Scaling Trends for Multi-Hop Contextual Reasoning in Mid-Scale Language Models
Authors: Brady Steele, Micah Katz
Deep-Dive Summary:
中等规模语言模型中多跳上下文推理的扩展趋势
Brady Steele 佐治亚理工学院
Micah Katz 德克萨斯大学奥斯汀分校
摘要
我们对大型语言模型中的多跳上下文推理进行了一项受控研究,清晰地展示了任务-方法分离现象:基于规则的模式匹配在结构化信息检索任务上实现了 100 % 100\% 100% 的成功率,但在需要跨文档推理的任务上仅实现了 6.7 % 6.7\% 6.7%;而基于 LLM 的多智能体系统则显示出相反的模式,在基于规则的方法失败的推理任务上达到了 80 % 80\% 80% 的成功率。我们使用一个包含 120 次试验的合成评估框架,测试了四种模型(LLaMA-3 8B、LLaMA-2 13B、Mixtral 8 × 7 B 8 \times 7 \mathrm{~B} 8×7 B、DeepSeek-V2 16B),报告了三个关键发现:(1) 多智能体放大效应取决于基础能力:仅对于具有足够推理能力的模型,才出现统计学上显著的增益(LLaMA-3 8B 为 p < 0.001 p < 0.001 p<0.001,Mixtral 为 p = 0.014 p = 0.014 p=0.014),改进高达 46.7 个百分点,而较弱的模型则没有获益,这表明是放大而非补偿作用;(2) 活跃参数预测推理性能:Mixtral 的性能与其约 12 B 12 \mathrm{~B} 12 B 的活跃参数而非 47B 的总参数相符,这与推理时计算能力驱动 MoE 架构推理能力的假设一致;(3) 架构质量很重要:LLaMA-3 8B 尽管参数较少,但性能优于 LLaMA-2 13B,这与已知的训练改进一致。我们的结果为关于多智能体协作和 MoE 扩展的直觉提供了受控的定量证据,同时强调了多智能体优势对基础模型能力的依赖性。我们发布了我们的评估框架,以支持中等规模模型推理的可复现研究。
1 引言
大型语言模型(LLMs)在从文本生成到代码合成再到数学推理等广泛任务中展示了卓越的能力 Brown et al., 2020, Chowdhery et al., 2022, OpenAI, 2023。了解这些能力如何随模型规模变化对于模型开发中的能力预测和资源分配至关重要 Kaplan et al., 2020, Hoffmann et al., 2022。虽然先前的研究已经确立了模型规模与许多基准测试性能之间的幂律关系,但对于更复杂的认知能力,特别是那些需要跨不同信息源进行多步骤推理的能力,其行为仍是一个活跃的研究领域。
多跳上下文推理是扩展分析中一个特别有趣的案例。与可以通过模式匹配或单步检索解决的任务不同,多跳推理要求模型:(1) 识别分布在上下文中的相关信息片段,(2) 识别这些片段之间隐含的关系,以及 (3) 综合它们以得出任何单一来源中未明确说明的结论。这种能力对于文档理解、科学发现和安全分析等现实世界应用至关重要。
