搭建部署在 AutoDL V100 32G GPU Ubuntu 环境下的 QWen2.5-7B-Instruct 模型的 vLLM 推理流程,支持在本地浏览器访问。具体流程如下:
1、服务器选型
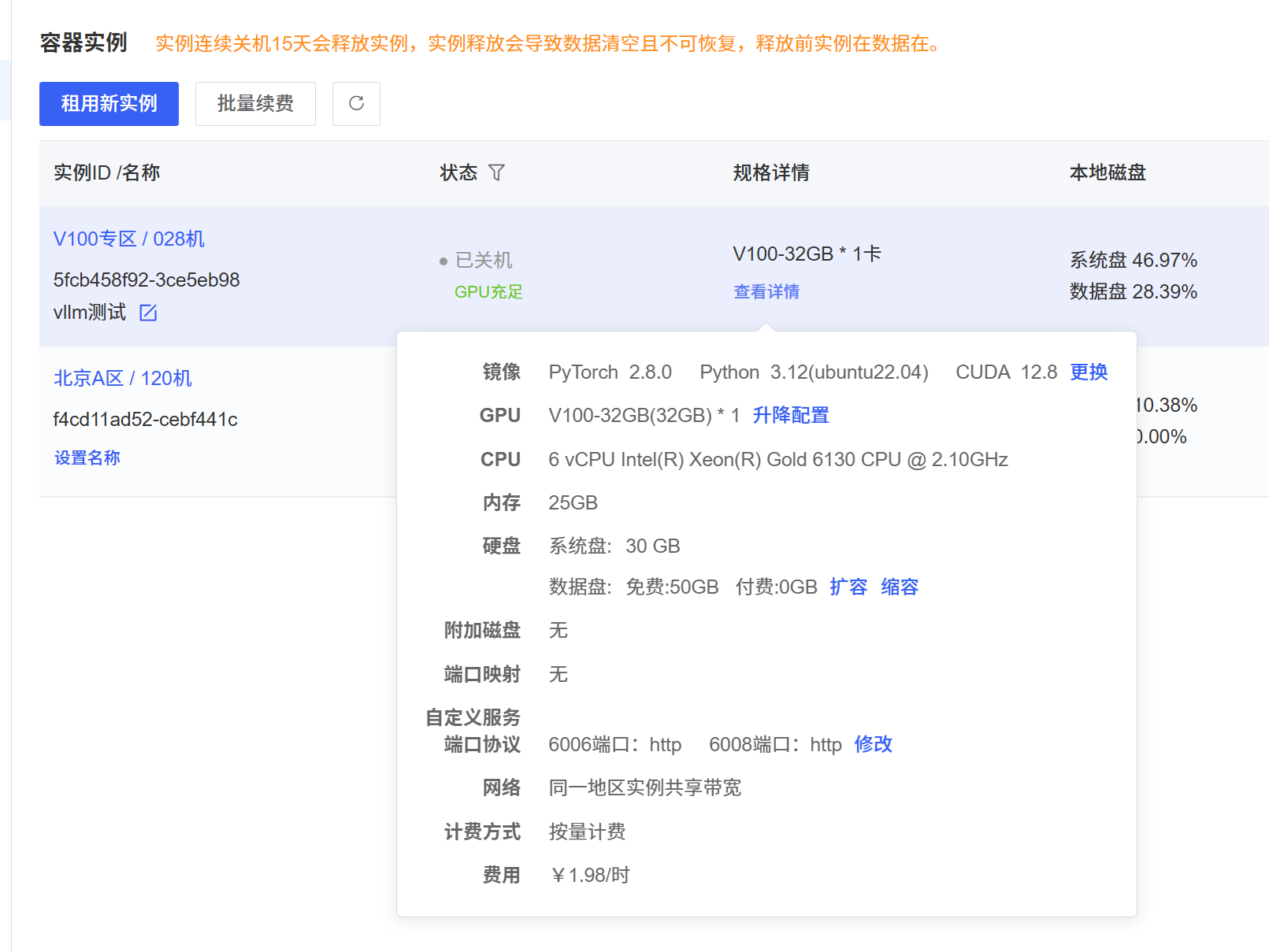
- AutoDL:选用 V100 32G 容器
- vLLM
- HuggingFace
- WebUI
2、环境搭建
2.1、VSCode 连接 AutoDL 远程服务器
VSCode 安装 Remote-SSH 插件
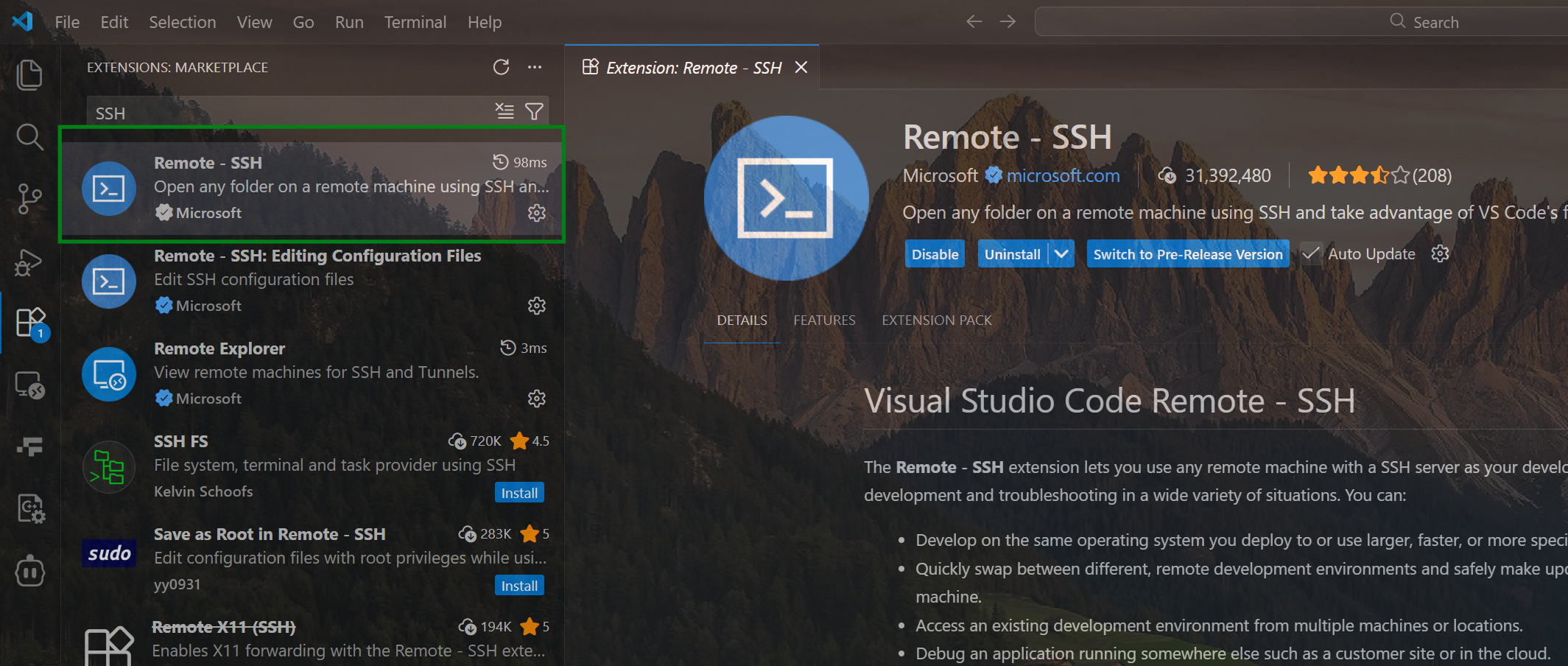
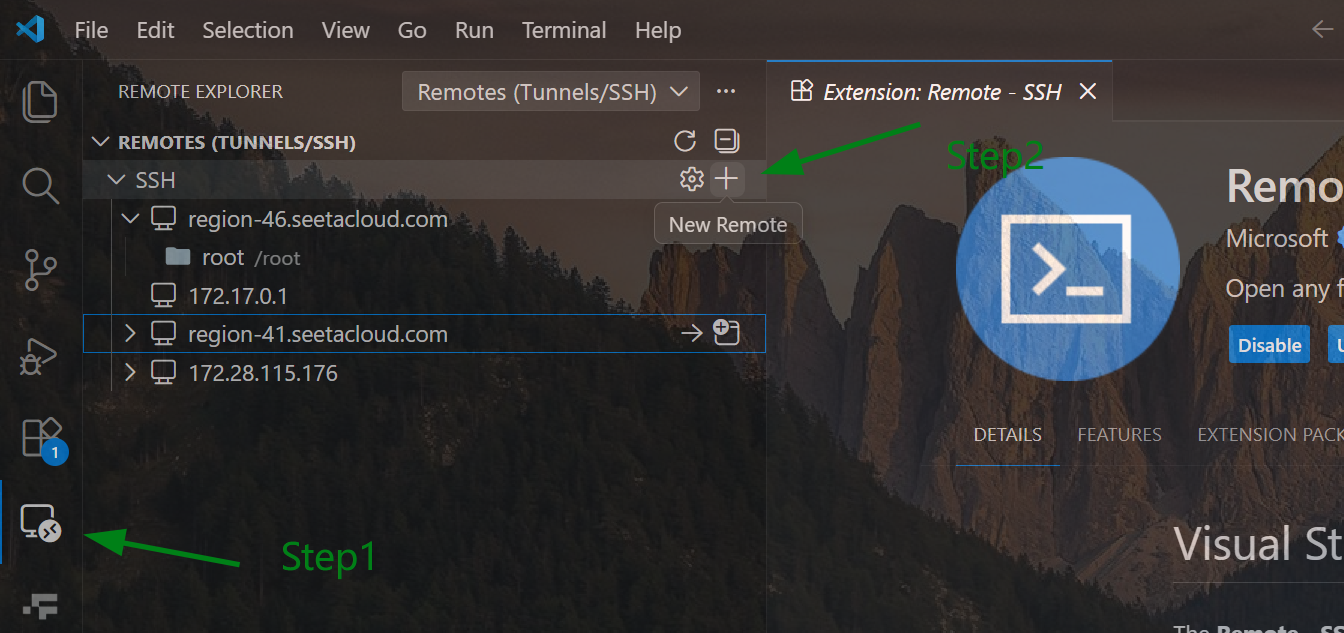
点击 VSCode SSH + 按钮添加 AutoDL 中创建的容器账号和密码,建立 SSH 远程连接。
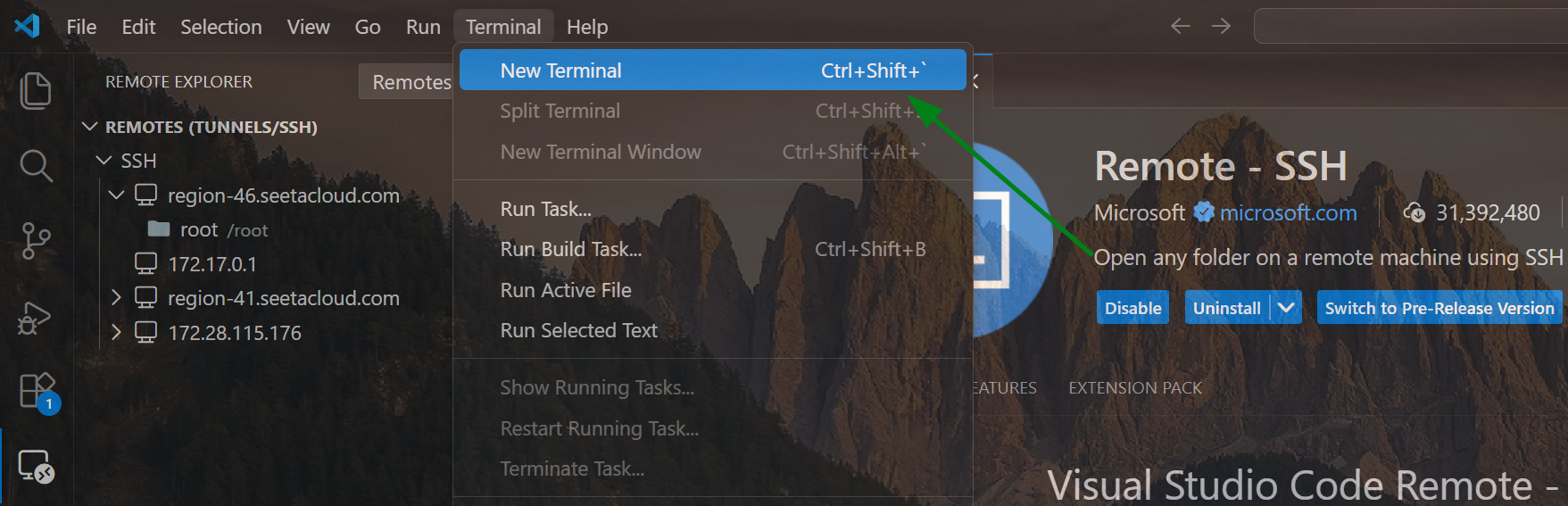
使用 VSCode 连接上 AutoDL 容器后,点击 VSCode 菜单栏中的 Terminal,创建新的命令行终端:
由于 AutoDL 的容器中无法直接访问 HuggingFace 官网,导致开启 vLLM 服务过程中部分子任务无法自动执行,需要配置国内镜像。
以下大部分命令均是在 VSCode 创建的新的命令行终端里面执行:
2.2、安装依赖库
1、安装 huggingface hub
bash
pip install -U huggingface_hub2、设置镜像
bash
export HF_ENDPOINT=https://hf-mirror.com
export HF_TOKEN="你自己的HuggingFace的AccessToken"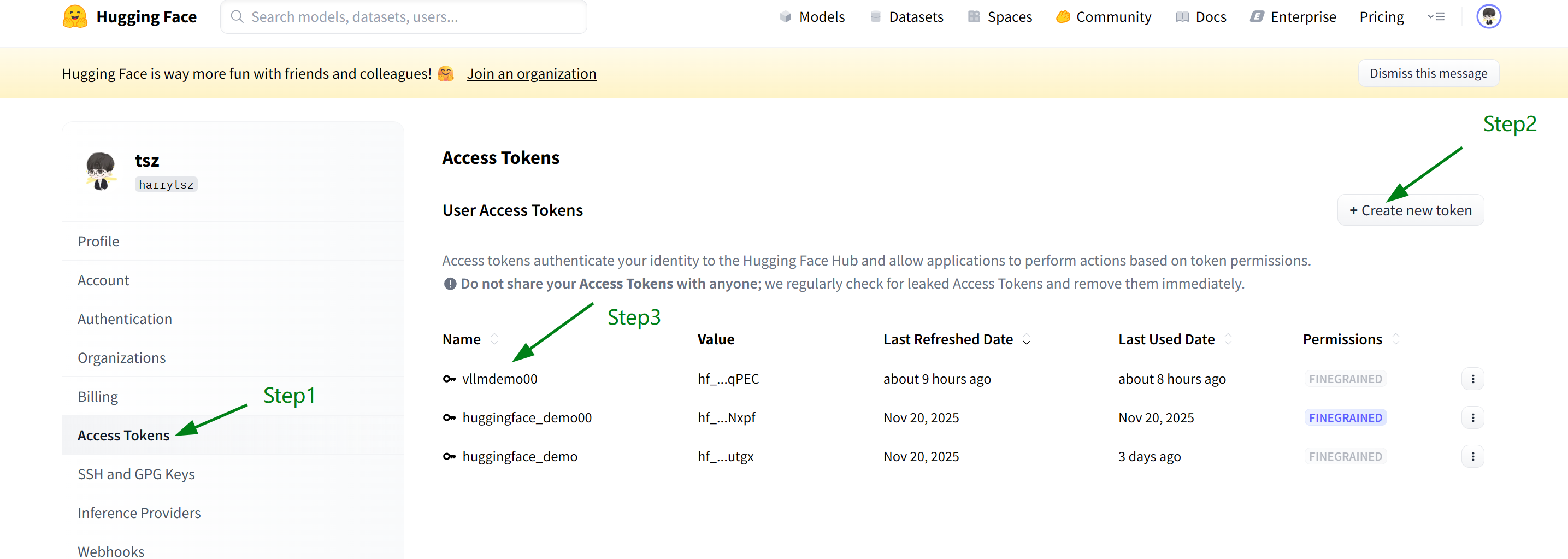
可以在 HuggingFace 官网的 Access Tokens 中创建一个新的 Token,对应的 Token 填入到 HF_TOKEN 中即可。
3、AutoDL Ubuntu 容器中登录 HuggingFace
bash
hf auth login --token $HF_TOKEN
