
笔记整理:邹堉莹,东南大学硕士,研究方向为知识图谱与大语言模型相结合
论文链接:https://arxiv.org/abs/2404.14741
发表会议:EMNLP 2024
1. 动机
大语言模型与知识图谱结合的 现状仍有局 限 **。**大语言模型(LLMs)在自然语言处理任务中取得了巨大成功,但它们仍深受知识匮乏和幻觉(Hallucination)问题的困扰。为了缓解这些问题,学术界提出了将 LLMs 与知识图谱(KGs)相结合的方法。现有的主流范式主要分为两类:语义解析(Semantic Parsing)和检索增强(Retrieval Augmented)。这些方法利用 KGs 提供准确的事实知识,利用 LLMs 进行语言处理和推理。
然而,现有的评估通常基于传统的知识图谱问答(KGQA)任务,这类任务有一个极强的假设:即给定的知识图谱是完整(Complete) 的。换句话说,回答问题所需的所有事实三元组都必须存在于 KG 中。在这种理想化设定下,LLMs 主要扮演"代理(Agent)"的角色,即在 KG 中寻找现成的答案实体,而不是真正地融合 LLM 内部的参数化知识和 KG 的外部结构化知识。但是在现实世界的应用场景中,知识图谱往往是**不完整(Incomplete)**的,无法覆盖回答复杂问题所需的所有知识。例如,图谱中可能缺失了关键的关系边(如缺失了"某公司总部位于某城市"的三元组)。在这种情况下,传统的语义解析方法生成的查询语句将无法检索到结果;而现有的检索增强方法(如 ToG, RoG)一旦在图上检索不到路径,推理链条就会中断,或者被迫产生幻觉。
本文认为,要解决不完整知识图谱问答(IKGQA)问题,不能仅将 LLM 视为在图上游走的代理。LLM 本身拥有海量的内部知识,当外部图谱缺失时,LLM 应当能够利用内部知识"生成"缺失的链接。因此,本文提出了一个新的视角:在 IKGQA 任务中,将 LLM 同时视为代理(Agent)和知识库(KG) 。这不仅能利用图谱的准确性,还能利用 LLM 的生成能力来补全图谱的缺失,从而实现内外部知识的真正融合。
2. 贡献
本文的主要贡献可以总结为以下三点:
(1)重新定义任务与数据集构建:本文提出了利用LLMs 进行不完整知识图谱问答(IKGQA)的新任务,旨在更好地评估 LLMs 整合内外部知识的能力。由于缺乏现成的数据集,作者基于现有的 WebQSP 和 CWQ 数据集,通过随机删除关键三元组的方式构建了相应的 IKGQA 基准数据集,模拟了真实世界中图谱不完整的场景。
(2)提出GoG 框架:本文提出了一种名为Generate-on-Graph (GoG) 的免训练方法。GoG 采用了一种创新的"思考-搜索-生成(Thinking-Searching-Generating)"框架。在该框架下,模型不仅作为代理在图谱上探索,当遇到路径缺失时,还能作为知识库生成新的事实三元组,从而动态地填补图谱的空白。
**(3)验证了方法的有效性:**在两个基准数据集上的实验结果表明,GoG 的性能优于所有先前的基线方法(包括 ToG, StructGPT 等)。实验证明,通过将 LLM 视为代理和知识库的双重角色,GoG 能够有效结合不完整的 KGs 回答复杂问题,显著提升了推理的鲁棒性。
3. 方法
本文提出了 GoG (Generate-on-Graph) 方法,其核心是一个迭代式的**"思考-搜索-生成(Thinking-Searching-Generating)"**框架。该框架允许模型在推理的每一步动态决定是利用外部图谱还是内部知识,如图1和图2所示:
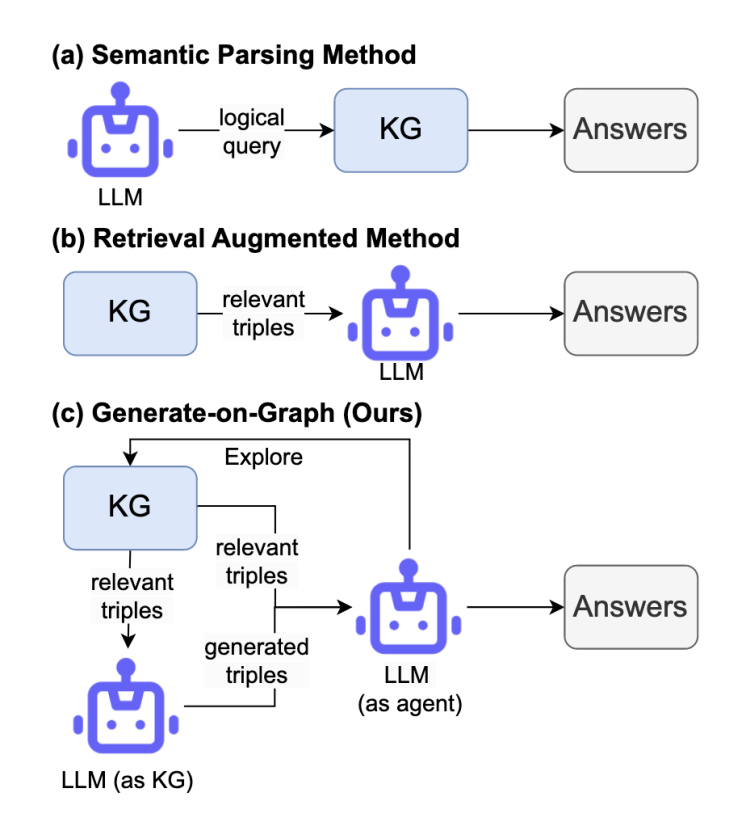
图1 LLMs 与 KGs 结合的三个范例,(c) 是GoG 方法框架图

图2 GoG 方法的整体流程图
本文提出的 GoG (Generate-on-Graph) 方法旨在解决知识图谱不完整(Incomplete KG)场景下的问答难题。其核心思想是打破传统方法将大语言模型(LLM)仅视为外部图谱检索代理的局限,转而采用一种"LLM 既是代理又是知识库"的双重角色设定。具体而言,GoG 构建了一个迭代式的"思考-搜索-生成(Thinking-Searching-Generating)"推理框架,该框架允许模型在推理的每一步动态地评估当前信息状态,并灵活决定是利用外部图谱的结构化知识,还是激活内部参数化记忆来生成缺失的链路。整个推理过程是一个循环往复的闭环,直到模型收集到足够的信息并输出最终答案。
推理过程的第一步是"思考(Thinking)"阶段,这相当于智能体的"大脑"。受 ReAct 框架的启发,GoG 将 LLM 视为在环境中交互的代理。在推理的每一个步骤中,模型首先会根据当前的上下文生成一个"想法(Thought)"。这个想法的作用至关重要,它负责对原始的复杂问题进行分解,规划出当前需要解决的子问题,或者评估现有的观测信息是否已经足以推导出最终答案。基于这个生成的想法,模型会进一步决策出具体的"动作(Action)"类型。如果模型判断所需信息可能存在于外部图谱中,它会执行搜索动作;如果模型判断图谱中可能缺失关键路径,或者之前的搜索未能返回有效结果,它则会转向生成动作,利用自身知识进行补全。
当模型决定从外部获取知识时,会进入"搜索(Searching)"阶段。这一阶段通过 Searche_i 指令调用,旨在探索目标实体e_i 在知识图谱中的邻居节点。搜索过程细分为"探索(Exploring)"和"过滤(Filtering)"两个子步骤。首先,在探索步骤中,GoG 利用预定义的 SPARQL 查询工具,从知识图谱中检索与目标实体相连的所有一跳关系和邻居节点。然而,由于图谱中热门实体的邻居节点数量往往极其庞大,直接将所有检索结果输入 LLM 会导致上下文过长并引入无关噪声。