost),点击"开始预测"即可得到案件的具体分类结果及置信度。
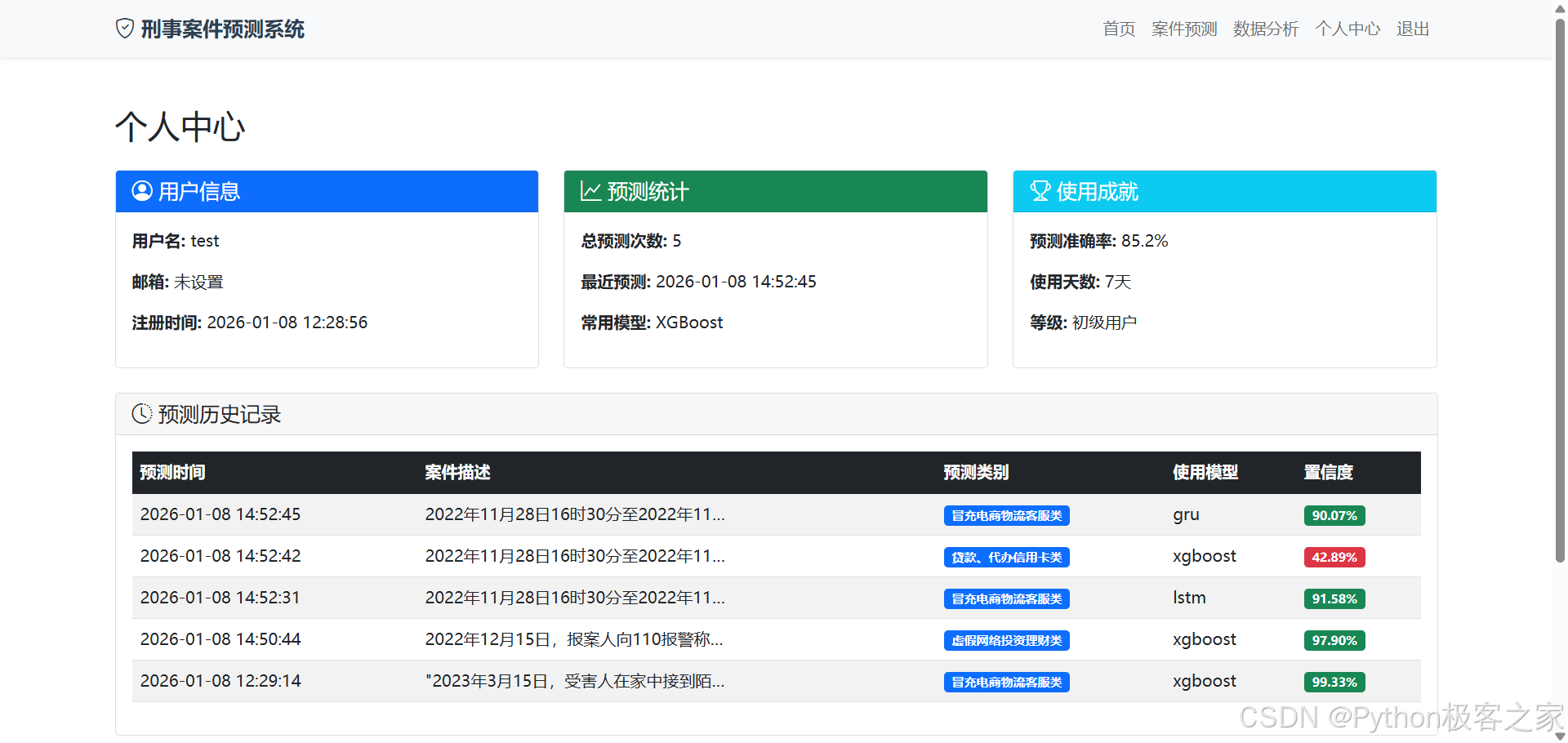
5.4 个人中心
用户可以在个人中心查看自己的历史预测记录,系统会记录每一次的输入案情和预测结果,方便回顾和管理。
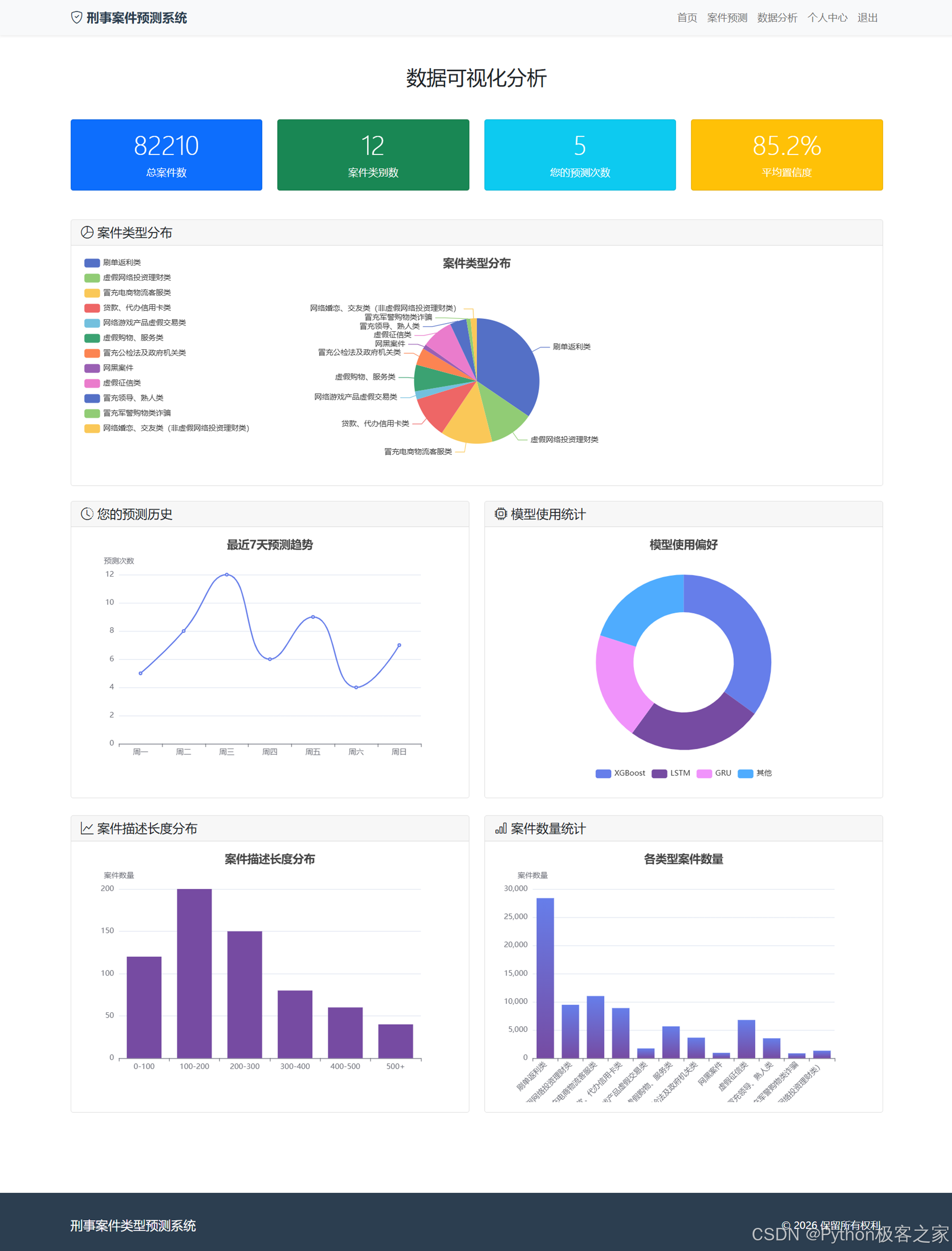
5.5 数据可视化
系统集成了 ECharts,对案件数据及其模型性能进行了可视化展示,帮助用户直观了解各类案件的分布情况以及不同模型的训练效果对比。
6. 总结与展望
本项目成功构建了一个端到端的刑事案件智能分类系统,实现了从数据清洗、特征提取、模型训练到 Web 应用部署的全流程。目前系统在 GRU 和 XGBoost 模型的支持下,总体分类准确率达到了 87% 左右,能够有效辅助办案人员快速识别案件类型。
未来改进方向:
- 数据平衡与增强: 针对"网络婚恋交友类"等样本较少的类别进行数据增强(如回译、EDA),以提高模型在长尾类别上的表现。
- 模型优化: 引入 BERT、RoBERTa 等预训练语言模型(PLM),利用其强大的语义理解能力进一步提升分类精度。
- 实时性优化: 优化深度学习模型的推理速度,支持更高并发的实时预测请求。
- 功能扩展: 增加案件要素提取(如涉案金额、嫌疑人特征等)功能,构建更全面的案件知识图谱。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取 认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