hf auth whoami #看是否登录成功4、安装 WebUI
bash
pip install webui5、安装 vLLM
bash
pip install vllm安装好 vLLM 后,启动服务:
bash
# Launch vLLM with a language model
vllm serve Qwen/Qwen2.5-7B-Instruct由于 Qwen2.5-7B-Instruct 模型较大,需要耐心等待程序自动下载模型文件,大约需要 10 分钟。
程序执行完成后,可以验证一下服务是否成功启动,VSCode 开启新的命令行终端,执行下述指令:
bash
curl -o- localhost:8000/v1/models如果返回 json 形式的内容,则证明 vLLM 服务成功开启。
2.3、模型文件迁移
由于 AutoDL 系统盘容量默认 30G,下载完 QWen2.5-7B-Instruct 文件后,此时的系统盘基本全满,无法执行后续的任务。需要将系统盘中的大模型文件迁移到数据盘中,此时的数据盘有 50G 容量。可以使用以下指令查看内存占用情况:
bash
source ~/.bashrc可以看到此时的系统盘占用接近 100%,需要迁移数据到数据盘。
AutoDL 数据盘默认路径为 /root/autodl-tmp(可扩容、空间充足),先创建专门存放模型的目录,避免文件混乱:
bash
# 1. 创建模型目标目录(数据盘内)
mkdir -p /root/autodl-tmp/huggingface/models
# 2. 进入该目录,确认路径有效(可选,验证用)
cd /root/autodl-tmp/huggingface/models
pwd输出应为 /root/autodl-tmp/huggingface/models,说明目标目录创建成功。
使用 mv 命令直接迁移(比 cp 更高效,无需额外占用系统盘空间),替换以下命令中的「模型原路径」为第一步找到的实际路径。
bash
# 迁移默认缓存路径的模型(示例,替换为你的实际原路径)
mv /root/.cache/huggingface/hub/models--Qwen--Qwen2.5-7B-Instruct /root/autodl-tmp/huggingface/models/