因此,在过滤步骤中,GoG 利用 LLM 的语义理解能力,根据上一步生成的"想法"对所有检索到的关系进行打分和排序,仅保留最相关的 Top-N 个关系。这些经过筛选的三元组(例如 (Apple Inc, headquarter, Cupertino))构成了当前的"观测(Observation)",并被反馈给模型用于辅助下一步的推理。
当外部搜索无法提供直接答案,或者图谱中存在路径缺失时,GoG 就会激活其最具创新性的"生成(Generating)"阶段。这是应对不完整知识图谱(IKGQA)任务的关键所在。该阶段包含"选择(Choosing)"、"生成(Generating)"和"验证(Verifying)"三个精细的步骤。首先,为了给生成过程提供准确的上下文依据,系统使用 BM25 算法从历史观测中检索出与当前想法最相关的三元组。接着,LLM 结合这些上下文线索及其内部存储的海量世界知识,生成新的事实三元组。例如,当图谱中缺失某城市的时区信息时,LLM 可以凭借记忆直接生成 (Cupertino, timezone, Pacific Standard Time)。为了最大限度地减少大模型常见的幻觉问题,系统会重复执行生成过程 n 次,并引入一个自我验证机制,让 LLM 对生成的三元组进行置信度评估,最终仅保留那些被判定为准确可靠的知识作为新的观测结果。
此外,为了处理生成过程中可能出现的图谱外新实体,GoG 还设计了实体链接机制。如果 LLM 生成了一个图谱中尚未记录或未被识别的实体,系统会执行链接操作,将其映射到图谱中对应的机器标识符(MID),或者利用 LLM 基于类型推断选择最相关的实体。上述的思考、搜索、生成以及验证过程会不断循环迭代,模型在每一步都会更新其状态和上下文,直到模型生成 Finishe_a 动作,标志着推理结束并输出最终的答案实体e_a。这种动态的、即时生成的机制,使得 GoG 能够有效地在图谱"断路"的地方"架桥",从而实现了对不完整知识图谱的鲁棒推理。
4. 实验
为评估 GoG 的性能,作者在数据集 WebQuestionSP (WebQSP) 和 Complex WebQuestion (CWQ) 上进行了实验。为了模拟 IKGQA 场景,作者随机删除了每个问题黄金关系路径(Gold Relation Path)中的关键三元组。设置了不同的缺失比例(20%, 40%, 60%, 80%)来测试模型的鲁棒性。
基线模型有以下3种:仅基于 LLM 的方法(IO, CoT, Self-Consistency)、语义解析方法(KB-BINDER, ChatKBQA)以及检索增强方法(StructGPT, RoG, ToG)。作者比较了这几种方法的Hits@1,总体结果如表1所示:
表1不同模型在不同设置下在两个数据集上的Hits@1得分(%)。CKG和IKG分别表示使用完全KG和不完全KG (IKG-40%)。其他基线的结果由我们重新运行2。黑体字表示最佳结果
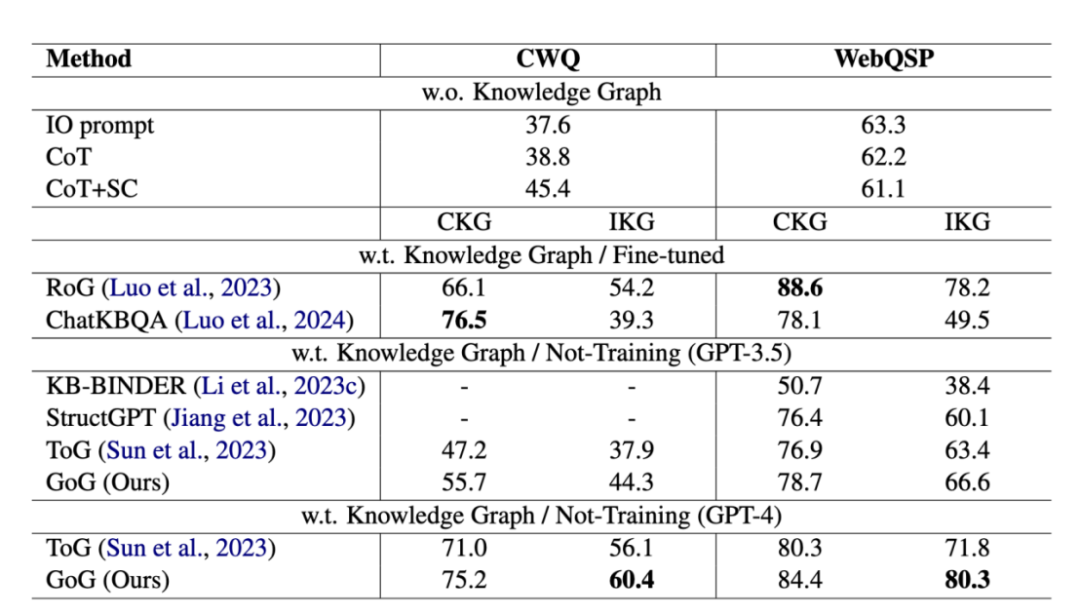
GoG 在各项指标上均优于基线模型:在完整 KG (CKG) 设定下,GoG 依然优于 ToG 等方法。这是因为 GoG 采用了动态子图扩展策略和明确的规划(Thinking),避免了像 ToG 那样在搜索中迷失方向。在不完整 KG (IKG) 设定下,语义解析方法(如 ChatKBQA)性能急剧下降,因为它们生成的查询语句无法匹配缺失的图结构。相比之下,GoG 展现出了极强的鲁棒性。特别是在 CWQ 数据集上,GoG 的性能显著高于 ToG,平均提升了 5.0% 。这直接证明了"生成动作"在填补知识空白方面的有效性。此外,实验对比了去除"生成动作"后的 GoG 变体(即退化为纯搜索代理)。结果显示,带有生成动作的 GoG 性能更好,证实了在图谱不完整时,利用 LLM 内部知识至关重要。而在使用 GPT-4 作为基座模型时,GoG 取得了最佳性能(WebQSP 上达到 84.4% Hits@1),达到了该领域的 SOTA 水平。
5. 总结
本文针对现有知识图谱问答方法在处理不完整图谱(Incomplete KG)时的局限性,提出了一项具有开创性的工作。
首先,文章敏锐地指出了传统方法(如语义解析和路径检索)过度依赖图谱完整性的弊端。在现实应用中,知识图谱往往存在大量的关系缺失,这导致现有的"LLM作为代理"范式经常面临推理中断或产生幻觉的问题。为了解决这一痛点,本文提出了 IKGQA 任务,并构建了相应的基准数据集,填补了该领域评估标准的空白。
其次,本文的核心创新在于提出了 Generate-on-Graph (GoG) 框架,创造性地将大语言模型同时视为"图上游走的代理"和"参数化的知识库"。通过设计精巧的"思考-搜索-生成"闭环机制,GoG 赋予了模型灵活的决策能力:当图谱知识完备时,它利用结构化数据的准确性进行检索;当图谱知识缺失时,它能够激活 LLM 的内部记忆,主动生成缺失的三元组来修补推理路径。这种机制完美地实现了外部结构化知识与内部参数化知识的互补融合。
最后,广泛的实验证明了 GoG 的有效性。特别是在高比例缺失(如缺失 40%-80% 三元组)的极端情况下,GoG 依然保持了较高的回答准确率,显著优于 ToG 和 RoG 等现有最先进方法。这项工作不仅为不完整知识图谱问答提供了一个强有力的解决方案,也为未来探索 LLM 与 KG 的深度协同(Synergy)提供了重要的启示:真正的智能体不应只是工具的使用者,更应该是知识的创造者和补全者。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。


点击阅读原文 ,进入 OpenKG 网站。