在这项工作中,我们使用一个受控的合成评估框架来研究多跳上下文推理的扩展特性。我们的框架生成结构化推理任务,需要连接多个上下文信息片段,例如,将家庭成员的姓名与出生年份关联起来以推断可能的密码模式。关键的是,我们的评估完全使用合成数据,不包含任何真实用户信息,从而能够在没有隐私问题的情况下进行严格分析。
我们的工作做出了以下贡献:
- 任务-方法分离的受控演示 :我们提供了清晰的定量确认,即基于规则的方法在模式匹配任务上达到 100 % 100\% 100%,但在推理任务上仅为 6.7 % 6.7\% 6.7%,而 LLM 智能体则显示相反,提供了一个受控的合成环境来研究一个众所周知的现象。
- 多智能体放大效应取决于基础能力 :我们表明,多智能体协作在推理任务上提供了显著的统计学改进(高达 + 46.7 +46.7 +46.7 个百分点, p < 0.001 p < 0.001 p<0.001),但仅适用于具有足够基础推理能力的模型。较弱的模型没有获益,这表明多智能体系统是放大现有能力,而非弥补其缺失。
- 活跃参数预测 MoE 推理能力 :我们提供证据表明 Mixtral 的推理性能与其活跃参数数量(约 12 B 12\mathrm{B} 12B)而非总参数(47B)相符,这与推理时计算能力驱动 MoE 架构推理能力的假设一致。
- 易于访问的评估框架:我们发布了一个合成评估框架,支持使用消费级硬件进行多跳推理的可复现研究,所有数据均为合成生成,以避免隐私问题。
2 相关工作
2.1 语言模型的扩展定律
神经网络扩展定律的研究揭示了模型规模、数据、计算和性能之间的一致关系。Kaplan et al. 2020 建立了语言模型损失的幂律关系,表明性能随规模的增加而平滑改进,跨越多个数量级。Hoffmann et al. 2022 进一步完善了这些发现,证明了最佳计算分配需要数据与参数成比例地扩展。
然而,随后的研究表明,不同的能力可能以不同的方式扩展。Wei et al. 2022b 记录了涌现能力,即在特定规模下突然出现而非逐渐改进的能力。这些能力包括算术、多步推理和指令遵循。Schaeffer et al. 2023 质疑这些涌现是基础性的还是度量选择的产物,引发了关于能力扩展本质的持续争论。
我们的工作通过为多跳上下文推理提供详细的扩展分析,为该文献做出了贡献,多跳上下文推理是先前扩展研究中未系统研究过的能力。
2.2 大型语言模型中的涌现能力
LLMs 中"涌现"的概念引起了广泛的兴趣和争论。Wei et al. 2022b 识别了许多表现出涌现行为的任务,在这些任务中,性能在达到某个模型规模阈值之前保持在随机水平,然后迅速提高。例子包括多位算术、单词重组和波斯语问答。
Ganguli et al. 2022 认为,不可预测的涌现给人工智能安全带来了挑战,因为危险的能力可能在扩展过程中突然出现。相反,Schaeffer et al. 2023 证明,一些明显的涌现在使用连续度量时会消失,这表明它们可能是测量误差。
最近的理论工作试图通过电路形成 Olsson et al., 2022、损失景观中的相变 Power et al., 2022 和能力组合 Arora \& Goyal, 2023 等角度来解释涌现。我们的观察与相变解释一致,尽管我们有限的模型范围不允许得出确定性结论。
2.3 多智能体LLM系统
多智能体架构已成为增强 LLM 在复杂任务上能力的强大范式。Hong et al. 2024 引入了 MetaGPT,使用标准操作程序来协调智能体执行软件工程任务。Wu et al. 2023 开发了 AutoGen 用于可定制的多智能体对话,展示了在编码和数学基准上的改进。
Du et al. 2023 表明多智能体辩论提高了事实性和推理能力,而 Liang et al. 2023 发现多样化的智能体角色有助于解决问题。Chen et al. 2024 展示了多智能体 LLM 系统中涌现的社会行为。
然而,基础模型能力与多智能体有效性之间的关系受到的系统关注有限。我们的工作通过提供受控证据来填补这一空白,即多智能体收益关键取决于基础模型的推理能力,这一发现对部署决策具有实际意义。
2.4 组合式和多跳推理
多跳推理需要结合多条信息才能得出结论。包括 HotpotQA Yang et al., 2018、MuSiQue Trivedi et al., 2022 和 StrategyQA Geva et al., 2021 在内的基准评估了这种能力,尽管这些基准使用自然语言而非我们采用的受控合成设置。
Press et al. 2023 研究了 LLMs 中的组合推理,发现在需要结合已学事实的任务中存在系统性失败。Dziri et al. 2023 分析了推理链,发现 LLMs अक्सर 依赖捷径而非真正的多步推理。Ofir et al. 2024 提出了理解组合泛化的理论框架。
我们的合成评估框架能够将多跳推理与自然语言基准中存在的混淆因素隔离开来,进行受控研究。
2.5 用于安全应用的LLM
LLMs 在安全任务中的应用已大幅增长。Fang et al. 2024 调查了用于网络安全领域的 LLM 智能体,记录了在漏洞检测、渗透测试和安全分析中的应用。Happe et al. 2023 展示了 LLM 在渗透测试中的有效性,而 Yang et al. 2024 研究了 LLM 在网络钓鱼检测中的应用。
密码推断是一个具体的安全应用,其中上下文推理至关重要。Hitaj et al. 2019 将 GANs 应用于密码生成,而 Wang et al. 2024 使用基于 Transformer 的学习方法。我们的工作不同之处在于侧重于从辅助信息进行上下文推断,而非密码分布的统计建模。
3 方法论
3.1 任务设计:合成多跳推理
我们设计了一个基于合成上下文推理任务的受控评估框架。每个任务实例包括:
- 上下文文档:一组包含虚构实体(公司、个人、组织)信息的合成文档
- 目标:根据需要综合多个上下文信息片段的规则构建的目标字符串
- 评估:通过模型是否能在固定次数的尝试内推断出目标字符串来衡量成功率
我们定义了两种任务类别以实现区分性评估:
结构化任务。这些任务的目标可以通过简单的模式匹配或单跳检索得出。例如,目标字符串可能是一个公司创始人的姓名后跟成立年份,两者都明确出现在文档中。这些任务作为对照,用于验证模型是否能执行基本信息提取。
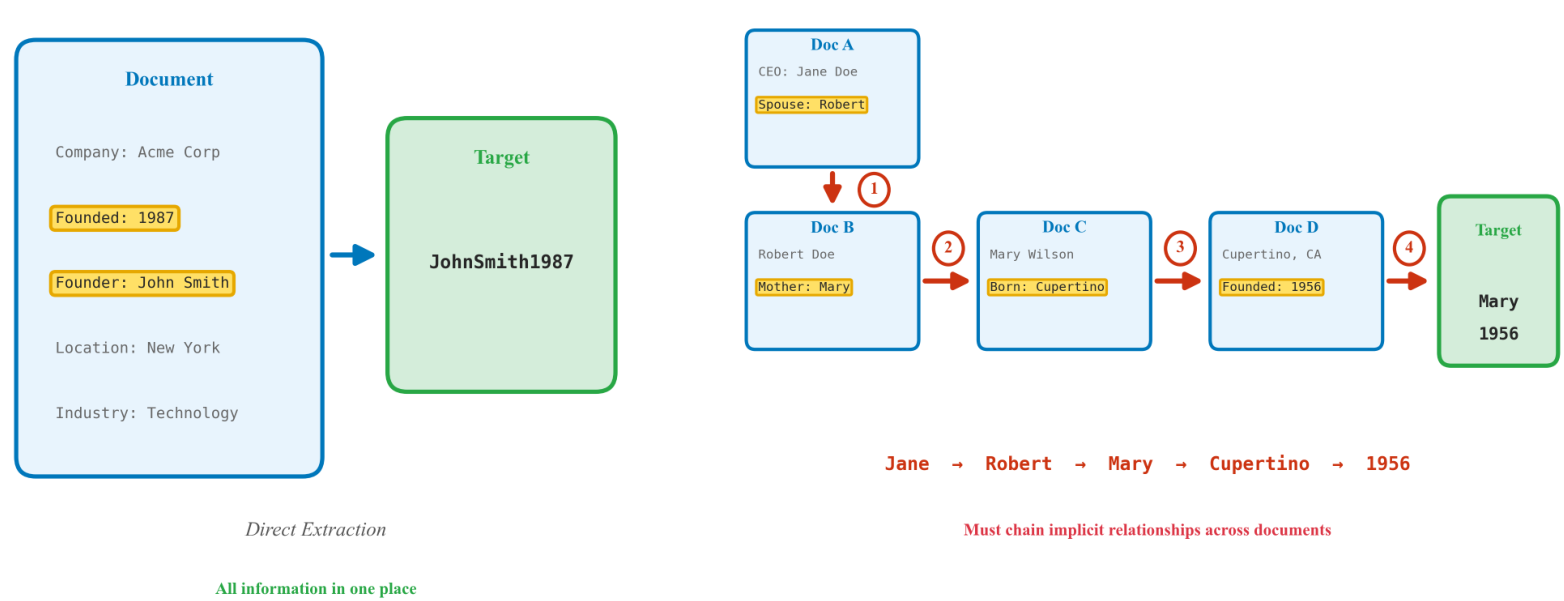
图 1:结构化(单跳)和上下文(多跳)推理任务的比较。结构化任务仅需要对共存信息进行模式匹配,而上下文任务需要通过隐含关系连接不同的事实。
上下文任务。这些任务需要真正的多跳推理,综合从不共存的信息。例如,目标字符串可能结合一个家庭成员的姓名(在一个文档部分中提及)和他们的出生年份(在不同部分中提及),这要求模型:(1) 识别家庭信息是相关的,(2) 找到家庭成员的姓名,(3) 找到相关的 temporal 信息,以及 (4) 适当地组合这些信息。
基于规则的基线。基于规则的基线有意地限制在模式匹配和实体提取;它不包括手工制作的多跳逻辑。这反映了常见的工业提取流程,而非最优的符号推理器。它在上下文任务上接近零的性能表明了任务的难度,而非基线过弱。
3.2 场景生成
我们沿着几个维度生成具有受控复杂度的场景:
- 信息密度:嵌入在干扰上下文中的相关事实数量
- 跳数:所需的推理步骤数(2-4 跳)
- 关系类型:家庭、专业、时间或地理关系
- 组合规则:如何组合提取的事实(连接、交错、转换)
所有生成的内容都是合成的,与真实个人或组织无关。目标字符串遵循由密码研究 Bonneau et al., 2012 启发但只包含虚构信息的现实模式。
3.3 智能体架构
我们评估了两种模型配置:
单智能体。模型接收完整上下文,并被提示分析文档并生成目标字符串候选项。我们使用思维链提示 Wei et al., 2022a 来鼓励显式推理。
多智能体架构
智能体流程:
- 分析智能体(信息提取) ← \leftarrow ← 文档
- 策略智能体(假设生成) ← \leftarrow ← 提取的事实
- 生成智能体(候选项生成) → \rightarrow → 候选项
- 验证 → \rightarrow → 成功 / 失败
反馈循环:失败时,结果反馈给策略智能体进行迭代细化。
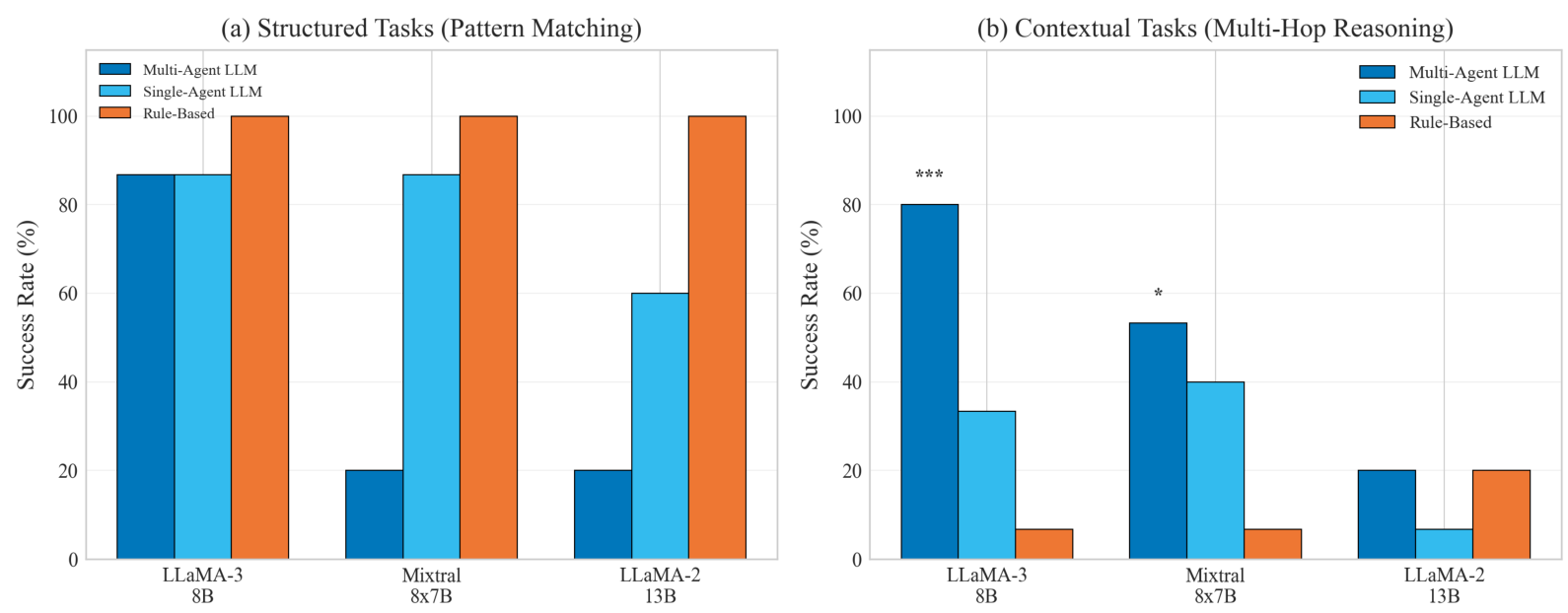
图 2:用于上下文推理的多智能体架构。分析智能体提取信息,策略智能体生成假设,生成智能体生成候选项。失败的尝试会通过反馈循环触发迭代细化。
多智能体。我们实现了一个三智能体架构(图 2):
- 分析智能体:从文档中提取结构化信息,识别实体、关系和重要事实
- 策略智能体:分析提取的信息和失败尝试,生成关于目标字符串构建的假设
- 生成智能体:根据策略智能体的建议生成目标字符串候选项
智能体通过结构化状态传递进行通信,通过 LangGraph 工作流实现,该工作流能够根据验证尝试的反馈进行迭代细化。
3.4 评估模型
我们评估了四种跨密集型和 MoE 架构的模型配置,这些模型均可在消费/研究硬件上访问:
| 模型 | 架构 | 总参数 | 活跃参数 |
|---|---|---|---|
| LLaMA-3 8B | 密集 | 8B | 8B |
| LLaMA-2 13B | 密集 | 13B | 13B |
| Mixtral 8 × 7 B 8 \times 7\mathrm{B} 8×7B | MoE | 47B | ∼ 12 B \sim 12 \mathrm{B} ∼12B |
| DeepSeek-V2 16B | MoE | 16B | ∼ 2.1 B \sim 2.1 \mathrm{B} ∼2.1B |
这种选择使得能够在以下方面进行比较:
- 模型系列:LLaMA-2 vs LLaMA-3(同一系列,不同代)
- 架构:密集型 vs 专家混合模型 (MoE)
- 参数数量:8B 到 47B 总参数
我们特意关注大多数研究人员可以访问的中等规模模型,而非需要专业基础设施的 70B+ 密集型模型。
3.5 扩展分析形式化
我们拟合了两种函数形式来表征扩展行为:
幂律模型 。遵循 Kaplan et al. 2020,我们拟合:
A c c ( N ) = a ⋅ N − α + b ( 1 ) \mathrm{Acc}(N) = a\cdot N^{-\alpha} + b \quad (1) Acc(N)=a⋅N−α+b(1)
其中 N N N 是参数数量, a , α , b a, \alpha, b a,α,b 是拟合常数,Acc 是任务准确率。
S型模型 。为了捕获阈值行为,我们拟合:
A c c ( N ) = L 1 + e − k ( log N − N 0 ) + c ( 2 ) \mathrm{Acc}(N) = \frac{L}{1 + e^{-k(\log N - N_{0})}} + c \quad (2) Acc(N)=1+e−k(logN−N0)L+c(2)
其中 L L L 是最大准确率, k k k 控制转换的陡峭程度, N 0 N_{0} N0 是阈值参数数量(在对数尺度上), c c c 是基线准确率。
S型模型捕获了相变行为:性能在 N ≪ e N 0 N \ll e^{N_{0}} N≪eN0 时保持接近基线,在 N ≈ e N 0 N \approx e^{N_{0}} N≈eN0 附近急剧转换,并在 N ≫ e N 0 N \gg e^{N_{0}} N≫eN0 时饱和。
4 实验设置
4.1 试验配置
- 总试验次数:120 次(每个模型 30 次 × 4 \times 4 ×4 个模型)
- 每种场景类型的试验次数:每个模型 15 次结构化 + 15 次上下文
- 每次试验最大尝试次数:50 次候选猜测
- 最大轮次(多智能体):3 个细化循环
- 难度级别:3 个级别,具有不同的推理跳数要求(2、3、4 跳)
4.2 评估指标
主要指标。
- 成功率:正确推断目标字符串的试验比例
- 统计显著性:用于比较不同方法成功率的 Fisher 精确检验
次要指标。
- 多智能体改进:多智能体和单智能体成功率之间的百分点差异
- 推理器消融:从流程中移除推理步骤时的性能下降
4.3 统计分析
我们报告了随机种子上的均值和标准误差。对于模型比较,我们使用带有 Bonferroni 校正的双尾 t 检验进行多重比较。对于扩展曲线拟合,我们使用非线性最小二乘法和参数估计的 Bootstrap 置信区间。我们使用 Fisher 精确检验进行二元成功率比较,t 检验进行跨种子均值比较,以及 Bootstrap 置信区间进行非线性曲线拟合,遵循混合离散-连续评估的标准实践。鉴于每个条件下的试验次数较少,报告的 p 值应被解释为指示性的而非决定性的,并且效应大小比精确的显著性阈值更具信息量。
幂律和 S 型拟合之间的模型选择使用贝叶斯信息准则(BIC):
B I C = k ln ( n ) − 2 ln ( L ^ ) ( 3 ) \mathrm{BIC} = k\ln (n) - 2\ln (\hat{L}) \quad (3) BIC=kln(n)−2ln(L^)(3)
其中 k k k 是参数数量, n n n 是数据点数量, L ^ \hat{L} L^ 是最大似然。
5 结果
5.1 任务-方法分离
表 2(此文本未提供,但内容可见)展示了跨模型和任务类型的主要结果。最引人注目的发现是任务-方法分离:基于规则的方法在结构化任务中占主导地位,而 LLM 智能体在推理任务中占主导地位。
关键观察 。最引人注目的模式是任务-方法分离:基于规则的方法在结构化任务上实现了 100 % 100\% 100% 的成功率,但在上下文推理任务上仅为 6.7 % 6.7\% 6.7%,而 LLM 多智能体系统则显示出相反的模式。对于有能力的模型(LLaMA-3 8B、Mixtral),多智能体协作提供了统计学上显著的改进(分别为 p < 0.001 p < 0.001 p<0.001 和 p = 0.014 p = 0.014 p=0.014),而较弱的模型则没有获益。对这些模式的详细分析将在后续章节中进行。
简单任务上的多智能体开销 。有趣的是,Mixtral 的多智能体配置在结构化任务上的性能低于其单智能体基线( 20 % 20\% 20% vs 86.7 % 86.7\% 86.7%)。我们将其归因于协调开销和假设探索干扰了仅需要直接提取的任务。这支持了我们更广泛的结论,即多智能体系统主要对需要真正推理的任务有益,而在无需推理时可能会适得其反。
5.2 统计显著性
图 3 将交叉效应与统计显著性注释可视化。
模型比较。我们对我们的数据加上文献参考点拟合了幂律和 S 型模型,以评估扩展行为。
外推阈值(推测性) 。为了探索与先前报告的一致性,我们进行了一项补充拟合,其中包含一个文献中报告的 70B 参考点以及我们的实验数据(8B、12B、13B 活跃参数)。我们强调,这个 70B 点不属于我们的实验数据,仅作为定性锚点。由此产生的 S 型拟合得出的估计阈值约为 50 B 50\mathrm{B} 50B 活跃参数。鉴于我们有限的模型范围,这具有高度推测性,验证这样一个阈值需要对 30B-70B 密集型模型进行实验。我们进行此分析主要是为了提出一个未来研究的假设,而不是作为一个已确立的发现。
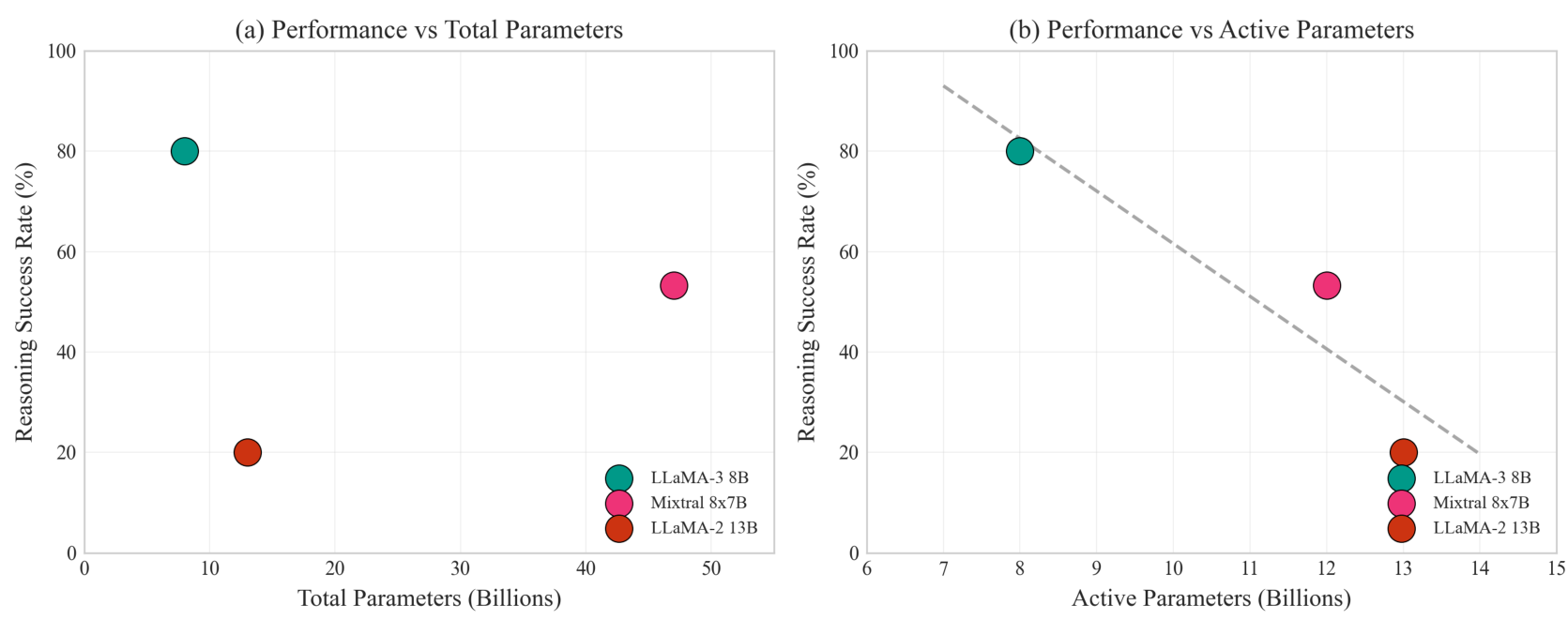
图 3:任务-方法分离。左:在结构化任务上,基于规则的方法达到 100%,而 LLM 性能各异。右:在上下文推理任务上,模式反转,LLM 多智能体系统显著优于基于规则的方法。星号表示统计显著性: ∗ ∗ ∗ p < 0.001 *** p < 0.001 ∗∗∗p<0.001, ∗ p < 0.05 * p < 0.05 ∗p<0.05。
5.3 实体提取分析
为了区分信息提取和推理能力,我们单独评估了实体提取准确率,即每个模型正确识别出的任务相关实体的比例。
所有测试模型都达到了高实体提取准确率( > 80 % >80\% >80%),这表明上下文推理的瓶颈在于组合提取的信息,而非检索信息。这一发现对基准设计具有启示:仅凭实体提取不足以评估多跳推理能力。
5.4 密集型 vs 专家混合模型
Mixtral 8 × 7 B 8\times 7\mathrm{B} 8×7B 提供了一个有趣的案例:总参数为 47B,但每次前向传播仅有约 12 B 12\mathrm{B} 12B 活跃参数,这测试了总参数还是活跃参数能更好地预测上下文推理能力。图 4 将这种比较可视化。
如果 Mixtral 的性能与 LLaMA-2 13B(相似的活跃参数)的性能更接近,而不是与 47B 密集型模型的预期性能接近,那么这与推理时活跃参数数量是衡量上下文推理能力的相关指标,而非总模型容量的假设是一致的。然而,由于只有两个 MoE 模型,这仍然是暗示性的而非结论性的。如果得到验证,这一假设具有实际意义:MoE 模型可能需要比密集型模型多得多的总参数才能获得等效的推理能力。

图 4:性能预测:总参数 vs 活跃参数。左图显示总参数与推理成功率之间的相关性较差(Mixtral 表现为异常值)。右图显示与活跃参数绘图时对齐性更好,支持活跃参数数量驱动推理能力的假设。
5.5 随推理复杂性增加的性能下降
图 5 显示了性能如何随所需推理跳数的变化而变化。此分析揭示了一个关键发现:多智能体架构在更高推理复杂性下保持性能,而单智能体性能则迅速下降。
关键观察。
- 基于规则的天花板效应 :基于规则的方法在 1 跳(模式匹配)任务上实现了完美性能,但对于 ≥ 2 \geq 2 ≥2 跳的任务则骤降至接近零,证实了这些任务确实需要超越模式匹配的推理。
- 单智能体性能下降 :单智能体 LLM 性能随跳数急剧下降,LLaMA-3 8B 从 2 跳时的 80 % 80\% 80% 下降到 4 跳时的 0 % 0\% 0%。
- 多智能体弹性 :多智能体架构在不同跳数下保持相对稳定的性能( 60 − 100 % 60-100\% 60−100%),这表明智能体协作能够支持跨复杂性级别的持续推理。
图 5:LLaMA-3 8B 性能与推理复杂性对比。多智能体架构在 2-4 个推理跳数下保持高成功率(60-100%),而单智能体性能从 2 跳时的 80% 下降到 4 跳时的 0%。基于规则的方法在 1 跳(模式匹配)任务上达到 100%,但在多跳任务上完全失败。
5.6 多智能体放大效应
图 6(此文本未提供,但内容可见)说明了基础模型能力与多智能体效益之间的相互作用。
解释。多智能体架构可以协调和细化推理,但它们无法创造基础模型所缺乏的推理能力。在我们测试的范围内,基础上下文成功率较高的模型从多智能体协作中获得了按比例更大的收益,这表明多智能体系统是放大现有能力,而不是弥补其缺失。
6 分析
6.1 与相变一致的观察(假设)
尽管我们的实验范围(8B-13B 活跃参数)并未涵盖完整的相变,但有几项观察与阈值行为的假设一致。我们将其呈现为暗示性模式,而非已证实的发现:
- 中等规模的陡峭斜率:即使在我们有限的范围内,上下文推理的改进速度也比结构化推理更快,这与 S 形曲线的早期部分一致。
- 活跃参数对齐:Mixtral 的性能遵循活跃参数而非总参数,这表明相变可能与每次前向传播的计算能力有关,而非存储知识。
- 与文献的一致性 :我们的外推阈值(约 50 B 50\mathrm{B} 50B)与 Wei et al. 2022b 报告的 50B-70B 范围内的涌现推理能力相符,尽管这种对齐可能是巧合。
我们强调,确认相变需要对跨越相变区域(30B-70B 密集型模型)进行实验。我们的贡献是识别了可访问的中等规模模型中的模式,这些模式激励了此类实验。
Original Abstract: We present a controlled study of multi-hop contextual reasoning in large language models, providing a clean demonstration of the task-method dissociation: rule-based pattern matching achieves 100% success on structured information retrieval but only 6.7% on tasks requiring cross-document reasoning, while LLM-based multi-agent systems show the inverse pattern, achieving up to 80% on reasoning tasks where rule-based methods fail. Using a synthetic evaluation framework with 120 trials across four models (LLaMA-3 8B, LLaMA-2 13B, Mixtral 8x7B, DeepSeek-V2 16B), we report three key findings: (1) Multi-agent amplification depends on base capability: statistically significant gains occur only for models with sufficient reasoning ability (p < 0.001 for LLaMA-3 8B, p = 0.014 for Mixtral), with improvements of up to 46.7 percentage points, while weaker models show no benefit, suggesting amplification rather than compensation; (2) Active parameters predict reasoning performance: Mixtral's performance aligns with its ~12B active parameters rather than 47B total, consistent with the hypothesis that inference-time compute drives reasoning capability in MoE architectures; (3) Architecture quality matters: LLaMA-3 8B outperforms LLaMA-2 13B despite fewer parameters, consistent with known training improvements. Our results provide controlled quantitative evidence for intuitions about multi-agent coordination and MoE scaling, while highlighting the dependence of multi-agent benefits on base model capability. We release our evaluation framework to support reproducible research on reasoning in mid-scale models.
PDF Link: 2601.04254v1
部分平台可能图片显示异常,请以我的博客内容为准