# 若为手动指定路径(示例),替换为你的实际路径即可
# mv /root/workspace/Qwen2.5-7B-Instruct /root/autodl-tmp/huggingface/models/迁移注意事项
- 模型文件较大(约 14GB 左右),迁移过程耗时 2-5 分钟,期间不要关闭终端、不要中断命令;
- 若提示「权限不足」,在命令前添加
sudo即可(AutoDL 根用户通常无需); - 迁移完成后,系统盘的原模型目录会消失,文件全部转移到数据盘。
迁移后模型路径变了,直接运行代码会找不到模型,建立软链接可以让原调用路径「指向」数据盘的新模型,相当于给新路径建了一个「快捷方式」,代码无需做任何修改。
bash
# 场景 1:默认缓存路径(原路径 → 数据盘新路径)
ln -s /root/autodl-tmp/huggingface/models/models--Qwen--Qwen2.5-7B-Instruct /root/.cache/huggingface/hub/models--Qwen--Qwen2.5-7B-Instruct
# 场景 2:手动指定路径(原手动路径 → 数据盘新路径,替换为你的实际路径)
# ln -s /root/autodl-tmp/huggingface/models/Qwen2.5-7B-Instruct /root/workspace/Qwen2.5-7B-Instruct执行以下命令,若能看到「箭头指向数据盘路径」,说明软链接创建成功:
bash
# 验证默认缓存路径的软链接
ls -lh ~/.cache/huggingface/hub/ | grep Qwen2.5-7B-Instruct
# 验证手动路径的软链接(可选)
# ls -lh /root/workspace/ | grep Qwen2.5-7B-Instruct此时,Qwen2.5-7B-Instruct 大模型文件已经成功地从系统盘迁移至数据盘,并且已经创建了软链接。执行以下指令,可以看到内存占用情况:
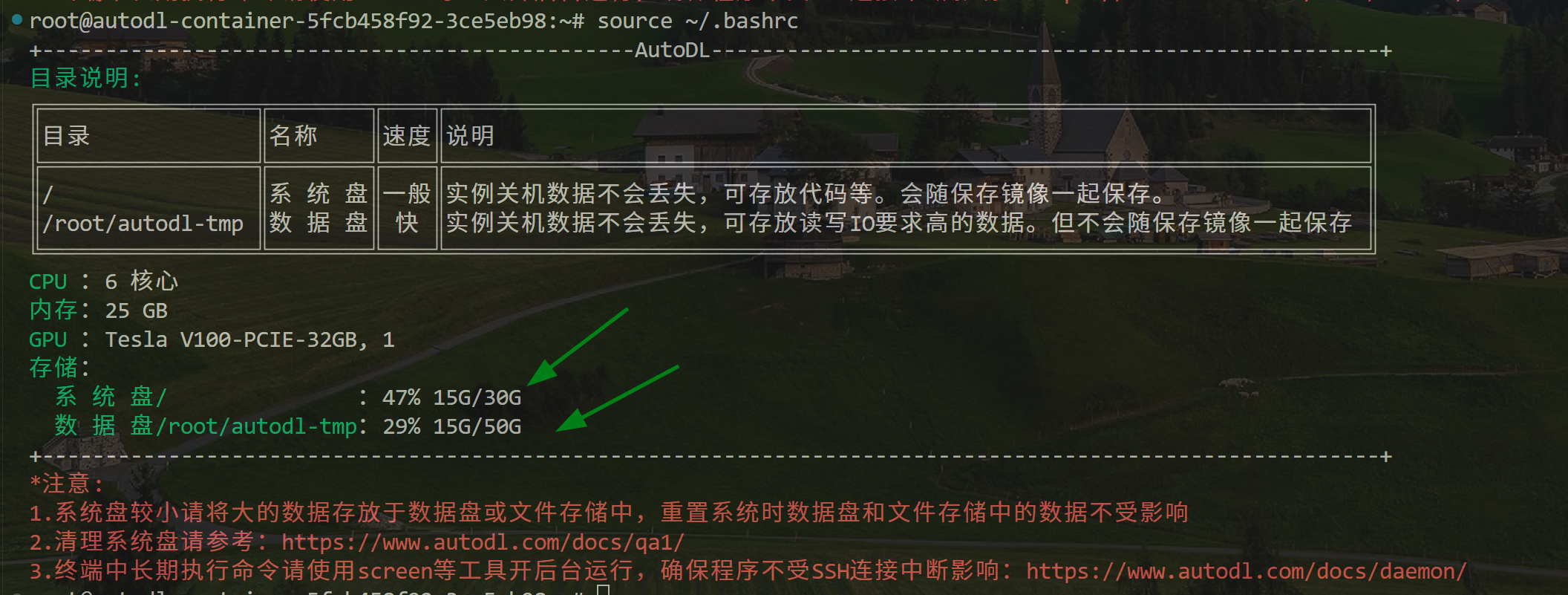
2.4、开启服务
系统盘数据已经成功迁移至数据盘,可以继续开启各项服务。
1、开启 vLLM 服务:
由于启动 vllm 服务需要找到包含 config.json 的最终模型根目录,需要将启动指令改成下述类似,具体路径每个人根据实际情况进行调整:
bash
vllm serve ./.cache/huggingface/hub/models--Qwen--Qwen2.5-7B-Instruct/snapshots/a09a35458c702b33eeacc393d103063234e8bc28/ --host 0.0.0.0 --port 8000 --served-model-name Qwen2.5-7B-Instruct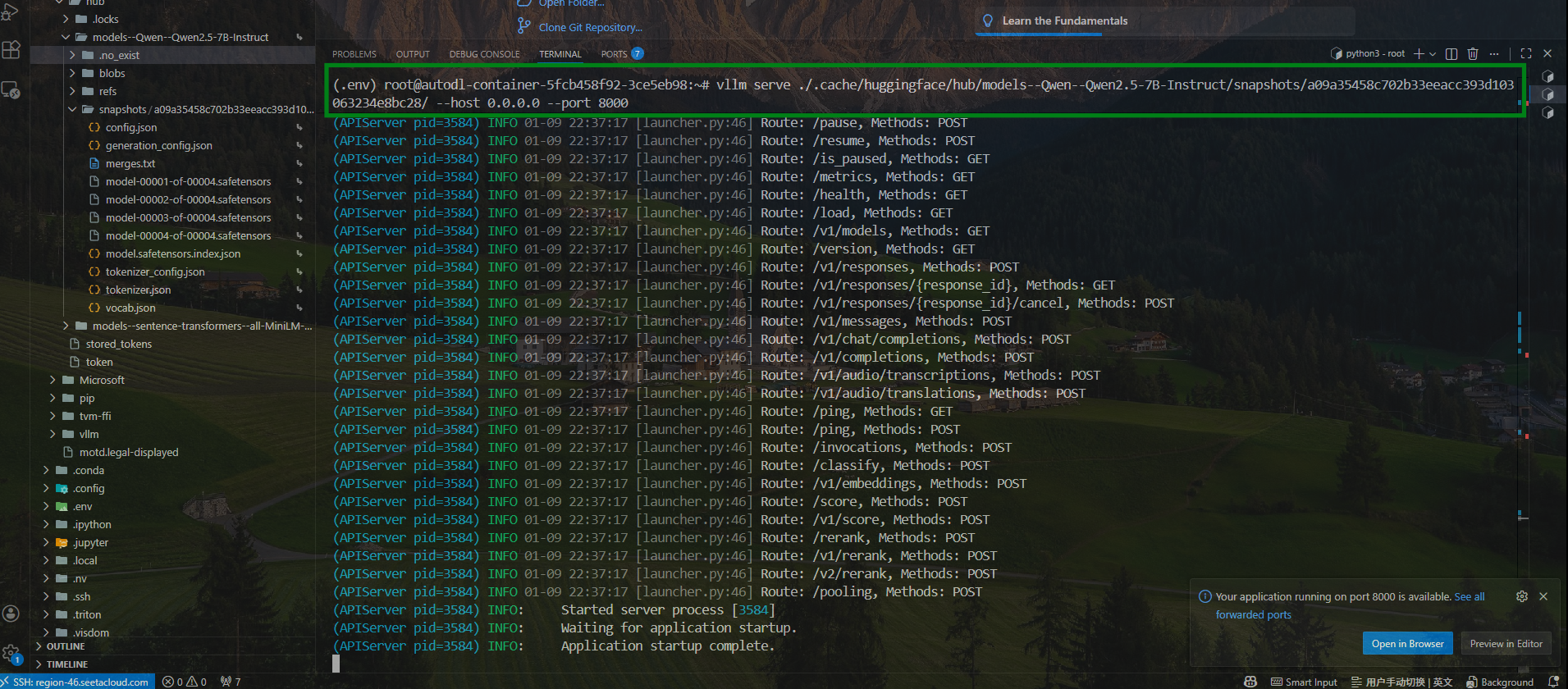
测试 vllm 是否成功启动:
bash
curl -o- localhost:8000/v1/models
2、开启 WebUI 服务:
bash
open-webui serve --host 0.0.0.0 --port 8080
3、开启本地 SSH 隧道
在本地 Windows/MacOS 命令行终端里面创建 SSH 隧道:
bash
ssh -N -L 8001:127.0.0.1:8000 -L 8081:127.0.0.1:8080 -p 15414 root@region-46.seetacloud.com
也可以通过 AutoDL 客户端工具来实现:AutoDL帮助文档
在本地浏览器中输入 http://localhost:8081 即可访问到 AutoDL 远程服务器中开启的 WebUI 端口,此时输入注册的账号、密码即可登录。
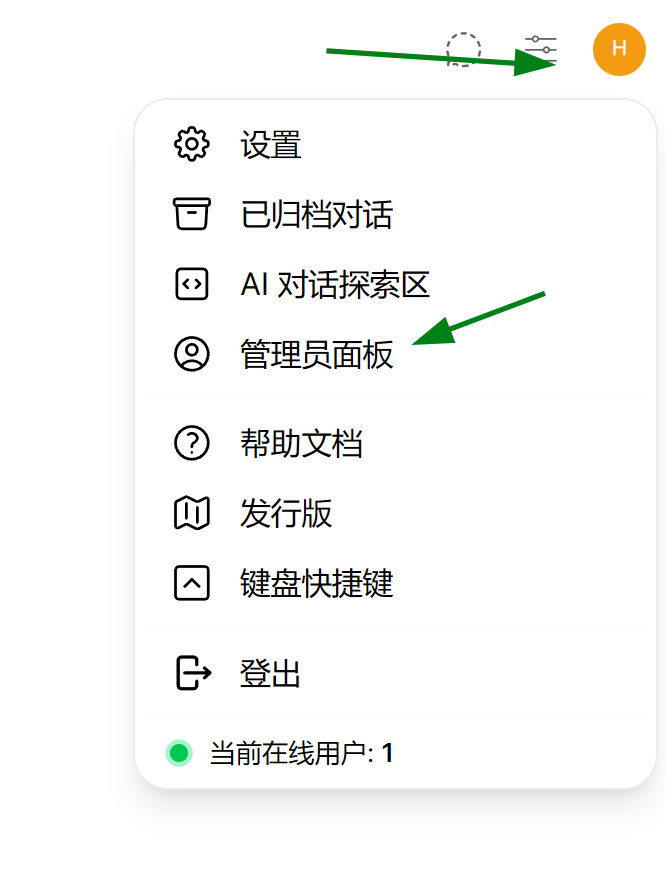
登录后,在页面的右上角圆圈中找到管理员面板:
在 设置 中找到 外部连接:

点击 右边 + 添加
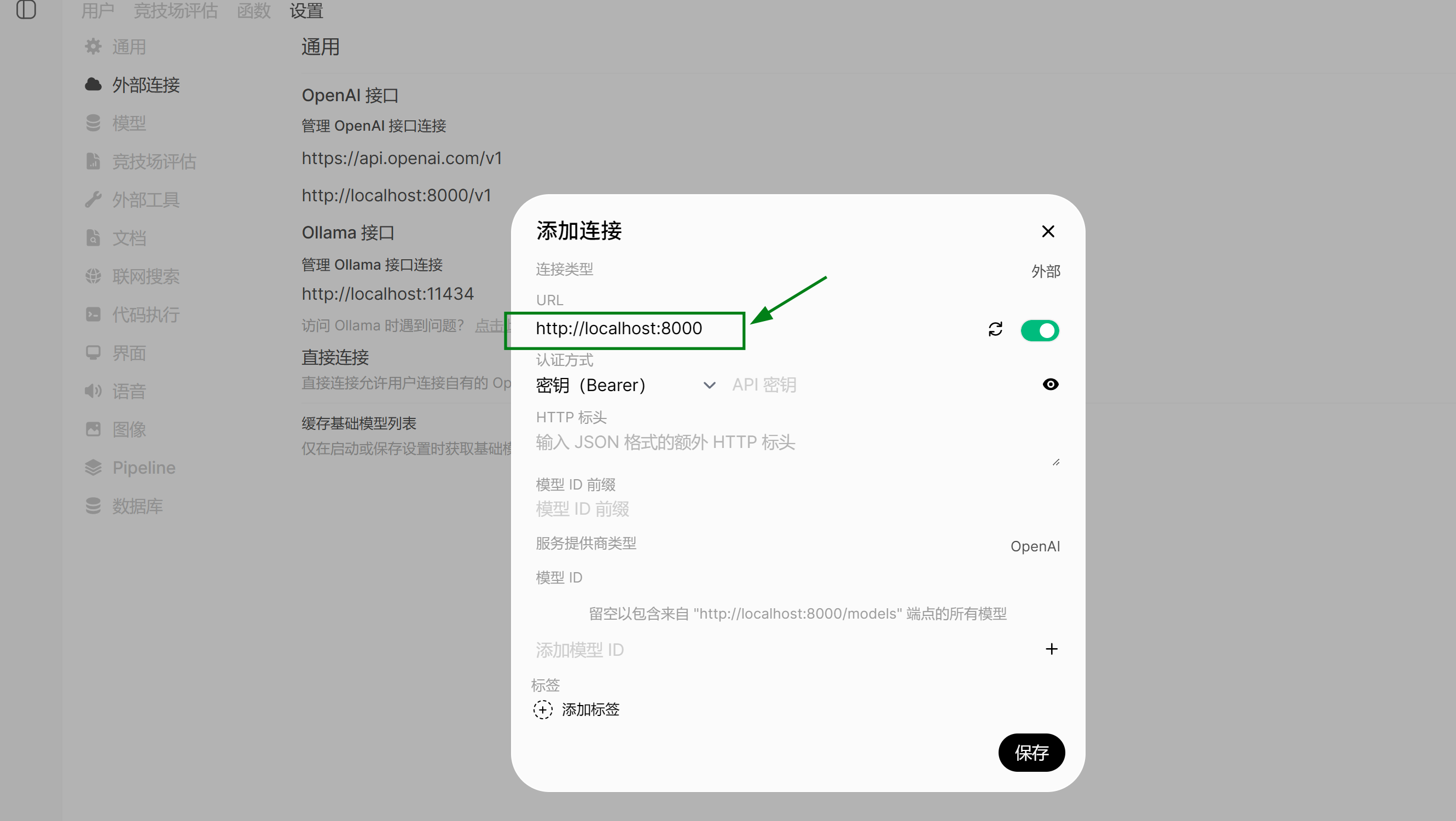
填入 http://localhost:8000 ,即 AutoDL 容器中开启的 vllm 服务 url ,保存。
此时就可以和 AutoDL 中部署的 QWen2.5-7B-Instruct 大模型愉快的聊天了:
