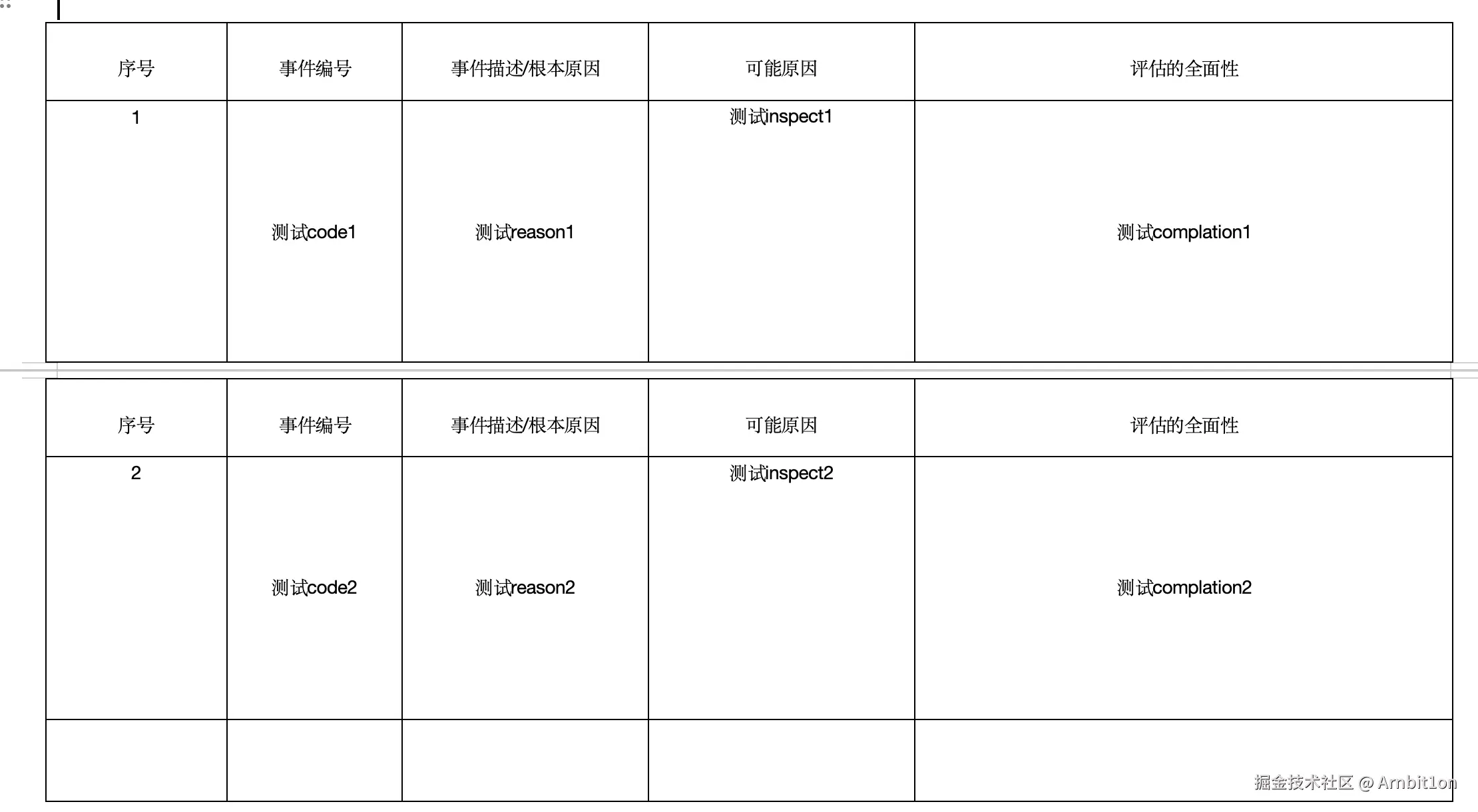
最近给其他部门做了个简单的脚本要把一堆数据填充到word报告里。模板固定的都好说。用 docxtemplater 就行。
使用 npm install docxtemplater 直接下载即可。word的格式如下处理就行:
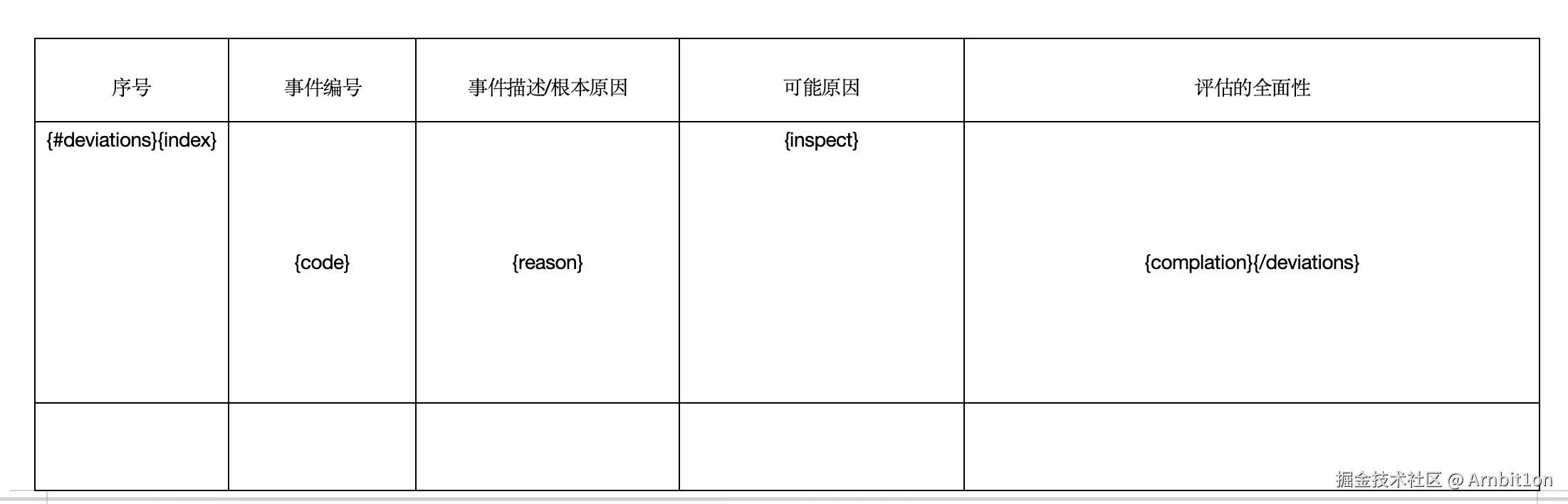
deviations是后面js代码里传递的对象名称。以{#deviations}开头,{/deviations}结尾。类似于for循环。index、code这些字段就是item.index,item.code等。只不过省去了item。
test.json文件格式如下:
css
[ { "code": "测试code1", "reason": "测试reason1", "inspect": "测试inspect1", "complation": "测试complation1" }, { "code": "测试code2", "reason": "测试reason2", "inspect": "测试inspect2", "complation": "测试complation2" }]可以简单实现的代码如下根据自己需求去更改就行:
javascript
import fs from "fs/promises";
import Docxtemplater from "docxtemplater";
import PizZip from "pizzip";
async function main() {
// 读取模板
const templateContent = await fs.readFile("测试.docx");
// 加载数据
const data = JSON.parse(await fs.readFile("test.json", "utf8"));
// 构造符合模板要求的数据结构
const reportData = {
deviations: data.map((item, i) => ({
index: i + 1,
code: item.code || "",
reason: item.reason || "",
inspect: item.inspect || "",
complation: item.complation || "",
})),
};
// 渲染模板
const zip = new PizZip(templateContent);
const doc = new Docxtemplater(zip, {
paragraphLoop: true,
linebreaks: true,
nullGetter: () => "",
});
doc.render(reportData);
const buffer = doc
.getZip()
.generate({ type: "nodebuffer", compression: "DEFLATE" });
await fs.writeFile("test输出.docx", buffer);
}
main().catch(console.error);输出的结果如下: