目录
[一、Flannel 的核心基础(通信前的准备)](#一、Flannel 的核心基础(通信前的准备))
[二、Flannel 的三种核心通信模式](#二、Flannel 的三种核心通信模式)
[场景 1:同节点内 Pod 通信(无需 Flannel 隧道)](#场景 1:同节点内 Pod 通信(无需 Flannel 隧道))
[场景 2:跨节点 Pod 通信(Flannel 核心)](#场景 2:跨节点 Pod 通信(Flannel 核心))
[模式 1:VXLAN(默认,隧道模式)](#模式 1:VXLAN(默认,隧道模式))
[模式 2:host-gw(直连模式,性能更高)](#模式 2:host-gw(直连模式,性能更高))
[步骤详解(核心是「纯 UDP 封装」):](#步骤详解(核心是「纯 UDP 封装」):)
[三、Flannel 的优缺点](#三、Flannel 的优缺点)
[4.1 Calico 的核心工作模式](#4.1 Calico 的核心工作模式)
[1. 纯 BGP 模式(默认 / 推荐)](#1. 纯 BGP 模式(默认 / 推荐))
[2. IPIP/VXLAN 模式(Overlay 模式)](#2. IPIP/VXLAN 模式(Overlay 模式))
[4.2 Calico 跨节点 Pod 通信流程](#4.2 Calico 跨节点 Pod 通信流程)
[五、Calico 架构组件](#五、Calico 架构组件)
[六、Flannel vs Calico 总结](#六、Flannel vs Calico 总结)
[七、Kubernetes 操作管理概述](#七、Kubernetes 操作管理概述)
[2.1 基本原理](#2.1 基本原理)
[2.2 基础信息查看命令](#2.2 基础信息查看命令)
[2.3 基本资源查看命令](#2.3 基本资源查看命令)
[2.4 命名空间操作](#2.4 命名空间操作)
[2.5 创建 Deployment(副本控制器)](#2.5 创建 Deployment(副本控制器))
[2.6 登录容器与删除 Pod](#2.6 登录容器与删除 Pod)
[2.7 扩缩容与删除](#2.7 扩缩容与删除)
[1、创建阶段(kubectl create)](#1、创建阶段(kubectl create))
[2、发布阶段(kubectl expose)](#2、发布阶段(kubectl expose))
[3.更新阶段(kubectl set)](#3.更新阶段(kubectl set))
[4.回滚阶段(kubectl rollout)](#4.回滚阶段(kubectl rollout))
[5 删除阶段(kubectl delete)](#5 删除阶段(kubectl delete))
一、Flannel 的核心基础(通信前的准备)
在讲解通信流程前,先明确 Flannel 的核心配置和网络规划,这是通信的前提:
- 集群级 Pod 网段 :Flannel 会为整个 K8s 集群分配一个大的私有网段(默认
10.244.0.0/16),通过kube-flannel-cfgConfigMap 定义。 - Node 级子网分配 :Flannel 为每个 Node 分配一个独立的子网段(默认
/24,即 254 个 IP),例如:
- Node1(IP:192.168.1.101)→
10.244.1.0/24 - Node2(IP:192.168.1.102)→
10.244.2.0/24 - 该映射关系存储在 K8s 集群的 etcd 中,由每个 Node 上的
flanneld进程维护。
- 核心组件:
flanneld:每个 Node 上的守护进程(以 DaemonSet Pod 运行),负责从 etcd 获取网段映射、更新本地路由表、管理隧道设备。cni0:Node 上的网桥,连接该 Node 上的所有 Pod(类似 Docker 的 docker0),Pod 的虚拟网卡(veth pair)一端接入 cni0。flannel.1:VXLAN 模式下的虚拟隧道网卡,负责跨节点数据包的封装 / 解封装。
二、Flannel 的三种核心通信模式
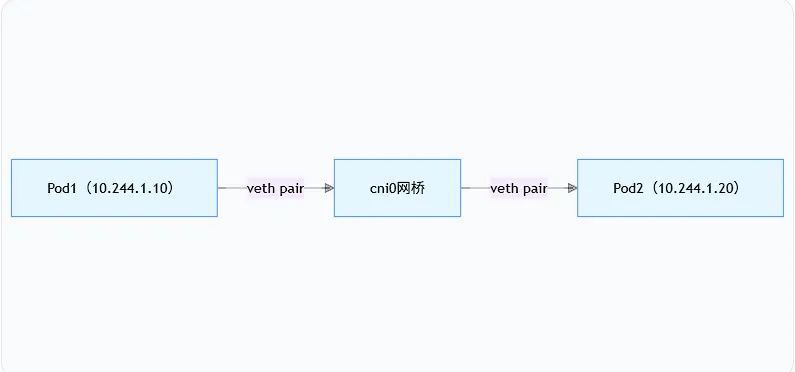
场景 1:同节点内 Pod 通信(无需 Flannel 隧道)
同 Node 上的 Pod 通信不经过 Flannel 隧道 ,仅靠cni0网桥即可完成,流程极简单:
1.Pod1 要访问 Pod2,先查询本地路由表,发现目标 IP(10.244.1.20)属于本机直连网段 (10.244.1.0/24),下一跳指向cni0网桥。
2.Pod1 通过虚拟网卡(veth)将数据包发送到cni0网桥。
3.cni0通过 ARP 解析 Pod2 的 MAC 地址,直接将数据包转发到 Pod2 的虚拟网卡。
场景 2:跨节点 Pod 通信(Flannel 核心)
以「Node1 的 Pod1(10.244.1.10)访问 Node2 的 Pod2(10.244.2.20)」为例,分两种模式讲解:
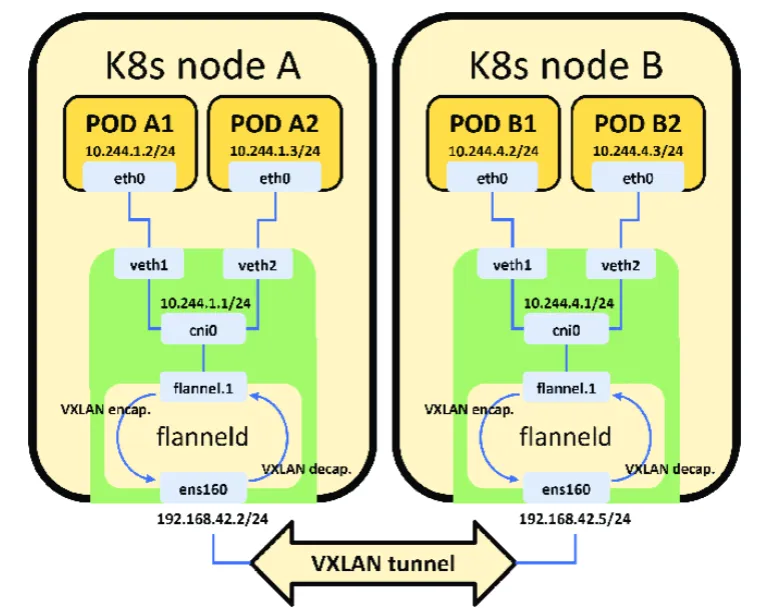
模式 1:VXLAN(默认,隧道模式)
VXLAN 是 Flannel 的默认模式,通过封装数据包为 VXLAN 隧道帧,实现跨节点通信(即使节点在不同子网),流程如下:
1.Pod1 发送数据包到cni0网桥,Node1 查询路由表(由 Flannel 自动维护),发现10.244.2.0/24的下一跳是flannel.1网卡。
2.数据包进入flannel.1后,flanneld进程对数据包做VXLAN 隧道封装:
- 内层:原始 Pod 通信的 IP 包(源 10.244.1.10,目的 10.244.2.20);
- 外层:Node 间通信的 IP 包(源 192.168.1.101,目的 192.168.1.102),并指定 VXLAN 端口(默认 8472)。
- 加上VXLAND头(包含VNI=1,标识属于Flannel集群的隧道)
3.封装后的数据包通过 Node1 的物理网卡eth0发送到 Node2 的eth0。
4.Node2 的eth0收到数据包后,交给flannel.1网卡,flanneld解封装还原出原始 IP 包。
5.Node2 查询路由表,将原始数据包转发到cni0网桥,最终送达 Pod2
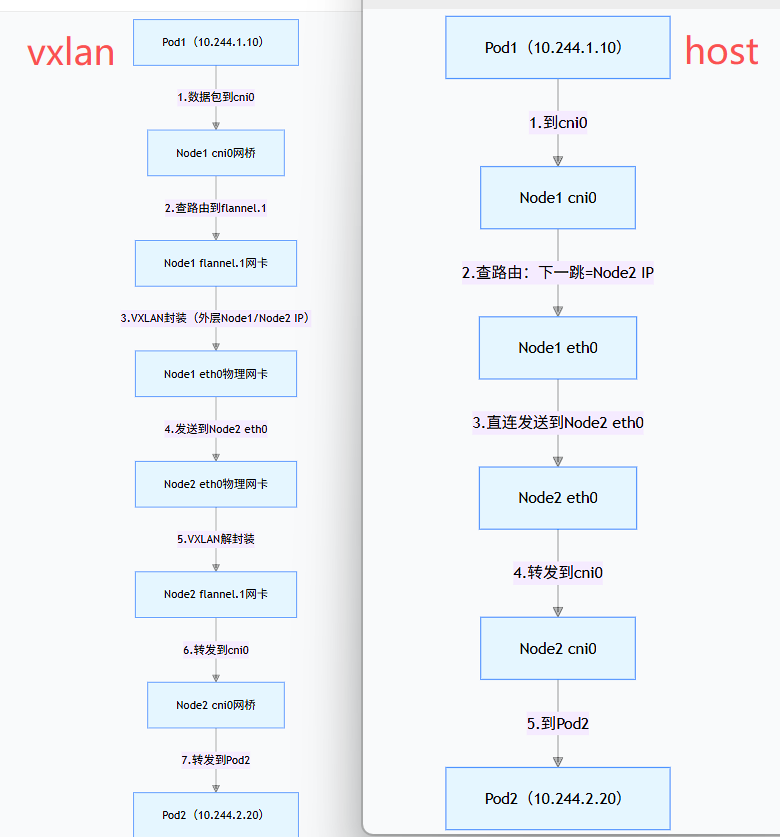
模式 2:host-gw(直连模式,性能更高)
host-gw(Host Gateway)是无隧道模式,要求所有 Node 在同一二层网络(如同一交换机 / 同一网段),直接通过路由表将数据包转发到目标 Node,流程更简单:
模式3:UDP
- 本质:Flannel 最早的隧道后端,直接将 Pod 的 IP 数据包封装成 UDP 数据包(无 VXLAN 头),通过节点物理网络传输,实现跨节点 Pod 互通。
- 现状:Flannel v0.7 之后已标记为「废弃」,默认使用 VXLAN 模式(更高效的 UDP 封装方式),仅在极老的集群或特殊兼容场景可能见到。
- 核心网卡 :UDP 模式下,节点上创建的是
udp0虚拟网卡(而非 VXLAN 模式的flannel.1),作为 UDP 隧道的收发端点。
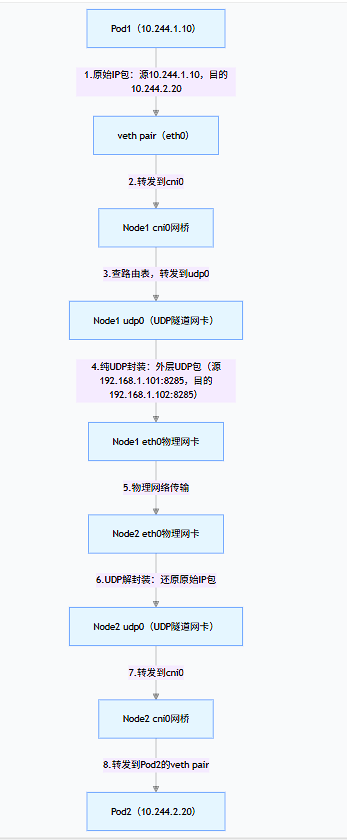
步骤详解(核心是「纯 UDP 封装」):
- Pod1 发送原始数据包 :Pod1 生成目标为 Pod2 的 IP 包,通过 veth pair 发送到 Node1 的
cni0网桥(同 VXLAN 模式)。 - 路由表转发到 udp0 :Node1 的路由表由
flanneld维护,10.244.2.0/24网段的下一跳指向udp0网卡,数据包被转发到udp0。 - 纯 UDP 封装(无 VXLAN 头) :
flanneld进程(而非内核)负责封装(这是性能差的核心原因):
- 外层直接封装成 UDP 数据包:
- 源 IP:Node1 物理 IP(192.168.1.101),源 UDP 端口:8285(Flannel UDP 模式固定端口);
- 目的 IP:Node2 物理 IP(192.168.1.102),目的 UDP 端口:8285;
- 无 VXLAN 头、无二层帧封装,仅简单包裹原始 IP 包。
- 物理网络传输 :封装后的 UDP 包通过 Node1 的
eth0发送到 Node2 的eth0。 - 解封装并转发到 Pod2 :Node2 的
flanneld进程监听 8285 端口,收到 UDP 包后剥离外层 UDP 头,还原原始 IP 包,通过udp0转发到cni0网桥,最终送达 Pod2。
三、Flannel 的优缺点
优点
- 部署简单
- 小集群够用
缺点
- 封包 + 解包 = 性能损耗
- 不适合高并发
- 网络策略能力弱
四、Calico核心理念
Calico 区别于 Flannel(如 vxlan 模式)等 Overlay 网络插件的核心是:基于三层网络(IP 层)实现通信,默认无数据包封装。简单来说,Calico 把 k8s 集群中的每个节点当作一台 "路由器",通过路由协议交换 Pod IP 的路由信息,让 Pod 之间直接通过三层 IP 路由通信,而非通过隧道封装(Overlay),因此性能接近原生网络。
4.1 Calico 的核心工作模式
1. 纯 BGP 模式(默认 / 推荐)
- 适用场景:集群节点处于同一二层网络(如同一数据中心、同一 VPC 内,节点间可直接二层通信)。
- 核心原理 :
- 每个节点通过 BGP 协议(路由器之间交换路由的标准协议),向集群内所有节点 "宣告" 自己节点上的 Pod IP 段路由(比如 "10.244.1.0/24 的 Pod 都在我这台节点上,下一跳是我的节点 IP")。
- 所有节点学习到全网的 Pod 路由后,直接通过三层 IP 路由转发数据包,无任何封装,性能和原生物理机通信几乎一致。
2. IPIP/VXLAN 模式(Overlay 模式)
- 适用场景:节点跨二层网络(如公有云不同子网、跨数据中心),纯 BGP 无法直接路由。
- 核心原理 :
- 在原 Pod IP 数据包外层再封装一层 IP(IPIP)或 VXLAN 帧,外层的源 / 目的是节点的物理 IP。
- 数据包先通过节点物理网络转发到目标节点,目标节点解封装后,再转发到本地 Pod。
- 该模式有轻微性能损耗(封装 / 解封装),但能解决跨网段通信问题。
4.2 Calico 跨节点 Pod 通信流程
以 "节点 A 的 PodA" 访问 "节点 B 的 PodB" 为例,流程如下(无封装,最核心的路径):
- PodA 发送数据包(目标 IP=PodB 的 IP),先通过本地的 Calico 虚拟网卡(calixxx)进入节点 A 的主机网络命名空间。
- 节点 A 的内核查询路由表(由 Felix 维护),发现 PodB 的路由 "下一跳" 是节点 B 的物理 IP(该路由由 BIRD 从节点 B 学习而来)。
- 节点 A 直接将数据包通过物理网卡转发到节点 B(二层网络直接通信)。
- 节点 B 收到数据包后,内核查询本地路由表,发现 PodB 在本机,通过本地的 calixxx 网卡将数据包转发到 PodB。
- 响应包按反向路径返回 PodA,全程无封装,直接三层路由转发。
五、Calico 架构组件
|--------|---------------|
| 组件 | 作用 |
| CNI插件 | 创建Veth |
| Felix | 路由规则、iptables |
| BIRD | BGP路由分发 |
六、Flannel vs Calico 总结
|--------|-------------|------------|
| 对比 | Flannel | Calico |
| 网络模式 | Overlay | 路由 |
| 是否封包 | 是 | 否 |
| 性能 | 一般 | 高 |
| 复杂度 | 低 | 高 |
| 适合场景 | 小集群 | 生产/大集群 |
七、Kubernetes 操作管理概述
1、管理操作分类
- 陈述式(命令式)管理方法
- 声明式(配置清单式)管理方法
2、陈述式资源管理方法
2.1 基本原理
-
Kubernetes 集群资源管理的唯一入口是通过调用 apiserver 的接口。
-
kubectl 是官方 CLI 命令行工具,用于与 apiserver 通信,将用户命令转化为 apiserver 能识别的
请求,实现集群资源管理。
- 查看 kubectl 命令大全:
kubectl --help
- 对资源的"增、删、查"操作较方便,但"改"操作相对复杂。
2.2 基础信息查看命令
bash
(1)版本与集群信息
kubectl version # 查看版本信息
kubectl api-resources # 查看资源对象简写
kubectl cluster-info # 查看集群信息
(2)命令自动补全与日志查看
yum -y install bash-completion
echo "source <(kubectl completion bash)" >> /etc/profile
source /etc/profile2.3 基本资源查看命令
kubectl get <resource> [-o wide|json|yaml] [-n namespace]
- -n 指定命名空间
- -o 指定输出格式
- --all-namespaces:显示所有命名空间
- --show-labels:显示所有标签
- -l app=nginx:筛选指定标签的资源
示例:
kubectl get componentstatuses # 查看 master 节点状态
kubectl get namespace # 查看命名空间
kubectl get all -n default # 查看default命名空间的所有资源
2.4 命名空间操作
kubectl create ns app # 创建命名空间
kubectl delete namespace app # 删除命名空间
2.5 创建 Deployment(副本控制器)
bash
kubectl create deployment nginx --image=nginx -n kube-public
kubectl create deployment
#描述某个资源的详细信息
kubectl describe deployment nginx -n kube-public
kubectl describe pod nginx-d47f99cb6-hv6gz -n kube-public
kubectl get pods -n kube-public2.6 登录容器与删除 Pod
kubectl exec -it nginx-d47f99cb6-hv6gz bash -n kube-public
kubectl delete pod nginx-d47f99cb6-hv6gz -n kube-public
#若pod无法删除,总是处于terminate状态,则要强行删除pod
kubectl delete pod <pod-name> -n <namespace> --force --grace-period=0
#grace-period表示过渡存活期,默认30s,在删除pod之前允许POD慢慢终止其上的容器进程,从而优雅退出,0表示立即终止pod
2.7 扩缩容与删除
kubectl scale deployment nginx --replicas=2 -n kube-public
kubectl scale deployment nginx --replicas=1 -n kube-public
kubectl delete deployment nginx -n kube-public
八、项目生命周期管理
项目的生命周期包括:
创建 → 发布 → 更新 → 回滚 → 删除
1、创建阶段(kubectl create)
bash
创建并运行一个或多个容器镜像。
创建一个deployment 或job 来管理容器。
kubectl create --help
启动 nginx 实例,暴露容器端口 80,设置副本数 3
kubectl create deployment nginx --image=nginx:1.14 --port=80 --replicas=3
kubectl get pods
kubectl get all2、发布阶段(kubectl expose)
将资源暴露为 Service
kubectl expose --help
kubectl expose deployment nginx --port=80 --target-port=80 --name=nginx-service --type=NodePort
① Service 类型:
|--------------|-------------------------|
| 类型 | 说明 |
| ClusterIP | 集群内部访问(默认) |
| NodePort | 集群外部访问,端口范围 30000-32767 |
| LoadBalancer | 云平台负载均衡 |
| externalName | 映射到外部域名 |
② 扩展端口类型:
- port
- port 是 k8s 集群内部访问service的端口,即通过 clusterIP: port 可以从 Pod 所在的 Node 上访问到 service
- nodePort
- nodePort 是外部访问 k8s 集群中 service 的端口,通过 nodeIP: nodePort 可以从外部访问到某个 service。
- targetPort
- targetPort 是 Pod 的端口,从 port 或 nodePort 来的流量经过 kube-proxy 反向代理负载均衡转发到后端 Pod 的 targetPort 上,最后进入容器。
- containerPort
- containerPort 是 Pod 内部容器的端口,targetPort 映射到 containerPort。
③ 查看网络状态与服务端口:
#查看pod网络状态详细信息和 Service暴露的端口
kubectl get pods,svc -o wide
#查看关联后端的节点
kubectl get endpoints
#查看 service 的描述信息
kubectl describe svc nginx
3.更新阶段(kubectl set)
bash
更改现有应用资源一些信息。
kubectl set --help
//获取修改模板
kubectl set image --help
Examples:
# Set a deployment's nginx container image to 'nginx:1.9.1', and its busybox container image to 'busybox'.
kubectl set image deployment/nginx busybox=busybox nginx=nginx:1.9.1
//查看当前 nginx 的版本号
curl -I http://192.168.10.20:44847
curl -I http://192.168.10.21:44847
##将nginx 版本更新为 1.15 版本
kubectl set image deployment/nginx nginx=nginx:1.15
kubectl get pods -w #/处于动态监听 pod 状态,由于使用的是滚动更新方式,所以会先生成一个新的pod,然后删除一个旧的pod,往后依次类推
kubectl get pods -o wide #再看更新好后的 Pod 的 ip 会改变4.回滚阶段(kubectl rollout)
bash
#对资源进行回滚管理
kubectl rollout --help
//查看历史版本
kubectl rollout history deployment/nginx
//执行回滚到上一个版本
kubectl rollout undo deployment/nginx
//执行回滚到指定版本
kubectl rollout undo deployment/nginx --to-revision=1
//检查回滚状态
kubectl rollout status deployment/nginx5 删除阶段(kubectl delete)
//删除副本控制器
kubectl delete deployment/nginx
//删除service
kubectl delete svc/nginx-service
kubectl get all