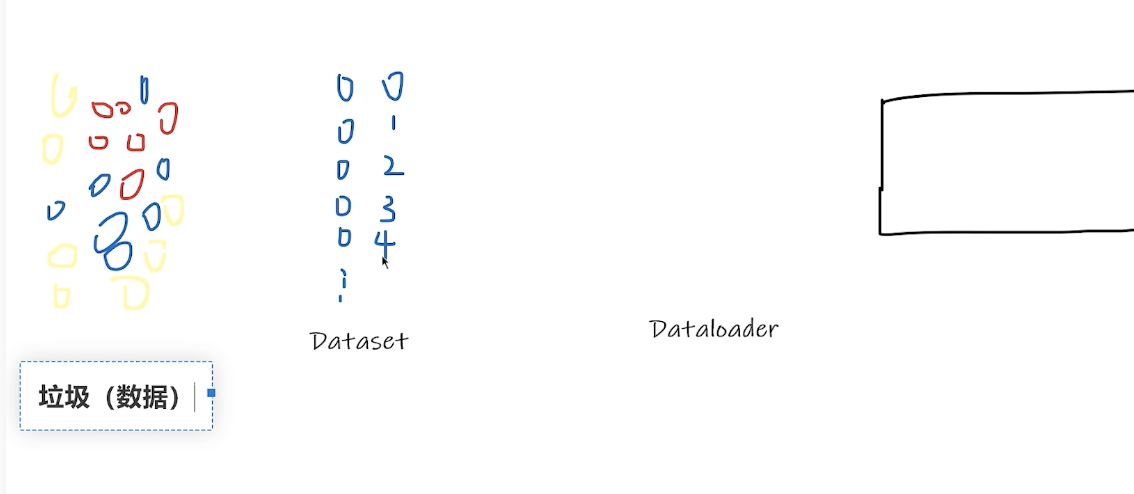
Dataset = 数据仓库,DataLoader = 搬运工
比喻:
Dataset = 一整箱苹果(所有数据)
DataLoader = 每次拿几个苹果出来(分批取数据)代码理解:
from torch.utils.data import Dataset, DataLoader
# Dataset:定义数据怎么存、怎么取
class MyDataset(Dataset):
def __init__(self):
self.data = [1, 2, 3, 4, 5, 6, 7, 8] # 所有数据
def __len__(self):
return len(self.data) # 一共多少个
def __getitem__(self, idx):
return self.data[idx] # 取第 idx 个
# DataLoader:分批次取
dataset = MyDataset() # 8个数据
loader = DataLoader(dataset, batch_size=2) # 每次取2个
for batch in loader:
print(batch) # 输出: [1,2], [3,4], [5,6], [7,8]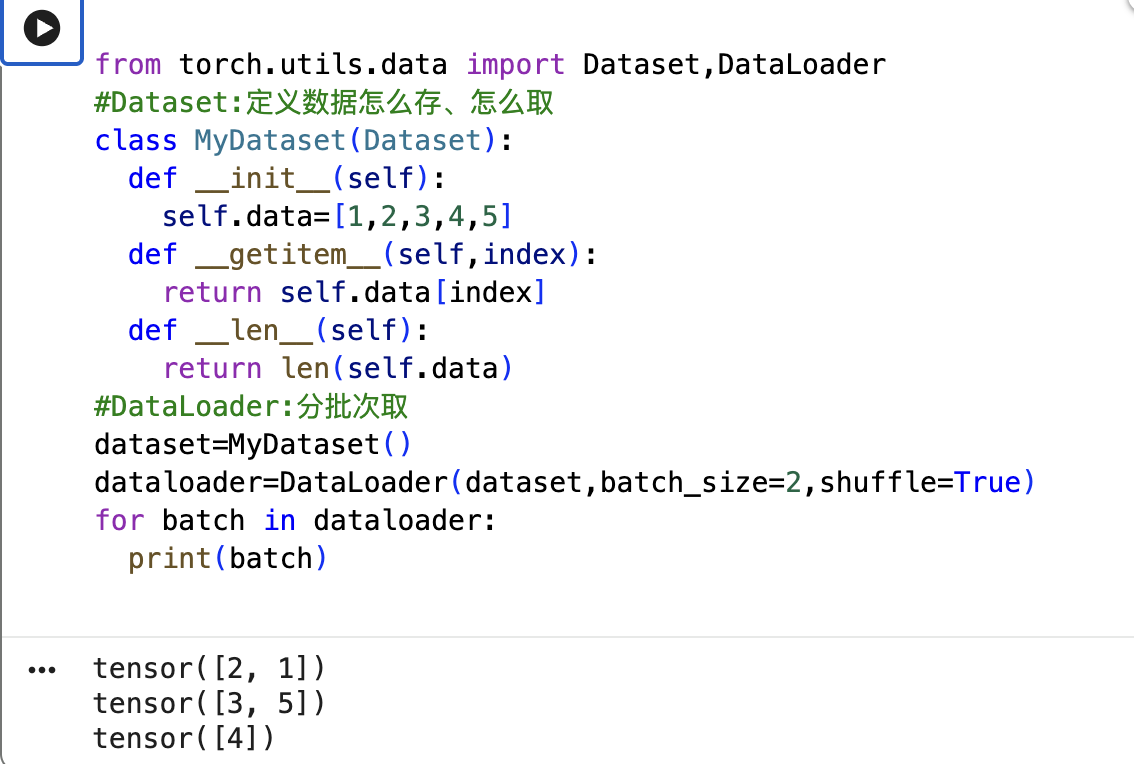
为什么要分开?
| 角色 | 职责 |
|---|---|
| Dataset | 告诉我"数据在哪、怎么读" |
| DataLoader | 告诉我"每次取几个、要不要打乱" |
一句话:Dataset 存数据,DataLoader 分批喂给模型。
用已经有的数据集
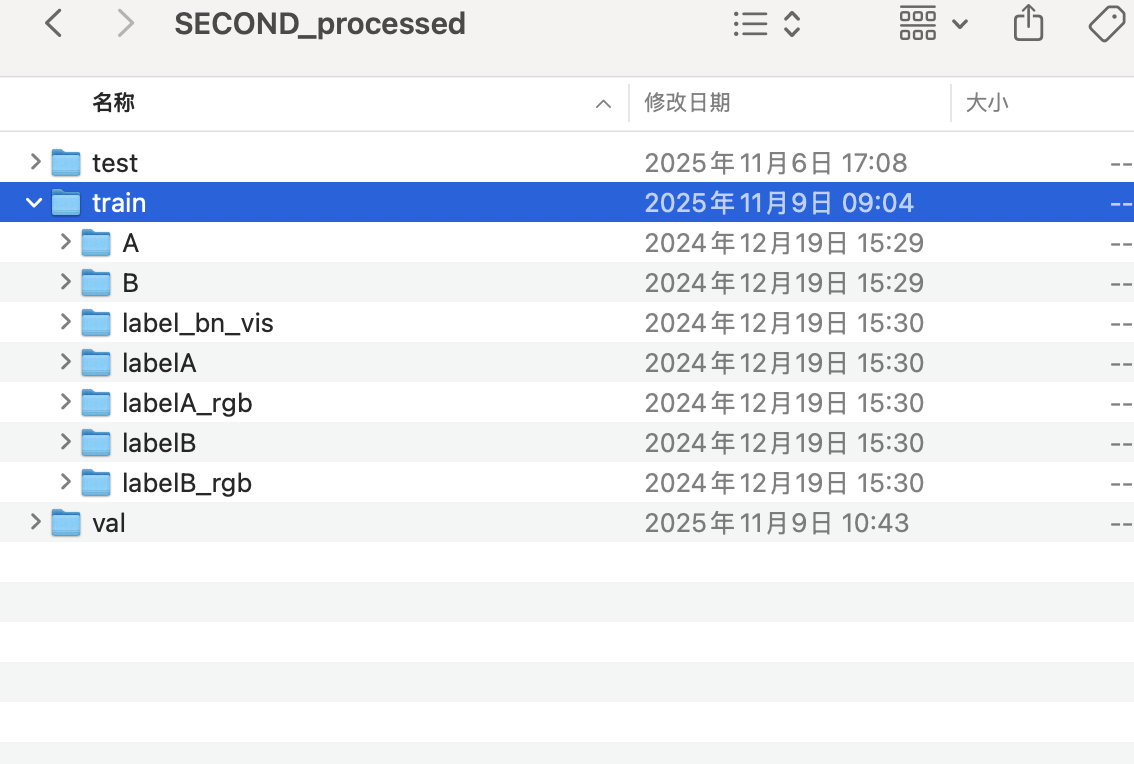
在 mydataset.py 里写这个:
import os
from PIL import Image
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class MyDataset(Dataset):
def __init__(self, root, split='train'):
"""
root: 数据集路径,如 '/path/to/SECOND'
split: 'train', 'val', 或 'test'
"""
self.dir_t1 = os.path.join(root, split, 't1')
self.dir_t2 = os.path.join(root, split, 't2')
self.dir_label = os.path.join(root, split, 'change')
# 获取所有图片名
self.images = os.listdir(self.dir_t1)
# 预处理
self.transform = transforms.ToTensor()
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
name = self.images[idx]
# 读图
img_t1 = Image.open(os.path.join(self.dir_t1, name))
img_t2 = Image.open(os.path.join(self.dir_t2, name))
label = Image.open(os.path.join(self.dir_label, name))
# 转 Tensor
img_t1 = self.transform(img_t1)
img_t2 = self.transform(img_t2)
label = self.transform(label)
return img_t1, img_t2, label
# 测试代码
if __name__ == '__main__':
root = '/path/to/SECOND' # ← 改成你的路径
dataset = MyDataset(root, split='test')
print("数据量:", len(dataset))
loader = DataLoader(dataset, batch_size=2, shuffle=True)
for t1, t2, label in loader:
print("t1 形状:", t1.shape)
print("t2 形状:", t2.shape)
print("label 形状:", label.shape)
break然后运行:
python mydataset.py预期输出:
数据量: 1000(或其他数字)
t1 形状: torch.Size([2, 3, H, W])
t2 形状: torch.Size([2, 3, H, W])
label 形状: torch.Size([2, 1, H, W])记得改 root 路径,改成本地/服务器上 SECOND 数据集的实际位置。
读数据用 CPU,训练模型才用 GPU。
